
Rumah >Peranti teknologi >AI >Meletupkan GPT3 dan Google PaLM sepenuhnya! Pengambilan semula model dipertingkatkan Atlas menyegarkan tugas sampel kecil berasaskan pengetahuan SOTA
Meletupkan GPT3 dan Google PaLM sepenuhnya! Pengambilan semula model dipertingkatkan Atlas menyegarkan tugas sampel kecil berasaskan pengetahuan SOTA

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-15 15:04:031320semak imbas
Secara tidak sedar, model besar + sampel kecil telah menjadi pendekatan arus perdana dalam bidang pembelajaran sampel kecil Dalam banyak konteks tugasan, idea biasa ialah melabelkan sampel data kecil dahulu, dan kemudian bermula dari pra-latihan Besar. model dilatih menggunakan sampel data kecil. Walaupun seperti yang telah kita lihat, model besar telah mencapai hasil yang menakjubkan pada pelbagai tugas pembelajaran sampel kecil, ia juga secara semula jadi meletakkan beberapa kelemahan yang wujud dalam model besar dalam perhatian pembelajaran sampel kecil.
Pembelajaran sampel kecil menjangkakan model mempunyai keupayaan untuk melengkapkan penaakulan bebas berdasarkan bilangan sampel yang kecil Dalam erti kata lain, model ideal harus menguasai idea penyelesaian masalah dengan menyelesaikan masalah , supaya menghadapi masalah baru yang timbul Soalan boleh membuat inferens dari satu kejadian ke yang lain. Walau bagaimanapun, keupayaan pembelajaran yang ideal dan praktikal bagi model besar + sampel kecil nampaknya bergantung pada jumlah besar maklumat yang disimpan semasa latihan model besar untuk menghafal proses menyelesaikan masalah Walaupun ia sangat berani pada pelbagai set data, ia akan sentiasa gagal. Ia membawa keraguan kepada orang ramai. Adakah pelajar yang belajar dengan cara ini benar-benar seorang pelajar yang berpotensi?

Kertas yang diperkenalkan hari ini oleh Meta AI mengambil pendekatan baharu dalam mengaplikasikan kaedah peningkatan perolehan kepada bidang pembelajaran sampel kecil, bukan sahaja Dengan hanya 64 contoh, ia mencapai ketepatan 42% pada set data Soalan Semulajadi (Soalan Semulajadi) Ia juga membandingkan model besar PaLM untuk mengurangkan bilangan parameter sebanyak 50 kali (540B->11B), dan meningkatkan kebolehtafsiran. kebolehkawalan, kebolehkemaskinian dan aspek lain mempunyai kelebihan ketara yang tidak dimiliki oleh model besar lain.
Tajuk kertas:Pembelajaran Beberapa Tangkapan dengan Retrieval Model Bahasa DitambahkanPautan kertas:https://arxiv.org/pdf/2208.03299.pdf
Mendapatkan semula kebolehkesanan dipertingkatkan
Pada mulanya kertas itu, dan bertanya kepada semua orang soalan: "Dalam bidang pembelajaran sampel kecil, adakah perlu menggunakan sejumlah besar parameter untuk menyimpan maklumat Melihat kepada pembangunan model besar, model besar berturut-turut boleh terus berfungsi?" pada SOTA Salah satu sebabnya ialah parameternya yang besar menyimpan maklumat yang diperlukan untuk masalah tersebut. Sejak kelahiran Transformer, model besar telah menjadi paradigma arus perdana dalam bidang NLP Dengan perkembangan beransur-ansur model besar, masalah "besar" sentiasa terdedah, dan agak bermakna untuk bertanya tentang keperluan "besar". Penulis kertas bermula dari Bermula daripada soalan ini, jawapan negatif diberikan kepada soalan ini, dan kaedahnya adalah untuk mendapatkan semula model yang dipertingkatkan.

Pencapaian kebolehkesanan dipertingkatkan, walaupun teknologinya digunakan terutamanya dalam tugas seperti menjawab soalan domain terbuka, pembacaan mesin dan penjanaan teks. retrieval Idea peneguhan boleh dikesan kembali ke era RNN NLP. Kekurangan model RNN yang tidak dapat menyelesaikan pergantungan jangka panjang data telah mendorong penyelidik untuk meneroka secara meluas penyelesaian, yang kami agak biasa, menggunakan mekanisme Perhatian untuk menyelesaikan masalah ketidakupayaan model untuk mengingati dengan berkesan. sekali gus membuka pintu kepada pra-latihan model besar.
Pada masa itu, sebenarnya ada cara lain, iaitu Cached LM Idea terasnya ialah kerana RNN mungkin tidak diingati sebaik sahaja ia memasuki bilik peperiksaan, maka biarkan sahaja Dalam peperiksaan buku terbuka RNN, mekanisme Cache diperkenalkan untuk menyimpan perkataan yang diramalkan semasa latihan dalam Cache Semasa ramalan, maklumat daripada kedua-dua pertanyaan dan indeks cache boleh digabungkan untuk menyelesaikan tugas, dengan itu menyelesaikan kekurangan RNN. model pada masa itu.
Hasilnya, teknologi peningkatan perolehan telah memulakan laluan yang sama sekali berbeza daripada model besar yang bergantung pada parameter untuk menghafal maklumat. Model berdasarkan peningkatan perolehan membolehkan pengenalan pengetahuan luaran daripada sumber yang berbeza, dan sumber perolehan semula ini termasuk korpus latihan, data luaran, data tidak diselia dan pilihan lain. Model peningkatan perolehan biasanya terdiri daripada retriever dan penjana Retriever memperoleh pengetahuan yang berkaitan daripada sumber perolehan luaran berdasarkan pertanyaan, dan penjana menggabungkan pertanyaan dengan pengetahuan berkaitan yang diperoleh untuk melaksanakan ramalan model.
Dalam analisis akhir, matlamat model yang dipertingkatkan semula adalah untuk mengharapkan model bukan sahaja belajar mengingat data, tetapi juga belajar mencari data sendiri. Ciri ini mempunyai kelebihan yang besar dalam banyak tugas berintensif pengetahuan dan model yang dipertingkatkan semula juga Kejayaan besar telah dicapai dalam bidang ini, tetapi sama ada peningkatan perolehan sesuai untuk pembelajaran beberapa pukulan tidak diketahui. Berbalik kepada kertas kerja ini dalam Meta AI, kami berjaya menguji aplikasi peningkatan perolehan dalam pembelajaran sampel kecil, dan Atlas muncul.
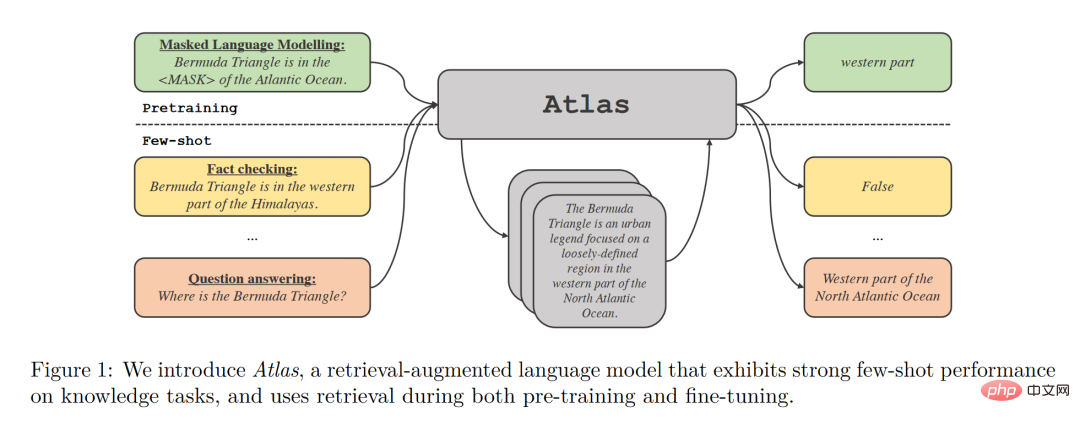
Struktur model
Atlas mempunyai dua submodel, retriever dan model bahasa. Apabila berhadapan dengan tugasan, Atlas menggunakan pencari untuk menjana dokumen top-k paling relevan daripada sejumlah besar korpus berdasarkan soalan input, dan kemudian meletakkan dokumen ini ke dalam model bahasa bersama-sama dengan pertanyaan soalan untuk menjana output yang diperlukan .

Strategi latihan asas model Atlas adalah untuk bersama-sama melatih retriever dan model bahasa menggunakan fungsi kehilangan yang sama. Kedua-dua retriever dan model bahasa adalah berdasarkan rangkaian Transformer yang telah terlatih, di mana:
- Retriever direka bentuk berdasarkan Contriever, yang telah dilatih dengan data tanpa pengawasan dan menggunakan pengekod dua lapisan, pertanyaan dan dokumen dikodkan secara bebas ke dalam pengekod, dan persamaan antara pertanyaan dan dokumen diperoleh melalui hasil darab titik keluaran yang sepadan. Reka bentuk ini membolehkan Atlas melatih retriever tanpa anotasi dokumen, dengan ketara mengurangkan keperluan memori.
- Model bahasa dilatih berdasarkan T5 dokumen dan pertanyaan yang berbeza disambung bersama dan diproses secara bebas oleh pengekod Akhirnya, penyahkod melakukan Perhatian Silang pada semua perenggan yang diambil siri untuk mendapatkan hasil akhir. Pendekatan Fusion-in-Decoder ini membantu Atlas menyesuaikan diri dengan berkesan kepada pengembangan bilangan dokumen.
Perlu diperhatikan bahawa penulis membandingkan dan menguji empat fungsi kehilangan dan situasi tanpa latihan bersama model retriever dan bahasa Hasilnya adalah seperti berikut:
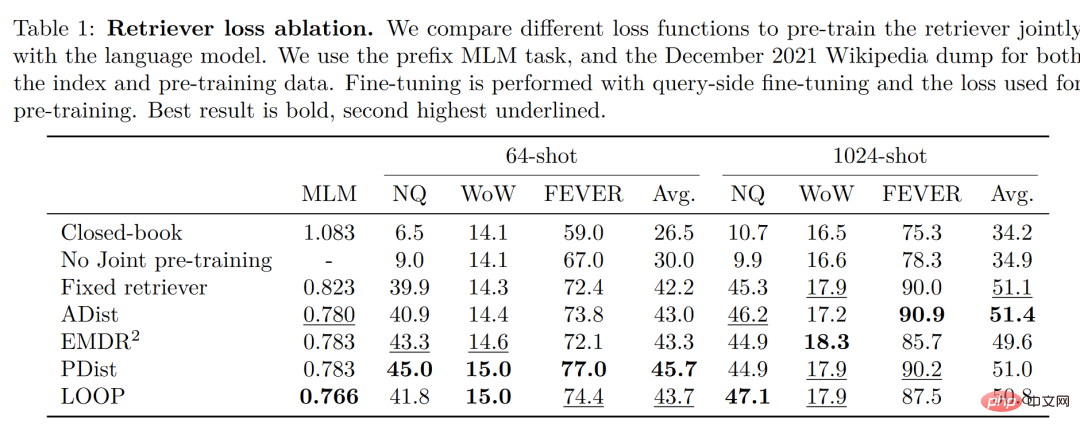
Dapat dilihat bahawa dalam persekitaran sampel yang kecil, ketepatan yang diperoleh dengan menggunakan kaedah latihan bersama adalah lebih tinggi daripada tidak menggunakan latihan bersama , penulis Disimpulkan bahawa latihan bersama retriever dan model bahasa ini adalah kunci kepada keupayaan pembelajaran pukulan kecil Atlas.
Hasil eksperimen
Dalam tugasan pemahaman bahasa berbilang tugas besar-besaran (MMLU), berbanding dengan model lain, Atlas hanya mempunyai 11B Dalam kes ini, ia mempunyai kadar ketepatan yang lebih baik daripada GPT-3, yang mempunyai 15 kali ganda bilangan parameter Atlas Selepas pengenalan latihan pelbagai tugas, kadar ketepatan dalam ujian 5 pukulan adalah hampir iaitu Gopher, yang mempunyai 25 kali ganda bilangan parameter Atlas.
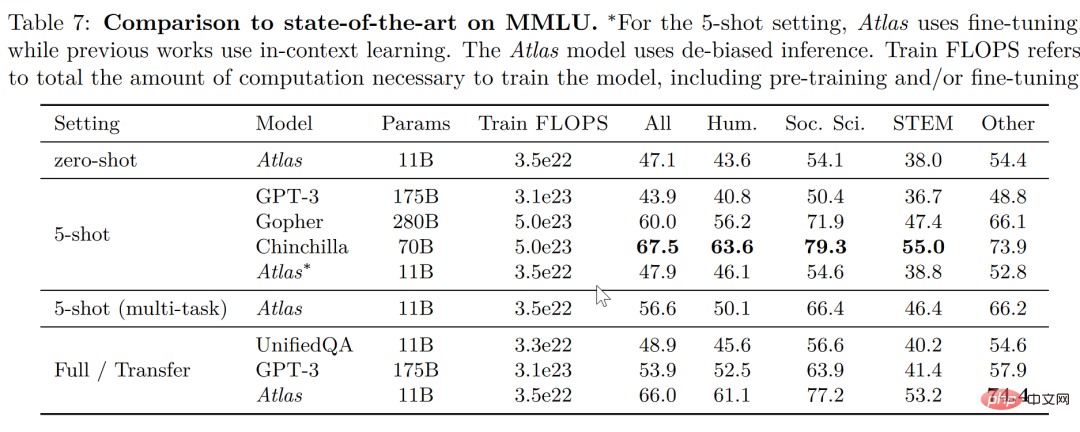
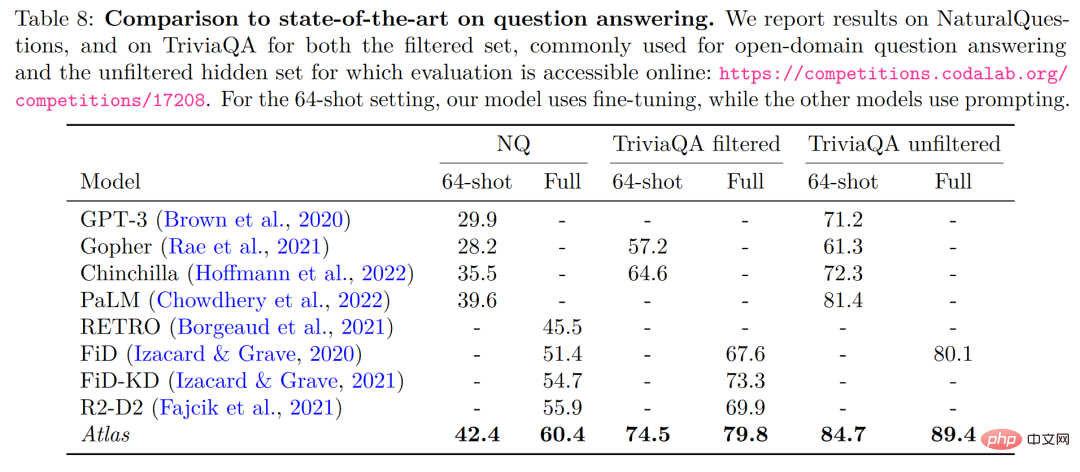
Dalam dua data ujian menjawab soalan domain terbuka - NaturalQuestions dan TriviaQA, prestasi Atlas dan model lain pada 64 contoh telah dibandingkan prestasi pada set latihan penuh ditunjukkan dalam rajah di bawah Atlas mencapai SOTA baharu dalam 64 pukulan, mencapai ketepatan 84.7% pada TrivuaQA menggunakan hanya 64 data.
Dalam tugasan semakan fakta (DEMAM), Atlas juga menunjukkan prestasi yang lebih baik pada sampel kecil berbanding Gopher dan Gopher, yang mempunyai berpuluh-puluh kali ganda. bilangan parameter sebagai Atlas, mengatasi Gopher sebanyak 5.1% dalam tugasan 15 pukulan.

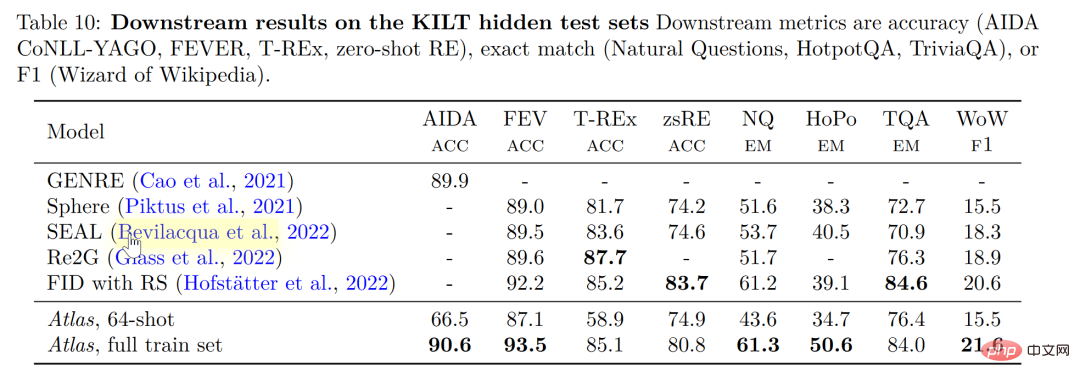
Pada KILT, penanda aras yang diterbitkan sendiri untuk tugas pemprosesan bahasa semula jadi intensif pengetahuan, ketepatan Atlas yang dilatih menggunakan 64 sampel dalam beberapa tugasan Ia malah hampir dengan ketepatan yang diperoleh oleh model lain menggunakan sampel penuh Selepas menggunakan sampel penuh untuk melatih Atlas, Atlas menyegarkan SOTA pada lima set data.
Kebolehtafsiran, kebolehkawalan dan kebolehkemaskinian
Menurut penyelidikan dalam kertas kerja ini, model peningkatan perolehan bukan sahaja mengambil kira lebih kecil dan lebih baik, tetapi juga Dari segi kebolehtafsiran, ia juga mempunyai kelebihan ketara yang tidak dimiliki oleh model besar lain. Sifat kotak hitam model besar menyukarkan penyelidik menggunakan model besar untuk menganalisis mekanisme operasi model Walau bagaimanapun, model yang dipertingkatkan dapat mengekstrak secara langsung dokumen yang diambil, supaya dengan menganalisis artikel yang diperoleh semula, kami. boleh mendapatkan pandangan tentang kerja Atlas. Sebagai contoh, kertas itu mendapati bahawa dalam bidang algebra abstrak, 73% daripada korpus model bergantung pada Wikipedia, manakala dalam bidang berkaitan etika, hanya 3% daripada dokumen yang diekstrak oleh pencari berasal dari Wikipedia, yang konsisten dengan manusia. gerak hati. Seperti yang ditunjukkan dalam carta statistik di sebelah kiri rajah di bawah, walaupun model lebih suka menggunakan data CCNet, dalam medan STEM yang lebih memfokuskan pada formula dan penaakulan, kadar penggunaan artikel Wikipedia telah meningkat dengan ketara.
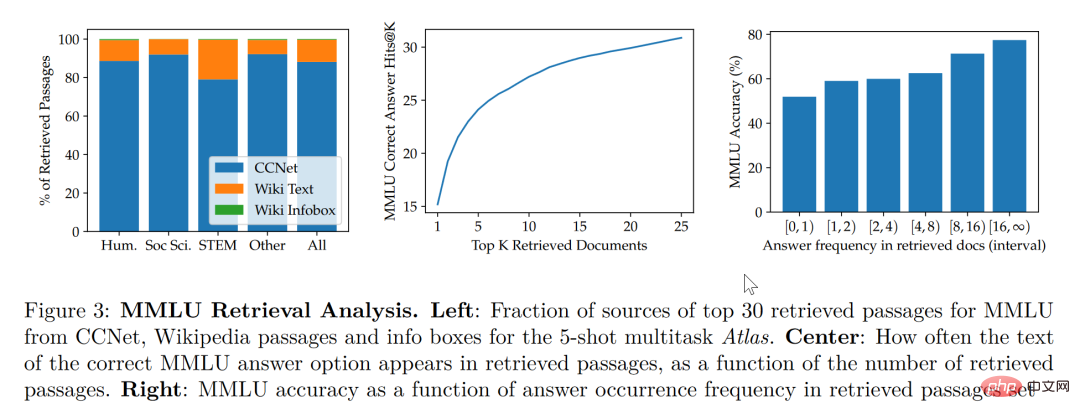
Mengikut carta statistik di sebelah kanan rajah di atas, penulis mendapati bahawa apabila bilangan artikel yang diambil yang mengandungi jawapan betul bertambah, model lebih tepat Kadar ketepatan juga meningkat Apabila artikel tidak mengandungi jawapan, ia hanya 55% betul Apabila jawapan disebut lebih daripada 15 kali, kadar ketepatan mencapai 77%. Di samping itu, apabila memeriksa secara manual dokumen yang diambil oleh 50 enjin carian, didapati bahawa 44% daripadanya mengandungi maklumat latar belakang yang berguna Jelas sekali, bahan-bahan ini yang mengandungi maklumat latar belakang tentang isu-isu boleh memberikan penyelidik peluang besar untuk mengembangkan bacaan mereka.
Secara umumnya, kita cenderung untuk berfikir bahawa model besar mempunyai risiko "kebocoran" data latihan, iaitu, kadangkala jawapan model besar untuk soalan ujian tidak berdasarkan keupayaan pembelajaran model tetapi pada Keupayaan ingatan model bermakna jawapan kepada soalan ujian bocor dalam jumlah besar korpus yang dipelajari oleh model besar Dalam kertas ini, selepas penulis menghapuskan maklumat korpus secara manual yang mungkin telah dibocorkan, ketepatan model menurun daripada 56.4%. Ia mencapai 55.8%, penurunan hanya 0.6%.
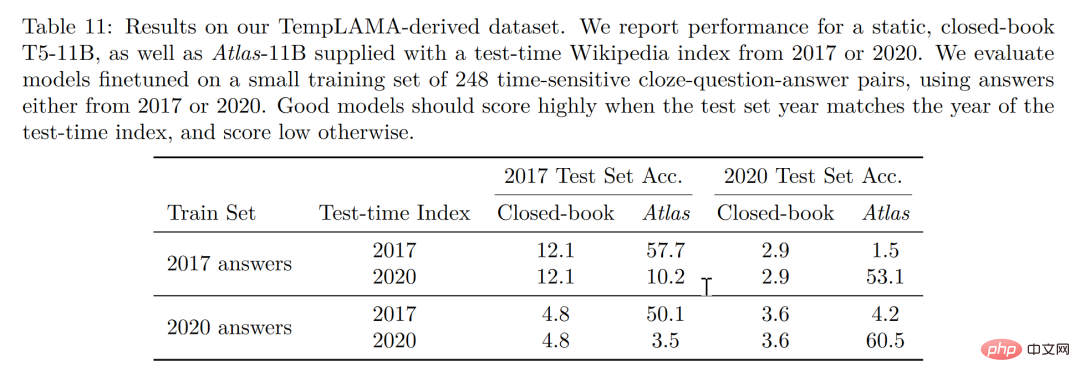
Akhir sekali, kebolehkemaskinian juga merupakan kelebihan unik bagi model peningkatan perolehan Model peningkatan perolehan boleh dikemas kini dari semasa ke semasa tanpa latihan semula, tetapi hanya dengan mengemas kini atau menggantikan korpus yang ia bergantung. pada. Dengan membina set data siri masa, seperti yang ditunjukkan dalam rajah di bawah, tanpa mengemas kini parameter Atlas, penulis mencapai ketepatan 53.1% hanya dengan menggunakan Atlas korpus 2020 Apa yang menarik ialah walaupun dengan penalaan halus data 2020 T5, T5 juga tidak menunjukkan prestasi yang baik Penulis percaya bahawa sebabnya sebahagian besarnya disebabkan oleh fakta bahawa data yang digunakan dalam pra-latihan T5 adalah data sebelum 2020.
Kesimpulan
Kita boleh bayangkan terdapat tiga pelajar, dan seorang pelajar hanya bergantung pada hafalan hafalan untuk menyelesaikan masalah, jawapan kepada masalah matematik boleh dibaca dengan tepat Seorang pelajar bergantung pada mencari buku Apabila menghadapi masalah, dia tidak akan terlebih dahulu mencari maklumat untuk mencari satu yang paling sesuai dan kemudian menjawab satu persatu. Pelajar terakhir adalah berbakat dan pintar dan boleh belajar dengan mudah Dengan sedikit pengetahuan dalam buku teks, anda dengan yakin boleh pergi ke bilik peperiksaan untuk memberi petunjuk.
Jelas sekali, ideal pembelajaran sampel kecil adalah untuk menjadi pelajar ketiga, tetapi realitinya berkemungkinan kekal di atas pelajar pertama. Model besar mudah digunakan, tetapi "besar" bukanlah matlamat utama model Kembali kepada niat asal pembelajaran sampel kecil untuk mengharapkan model mempunyai pertimbangan penaakulan dan keupayaan untuk membuat kesimpulan yang serupa dengan manusia, maka. kita dapat melihat bahawa kertas ini adalah dari perspektif yang berbeza Adalah baik untuk mengambil langkah ke hadapan, sekurang-kurangnya untuk memudahkan pelajar untuk tidak memuatkan banyak pengetahuan yang berpotensi berlebihan dalam kepalanya, tetapi untuk mengambil buku teks dan. perjalanan ringan mungkin juga membenarkan pelajar mengambil peperiksaan buku terbuka dengan buku teks untuk semakan berterusan , dan ia akan menjadi lebih dekat dengan kecerdasan daripada pelajar menghafal secara hafalan!

Atas ialah kandungan terperinci Meletupkan GPT3 dan Google PaLM sepenuhnya! Pengambilan semula model dipertingkatkan Atlas menyegarkan tugas sampel kecil berasaskan pengetahuan SOTA. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI