
Rumah >Peranti teknologi >AI >Membina enjin carian video menggunakan CLIP
Membina enjin carian video menggunakan CLIP

- WBOYke hadapan
- 2023-04-12 13:43:031025semak imbas
CLIP (Pra-latihan Bahasa-Imej Kontrastif) ialah teknologi pembelajaran mesin yang boleh memahami dan mengklasifikasikan imej dan teks bahasa semula jadi dengan tepat, yang mempunyai kesan mendalam pada pemprosesan imej dan bahasa serta telah digunakan sebagai mekanisme asas yang popular model resapan DALL-E. Dalam siaran ini, kami akan membincangkan cara menyesuaikan CLIP untuk membantu carian video.
Artikel ini tidak akan menyelidiki butiran teknikal model CLIP, tetapi akan menunjukkan satu lagi aplikasi praktikal CLIP (sebagai tambahan kepada model resapan).
Mula-mula kita perlu tahu: CLIP menggunakan penyahkod imej dan pengekod teks untuk meramalkan imej dalam set data yang sepadan dengan teks yang mana.

Cari menggunakan CLIP
Dengan menggunakan model CLIP terlatih dari muka berpeluk, kami boleh membina enjin carian video yang ringkas namun berkuasa dengan keupayaan bahasa Semulajadi dan tidak memerlukan kejuruteraan ciri.
Kita perlu menggunakan perisian berikut
Python≥= 3.8,ffmpeg,opencv
Terdapat banyak teknik untuk mencari video melalui teks. Kita boleh menganggap enjin carian terdiri daripada dua bahagian, pengindeksan dan carian.
Pengindeksan
Pengindeksan video selalunya melibatkan gabungan proses manusia dan mesin. Manusia pra-memproses video dengan menambahkan kata kunci yang berkaitan dalam tajuk, teg dan perihalan, manakala proses automatik mengekstrak ciri visual dan pendengaran seperti pengesanan objek dan transkripsi audio. Metrik interaksi pengguna dan banyak lagi, yang merekodkan bahagian video yang paling berkaitan dan tempoh masa ia kekal relevan. Semua langkah ini membantu mencipta indeks kandungan video anda yang boleh dicari.
Ikhtisar proses pengindeksan adalah seperti berikut
- Pisah video kepada berbilang adegan
- Sampel adegan untuk bingkai
- Pembenaman piksel selepas bingkai pemprosesan
- Storan bangunan indeks
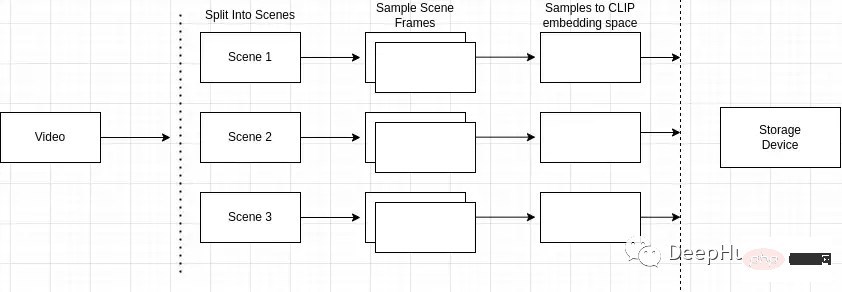
Pisah video kepada berbilang adegan
Mengapa pengesanan adegan penting? adegan, dan Pemandangan terdiri daripada bingkai yang serupa. Jika kami hanya mencuba adegan sewenang-wenangnya dalam video, kami mungkin terlepas bingkai utama dalam keseluruhan video.
Jadi kita perlu mengenal pasti dan mengesan peristiwa atau tindakan tertentu dengan tepat dalam video. Contohnya, jika saya mencari "anjing di taman" dan video yang saya cari mengandungi berbilang adegan, seperti adegan lelaki menunggang basikal dan adegan anjing di taman, pengesanan pemandangan membolehkan saya kenal pasti yang paling berkaitan dengan pertanyaan carian.
Anda boleh menggunakan pakej python "scene detect" untuk melakukan operasi ini.
mport scenedetect as sd video_path = '' # path to video on machine video = sd.open_video(video_path) sm = sd.SceneManager() sm.add_detector(sd.ContentDetector(threshold=27.0)) sm.detect_scenes(video) scenes = sm.get_scene_list()
Mengambil sampel bingkai tempat kejadian
Kemudian anda perlu menggunakan cv2 untuk membingkai video.
import cv2 cap = cv2.VideoCapture(video_path) every_n = 2 # number of samples per scene scenes_frame_samples = [] for scene_idx in range(len(scenes)): scene_length = abs(scenes[scene_idx][0].frame_num - scenes[scene_idx][1].frame_num) every_n = round(scene_length/no_of_samples) local_samples = [(every_n * n) + scenes[scene_idx][0].frame_num for n in range(3)] scenes_frame_samples.append(local_samples)
Tukar bingkai kepada pembenaman piksel
Selepas mengumpul sampel, kami perlu mengiranya menjadi sesuatu yang boleh digunakan oleh model CLIP.
Setiap sampel terlebih dahulu perlu ditukar kepada pembenaman tensor imej.
from transformers import CLIPProcessor
from PIL import Image
clip_processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
def clip_embeddings(image):
inputs = clip_processor(images=image, return_tensors="pt", padding=True)
input_tokens = {
k: v for k, v in inputs.items()
}
return input_tokens['pixel_values']
# ...
scene_clip_embeddings = [] # to hold the scene embeddings in the next step
for scene_idx in range(len(scenes_frame_samples)):
scene_samples = scenes_frame_samples[scene_idx]
pixel_tensors = [] # holds all of the clip embeddings for each of the samples
for frame_sample in scene_samples:
cap.set(1, frame_sample)
ret, frame = cap.read()
if not ret:
print('failed to read', ret, frame_sample, scene_idx, frame)
break
pil_image = Image.fromarray(frame)
clip_pixel_values = clip_embeddings(pil_image)
pixel_tensors.append(clip_pixel_values)Langkah seterusnya ialah purata semua sampel dalam adegan yang sama, yang boleh mengurangkan dimensi sampel dan juga menyelesaikan masalah hingar dalam satu sampel.
import torch
import uuid
def save_tensor(t):
path = f'/tmp/{uuid.uuid4()}'
torch.save(t, path)
return path
# ..
avg_tensor = torch.mean(torch.stack(pixel_tensors), dim=0)
scene_clip_embeddings.append(save_tensor(avg_tensor))Dengan cara ini, senarai tensor terbenam CLIP yang mewakili kandungan video diperolehi.
Menyimpan Indeks
Untuk storan indeks asas, kami menggunakan LevelDB (LevelDB ialah perpustakaan kunci/nilai yang diselenggara oleh Google). Seni bina enjin carian kami akan merangkumi 3 indeks bebas:
- Indeks adegan video: adegan manakah yang tergolong dalam video tertentu
- Indeks terbenam adegan: simpan data pemandangan tertentu
- Indeks Metadata Video: Simpan metadata video.
Kami akan memasukkan semua metadata yang dikira dalam video dan pengecam unik video ke dalam indeks metadata terlebih dahulu.
import leveldb
import uuid
def insert_video_metadata(videoID, data):
b = json.dumps(data)
level_instance = leveldb.LevelDB('./dbs/videometadata_index')
level_instance.Put(videoID.encode('utf-8'), b.encode('utf-8'))
# ...
video_id = str(uuid.uuid4())
insert_video_metadata(video_id, {
'VideoURI': video_path,
})Kemudian buat entri baharu dalam indeks pembenaman pemandangan untuk menahan setiap pembenaman piksel dalam video, juga memerlukan pengecam unik untuk mengenal pasti setiap babak.
import leveldb
import uuid
def insert_scene_embeddings(sceneID, data):
level_instance = leveldb.LevelDB('./dbs/scene_embedding_index')
level_instance.Put(sceneID.encode('utf-8'), data)
# ...
for f in scene_clip_embeddings:
scene_id = str(uuid.uuid4())
with open(f, mode='rb') as file:
content = file.read()
insert_scene_embeddings(scene_id, content)Akhir sekali, kita perlu menyimpan adegan mana yang tergolong dalam video mana.
import leveldb
import uuid
def insert_video_scene(videoID, sceneIds):
b = ",".join(sceneIds)
level_instance = leveldb.LevelDB('./dbs/scene_index')
level_instance.Put(videoID.encode('utf-8'), b.encode('utf-8'))
# ...
scene_ids = []
for f in scene_clip_embeddings:
# .. as shown in previous step
scene_ids.append(scene_id)
scene_embedding_index.insert(scene_id, content)
scene_index.insert(video_id, scene_ids)Cari
Sekarang kami mempunyai indeks video, kami boleh mencari dan mengisihnya berdasarkan output model.
Langkah pertama memerlukan merentasi semua rekod dalam indeks adegan. Kemudian, buat senarai semua video dan id adegan yang sepadan dalam video.
records = []
level_instance = leveldb.LevelDB('./dbs/scene_index')
for k, v in level_instance.RangeIter():
record = (k.decode('utf-8'), str(v.decode('utf-8')).split(','))
records.append(record)Langkah seterusnya melibatkan pengumpulan semua tensor benam adegan yang terdapat dalam setiap video.
import leveldb
def get_tensor_by_scene_id(id):
level_instance = leveldb.LevelDB('./dbs/scene_embedding_index')
b = level_instance.Get(bytes(id,'utf-8'))
return BytesIO(b)
for r in records:
tensors = [get_tensor_by_scene_id(id) for id in r[1]]Selepas kami mempunyai semua tensor yang membentuk video, kami boleh memasukkannya ke dalam model. Input kepada model ialah "nilai_pixel", tensor yang mewakili adegan video.
import torch
from transformers import CLIPProcessor, CLIPModel
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
inputs = processor(text=text, return_tensors="pt", padding=True)
for tensor in tensors:
image_tensor = torch.load(tensor)
inputs['pixel_values'] = image_tensor
outputs = model(**inputs)Kemudian akses "logits_per_image" dalam output model untuk mendapatkan output model.
Logit pada asasnya ialah ramalan mentah yang tidak normal bagi rangkaian. Memandangkan kami hanya menyediakan rentetan teks dan tensor yang mewakili adegan dalam video, struktur logit akan menjadi ramalan nilai tunggal.
logits_per_image = outputs.logits_per_image probs = logits_per_image.squeeze() prob_for_tensor = probs.item()
Tambahkan kebarangkalian untuk setiap lelaran dan bahagikannya dengan jumlah bilangan tensor pada penghujung operasi untuk mendapatkan purata kebarangkalian video.
def clip_scenes_avg(tensors, text): avg_sum = 0.0 for tensor in tensors: # ... previous code snippets probs = probs.item() avg_sum += probs.item() return avg_sum / len(tensors)
最后在得到每个视频的概率并对概率进行排序后,返回请求的搜索结果数目。
import leveldb
import json
top_n = 1 # number of search results we want back
def video_metadata_by_id(id):
level_instance = leveldb.LevelDB('./dbs/videometadata_index')
b = level_instance.Get(bytes(id,'utf-8'))
return json.loads(b.decode('utf-8'))
results = []
for r in records:
# .. collect scene tensors
# r[0]: video id
return (clip_scenes_avg, r[0])
sorted = list(results)
sorted.sort(key=lambda x: x[0], reverse=True)
results = []
for s in sorted[:top_n]:
data = video_metadata_by_id(s[1])
results.append({
'video_id': s[1],
'score': s[0],
'video_uri': data['VideoURI']
})就是这样!现在就可以输入一些视频并测试搜索结果。
总结
通过CLIP可以轻松地创建一个频搜索引擎。使用预训练的CLIP模型和谷歌的LevelDB,我们可以对视频进行索引和处理,并使用自然语言输入进行搜索。通过这个搜索引擎使用户可以轻松地找到相关的视频,最主要的是我们并不需要大量的预处理或特征工程。
那么我们还能有什么改进呢?
- 使用场景的时间戳来确定最佳场景。
- 修改预测让他在计算集群上运行。
- 使用向量搜索引擎,例如Milvus 替代LevelDB
- 在索引的基础上建立推荐系统
- 等等
可以在这里找到本文的代码:https://github.com/GuyARoss/CLIP-video-search/tree/article-01。
以及这个修改版本:https://github.com/GuyARoss/CLIP-video-search。
Atas ialah kandungan terperinci Membina enjin carian video menggunakan CLIP. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI