
Rumah >Peranti teknologi >AI >Daripada video kepada audio: pengelasan audio menggunakan VIT
Daripada video kepada audio: pengelasan audio menggunakan VIT

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-12 11:43:051076semak imbas
Mengenai pembelajaran mesin, audio itu sendiri adalah medan lengkap dengan pelbagai aplikasi, termasuk pengecaman pertuturan, klasifikasi muzik, pengesanan acara bunyi, dsb. Pengelasan audio secara tradisinya menggunakan kaedah seperti analisis spektrogram dan model Markov tersembunyi, yang telah terbukti berkesan tetapi juga mempunyai hadnya. Baru-baru ini VIT telah muncul sebagai alternatif yang menjanjikan untuk tugas audio, dengan Whisper OpenAI menjadi contoh yang baik.

Pengenalan Set Data
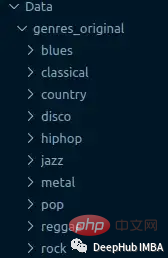
Dataset GTZAN ialah set data awam yang paling biasa digunakan dalam penyelidikan pengecaman genre muzik (MGR). Fail-fail tersebut dikumpulkan pada tahun 2000-2001 daripada pelbagai sumber, termasuk CD peribadi, radio, rakaman mikrofon, dan mewakili bunyi dalam pelbagai keadaan rakaman.
Dataset data ini terdiri daripada subfolder, setiap satunya adalah jenis.
Memuatkan Set Data
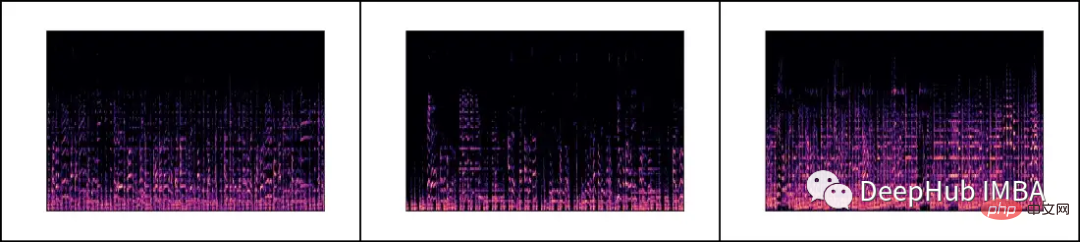
Kami akan memuatkan setiap fail .wav dan menjana spektrum Mel yang sepadan melalui perpustakaan librosa.
Spektrogram mel ialah perwakilan visual kandungan spektrum isyarat bunyi Paksi menegaknya mewakili kekerapan pada skala mel dan paksi mendatar mewakili masa. Ia merupakan representasi yang biasa digunakan dalam pemprosesan isyarat audio, terutamanya dalam bidang pencarian maklumat muzik.
Mel scale (Bahasa Inggeris: mel scale) ialah skala muzik yang mengambil kira persepsi pic manusia. Kerana manusia tidak melihat julat linear frekuensi, ini bermakna kita lebih baik dalam mengesan perbezaan pada frekuensi rendah daripada pada frekuensi tinggi. Sebagai contoh, kita boleh dengan mudah membezakan antara 500 Hz dan 1000 Hz, tetapi kita mempunyai masa yang lebih sukar untuk memberitahu perbezaan antara 10,000 Hz dan 10,500 Hz, walaupun jarak antara mereka adalah sama. Jadi skala Mel menyelesaikan masalah ini, jika perbezaan dalam skala Mel adalah sama, bermakna perbezaan pic yang dirasakan oleh manusia akan sama.
def wav2melspec(fp):
y, sr = librosa.load(fp)
S = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=128)
log_S = librosa.amplitude_to_db(S, ref=np.max)
img = librosa.display.specshow(log_S, sr=sr, x_axis='time', y_axis='mel')
# get current figure without white border
img = plt.gcf()
img.gca().xaxis.set_major_locator(plt.NullLocator())
img.gca().yaxis.set_major_locator(plt.NullLocator())
img.subplots_adjust(top = 1, bottom = 0, right = 1, left = 0,
hspace = 0, wspace = 0)
img.gca().xaxis.set_major_locator(plt.NullLocator())
img.gca().yaxis.set_major_locator(plt.NullLocator())
# to pil image
img.canvas.draw()
img = Image.frombytes('RGB', img.canvas.get_width_height(), img.canvas.tostring_rgb())
return imgFungsi di atas akan menghasilkan spektrogram mel ringkas:

Sekarang kami memuatkan set data daripada folder dan menggunakan transformasi pada imej .
class AudioDataset(Dataset):
def __init__(self, root, transform=None):
self.root = root
self.transform = transform
self.classes = sorted(os.listdir(root))
self.class_to_idx = {c: i for i, c in enumerate(self.classes)}
self.samples = []
for c in self.classes:
for fp in os.listdir(os.path.join(root, c)):
self.samples.append((os.path.join(root, c, fp), self.class_to_idx[c]))
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
fp, target = self.samples[idx]
img = Image.open(fp)
if self.transform:
img = self.transform(img)
return img, target
train_dataset = AudioDataset(root, transform=transforms.Compose([
transforms.Resize((480, 480)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]))Model ViT
Kami akan menggunakan ViT sebagai model kami: Vision Transformer mula-mula memperkenalkan imej bersamaan dengan 16x16 perkataan dalam kertas dan berjaya menunjukkan ini Kaedah ini tidak bergantung pada mana-mana CNN , dan Transformer tulen yang digunakan secara langsung pada jujukan Tampalan imej boleh melaksanakan tugas pengelasan imej dengan baik.
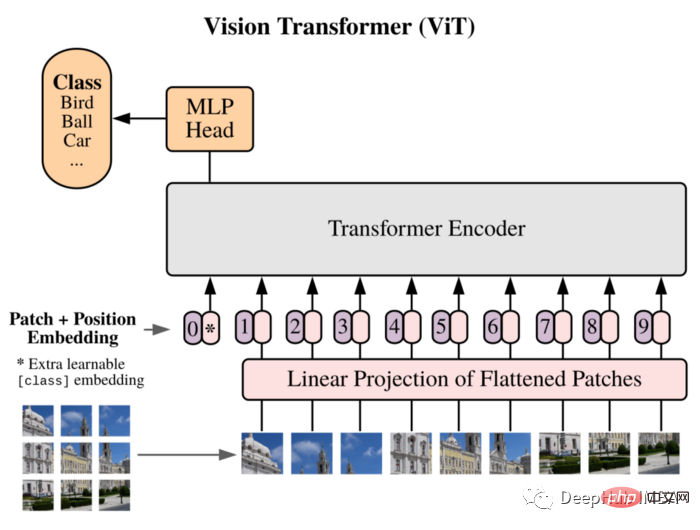
Pisahkan imej kepada Tampalan, dan gunakan urutan pembenaman linear Tampalan ini sebagai input Transformer. Patch diperlakukan dengan cara yang sama seperti token (perkataan) dalam aplikasi NLP.
Disebabkan kekurangan bias induktif (seperti lokaliti) yang wujud dalam CNN, Transformer tidak boleh membuat generalisasi dengan baik apabila jumlah data latihan tidak mencukupi. Tetapi apabila dilatih pada set data yang besar, ia memenuhi atau mengalahkan tercanggih pada berbilang tanda aras pengecaman imej.
Struktur yang dilaksanakan adalah seperti berikut:
class ViT(nn.Sequential): def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768, img_size: int = 356, depth: int = 12, n_classes: int = 1000, **kwargs): super().__init__( PatchEmbedding(in_channels, patch_size, emb_size, img_size), TransformerEncoder(depth, emb_size=emb_size, **kwargs), ClassificationHead(emb_size, n_classes)
Latihan
Gelung latihan juga merupakan proses latihan tradisional:
vit = ViT(
n_classes = len(train_dataset.classes)
)
vit.to(device)
# train
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
optimizer = optim.Adam(vit.parameters(), lr=1e-3)
scheduler = ReduceLROnPlateau(optimizer, 'max', factor=0.3, patience=3, verbose=True)
criterion = nn.CrossEntropyLoss()
num_epochs = 30
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
vit.train()
running_loss = 0.0
running_corrects = 0
for inputs, labels in tqdm.tqdm(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(True):
outputs = vit(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(train_dataset)
epoch_acc = running_corrects.double() / len(train_dataset)
scheduler.step(epoch_acc)
print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc))Ringkasan
Melatih pelaksanaan tersuai seni bina Vision Transformer ini dari awal menggunakan PyTorch. Oleh kerana set data adalah sangat kecil (hanya 100 sampel setiap kelas), ini menjejaskan prestasi model, dan hanya ketepatan 0.71 diperolehi.
Ini hanyalah demonstrasi mudah Jika anda perlu meningkatkan prestasi model, anda boleh menggunakan set data yang lebih besar, atau melaraskan sedikit pelbagai hiperparameter seni bina
Kod vit yang digunakan ini datang daripada:
https://medium.com/artificialis/vit-visiontransformer-a-pytorch-implementation-8d6a1033bdc5
Atas ialah kandungan terperinci Daripada video kepada audio: pengelasan audio menggunakan VIT. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI