

 Peranti teknologiAIRangkaian saraf binari pertama BNext dengan ketepatan lebih daripada 80% pada ImageNet keluar, perjalanan lima tahun -1 dan +1
Peranti teknologiAIRangkaian saraf binari pertama BNext dengan ketepatan lebih daripada 80% pada ImageNet keluar, perjalanan lima tahun -1 dan +1Rangkaian saraf binari pertama BNext dengan ketepatan lebih daripada 80% pada ImageNet keluar, perjalanan lima tahun -1 dan +1

Dua tahun lalu, apabila MeliusNet keluar, Machine Heart menerbitkan artikel teknikal "Rangkaian saraf binari mengatasi MobileNet buat kali pertama, - 1 dan + 1 tiga- tahun perjalanan yang sukar ", mengkaji semula sejarah pembangunan BNN. Pada masa itu, XNOR.AI, yang bermula dengan kerja awal BNN XNOR-Net, telah diperoleh oleh Apple Semua orang telah membayangkan sama ada teknologi rangkaian saraf binari berkuasa rendah dan berprestasi tinggi ini tidak lama lagi akan membuka prospek aplikasi yang luas.
Walau bagaimanapun, dalam tempoh dua tahun yang lalu, adalah sukar bagi kami untuk mendapatkan lebih banyak maklumat tentang aplikasi teknologi BNN daripada Apple, yang dengan ketat merahsiakan teknologi, dan tidak ada penampilan dalam akademik atau industri Lain-lain kes aplikasi yang menarik perhatian. Sebaliknya, apabila bilangan peranti terminal meroket, aplikasi dan pasaran AI edge berkembang pesat: dijangkakan 500 hingga 125 bilion peranti edge akan dihasilkan menjelang 2030, dan pasaran pengkomputeran tepi akan melonjak kepada AS$60 bilion. Terdapat beberapa kawasan aplikasi yang popular pada masa ini: AIoT, Metaverse dan peralatan terminal robotik. Industri yang berkaitan sedang mempercepatkan pelaksanaan teknologi Pada masa yang sama, keupayaan AI telah dibenamkan dalam banyak pautan teknikal teras dalam bidang di atas, seperti aplikasi meluas teknologi AI dalam pembinaan semula tiga dimensi, pemampatan video dan masa nyata. persepsi adegan robot. Berdasarkan latar belakang ini, permintaan industri untuk kecekapan tenaga tinggi berasaskan kelebihan, teknologi AI berkuasa rendah, alatan perisian dan pecutan perkakasan telah menjadi semakin mendesak.
Pada masa ini, terdapat dua kesesakan utama yang menyekat penggunaan BNN: pertama, ketidakupayaan untuk mengecilkan jurang ketepatan secara berkesan dengan model pembelajaran mendalam 32-bit tradisional, kedua, kekurangan prestasi pada perkakasan berbeza Pelaksanaan algoritma berprestasi tinggi. Kelajuan dalam kertas pembelajaran mesin selalunya tidak diterjemahkan kepada GPU atau CPU yang anda gunakan. Sebab kedua mungkin timbul daripada sebab pertama BNN tidak dapat mencapai ketepatan yang memuaskan dan oleh itu tidak dapat menarik perhatian meluas daripada pengamal dalam bidang pecutan dan pengoptimuman sistem dan perkakasan. Komuniti algoritma pembelajaran mesin selalunya tidak dapat membangunkan kod perkakasan berprestasi tinggi sendiri. Oleh itu, untuk mencapai ketepatan yang tinggi dan pecutan yang kuat, aplikasi atau pemecut BNN sudah pasti memerlukan kerjasama pembangun dari dua bidang berbeza ini.
Mengapa BNN adalah cekap dari segi pengiraan dan memori
Sebagai contoh, model sistem pengesyoran Meta DLRM menggunakan nombor titik terapung 32-bit untuk menyimpan berat dan parameter pengaktifan, dan model Saiznya lebih kurang 2.2GB. Versi binari model dengan pengurangan kecil dalam ketepatan (
Kelebihan ketara kedua BNN ialah kaedah pengiraan sangat cekap. Ia hanya menggunakan 1 bit, iaitu, dua keadaan, untuk mewakili pembolehubah. Ini bermakna semua operasi boleh diselesaikan hanya dengan operasi bit Dengan bantuan get AND, get XOR dan operasi lain, operasi pendaraban dan penambahan tradisional boleh diganti. Operasi bit adalah unit asas dalam litar Pelajar yang biasa dengan reka bentuk litar harus memahami bahawa mengurangkan luas unit pengiraan pendaraban dan penambahan dan mengurangkan akses memori luar cip adalah cara yang paling berkesan untuk mengurangkan penggunaan kuasa. BNN memfokuskan pada memori dan pengiraan Kesemuanya mempunyai kelebihan unik WRPN [1] menunjukkan bahawa pada FPGA dan ASIC tersuai, BNN boleh mencapai penjimatan kuasa 1000 kali berbanding dengan ketepatan penuh. Kerja yang lebih baru BoolNet [2] menunjukkan reka bentuk struktur BNN yang boleh menggunakan hampir tiada operasi titik terapung dan mengekalkan aliran maklumat binari tulen, yang mencapai penggunaan kuasa yang sangat baik dan pertukaran ketepatan dalam simulasi ASIC.
Apakah rupa BNN pertama dengan ketepatan 80%?
Penyelidik seperti Nianhui Guo dan Haojin Yang dari Institut Kejuruteraan Sistem Komputer Hasso Plattner di Jerman mencadangkan model BNext, menjadi BNN pertama yang mencapai ketepatan klasifikasi top1 melebihi 80% di ImageNet set data. :

Rajah 1 Perbandingan prestasi SOTA BNN berdasarkan ImageNet

Alamat kertas: https://arxiv.org/pdf/2211.12933.pdf
Pengarang Pertama, berdasarkan borang visualisasi Landskap Kehilangan, perbandingan yang mendalam dibuat tentang perbezaan besar dalam keramahan pengoptimuman antara model BNN arus perdana dan model 32-bit (Rajah 2 adalah dicadangkan bahawa Landskap Kehilangan kasar bagi BNN menghalang komuniti penyelidikan semasa menerokai sempadan prestasi BNN. Salah satu sebab utama.
Berdasarkan andaian ini, penulis cuba menggunakan reka bentuk struktur baru untuk meningkatkan keramahan pengoptimuman model BNN, dan membina seni bina rangkaian neural binari dengan Landskap Kerugian yang lebih lancar untuk mengurangkan risiko tinggi Kesukaran mengoptimumkan ketepatan model BNN. Secara khusus, pengarang menekankan bahawa perduaan model sangat mengehadkan corak ciri yang boleh digunakan untuk perambatan ke hadapan, memaksa lilitan binari untuk hanya mengekstrak dan memproses maklumat dalam ruang ciri terhad ini Kesukaran pengoptimuman yang disebabkan olehnya dikurangkan dengan berkesan melalui dua peringkat reka bentuk struktur: (1) membina modul penentukuran ciri lilitan bersebelahan yang fleksibel untuk meningkatkan kebolehsesuaian model kepada perwakilan binari; .

Rajah 2 Perbandingan visualisasi Landskap Kehilangan untuk seni bina BNN popular (perspektif kontur 2D)
Berdasarkan analisis di atas, penulis mencadangkan BNext, seni bina rangkaian neural binari pertama yang mencapai ketepatan > 80% dalam tugas pengelasan imej ImageNe Reka bentuk seni bina rangkaian khusus ditunjukkan dalam Rajah 4 ditunjukkan. Penulis mula-mula mereka bentuk unit pemprosesan binari asas berdasarkan modul Info-Recoupling (Info-RCP). Untuk menangani masalah kesesakan maklumat antara lilitan bersebelahan, reka bentuk penentukuran awal taburan keluaran lilitan binari diselesaikan dengan memperkenalkan lapisan Normalisasi Batch tambahan dan lapisan PReLU. Kemudian penulis membina reka bentuk penentukuran taburan dinamik kuadratik berdasarkan struktur baki songsang dan struktur cawangan Squeeze-And-Expand. Seperti yang ditunjukkan dalam Rajah 3, berbanding dengan struktur penentukuran Real2Binary tradisional, struktur baki songsang tambahan mempertimbangkan sepenuhnya jurang ciri antara input dan output unit binari, mengelakkan penentukuran pengedaran suboptimum berdasarkan sepenuhnya pada maklumat input. Penentukuran pengedaran dinamik dua peringkat ini dengan berkesan boleh mengurangkan kesukaran pengekstrakan ciri dalam lapisan lilitan binari bersebelahan berikutnya.

Rajah 3 Perbandingan reka bentuk modul konvolusi
Kedua, penulis mencadangkan modul Blok Asas binari yang dipertingkatkan digabungkan dengan Perhatian Element-wise (ELM-Attention). Penulis menyelesaikan pembinaan asas Blok Asas dengan menyusun berbilang modul Info-RCP, dan memperkenalkan Penormalan Batch tambahan dan sambungan baki berterusan kepada setiap modul Info-RCP untuk mengurangkan lagi masalah kesesakan maklumat antara modul Info-RCP yang berbeza. Berdasarkan analisis kesan struktur pintasan pada pengoptimuman model binari, penulis mencadangkan untuk menggunakan cawangan pendaraban matriks Element-wise untuk melaksanakan penentukuran pengedaran pada output modul 3x3 Info-RCP pertama setiap Blok Asas . Mekanisme pemberat perhatian ruang udara tambahan boleh membantu Blok Asas melaksanakan gabungan dan pengedaran maklumat ke hadapan dengan mekanisme yang lebih fleksibel, meningkatkan kelancaran Landskap Kehilangan model. Seperti yang ditunjukkan dalam Rajah 2.e dan Rajah 2.f, reka bentuk modul yang dicadangkan boleh meningkatkan kelicinan Landskap Kehilangan model dengan ketara.

Rajah 4 BNreka bentuk seni bina seterusnya. "Pemproses mewakili modul Info-RCP, "BN" mewakili lapisan Normalisasi Kelompok, "C" mewakili lebar asas model, "N" dan "M" mewakili parameter skala kedalaman peringkat berbeza model.

Jadual 1 BNext series “Q” mewakili tetapan lapisan input, SEbranch dan lapisan output. > Pengarang menggabungkan reka bentuk struktur di atas dengan model penanda aras MoboleNetv1 yang popular, dan membina empat siri model BNext kerumitan berbeza (Jadual 1) dengan menukar pekali berkadar kedalaman dan lebar model: BNex-Tiny, BNext - Kecil, BNext-Middle, BNext-Large. Disebabkan Landskap Kerugian yang agak kasar, pengoptimuman model binari semasa secara amnya bergantung pada maklumat penyeliaan yang lebih halus yang disediakan melalui kaedah seperti penyulingan pengetahuan untuk menyingkirkan penumpuan suboptimum yang meluas. Buat pertama kalinya, pengarang BNext mempertimbangkan kemungkinan kesan jurang yang besar dalam taburan ramalan antara model guru dan model pelajar binari semasa proses pengoptimuman, dan menegaskan bahawa pemilihan guru berdasarkan ketepatan model semata-mata akan membawa kepada pembilang. -hasil overfitting pelajar yang intuitif. Untuk menyelesaikan masalah ini, penulis mencadangkan kerumitan pengetahuan (KC) sebagai metrik pemilihan guru baharu, dengan mengambil kira perkaitan antara keberkesanan label lembut keluaran model guru dan kerumitan parameter model guru. Seperti yang ditunjukkan dalam Rajah 5, berdasarkan kerumitan pengetahuan, penulis menjalankan pengukuran kerumitan dan perbandingan siri model ketepatan penuh yang popular seperti ResNet, EfficientNet, dan ConvNext Ranking, digabungkan dengan BNext-T sebagai model pelajar, mengesahkan keberkesanan metrik ini secara awal dan keputusan penarafan digunakan untuk pemilihan model penyulingan pengetahuan dalam eksperimen seterusnya. Rajah 5 Kesan overfitting kontra-intuitif dan kesan kerumitan pengetahuan di bawah pemilihan guru yang berbeza Atas dasar ini, pengarang kertas kerja mempertimbangkan lagi masalah pengoptimuman yang disebabkan oleh jurang pengedaran ramalan awal dalam proses pengoptimuman guru yang kukuh, dan mencadangkan Diversified Consecutive KD. Seperti yang ditunjukkan di bawah, penulis memodulasi fungsi objektif dalam proses pengoptimuman melalui kaedah integrasi pengetahuan gabungan guru kuat dan lemah. Atas dasar ini, strategi peningkatan pengetahuan diperkenalkan lagi, menggunakan berbilang calon guru yang telah ditetapkan untuk menukar guru yang lemah secara sekata semasa proses latihan, membimbing gabungan kerumitan pengetahuan dalam cara kurikulum daripada lemah kepada kuat, dan mengurangkan gangguan Pengoptimuman disebabkan oleh perbezaan. Dari segi teknik pengoptimuman, penulis BNext mempertimbangkan sepenuhnya kemungkinan keuntungan yang dibawa oleh penambahan data dalam pengoptimuman model ketepatan tinggi moden dan menyediakan yang pertama Memandangkan keputusan analisis kemungkinan kesan strategi penambahan data popular sedia ada dalam pengoptimuman model binari, keputusan eksperimen menunjukkan bahawa kaedah penambahan data sedia ada tidak sesuai sepenuhnya untuk pengoptimuman model binari, yang khusus untuk model binari dalam data Dioptimumkan reka bentuk strategi peningkatan menyediakan idea. Berdasarkan reka bentuk seni bina yang dicadangkan dan kaedah pengoptimuman, penulis menjalankan pengesahan kaedah pada tugas pengelasan imej berskala besar ImageNet-1k. Keputusan eksperimen ditunjukkan dalam Rajah 6. Rajah 6 Perbandingan kaedah SOTA BNN berdasarkan ImageNet-1k. Berbanding dengan kaedah sedia ada, BNext-L melonjakkan sempadan prestasi model binari kepada 80.57% buat kali pertama pada ImageNet-1k, mencapai ketepatan 10%+ mengatasi kebanyakan kaedah sedia ada. Berbanding dengan PokeBNN daripada Google, BNext-M adalah 0.7% lebih tinggi dengan parameter yang serupa. Pengarang juga menekankan bahawa pengoptimuman PokeBNN bergantung pada sumber pengkomputeran yang lebih tinggi, seperti Saiz Bacth sehingga 8192 dan TPU 720 Epochs , manakala BNext-L hanya mengulangi 512 Epoch dengan Saiz Kelompok konvensional 512, yang mencerminkan keberkesanan kaedah reka bentuk dan pengoptimuman struktur BNext. Dalam perbandingan berdasarkan model garis dasar yang sama, kedua-dua BNext-T dan BNext-18 telah meningkatkan ketepatan dengan ketara. Berbanding dengan model ketepatan penuh seperti RegNetY-4G (80.0%), BNext-L menunjukkan padanan keupayaan pembelajaran representasi visual sambil hanya menggunakan ruang parameter terhad dan kerumitan pengiraan, yang menjadikannya sesuai untuk penggunaan edge berdasarkan model tugas visual pada pengekstrak ciri model binari menyediakan ruang imaginasi yang kaya. BNext Penulis menyebut dalam kertas kerja bahawa mereka dan rakan usaha sama mereka sedang giat melaksanakan dan mengesahkan seni bina BNN berketepatan tinggi ini pada kecekapan operasi perkakasan GPU, dan merancang untuk berkembang ke platform perkakasan lain yang lebih luas pada masa hadapan. Walau bagaimanapun, pada pendapat editor, masyarakat telah memperoleh semula keyakinan terhadap BNN dan menarik perhatian lebih ramai pakar dalam bidang sistem dan perkakasan Mungkin kepentingan yang lebih penting dalam karya ini adalah untuk membentuk semula imaginasi potensi aplikasi BNN. Dalam jangka panjang, apabila semakin banyak aplikasi berhijrah daripada paradigma pengkomputeran tertumpu awan kepada pengkomputeran tepi terdesentralisasi, bilangan besar peranti tepi pada masa hadapan akan memerlukan teknologi AI, rangka kerja perisian dan platform pengkomputeran perkakasan yang lebih cekap. Walau bagaimanapun, model AI yang paling arus perdana dan seni bina pengkomputeran tidak direka bentuk dan dioptimumkan untuk senario kelebihan. Oleh itu, sehingga jawapan kepada edge AI ditemui, saya percaya bahawa BNN akan sentiasa menjadi pilihan penting yang penuh dengan cabaran teknikal dan potensi besar. 



Apa seterusnya?
Atas ialah kandungan terperinci Rangkaian saraf binari pertama BNext dengan ketepatan lebih daripada 80% pada ImageNet keluar, perjalanan lima tahun -1 dan +1. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

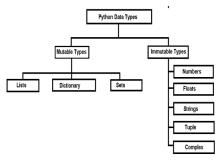 Mutable vs objek yang tidak berubah di Python - Analytics VidhyaApr 13, 2025 am 09:15 AM
Mutable vs objek yang tidak berubah di Python - Analytics VidhyaApr 13, 2025 am 09:15 AMPengenalan Python adalah bahasa pengaturcaraan berorientasikan objek (atau oops). Dalam artikel saya yang terdahulu, kami meneroka sifatnya yang serba boleh. Oleh kerana itu, Python menawarkan pelbagai jenis data, yang boleh diklasifikasikan secara meluas ke m
 11 Saluran YouTube Untuk Belajar Tableau secara Percuma - Analytics VidhyaApr 13, 2025 am 09:14 AM
11 Saluran YouTube Untuk Belajar Tableau secara Percuma - Analytics VidhyaApr 13, 2025 am 09:14 AMPengenalan Tableau dianggap sebagai salah satu alat visualisasi data yang paling mantap yang sedang digunakan oleh syarikat dan individu di seluruh dunia untuk analisis dan pembentangan data yang cekap. Dengan antara muka mesra pengguna dan exten
 10 Pelanjutan pengekodan AI generatif dalam kod vs yang mesti anda pelajariApr 13, 2025 am 01:14 AM
10 Pelanjutan pengekodan AI generatif dalam kod vs yang mesti anda pelajariApr 13, 2025 am 01:14 AMHei ada, pengekodan ninja! Apa tugas yang berkaitan dengan pengekodan yang anda telah merancang untuk hari itu? Sebelum anda menyelam lebih jauh ke dalam blog ini, saya ingin anda memikirkan semua kesengsaraan yang berkaitan dengan pengekodan anda-lebih jauh menyenaraikan mereka. Selesai? - Let ’
 Memasak Inovasi: Bagaimana Kecerdasan Buatan Mengubah Perkhidmatan MakananApr 12, 2025 pm 12:09 PM
Memasak Inovasi: Bagaimana Kecerdasan Buatan Mengubah Perkhidmatan MakananApr 12, 2025 pm 12:09 PMAI Menambah Penyediaan Makanan Walaupun masih dalam penggunaan baru, sistem AI semakin digunakan dalam penyediaan makanan. Robot yang didorong oleh AI digunakan di dapur untuk mengautomasikan tugas penyediaan makanan, seperti membuang burger, membuat pizza, atau memasang SA
 Panduan Komprehensif mengenai Python Namespaces & Variable ScopesApr 12, 2025 pm 12:00 PM
Panduan Komprehensif mengenai Python Namespaces & Variable ScopesApr 12, 2025 pm 12:00 PMPengenalan Memahami ruang nama, skop, dan tingkah laku pembolehubah dalam fungsi Python adalah penting untuk menulis dengan cekap dan mengelakkan kesilapan runtime atau pengecualian. Dalam artikel ini, kami akan menyelidiki pelbagai ASP
 Panduan Komprehensif untuk Model Bahasa Visi (VLMS)Apr 12, 2025 am 11:58 AM
Panduan Komprehensif untuk Model Bahasa Visi (VLMS)Apr 12, 2025 am 11:58 AMPengenalan Bayangkan berjalan melalui galeri seni, dikelilingi oleh lukisan dan patung yang terang. Sekarang, bagaimana jika anda boleh bertanya setiap soalan dan mendapatkan jawapan yang bermakna? Anda mungkin bertanya, "Kisah apa yang anda ceritakan?
 MediaTek meningkatkan barisan premium dengan Kompanio Ultra dan Dimensity 9400Apr 12, 2025 am 11:52 AM
MediaTek meningkatkan barisan premium dengan Kompanio Ultra dan Dimensity 9400Apr 12, 2025 am 11:52 AMMeneruskan irama produk, bulan ini MediaTek telah membuat satu siri pengumuman, termasuk Kompanio Ultra dan Dimensity 9400 yang baru. Produk ini mengisi bahagian perniagaan MediaTek yang lebih tradisional, termasuk cip untuk telefon pintar
 Minggu ini di AI: Walmart menetapkan trend fesyen sebelum mereka pernah berlakuApr 12, 2025 am 11:51 AM
Minggu ini di AI: Walmart menetapkan trend fesyen sebelum mereka pernah berlakuApr 12, 2025 am 11:51 AM#1 Google melancarkan Agent2Agent Cerita: Ia Isnin pagi. Sebagai perekrut berkuasa AI, anda bekerja lebih pintar, tidak lebih sukar. Anda log masuk ke papan pemuka syarikat anda di telefon anda. Ia memberitahu anda tiga peranan kritikal telah diperolehi, dijadualkan, dan dijadualkan untuk


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

mPDF
mPDF ialah perpustakaan PHP yang boleh menjana fail PDF daripada HTML yang dikodkan UTF-8. Pengarang asal, Ian Back, menulis mPDF untuk mengeluarkan fail PDF "dengan cepat" dari tapak webnya dan mengendalikan bahasa yang berbeza. Ia lebih perlahan dan menghasilkan fail yang lebih besar apabila menggunakan fon Unicode daripada skrip asal seperti HTML2FPDF, tetapi menyokong gaya CSS dsb. dan mempunyai banyak peningkatan. Menyokong hampir semua bahasa, termasuk RTL (Arab dan Ibrani) dan CJK (Cina, Jepun dan Korea). Menyokong elemen peringkat blok bersarang (seperti P, DIV),

SecLists
SecLists ialah rakan penguji keselamatan muktamad. Ia ialah koleksi pelbagai jenis senarai yang kerap digunakan semasa penilaian keselamatan, semuanya di satu tempat. SecLists membantu menjadikan ujian keselamatan lebih cekap dan produktif dengan menyediakan semua senarai yang mungkin diperlukan oleh penguji keselamatan dengan mudah. Jenis senarai termasuk nama pengguna, kata laluan, URL, muatan kabur, corak data sensitif, cangkerang web dan banyak lagi. Penguji hanya boleh menarik repositori ini ke mesin ujian baharu dan dia akan mempunyai akses kepada setiap jenis senarai yang dia perlukan.

EditPlus versi Cina retak
Saiz kecil, penyerlahan sintaks, tidak menyokong fungsi gesaan kod

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

Dreamweaver Mac版
Alat pembangunan web visual

