
Rumah >pembangunan bahagian belakang >Tutorial Python >Gunakan Python untuk menganalisis 1.4 bilion keping data
Gunakan Python untuk menganalisis 1.4 bilion keping data

- PHPzke hadapan
- 2023-04-12 22:19:251828semak imbas

Google Ngram viewer ialah alat yang menyeronokkan dan berguna yang menggunakan khazanah besar data Google yang diimbas daripada buku untuk merancang perubahan dalam penggunaan perkataan dari semasa ke semasa. Sebagai contoh, perkataan Python (sensitif huruf besar/kecil):
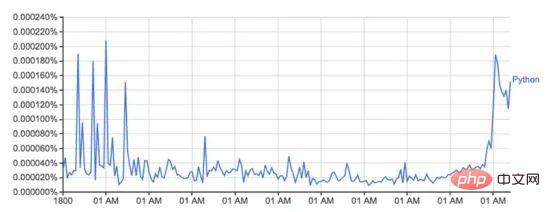
Graf dari: books.google.com/ngrams… menggambarkan penggunaan perkataan 'Python' Berubah dari semasa ke semasa .
Ia dikuasakan oleh set data n-gram Google, yang merekodkan penggunaan perkataan atau frasa tertentu dalam Buku Google untuk setiap tahun buku itu dicetak. Walau bagaimanapun, ini tidak lengkap (ia tidak termasuk setiap buku yang pernah diterbitkan!), terdapat berjuta-juta buku dalam set data, merangkumi tempoh dari abad ke-16 hingga 2008. Set data boleh dimuat turun secara percuma dari sini.
Saya memutuskan untuk menggunakan Python dan perpustakaan pemuatan data baharu saya PyTubes untuk melihat betapa mudahnya untuk menjana semula plot di atas.
Cabaran
Set data 1 gram boleh dikembangkan kepada 27 Gb data pada cakera keras, iaitu sejumlah besar data apabila dibaca ke dalam python. Python boleh memproses gigabait data dengan mudah pada satu masa, tetapi apabila data rosak dan diproses, ia menjadi lebih perlahan dan kurang cekap memori.
Secara keseluruhan, 1.4 bilion keping data ini (1,430,727,243) bertaburan di 38 fail sumber, dengan jumlah 24 juta (24,359,460) perkataan (dan teg sebahagian daripada ucapan, lihat di bawah), dikira daripada 1505-2008.
Ia perlahan dengan cepat apabila memproses 1 bilion baris data. Dan Python asli tidak dioptimumkan untuk mengendalikan aspek data ini. Nasib baik, numpy benar-benar pandai mengendalikan sejumlah besar data. Menggunakan beberapa helah mudah, kita boleh membuat analisis ini boleh dilaksanakan menggunakan numpy.
Mengendalikan rentetan dalam python/numpy adalah rumit. Overhed memori rentetan dalam python adalah penting, dan numpy hanya boleh mengendalikan rentetan yang diketahui dan panjang tetap. Disebabkan keadaan ini, kebanyakan perkataan mempunyai panjang yang berbeza, jadi ini tidak sesuai.
Memuatkan data
Semua kod/contoh di bawah dijalankan pada Macbook Pro 2016 dengan 8 GB RAM. Jika perkakasan atau contoh awan mempunyai konfigurasi ram yang lebih baik, prestasi akan menjadi lebih baik.
Data 1-gram disimpan dalam fail dalam bentuk tab-delimited form, yang kelihatan seperti berikut:

Setiap sekeping data mengandungi medan berikut :
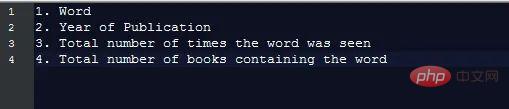
Untuk menjana carta seperti yang diperlukan, kami hanya perlu mengetahui maklumat ini, iaitu:

Dengan mengekstrak Maklumat ini, kos tambahan untuk memproses data rentetan panjang yang berbeza diabaikan, tetapi kita masih perlu membandingkan nilai rentetan yang berbeza untuk membezakan baris data mana yang mempunyai medan yang kita minati. Inilah yang boleh dilakukan oleh pytubes:
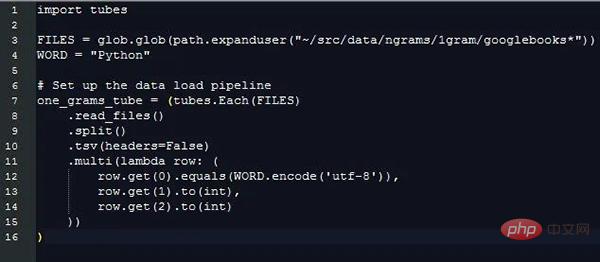
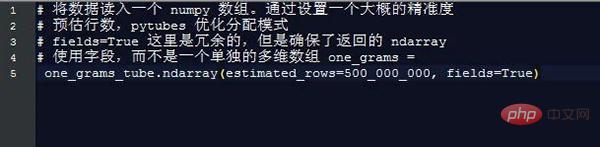
Selepas hampir 170 saat (3 minit), one_grams ialah tatasusunan numpy yang mengandungi hampir 1.4 bilion baris daripada data, kelihatan seperti ini (menambah pengepala jadual untuk ilustrasi):
╒═══════════╤════════␐═══════════ ═/ ══╪═══ ══════╡
│ 0 │ 1799 │ 2 │
“└“>“│ ───┼── - ─────┼ ──────────┼─ ────────┤│ 0 │ 1805 ────────┤│ 0 │ 1805 ││ │ ────── ─┼─────────┼ ─────────┤│ 0 │┼│ 1811 │─ ────── ──┼───────── ┼─────────┤│ 0 ││Dari sini, anda hanya perlu menggunakan kaedah numpy untuk mengira sesuatu:
Jumlah penggunaan perkataan dalam setiap tahun
Google menunjukkan peratusan kejadian setiap perkataan (bilangan kali a perkataan muncul pada tahun ini / jumlah bilangan kali semua perkataan muncul pada tahun ini), yang lebih berguna daripada hanya mengira perkataan asal. Untuk mengira peratusan ini, kita perlu mengetahui jumlah bilangan perkataan.
Nasib baik, numpy menjadikannya sangat mudah:
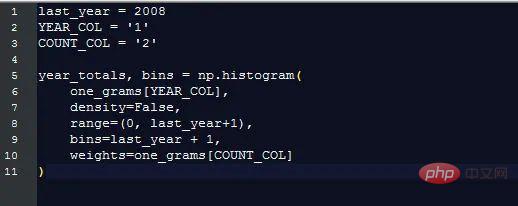
Plot graf ini untuk menunjukkan bilangan perkataan yang dikumpulkan Google setiap tahun:
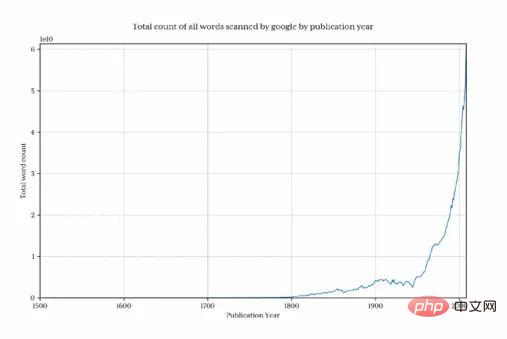
Adalah jelas bahawa sebelum tahun 1800, jumlah data menurun dengan cepat, sekali gus memesongkan keputusan akhir dan menyembunyikan corak minat. Untuk mengelakkan masalah ini, kami hanya mengimport data selepas 1800:
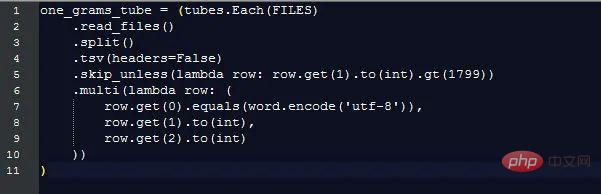
Ini mengembalikan 1.3 bilion baris data (hanya 3.7% sebelum 1800)
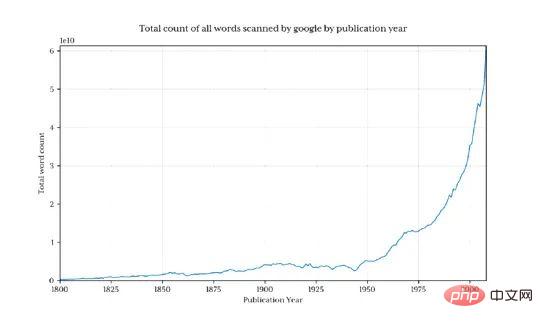
Peratusan Python dalam setiap tahun
Mendapatkan peratusan Python dalam setiap tahun kini amat mudah.
Gunakan helah mudah untuk mencipta tatasusunan berdasarkan tahun Panjang elemen 2008 bermakna indeks setiap tahun adalah sama dengan bilangan tahun, contohnya, 1995 mendapat unsur 1995. .
Tiada satu pun perkara ini patut dilakukan dengan numpy:

Memplot hasil bilangan_perkataan:

Bentuknya kelihatan hampir sama dengan versi Google
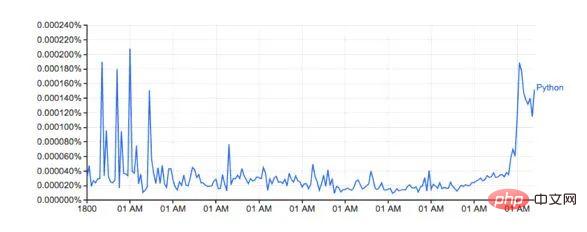
Peratusan sebenar tidak sepadan kerana set data yang dimuat turun mengandungi perkataan yang berbeza (Contohnya: Python_VERB ). Set data ini tidak dijelaskan dengan baik di halaman google dan menimbulkan beberapa soalan:
Bagaimanakah kita menggunakan Python sebagai kata kerja?
Adakah jumlah pengiraan 'Python' termasuk 'Python_VERB'? dan lain-lain.
Nasib baik, kita semua tahu bahawa kaedah yang saya gunakan menghasilkan ikon yang kelihatan sangat serupa dengan Google, dan arah aliran yang berkaitan tidak terjejas, jadi untuk penerokaan ini, saya tidak akan cuba membetulkannya .
Prestasi
Google menjana imej dalam masa sekitar 1 saat, yang munasabah berbanding 8 minit untuk skrip ini. Bahagian belakang kiraan perkataan Google berfungsi daripada paparan eksplisit set data yang disediakan.
Sebagai contoh, mengira jumlah penggunaan perkataan untuk tahun sebelumnya terlebih dahulu dan menyimpannya dalam jadual carian berasingan boleh menjimatkan masa dengan ketara. Begitu juga, mengekalkan penggunaan perkataan dalam pangkalan data/fail yang berasingan dan kemudian mengindeks lajur pertama akan menghapuskan hampir semua masa pemprosesan.
Penjelajahan ini benar-benar menunjukkan bahawa menggunakan numpy dan pytubes yang masih baru dengan perkakasan komoditi standard dan Python, adalah mungkin untuk memuatkan, memproses dan mengekstrak statistik sewenang-wenangnya daripada set data bilion baris dalam jumlah masa yang munasabah.
Perang Bahasa
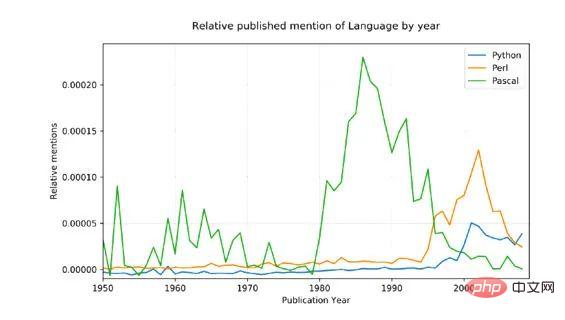
Untuk menunjukkan konsep ini dengan contoh yang lebih kompleks, saya memutuskan untuk membandingkan tiga bahasa pengaturcaraan yang disebut: Python, Pascal dan Perl
Sumbernya data adalah bising (ia mengandungi semua perkataan Inggeris yang digunakan, bukan hanya menyebut bahasa pengaturcaraan, dan, sebagai contoh, python mempunyai makna bukan teknikal juga!), jadi untuk menyesuaikannya, Kami telah melakukan dua perkara:
Hanya bentuk nama dengan huruf besar dipadankan (Python, bukan python)
Jumlah bilangan sebutan bagi setiap bahasa telah ditukar daripada 1800 kepada Purata peratusan untuk tahun 1960, yang sepatutnya memberikan garis dasar yang munasabah memandangkan Pascal adalah pertama kali disebut pada tahun 1970.
Keputusan:
Berbanding dengan Google (tanpa sebarang pelarasan garis dasar):
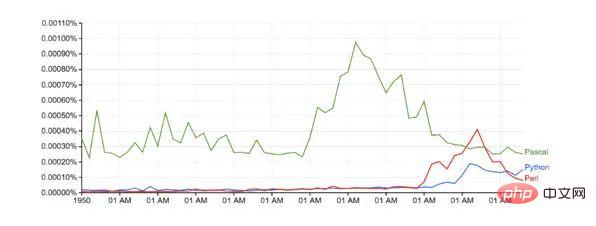
Masa larian: hanya lebih 10 minit
Peningkatan PyTubes Masa Depan
Pada peringkat ini, pytubes hanya mempunyai konsep integer tunggal, iaitu 64 bit. Ini bermakna tatasusunan numpy yang dijana oleh pytubes menggunakan i8 dtypes untuk semua integer. Di sesetengah tempat (seperti data ngrams), integer 8-bit agak berlebihan dan membazirkan memori (jumlah ndarray ialah 38Gb, dtypes boleh mengurangkan ini sebanyak 60%) dengan mudah. Saya bercadang untuk menambah beberapa sokongan integer tahap 1, 2 dan 4 bit ( github.com/stestagg/py… )
Lebih logik penapisan - Tube.skip_unless() ialah kaedah baris penapis yang agak mudah, tetapi tidak mempunyai keupayaan untuk menggabungkan keadaan (DAN/ATAU/TIDAK). Ini boleh mengurangkan saiz data yang dimuatkan dengan lebih cepat dalam beberapa kes penggunaan.
Padanan rentetan yang lebih baik - ujian mudah seperti: bermula dengan, berakhir dengan, mengandungi dan adalah_satu_daripada boleh ditambah dengan mudah untuk meningkatkan keberkesanan pemuatan data rentetan dengan ketara.
Atas ialah kandungan terperinci Gunakan Python untuk menganalisis 1.4 bilion keping data. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!