
Rumah >pembangunan bahagian belakang >Tutorial Python >30 pakej Python penting untuk kejuruteraan data
30 pakej Python penting untuk kejuruteraan data

- PHPzke hadapan
- 2023-04-12 16:58:072048semak imbas
Python boleh dikatakan sebagai bahasa pengaturcaraan yang paling mudah untuk dimulakan Dengan bantuan pakej asas seperti numpy dan scipy, Python boleh dikatakan sebagai bahasa terbaik pada masa ini untuk pemprosesan data dan pembelajaran mesin Terima kasih kepada semua pakar dan Python yang bersemangat mempunyai komuniti besar penyumbang yang menyokong pembangunan teknologi, dengan dua pelbagai pakej Python dibangunkan untuk membantu saintis data dalam kerja mereka.

Dalam artikel ini, kami akan memperkenalkan beberapa pakej Python yang sangat unik dan mudah digunakan yang boleh membantu anda membina aliran kerja data dalam pelbagai cara.
1. Knockknock
Knockknock ialah pakej Python ringkas yang memberitahu anda apabila latihan model pembelajaran mesin tamat atau ranap. Kami boleh mendapatkan pemberitahuan melalui berbilang saluran, seperti e-mel, Slack, Microsoft Teams, dsb.
Untuk memasang pakej, kami menggunakan kod berikut.
pip install knockknock
Sebagai contoh, kita boleh menggunakan kod berikut untuk memberitahu status latihan pemodelan pembelajaran mesin ke alamat e-mel yang ditentukan.
from knockknock import email_senderfrom sklearn.linear_model import LinearRegressionimport numpy as np@email_sender(recipient_emails=["<your_email@address.com>", "<your_second_email@address.com>"], sender_email="<sender_email@gmail.com>")def train_linear_model(your_nicest_parameters):x = np.array([[1, 1], [1, 2], [2, 2], [2, 3]])y = np.dot(x, np.array([1, 2])) + 3 regression = LinearRegression().fit(x, y)return regression.score(x, y)
Dengan cara ini anda boleh dimaklumkan apabila fungsi mengalami masalah atau selesai.
2. tqdm
Apabila lelaran atau gelung diperlukan, jika anda perlu memaparkan bar kemajuan Maka tqdm adalah apa yang anda perlukan? Pakej ini akan menyediakan meter kemajuan mudah dalam buku nota atau gesaan arahan anda.
Mari mulakan dengan memasang pakej.
pip install tqdm
Anda kemudian boleh menggunakan kod berikut untuk memaparkan bar kemajuan semasa gelung.
from tqdm import tqdmq = 0for i in tqdm(range(10000000)):q = i +1
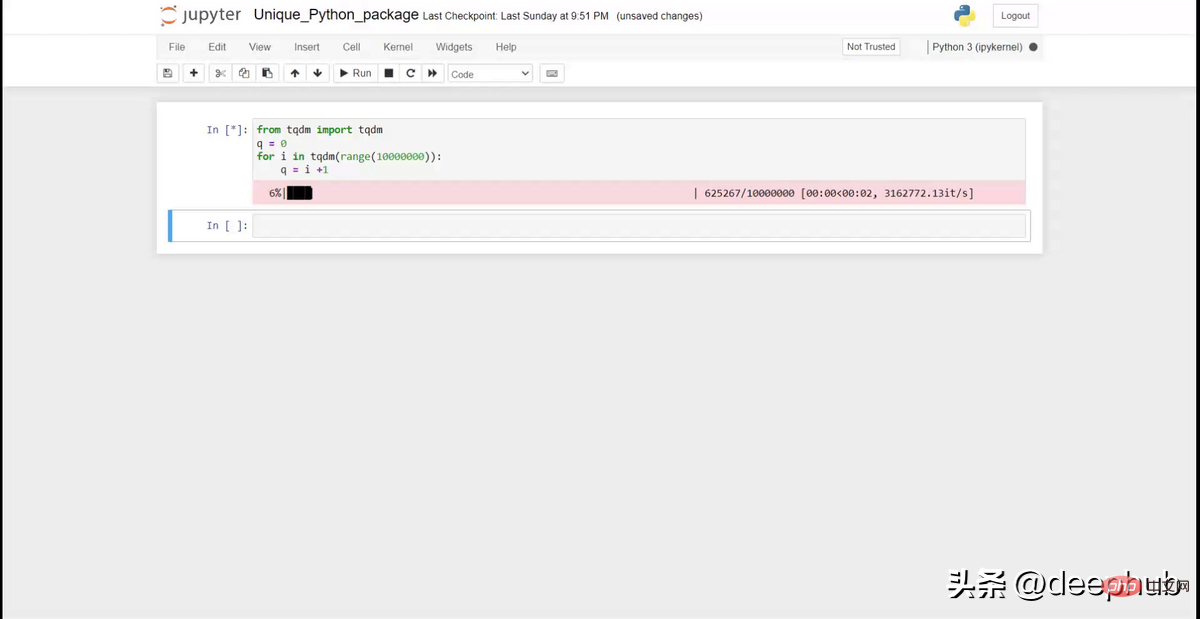
Sama seperti gifg di atas, ia boleh memaparkan bar kemajuan yang bagus pada buku nota. Ia berguna apabila anda mempunyai lelaran yang kompleks dan ingin menjejaki kemajuan.
3. Pandas-log
Panda -log boleh memberikan maklum balas tentang operasi asas Panda, seperti .query, .drop, .merge, dsb. Ia berdasarkan Tidyverse R dan boleh digunakan untuk memahami semua langkah analisis data.
Pasang pakej
pip install pandas-log
Selepas memasang pakej, lihat contoh di bawah.
import pandas as pdimport numpy as npimport pandas_logdf = pd.DataFrame({"name": ['Alfred', 'Batman', 'Catwoman'],"toy": [np.nan, 'Batmobile', 'Bullwhip'],"born": [pd.NaT, pd.Timestamp("1940-04-25"), pd.NaT]})Kemudian mari kita cuba menggunakan kod berikut untuk membuat rekod operasi panda yang mudah.
with pandas_log.enable():res = (df.drop("born", axis = 1).groupby('name'))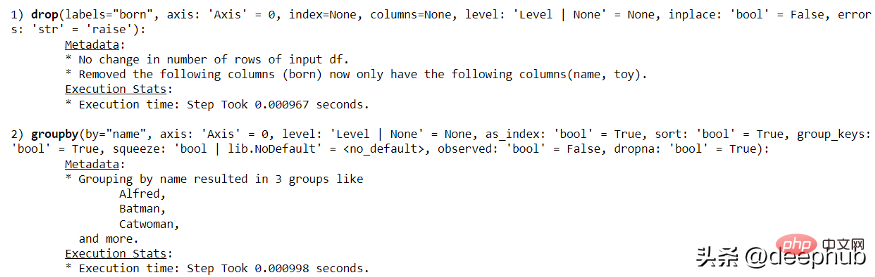
Melalui panda-log, kami boleh mendapatkan semua maklumat pelaksanaan.
4. Emoji
Seperti namanya, Emoji ialah pakej Python yang menyokong penghuraian teks emoji. Biasanya, sukar untuk kami mengendalikan emoji dalam Python, tetapi pakej Emoji boleh membantu kami dengan penukaran.
Gunakan kod berikut untuk memasang pakej Emoji.
pip install emoji
Lihat kod berikut:
import emojiprint(emoji.emojize('Python is :thumbs_up:'))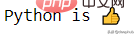
Dengan pakej ini, anda boleh mengeluarkan emotikon dengan mudah.
5. TheFuzz
TheFuzz menggunakan jarak Levenshtein untuk memadankan teks untuk mengira persamaan.
pip install thefuzz
Kod berikut menerangkan cara menggunakan TheFuzz untuk pemadanan teks persamaan.
from thefuzz import fuzz, process#Testing the score between two sentencesfuzz.ratio("Test the word", "test the Word!")
TheFuzz juga boleh mengeluarkan skor persamaan daripada berbilang perkataan secara serentak.
choices = ["Atlanta Falcons", "New York Jets", "New York Giants", "Dallas Cowboys"]process.extract("new york jets", choices, limit=2)
TheFuzz sesuai untuk sebarang pengesanan persamaan data teks, kerja ini sangat penting dalam nlp.
6. Numerizer
Numerizer boleh menukar teks berangka bertulis kepada integer atau nombor terapung yang sepadan.
pip install numerizer
Kemudian mari cuba beberapa input untuk ditukar.
from numerizer import numerizenumerize('forty two')
Ia juga akan berfungsi jika anda menggunakan gaya penulisan lain.
numerize('forty-two')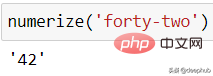
numerize('nine and three quarters')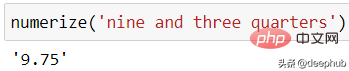
Jika input bukan ungkapan angka, maka ia akan dikekalkan:
numerize('maybe around nine and three quarters')
7、PyAutoGUI
PyAutoGUI 可以自动控制鼠标和键盘。
pip install pyautogui
然后我们可以使用以下代码测试。
import pyautoguipyautogui.moveTo(10, 15)pyautogui.click()pyautogui.doubleClick()pyautogui.press('enter')上面的代码会将鼠标移动到某个位置并单击鼠标。 当需要重复操作(例如下载文件或收集数据)时,非常有用。
8、Weightedcalcs
Weightedcalcs 用于统计计算。 用法从简单的统计数据(例如加权平均值、中位数和标准变化)到加权计数和分布等。
pip install weightedcalcs
使用可用数据计算加权分布。
import seaborn as snsdf = sns.load_dataset('mpg')import weightedcalcs as wccalc = wc.Calculator("mpg")然后我们通过传递数据集并计算预期变量来进行加权计算。
calc.distribution(df, "origin")

9、scikit-posthocs
scikit-posthocs 是一个用于“事后”测试分析的 python 包,通常用于统计分析中的成对比较。 该软件包提供了简单的类似 scikit-learn API 来进行分析。
pip install scikit-posthocs
然后让我们从简单的数据集开始,进行 ANOVA 测试。
import statsmodels.api as saimport statsmodels.formula.api as sfaimport scikit_posthocs as spdf = sa.datasets.get_rdataset('iris').datadf.columns = df.columns.str.replace('.', '')lm = sfa.ols('SepalWidth ~ C(Species)', data=df).fit()anova = sa.stats.anova_lm(lm)print(anova)
获得了 ANOVA 测试结果,但不确定哪个变量类对结果的影响最大,可以使用以下代码进行原因的查看。
sp.posthoc_ttest(df, val_col='SepalWidth', group_col='Species', p_adjust='holm')

使用 scikit-posthoc,我们简化了事后测试的成对分析过程并获得了 P 值
10、Cerberus
Cerberus 是一个用于数据验证的轻量级 python 包。
pip install cerberus
Cerberus 的基本用法是验证类的结构。
from cerberus import Validatorschema = {'name': {'type': 'string'}, 'gender':{'type': 'string'}, 'age':{'type':'integer'}}v = Validator(schema)定义好需要验证的结构后,可以对实例进行验证。
document = {'name': 'john doe', 'gender':'male', 'age': 15}v.validate(document)
如果匹配,则 Validator 类将输出True 。 这样我们可以确保数据结构是正确的。
11、ppscore
ppscore 用于计算与目标变量相关的变量的预测能力。 该包计算可以检测两个变量之间的线性或非线性关系的分数。 分数范围从 0(无预测能力)到 1(完美预测能力)。
pip install ppscore
使用 ppscore 包根据目标计算分数。
import seaborn as snsimport ppscore as ppsdf = sns.load_dataset('mpg')pps.predictors(df, 'mpg')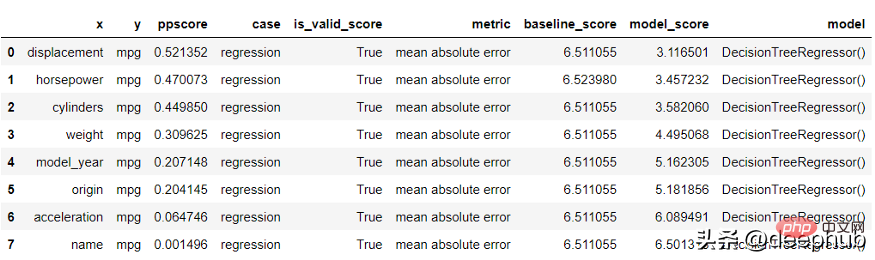
结果进行了排序。 排名越低变量对目标的预测能力越低。
12、Maya
Maya 用于尽可能轻松地解析 DateTime 数据。
pip install maya
然后我们可以使用以下代码轻松获得当前日期。
import mayanow = maya.now()print(now)
还可以为明天日期。
tomorrow = maya.when('tomorrow')tomorrow.datetime()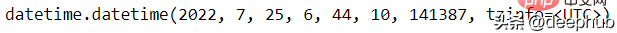
13、Pendulum
Pendulum 是另一个涉及 DateTime 数据的 python 包。 它用于简化任何 DateTime 分析过程。
pip install pendulum
我们可以对实践进行任何的操作。
import pendulumnow = pendulum.now("Europe/Berlin")now.in_timezone("Asia/Tokyo")now.to_iso8601_string()now.add(days=2)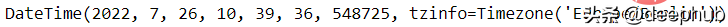
14、category_encoders
category_encoders 是一个用于类别数据编码(转换为数值数据)的python包。 该包是各种编码方法的集合,我们可以根据需要将其应用于各种分类数据。
pip install category_encoders
可以使用以下示例应用转换。
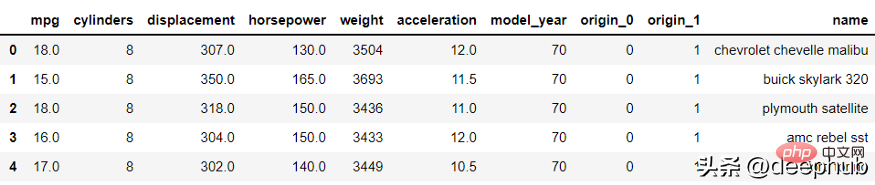
from category_encoders import BinaryEncoderimport pandas as pdenc = BinaryEncoder(cols=['origin']).fit(df)numeric_dataset = enc.transform(df)numeric_dataset.head()
15、scikit-multilearn
scikit-multilearn 可以用于特定于多类分类模型的机器学习模型。 该软件包提供 API 用于训练机器学习模型以预测具有两个以上类别目标的数据集。
pip install scikit-multilearn
利用样本数据集进行多标签KNN来训练分类器并度量性能指标。
from skmultilearn.dataset import load_datasetfrom skmultilearn.adapt import MLkNNimport sklearn.metrics as metricsX_train, y_train, feature_names, label_names = load_dataset('emotions', 'train')X_test, y_test, _, _ = load_dataset('emotions', 'test')classifier = MLkNN(k=3)prediction = classifier.fit(X_train, y_train).predict(X_test)metrics.hamming_loss(y_test, prediction)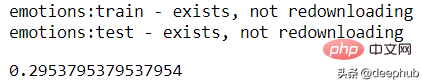
16、Multiset
Multiset类似于内置的set函数,但该包允许相同的字符多次出现。
pip install multiset
可以使用下面的代码来使用 Multiset 函数。
from multiset import Multisetset1 = Multiset('aab')set1
17、Jazzit
Jazzit 可以在我们的代码出错或等待代码运行时播放音乐。
pip install jazzit
使用以下代码在错误情况下尝试示例音乐。
from jazzit import error_track@error_track("curb_your_enthusiasm.mp3", wait=5)def run():for num in reversed(range(10)):print(10/num)这个包虽然没什么用,但是它的功能是不是很有趣,哈
18、handcalcs
handcalcs 用于简化notebook中的数学公式过程。 它将任何数学函数转换为其方程形式。
pip install handcalcs
使用以下代码来测试 handcalcs 包。 使用 %%render 魔术命令来渲染 Latex 。
import handcalcs.renderfrom math import sqrt
%%rendera = 4b = 6c = sqrt(3*a + b/7)
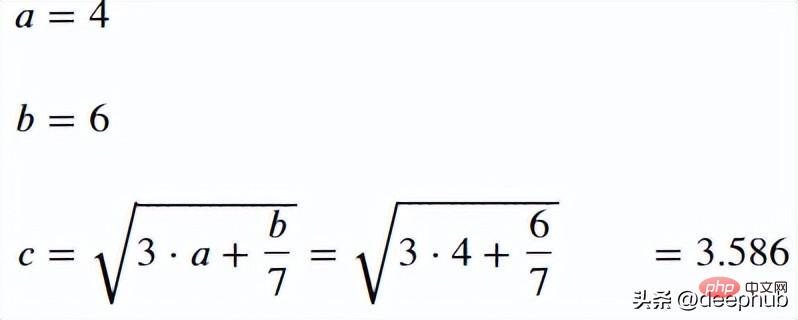
19、NeatText
NeatText 可简化文本清理和预处理过程。 它对任何 NLP 项目和文本机器学习项目数据都很有用。
pip install neattext
使用下面的代码,生成测试数据
import neattext as nt mytext = "This is the word sample but ,our WEBSITE is https://exaempleeele.com ✨."docx = nt.TextFrame(text=mytext)
TextFrame 用于启动 NeatText 类然后可以使用各种函数来查看和清理数据。
docx.describe()
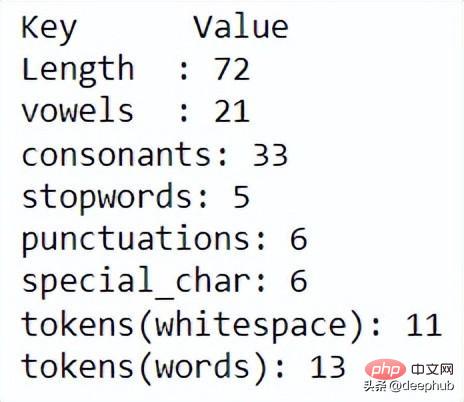
使用 describe 函数,可以显示每个文本统计信息。进一步清理数据,可以使用以下代码。
docx.normalize()
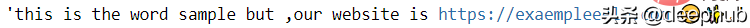
20、Combo
Combo 是一个用于机器学习模型和分数组合的 python 包。 该软件包提供了一个工具箱,允许将各种机器学习模型训练成一个模型。 也就是可以对模型进行整合。
pip install combo
使用来自 scikit-learn 的乳腺癌数据集和来自 scikit-learn 的各种分类模型来创建机器学习组合。
from sklearn.tree import DecisionTreeClassifierfrom sklearn.linear_model import LogisticRegressionfrom sklearn.ensemble import GradientBoostingClassifierfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.model_selection import train_test_splitfrom sklearn.datasets import load_breast_cancerfrom combo.models.classifier_stacking import Stackingfrom combo.utils.data import evaluate_print
接下来,看一下用于预测目标的单个分类器。
# Define data file and read X and yrandom_state = 42X, y = load_breast_cancer(return_X_y=True)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4,random_state=random_state)# initialize a group of clfsclassifiers = [DecisionTreeClassifier(random_state=random_state),LogisticRegression(random_state=random_state),KNeighborsClassifier(),RandomForestClassifier(random_state=random_state),GradientBoostingClassifier(random_state=random_state)]clf_names = ['DT', 'LR', 'KNN', 'RF', 'GBDT']for i, clf in enumerate(classifiers):clf.fit(X_train, y_train)y_test_predict = clf.predict(X_test)evaluate_print(clf_names[i] + ' | ', y_test, y_test_predict)print()

使用 Combo 包的 Stacking 模型。
clf = Stacking(classifiers, n_folds=4, shuffle_data=False,keep_original=True, use_proba=False,random_state=random_state)clf.fit(X_train, y_train)y_test_predict = clf.predict(X_test)evaluate_print('Stacking | ', y_test, y_test_predict)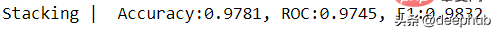
21、PyAztro
你是否需要星座数据或只是对今天的运气感到好奇? 可以使用 PyAztro 来获得这些信息! 这个包有幸运数字、幸运标志、心情等等。 这是我们人工智能算命的基础数据,哈
pip install pyaztro
使用以下代码访问今天的星座信息。
import pyaztropyaztro.Aztro(sign='gemini').description
22、Faker
Faker 可用于简化生成合成数据。 许多开发人员使用这个包来创建测试的数据。
pip install Faker
要使用 Faker 包生成合成数据
from faker import Fakerfake = Faker()
生成名字
fake.name()

每次从 Faker 类获取 .name 属性时,Faker 都会随机生成数据。
23、Fairlearn
Fairlearn 用于评估和减轻机器学习模型中的不公平性。 该软件包提供了许多查看偏差所必需的 API。
pip install fairlearn
然后可以使用 Fairlearn 的数据集来查看模型中有多少偏差。
from fairlearn.metrics import MetricFrame, selection_ratefrom fairlearn.datasets import fetch_adultdata = fetch_adult(as_frame=True)X = data.datay_true = (data.target == '>50K') * 1sex = X['sex']selection_rates = MetricFrame(metrics=selection_rate,y_true=y_true,y_pred=y_true,sensitive_features=sex)fig = selection_rates.by_group.plot.bar(legend=False, rot=0,title='Fraction earning over $50,000')
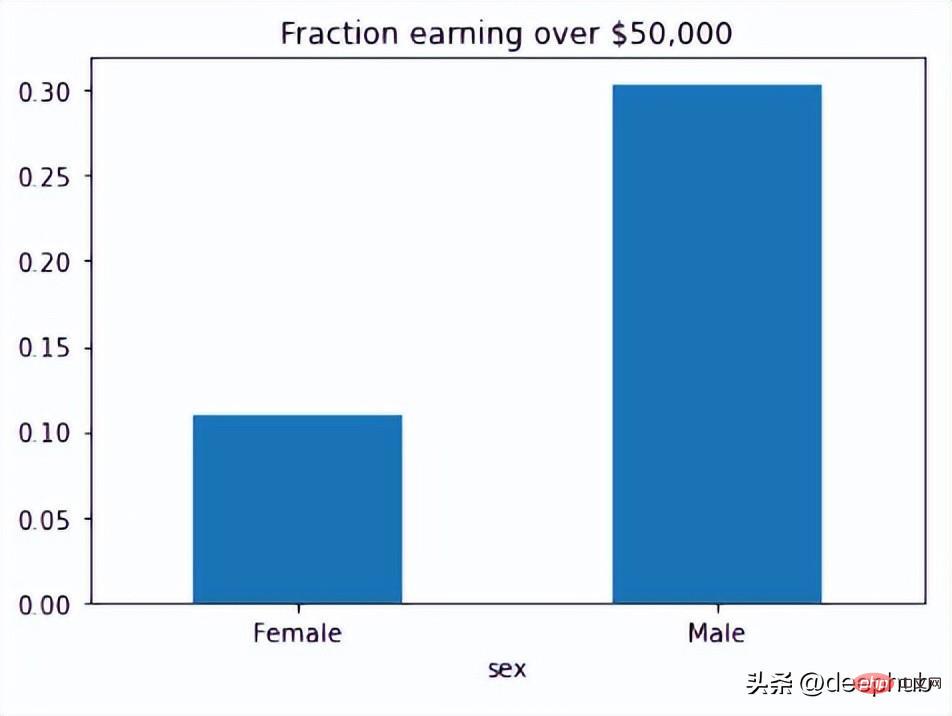
Fairlearn API 有一个 selection_rate 函数,可以使用它来检测组模型预测之间的分数差异,以便我们可以看到结果的偏差。
24、tiobeindexpy
tiobeindexpy 用于获取 TIOBE 索引数据。 TIOBE 指数是一个编程排名数据,对于开发人员来说是非常重要的因为我们不想错过编程世界的下一件大事。
pip install tiobeindexpy
可以通过以下代码获得当月前 20 名的编程语言排名。
from tiobeindexpy import tiobeindexpy as tbdf = tb.top_20()

25、pytrends
pytrends 可以使用 Google API 获取关键字趋势数据。如果想要了解当前的网络趋势或与我们的关键字相关的趋势时,该软件包非常有用。这个需要访问google,所以你懂的。
pip install pytrends
假设我想知道与关键字“Present Gift”相关的当前趋势,
from pytrends.request import TrendReqimport pandas as pdpytrend = TrendReq()keywords = pytrend.suggestions(keyword='Present Gift')df = pd.DataFrame(keywords)df
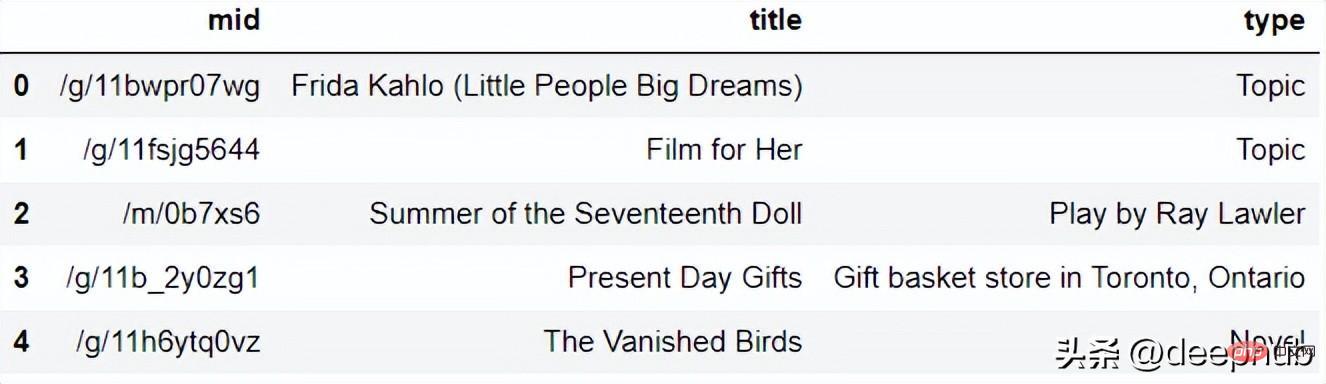
该包将返回与关键字相关的前 5 个趋势。
26、visions
visions 是一个用于语义数据分析的 python 包。 该包可以检测数据类型并推断列的数据应该是什么。
pip install visions
可以使用以下代码检测数据中的列数据类型。 这里使用 seaborn 的 Titanic 数据集。
import seaborn as snsfrom visions.functional import detect_type, infer_typefrom visions.typesets import CompleteSetdf = sns.load_dataset('titanic')typeset = CompleteSet()converting everything to stringsprint(detect_type(df, typeset))
27、Schedule
Schedule 可以为任何代码创建作业调度功能
pip install schedule
例如,我们想10 秒工作一次:
import scheduleimport timedef job():print("I'm working...")schedule.every(10).seconds.do(job)while True:schedule.run_pending()time.sleep(1)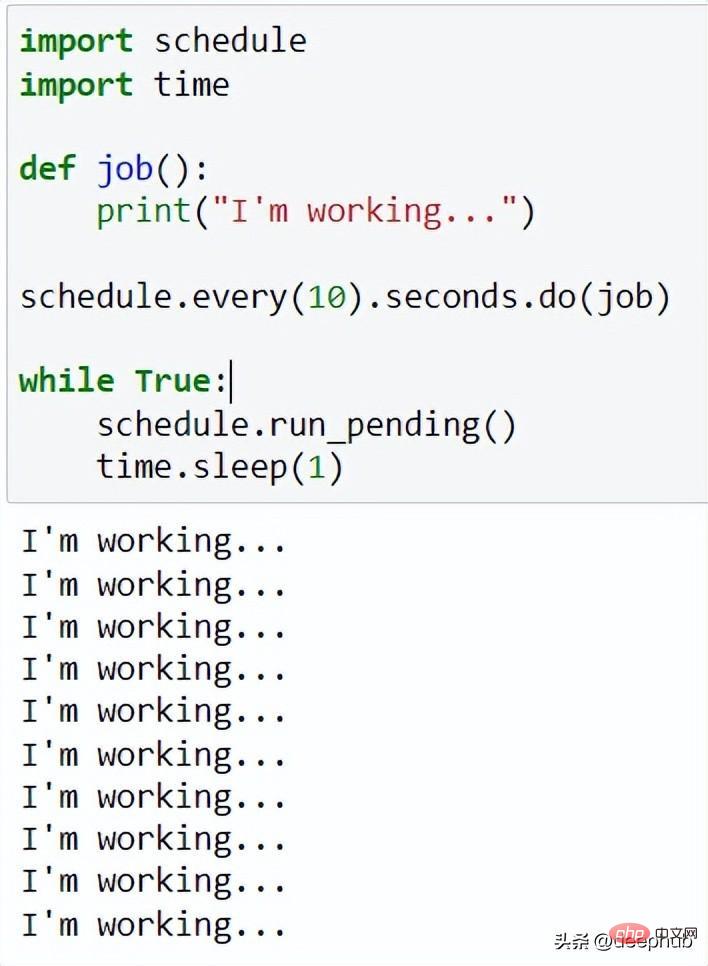
28、autocorrect
autocorrect 是一个用于文本拼写更正的 python 包,可应用于多种语言。 用法很简单,并且对数据清理过程非常有用。
pip install autocorrect
可以使用类似于以下代码进行自动更正。
from autocorrect import Spellerspell = Speller()spell("I'm not sleaspy and tehre is no place I'm giong to.")
29、funcy
funcy 包含用于日常数据分析使用的精美实用功能。 包中的功能太多了,我无法全部展示出来,有兴趣的请查看他的文档。
pip install funcy
这里只展示一个示例函数,用于从可迭代变量中选择一个偶数,如下面的代码所示。
from funcy import select, evenselect(even, {i for i in range (20)})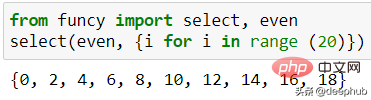
30、IceCream
IceCream 可以使调试过程更容易。该软件包在打印/记录过程中提供了更详细的输出。
pip install icecream
可以使用下面代码
from icecream import icdef some_function(i):i = 4 + (1 * 2)/ 10 return i + 35ic(some_function(121))

也可以用作函数检查器。
def foo():ic()if some_function(12):ic()else:ic()foo()
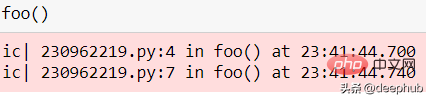
Tahap butiran yang dicetak sesuai untuk analisis.
Ringkasan
Dalam artikel ini, 30 pakej Python unik yang berguna dalam kerja data diringkaskan. Kebanyakan pakej perisian mudah digunakan dan ringkas dan jelas, tetapi sesetengahnya mungkin mempunyai lebih banyak fungsi dan memerlukan bacaan lanjut dokumentasinya. Jika anda berminat, sila pergi ke tapak web pypi untuk mencari dan melihat halaman utama dan dokumentasi pakej I semoga artikel ini dapat membantu anda.
Atas ialah kandungan terperinci 30 pakej Python penting untuk kejuruteraan data. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!