
Rumah >Peranti teknologi >AI >Google menyelesaikan masalah menyimpan dan memanipulasi data n-dimensi dengan perpustakaan perisian sumber terbuka
Google menyelesaikan masalah menyimpan dan memanipulasi data n-dimensi dengan perpustakaan perisian sumber terbuka

- 王林ke hadapan
- 2023-04-15 10:52:051543semak imbas
Banyak aplikasi dalam sains komputer dan pembelajaran mesin (ML) memerlukan pemprosesan set data berbilang dimensi yang merangkumi sistem koordinat, dan satu set data juga mungkin perlu menyimpan terabait atau petabait data. Sebaliknya, bekerja dengan set data sedemikian juga boleh mencabar kerana pengguna mungkin membaca dan menulis data pada selang masa yang tidak teratur dan pada skala yang berbeza, selalunya melakukan kerja selari yang meluas.
Untuk menyelesaikan masalah di atas, Google membangunkan TensorStore, pustaka perisian C++ dan Python sumber terbuka, direka untuk menyimpan dan mengendalikan data n-dimensi. Jeff Dean, ketua Google AI, juga menulis tweet bahawa TensorStore kini secara rasmi sumber terbuka.
Fungsi utama TensorStore termasuk:
- Menyediakan API bersatu untuk membaca dan menulis Berbilang format tatasusunan, termasuk zarr dan N5;
- Menyokong caching baca/tulis dan transaksi, dengan ciri atomicity, pengasingan, konsistensi dan ketahanan (ACID) yang kuat; daripada berbilang proses dan mesin; operasi pengindeksan boleh gubah sepenuhnya dan pandangan maya.
- TensorStore telah digunakan untuk menyelesaikan cabaran kejuruteraan dalam pengkomputeran saintifik dan juga telah digunakan untuk mencipta model pembelajaran mesin yang besar, seperti untuk mengurus model PaLM semasa Parameter latihan yang diedarkan (titik pemeriksaan ).
- Alamat GitHub: https://github.com/google/tensorstore
- API untuk akses dan manipulasi data
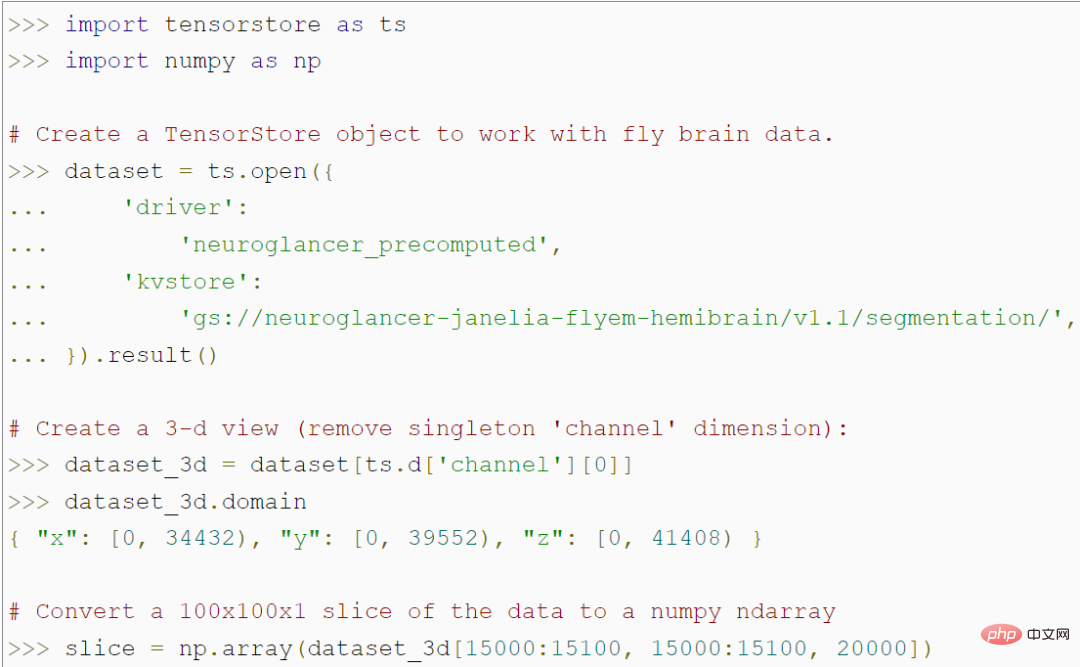
Selain itu, TensorStore menyediakan sokongan meluas untuk ciri pengindeksan lanjutan, termasuk penjajaran, paparan maya dan banyak lagi.
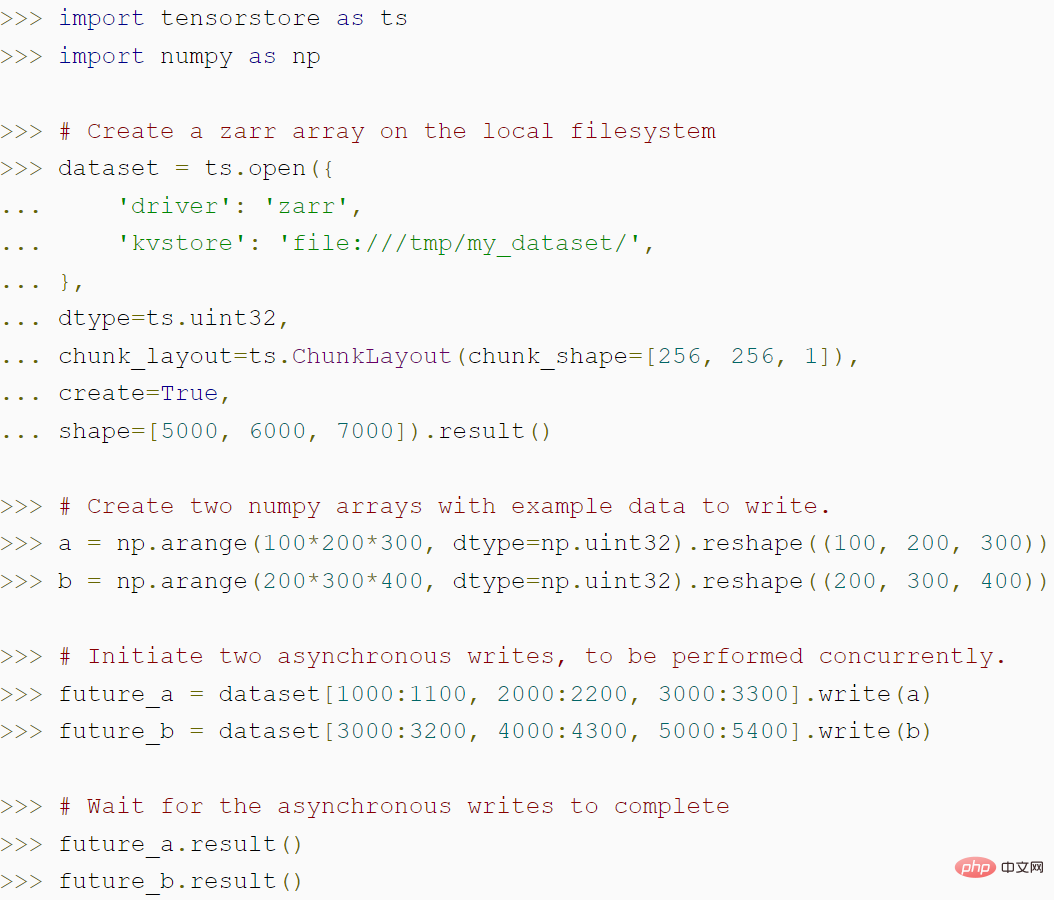
Kod berikut menunjukkan cara menggunakan TensorStore untuk mencipta tatasusunan zarr dan cara API tak segerak TensorStore boleh mencapai daya pemprosesan yang lebih tinggi:
 Pelanjutan Keselamatan dan Prestasi
Pelanjutan Keselamatan dan Prestasi
Sudah diketahui umum bahawa menganalisis dan memproses set data yang besar memerlukan sumber pengkomputeran yang ketara, selalunya memerlukan penyelarasan teras CPU atau pemecut yang diedarkan merentas berbilang mesin. Oleh itu, matlamat asas TensorStore adalah untuk melaksanakan pemprosesan selari untuk mencapai kedua-dua keselamatan dan prestasi tinggi. Malah, dalam ujian di pusat data Google, mereka mendapati bahawa apabila bilangan CPU meningkat, prestasi baca dan tulis TensorStore meningkat hampir secara linear:
Dalam prestasi baca dan tulis set data format zarr pada Storan Awan Google (GCS), prestasi baca dan tulis meningkat hampir secara linear dengan bilangan tugasan pengkomputeran.
Contoh 1 Model bahasa: Sejak kebelakangan ini, beberapa model bahasa lanjutan seperti PaLM telah muncul dalam bidang pembelajaran mesin. Model ini mengandungi ratusan bilion parameter dan mempamerkan keupayaan yang menakjubkan dalam pemahaman dan penjanaan bahasa semula jadi. Walau bagaimanapun, model ini menimbulkan cabaran kepada kemudahan pengkomputeran Secara khususnya, melatih model bahasa seperti PaLM memerlukan beribu-ribu TPU yang berfungsi secara selari. Membaca dan menulis parameter model dengan cekap ialah masalah yang dihadapi dalam proses latihan: contohnya, latihan diedarkan pada mesin yang berbeza, tetapi parameter mesti disimpan ke pusat pemeriksaan dengan kerap; latihan tunggal mesti hanya membaca set parameter tertentu untuk mengelakkan overhed yang diperlukan untuk memuatkan keseluruhan set parameter model (yang mungkin beratus-ratus GB). TensorStore boleh menyelesaikan masalah di atas. Ia telah digunakan untuk mengurus pusat pemeriksaan yang berkaitan dengan model besar (berbilang) dan telah disepadukan dengan rangka kerja seperti T5X dan Pathways. TensorStore menukar pusat pemeriksaan kepada storan format zarr dan memilih struktur blok untuk membolehkan setiap sekatan TPU dibaca dan ditulis secara bebas secara selari. Apabila menyimpan checkpoint, parameter ditulis dalam format zarr, blok rangkaian Kekisi dibahagikan lagi untuk penjeratan parameter pada TPU. Hos menulis blok zarr secara selari untuk setiap partition yang diberikan kepada TPU hos. Menggunakan API tak segerak TensorStore, latihan diteruskan walaupun data masih ditulis ke storan berterusan. Apabila pulih dari pusat pemeriksaan, setiap hos hanya membaca blok partition yang diberikan kepada hos itu. Contoh 2 Pemetaan 3D Otak: Connectomic diselesaikan sinaps bertujuan untuk memetakan pendawaian otak haiwan dan manusia pada tahap sambungan sinaptik individu. Untuk mencapai ini memerlukan pengimejan otak pada resolusi yang sangat tinggi (skala nano) pada medan pandangan milimeter atau lebih besar, menghasilkan petabait data. Walau bagaimanapun, pada masa ini, set data menghadapi masalah dengan penyimpanan, pemprosesan, dll. Malah satu sampel otak boleh memerlukan berjuta-juta gigabait ruang. Google telah menggunakan TensorStore untuk menyelesaikan cabaran pengiraan yang dikaitkan dengan set data connectomics berskala besar. Khususnya, TensorStore telah mula mengurus beberapa set data connectomics dan menggunakan Storan Awan Google sebagai sistem storan objek asas. Pada masa ini, TensorStore telah digunakan untuk set data korteks serebrum manusia H01, dengan data pengimejan asal ialah 1.4 PB (kira-kira 500000 * 350000 * 5000 piksel). Data mentah kemudiannya dibahagikan kepada blok bebas 128x128x16 piksel dan disimpan dalam format "Neuroglancer prakiraan", yang boleh dimanipulasi dengan mudah oleh TensorStore. Data asas (pembinaan semula otak terbang) boleh diakses dan dimanipulasi dengan mudah menggunakan TensorStore Mereka yang ingin bermula boleh menggunakan kaedah berikut untuk memasang pakej TensorStore PyPI: Contoh paparan


<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">tensorstore</span>
Atas ialah kandungan terperinci Google menyelesaikan masalah menyimpan dan memanipulasi data n-dimensi dengan perpustakaan perisian sumber terbuka. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI