
Rumah >Peranti teknologi >AI >11 teknik pengekodan ciri klasifikasi biasa
11 teknik pengekodan ciri klasifikasi biasa

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-12 12:16:092063semak imbas
Algoritma pembelajaran mesin hanya menerima input berangka, jadi jika kami menemui ciri kategori, kami akan mengekodkan ciri kategori Artikel ini meringkaskan 11 kaedah pengekodan pembolehubah kategori biasa.

1. ONE HOT ENCOD
Kaedah pengekodan yang paling popular dan biasa digunakan ialah One Hot Enoding. Pembolehubah tunggal dengan n pemerhatian dan d nilai berbeza ditukar kepada d pembolehubah binari dengan n pemerhatian, setiap pembolehubah binari dikenal pasti dengan sedikit (0, 1).
Contohnya:
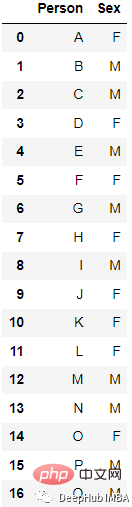
Selepas pengekodan

Pelaksanaan paling mudah ialah menggunakan get_dummies panda
new_df=pd.get_dummies(columns=[‘Sex’], data=df)
2. Pengekodan Label
Tetapkan integer yang dikenal pasti secara unik kepada pembolehubah data kategori. Kaedah ini sangat mudah, tetapi boleh menyebabkan masalah untuk pembolehubah kategori yang mewakili data tidak tertib. Contohnya: teg dengan nilai tinggi boleh mempunyai keutamaan yang lebih tinggi daripada teg dengan nilai rendah.
Sebagai contoh, dalam data di atas, kami mendapat keputusan berikut selepas pengekodan:

Pengekod Label sklearn boleh ditukar terus:
from sklearn.preprocessing import LabelEncoder le=LabelEncoder() df[‘Sex’]=le.fit_transform(df[‘Sex’])
3. Label Binarizer
Label Binarizer ialah kelas alat yang digunakan untuk mencipta matriks label daripada senarai berbilang kategori Ia akan menukar senarai kepada senarai dengan bilangan lajur yang sama persis nilai dalam set input.
Sebagai contoh, data ini
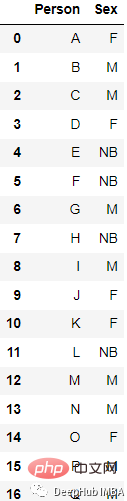
Hasil yang ditukar ialah

from sklearn.preprocessing import LabelBinarizer lb = LabelBinarizer() new_df[‘Sex’]=lb.fit_transform(df[‘Sex’])
4. Tinggalkan satu Pengekodan
Tinggalkan Satu Keluar Apabila pengekodan, semua rekod dengan nilai yang sama untuk pembolehubah ciri kategori sasaran dipuratakan untuk menentukan min pembolehubah sasaran. Algoritma pengekodan berbeza sedikit antara set data latihan dan ujian. Oleh kerana rekod ciri yang dipertimbangkan untuk klasifikasi dikecualikan daripada set data latihan, ia dipanggil "Tinggalkan Satu".
Nilai khusus pembolehubah kategori tertentu dikodkan seperti berikut.
ci = (Σj != i tj / (n — 1 + R)) x (1 + εi) where ci = encoded value for ith record tj = target variable value for jth record n = number of records with the same categorical variable value R = regularization factor εi = zero mean random variable with normal distribution N(0, s)
Sebagai contoh, data berikut:

Selepas pengekodan:

Kepada tunjukkan ini Dalam proses pengekodan, kami mencipta set data:
import pandas as pd; data = [[‘1’, 120], [‘2’, 120], [‘3’, 140], [‘2’, 100], [‘3’, 70], [‘1’, 100],[‘2’, 60], [‘3’, 110], [‘1’, 100],[‘3’, 70] ] df = pd.DataFrame(data, columns = [‘Dept’,’Yearly Salary’])
dan kemudian mengekod:
import category_encoders as ce
tenc=ce.TargetEncoder()
df_dep=tenc.fit_transform(df[‘Dept’],df[‘Yearly Salary’])
df_dep=df_dep.rename({‘Dept’:’Value’}, axis=1)
df_new = df.join(df_dep)Dengan cara ini kita mendapat keputusan di atas.
5. Pencincangan
Apabila menggunakan fungsi cincang, rentetan akan ditukar kepada nilai cincang yang unik. Kerana ia menggunakan memori yang sangat sedikit dan boleh mengendalikan lebih banyak data kategori. Pencincangan ciri ialah kaedah yang berkesan untuk mengurus ciri berdimensi tinggi yang jarang dalam pembelajaran mesin. Ia sesuai untuk senario pembelajaran dalam talian dan mempunyai ciri-ciri cepat, mudah, cekap dan pantas.
Sebagai contoh, data berikut:
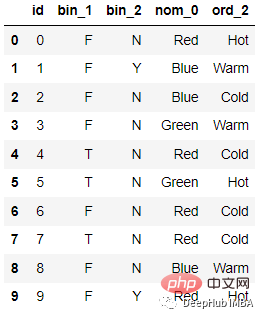
Selepas pengekodan
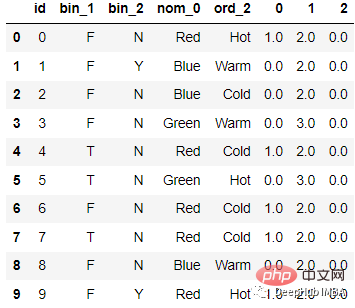
Kodnya adalah seperti berikut :
from sklearn.feature_extraction import FeatureHasher # n_features contains the number of bits you want in your hash value. h = FeatureHasher(n_features = 3, input_type =’string’) # transforming the column after fitting hashed_Feature = h.fit_transform(df[‘nom_0’]) hashed_Feature = hashed_Feature.toarray() df = pd.concat([df, pd.DataFrame(hashed_Feature)], axis = 1) df.head(10)
6. Weight of Evidence Encoding
(WoE) Matlamat utama pembangunan adalah untuk mencipta model ramalan untuk menilai risiko mungkir pinjaman dalam industri kredit dan kewangan. Sejauh mana bukti menyokong atau menyangkal teori bergantung pada berat buktinya, atau WOE.
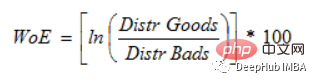
Jika P(Barang) / P(Bads) = 1, maka Celaka ialah 0. Jika keputusan untuk kumpulan ini adalah rawak, maka P(Bads) > P(Goods), nisbah odds ialah 1, dan berat bukti (WoE) ialah 0. Jika P(Barang) > P(buruk) dalam kumpulan, maka WoE lebih besar daripada 0.
因为Logit转换只是概率的对数,或ln(P(Goods)/P(bad)),所以WoE非常适合于逻辑回归。当在逻辑回归中使用wo编码的预测因子时,预测因子被处理成与编码到相同的尺度,这样可以直接比较线性逻辑回归方程中的变量。
例如下面的数据

会被编码为:

代码如下:
from category_encoders import WOEEncoder
df = pd.DataFrame({‘cat’: [‘a’, ‘b’, ‘a’, ‘b’, ‘a’, ‘a’, ‘b’, ‘c’, ‘c’], ‘target’: [1, 0, 0, 1, 0, 0, 1, 1, 0]})
woe = WOEEncoder(cols=[‘cat’], random_state=42)
X = df[‘cat’]
y = df.target
encoded_df = woe.fit_transform(X, y)7、Helmert Encoding
Helmert Encoding将一个级别的因变量的平均值与该编码中所有先前水平的因变量的平均值进行比较。
反向 Helmert 编码是类别编码器中变体的另一个名称。它将因变量的特定水平平均值与其所有先前水平的水平的平均值进行比较。

会被编码为

代码如下:
import category_encoders as ce encoder=ce.HelmertEncoder(cols=’Dept’) new_df=encoder.fit_transform(df[‘Dept’]) new_hdf=pd.concat([df,new_df], axis=1) new_hdf
8、Cat Boost Encoding
是CatBoost编码器试图解决的是目标泄漏问题,除了目标编码外,还使用了一个排序概念。它的工作原理与时间序列数据验证类似。当前特征的目标概率仅从它之前的行(观测值)计算,这意味着目标统计值依赖于观测历史。

TargetCount:某个类别特性的目标值的总和(到当前为止)。
Prior:它的值是恒定的,用(数据集中的观察总数(即行))/(整个数据集中的目标值之和)表示。
featucalculate:到目前为止已经看到的、具有与此相同值的分类特征的总数。

编码后的结果如下:

代码:
import category_encoders category_encoders.cat_boost.CatBoostEncoder(verbose=0, cols=None, drop_invariant=False, return_df=True, handle_unknown=’value’, handle_missing=’value’, random_state=None, sigma=None, a=1) target = df[[‘target’]] train = df.drop(‘target’, axis = 1) # Define catboost encoder cbe_encoder = ce.cat_boost.CatBoostEncoder() # Fit encoder and transform the features cbe_encoder.fit(train, target) train_cbe = cbe_encoder.transform(train)
9、James Stein Encoding
James-Stein 为特征值提供以下加权平均值:
- 观察到的特征值的平均目标值。
- 平均期望值(与特征值无关)。
James-Stein 编码器将平均值缩小到全局的平均值。该编码器是基于目标的。但是James-Stein 估计器有缺点:它只支持正态分布。
它只能在给定正态分布的情况下定义(实时情况并非如此)。为了防止这种情况,我们可以使用 beta 分布或使用对数-比值比转换二元目标,就像在 WOE 编码器中所做的那样(默认使用它,因为它很简单)。
10、M Estimator Encoding:
Target Encoder的一个更直接的变体是M Estimator Encoding。它只包含一个超参数m,它代表正则化幂。m值越大收缩越强。建议m的取值范围为1 ~ 100。
11、 Sum Encoder
Sum Encoder将类别列的特定级别的因变量(目标)的平均值与目标的总体平均值进行比较。在线性回归(LR)的模型中,Sum Encoder和ONE HOT ENCODING都是常用的方法。两种模型对LR系数的解释是不同的,Sum Encoder模型的截距代表了总体平均值(在所有条件下),而系数很容易被理解为主要效应。在OHE模型中,截距代表基线条件的平均值,系数代表简单效应(一个特定条件与基线之间的差)。
最后,在编码中我们用到了一个非常好用的Python包 “category-encoders”它还提供了其他的编码方法,如果你对他感兴趣,请查看它的官方文档:
http://contrib.scikit-learn.org/category_encoders/
Atas ialah kandungan terperinci 11 teknik pengekodan ciri klasifikasi biasa. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI