
Rumah >pembangunan bahagian belakang >Tutorial Python >Satu baris kod Python untuk mencapai keselarian
Satu baris kod Python untuk mencapai keselarian

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-12 19:04:29973semak imbas

Python mempunyai reputasi yang agak buruk apabila ia berkaitan dengan penyelarasan program. Mengetepikan isu teknikal, seperti pelaksanaan benang dan GIL, saya merasakan bimbingan pengajaran yang salah adalah masalah utama. Tutorial berbilang benang dan pelbagai proses Python klasik biasa cenderung "berat". Dan ia sering mencalarkan permukaan tanpa mendalami kandungan yang paling berguna dalam kerja harian.
Contoh tradisional
Cari mudah untuk "Tutorial berbilang benang Python", tidak sukar untuk mencari hampir semua tutorial Kedua-duanya memberikan contoh yang melibatkan kelas dan baris gilir :
import os
import PIL
from multiprocessing import Pool
from PIL import Image
SIZE = (75,75)
SAVE_DIRECTORY = 'thumbs'
def get_image_paths(folder):
return (os.path.join(folder, f)
for f in os.listdir(folder)
if 'jpeg' in f)
def create_thumbnail(filename):
im = Image.open(filename)
im.thumbnail(SIZE, Image.ANTIALIAS)
base, fname = os.path.split(filename)
save_path = os.path.join(base, SAVE_DIRECTORY, fname)
im.save(save_path)
if __name__ == '__main__':
folder = os.path.abspath(
'11_18_2013_R000_IQM_Big_Sur_Mon__e10d1958e7b766c3e840')
os.mkdir(os.path.join(folder, SAVE_DIRECTORY))
images = get_image_paths(folder)
pool = Pool()
pool.map(creat_thumbnail, images)
pool.close()
pool.join()
Ha, ia kelihatan seperti Java, bukan?
Saya tidak mengatakan bahawa menggunakan model pengeluar/pengguna untuk tugasan berbilang benang/berbilang proses adalah salah (malah, model ini ada tempatnya). Walau bagaimanapun, kita boleh menggunakan model yang lebih cekap apabila berurusan dengan tugasan skrip harian.
Masalahnya...
Pertama, anda memerlukan kelas boilerplate
Kedua, anda perlukan barisan Untuk melepasi objek;
Selain itu, anda juga perlu membina kaedah yang sepadan pada kedua-dua hujung saluran untuk membantu kerjanya (jika anda perlu menjalankan komunikasi dua hala atau menyimpan hasilnya, anda perlu memperkenalkan barisan).
Semakin ramai pekerja, semakin banyak masalah
Mengikut garis pemikiran ini, anda kini memerlukan rangkaian pekerja benang Kolam. Berikut ialah contoh daripada tutorial IBM klasik - pecutan melalui berbilang benang apabila mendapatkan semula halaman web.
#Example2.py
'''
A more realistic thread pool example
'''
import time
import threading
import Queue
import urllib2
class Consumer(threading.Thread):
def __init__(self, queue):
threading.Thread.__init__(self)
self._queue = queue
def run(self):
while True:
content = self._queue.get()
if isinstance(content, str) and content == 'quit':
break
response = urllib2.urlopen(content)
print 'Bye byes!'
def Producer():
urls = [
'http://www.python.org', 'http://www.yahoo.com'
'http://www.scala.org', 'http://www.google.com'
# etc..
]
queue = Queue.Queue()
worker_threads = build_worker_pool(queue, 4)
start_time = time.time()
# Add the urls to process
for url in urls:
queue.put(url)
# Add the poison pillv
for worker in worker_threads:
queue.put('quit')
for worker in worker_threads:
worker.join()
print 'Done! Time taken: {}'.format(time.time() - start_time)
def build_worker_pool(queue, size):
workers = []
for _ in range(size):
worker = Consumer(queue)
worker.start()
workers.append(worker)
return workers
if __name__ == '__main__':
Producer()
Kod ini berfungsi dengan betul, tetapi lihat dengan lebih dekat apa yang perlu kita lakukan: membina kaedah yang berbeza, menjejaki satu siri benang dan menyelesaikan masalah yang menjengkelkan Untuk masalah kebuntuan, kita perlu melakukan beberapa siri operasi bergabung. Ini baru permulaan...
Setakat ini kami telah menyemak tutorial multi-threading klasik, yang agak kosong, bukan? Rebus dan terdedah kepada kesilapan, gaya ini mendapat hasil dua kali ganda dengan separuh usaha jelas tidak sesuai untuk kegunaan harian Mujurlah, kami mempunyai cara yang lebih baik.
Mengapa tidak mencuba peta
peta Fungsi kecil dan indah ini adalah kunci untuk menyelaraskan atur cara Python dengan mudah. Peta berasal daripada bahasa pengaturcaraan berfungsi seperti Lisp. Ia boleh mencapai pemetaan antara dua fungsi melalui urutan.
urls = ['http://www.yahoo.com', 'http://www.reddit.com']
results = map(urllib2.urlopen, urls)
Dua baris kod di atas menghantar setiap elemen dalam jujukan url sebagai parameter kepada kaedah urlopen dan simpan semua hasil ke senarai hasil . Hasilnya kira-kira bersamaan dengan:
results = []
for url in urls:
results.append(urllib2.urlopen(url))
Fungsi peta secara bersendirian mengendalikan siri operasi seperti operasi jujukan, hantaran parameter dan storan hasil.
Mengapa ini penting? Ini kerana operasi peta boleh disejajarkan dengan mudah dengan perpustakaan yang betul.
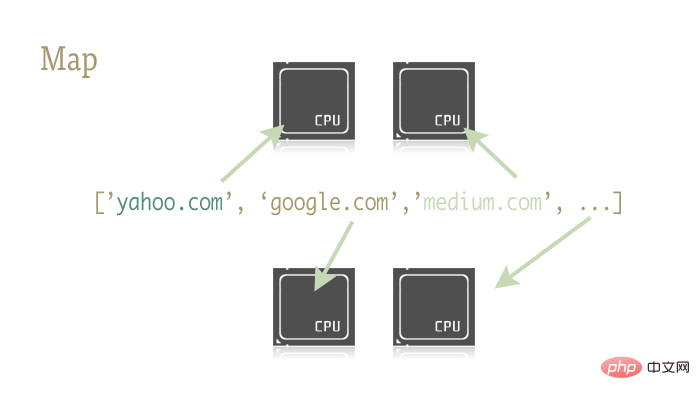
Terdapat dua perpustakaan dalam Python yang mengandungi fungsi peta: multiprocessing dan sub-library multiprocessing .dummy yang kurang dikenali. .
Beberapa perkataan lagi di sini: multiprocessing.dummy? Klon berulir perpustakaan mltiprocessing? Adakah ini udang? Malah dalam dokumentasi rasmi perpustakaan berbilang pemprosesan, hanya terdapat satu huraian yang relevan tentang sub perpustakaan ini. Dan penerangan ini diterjemahkan ke dalam bahasa dewasa pada asasnya bermaksud: "Nah, ada perkara seperti itu, ketahuilah, perpustakaan ini sangat dipandang remeh!"
dummy ialah klon lengkap modul multiprocessing, satu-satunya perbezaan ialah multiprocessing berfungsi pada proses, manakala modul dummy berfungsi pada thread (dan dengan itu termasuk semua batasan multithreading biasa Python) .
Jadi sangat mudah untuk menggantikan kedua-dua perpustakaan ini. Anda boleh memilih perpustakaan yang berbeza untuk tugas intensif IO dan tugas intensif CPU.
Cubalah
Gunakan dua baris kod berikut untuk merujuk perpustakaan yang mengandungi fungsi peta selari:
from multiprocessing import Pool from multiprocessing.dummy import Pool as ThreadPool
Segera objek Pool:
pool = ThreadPool()
Pernyataan mudah ini menggantikan binaanpekerjaFungsi pool berfungsi dalam 7 baris kod. Ia menghasilkan satu siri benang pekerja dan memulakannya, menyimpannya dalam pembolehubah untuk akses mudah.
Objek Pool mempunyai beberapa parameter yang perlu saya fokuskan di sini ialah parameter pertamanya: proses Parameter ini digunakan untuk menetapkan bilangan utas dalam kumpulan benang. Nilai lalainya ialah bilangan teras CPU mesin semasa.
Secara umumnya, apabila melakukan tugasan intensif CPU, semakin banyak teras yang anda panggil, semakin pantas ia akan berlaku. Tetapi apabila menangani tugas intensif rangkaian, perkara menjadi tidak dapat diramalkan, dan adalah bijak untuk mencuba untuk menentukan saiz kumpulan benang.
pool = ThreadPool(4) # Sets the pool size to 4
线程数过多时,切换线程所消耗的时间甚至会超过实际工作时间。对于不同的工作,通过尝试来找到线程池大小的最优值是个不错的主意。
创建好 Pool 对象后,并行化的程序便呼之欲出了。我们来看看改写后的 example2.py
import urllib2
from multiprocessing.dummy import Pool as ThreadPool
urls = [
'http://www.python.org',
'http://www.python.org/about/',
'http://www.onlamp.com/pub/a/python/2003/04/17/metaclasses.html',
'http://www.python.org/doc/',
'http://www.python.org/download/',
'http://www.python.org/getit/',
'http://www.python.org/community/',
'https://wiki.python.org/moin/',
'http://planet.python.org/',
'https://wiki.python.org/moin/LocalUserGroups',
'http://www.python.org/psf/',
'http://docs.python.org/devguide/',
'http://www.python.org/community/awards/'
# etc..
]
# Make the Pool of workers
pool = ThreadPool(4)
# Open the urls in their own threads
# and return the results
results = pool.map(urllib2.urlopen, urls)
#close the pool and wait for the work to finish
pool.close()
pool.join()
实际起作用的代码只有 4 行,其中只有一行是关键的。map 函数轻而易举的取代了前文中超过 40 行的例子。为了更有趣一些,我统计了不同方法、不同线程池大小的耗时情况。
# results = [] # for url in urls: # result = urllib2.urlopen(url) # results.append(result) # # ------- VERSUS ------- # # # ------- 4 Pool ------- # # pool = ThreadPool(4) # results = pool.map(urllib2.urlopen, urls) # # ------- 8 Pool ------- # # pool = ThreadPool(8) # results = pool.map(urllib2.urlopen, urls) # # ------- 13 Pool ------- # # pool = ThreadPool(13) # results = pool.map(urllib2.urlopen, urls)
结果:
# Single thread: 14.4 Seconds # 4 Pool: 3.1 Seconds # 8 Pool: 1.4 Seconds # 13 Pool: 1.3 Seconds
很棒的结果不是吗?这一结果也说明了为什么要通过实验来确定线程池的大小。在我的机器上当线程池大小大于 9 带来的收益就十分有限了。
另一个真实的例子
生成上千张图片的缩略图
这是一个 CPU 密集型的任务,并且十分适合进行并行化。
基础单进程版本
import os
import PIL
from multiprocessing import Pool
from PIL import Image
SIZE = (75,75)
SAVE_DIRECTORY = 'thumbs'
def get_image_paths(folder):
return (os.path.join(folder, f)
for f in os.listdir(folder)
if 'jpeg' in f)
def create_thumbnail(filename):
im = Image.open(filename)
im.thumbnail(SIZE, Image.ANTIALIAS)
base, fname = os.path.split(filename)
save_path = os.path.join(base, SAVE_DIRECTORY, fname)
im.save(save_path)
if __name__ == '__main__':
folder = os.path.abspath(
'11_18_2013_R000_IQM_Big_Sur_Mon__e10d1958e7b766c3e840')
os.mkdir(os.path.join(folder, SAVE_DIRECTORY))
images = get_image_paths(folder)
for image in images:
create_thumbnail(Image)
上边这段代码的主要工作就是将遍历传入的文件夹中的图片文件,一一生成缩略图,并将这些缩略图保存到特定文件夹中。
这我的机器上,用这一程序处理 6000 张图片需要花费 27.9 秒。
如果我们使用 map 函数来代替 for 循环:
import os
import PIL
from multiprocessing import Pool
from PIL import Image
SIZE = (75,75)
SAVE_DIRECTORY = 'thumbs'
def get_image_paths(folder):
return (os.path.join(folder, f)
for f in os.listdir(folder)
if 'jpeg' in f)
def create_thumbnail(filename):
im = Image.open(filename)
im.thumbnail(SIZE, Image.ANTIALIAS)
base, fname = os.path.split(filename)
save_path = os.path.join(base, SAVE_DIRECTORY, fname)
im.save(save_path)
if __name__ == '__main__':
folder = os.path.abspath(
'11_18_2013_R000_IQM_Big_Sur_Mon__e10d1958e7b766c3e840')
os.mkdir(os.path.join(folder, SAVE_DIRECTORY))
images = get_image_paths(folder)
pool = Pool()
pool.map(creat_thumbnail, images)
pool.close()
pool.join()
5.6 秒!
虽然只改动了几行代码,我们却明显提高了程序的执行速度。在生产环境中,我们可以为 CPU 密集型任务和 IO 密集型任务分别选择多进程和多线程库来进一步提高执行速度——这也是解决死锁问题的良方。此外,由于 map 函数并不支持手动线程管理,反而使得相关的 debug 工作也变得异常简单。
到这里,我们就实现了(基本)通过一行 Python 实现并行化。
译者:caspar
译文:https://www.php.cn/link/687fe34a901a03abed262a62e22f90dbm/a/1190000000414339
原文:https://medium.com/building-things-on-the-internet/40e9b2b36148
Atas ialah kandungan terperinci Satu baris kod Python untuk mencapai keselarian. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!