
Rumah >Peranti teknologi >AI >Artikel panjang 10,000 perkataan, sains popular tentang algoritma dan sistem pengecaman muka
Artikel panjang 10,000 perkataan, sains popular tentang algoritma dan sistem pengecaman muka

- 王林ke hadapan
- 2023-04-13 08:16:112079semak imbas

Matlamat pengecaman muka
Untuk meringkaskan dua perkara, pertama, kenali orang yang sama, tidak kira bagaimana status anda berubah, anda boleh tahu bahawa anda adalah anda. Kedua, membezakan orang yang berbeza Mungkin kedua-dua orang kelihatan sangat serupa, atau kedua-dua orang memakai solek, tetapi tidak kira bagaimana perubahan status, pengecaman muka dapat mengetahui bahawa ini adalah dua orang yang berbeza.
Pengecaman muka itu sendiri adalah sejenis teknologi biometrik, terutamanya menyediakan cara pengesahan identiti Dari segi ketepatan, pengecaman muka bukanlah yang tertinggi. Pengecaman muka dipengaruhi oleh banyak keadaan lain, seperti pencahayaan. Kelebihan pengecaman muka ialah ia secara amnya tidak memerlukan banyak kerjasama daripada pengguna Pada masa kini, kamera pengawasan di pelbagai tempat, termasuk kamera komputer, peranti input video telefon bimbit, dan peralatan kamera telah menjadi sangat popular boleh Boleh melakukan pengecaman muka. Oleh itu, apabila pengenalan wajah diperkenalkan, pelaburan baru mungkin sangat kecil, yang merupakan kelebihannya.
Proses pengecaman muka
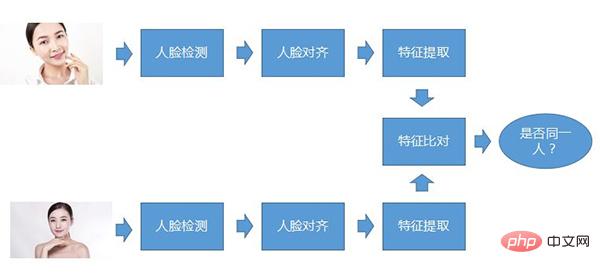
Proses teras pengecaman muka Apa yang dipanggil proses teras bermakna tidak kira apa jenis sistem pengecaman muka, proses ini pada asasnya ada. Langkah pertama ialah pengesanan muka, langkah kedua ialah penjajaran muka, dan langkah ketiga ialah pengekstrakan ciri Ini adalah tiga langkah yang mesti dilakukan untuk setiap foto muka milik orang yang sama.
Pengesanan muka
Pengesanan muka adalah untuk menentukan sama ada terdapat wajah dalam pemandangan yang besar, dan untuk mencari kedudukan muka dan memotongnya . Ia adalah sejenis teknologi pengesanan objek dan merupakan asas kepada keseluruhan tugas persepsi muka. Kaedah asas pengesanan muka ialah meluncurkan tetingkap pada piramid imej, menggunakan pengelas untuk memilih tetingkap calon, dan menggunakan model regresi untuk membetulkan kedudukan.
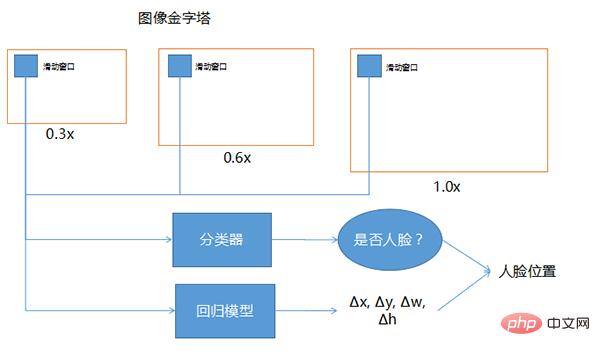
Tiga tingkap yang dilukis di atas, satu ialah 0.3 kali, 0.6 kali, dan 1.0 kali Teknologi ini boleh digunakan apabila kedudukan muka tidak menentu dan saiznya tidak boleh dikenali, supaya ini Graf itu sendiri menjadi saiz yang berbeza, manakala tetingkap gelongsor adalah saiz yang sama. Saiz input imej ke rangkaian dalam biasanya ditetapkan, jadi tetingkap gelongsor di hadapan pada dasarnya tetap. Untuk membolehkan tetingkap gelongsor tetap meliputi julat yang berbeza, saiz keseluruhan imej diskalakan kepada perkadaran yang berbeza. 0.3, 0.6 dan 1.0 yang ditunjukkan di sini hanyalah contoh. Terdapat banyak gandaan lain yang berbeza dalam penggunaan sebenar.
Pengkelas merujuk kepada melihat setiap kedudukan tetingkap gelongsor untuk menentukan sama ada ia adalah muka, kerana kedudukan di mana tetingkap gelongsor meluncur mungkin tidak termasuk keseluruhan muka, atau mungkin lebih besar daripada keseluruhan muka . Untuk mencari wajah yang lebih tepat, meletakkan tetingkap gelongsor ke dalam model regresi boleh membantu membetulkan ketepatan pengesanan muka.
Input ialah tetingkap gelongsor Jika terdapat muka di dalamnya semasa output, arah mana yang perlu dibetulkan dan berapa banyak yang perlu dibetulkan, jadi Δx, Δy, Δw, Δh ialah koordinatnya dan koordinatnya. lebar dan tinggi lebih kurang berapa banyak pembetulan. Selepas mempunyai jumlah pembetulan dan menggunakan pengelas untuk menentukan bahawa ia adalah tingkap muka manusia, dengan menggabungkan kedua-dua ini bersama-sama, kedudukan wajah manusia yang lebih tepat boleh diperolehi.
Di atas ialah proses pengesanan muka, dan ia juga boleh digunakan pada pengesanan objek lain
Penunjuk penilaian pengesanan muka
Tidak kira apa jenis model, ia adalah berdasarkan kelajuan dan ketepatan
1. Kelajuan
(1) Kelajuan ialah kelajuan pengesanan pada resolusi yang ditentukan
Sebab mengapa resolusi ditentukan adalah kerana tetingkap gelongsor meluncur setiap kali Penilaian klasifikasi dan regresi mesti dibuat untuk mencapai setiap kedudukan, jadi apabila imej lebih besar, bilangan tetingkap yang perlu dibuat untuk pengesanan dan penghakiman mungkin lebih banyak, dan keseluruhan pengesanan muka akan mengambil masa yang lebih lama.
Oleh itu, untuk menilai kualiti algoritma atau model, anda perlu melihat kelajuan pengesanannya pada resolusi tetap. Secara umumnya, apakah kelajuan pengesanan mungkin masa yang diperlukan untuk mengesan wajah gambar, seperti 100 milisaat, 200 milisaat, 50 milisaat, 30 milisaat, dsb.
Satu lagi cara untuk mengekspresikan kelajuan ialah fps Pada masa kini, kamera web umum selalunya 25fps atau 30fps, yang bermaksud berapa banyak gambar yang boleh diproses sesaat Manfaat fps boleh digunakan untuk menilai sama ada pengesanan muka boleh dilakukan . Untuk mencapai pengesanan masa nyata, selagi bilangan fps pengesanan muka lebih besar daripada nombor fps kamera, pengesanan masa nyata boleh dicapai, jika tidak, ia tidak boleh dicapai.
(2) Adakah kelajuan dipengaruhi oleh bilangan muka dalam gambar yang sama
Dari operasi sebenar kami, sebahagian besarnya tidak terjejas, kerana ia dipengaruhi terutamanya oleh gelongsor? Bilangan tetingkap mempengaruhi bilangan hits Jumlah hits tidak begitu penting, tetapi ia mempunyai sedikit kesan.
2. Ketepatan
Ketepatan pada asasnya ditentukan oleh kadar ingatan semula, kadar pengesanan palsu dan lengkung ROC. Kadar ingat semula merujuk kepada bahagian foto yang merupakan wajah manusia dan model sebenar menentukan bahawa ia adalah wajah manusia Kadar pengesanan palsu dan kadar ralat sampel negatif merujuk kepada bahagian foto yang bukan wajah manusia tetapi disalah anggap sebagai wajah manusia.
Ketepatan ACC
Kaedah pengiraan ACC adalah untuk membahagikan bilangan sampel yang betul dengan jumlah sampel Contohnya, jika anda mengambil 10,000 foto untuk pengesanan muka , 10,000 ini Sesetengah foto mempunyai wajah, dan ada yang tidak mempunyai wajah. Kemudian tentukan apakah nisbah yang betul.
Tetapi ada masalah dengan ketepatan ini Jika anda menggunakannya untuk menilai, ia tidak ada kaitan dengan nisbah sampel positif dan negatif, ia tidak mengambil berat tentang ketepatan sampel positif dan ketepatan sampel negatif Apa itu, saya hanya mengambil berat tentang jumlah. Apabila ketepatan model ini adalah 90%, orang lain tidak tahu perbezaan antara sampel positif dan negatif. Termasuk klasifikasi, termasuk regresi, secara amnya, model klasifikasi akan mula-mula menggunakan regresi untuk mendapatkan apa yang dipanggil tahap keyakinan Apabila tahap keyakinan lebih besar daripada nilai tertentu, ia dianggap sebagai, dan kemudian apabila tahap keyakinan adalah kurang daripada nilai yang sama, ia dianggap tidak.
Model statistik ACC boleh laras, iaitu melaraskan tahap keyakinan akan mengubah ketepatan.
Jadi nilai ACC itu sendiri sangat dipengaruhi oleh proporsi sampel, jadi agak bermasalah untuk menggunakannya untuk mencirikan kualiti model Apabila penunjuk ujian mengatakan ia telah mencapai 99.9%, hanya lihat nilai ini, lebih mudah untuk ditipu atau statistik ini berat sebelah. Untuk menyelesaikan masalah ini, lengkung yang dipanggil ROC biasanya digunakan untuk mencirikan ketepatan model ini
lengkung ciri pengendalian penerima ROC
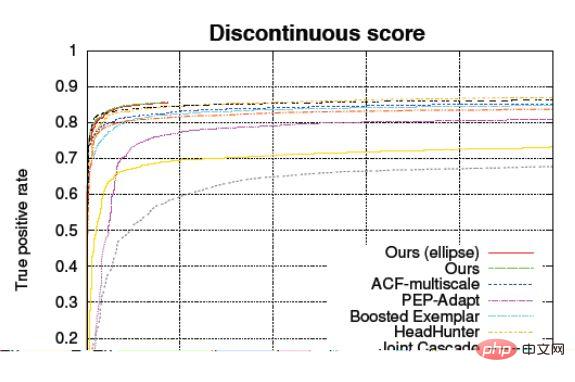
Abscissa: FPR (Kadar Positif Palsu), iaitu kadar ralat sampel negatif
Ordinasi: TPR (Kadar Positif Benar), iaitu kadar sampel positif yang betul
Boleh membezakan algoritma dalam sampel positif dan prestasi pada sampel negatif, dan bentuk lengkung tidak ada kaitan dengan nisbah sampel positif dan negatif.
Keluk ROC (Receiver Operating Characteristic) adalah untuk menandakan absis dan menyelaraskan dengan kadar ralat sampel negatif dan kadar betul sampel positif Dalam kes ini, model yang sama tidak akan dilihat sebagai titik pada graf ini . , atau bukan satu data, tetapi satu baris. Garis ini ialah ambang keyakinan Semakin tinggi anda melaraskannya, semakin ketat ia, dan semakin rendah ia, semakin kurang ketatnya. Di atas ini, ia boleh mencerminkan kesan perubahan dalam ambang keyakinan.
Pada masa hadapan, adalah lebih baik untuk tidak bertanya secara langsung tentang ketepatan anda, tetapi melihat keluk ROC, yang memudahkan untuk menilai keupayaan model.
Penjajaran Muka
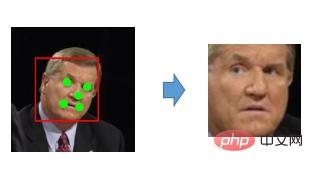
Tujuan penjajaran muka adalah untuk melaraskan tekstur muka ke kedudukan standard sebanyak mungkin dan mengurangkan kesukaran pengecam muka .
Untuk mengurangkan kesukarannya secara buatan, anda boleh menyelaraskannya terlebih dahulu, iaitu, biarkan mata, hidung dan mulut orang yang dikesan semuanya berada dalam kedudukan yang sama Dengan cara ini, model boleh membandingkan Apabila anda mencari, anda hanya perlu mencari objek berhampiran lokasi yang sama Sama ada ia sama atau serupa antara satu sama lain masih sangat berbeza. Jadi kita dapat melakukan langkah penjajaran ini Untuk langkah ini, kaedah yang biasa kita gunakan sekarang ialah kaedah dua dimensi, iaitu mencari titik ciri utama dalam gambar ini. dan lebih daripada enam puluh mata Terdapat semua jenis tempat, termasuk lebih daripada 80 tempat. Tetapi untuk pengecaman muka, lima pada asasnya cukup.
Untuk imej titik lain selain daripada lima titik ini, ia boleh dianggap sebagai melakukan operasi yang serupa dengan interpolasi, dan kemudian menampalnya ke kedudukan itu Selepas ia selesai, ia boleh dihantar ke kemudian Pengecaman muka dilakukan dalam mesin pengecaman muka. Ini adalah pendekatan umum, tetapi terdapat juga pendekatan yang lebih canggih Sesetengah institusi penyelidikan menggunakan apa yang dipanggil penjajaran muka 3D, yang bermaksud saya memberitahu anda rupa muka hadapan, seperti rupa apabila diputar 45. darjah. Jadi selepas melatihnya dengan gambar sebegini, dia akan tahu bahawa apabila saya melihat gambar dipusing 45 darjah ke kiri dan kanan, ia mungkin akan kelihatan seperti apabila ia membelok ke kanan, dan model ini boleh mengagaknya. .
Algoritma pengekstrakan ciri muka
Kaedah tradisional sebelum ini ialah apa yang dipanggil model tekstur tempatan, model tekstur global, model regresi bentuk dan seumpamanya. Apa yang lebih popular sekarang ialah penggunaan rangkaian neural convolutional dalam atau rangkaian neural berulang, atau rangkaian neural convolutional dengan parameter 3DMM. Parameter yang dipanggil 3DMM mempunyai maklumat tiga dimensi di dalamnya, dan kemudian terdapat rangkaian saraf dalam yang melata.
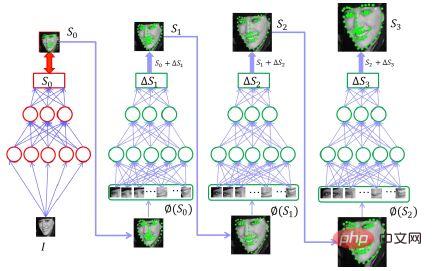
Rangkaian neural mendalam berlatarkan, iaitu, untuk mendapatkan muka, anda mesti membuat kesimpulan pertama kedudukan lima mata Jika anda menggunakan model tunggal, anda mesti melakukan ini di sekali Jika ya, model itu perlu menjadi sangat kompleks.
Tetapi bagaimanakah kita boleh mengurangkan kerumitan model ini?
Iaitu, berbilang input dibuat Selepas input pertama ke dalam rangkaian, tekaan ini adalah tekaan yang boleh diterima dan kurang tepat ia mengetahui di mana lima titik muka manusia. Kemudian letakkan lima mata ini dan imej asal ke dalam rangkaian kedua untuk mendapatkan jumlah pembetulan anggaran Selepas anda mempunyai lima mata asas dan kemudian mencari jumlah pembetulan, ia akan menjadi lebih baik daripada mencari lima mata tepat terus daripada imej asal. Perkara ini lebih mudah sedikit. Oleh itu, menggunakan kaedah penghalusan beransur-ansur dan melata berbilang rangkaian bersama-sama boleh mencapai keseimbangan yang lebih baik antara kelajuan dan ketepatan Malah, apabila kita melakukannya sekarang, kita pada asasnya menggunakan dua lapisan dan ia adalah lebih kurang sama.
Indeks penilaian untuk pengekstrakan titik ciri muka
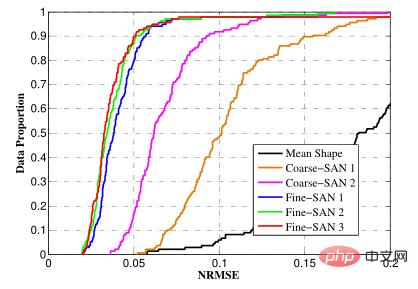
NRMSE (Normalized Root Mean Square Error) ialah punca normal ralat min kuasa dua
Digunakan untuk mengukur perbezaan antara koordinat setiap titik ciri dan koordinat berlabel.
Ketepatan
Untuk membolehkan muka dengan saiz berbeza dibandingkan bersama, apa yang secara statistik dipanggil ralat kuasa dua min punca ternormal digunakan. Sebagai contoh: kita melukis lima mata di atas kertas, dan kemudian biarkan mesin memberitahu jarak antara lima titik ini Semakin dekat nilai yang diberikan dengan jarak sebenar, semakin tepat ramalannya. Secara umumnya, nilai yang diramalkan mestilah agak berat sebelah, jadi bagaimana untuk menyatakan nilai ketepatan ini? Kami biasanya menyatakannya dengan purata atau punca purata nilai kuasa dua jarak. Walau bagaimanapun, masalah timbul Apabila mesin yang sama meramalkan imej dengan saiz yang berbeza, nilai ketepatan akan kelihatan berbeza, kerana semakin besar imej, semakin tinggi nilai ralat mutlak. Prinsip yang sama berlaku untuk muka yang berbeza saiz. Oleh itu, penyelesaian kami adalah dengan mengambil kira saiz asal muka manusia Secara amnya, penyebut ialah jarak antara mata manusia atau jarak pepenjuru muka manusia, dan kemudian bahagikan perbezaan jarak dengan jarak antara mata. atau bahagikan dengan pepenjuru muka, dalam kes ini, anda boleh mendapatkan nilai yang pada dasarnya tidak berubah dengan saiz muka, dan menggunakannya untuk penilaian.
Perbandingan muka
(1) Tujuan: untuk menentukan sama ada dua muka yang sejajar adalah milik orang yang sama
(2) Kesukaran: orang yang sama Muka akan kelihatan berbeza keadaan di bawah keadaan yang berbeza, seperti dipengaruhi terutamanya oleh cahaya, asap, solek, dsb. Yang kedua disebabkan oleh parameter berbeza yang dipetakan kepada foto dua dimensi Yang dipanggil pemetaan kepada parameter dua dimensi bermakna muka asal kelihatan seperti ini Apabila peralatan penangkapan mengambil gambar, sudut yang ditunjukkan kepadanya jarak darinya, dan fokus Sama ada tepat, sudut penangkapan, dan pengumpulan cahaya semuanya mempunyai kesan, yang akan menyebabkan wajah yang sama muncul dalam keadaan yang berbeza. Yang ketiga ialah pengaruh umur dan pembedahan plastik.
Kaedah perbandingan muka
(1) Kaedah tradisional
1 Ekstrak beberapa ciri secara manual seperti HOG, SIFT, transformasi wavelet, dll. , Secara umumnya, ciri yang diekstrak mungkin memerlukan parameter tetap, iaitu, tiada latihan atau pembelajaran diperlukan, algoritma tetap digunakan, dan kemudian ciri tersebut dibandingkan.
(2) Kaedah kedalaman
Kaedah arus perdana ialah kaedah kedalaman, iaitu rangkaian neural convolutional dalam Rangkaian ini biasanya menggunakan DCNN untuk menggantikan yang sebelumnya Kaedah pengekstrakan ciri tersebut adalah untuk mengekstrak beberapa ciri yang berbeza pada gambar atau muka Terdapat banyak parameter dalam DCNN Parameter ini dipelajari, tidak diberitahu oleh orang, ia akan menjadi lebih baik daripada apa yang telah diringkaskan .
Kemudian set ciri yang diperoleh biasanya mempunyai 128 dimensi, 256 dimensi atau 512 dimensi atau 1024 dimensi, dan kemudian membandingkannya untuk menilai jarak antara vektor ciri, jarak Euclidean atau persamaan kosinus biasanya digunakan .
Penunjuk penilaian perbandingan muka juga dibahagikan kepada kelajuan dan ketepatan Kelajuan termasuk masa pengiraan vektor ciri muka tunggal dan kelajuan perbandingan. Ketepatan termasuk ACC dan ROC. Oleh kerana ia telah diperkenalkan sebelum ini, di sini kami memberi tumpuan kepada kelajuan perbandingan.
Perbandingan biasa ialah operasi mudah, iaitu mengira jarak antara dua titik Anda mungkin hanya perlu melakukan produk dalam sekali, iaitu hasil darab dalam dua vektor, tetapi apabila pengecaman muka bertemu 1: N Apabila membandingkan, apabila pangkalan data N adalah sangat besar, apabila anda mendapat foto dan mencarinya dalam pangkalan data N, bilangan carian akan menjadi sangat besar. Contohnya, jika pangkalan data N adalah satu juta, anda mungkin perlu mencari ia satu juta kali ganda bersamaan dengan satu juta perbandingan Pada masa ini, masih terdapat keperluan untuk jumlah masa, jadi akan ada pelbagai teknologi untuk mempercepatkan perbandingan ini.
Algoritma lain yang berkaitan dengan pengecaman muka
Terutamanya termasuk penjejakan muka, penilaian kualiti dan pengecaman badan hidup.
● Penjejakan muka
Dalam senario pengecaman muka video seperti pengawasan, jika keseluruhan proses pengecaman muka dilaksanakan untuk setiap bingkai orang yang sama berjalan, ia bukan sahaja membazirkan sumber pengkomputeran , dan ada kemungkinan beberapa bingkai berkualiti rendah boleh menyebabkan salah pengiktirafan, jadi adalah perlu untuk menentukan wajah yang dimiliki oleh orang yang sama. Dan pilih foto yang sesuai untuk pengecaman, yang sangat meningkatkan prestasi keseluruhan model.
Kini, bukan sahaja penjejakan muka, tetapi juga pelbagai penjejakan objek atau penjejakan kenderaan, dsb., akan menggunakan algoritma penjejakan sedemikian tidak bergantung pada atau tidak akan sentiasa bergantung pada pengesanan. Sebagai contoh, selepas mengesan objek pada mulanya, ia tidak akan mengesannya sama sekali dan hanya menggunakan algoritma penjejakan untuk melakukannya. Pada masa yang sama, untuk mencapai ketepatan yang sangat tinggi dan mengelakkan kehilangan, setiap penjejakan mengambil banyak masa.
Untuk mengelakkan wajah yang dijejaki daripada tidak sepadan dengan julat pengecam muka, secara amnya, pengesan muka akan digunakan untuk pengesanan ini bergantung pada pengesanan muka dan penjejakan kuantitatif boleh mencapai keseimbangan antara kelajuan dan kualiti dalam senario tertentu.
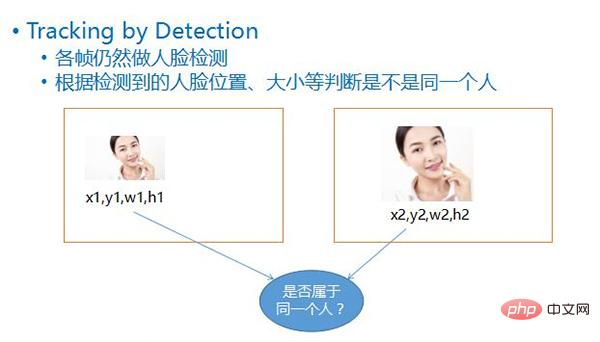
Kaedah pengesanan ini dipanggil Penjejakan melalui Pengesanan, iaitu pengesanan muka masih dilakukan pada setiap bingkai Selepas wajah dikesan, berdasarkan empat nilai setiap muka, Iaitu, kedudukan koordinatnya, lebar dan tingginya, dan dengan membandingkan kedudukan dan saiz muka dalam dua bingkai sebelum dan selepas, secara kasarnya boleh disimpulkan sama ada kedua-dua muka itu tergolong dalam objek bergerak yang sama. .
● Pengesanan skrin penuh selang pilihan
bermakna apabila melakukan Penjejakan melalui Pengesanan, satu cara adalah dengan melakukan pengesanan skrin penuh pada dua bingkai sebelum dan selepas, yang dipanggil penuh- pengesanan skrin Iaitu untuk mengimbas keseluruhan skrin, tetapi kaedah ini sangat memakan masa, jadi kaedah lain kadang-kadang digunakan, iaitu mengimbas keseluruhan skrin setiap beberapa bingkai Secara umumnya, bingkai seterusnya diramalkan, dan kedudukannya tidak berubah terlalu banyak selagi bingkai sebelumnya adalah Jika kedudukan bingkai dikembangkan sedikit ke atas, bawah, kiri, dan kanan, dan dikesan semula, selalunya terdapat kebarangkalian yang tinggi bahawa ia boleh dikesan, dan kebanyakan bingkai boleh dikesan. dilangkau.
Mengapa kita perlu melakukan pengesanan skrin penuh setiap beberapa bingkai?
adalah untuk menghalang objek baharu daripada masuk. Jika anda hanya mencari berdasarkan kedudukan objek sebelumnya, objek baharu mungkin tidak dapat dikesan apabila ia masuk. Untuk mengelakkan situasi ini, anda boleh menunggu lima bingkai . , lakukan pengesanan skrin penuh yang lain selepas sepuluh bingkai.
● Penilaian kualiti muka
Disebabkan oleh had data latihan pengecam muka, dsb., adalah mustahil untuk menunjukkan prestasi yang baik pada wajah di semua negeri Penilaian kualiti akan menilai orang yang dikesan. Mengikut tahap persetujuan antara ciri-ciri muka dan pengecam, hanya muka dengan tahap persetujuan yang tinggi dipilih dan dihantar untuk pengiktirafan untuk meningkatkan prestasi keseluruhan sistem.
Penilaian kualiti wajah merangkumi 4 elemen berikut
① Saiz muka, jika muka terlalu kecil, kesan pengecaman akan sangat berkurangan.
② Postur muka merujuk kepada sudut putaran dalam tiga paksi Secara umumnya, ia berkaitan dengan data yang digunakan untuk latihan pengecam. Jika kebanyakan muka dengan postur kecil digunakan semasa latihan, sebaiknya jangan pilih muka dengan pesongan besar apabila benar-benar melakukan pengecaman, jika tidak, ia tidak akan terpakai.
③ Tahap blur, faktor ini sangat penting Jika foto telah kehilangan maklumat, akan ada masalah dalam pengecaman.
④ Oklusi, jika mata, hidung, dan lain-lain ditutup, ciri-ciri kawasan ini tidak boleh diperolehi, atau ciri-ciri yang diperolehi adalah salah, yang akan memberi kesan kepada yang berikutnya pengiktirafan. Jika ia boleh ditentukan bahawa ia tersumbat, maka buangnya, atau lakukan beberapa pemprosesan khas, seperti tidak memasukkannya ke dalam model pengecaman.
● Pengecaman langsung
Ini adalah masalah yang akan dihadapi oleh semua sistem pengecaman muka Jika hanya wajah dikenali, foto juga boleh ditipu. Bagi mengelakkan sistem daripada diserang, beberapa pertimbangan akan dibuat untuk menentukan sama ada ini muka sebenar atau muka palsu.
Pada asasnya, terdapat tiga kaedah semasa:
① Pengiktirafan dinamik tradisional banyak mesin pengeluaran tunai bank memerlukan sedikit kerjasama daripada pengguna, seperti meminta pengguna untuk berkedip, menoleh, dsb. Ini digunakan untuk menentukan sama ada pengguna telah membuat penyelarasan yang sama dengan mengedipkan mata dan menolehkan kepalanya. Oleh itu, terdapat masalah dengan pengecaman dinamik, iaitu memerlukan banyak kerjasama daripada pengguna, jadi pengalaman pengguna akan menjadi agak teruk.
② Pengiktirafan statik, iaitu, bukan menilai berdasarkan tindakan, tetapi hanya menilai sama ada ia adalah wajah sebenar atau wajah palsu berdasarkan foto itu sendiri. Ia berdasarkan kaedah serangan yang biasa digunakan, yang agak mudah Sebagai contoh, ambil telefon bimbit atau skrin paparan dan gunakan skrin untuk menyerang.
Keupayaan bercahaya skrin jenis ini berbeza daripada keupayaan bercahaya wajah manusia di bawah keadaan pencahayaan sebenar Contohnya, monitor dengan 16 juta warna pemancar tidak dapat mencapai keupayaan bercahaya cahaya yang boleh dilihat, iaitu , kesemuanya adalah berterusan Semua jalur boleh dipancarkan. Oleh itu, apabila merakam skrin jenis ini, berbanding dengan pengimejan utama dalam persekitaran semula jadi yang sebenar, mata manusia juga dapat melihat bahawa akan ada beberapa perubahan dan beberapa keanehan. Selepas meletakkan sifat tidak semulajadi ini sebagai model untuk latihan, anda masih boleh menilai sama ada ia adalah wajah sebenar berdasarkan perbezaan halus ini.
③ Pengecaman stereo, jika anda menggunakan dua kamera atau kamera dengan maklumat kedalaman, anda boleh mengetahui jarak setiap titik yang ditangkap dari kamera, yang bersamaan dengan pengimejan 3D orang, menggunakan satu skrin Apabila saya pergi untuk merakam, skrin mestilah permukaan rata Saya sedar bahawa ia adalah permukaan rata, tetapi permukaan rata itu pastinya bukan orang sebenar. Ini adalah untuk menggunakan kaedah pengecaman tiga dimensi untuk mengecualikan muka rata.
Komposisi sistem pengecaman muka
Mula-mula buat klasifikasi Dari perspektif perbandingan, terdapat sistem pengecaman 1:1 dan sistem pengecaman 1:N dari perspektif objek perbandingan, terdapat foto sistem perbandingan dan sistem perbandingan video mengikut borang penggunaan, terdapat penggunaan peribadi, penggunaan awan atau penggunaan peranti mudah alih.
Sistem pengecaman Foto 1:1
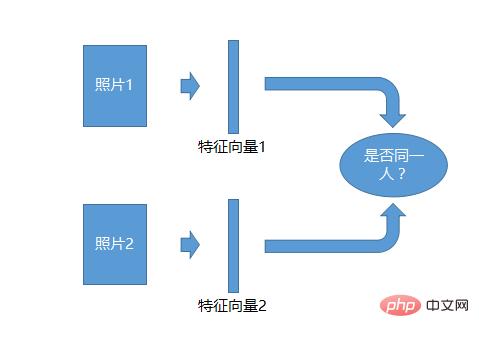
Sistem pengecaman 1:1 adalah yang paling mudah, ambil dua foto dan jana ciri untuk setiap Vektor foto, dan kemudian bandingkan dua vektor ciri untuk melihat sama ada mereka adalah orang yang sama, dan anda boleh mengenal pasti mereka.
Foto 1: Sistem pengecaman N
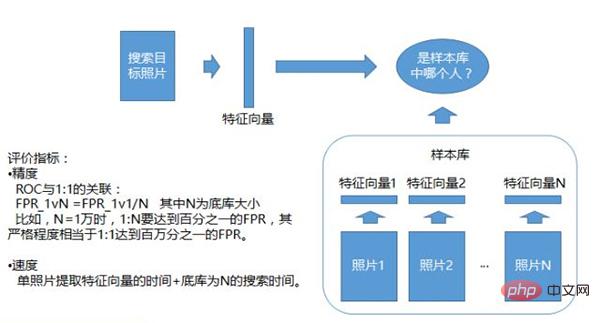
1: Sistem pengecaman N, yang menentukan sama ada bahan foto berada dalam perpustakaan sampel yang sama. Pustaka sampel ini disediakan lebih awal dan mungkin mempunyai senarai putih atau senarai hitam Ia mengandungi foto setiap orang dan satu siri vektor ciri dihasilkan daripada foto ini. Ini digunakan sebagai perpustakaan sampel Foto yang dimuat naik dibandingkan dengan semua ciri dalam perpustakaan sampel untuk melihat yang mana satu yang paling serupa dengan orang tersebut.
Sistem pengecaman Video 1:1
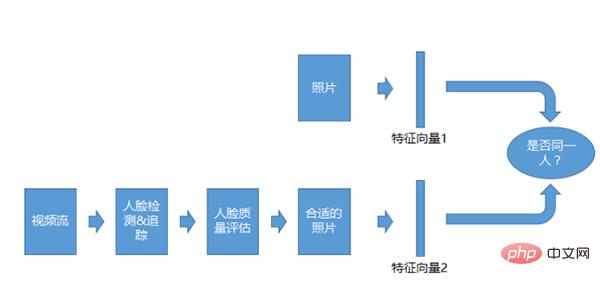
Sistem pengecaman Video 1:1 adalah serupa dengan sistem foto 1:1, tetapi objek perbandingan tidak Foto, tetapi strim video. Selepas mendapat strim video, kami akan melakukan pengesanan, penjejakan dan penilaian kualiti, dan kemudian kami akan membandingkannya selepas kami mendapat foto yang sesuai.
Video 1: Sistem pengecaman N
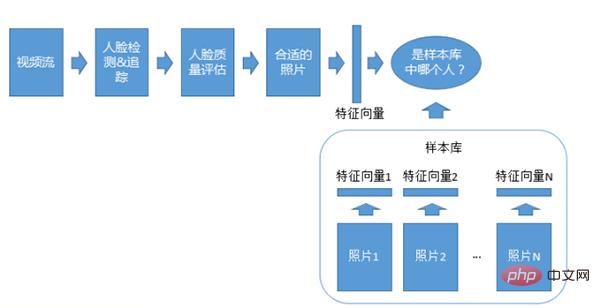
Video 1: Sistem penyesuaian N adalah serupa dengan sistem foto 1:N, tetapi digunakan untuk pengecaman Apa yang penting ialah penstriman video, yang juga memerlukan pengesanan, penjejakan dan penilaian kualiti.
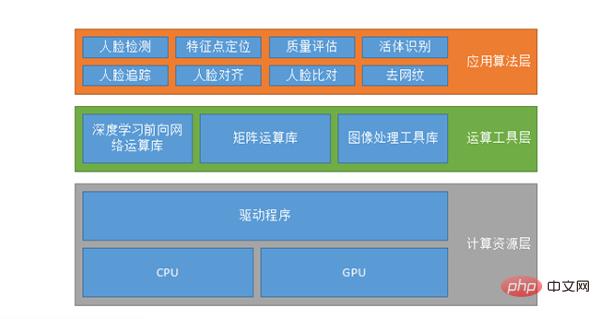
Konfigurasi sistem yang dipanggil tidak semestinya sistem pengecaman muka, ia mungkin sama untuk pelbagai sistem AI. Yang pertama ialah lapisan sumber pengkomputeran, yang berjalan pada CPU atau GPU yang berjalan pada GPU juga mungkin mempunyai sokongan untuk CUDA, CUDN, dsb.
Yang kedua ialah lapisan alat pengkomputeran, termasuk perpustakaan pengkomputeran rangkaian ke hadapan pembelajaran mendalam, perpustakaan pengkomputeran matriks dan pustaka alat pemprosesan imej. Memandangkan adalah mustahil untuk semua orang yang membuat algoritma menulis operasi data mereka sendiri, mereka akan menggunakan beberapa pustaka operasi data sedia ada, seperti TensorFlow, MXNET atau Caffe, dsb., atau mereka boleh menulis set mereka sendiri.
Atas ialah kandungan terperinci Artikel panjang 10,000 perkataan, sains popular tentang algoritma dan sistem pengecaman muka. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI