
Rumah >Peranti teknologi >AI >Model penerokaan berdasarkan kecerunan lawan dan penggunaannya dalam ramalan klik
Model penerokaan berdasarkan kecerunan lawan dan penggunaannya dalam ramalan klik

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-13 23:34:011729semak imbas
1. Abstrak
Model kedudukan memainkan peranan penting dalam sistem pengiklanan, pengesyoran dan carian. Dalam modul kedudukan, teknologi anggaran kadar klikan adalah keutamaan. Pada masa ini, kebanyakan teknologi ramalan kadar klik lalu dalam industri menggunakan algoritma pembelajaran mendalam untuk melatih rangkaian saraf dalam berdasarkan pemacu data Walau bagaimanapun, masalah yang sepadan yang disebabkan oleh pemacu data ialah projek baharu dalam sistem pengesyoran akan mengalami masalah permulaan yang sejuk.
Kaedah Eksplorasi-Eksploitasi (E&E) biasanya digunakan untuk menangani masalah kitaran data dalam sistem pengesyoran dalam talian berskala besar. Penyelidikan lepas biasanya percaya bahawa ketidakpastian yang tinggi dalam ramalan model bermakna potensi pulangan yang tinggi, jadi kebanyakan literatur penyelidikan tertumpu pada anggaran ketidakpastian. Untuk sistem pengesyoran dalam talian yang menggunakan latihan penstriman, strategi penerokaan akan memberi impak yang lebih besar pada pengumpulan sampel latihan, yang seterusnya memberi kesan kepada pembelajaran selanjutnya model. Walau bagaimanapun, kebanyakan strategi penerokaan semasa tidak dapat memodelkan cara sampel yang diterokai mempengaruhi pembelajaran model seterusnya. Oleh itu, kami mereka bentuk modul penerokaan pseudo (Penerokaan Pseudo) untuk mensimulasikan kesan ke atas pembelajaran model pengesyoran seterusnya selepas sampel berjaya diterokai dan dipaparkan.
Proses kuasi-penerokaan direalisasikan dengan menambahkan gangguan pertentangan pada input model Kami juga menyediakan analisis teori yang sepadan dan bukti proses ini. Berdasarkan ini, kami menamakan kaedah ini sebagai strategi penerokaan berdasarkan kecerunan adversarial (Penerokaan yang didorong oleh Gradient Adversarial, selepas ini dirujuk sebagai AGE). Untuk meningkatkan kecekapan penerokaan, kami juga mencadangkan unit gating dinamik untuk menapis sampel bernilai rendah untuk mengelakkan pembaziran sumber pada penerokaan bernilai rendah. Untuk mengesahkan keberkesanan algoritma AGE, kami bukan sahaja menjalankan sejumlah besar percubaan pada set data akademik awam, tetapi juga menggunakan model AGE ke platform pengiklanan paparan Alimama dan mencapai pulangan dalam talian yang baik. Kerja ini telah disertakan sebagai Kertas Penuh dalam Trek Penyelidikan KDD 2022 Anda dialu-alukan untuk membaca dan berkomunikasi.
Kertas: Penerokaan Didorong Kecerunan Bermusuhan untuk Ramalan Kadar Klik Lalu Dalam
Muat turun: https://arxiv.org/abs/2112.11136
Latar Belakang
Dalam sistem pengiklanan, model ramalan kadar klikan (CTR) biasanya dilatih menggunakan kaedah penstriman, dan sumber data penstriman dihasilkan oleh model CTR yang digunakan dalam talian, yang mencipta soalan kitaran data yang dipanggil. Memandangkan iklan permulaan sejuk dan iklan long-tail tidak dipaparkan sepenuhnya, model CTR kekurangan data latihan untuk iklan ini. Ini juga membawa kepada anggaran model iklan ini mungkin mempunyai ralat yang besar, yang akan menyukarkan untuk memaparkan iklan ini. sukar untuk menyelesaikan permulaan sejuk. Secara khususnya, Rajah 1 menunjukkan hubungan antara kadar klikan sebenar iklan dan bilangan tera: Dalam sistem kami, iklan baharu perlu dipaparkan secara purata kira-kira 10,000 kali sebelum kadar klikan boleh mencapai penumpuan negeri. Ini membawa masalah biasa kepada banyak sistem dalam talian, iaitu, cara memulakan iklan ini secara sejuk sambil memastikan pengalaman pengguna.
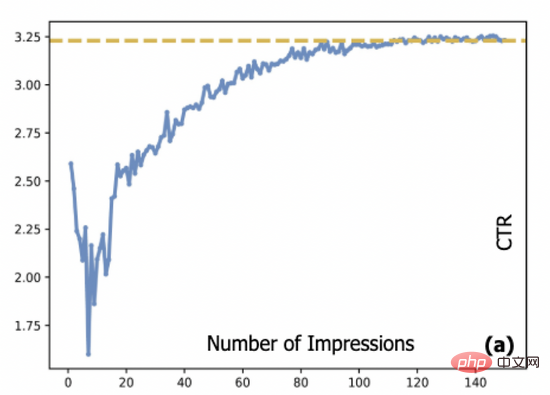
Rajah 1: Hubungan antara CTR pengiklanan dan bilangan tera
Algoritma Penerokaan dan Eksploitasi (E&E) biasanya digunakan untuk menyelesaikan masalah di atas. Dalam sistem pengesyoran atau pengiklanan, kaedah biasa (seperti Penyamun Pelbagai Bersenjata Kontekstual, penyamun berbilang bersenjata kontekstual) secara amnya memodelkan masalah ini seperti berikut. Pada setiap langkah, sistem memilih tindakan berdasarkan dasar P (iaitu, mengesyorkan item _ _ kepada pengguna). Untuk memaksimumkan ganjaran terkumpul (biasanya diukur sebagai jumlah klik), sistem perlu menimbang sama ada penekanan semasa adalah pada penerokaan atau eksploitasi. Penyelidikan terdahulu secara amnya menganggap ketidakpastian yang tinggi sebagai ukuran potensi pulangan. Di satu pihak, strategi P perlu memberi keutamaan kepada projek dengan utiliti semasa yang lebih besar untuk memaksimumkan pusingan manfaat semasa sebaliknya, algoritma juga perlu memilih operasi dengan ketidakpastian yang lebih besar untuk mencapai penerokaan. Jika digunakan untuk mewakili strategi menimbang penerokaan dan eksploitasi, skor akhir projek oleh sistem boleh dinyatakan dengan formula berikut:
Anggaran ketidakpastian telah menjadi modul teras banyak algoritma E&E. Ketidakpastian mungkin berpunca daripada kebolehubahan data, hingar pengukuran, dan ketidakstabilan model (cth., kaedah penganggaran biasa termasuk Monte Carlo MC-Dropout, rangkaian saraf Bayesian, dan ketidakpastian ramalan, dan pemodelan ketidakpastian berdasarkan norma kecerunan (). berat model), dsb. Atas dasar ini, terdapat dua strategi penerokaan biasa: Kaedah berasaskan UCB biasanya menggunakan had atas potensi pulangan sebagai skor akhir [1,2], manakala kaedah berasaskan persampelan Thompson dilakukan dengan pensampelan daripada pengagihan kebarangkalian anggaran [3]. ].
3. Pengenalan kaedah
Kami percaya bahawa kaedah di atas tidak menganggap penerokaan lengkap gelung tertutup. Untuk sistem dalam talian dipacu data, faedah utama penerokaan datang daripada data maklum balas yang diperoleh daripada proses penerokaan, dan data maklum balas untuk latihan dan pengemaskinian model. Ketidakpastian anggaran model itu sendiri tidak mencerminkan sepenuhnya keseluruhan gelung maklum balas. Untuk tujuan ini, kami memperkenalkan modul kuasi-penerokaan untuk mensimulasikan kesan data maklum balas pada model selepas melengkapkan tindakan penerokaan, dan menggunakan ini untuk mengukur keberkesanan penerokaan. Analisis mendapati bahawa keberkesanan penerokaan bergantung bukan sahaja pada anggaran ketidakpastian model, tetapi juga pada saiz "gangguan balas". Apa yang dipanggil gangguan adversarial merujuk kepada vektor gangguan dengan panjang modul tetap ditambah pada input model yang menyebabkan perubahan terbesar dalam output model. Dalam kertas itu, kami juga membuktikan bahawa selepas model dilatih sekali menggunakan data yang diterokai, jangkaan perubahan dalam output model adalah bersamaan dengan menambah vektor tambahan yang modulusnya tidak menentu dan vektor gangguan ialah kecerunan lawan kepada vektor input . Kami mengesahkan bahawa pemodelan dengan cara ini boleh menganggarkan kesan seterusnya sampel yang diterokai pada model secara gelung tertutup, dengan itu menganggarkan nilai sebenar sampel yang diterokai.
Kami memanggil kaedah ini Adversarial Gradient driven Exploration, atau singkatannya AGE. Model AGE terdiri daripada dua bahagian: Modul Pseudo-Exploration dan Unit Gating Dinamik Struktur keseluruhannya ditunjukkan dalam Rajah 2.
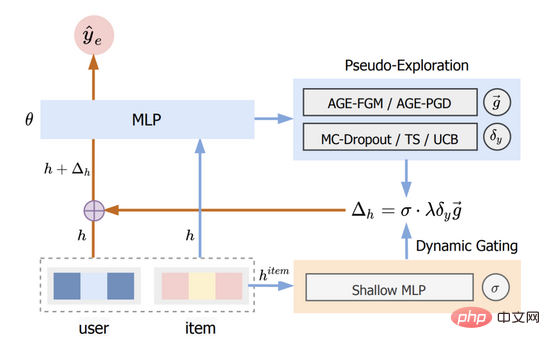
Rajah 2: Gambar rajah struktur AGE
Lihat bahagian 3.1 untuk butiran, dan bahagian 3.3 untuk butiran.
3.1 Modul Pseudo-Exploration
3.1.1 Pengenalan Modul
Tujuan utama Modul Pseudo-Exploration adalah untuk mensimulasikan secara kuantitatif penggunaan model Selepas sampel penerokaan dilatih, perubahan dalam skor sampel dianggarkan untuk menganggarkan kesan gelung tertutup penerokaan ke atas model. Selepas derivasi, kami mendapati bahawa proses di atas boleh diselesaikan melalui formula (2), yang mewakili skor sampel selepas penerokaan oleh model, yang kami gunakan untuk pemeringkatan akhir.
Formula di atas bermakna kita tidak perlu melakukan sebarang operasi pada parameter model asal Kita hanya perlu menambah hasil kecerunan lawan, anggaran ketidakpastian dan menetapkan hiperparameter secara manual kepada perwakilan input daripada anggaran skor model selepas penerokaan. Antaranya, kaedah pengiraan parameter dan akan diperkenalkan pada bahagian seterusnya. Kemudian dalam bahagian ini, kami akan memperkenalkan proses terbitan terperinci formula (2) dalam modul penerokaan yang dicadangkan.
3.1.2 Derivasi terperinci
Bagi setiap sampel data, latihan model akan mempengaruhi dua bahagian parameter: perwakilan yang sepadan dengan sampel (termasuk produk, Pembenaman pengguna, dsb.) dan parameter model. Oleh kerana matlamat parameter model dalam latihan adalah untuk menyesuaikan diri dengan semua sampel dan bukannya sampel tunggal, kita boleh berfikir bahawa latihan sampel tunggal akan mempengaruhi perwakilan sampel, manakala parameter model itu sendiri hanya memerlukan pelarasan kecil. Oleh itu, dalam kajian seterusnya, kami akan mengabaikan pelarasan dan hanya memberi tumpuan kepada perubahan dalam perwakilan yang sepadan dengan sampel. Dengan mengandaikan bahawa label sebenar sampel yang mengandungi perwakilan adalah, semasa latihan, kita perlu mencari jumlah kemas kini untuk meminimumkan fungsi kehilangan. Berdasarkan ini, kami mentakrifkan:
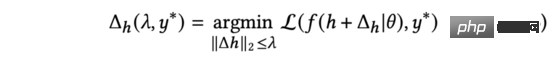
yang mewakili fungsi kehilangan yang digunakan dalam latihan, dan fungsi kehilangan entropi silang biasanya digunakan dalam tugas anggaran CTR. Pada masa yang sama, kami gunakan untuk mengekang perubahan maksimum dalam perwakilan. Untuk memudahkan penulisan, kami akan menulis sebelah kanan formula di atas sebagai.
Menurut teorem nilai min Lagrange, apabila norma kedua bagi menghampiri 0, kita boleh memperoleh formula fungsi kehilangan (3) di atas sebagai:
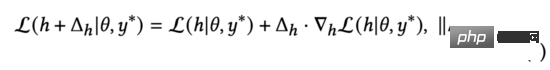
Kami memerhati formula (4) dan dengan mudah mendapati bahawa fungsi kehilangan memperoleh nilai minimum apabila ia mempunyai arah yang bertentangan dengan dua vektor. Dalam persamaan (3), kami mengekang gangguan. Oleh itu, dengan menyelesaikan persamaan (3), kita mendapat:
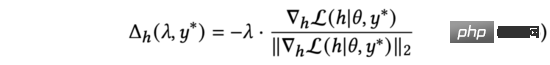
Dalam amalan, kita gunakan untuk menggantikan kecerunan ternormal dalam persamaan (5). Dengan memperoleh peraturan rantaian, ia boleh dikembangkan kepada dua bahagian: dan . Pengiraan selanjutnya menghasilkan:
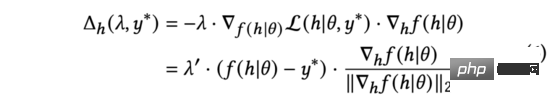
Dalam persamaan di atas, kita akan skala semula untuk memastikan persamaan itu benar. Walaupun maknanya berbeza, semuanya adalah hiperparameter yang dilaraskan secara manual, jadi kami boleh melengkapkan penggantian secara langsung. Kami memudahkan lagi formula (6) sebagai:
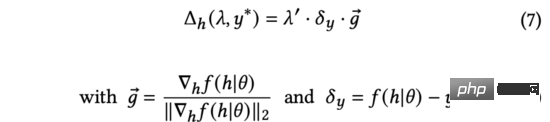
Dalam formula di atas, kecerunan ternormal mewakili arah terbitan keluaran model berbanding perwakilan input. Memandangkan maklum balas pengguna sebenar tidak tersedia pada masa penerokaan, kami akan menggunakan anggaran ketidakpastian untuk mengukur perbezaan antara skor ramalan dan maklum balas pengguna sebenar.
Dalam formula (7), kita dapati penyelesaian analitikal yang boleh memaksimumkan perubahan dalam output ramalan model di bawah kekangan (terbitan adalah sama dengan formula (3) kepada formula (5)). Tambahan pula, kami juga mendapati bahawa proses menambah perwakilan input di atas adalah dalam bentuk yang sama seperti gangguan lawan (lihat persamaan (9)).
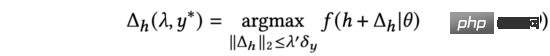
Oleh itu, kami menggunakan kecerunan adversarial untuk menggantikan dalam formula (7) dan menamakan kaedah kami sebagai algoritma penerokaan berasaskan kecerunan adversarial.
Formula (9) menunjukkan bahawa cara yang paling berkesan untuk meneroka AGE ialah menambahkan gangguan musuh pada input perwakilan, dan menggunakan output model terganggu sebagai faktor pengisihan: arah vektor gangguan yang diwakili oleh lawan. kecerunan sebagai input, dan Tahap gangguan dalam ketidakpastian ramalan. Oleh itu, selepas mendapat jumlah, kita boleh menggunakan formula berikut untuk mengira skor ramalan model selepas penerokaan, iaitu formula yang disebutkan di atas (2).
3.2 Butiran pelaksanaan
Dalam AGE, kami menggunakan kaedah MC-Dropout untuk menganggarkan ketidakpastian. Khususnya, MC-Dropout memberikan berat Mask rawak kepada setiap neuron dalam model dalam Kaedah khusus ditunjukkan dalam formula berikut (11). Satu faedah kaedah ini ialah kita boleh mendapatkan ketidakpastian secara langsung tanpa mengubah struktur asal model. Dalam operasi sebenar, ketidakpastian boleh dinyatakan dengan mengira varians keciciran melalui idea UCB, atau dengan merujuk kepada kaedah persampelan rawak Thompson dengan mengira perbezaan antara persampelan dan min, iaitu formula ( 12) dan formula (13) ).
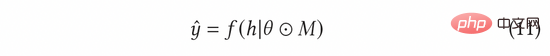
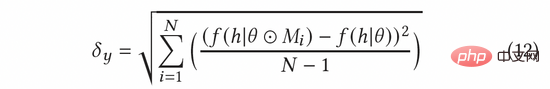
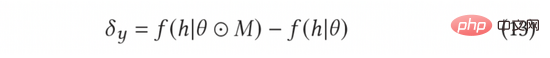
Kecerunan lawan ternormal boleh dikira mengikut kaedah kecerunan pantas (FGM) dalam formula (8). Untuk mengira kecerunan lawan dengan lebih tepat, kita boleh menggunakan kaedah keturunan kecerunan proksimal (PGD) untuk mengemas kini kecerunan secara berulang dalam berbilang langkah, seperti yang ditunjukkan dalam Persamaan (14).
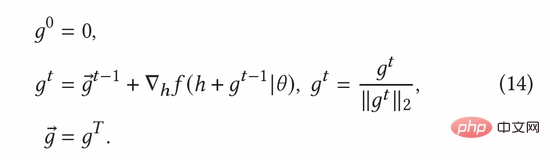
3.3 Unit Gating Dinamik
Dalam amalan, kami mendapati bahawa tidak semua iklan patut diterokai. Dalam sistem pengiklanan Top-K umum, bilangan iklan yang boleh dipaparkan kepada pengguna akhir adalah agak kecil. Oleh itu, untuk iklan dengan kadar klikan yang rendah (contohnya, iklan berkualiti rendah itu sendiri), walaupun model tersebut mempunyai ketidakpastian yang tinggi dalam ramalan iklan ini, nilai penerokaan masih sangat rendah memandangkan sifat perniagaan sistem pengiklanan. . Walaupun kami boleh mendapatkan sejumlah besar data mengenai iklan ini melalui penerokaan, supaya iklan ini dapat dilatih sepenuhnya oleh model dan menganggarkan dengan lebih tepat namun, kadar klik lalu yang rendah bagi iklan ini akan menjadikannya mustahil untuk mendapatkan iklan ini dengan sendirinya walaupun selepas penerokaan penuh Trafik, penerokaan sedemikian sudah pasti tidak cekap. Dalam kertas kerja ini, kami mencuba heuristik mudah untuk menjadikan penerokaan lebih cekap - jika anggaran skor model untuk iklan adalah lebih tinggi daripada purata kadar klikan untuk iklan merentas semua kumpulan, kami akan meneroka jika tidak, Penerokaan tidak akan berlaku.
Untuk mengira purata kadar klik lalu iklan, kami memperkenalkan modul Dynamic Gating Threshold Unit (DGU). DGU hanya menggunakan ciri sisi iklan sebagai input untuk menganggarkan purata kadar klik lalu iklan. Apabila anggaran kadar klik lalu model adalah lebih rendah daripada purata kadar klik lalu pengiklanan yang dianggarkan oleh modul DGU, penerokaan tidak akan dilakukan, jika tidak, penerokaan biasa akan dilakukan. Proses tersebut ditunjukkan dalam formula berikut:
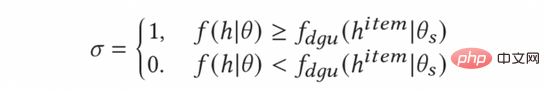
Akhir sekali, kami akan menggantikannya ke dalam formula (10) untuk mendapatkan kaedah pengiraan akhir dan lengkap model penerokaan AGE seperti berikut .
4. Penilaian Eksperimen
4.1 Eksperimen Luar Talian
Kami membandingkan tiga kategori utama kaedah asas, termasuk kaedah penerokaan berasaskan pensampelan rawak, kaedah penerokaan berasaskan model mendalam dan berasaskan kecerunan Kaedah penerokaan, keputusan ditunjukkan dalam Jadual 1. Dapat diperhatikan bahawa model garis dasar yang dibina berdasarkan kaedah Persampelan Thompson (TS) adalah lebih baik daripada model berdasarkan UCB, membuktikan TS adalah algoritma yang lebih baik untuk mengukur ketidakpastian model. Tambahan pula, kita boleh melihat bahawa algoritma AGE mengatasi semua kaedah asas, yang juga membuktikan keberkesanan kaedah AGE. Secara khusus, kedua-dua AGE-TS dan AGE-UCB mengatasi garis dasar terbaik UR-gradient-TS dan UR-gradient-UCB [4], dengan nilai peningkatan masing-masing 5.41% dan 15.3%. Kaedah AGE-TS meningkatkan klik sebanyak 28.0% penuh berbanding kaedah garis dasar tanpa penerokaan. Perlu diingat bahawa algoritma UCB dan TS berasaskan AGE AGE-UCB dan AGE-TS mencapai hasil yang sama, yang tidak berlaku untuk algoritma UCB dan TS berasaskan kecerunan, yang juga membuktikan bahawa AGE boleh mengimbangi ketidakstabilan kaedah UCB.
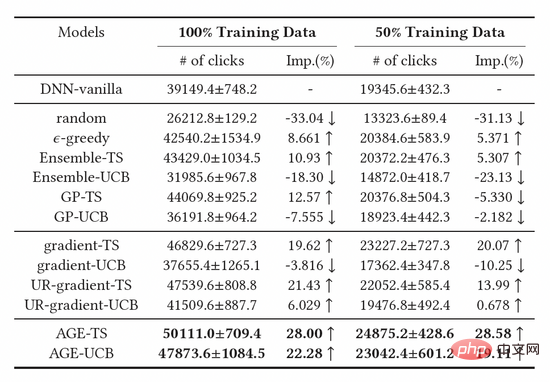
Jadual 1: Keputusan percubaan luar talian
Kami juga menjalankan sejumlah besar eksperimen ablasi untuk membuktikan keberkesanan setiap modul. Seperti yang ditunjukkan dalam Jadual 2, unit ambang, kecerunan lawan dan unit ketidakpastian semuanya amat diperlukan. Untuk menentukan lagi kesan DGU, kami mencuba parameter ambang tetap yang berbeza, dan akhirnya mendapati bahawa kesannya tidak sebaik ambang dinamik DGU.
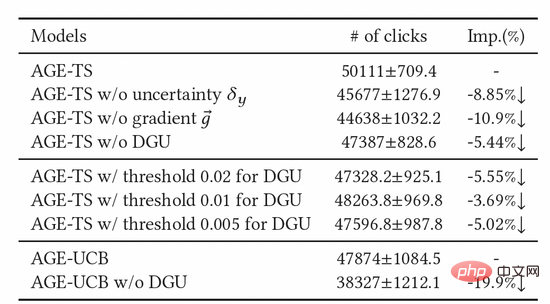
Jadual 2: Keputusan percubaan Ablasi
4.2 Percubaan dalam talian
Kami turut menggunakan model AGE ke dalam sistem pengiklanan paparan Alimama Untuk menilai dengan tepat nilai penerokaan model, kami mereka bentuk kaedah penilaian berdasarkan baldi adil. Seperti yang ditunjukkan dalam Rajah 3, kami mula-mula menyediakan baldi C dan baldi D untuk pengumpulan data. Dalam baldi D, kami menggunakan algoritma penerokaan seperti AGE, manakala dalam baldi C, kami menggunakan model CTR konvensional tanpa penerokaan. Selepas satu tempoh masa, kami menggunakan data maklum balas yang diperoleh daripada baldi C dan baldi D kepada latihan model yang digunakan pada baldi adil A dan B masing-masing. Akhir sekali, kami akan membandingkan prestasi model pada baldi adil A dan B. Dalam percubaan dalam talian, kami menggunakan beberapa penunjuk standard untuk penilaian, termasuk kadar klikan (CTR), bilangan PV iklan yang dipaparkan dan PCOC, nisbah CTR ramalan kepada CTR sebenar. Selain itu, kami memperkenalkan metrik operasi (AFR) untuk mengukur kepuasan pengiklan.
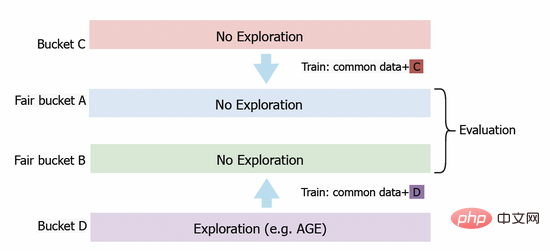
Rajah 3: Pelan Eksperimen Baldi Adil
Seperti yang ditunjukkan dalam Jadual 3, penunjuk di atas telah dipertingkatkan dengan berkesan. Antaranya, AGE dengan ketara mengatasi semua kaedah lain: CTR dan PV masing-masing adalah 6.4% dan 3.0% lebih tinggi daripada model garis dasar. Pada masa yang sama, penggunaan model AGE juga meningkatkan ketepatan ramalan model, iaitu ketepatan ramalan PCOC lebih hampir kepada 1. Lebih penting lagi, penunjuk AFR juga meningkat sebanyak 5.5%, yang menunjukkan bahawa kaedah penerokaan kami boleh meningkatkan pengalaman pengiklan dengan berkesan.
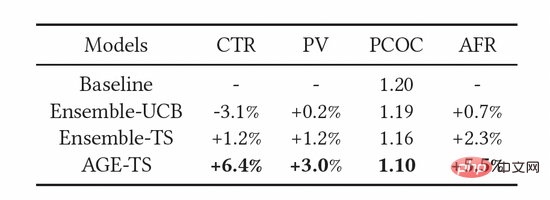
Jadual 3: Keputusan Eksperimen Dalam Talian
5 Ringkasan
Berbeza daripada kebanyakan kaedah penerokaan & eksploitasi yang menumpukan pada menganggar potensi pulangan , pendekatan kami AGE merangka semula masalah ini daripada perspektif pembelajaran dalam talian yang dipacu data. Di samping menganggarkan ketidakpastian ramalan model semasa, algoritma AGE menggunakan modul kuasi-penerokaan untuk mempertimbangkan selanjutnya kesan sampel penerokaan pada latihan model. Kami menjalankan eksperimen ujian A/B pada kedua-dua set data penyelidikan akademik dan pautan pengeluaran, dan keputusan yang berkaitan mengesahkan keberkesanan kaedah AGE. Pada masa hadapan, kami akan menggunakan AGE dalam lebih banyak senario aplikasi.
Atas ialah kandungan terperinci Model penerokaan berdasarkan kecerunan lawan dan penggunaannya dalam ramalan klik. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI