
Rumah >pembangunan bahagian belakang >Tutorial Python >Lengkapkan contoh operasi Python untuk sepuluh algoritma pengelompokan
Lengkapkan contoh operasi Python untuk sepuluh algoritma pengelompokan

- 王林ke hadapan
- 2023-04-13 09:40:101310semak imbas

Kluster atau analisis kelompok ialah masalah pembelajaran tanpa pengawasan. Ia sering digunakan sebagai teknik analisis data untuk menemui corak menarik dalam data, seperti segmen pelanggan berdasarkan tingkah laku mereka. Terdapat banyak algoritma pengelompokan untuk dipilih, dan tiada satu algoritma pengelompokan terbaik untuk semua situasi. Sebaliknya, adalah lebih baik untuk meneroka pelbagai algoritma pengelompokan dan konfigurasi berbeza bagi setiap algoritma. Dalam tutorial ini, anda akan mengetahui cara memasang dan menggunakan algoritma pengelompokan teratas dalam python.
Selepas melengkapkan tutorial ini, anda akan mengetahui:
- Pengkelompokan ialah masalah tanpa pengawasan untuk mencari kumpulan semula jadi dalam ruang ciri data input.
- Terdapat banyak algoritma pengelompokan yang berbeza dan satu kaedah terbaik untuk semua set data.
- Cara melaksanakan, menyesuaikan dan menggunakan algoritma pengelompokan teratas dalam Python dengan perpustakaan pembelajaran mesin scikit-lear.
Gambaran Keseluruhan Tutorial
- Tutorial ini dibahagikan kepada tiga bahagian:
- Pengelompokan
- Algoritma Pengelompokan BIRCH
- DBSCAN
- K-Means
- Mini-Batch K-Means
- Min Anjakan
- OPTIK
- Pengkelompokan Spektral
- Model Campuran Gaussian
- 1. Pengelompokan
- Analisis pengelompokan, iaitu pengelompokan, ialah tugas pembelajaran mesin yang diselia secara bebas. Ia termasuk secara automatik menemui kumpulan semula jadi dalam data. Tidak seperti pembelajaran diselia (serupa dengan pemodelan ramalan), algoritma pengelompokan hanya mentafsir data input dan mencari kumpulan atau gugusan semula jadi dalam ruang ciri.
- Teknik pengelompokan sesuai untuk situasi di mana tiada kelas untuk diramalkan, tetapi kejadian dibahagikan kepada kumpulan semula jadi.
- —Daripada: "Halaman Perlombongan Data: Alat dan Teknik Pembelajaran Mesin Praktikal" 2016.
- Kluster lazimnya ialah kawasan ketumpatan dalam ruang ciri di mana contoh (pemerhatian atau baris data) daripada domain lebih dekat dengan kluster berbanding kluster lain. Kluster boleh mempunyai pusat (centroid) yang merupakan sampel atau ruang ciri titik, dan boleh mempunyai sempadan atau julat.
Kluster ini mungkin menggambarkan beberapa mekanisme yang sedang berfungsi dalam domain dari mana tika itu dilukis, yang menjadikan beberapa kejadian lebih serupa antara satu sama lain berbanding tika yang lain.
—Daripada: "Halaman Perlombongan Data: Alat dan Teknik Pembelajaran Mesin Praktikal" 2016.
- Pengelompokkan boleh membantu sebagai aktiviti analisis data untuk mengetahui lebih lanjut tentang domain masalah, yang dikenali sebagai penemuan corak atau penemuan pengetahuan. Contohnya:
- Pokok evolusi boleh dianggap sebagai hasil analisis kelompok tiruan
Memisahkan data biasa daripada outlier atau kelainan boleh dianggap sebagai masalah pengelompokan;
- Memisahkan kelompok berdasarkan tingkah laku semula jadi ialah masalah pengelompokan yang dipanggil segmentasi pasaran.
- Pengkelompokan juga boleh digunakan sebagai sejenis kejuruteraan ciri, di mana contoh sedia ada dan baharu boleh dipetakan dan dilabelkan sebagai milik salah satu kelompok yang dikenal pasti dalam data. Walaupun banyak ukuran kuantitatif khusus kluster wujud, penilaian kluster yang dikenal pasti adalah subjektif dan mungkin memerlukan pakar domain. Lazimnya, algoritma pengelompokan dibandingkan secara akademik pada set data sintetik dengan kelompok pratakrif yang dijangka ditemui oleh algoritma.
Pengkelompokan ialah teknik pembelajaran tanpa pengawasan, jadi sukar untuk menilai kualiti output mana-mana kaedah tertentu.
- —Daripada: "Halaman Pembelajaran Mesin: Perspektif Kebarangkalian" 2012.
- 2. Algoritma pengelompokan
- Terdapat banyak jenis algoritma pengelompokan. Banyak algoritma menggunakan ukuran persamaan atau jarak antara contoh dalam ruang ciri untuk menemui kawasan cerapan yang padat. Oleh itu, selalunya amalan yang baik untuk mengembangkan data anda sebelum menggunakan algoritma pengelompokan.
Di tengah-tengah semua matlamat analisis kelompok ialah konsep tahap persamaan (atau ketidakserupaan) antara objek individu yang dikelompokkan. Kaedah pengelompokan cuba mengumpulkan objek berdasarkan definisi persamaan yang diberikan kepada objek.
- — Daripada: Elemen Pembelajaran Statistik: Perlombongan Data, Inferens dan Ramalan, 2016
- Sesetengah algoritma pengelompokan memerlukan anda untuk menentukan atau meneka kelompok yang ingin anda temui dalam data nombor, manakala algoritma lain memerlukan jarak minimum yang ditentukan antara pemerhatian di mana contoh boleh dianggap "tertutup" atau "bersambung". Oleh itu, analisis kluster ialah proses berulang di mana penilaian subjektif kluster yang dikenal pasti dimasukkan semula ke dalam perubahan dalam konfigurasi algoritma sehingga keputusan yang dikehendaki atau sesuai dicapai. Pustaka scikit-learn menyediakan satu set algoritma pengelompokan yang berbeza untuk dipilih. 10 daripada algoritma yang lebih popular disenaraikan di bawah:
- Penyebaran Perkaitan
- Pengkelompokan Agregat
- BIRCH
- DBSCAN
- K-Means
- Mini-Batch K - Min
- Anjakan Min
- OPTIK
- Pengkelompokan Spektral
- Campuran Gaussian
Setiap algoritma menyediakan pendekatan yang berbeza kepada cabaran untuk menemui kumpulan semula jadi dalam data. Tiada algoritma pengelompokan terbaik dan tiada cara mudah untuk mencari algoritma terbaik untuk data anda tanpa menggunakan eksperimen terkawal. Dalam tutorial ini, kami akan menyemak cara menggunakan setiap 10 algoritma pengelompokan popular ini daripada perpustakaan scikit-learn. Contoh-contoh ini akan memberi anda asas untuk menyalin dan menampal contoh dan menguji kaedah pada data anda sendiri. Kami tidak akan menyelidiki teori tentang cara algoritma berfungsi, dan kami tidak akan membandingkannya secara langsung. Mari kita gali sedikit lebih dalam.
3. Contoh Algoritma Pengelompokan
Dalam bahagian ini, kami akan menyemak cara menggunakan 10 algoritma pengelompokan yang popular dalam scikit-learn. Ini termasuk contoh pemasangan model dan contoh visualisasi hasil. Contoh-contoh ini adalah untuk menampal dan menyalin ke dalam projek anda sendiri dan menggunakan kaedah pada data anda sendiri.
1. Pemasangan perpustakaan
Mula-mula, mari pasang perpustakaan. Jangan langkau langkah ini kerana anda perlu memastikan anda memasang versi terkini. Anda boleh memasang repositori scikit-learn menggunakan pemasang Python pip seperti ini:
sudo pip install scikit-learn
Seterusnya, mari sahkan bahawa perpustakaan telah dipasang dan anda menggunakan versi moden. Jalankan skrip berikut untuk mengeluarkan nombor versi perpustakaan.
# 检查 scikit-learn 版本 import sklearn print(sklearn.__version__)
Apabila anda menjalankan contoh, anda sepatutnya melihat nombor versi berikut atau lebih tinggi.
0.22.1
2. Mengelompokkan set data
Kami akan menggunakan fungsi make_classification () untuk mencipta set data klasifikasi binari ujian. Set data akan mempunyai 1000 contoh, dengan dua ciri input dan satu kelompok bagi setiap kelas. Kelompok ini boleh dilihat dalam dua dimensi, jadi kita boleh memplot data dalam plot serakan dan mewarnai titik dalam plot mengikut kelompok yang ditentukan.
Ini akan membantu untuk memahami sejauh mana kluster dikenal pasti, sekurang-kurangnya pada masalah ujian. Kelompok dalam masalah ujian ini adalah berdasarkan Gaussians multivariate, dan tidak semua algoritma pengelompokan berkesan untuk mengenal pasti jenis kelompok ini. Oleh itu, keputusan dalam tutorial ini tidak boleh digunakan sebagai asas untuk membandingkan kaedah umum. Disenaraikan di bawah ialah contoh mencipta dan meringkaskan set data kelompok sintetik.
# 综合分类数据集 from numpy import where from sklearn.datasets import make_classification from matplotlib import pyplot # 定义数据集 X, y = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 为每个类的样本创建散点图 for class_value in range(2): # 获取此类的示例的行索引 row_ix = where(y == class_value) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()
Menjalankan contoh ini akan mencipta set data berkelompok sintetik dan kemudian mencipta plot serakan data input, dengan titik diwarnai oleh label kelas (kelompok ideal). Kami dapat melihat dengan jelas dua kumpulan data yang berbeza dalam dua dimensi dan berharap algoritma pengelompokan automatik dapat mengesan kumpulan ini.
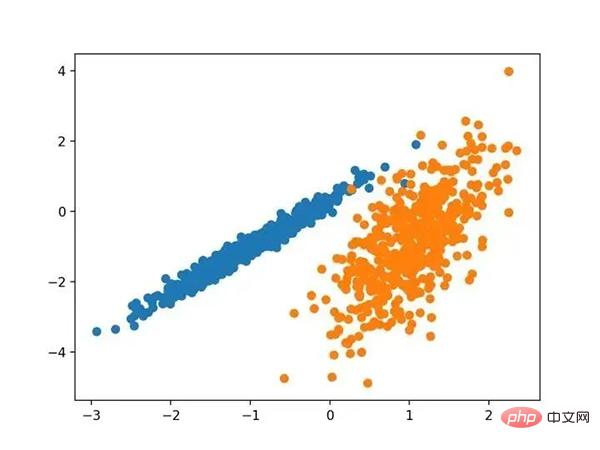
Scatterplot bagi set data pengelompokan sintetik bagi titik teduhan berkelompok yang diketahui
Seterusnya, kita boleh mula melihat hasil yang digunakan pada set data ini Contoh algoritma pengelompokan. Saya telah membuat beberapa percubaan minimum untuk menyesuaikan setiap kaedah kepada set data.
3. Penyebaran Perkaitan
Penyebaran Perkaitan melibatkan mencari satu set contoh yang terbaik meringkaskan data.
- Kami mereka kaedah yang dipanggil "perambatan pertalian" yang berfungsi sebagai ukuran input persamaan antara dua pasangan titik data. Mesej bernilai sebenar ditukar antara titik data sehingga satu set contoh berkualiti tinggi dan kelompok yang sepadan secara beransur-ansur muncul
- —Daripada: "Dengan menghantar mesej antara titik data" 2007.
Ia dilaksanakan melalui kelas AffinityPropagation, konfigurasi utama untuk diselaraskan adalah untuk menetapkan "Dampening" daripada 0.5 kepada 1, mungkin juga "Preferences".
Contoh penuh disenaraikan di bawah.
# 亲和力传播聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import AffinityPropagation from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = AffinityPropagation(damping=0.9) # 匹配模型 model.fit(X) # 为每个示例分配一个集群 yhat = model.predict(X) # 检索唯一群集 clusters = unique(yhat) # 为每个群集的样本创建散点图 for cluster in clusters: # 获取此群集的示例的行索引 row_ix = where(yhat == cluster) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()
Jalankan contoh agar sesuai dengan model pada set data latihan dan ramalkan kelompok untuk setiap contoh dalam set data. Plot berselerak kemudian dibuat, diwarnai oleh kelompok yang ditetapkan. Dalam kes ini saya tidak dapat mencapai keputusan yang baik.
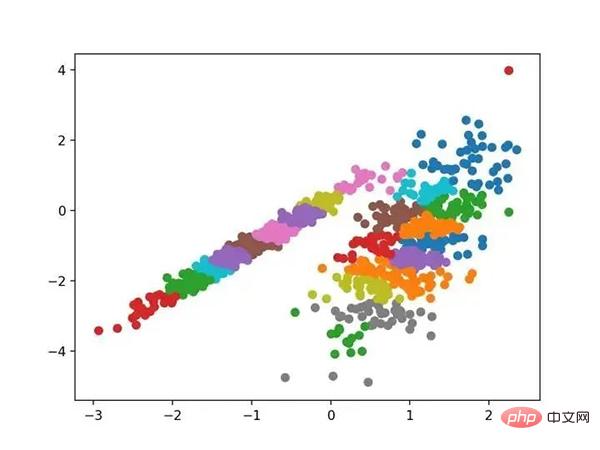
Scatterplot set data dengan kelompok dikenal pasti menggunakan perambatan perkaitan
4. Pengkelompokan Agregat
Pengelompokan Agregat Melibatkan contoh penggabungan sehingga nombor yang dikehendaki kluster dicapai. Ia merupakan sebahagian daripada kelas kaedah pengelompokan hierarki yang lebih luas, dilaksanakan melalui kelas AgglomerationClustering, dan konfigurasi utama ialah set " n_clusters ", yang merupakan anggaran bilangan gugusan dalam data, cth. Contoh lengkap disenaraikan di bawah.
# 聚合聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import AgglomerativeClustering from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = AgglomerativeClustering(n_clusters=2) # 模型拟合与聚类预测 yhat = model.fit_predict(X) # 检索唯一群集 clusters = unique(yhat) # 为每个群集的样本创建散点图 for cluster in clusters: # 获取此群集的示例的行索引 row_ix = where(yhat == cluster) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()
Jalankan contoh agar sesuai dengan model pada set data latihan dan ramalkan kelompok untuk setiap contoh dalam set data. Plot berselerak kemudian dibuat, diwarnai oleh kelompok yang ditetapkan. Dalam kes ini, kumpulan yang munasabah boleh didapati.
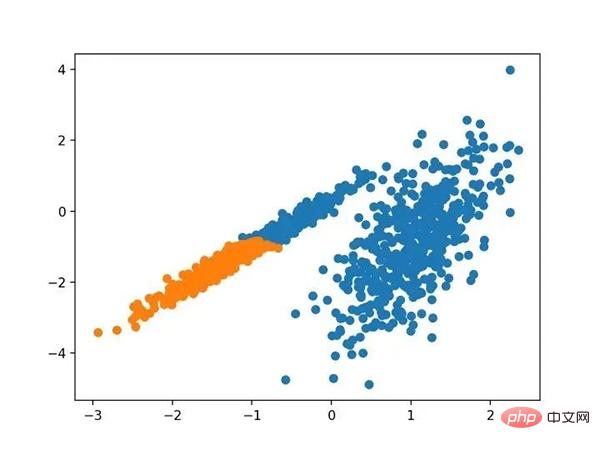
Petak serakan bagi set data dengan gugusan dikenal pasti menggunakan pengelompokan aglomeratif
5.BIRCH
BIRCH 聚类( BIRCH 是平衡迭代减少的缩写,聚类使用层次结构)包括构造一个树状结构,从中提取聚类质心。
- BIRCH 递增地和动态地群集传入的多维度量数据点,以尝试利用可用资源(即可用内存和时间约束)产生最佳质量的聚类。
- —源自:《 BIRCH :1996年大型数据库的高效数据聚类方法》
它是通过 Birch 类实现的,主要配置是“ threshold ”和“ n _ clusters ”超参数,后者提供了群集数量的估计。下面列出了完整的示例。
# birch聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import Birch from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = Birch(threshold=0.01, n_clusters=2) # 适配模型 model.fit(X) # 为每个示例分配一个集群 yhat = model.predict(X) # 检索唯一群集 clusters = unique(yhat) # 为每个群集的样本创建散点图 for cluster in clusters: # 获取此群集的示例的行索引 row_ix = where(yhat == cluster) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,可以找到一个很好的分组。
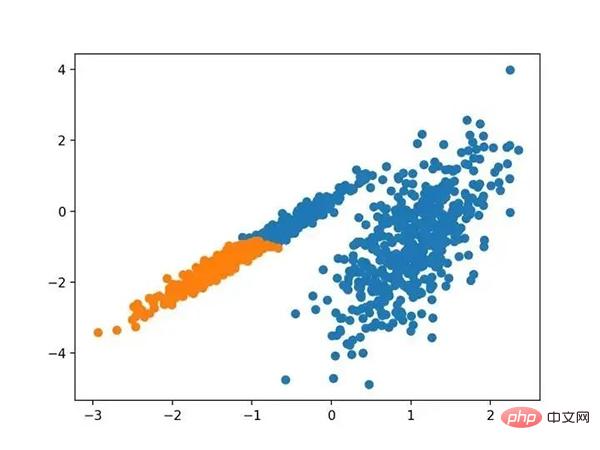
使用BIRCH聚类确定具有聚类的数据集的散点图
6.DBSCAN
DBSCAN 聚类(其中 DBSCAN 是基于密度的空间聚类的噪声应用程序)涉及在域中寻找高密度区域,并将其周围的特征空间区域扩展为群集。
- …我们提出了新的聚类算法 DBSCAN 依赖于基于密度的概念的集群设计,以发现任意形状的集群。DBSCAN 只需要一个输入参数,并支持用户为其确定适当的值
- -源自:《基于密度的噪声大空间数据库聚类发现算法》,1996
它是通过 DBSCAN 类实现的,主要配置是“ eps ”和“ min _ samples ”超参数。
下面列出了完整的示例。
# dbscan 聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import DBSCAN from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = DBSCAN(eps=0.30, min_samples=9) # 模型拟合与聚类预测 yhat = model.fit_predict(X) # 检索唯一群集 clusters = unique(yhat) # 为每个群集的样本创建散点图 for cluster in clusters: # 获取此群集的示例的行索引 row_ix = where(yhat == cluster) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,尽管需要更多的调整,但是找到了合理的分组。
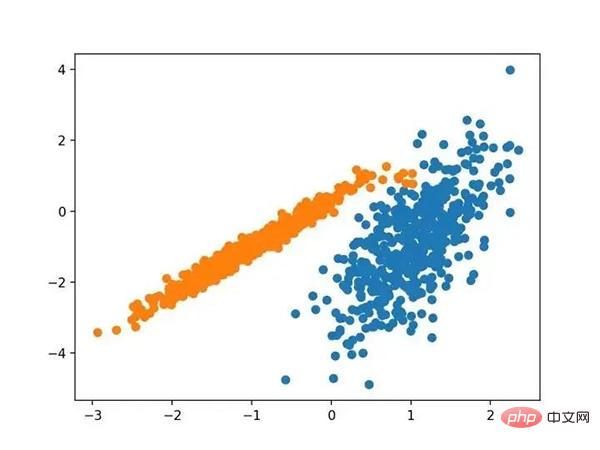
使用DBSCAN集群识别出具有集群的数据集的散点图
7.K均值
K-均值聚类可以是最常见的聚类算法,并涉及向群集分配示例,以尽量减少每个群集内的方差。
- 本文的主要目的是描述一种基于样本将 N 维种群划分为 k 个集合的过程。这个叫做“ K-均值”的过程似乎给出了在类内方差意义上相当有效的分区。
- -源自:《关于多元观测的分类和分析的一些方法》1967年
它是通过 K-均值类实现的,要优化的主要配置是“ n _ clusters ”超参数设置为数据中估计的群集数量。下面列出了完整的示例。
# k-means 聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import KMeans from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = KMeans(n_clusters=2) # 模型拟合 model.fit(X) # 为每个示例分配一个集群 yhat = model.predict(X) # 检索唯一群集 clusters = unique(yhat) # 为每个群集的样本创建散点图 for cluster in clusters: # 获取此群集的示例的行索引 row_ix = where(yhat == cluster) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,可以找到一个合理的分组,尽管每个维度中的不等等方差使得该方法不太适合该数据集。
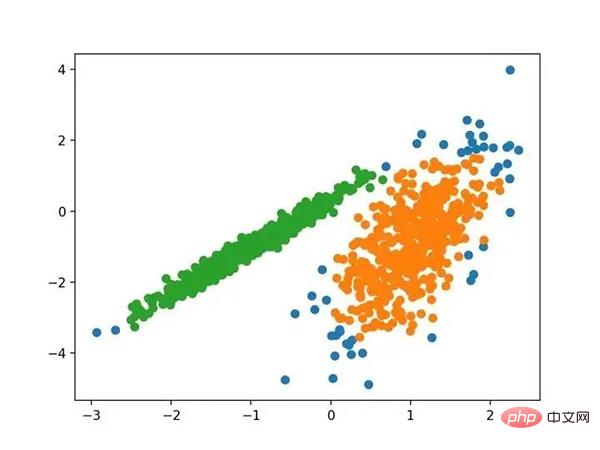
使用K均值聚类识别出具有聚类的数据集的散点图
8.Mini-Batch K-均值
Mini-Batch K-均值是 K-均值的修改版本,它使用小批量的样本而不是整个数据集对群集质心进行更新,这可以使大数据集的更新速度更快,并且可能对统计噪声更健壮。
- ...我们建议使用 k-均值聚类的迷你批量优化。与经典批处理算法相比,这降低了计算成本的数量级,同时提供了比在线随机梯度下降更好的解决方案。
- —源自:《Web-Scale K-均值聚类》2010
它是通过 MiniBatchKMeans 类实现的,要优化的主配置是“ n _ clusters ”超参数,设置为数据中估计的群集数量。下面列出了完整的示例。
# mini-batch k均值聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import MiniBatchKMeans from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = MiniBatchKMeans(n_clusters=2) # 模型拟合 model.fit(X) # 为每个示例分配一个集群 yhat = model.predict(X) # 检索唯一群集 clusters = unique(yhat) # 为每个群集的样本创建散点图 for cluster in clusters: # 获取此群集的示例的行索引 row_ix = where(yhat == cluster) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,会找到与标准 K-均值算法相当的结果。
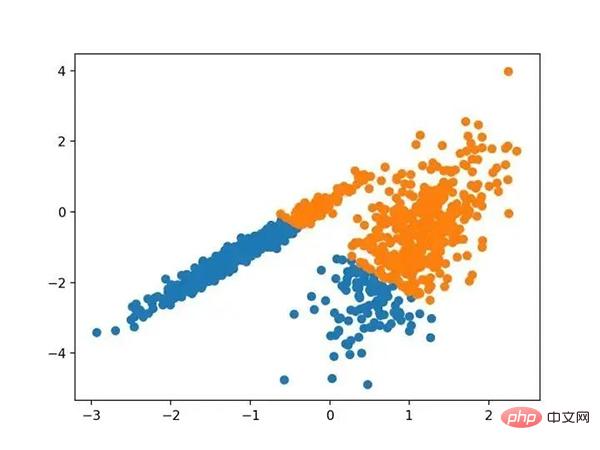
带有最小批次K均值聚类的聚类数据集的散点图
9.均值漂移聚类
均值漂移聚类涉及到根据特征空间中的实例密度来寻找和调整质心。
- 对离散数据证明了递推平均移位程序收敛到最接近驻点的基础密度函数,从而证明了它在检测密度模式中的应用。
- —源自:《Mean Shift :面向特征空间分析的稳健方法》,2002
它是通过 MeanShift 类实现的,主要配置是“带宽”超参数。下面列出了完整的示例。
# 均值漂移聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import MeanShift from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = MeanShift() # 模型拟合与聚类预测 yhat = model.fit_predict(X) # 检索唯一群集 clusters = unique(yhat) # 为每个群集的样本创建散点图 for cluster in clusters: # 获取此群集的示例的行索引 row_ix = where(yhat == cluster) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,可以在数据中找到一组合理的群集。
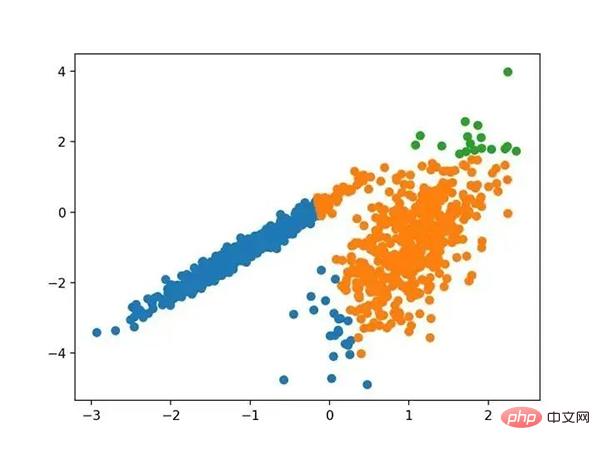
具有均值漂移聚类的聚类数据集散点图
10.OPTICS
OPTICS 聚类( OPTICS 短于订购点数以标识聚类结构)是上述 DBSCAN 的修改版本。
- 我们为聚类分析引入了一种新的算法,它不会显式地生成一个数据集的聚类;而是创建表示其基于密度的聚类结构的数据库的增强排序。此群集排序包含相当于密度聚类的信息,该信息对应于范围广泛的参数设置。
- —源自:《OPTICS :排序点以标识聚类结构》,1999
它是通过 OPTICS 类实现的,主要配置是“ eps ”和“ min _ samples ”超参数。下面列出了完整的示例。
# optics聚类 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import OPTICS from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = OPTICS(eps=0.8, min_samples=10) # 模型拟合与聚类预测 yhat = model.fit_predict(X) # 检索唯一群集 clusters = unique(yhat) # 为每个群集的样本创建散点图 for cluster in clusters: # 获取此群集的示例的行索引 row_ix = where(yhat == cluster) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,我无法在此数据集上获得合理的结果。
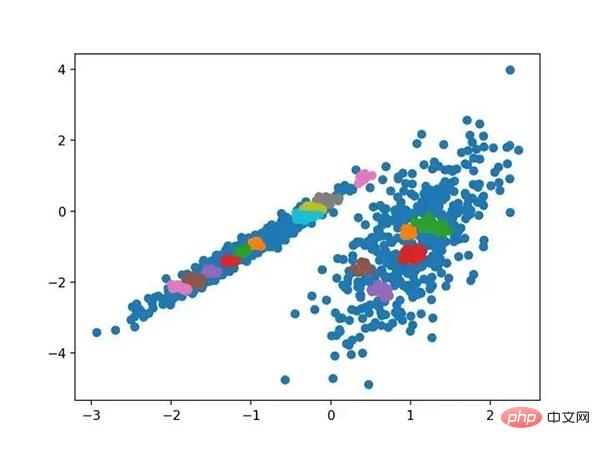
使用OPTICS聚类确定具有聚类的数据集的散点图
11.光谱聚类
光谱聚类是一类通用的聚类方法,取自线性线性代数。
- 最近在许多领域出现的一个有希望的替代方案是使用聚类的光谱方法。这里,使用从点之间的距离导出的矩阵的顶部特征向量。
- —源自:《关于光谱聚类:分析和算法》,2002年
它是通过 Spectral 聚类类实现的,而主要的 Spectral 聚类是一个由聚类方法组成的通用类,取自线性线性代数。要优化的是“ n _ clusters ”超参数,用于指定数据中的估计群集数量。下面列出了完整的示例。
# spectral clustering from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.cluster import SpectralClustering from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = SpectralClustering(n_clusters=2) # 模型拟合与聚类预测 yhat = model.fit_predict(X) # 检索唯一群集 clusters = unique(yhat) # 为每个群集的样本创建散点图 for cluster in clusters: # 获取此群集的示例的行索引 row_ix = where(yhat == cluster) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。
在这种情况下,找到了合理的集群。
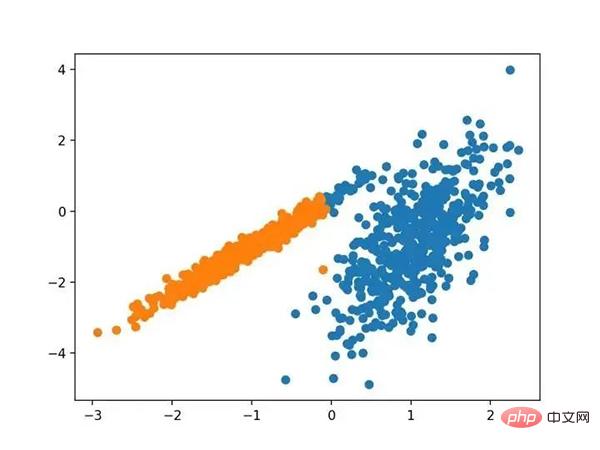
使用光谱聚类聚类识别出具有聚类的数据集的散点图
12.高斯混合模型
高斯混合模型总结了一个多变量概率密度函数,顾名思义就是混合了高斯概率分布。它是通过 Gaussian Mixture 类实现的,要优化的主要配置是“ n _ clusters ”超参数,用于指定数据中估计的群集数量。下面列出了完整的示例。
# 高斯混合模型 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.mixture import GaussianMixture from matplotlib import pyplot # 定义数据集 X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4) # 定义模型 model = GaussianMixture(n_components=2) # 模型拟合 model.fit(X) # 为每个示例分配一个集群 yhat = model.predict(X) # 检索唯一群集 clusters = unique(yhat) # 为每个群集的样本创建散点图 for cluster in clusters: # 获取此群集的示例的行索引 row_ix = where(yhat == cluster) # 创建这些样本的散布 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 绘制散点图 pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,我们可以看到群集被完美地识别。这并不奇怪,因为数据集是作为 Gaussian 的混合生成的。
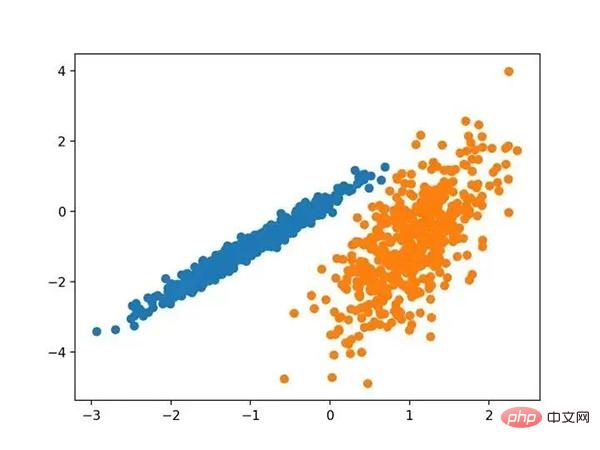
使用高斯混合聚类识别出具有聚类的数据集的散点图
三.总结
在本教程中,您发现了如何在 python 中安装和使用顶级聚类算法。具体来说,你学到了:
- 聚类是在特征空间输入数据中发现自然组的无监督问题。
- 有许多不同的聚类算法,对于所有数据集没有单一的最佳方法。
- 在 scikit-learn 机器学习库的 Python 中如何实现、适合和使用顶级聚类算法。
Atas ialah kandungan terperinci Lengkapkan contoh operasi Python untuk sepuluh algoritma pengelompokan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!