
Rumah >Peranti teknologi >AI >Bagaimanakah kami akan menjalankan carian maklumat pada masa hadapan?
Bagaimanakah kami akan menjalankan carian maklumat pada masa hadapan?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-12 14:10:071740semak imbas
Tetamu |.
Penganjuran | >Sudah lebih 20 tahun sejak kelahiran enjin carian, dan bentuk serta strukturnya tidak banyak berubah. Dengan perkembangan teknologi Internet yang berterusan, persekitaran carian pada masa hadapan akan menjadi lebih kompleks dan pelbagai, dan cara pengguna mendapatkan maklumat juga akan mengalami banyak perubahan Pelbagai bentuk input seperti bahasa semula jadi, suara, dan penglihatan pasti akan menggantikan kata kunci yang mudah ; Output kandungan berbilang modal seperti jawapan, pengetahuan peringkat tinggi, hasil analisis dan kandungan yang dijana akan menggantikan senarai hasil mudah kaedah interaksi juga boleh beralih daripada satu pusingan perolehan kepada beberapa pusingan interaksi bahasa semula jadi;
Jadi dalam persekitaran carian baharu, apakah ciri yang akan ditunjukkan oleh teknologi carian pintar masa hadapan? Baru-baru ini, di
Persidangan Teknologi Kecerdasan Buatan Global AIsummit
yang dihoskan oleh 51CTO, Encik Dou Zhicheng, Naib Dekan Pusat Pengajian Kepintaran Buatan di Universiti Renmin China Melalui ucaptama - "Teknologi Carian Pintar Generasi Seterusnya", trend pembangunan dan ciri teras generasi baharu teknologi carian pintar telah dikongsi dengan khalayak Pada masa yang sama, carian interaktif, berbilang modal dan boleh dijelaskan , dan carian De-indeks yang berpusatkan model besar dan teknologi lain telah dianalisis secara terperinci. Artikel ini telah menyunting dan menyelesaikan ucapan Encik Dou Zhicheng, dengan harapan dapat membawa anda beberapa inspirasi baharu: Ciri utama carian masa hadapanKami fikir Carian masa depan mungkin mempunyai sekurang-kurangnya lima ciri ini:
Perbualan, Enjin manusia dan carian ialah interaksi berbilang pusingan melalui cara bahasa semula jadi.
- Pemperibadian, akan memberi maklum balas hasil yang berbeza mengikut keperluan pengguna yang berbeza, dan bukannya membalas hasil yang sama kepada semua orang dengan cara pemotong kuki.
- Berbilang modal, Kandungan yang dikembalikan dan kaedah input mungkin tidak terhad kepada menggunakan teks sebagai medium atau kaedah.
- Pengetahuan yang kaya, Maklumat yang dikembalikan oleh carian bukan sahaja dalam bentuk senarai hasil, tetapi mungkin dalam pelbagai bentuk paparan, dengan pelbagai pengetahuan, Dipaparkan secara fizikal.
- Cara untuk mengindeks , indeks songsang atau indeks padat juga perlu membuat perubahan besar dengan segera.
- Perbualan Mod enjin carian yang biasa digunakan pada masa kini ialah memasukkan satu atau dua perkataan dalam kotak untuk mencari. Carian pada masa hadapan mungkin melibatkan kami berinteraksi dengan enjin carian dalam cara perbualan.
Dalam kaedah mendapatkan kata kunci yang digunakan oleh enjin carian tradisional, kami berharap dapat menerangkan semua maklumat teras yang kami cari melalui kata kunci, iaitu, kami menganggap bahawa satu pertanyaan boleh melengkapkan dan Menyatakan keperluan maklumat ini dengan tepat. Tetapi apabila menyatakan maklumat yang lebih kompleks, kata kunci sebenarnya sukar untuk memenuhi keperluan. Carian perbualan boleh menyatakan sepenuhnya keperluan maklumat melalui pelbagai pusingan interaksi, yang lebih sejajar dengan kaedah interaksi maklumat progresif antara orang semasa berkomunikasi.
Mencapai carian interaktif jenis ini akan membawa cabaran besar kepada sistem atau algoritma Enjin carian perlu memahami niat pengguna dengan tepat daripada pelbagai pusingan interaksi bahasa semula jadi. dan pada masa yang sama, adalah perlu untuk memadankan niat yang difahami dengan maklumat yang pengguna inginkan.
Berbanding dengan carian kata kunci tradisional, carian perbualan memerlukan pemahaman pertanyaan yang lebih kompleks (contohnya, ia perlu menyelesaikan masalah peninggalan, rujukan, dll. dalam pertanyaan semasa) untuk memulihkan niat carian Benar pengguna. Cara paling mudah ialah menggabungkan semua pertanyaan sejarah dan mengekodnya menggunakan model bahasa yang telah dilatih.
Walaupun kaedah dialog penyambungan mudah adalah mudah, ia mungkin menimbulkan bunyi bising. Tidak semua pertanyaan sejarah berguna untuk memahami pertanyaan semasa, jadi kami hanya memilih pertanyaan yang berkaitan dengannya. Konteks kebergantungan, yang juga boleh menyelesaikan masalah panjang.
Model perolehan perbualan COTED
Berdasarkan idea di atas, kami mencadangkan model perolehan padat perbualan COTED, yang terutamanya merangkumi tiga bahagian berikut:
1 Dengan mengenal pasti kebergantungan dalam pertanyaan dialog, kami boleh mengeluarkan bunyi dalam dialog dan meramalkan niat pengguna dengan lebih baik.
2. Peningkatan data (meniru pelbagai situasi hingar) dan menolak fungsi kehilangan berdasarkan pembelajaran kontras dengan berkesan membolehkan model belajar untuk mengabaikan konteks yang tidak relevan dan menggabungkannya dengan fungsi kehilangan pemadanan akhir Bersama , pembelajaran pelbagai tugas.
3. Mengurangkan kesukaran pembelajaran model pembelajaran pelbagai tugas melalui pembelajaran kursus, dan akhirnya meningkatkan prestasi model.
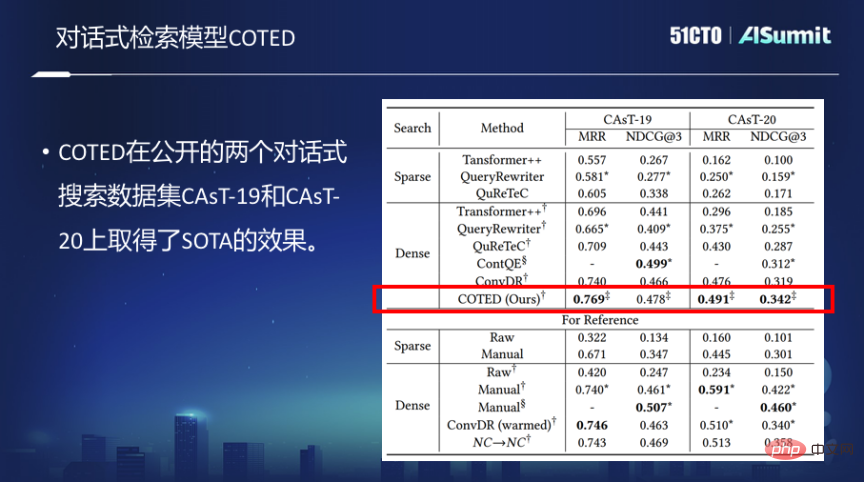
Walau bagaimanapun, data yang cukup untuk melatih model carian perbualan sebenarnya sangat terhad Dalam kes beberapa sampel yang terhad, model carian perbualan latihan model adalah sangat sukar.
Bagaimana untuk menyelesaikan masalah ini? Titik permulaan ialah sama ada log enjin carian boleh dipindahkan untuk latihan enjin carian perbualan. Berdasarkan idea ini, log carian web berskala besar ditukar kepada log carian perbualan, dan kemudian model carian perbualan dilatih pada data yang ditukar. Tetapi kaedah ini juga disertai dengan dua masalah yang jelas:
Pertama, carian web tradisional menggunakan carian kata kunci, dan carian perbualan ialah kaedah perbualan bahasa semula jadi. Borang pertanyaan adalah berbeza dan tidak boleh langsung berhijrah. Kedua, terdapat banyak bunyi dalam pertanyaan itu sendiri, dan data pengguna dalam log carian perlu dibersihkan, ditapis dan ditukar sebelum ia boleh digunakan dalam carian perbualan.
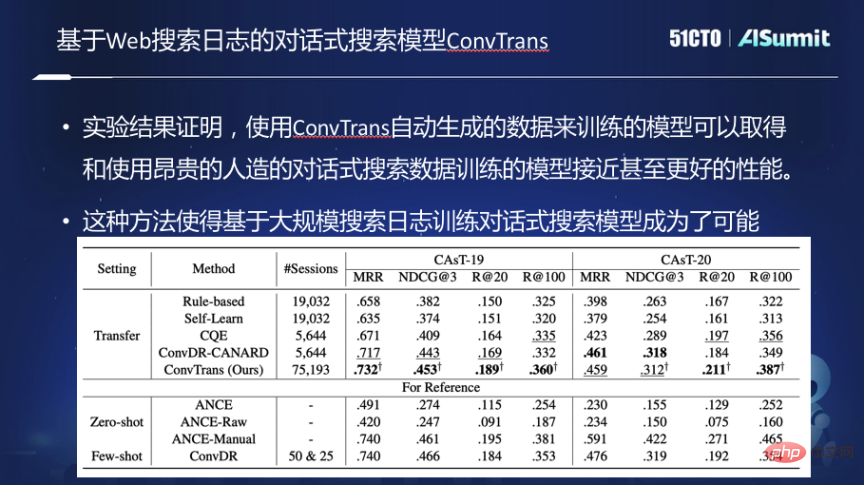
Model latihan carian perbualan ConvTrans
Untuk menyelesaikan masalah ini, kami membuat model latihan carian perbualan ConvTrans dan melaksanakan fungsi berikut.
Pertama, log dalam enjin carian web tradisional disusun dalam graf dan graf dibina dengan mewujudkan hubungan antara pertanyaan dan pertanyaan, pertanyaan dan dokumen. Berdasarkan graf, model penulisan semula pertanyaan dua peringkat berdasarkan T5 digunakan untuk menulis semula pertanyaan kata kunci ke dalam bentuk soalan. Selepas menulis semula, setiap pertanyaan dalam graf akan menggunakan bahasa semula jadi untuk menyatakan pertanyaan baharu, dan kemudian mereka bentuk algoritma pensampelan untuk melakukan langkah rawak pada graf untuk menjana sesi perbualan, dan kemudian melatih model perbualan berdasarkan data ini.
Eksperimen menunjukkan bahawa model carian perbualan yang dilatih dengan data latihan yang dijana secara automatik ini boleh mencapai kesan yang sama seperti menggunakan data tiruan atau yang dilabel secara manual yang mahal, dan dengan saiz Sebagai latihan yang dijana secara automatik data meningkat, prestasi akan terus bertambah baik. Pendekatan ini memungkinkan untuk melatih model carian perbualan berdasarkan log carian berskala besar.
Walaupun model carian perbualan telah mengambil langkah besar ke hadapan dalam carian, kaedah perbualan ini masih pasif dan enjin carian sentiasa pasif. Ia menerima input pengguna dan mengembalikan hasil berdasarkan input Enjin carian tidak secara aktif bertanya kepada pengguna apa sebenarnya yang anda cari. Tetapi dalam proses komunikasi antara orang, apabila anda ditanya soalan, kadang-kadang anda akan mengambil inisiatif untuk bertanya beberapa soalan untuk penjelasan.
Sebagai contoh, dalam carian Bing, jika Pertanyaan ialah "Sakit kepala", ia akan menjadi sakit kepala. Ia akan bertanya kepada anda "Apa yang ingin anda ketahui tentang keadaan perubatan ini", "Apa yang anda ingin ketahui tentang penyakit ini", seperti simptomnya, rawatan, diagnosis, punca atau pencetusnya. Oleh kerana Sakit Kepala itu sendiri adalah Pertanyaan yang sangat luas, dalam kes ini, sistem berharap dapat menjelaskan lagi maklumat yang ingin anda cari.
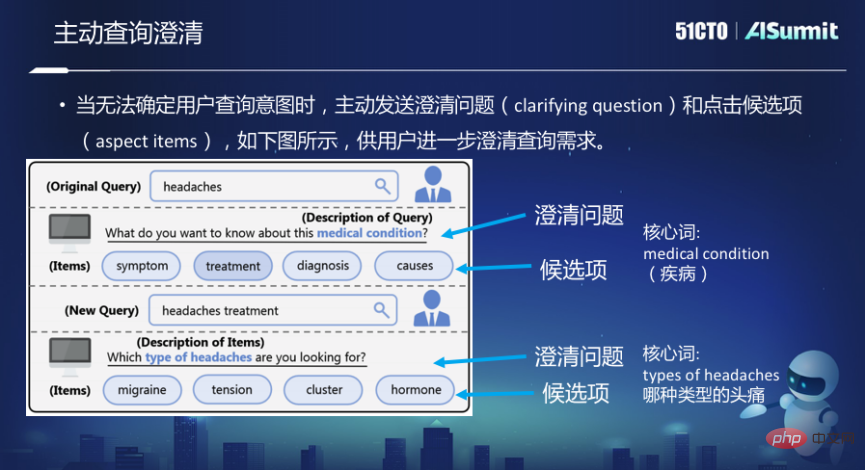
Terdapat dua masalah di sini yang pertama ialah item calon, item tertentu yang anda mahu pengguna jelaskan. Yang kedua adalah untuk menjelaskan soalan Enjin carian mengambil inisiatif untuk bertanya kepada pengguna soalan ini. Kata teras adalah bahagian yang paling penting untuk menjelaskan masalah.
Langkah pertama dalam meneroka aspek ini ialah menjana beberapa calon penjelasan apabila diberi pertanyaan melalui log pertanyaan dan pangkalan pengetahuan. Kedua, beberapa perkataan teras soalan penjelasan ini boleh diramalkan daripada hasil carian berdasarkan peraturan. Pada masa yang sama, beberapa data juga dilabelkan dan model yang diselia digunakan untuk mengklasifikasikan label teks. Ketiga, terus melatih model generatif hujung ke hujung berdasarkan data beranotasi ini.
Pemperibadian
Pemperibadian merujuk kepada carian masa hadapan akan berpusatkan pengguna. Enjin carian hari ini mengembalikan hasil yang sama tidak kira siapa yang mencari. Ini tidak memenuhi keperluan maklumat khusus pengguna.
Model semasa carian diperibadikan adalah untuk terlebih dahulu mempelajari maklumat pengetahuan yang pengguna kenali melalui sejarah pengguna dan menjalankan nyahkekaburan entiti diperibadikan pada pertanyaan. Kedua, padanan diperibadikan dipertingkatkan melalui entiti pertanyaan nyahkekaburan.
Selain itu, kami juga telah meneroka pembinaan model berbilang minat pengguna berdasarkan kategori produk Diandaikan bahawa pengguna mungkin mempunyai beberapa pilihan untuk jenama (spesifikasi, model) merentas semua kategori, tetapi keutamaan ini. tidak boleh mudah dicirikan oleh satu atau dua vektor. Graf pengetahuan harus dibina berdasarkan sejarah beli-belah pengguna, dan minat yang berbeza untuk kategori yang berbeza harus dipelajari melalui graf pengetahuan, dan akhirnya hasil carian diperibadikan yang lebih tepat boleh ditolak.
Anda juga boleh menggunakan kaedah diperibadikan yang sama untuk membina bot sembang Idea teras adalah untuk mempelajari minat dan corak bahasa yang diperibadikan pengguna melalui perbualan sejarah pengguna dan melatih model dialog yang diperibadikan. yang boleh ditiru Pengguna (ejen) bercakap.
Berbilang modaliti
Enjin carian semasa sebenarnya mempunyai beberapa had semasa memproses maklumat berbilang modal. Pada masa hadapan, maklumat yang diperoleh pengguna mungkin bukan sahaja beberapa teks dan halaman web, tetapi mungkin juga termasuk gambar, video dan maklumat struktur yang lebih kompleks. Oleh itu, enjin carian masa hadapan masih mempunyai banyak kerja yang perlu dilakukan dalam memperoleh maklumat berbilang modal.
Apabila enjin carian semasa memahami atau melakukan pencarian semula modal, iaitu, apabila mereka memberikan penerangan teks dan mencari gambar yang sepadan, mereka masih mempunyai banyak kelemahan. Jika carian serupa dipindahkan ke telefon mudah alih, pengehadan akan menjadi lebih besar.
Apa yang dipanggil multi-modal bermaksud bahasa, imej, gambar, video dan modaliti lain yang anda cari dipetakan ke ruang bersatu, yang bermaksud bahawa anda boleh mencari gambar melalui teks , gambar untuk mencari teks, gambar untuk mencari gambar, dsb.
Sehubungan itu, kami membuat model pra-latihan pelbagai mod berskala besar - Wenlan. Ia memberi tumpuan kepada latihan berdasarkan maklumat yang disumbangkan oleh korelasi imej Internet besar-besaran yang diselia dengan lemah dan teks berdekatan. Menggunakan mod menara berkembar, latihan terakhir ialah pengekod gambar dan pengekod teks Kedua-dua pengekod ini melepasi proses pembelajaran pengoptimuman pemadanan hujung ke hujung supaya vektor perwakilan akhir boleh dipetakan ke ruang bersatu, bukannya The. butiran halus gambar dan butiran halus teks dicantumkan bersama.
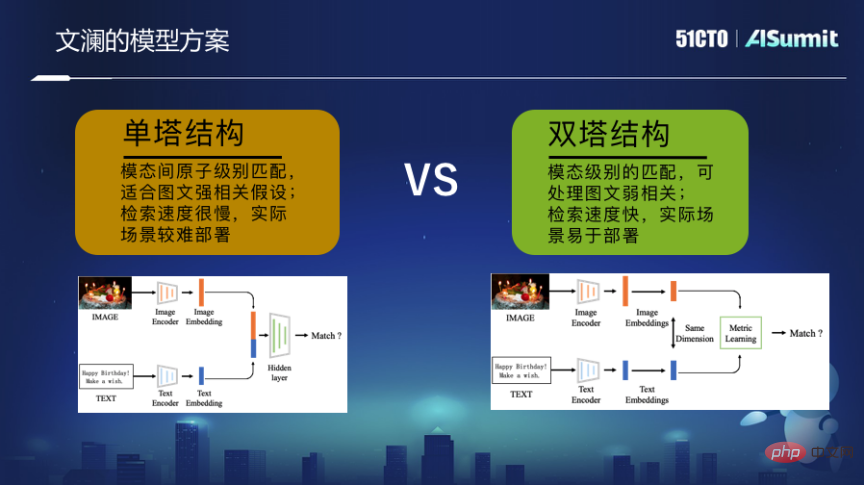
Keupayaan mendapatkan semula mod silang ini sebenarnya bukan sahaja menyediakan pengguna dengan lebih banyak ruang hujung ke hujung apabila menggunakan enjin carian web, tetapi juga Pada masa yang sama, ia juga boleh menyokong banyak aplikasi, seperti penciptaan, sama ada media sosial atau kategori budaya dan kreatif, ia boleh digunakan untuk menyokongnya.
Kaya dengan pengetahuan
Tubuh utama enjin carian hari ini masih laman web, tetapi pada masa hadapan, unit yang diproses oleh enjin carian bukan hanya halaman web, tetapi harus diproses dengan pengetahuan Unit, termasuk hasil yang dikembalikan, juga harus pengetahuan peringkat tinggi, bukannya senarai halaman demi halaman. Banyak kali, pengguna sebenarnya ingin menggunakan enjin carian untuk melengkapkan beberapa keperluan maklumat yang kompleks, jadi mereka berharap enjin carian akan membantu menganalisis keputusan, dan bukannya membiarkan orang menganalisisnya satu demi satu.
Berdasarkan idea ini, kami membina enjin analisis, yang setara dengan enjin carian dan boleh menyediakan analisis teks yang mendalam untuk membantu pengguna memperoleh pengetahuan peringkat tinggi dengan cekap dan cepat. Bantu pengguna membaca dan memahami dokumen berskala besar, dan mengekstrak, melombong dan meringkaskan maklumat dan pengetahuan penting yang terkandung di dalamnya Akhirnya, melalui proses analisis interaktif, pengguna boleh menyemak imbas dan menganalisis pengetahuan peringkat tinggi yang dilombong , dan kemudian memberikan pengguna dengan sokongan keputusan.
Sebagai contoh, jika pengguna ingin mencari maklumat berkaitan smog, dia boleh terus memasukkan "smog". Model pengetahuan yang kaya adalah berbeza daripada hasil yang dikembalikan oleh enjin carian tradisional Ia mungkin mengembalikan garis masa untuk memberitahu pengguna pengedaran maklumat tentang asap pada garis masa, dsb. Ia juga akan meringkaskan subtopik tentang asap dan institusi yang ada. . Sudah tentu, ia juga boleh menyediakan senarai terperinci hasil seperti enjin carian.
Keupayaan untuk menyediakan analisis secara langsung dan analisis interaktif ini boleh membantu pengguna mendapatkan maklumat yang kompleks dengan lebih baik. Apa yang diberikan kepada pengguna bukan lagi senarai ringkas hasil carian. Sudah tentu, analisis pengetahuan pelbagai dimensi interaktif seperti ini hanyalah kaedah paparan, dan lebih banyak kaedah boleh digunakan pada masa hadapan Contohnya, salah satu perkara yang kami lakukan sekarang ialah daripada mendapatkan semula kepada menjana kandungan (munasabah).
De-index
Kini enjin carian secara meluas menggunakan pendekatan berperingkat dengan pengindeksan sebagai teras, merangkak kembali kandungan yang diperlukan daripada sebilangan besar halaman web Internet dan kemudian membina Indeks, iaitu indeks terbalik atau pengindeksan vektor padat. Selepas Pertanyaan pengguna datang, panggilan semula dilakukan terlebih dahulu, dan kemudian pengisihan yang diperhalusi dilakukan berdasarkan hasil penarikan semula.
Model ini mempunyai banyak kelemahan, kerana ia perlu dibahagikan kepada peringkat-peringkat Jika terdapat masalah dalam satu peringkat, contohnya, hasil yang diinginkan tidak ditemui dalam peringkat ingat semula. tidak kira betapa baiknya dalam peringkat pengisihan, Ia juga tidak mungkin mengembalikan hasil yang sangat baik.
Dalam enjin carian masa hadapan, struktur ini mungkin rosak. Idea baharu ialah menggunakan model besar untuk menggantikan skema indeks semasa, dan semua pertanyaan boleh dipenuhi melalui model. Ini menghapuskan keperluan untuk menggunakan indeks dan terus memberi suapan kembali hasil yang diingini melalui model ini.
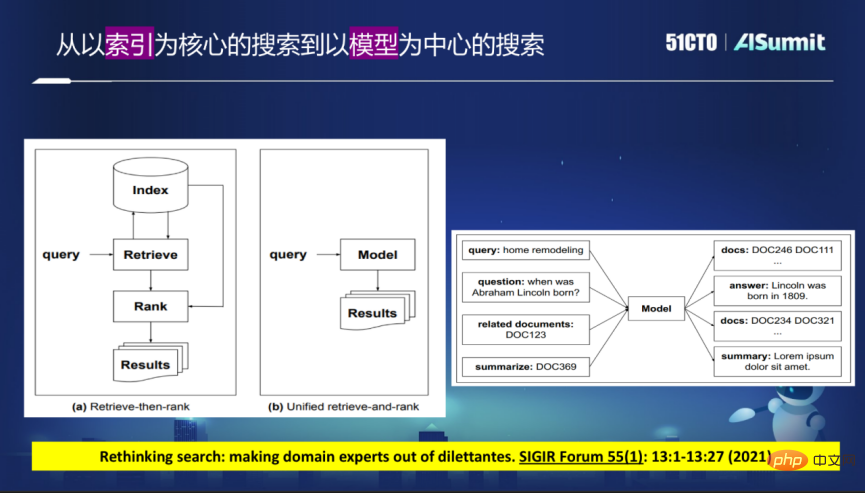
Atas dasar ini, anda boleh terus memberikan senarai keputusan, atau anda boleh terus memberikan jawapan yang diperlukan pengguna, malah jawapannya boleh menjadi imej, yang akan Mod lebih baik disepadukan bersama. Mengalih keluar indeks dan menyuap kembali hasil secara terus melalui model bermakna model boleh mengembalikan secara terus atau terus mengembalikan pengecam dokumen Pengecam dokumen mesti dibenamkan dalam model untuk membina carian berpusatkan model.
Ringkasan
Kini enjin carian secara meluas menggunakan model mudah kata kunci sebagai input dan senarai dokumen sebagai output. Sudah ada beberapa masalah dalam memenuhi keperluan pemerolehan maklumat yang kompleks orang ramai. Enjin carian masa depan akan menjadi perbualan, diperibadikan, berpusatkan pengguna, dan dapat menembusi stereotaip. Pada masa yang sama, ia boleh memproses maklumat berbilang modal, memproses pengetahuan, dan mengembalikan pengetahuan. Dari segi seni bina, pada masa hadapan, kami pasti akan menerobos model berpusat indeks sedia ada yang menggunakan indeks terbalik atau indeks vektor padat, dan secara beransur-ansur beralih kepada model berpusatkan model.
Pengenalan Tetamu
Dou Zhicheng, Renmin University Naib Presiden China Institut Kepintaran Buatan Hillhouse, Pengurus Projek "Pendapatan Maklumat Pintar dan Perlombongan" Institut Penyelidikan Kepintaran Buatan Zhiyuan Beijing. Pada tahun 2008, beliau menyertai Microsoft Research Asia dan terlibat dalam kerja berkaitan carian Internet, membangunkan pengalaman yang kaya dalam penyelidikan dan pembangunan teknologi perolehan semula maklumat. Beliau mula mengajar di Universiti Renmin China pada 2014. Hala tuju penyelidikan utamanya ialah pencarian maklumat pintar dan pemprosesan bahasa semula jadi. Beliau telah memenangi Anugerah Pencalonan Kertas Terbaik di Persidangan Antarabangsa mengenai Pencarian Maklumat (SIGIR 2013), Anugerah Kertas Terbaik di Persidangan Asia mengenai Pencarian Maklumat (AIRS 2012), dan Anugerah Kertas Terbaik di Persidangan Akademik Kebangsaan mengenai Pencarian Maklumat ( CCIR 2018, CCIR 2021). Beliau berkhidmat sebagai pengerusi jawatankuasa program SIGIR 2019 (artikel pendek), pengerusi jawatankuasa program Persidangan Penilaian Pencarian Maklumat NTCIR-16, dan timbalan setiausaha agung Jawatankuasa Pakar Data Besar Persekutuan Komputer China. . Dalam dua tahun yang lalu, beliau telah memberi tumpuan terutamanya pada kedudukan carian yang diperibadikan dan pelbagai, model carian interaktif dan perbualan, kaedah pra-latihan untuk mendapatkan maklumat, kebolehtafsiran model carian dan pengesyoran, carian produk yang diperibadikan, dsb.
Atas ialah kandungan terperinci Bagaimanakah kami akan menjalankan carian maklumat pada masa hadapan?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI