
Rumah >Peranti teknologi >AI >Kerja baru oleh Jeff Dean dan lain-lain: Lihat model bahasa dari sudut lain, ia tidak boleh ditemui jika skala tidak mencukupi
Kerja baru oleh Jeff Dean dan lain-lain: Lihat model bahasa dari sudut lain, ia tidak boleh ditemui jika skala tidak mencukupi

- 王林ke hadapan
- 2023-04-14 12:52:031463semak imbas
Model bahasa telah memberi kesan revolusioner pada pemprosesan bahasa semula jadi (NLP) dalam beberapa tahun kebelakangan ini. Adalah diketahui bahawa memanjangkan model bahasa, seperti parameter, boleh membawa kepada prestasi yang lebih baik dan kecekapan sampel pada pelbagai tugasan NLP hiliran. Dalam kebanyakan kes, kesan penskalaan pada prestasi selalunya boleh diramalkan oleh undang-undang penskalaan, dan kebanyakan penyelidik telah mengkaji fenomena yang boleh diramal.
Sebaliknya, 16 penyelidik termasuk Jeff Dean, Percy Liang, dsb. bekerjasama dalam kertas kerja "Keupayaan Muncul Model Bahasa Besar" Mereka membincangkan fenomena model besar yang tidak dapat diramalkan dan Ini dipanggil kebolehan muncul model bahasa besar. Apa yang dipanggil kemunculan bermaksud bahawa beberapa fenomena tidak wujud dalam model yang lebih kecil tetapi wujud dalam model yang lebih besar. Mereka percaya bahawa keupayaan model ini muncul.
Kemunculan sebagai idea telah lama dibincangkan dalam bidang seperti fizik, biologi dan sains komputer, dan kertas kerja ini bermula dengan definisi umum kemunculan yang diadaptasi daripada penyelidikan Steinhardt, dan berakar umbi dalam artikel yang dipanggil More Is Different oleh pemenang Hadiah Nobel dan ahli fizik Philip Anderson pada tahun 1972.
Artikel ini meneroka kemunculan saiz model, seperti yang diukur oleh pengiraan latihan dan parameter model. Secara khusus, kertas ini mentakrifkan keupayaan muncul model bahasa besar sebagai keupayaan yang tidak terdapat dalam model berskala kecil tetapi terdapat dalam model berskala besar oleh itu, model berskala besar tidak boleh diramalkan dengan hanya mengekstrapolasi peningkatan prestasi kecil; model skala. Kajian ini menyiasat keupayaan kemunculan model yang diperhatikan dalam julat kerja terdahulu dan mengklasifikasikannya ke dalam tetapan seperti kiu pukulan kecil dan kiu dirangsang.
Keupayaan model yang muncul ini memberi inspirasi kepada penyelidikan masa depan tentang sebab keupayaan ini diperoleh dan sama ada skala yang lebih besar memperoleh lebih banyak keupayaan yang muncul dan menyerlahkan ini Kepentingan penyelidikan.

Alamat kertas: https://arxiv.org/pdf/2206.07682.pdf
Tugas menggesa sampel kecil
Artikel ini mula-mula membincangkan keupayaan yang muncul dalam paradigma menggesa. Contohnya, dalam gesaan GPT-3, diberikan gesaan tugas model bahasa yang telah dilatih, model boleh melengkapkan respons tanpa latihan lanjut atau kemas kini kecerunan parameter. Di samping itu, Brown et al mencadangkan gesaan sampel kecil, di mana mereka menggunakan beberapa contoh input-output dalam konteks model (input) sebagai gesaan (mukadimah), dan kemudian meminta model untuk melaksanakan tugas inferens yang tidak kelihatan. Rajah 1 menunjukkan contoh gesaan.
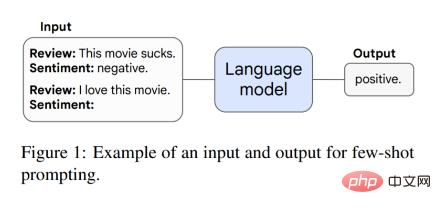

Apabila model mempunyai prestasi stokastik dan mempunyai skala tertentu, tugas boleh dilakukan dengan sampel kecil gesaan, Pada masa ini, keupayaan muncul akan muncul, dan kemudian prestasi model akan jauh lebih tinggi daripada prestasi rawak. Rajah di bawah menunjukkan 8 keupayaan muncul bagi 5 siri model bahasa (LaMDA, GPT-3, Gopher, Chinchilla dan PaLM).

BIG-Bench: Rajah 2A-D menggambarkan empat contoh kecil tugasan segera yang muncul daripada BIG-Bench, BIG-Bench ialah satu set lebih daripada 200 penanda aras penilaian model bahasa. Rajah 2A menunjukkan penanda aras aritmetik yang menguji penambahan dan penolakan nombor 3 digit, dan pendaraban nombor 2 digit. Jadual 1 memberikan lebih banyak keupayaan muncul BIG-Bench.

Strategi segera yang dipertingkatkan
Pada masa ini, walaupun pembayang sampel kecil ialah cara paling biasa untuk berinteraksi dengan model bahasa yang besar, kerja baru-baru ini telah mencadangkan beberapa pembayang lain dan strategi penalaan halus untuk meningkatkan lagi keupayaan model bahasa. Artikel ini juga menganggap teknologi sebagai keupayaan yang muncul jika ia tidak menunjukkan peningkatan atau berbahaya sebelum digunakan pada model yang cukup besar.
Penaakulan berbilang langkah: Untuk model bahasa dan model NLP, tugas penaakulan, terutamanya yang melibatkan penaakulan berbilang langkah, sentiasa menjadi cabaran besar . Strategi dorongan baru-baru ini yang dipanggil rantaian pemikiran membolehkan model bahasa menyelesaikan jenis masalah ini dengan membimbing mereka menjana satu siri langkah perantaraan sebelum memberikan jawapan akhir. Seperti yang ditunjukkan dalam Rajah 3A, apabila menskalakan kepada 1023 latihan FLOP (~100B parameter), gesaan rantaian pemikiran hanya mengatasi gesaan standard tanpa langkah perantaraan.
Arahan berikut: Seperti yang ditunjukkan dalam Rajah 3B, Wei et al mendapati bahawa apabila FLOP latihan adalah 7·10^21 (parameter 8B) atau lebih kecil, arahan penalaan halus (. arahan mengikut) -finetuning) teknik menjejaskan prestasi model dan hanya meningkatkan prestasi apabila melanjutkan FLOP latihan kepada 10^23 (~100B parameter).
Pelaksanaan program: Seperti yang ditunjukkan dalam Rajah 3C, dalam penilaian dalam domain penambahan 8-bit, menggunakan pad awal hanya membantu ∼9 · 10^19 latihan FLOP (parameter 40M) atau model yang lebih besar. Rajah 3D menunjukkan bahawa model ini juga boleh digeneralisasikan kepada penambahan 9-bit di luar domain, yang berlaku dalam ∼1.3 · 10^20 latihan FLOP (parameter 100M).

Artikel ini membincangkan kuasa kemunculan model bahasa, yang setakat ini hanya diperhatikan pada skala pengiraan tertentu Prestasi bermakna . Keupayaan model yang muncul ini boleh merangkumi pelbagai model bahasa, jenis tugas dan senario percubaan. Kewujudan kemunculan ini bermakna penskalaan tambahan dapat mengembangkan lagi keupayaan model bahasa. Keupayaan ini adalah hasil daripada sambungan model bahasa yang baru ditemui Bagaimana ia muncul dan sama ada lebih banyak sambungan akan membawa lebih banyak keupayaan muncul mungkin merupakan hala tuju penyelidikan masa hadapan yang penting dalam bidang NLP.
Untuk maklumat lanjut, sila rujuk kertas asal.
Atas ialah kandungan terperinci Kerja baru oleh Jeff Dean dan lain-lain: Lihat model bahasa dari sudut lain, ia tidak boleh ditemui jika skala tidak mencukupi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI