
Rumah >Peranti teknologi >AI >Pembelajaran mesin menguasai kejuruteraan perisian berkualiti tinggi
Pembelajaran mesin menguasai kejuruteraan perisian berkualiti tinggi

- PHPzke hadapan
- 2023-04-14 16:31:121005semak imbas
Penterjemah |. Zhu Xianzhong
Pengulas | Sun Shujuan
Pengenalan
Secara umumnya, ujian perisian cenderung agak mudah: setiap input => output yang diketahui. Walau bagaimanapun, sepanjang sejarah ujian perisian, anda akan mendapati bahawa banyak ujian selalunya kekal pada tahap tekaan. Dalam erti kata lain, semasa ujian, pembangun membayangkan proses operasi pengguna, menganggarkan kemungkinan beban dan menganalisis masa yang akan diambil, kemudian menjalankan ujian dan membandingkan keputusan semasa dengan jawapan garis dasar. Jika kami mendapati bahawa tiada regresi, maka pelan binaan semasa dianggap betul, kemudian, teruskan dengan ujian berikutnya. Jika terdapat regresi, kembalikannya. Selalunya, kita sudah mengetahui outputnya, walaupun ia perlu ditakrifkan dengan lebih baik - sempadan regresi adalah jelas dan tidak terlalu kabur. Sebenarnya, di sinilah sistem pembelajaran mesin (ML) dan analitik ramalan masuk - menamatkan kekaburan.
Selepas ujian selesai, apa yang dilakukan oleh jurutera prestasi bukan sahaja melihat min aritmetik dan min geometri keputusan, mereka juga melihat data peratusan yang berkaitan. Sebagai contoh, apabila sistem sedang berjalan, selalunya 10% daripada permintaan yang paling perlahan disebabkan oleh ralat sistem - ralat ini akan mewujudkan keadaan yang sentiasa mempengaruhi kelajuan program.
Walaupun kami boleh mengaitkan atribut yang tersedia dalam data secara manual, ML mungkin memautkan atribut data lebih cepat daripada yang anda boleh. Selepas mengenal pasti keadaan yang menyebabkan 10% permintaan buruk, jurutera prestasi boleh membina senario ujian untuk menghasilkan semula tingkah laku. Menjalankan ujian sebelum dan selepas pembetulan boleh membantu mengesahkan bahawa pembetulan telah diperbetulkan.

Rajah 1: Keyakinan Keseluruhan dalam Metrik Prestasi
Prestasi Pembelajaran Mesin dan Sains Data
Pembelajaran mesin membantu menggalakkan pembangunan perisian, menjadikan teknologi pembangunan lebih teguh dan lebih mampu memenuhi keperluan pengguna dalam pelbagai bidang dan industri. Kami boleh mendedahkan corak sebab akibat dengan memasukkan data daripada saluran paip dan persekitaran ke dalam algoritma pembelajaran mendalam. Algoritma analitik ramalan yang digabungkan dengan kaedah kejuruteraan prestasi membolehkan daya pemprosesan yang lebih cekap dan lebih pantas, mendapatkan cerapan tentang cara pengguna akhir menggunakan perisian dalam senario semula jadi dan membantu pembangun mengurangkan kemungkinan produk rosak digunakan dalam persekitaran pengeluaran . Dengan mengenal pasti isu dan puncanya sejak awal, anda boleh membetulkannya pada awal kitaran hayat pembangunan dan mencegah kesan ke atas pengeluaran. Secara keseluruhan, berikut ialah beberapa cara anda boleh memanfaatkan analitik ramalan untuk meningkatkan prestasi aplikasi.
- Tentukan punca. Anda boleh menggunakan teknik pembelajaran mesin untuk menentukan punca masalah ketersediaan atau prestasi untuk memfokus pada bahagian lain yang memerlukan perhatian. Analitik ramalan kemudiannya boleh menganalisis pelbagai ciri setiap kluster, memberikan cerapan tentang perubahan yang perlu kami lakukan untuk mencapai prestasi ideal dan mengelakkan kesesakan.
- Pantau kesihatan aplikasi. Menggunakan teknologi pembelajaran mesin untuk melaksanakan pemantauan aplikasi masa nyata membantu perusahaan mengesan kemerosotan prestasi sistem dalam masa dan bertindak balas dengan cepat. Kebanyakan aplikasi bergantung pada berbilang perkhidmatan untuk mendapatkan status aplikasi lengkap model analisis ramalan dapat mengaitkan dan menganalisis data apabila aplikasi berjalan seperti biasa untuk mengenal pasti sama ada data masuk adalah outlier.
- Ramalkan beban pengguna. Kami bergantung pada trafik pengguna puncak untuk meningkatkan infrastruktur kami untuk menampung bilangan pengguna yang mengakses aplikasi kami pada masa hadapan. Pendekatan ini mempunyai had kerana ia tidak mengambil kira perubahan atau faktor lain yang tidak diketahui. Analitis ramalan membantu menggambarkan beban pengguna dan bersedia dengan lebih baik untuk respons, membantu pasukan merancang keperluan infrastruktur dan penggunaan kapasiti mereka.
- Ramalkan gangguan sebelum terlambat. Meramalkan masa henti permohonan atau gangguan sebelum ia berlaku akan membantu mengambil langkah pencegahan. Model analitis ramalan akan mengikuti senario gangguan sebelumnya dan terus memantau situasi yang sama untuk meramalkan gangguan masa hadapan.
- Berhenti melihat ambang dan mula menganalisis data. Jumlah besar data yang dijana oleh pemerhatian dan pemantauan memerlukan sehingga beberapa ratus megabait setiap minggu. Walaupun dengan alat analisis moden, anda mesti tahu terlebih dahulu apa yang anda cari. Ini menyebabkan pasukan tidak melihat secara langsung pada data, sebaliknya menetapkan ambang sebagai pencetus tindakan. Malah pasukan matang mencari pengecualian dan bukannya menggali data mereka. Untuk mengurangkan ini, kami menyepadukan model dengan sumber data yang tersedia. Model kemudian menapis data dan mengira ambang dari semasa ke semasa. Menggunakan teknik ini, model diberi makan dan mengagregat data sejarah, memberikan ambang berdasarkan kemusim dan bukannya ditetapkan oleh manusia. Menetapkan ambang berdasarkan algoritma membantu mencetuskan lebih sedikit makluman, sebaliknya, ini juga membawa kepada kebolehtindakan yang lebih baik dan nilai yang lebih tinggi.
- Analisis dan kaitkan merentas set data. Data anda kebanyakannya adalah siri masa, jadi lebih mudah untuk melihat pembolehubah individu berubah dari semasa ke semasa. Banyak trend timbul daripada interaksi pelbagai langkah. Sebagai contoh, masa tindak balas hanya akan jatuh jika pelbagai transaksi berlaku serentak pada sasaran yang sama. Bagi manusia, ini hampir mustahil, tetapi algoritma yang terlatih dengan betul boleh membantu menemui korelasi ini.
Kepentingan Data dalam Analitis Ramalan
“Data Besar” secara amnya merujuk kepada set data. Ya, ia adalah set data yang besar, kelajuannya meningkat dengan cepat, dan kandungannya berubah dengan ketara. Analisis data tersebut memerlukan kaedah khusus supaya kita boleh mengekstrak corak dan maklumat daripadanya. Dalam beberapa tahun kebelakangan ini, penambahbaikan dalam storan, pemproses, keselarian proses dan reka bentuk algoritma telah membolehkan sistem memproses sejumlah besar data dalam jumlah masa yang munasabah, membolehkan penggunaan kaedah ini dengan lebih meluas. Untuk mendapatkan hasil yang bermakna, anda mesti memastikan ketekalan data.
Contohnya, setiap projek mesti menggunakan sistem ranking yang sama, jadi jika satu projek menggunakan 1 sebagai nilai utama dan satu lagi menggunakan 5 - seperti orang yang menggunakan "DEFCON 5 " bermaksud "DEFCON 1 ”; maka nilai mesti dinormalisasi sebelum diproses. Algoritma ramalan terdiri daripada algoritma dan data yang dimasukkan ke dalamnya, dan pembangunan perisian menjana sejumlah besar data yang, sehingga baru-baru ini, terbiar, menunggu untuk dipadamkan. Walau bagaimanapun, algoritma analitik ramalan boleh memproses fail ini untuk bertanya dan menjawab soalan berdasarkan data ini untuk corak yang tidak dapat kami kesan, seperti: Adakah kita membuang masa untuk menguji Senario penggunaan?
- Bagaimanakah peningkatan prestasi berkaitan dengan kebahagiaan pengguna?
- Berapa lama masa yang diperlukan untuk membaiki kecacatan tertentu?
- Soalan ini dan jawapannya adalah untuk analitik ramalan – untuk lebih memahami perkara yang mungkin berlaku.
- Klasifikasi : Pengelasan digunakan untuk meramalkan hasil koleksi dengan membuat kesimpulan label (seperti "bawah" atau "atas") daripada input data Untuk memulakan, bahagikan koleksi kepada kategori yang berbeza.
- Regression: Regresi digunakan untuk meramalkan hasil set apabila pembolehubah output ialah set nilai sebenar. Ia akan memproses data input untuk membuat ramalan - contohnya, jumlah memori yang digunakan, baris kod yang ditulis oleh pembangun, dsb. Model ramalan yang paling biasa digunakan ialah rangkaian saraf, pokok keputusan, dan regresi linear dan logistik.
- Analisis kecacatan dalam persekitaran
- Nilai Kesan terhadap pengalaman pelanggan
- Kenal pasti corak masalah
- Cipta senario ujian yang lebih tepat, dsb.
- Jenis Kecacatan
- Pada peringkat manakah kecacatan itu ditemui
- Apakah punca kecacatan itu
- Adakah kecacatan itu boleh dihasilkan semula
Algoritma
Komponen utama analisis ramalan yang lain ialah algoritma yang anda perlukan untuk memilih atau melaksanakannya dengan teliti. Bermula dengan mudah adalah penting kerana model cenderung menjadi semakin kompleks, semakin sensitif terhadap perubahan dalam data input dan berpotensi memesongkan ramalan. Mereka boleh menyelesaikan dua jenis masalah: klasifikasi dan regresi (lihat Rajah 2).
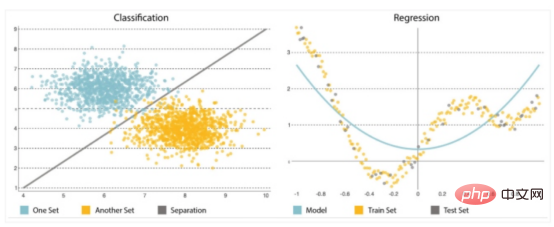
Rajah 2: Klasifikasi dan Regresi
Rangkaian Neural
Rangkaian saraf belajar melalui contoh dan menggunakan data sejarah dan semasa untuk meramalkan nilai masa hadapan. Seni bina mereka membolehkan mereka mengenal pasti hubungan kompleks yang tersembunyi dalam data, mereplikasi cara otak kita mengesan corak. Ia terdiri daripada banyak lapisan yang menerima data, mengira ramalan dan menyediakan output sebagai satu ramalan.
Pokok Keputusan
Pokok keputusan ialah kaedah analisis yang membentangkan keputusan dalam siri pilihan "jika/maka" untuk meramalkan potensi risiko pilihan tertentu dan pendapatan. Ia boleh menyelesaikan semua masalah klasifikasi dan menjawab soalan yang kompleks.
Seperti yang ditunjukkan dalam Rajah 3, pepohon keputusan adalah serupa dengan pepohon atas ke bawah yang dijana oleh algoritma yang mengiktiraf pelbagai cara untuk membahagikan data kepada sekatan seperti cawangan untuk Menjelaskan keputusan masa hadapan dan membantu mengenal pasti laluan keputusan.
Jika mengambil masa lebih daripada tiga saat untuk dimuatkan, satu dahan dalam pokok itu mungkin merupakan pengguna yang meninggalkan troli mereka. Di bawah ini, cawangan lain mungkin menunjukkan sama ada mereka perempuan. Jawapan "ya" meningkatkan kepentingan, kerana analisis menunjukkan wanita lebih cenderung untuk membuat pembelian impulsif, dan kelewatan ini boleh membawa kepada runcing.
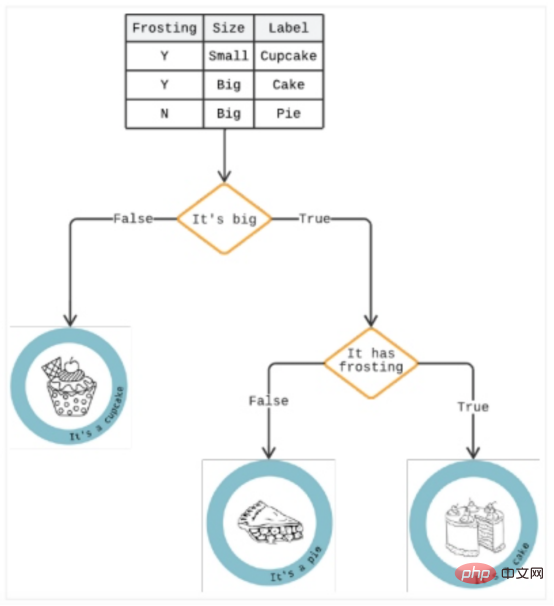
Rajah 3: Contoh pokok keputusan
Regression linear dan logistik
Regression Ia adalah salah satu kaedah statistik yang paling popular. Ini penting apabila menganggarkan nombor, seperti jumlah sumber tambahan yang perlu kami tambahkan pada setiap perkhidmatan semasa jualan Black Friday. Banyak algoritma regresi direka untuk menganggarkan perhubungan antara pembolehubah dan mencari corak utama dalam set data yang besar dan bercampur, serta perhubungan di antara mereka. Ia terdiri daripada model regresi linear mudah (mengira fungsi garis lurus yang sesuai dengan data) kepada regresi logistik (mengira lengkung) (Rajah 4).
Linear dan Logistik RegresiPerbandingan keseluruhan | |
Linear Kembali |
Regression logistik |
| digunakan untuk menentukan julat nilai berterusan, seperti risiko lonjakan trafik pengguna dalam beberapa bulan akan datang. |
Ini ialah kaedah statistik di mana parameter diramalkan berdasarkan set lama. Ia berfungsi paling baik untuk klasifikasi binari: set data dengan y=0 atau 1, dengan 1 mewakili kelas lalai dan . Namanya berasal daripada fungsi penukarannya ( ialah fungsi logik ) . |
Ia diwakili sebagai y=a+bx, dengan x ialah set input yang digunakan untuk menentukan output y. Pekali a dan b digunakan untuk mengukur hubungan antara x dan y, dengan a ialah pintasan dan b ialah kecerunan garis. |
Ia diwakili oleh fungsi logik: di mana , β0 ialah pintasan, β1 ialah kadarnya. Ia menggunakan data latihan untuk mengira pekali yang meminimumkan ralat antara keputusan yang diramalkan dan sebenar. |
Matlamatnya adalah untuk menyesuaikan garis lurus yang paling hampir dengan kebanyakan mata, mengurangkan jarak atau ralat antara y dan garis lurus. |
Ia membentuk lengkung berbentuk S di mana ambang digunakan untuk menukar kebarangkalian kepada pengelasan binari. |
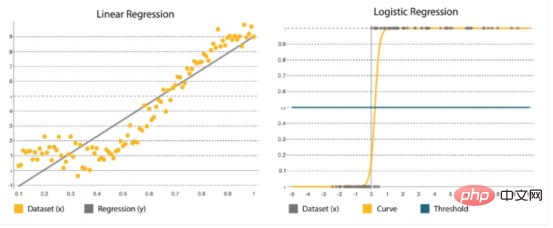
Rajah 4: Regresi Linear vs. Regresi Logistik
Ini adalah kaedah pembelajaran yang diselia kerana algoritma menyelesaikan sifat tertentu. Pembelajaran tanpa pengawasan digunakan apabila anda tidak memikirkan hasil tertentu, tetapi ingin mengenal pasti corak atau aliran yang mungkin. Dalam kes ini, model akan menganalisis seberapa banyak kombinasi ciri yang mungkin untuk mencari korelasi yang boleh dilakukan oleh manusia.
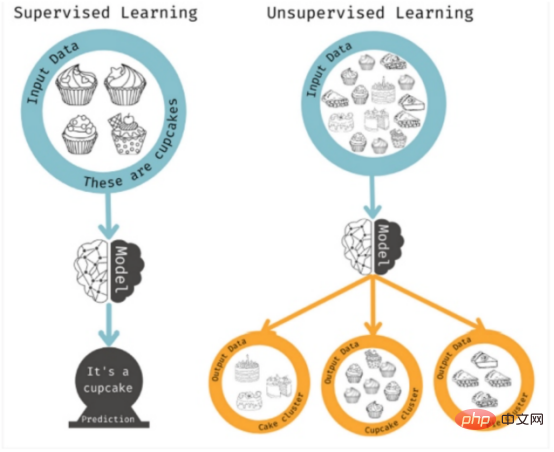
Rajah 5: Pembelajaran diselia dan tidak diselia
"Anjakan ke kiri" dalam kejuruteraan prestasi
Jadikan kejuruteraan prestasi lebih mengutamakan pengguna menggunakan algoritma sebelumnya untuk mengukur persepsi pengguna terhadap produk dan aplikasi. Setelah semua maklumat dikumpul, ia mesti disimpan dan dianalisis melalui alat dan algoritma yang sesuai. Data ini boleh termasuk log ralat, kes ujian, keputusan ujian, peristiwa pengeluaran, fail log aplikasi, dokumen projek, log peristiwa, jejak dan banyak lagi. Kami kemudiannya boleh menggunakan ini pada data untuk mendapatkan pelbagai cerapan:
Teknologi ini menyokong pendekatan anjakan ke kiri kepada kualiti, membolehkan anda meramalkan masa yang diperlukan untuk melaksanakan ujian prestasi, bilangan kecacatan yang mungkin dikenal pasti dan bilangan kecacatan yang mungkin membawa kepada pengeluaran, sekali gus membolehkan ujian prestasi. Liputan yang lebih baik dan cipta pengalaman pengguna yang tulen. Isu kebolehgunaan, keserasian, prestasi dan keselamatan boleh dihalang dan diperbetulkan tanpa memberi kesan kepada pengguna.
Berikut ialah beberapa contoh jenis maklumat yang boleh membantu meningkatkan kualiti:
Setelah anda memahami perkara ini, anda boleh membuat perubahan dan membuat ujian untuk mengelakkan isu yang serupa dengan lebih cepat.
Kesimpulan
Jurutera perisian telah membuat beratus-ratus andaian sejak permulaan pengaturcaraan. Tetapi pengguna digital hari ini lebih menyedari perkara ini dan kurang bertolak ansur dengan kesilapan dan kegagalan. Sebaliknya, perniagaan juga berlumba-lumba untuk menyediakan pengalaman pengguna yang lebih menarik dan digilap melalui perkhidmatan yang disesuaikan dan perisian kompleks yang semakin sukar untuk diuji.
Hari ini, segala-galanya perlu berfungsi dengan lancar dan menyokong semua penyemak imbas, peranti mudah alih dan apl yang popular. Kemalangan walaupun beberapa minit boleh menyebabkan kerosakan beribu-ribu atau berjuta-juta dolar. Untuk mengelakkan isu daripada timbul, pasukan mesti menyepadukan penyelesaian kebolehmerhatian dan pengalaman pengguna sepanjang kitaran hayat perisian. Menguruskan kualiti dan prestasi sistem yang kompleks memerlukan lebih daripada sekadar melaksanakan kes ujian dan menjalankan ujian beban. Aliran boleh membantu anda menentukan sama ada keadaan terkawal, bertambah baik atau bertambah buruk dan seberapa cepat. Teknologi pembelajaran mesin boleh membantu meramalkan isu prestasi supaya pasukan boleh membuat pelarasan pembetulan. Akhir sekali, mari kita simpulkan dengan petikan daripada Benjamin Franklin: "Seesen pencegahan bernilai satu paun penawar."
Pengenalan Penterjemah
Zhu Xianzhong, komuniti 51CTO editor, blogger pakar 51CTO, pensyarah, guru komputer di sebuah universiti di Weifang, dan seorang veteran dalam industri pengaturcaraan bebas.
Tajuk asal: Kejuruteraan Prestasi Dikuasakan oleh Pembelajaran Mesin, pengarang:
Atas ialah kandungan terperinci Pembelajaran mesin menguasai kejuruteraan perisian berkualiti tinggi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI