
Rumah >masalah biasa >Pengenalan kepada OpenAI dan Microsoft Sentinel
Pengenalan kepada OpenAI dan Microsoft Sentinel

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-13 12:07:111934semak imbas
Selamat datang ke siri kami tentang OpenAI dan Microsoft Sentinel! Model bahasa yang besar, atau LLM, seperti keluarga GPT3 OpenAI, mengambil alih imaginasi awam dengan kes penggunaan yang inovatif seperti ringkasan teks, perbualan seperti manusia, penghuraian kod dan nyahpepijat, dan banyak contoh lain. Kami telah melihat ChatGPT menulis skrip dan puisi, mengarang muzik, menulis esei, dan juga menterjemah kod komputer daripada satu bahasa ke bahasa lain.
Bagaimana jika kita boleh memanfaatkan potensi luar biasa ini untuk membantu pihak yang bertindak balas insiden di pusat operasi keselamatan? Sudah tentu kita boleh - dan ia mudah! Microsoft Sentinel sudah pun menyertakan penyambung terbina dalam untuk model OpenAI GPT3 yang boleh kami laksanakan dalam buku permainan automasi kami yang dikuasakan oleh Azure Logic Apps. Aliran kerja berkuasa ini mudah untuk ditulis dan disepadukan ke dalam operasi SOC. Hari ini kita akan melihat pada penyambung OpenAI dan meneroka beberapa parameter boleh dikonfigurasikan menggunakan kes penggunaan mudah: menerangkan dasar MITRE ATT&CK yang berkaitan dengan acara Sentinel.
Sebelum kita bermula, mari kita semak beberapa prasyarat:
- Jika anda belum mempunyai contoh Microsoft Sentinel, anda boleh menciptanya menggunakan akaun Azure percuma anda dan ikuti Dapatkan bermula dengan Sentinel Bermula dengan pantas.
- Kami akan menggunakan data prarakam daripada Makmal Latihan Microsoft Sentinel untuk menguji buku main kami.
- Anda juga memerlukan akaun OpenAI peribadi dengan kunci API untuk sambungan GPT3.
- Saya juga sangat mengesyorkan menyemak blog Antonio Formato yang sangat baik tentang pengendalian acara dengan ChatGPT dan Sentinel, di mana Antonio memperkenalkan manual serba guna yang sangat berguna yang telah dilaksanakan dalam hampir semua model OpenAI di Sentinel sehingga kini merujuk kepada.
Kami akan bermula dengan buku main pencetus insiden asas (Sentinel > Automation > Create > Playbook dengan pencetus insiden).
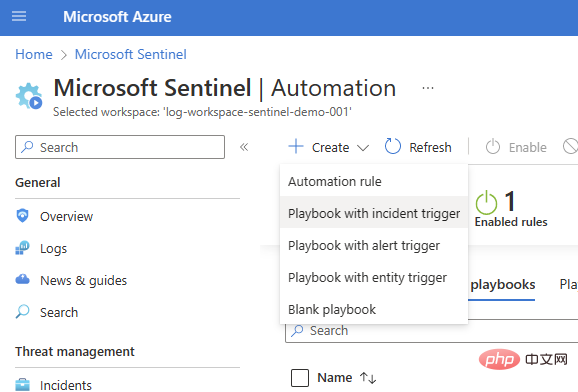
Pilih langganan dan kumpulan sumber anda, tambahkan nama skrip dan pindah ke tab Sambungan. Anda sepatutnya melihat Microsoft Sentinel dengan satu atau dua pilihan pengesahan - Saya menggunakan Identiti Terurus dalam contoh ini - tetapi jika anda belum mempunyai sebarang sambungan, anda juga boleh menambah sambungan Sentinel dalam Logic Apps Designer .
Lihat dan cipta buku main, selepas beberapa saat sumber akan digunakan dengan jayanya dan membawa kami ke kanvas Pereka Aplikasi Logik:
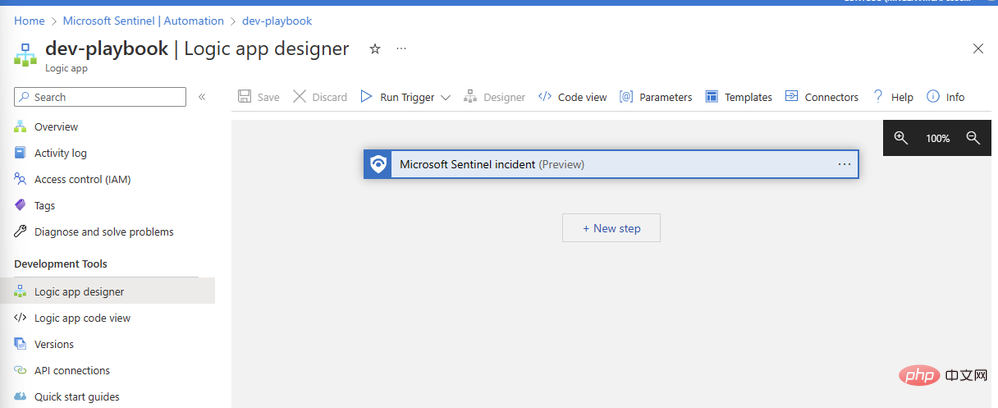
Jom tambah penyambung OpenAI kami. Klik Langkah Baharu dan taip "OpenAI" dalam kotak carian. Anda akan melihat penyambung dalam anak tetingkap atas dan dua tindakan di bawahnya: "Buat Imej" dan "GPT3 Lengkapkan Petua Anda":
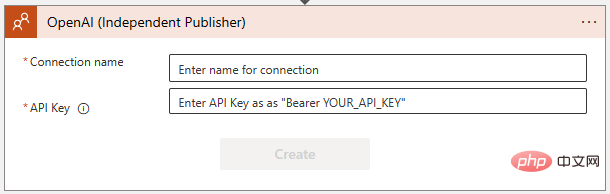
Pilih "GPT3 Lengkapkan gesaan anda" . Anda kemudiannya akan diminta untuk membuat sambungan ke OpenAI API dalam kotak dialog berikut. Jika anda belum berbuat demikian, buat kunci di https://platform.openai.com/account/api-keys dan pastikan anda menyimpannya di lokasi yang selamat!
Pastikan anda mengikut arahan dengan tepat semasa menambah kunci OpenAI API - ia memerlukan perkataan "Pembawa", diikuti dengan ruang, dan kemudian kekunci itu sendiri:
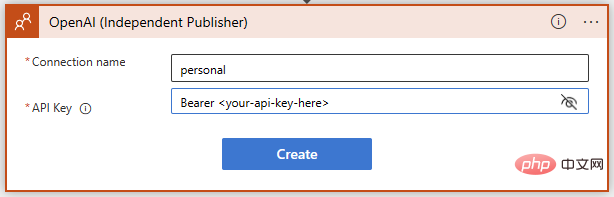
Berjaya! Kami kini mempunyai pelengkapan teks GPT3 sedia untuk gesaan kami. Kami mahu model AI mentafsir strategi dan teknik MITRE ATT&CK yang berkaitan dengan acara Sentinel, jadi mari tulis gesaan ringkas menggunakan kandungan dinamik untuk memasukkan strategi acara daripada Sentinel.
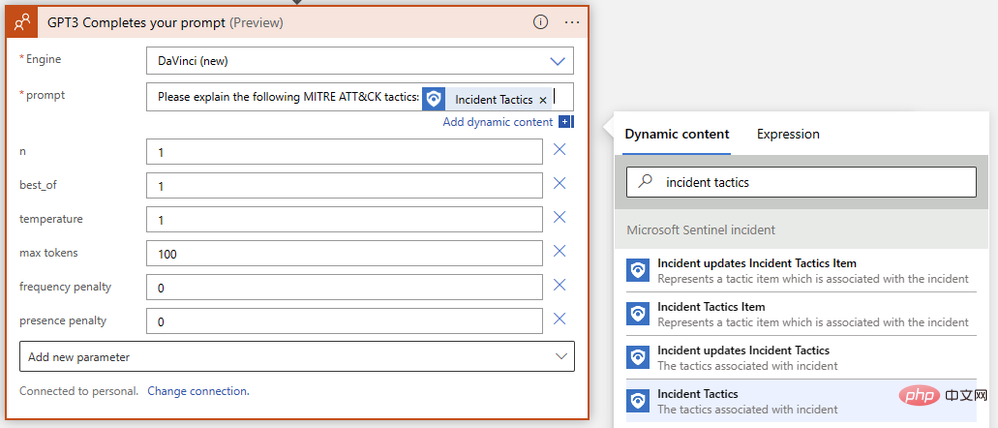
Kita hampir selesai! Simpan apl logik anda dan pergi ke Microsoft Sentinel Events untuk menguji jalankannya. Saya mempunyai data ujian daripada Microsoft Sentinel Training Lab dalam contoh saya, jadi saya akan menjalankan buku main ini terhadap peristiwa yang dicetuskan oleh makluman peraturan peti masuk berniat jahat.
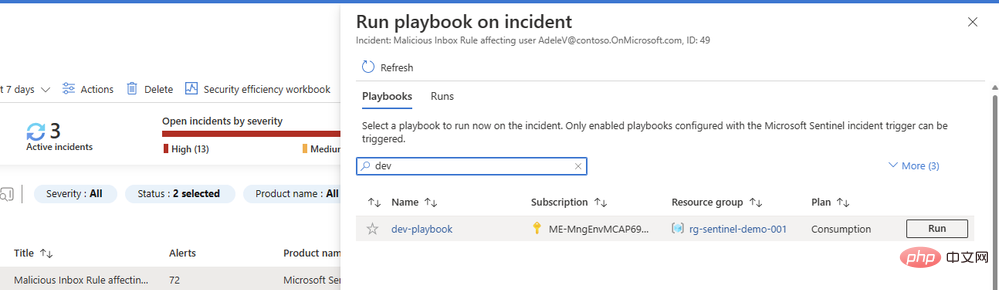
Anda mungkin tertanya-tanya mengapa kami tidak mengkonfigurasi tindakan kedua dalam buku main kami untuk menambah ulasan atau tugasan dengan hasilnya. Kami akan sampai ke sana - tetapi pertama-tama kami ingin memastikan gesaan kami mengembalikan kandungan yang baik daripada model AI. Kembali ke Playbook dan buka Gambaran Keseluruhan dalam tab baharu. Anda sepatutnya melihat item dalam sejarah larian anda, mudah-mudahan dengan tanda semak hijau:
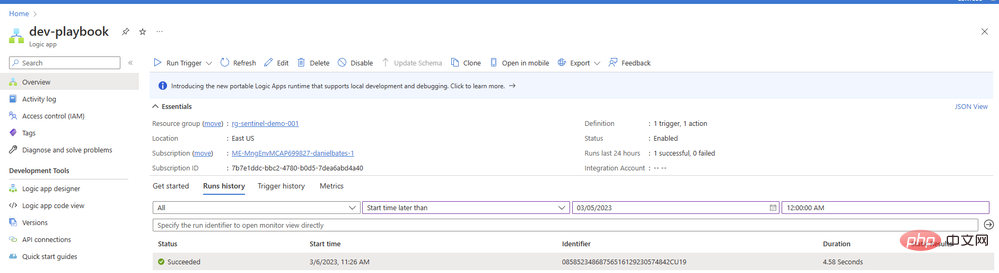
Klik item untuk melihat butiran tentang larian apl logik anda. Kami boleh mengembangkan sebarang blok operasi untuk melihat parameter input dan output terperinci:
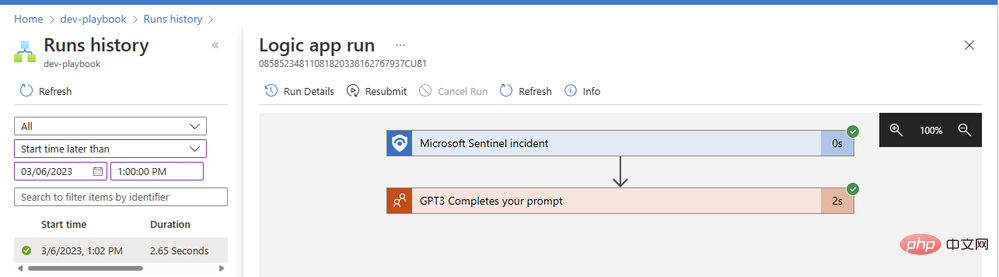
Operasi GPT3 kami berjaya diselesaikan dalam masa dua saat sahaja. Mari klik pada blok tindakan untuk mengembangkannya dan lihat butiran penuh input dan outputnya:
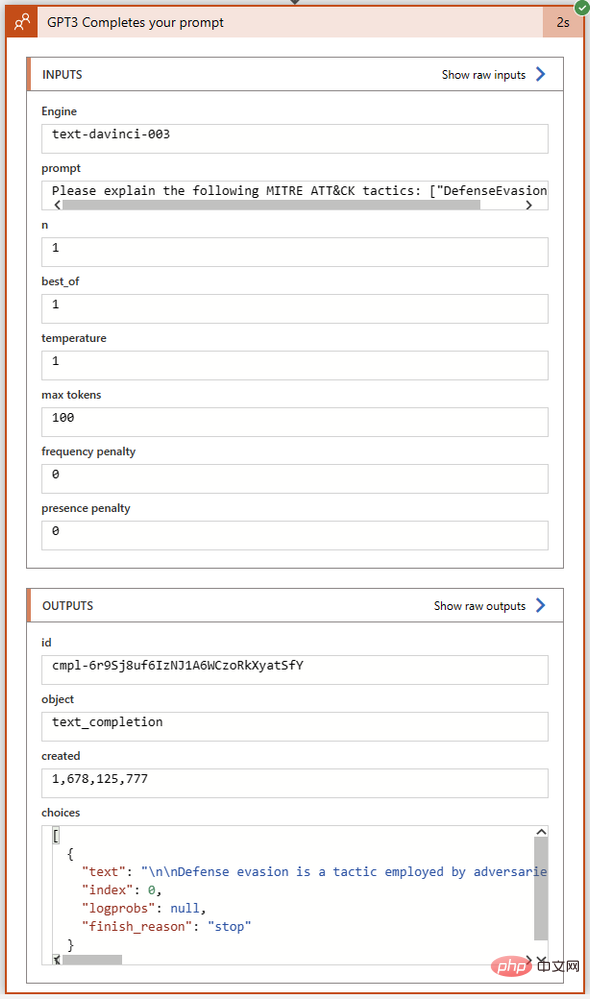
Mari kita lihat dengan lebih dekat medan Pilih dalam bahagian Output . Di sinilah GPT3 mengembalikan teks penyiapannya bersama-sama dengan status penyiapan dan sebarang kod ralat. Saya telah menyalin teks penuh output Pilihan ke dalam Kod Visual Studio:
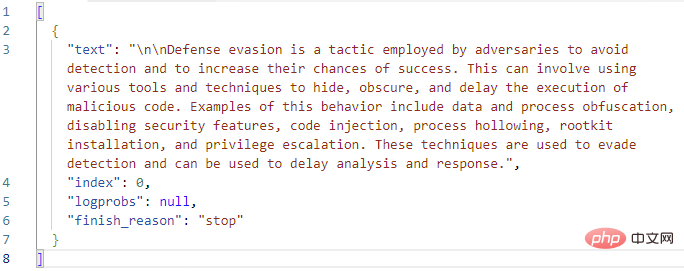
Nampak bagus setakat ini! GPT3 mengembangkan definisi MITRE bagi "pengelak pertahanan" dengan betul. Sebelum kita menambah tindakan logik pada buku main untuk membuat ulasan acara dengan teks jawapan ini, mari kita lihat sekali lagi pada parameter tindakan GPT3 itu sendiri. Terdapat sejumlah sembilan parameter dalam tindakan penyiapan teks OpenAI, tidak mengira pemilihan enjin dan petunjuk:
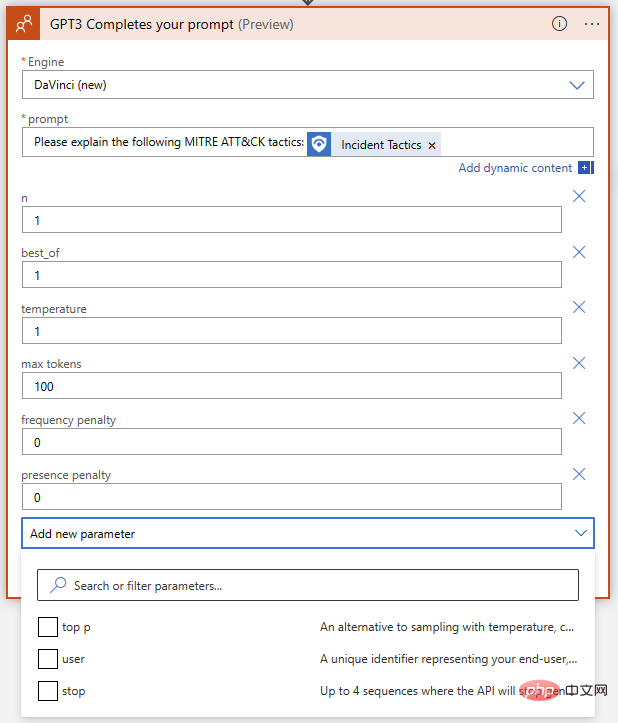
Apakah maksud ini, dan bagaimana kita menalanya untuk mendapatkan hasil terbaik? Untuk membantu kami memahami kesan setiap parameter pada keputusan, mari pergi ke OpenAI API Playground. Kami boleh menampal gesaan tepat dalam medan input tempat apl logik berjalan, tetapi sebelum mengklik Serah kami ingin memastikan parameter sepadan. Berikut ialah jadual pantas membandingkan nama parameter antara penyambung OpenAI Azure Logic App dan Taman Permainan OpenAI:
| Azure 逻辑应用程序连接器 | 开放人工智能游乐场 | 解释 |
| 引擎 | 模型 | 将生成完成的模型。我们可以在OpenAI connector中选择达芬奇(新)、达芬奇(旧)、居里、巴贝奇或阿达,分别对应'text-davinci-003'、'text-davinci-002'、'text-curie-001' 、'text-babbage-001' 和 'text-ada-001' 在 Playground 中。 |
| n | 不适用 | 为每个提示生成多少完成。相当于在Playground中多次重新进入提示。 |
| 最好的 | (相同的) | 生成多个完成并返回最好的一个。谨慎使用——这会消耗大量代币! |
| 温度 | (相同的) | 定义响应的随机性(或创造性)。设置为 0 以获得高度确定性、重复的提示完成,其中模型将始终返回其最有信心的选择。设置为 1 以获得具有更多随机性的最大创意回复,或根据需要介于两者之间。 |
| 最大代币 | 最大长度 | ChatGPT 响应的最大长度,以令牌形式给出。一个令牌大约等于四个字符。ChatGPT 使用以代币计价;在撰写本文时,1000 个代币的价格为 0.002 美元。API 调用的成本将包括提示的令牌长度和回复一起,因此如果您想保持每次响应的最低成本,请从 1000 中减去提示的令牌长度来设置回复的上限。 |
| 频率惩罚 | (相同的) | 范围从 0 到 2 的数字。值越高,模型逐字重复行的可能性就越小(它将尝试查找同义词或重述行)。 |
| 存在惩罚 | (相同的) | 一个介于 0 到 2 之间的数字。值越高,模型重复响应中已经提到的主题的可能性就越小。 |
| 顶部 | (相同的) | 如果您不使用温度,另一种设置响应“创造力”的方法。该参数根据概率限制可能的答案标记;设置为 1 时,将考虑所有标记,但较小的值会减少前 X% 的可能答案集。 |
| 用户 | 不适用 | 唯一标识符。我们不需要设置此参数,因为我们的 API 密钥已经用作我们的标识符字符串。 |
| 停止 | 停止序列 | 最多四个序列将结束模型的响应。 |
Mari gunakan tetapan OpenAI API Playground berikut untuk memadankan tindakan aplikasi logik kami:
- Model: text-davinci-003
- Suhu: 1
- Maksimum panjang: 100
Inilah hasil yang kami dapat dari enjin GPT3.
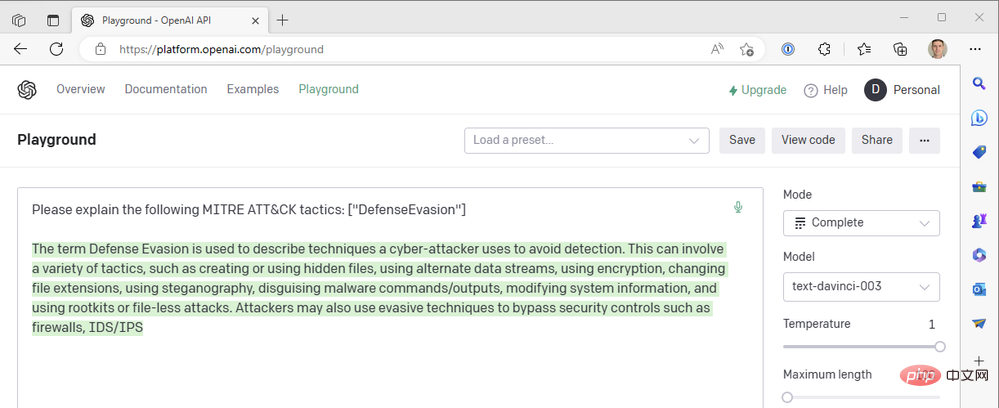
Nampaknya respons telah dipotong di tengah ayat, jadi kita harus meningkatkan parameter panjang maksimum. Jika tidak, respons ini kelihatan agak baik. Kami menggunakan nilai suhu tertinggi yang mungkin - apakah yang berlaku jika kami menurunkan suhu untuk mendapatkan tindak balas yang lebih pasti? Ambil suhu sifar sebagai contoh:
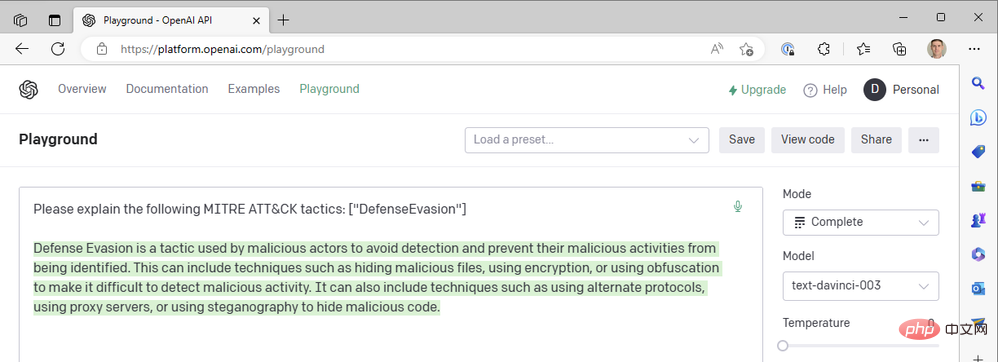
Pada suhu=0, tidak kira berapa kali kita menjana semula gesaan ini, kita mendapat hasil yang hampir sama. Ini berfungsi dengan baik apabila kami meminta GPT3 untuk mentakrifkan istilah teknikal tidak sepatutnya terdapat banyak perbezaan dalam maksud "pengelak pertahanan" sebagai taktik MITRE ATT&CK. Kami boleh meningkatkan kebolehbacaan respons dengan menambahkan penalti kekerapan untuk mengurangkan kecenderungan model untuk menggunakan semula perkataan yang sama ("seperti teknikal"). Mari tingkatkan penalti kekerapan kepada maksimum 2:
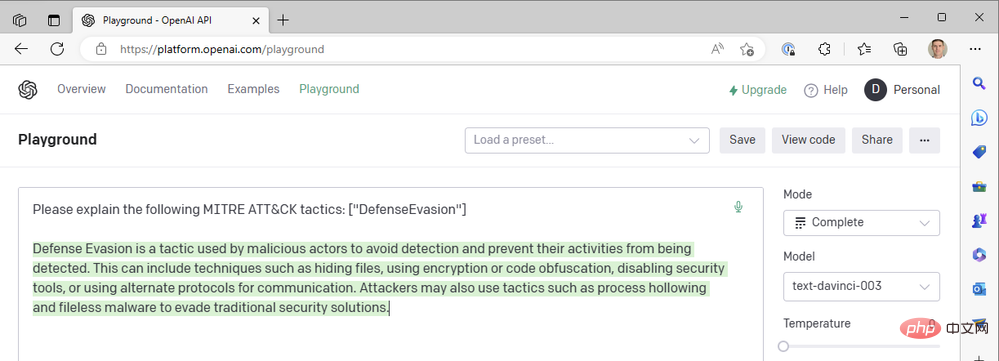
Setakat ini kami hanya menggunakan model da Vinci terkini untuk menyelesaikan sesuatu dengan cepat. Apakah yang berlaku jika kita turun ke salah satu model OpenAI yang lebih pantas dan lebih murah, seperti Curie, Babbage atau Ada? Mari tukar model kepada "text-ada-001" dan bandingkan hasilnya:
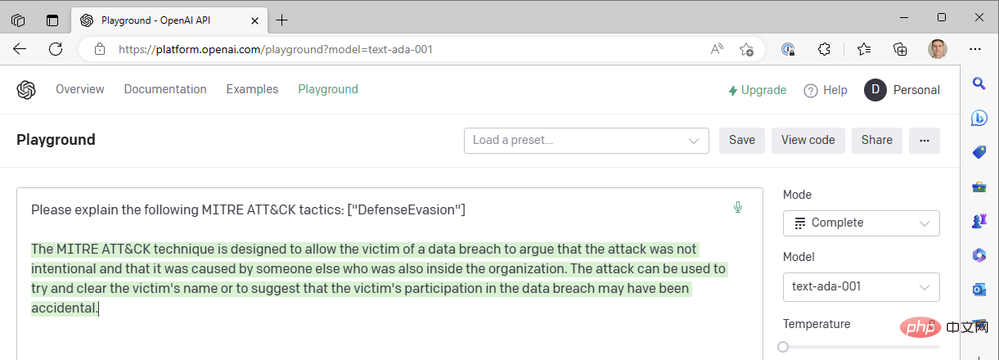
Hmm... tidak cukup. Jom cuba Babbage:
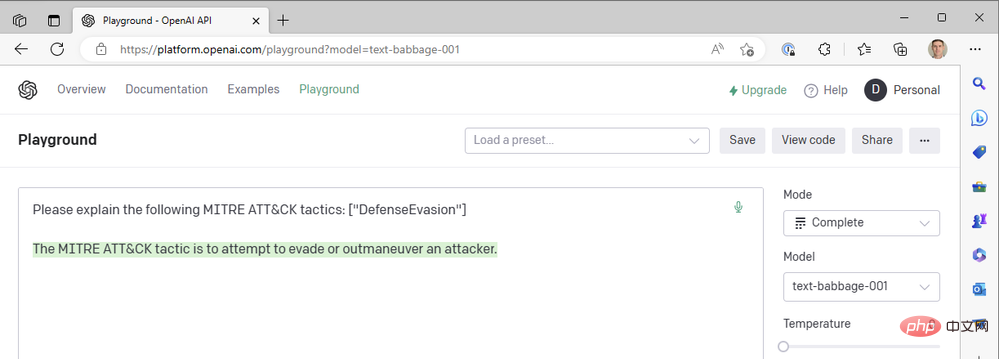
Babbage juga nampaknya tidak mengembalikan hasil yang kita cari. Mungkin Curie akan lebih baik?
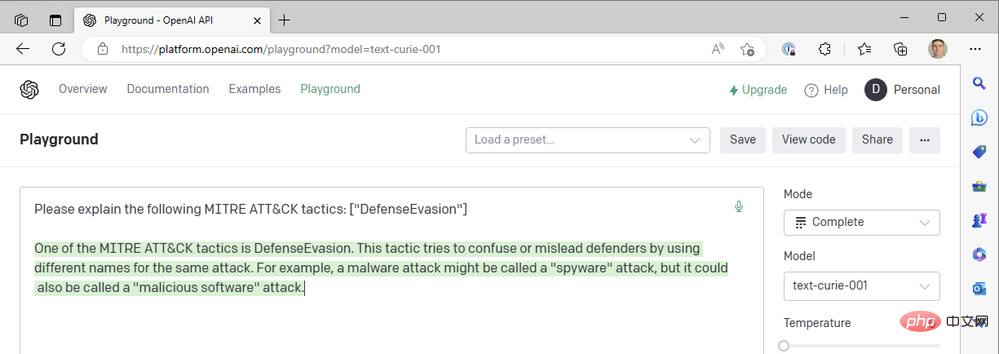
Malangnya, Curie juga tidak memenuhi piawaian yang ditetapkan oleh Leonardo da Vinci. Ia sememangnya pantas, tetapi kes penggunaan kami untuk menambahkan konteks pada acara keselamatan tidak bergantung pada masa tindak balas subsaat - ketepatan ringkasan adalah lebih penting. Kami terus menggunakan gabungan model da Vinci yang berjaya, suhu rendah dan hukuman frekuensi tinggi.
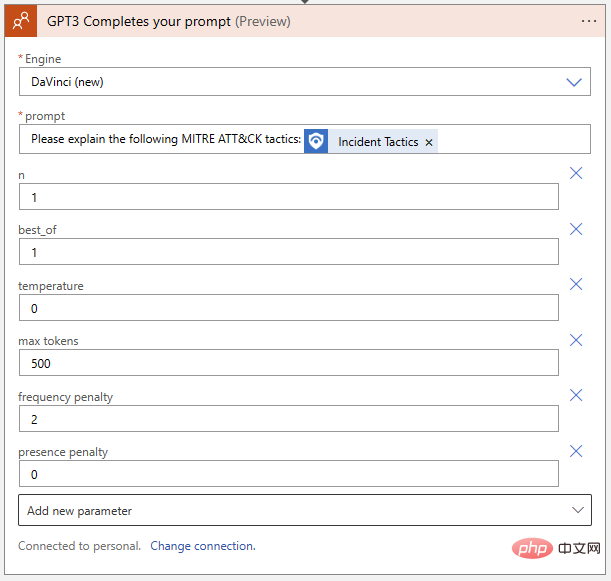
Kembali ke dalam Apl Logik kami, mari pindahkan tetapan yang kami temui dari Taman Permainan ke Blok Tindakan OpenAI:
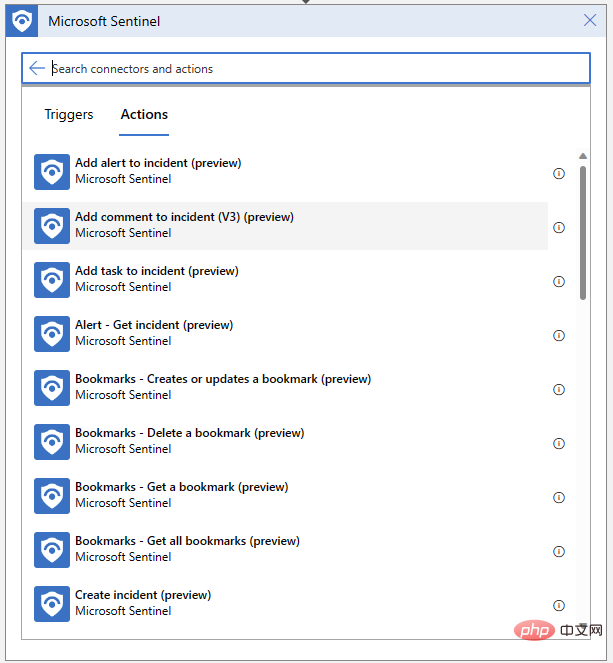
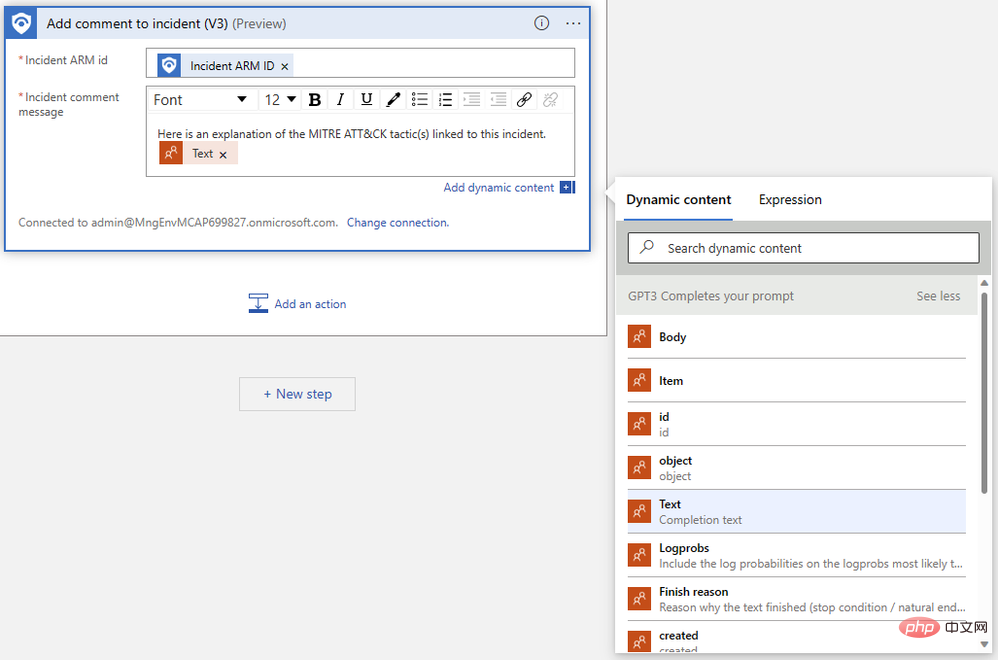
Apl Logik kami juga Perlu boleh untuk menulis ulasan untuk acara kami. Klik "Langkah Baharu" dan pilih "Tambah Komen pada Acara" daripada penyambung Microsoft Sentinel:
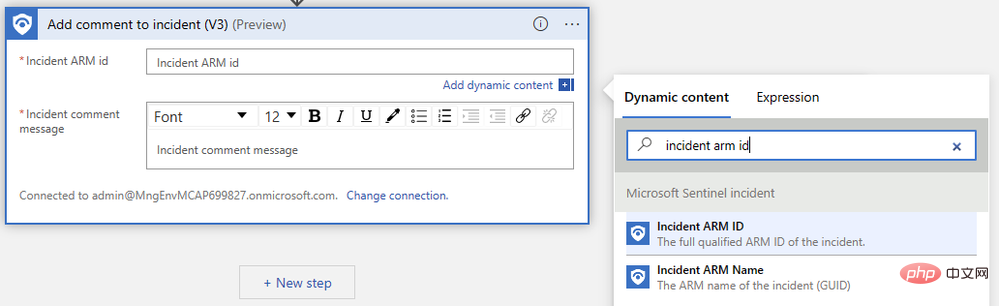
Kami hanya perlu menentukan pengecam ARM acara dan mengarang mesej ulasan kami. Mula-mula, cari "ID ARM Acara" dalam menu pop timbul kandungan dinamik:
Seterusnya, cari "Teks" yang kami keluarkan dalam langkah sebelumnya. Anda mungkin perlu mengklik Lihat Lagi untuk melihat output. Pereka Apl Logik secara automatik membalut tindakan ulasan kami dalam blok logik "Untuk setiap" untuk mengendalikan kes yang berbilang pelengkapan dijana untuk gesaan yang sama.
Apl logik siap kami sepatutnya kelihatan seperti ini:
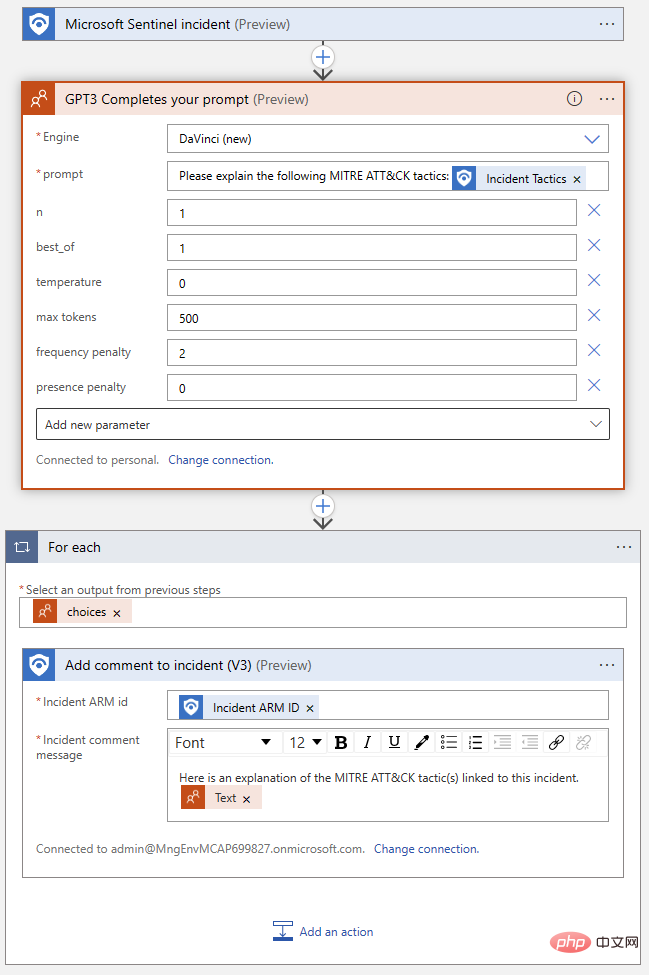
Mari kita uji sekali lagi! Kembali ke acara Microsoft Sentinel itu dan jalankan buku main. Kami sepatutnya mendapat satu lagi penyiapan yang berjaya dalam sejarah larian Apl Logik kami dan ulasan baharu dalam log aktiviti acara kami.
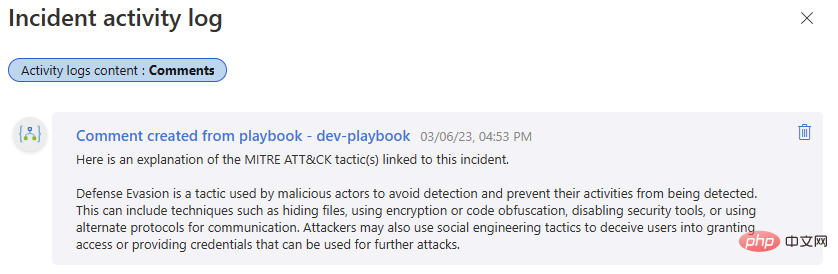
Jika anda sentiasa berhubung dengan kami setakat ini, anda kini boleh menyepadukan OpenAI GPT3 dengan Microsoft Sentinel, yang boleh menambah nilai kepada penyiasatan keselamatan anda. Nantikan ansuran kami yang seterusnya, di mana kami akan membincangkan lebih banyak cara untuk menyepadukan model OpenAI dengan Sentinel, membuka kunci aliran kerja yang boleh membantu anda memanfaatkan sepenuhnya platform keselamatan anda!
Atas ialah kandungan terperinci Pengenalan kepada OpenAI dan Microsoft Sentinel. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!