
Rumah >Peranti teknologi >AI >Sebuah artikel membincangkan secara ringkas keupayaan generalisasi pembelajaran mendalam
Sebuah artikel membincangkan secara ringkas keupayaan generalisasi pembelajaran mendalam

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-13 09:19:021184semak imbas

1. Isu keupayaan generalisasi DNN
Kertas ini terutamanya membincangkan mengapa model rangkaian saraf lebih parameter masih boleh mempunyai generalisasi yang baik? Iaitu, ia bukan sekadar menghafal set latihan, tetapi meringkaskan peraturan am dari set latihan, supaya ia boleh disesuaikan dengan set ujian (keupayaan generalisasi).

Ambil model pepohon keputusan klasik sebagai contoh Apabila model pepohon mempelajari peraturan am set data: situasi yang baik, jika pepohon mula-mula membelah nod, Ia hanya boleh membezakan sampel dengan label yang berbeza, kedalamannya sangat kecil, dan bilangan sampel pada setiap daun yang sepadan adalah mencukupi (iaitu, jumlah asas data untuk peraturan statistik juga agak besar), maka peraturan yang akan yang diperolehi akan lebih mungkin digeneralisasikan kepada data lain. (iaitu: kesesuaian yang baik dan keupayaan generalisasi).
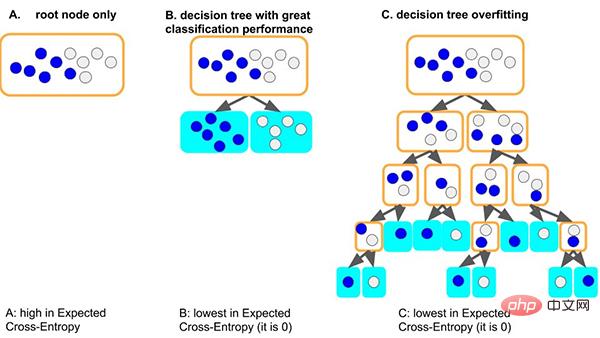
Situasi lain yang lebih teruk ialah jika pokok tidak dapat mempelajari beberapa peraturan am, untuk mempelajari set data ini, pokok akan menjadi lebih dalam dan lebih dalam, mungkin setiap kali Setiap daun nod sepadan dengan sebilangan kecil sampel (maklumat statistik yang dibawa oleh sejumlah kecil data mungkin hanya bunyi bising Akhirnya, semua data dihafal dengan hafalan (iaitu: overfitting dan tiada keupayaan generalisasi). Kita dapat melihat bahawa model pokok yang terlalu dalam dengan mudah boleh menjadi terlalu muat.
Jadi, bagaimanakah rangkaian neural terparameter boleh mencapai generalisasi yang baik?
2. Sebab keupayaan generalisasi DNN
Artikel ini menerangkan dari perspektif yang mudah dan umum - meneroka sebab keupayaan generalisasi dalam proses pengoptimuman keturunan kecerunan rangkaian saraf:
Kami meringkaskan teori koheren kecerunan: koheren kecerunan daripada sampel yang berbeza adalah sebab mengapa rangkaian saraf boleh mempunyai keupayaan generalisasi yang baik. Apabila kecerunan sampel yang berbeza diselaraskan dengan baik semasa latihan, iaitu, apabila ia koheren, keturunan kecerunan adalah stabil, boleh menumpu dengan cepat, dan model yang terhasil boleh digeneralisasikan dengan baik. Jika tidak, jika sampel terlalu sedikit atau masa latihan terlalu lama, ia mungkin tidak digeneralisasikan.

Berdasarkan teori ini, kita boleh membuat penjelasan berikut.
2.1 Generalisasi Rangkaian Neural Lebar
Model rangkaian saraf yang lebih luas mempunyai keupayaan generalisasi yang baik. Ini kerana rangkaian yang lebih luas mempunyai lebih banyak sub-rangkaian dan lebih berkemungkinan menghasilkan keselarasan kecerunan daripada rangkaian yang lebih kecil, menghasilkan generalisasi yang lebih baik. Dalam erti kata lain, keturunan kecerunan ialah pemilih ciri yang mengutamakan kecerunan generalisasi (kepaduan), dan rangkaian yang lebih luas mungkin mempunyai ciri yang lebih baik hanya kerana mereka mempunyai lebih banyak ciri.
- Kertas asal: Generalisasi dan lebar Neyshabur et al [2018b] mendapati bahawa rangkaian yang lebih luas dapat menjelaskan perkara ini secara intuitif, rangkaian yang lebih luas pada tahap tertentu. maka sub-rangkaian dengan koheren maksimum dalam rangkaian yang lebih luas mungkin lebih koheren daripada rakan sejawatannya dalam rangkaian yang lebih nipis, dan oleh itu menggeneralisasikan dengan lebih baik, kerana—seperti yang dibincangkan dalam Bahagian 10—keturunan kecerunan ialah pemilih ciri yang mengutamakan. ciri generalisasi (koheren), rangkaian yang lebih luas berkemungkinan mempunyai ciri yang lebih baik hanya kerana mereka mempunyai lebih banyak ciri Dalam hubungan ini, lihat juga Hipotesis Tiket Loteri [Frankle dan Carbin, 2018]
- Pautan kertas :https. ://github.com/aialgorithm/Blog
Tetapi secara peribadi, saya rasa ia masih perlu membezakan lebar lapisan input rangkaian/lapisan tersembunyi. Terutama untuk lapisan input tugas perlombongan data, kerana ciri input biasanya direka secara manual, anda perlu mempertimbangkan pemilihan ciri (iaitu, mengurangkan lebar lapisan input Jika tidak, bunyi ciri input secara langsung akan mengganggu koheren kecerunan). .
2.2 Generalisasi Rangkaian Neural Dalam
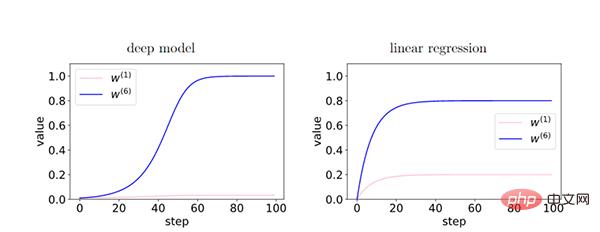
Semakin dalam rangkaian, fenomena koheren kecerunan dikuatkan dan mempunyai keupayaan generalisasi yang lebih baik.

Dalam model dalam, memandangkan maklum balas antara lapisan menguatkan kecerunan koheren, terdapat ciri-ciri kecerunan koheren (W6) dan ciri-ciri kecerunan tidak koheren ( Perbezaan relatif antara W1) dikuatkan secara eksponen semasa latihan. Ini menjadikan rangkaian yang lebih dalam memilih kecerunan yang koheren, menghasilkan keupayaan generalisasi yang lebih baik.
2.3 Berhenti awal
Dengan berhenti awal, kita boleh mengurangkan pengaruh kecerunan tidak koheren yang berlebihan dan meningkatkan generalisasi.
Semasa latihan, beberapa sampel mudah dipasang lebih awal daripada sampel lain (sampel keras). Pada peringkat awal latihan, kecerunan korelasi sampel mudah ini mendominasi dan mudah untuk dimuatkan. Pada peringkat akhir latihan, kecerunan tidak koheren sampel sukar mendominasi kecerunan purata g(wt), mengakibatkan keupayaan generalisasi yang lemah Pada masa ini, adalah perlu untuk berhenti lebih awal.

- (Nota: Sampel mudah ialah sampel yang mempunyai banyak kecerunan yang sama dalam set data. Atas sebab ini, kebanyakan kecerunan memberi manfaat kepadanya. , penumpuan juga lebih cepat. Tambahan pula, eksperimen yang teliti menunjukkan bahawa keturunan kecerunan stokastik tidak semestinya membawa kepada generalisasi yang lebih baik, tetapi ini tidak menolak kemungkinan bahawa kecerunan stokastik lebih berkemungkinan melompat keluar dari minima tempatan, memainkan peranan dalam regularisasi, dsb.
Berdasarkan teori kami, kadar pembelajaran terhingga dan stokastik kumpulan mini tidak diperlukan untuk generalisasi
Kami percaya bahawa kadar pembelajaran yang lebih rendah mungkin tidak mengurangkan ralat generalisasi , kerana kadar pembelajaran yang lebih rendah bermakna lebih banyak lelaran (bertentangan dengan berhenti awal).- Dengan mengandaikan kadar pembelajaran yang cukup kecil, semasa latihan berlangsung, jurang generalisasi tidak boleh berkurangan Ini berikutan daripada analisis kestabilan berulang latihan: dengan 40 langkah lagi, kestabilan hanya boleh merosot dalam suasana praktikal, ia akan menunjukkan had teori yang menarik
- Tambah L2, L1 regularization pada fungsi objektif, dan pengiraan kecerunan yang sepadan , Kecerunan yang perlu ditambah pada sebutan biasa L1 ialah tanda(w), dan kecerunan L2 ialah w. Mengambil penyelarasan L2 sebagai contoh, formula kemas kini kecerunan W(i+1) yang sepadan ialah: Gambar
Kita boleh menganggap "penyaturan L2 (pereputan berat)" sebagai A "daya latar belakang" yang boleh menolak setiap parameter hampir kepada nilai sifar bebas data (L1 dengan mudah boleh mendapatkan penyelesaian yang jarang, dan L2 dengan mudah boleh mendapatkan penyelesaian yang lancar menghampiri 0) untuk menghapuskan pengaruh dalam arah kecerunan yang lemah. Hanya dalam kes arah kecerunan yang koheren, parameter boleh dipisahkan secara relatif daripada "daya latar belakang" dan kemas kini kecerunan boleh diselesaikan berdasarkan data.
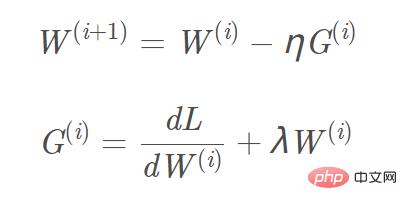
2.6 Algoritma Turun Kecerunan Lanjutan
 Momentum, Adam dan algoritma keturunan kecerunan lain
Momentum, Adam dan algoritma keturunan kecerunan lain
- Sekat penurunan kecerunan dalam arah kecerunan lemah
Ringkasan
Beberapa ayat di akhir artikel Jika anda berminat dengan teori pembelajaran mendalam, anda boleh membaca penyelidikan berkaitan yang dinyatakan dalam kertas. 

Atas ialah kandungan terperinci Sebuah artikel membincangkan secara ringkas keupayaan generalisasi pembelajaran mendalam. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI