
Rumah >Peranti teknologi >AI >Bercakap tentang AI berpusatkan data di sebalik model GPT
Bercakap tentang AI berpusatkan data di sebalik model GPT

- 王林ke hadapan
- 2023-04-11 23:55:011466semak imbas
Kecerdasan buatan (AI) membuat kemajuan besar dalam mengubah cara kita hidup, bekerja dan berinteraksi dengan teknologi. Baru-baru ini, bidang di mana kemajuan ketara telah dicapai ialah pembangunan model bahasa besar (LLM) seperti GPT-3, ChatGPT dan GPT-4. Model ini boleh melaksanakan tugas dengan tepat seperti terjemahan bahasa, ringkasan teks dan menjawab soalan.

Walaupun sukar untuk mengabaikan saiz model LLM yang semakin meningkat, adalah sama penting untuk menyedari bahawa kejayaan mereka sebahagian besarnya disebabkan oleh jumlah data yang besar yang digunakan untuk melatih mereka data berkualiti tinggi.
Dalam artikel ini, kami akan memberikan gambaran keseluruhan kemajuan terkini dalam LLM daripada perspektif AI yang mengutamakan data. Kami akan memeriksa model GPT melalui lensa AI berpusatkan data, konsep yang semakin berkembang dalam komuniti sains data. Kami mendedahkan konsep AI tertumpu data di sebalik model GPT dengan membincangkan tiga matlamat AI tertumpu data: pembangunan data latihan, pembangunan data inferens dan penyelenggaraan data.
Model Bahasa Besar (LLM) dan Model GPT
LLM ialah model pemprosesan bahasa semula jadi yang dilatih untuk membuat kesimpulan perkataan dalam konteks. Sebagai contoh, fungsi paling asas LLM adalah untuk meramalkan penanda yang hilang berdasarkan konteks. Untuk tujuan ini, LLM dilatih untuk meramalkan kebarangkalian setiap perkataan calon daripada jumlah data yang besar. Rajah di bawah ialah contoh ilustrasi menggunakan LLM dalam konteks untuk meramalkan kebarangkalian penanda hilang.

Model GPT merujuk kepada siri LLM yang dicipta oleh OpenAI, seperti GPT-1, GPT-2, GPT-3, InstructGPT, ChatGPT/GPT-4, dsb. . Seperti LLM lain, seni bina model GPT terutamanya berdasarkan Transformers, yang menggunakan pembenaman teks dan lokasi sebagai input dan menggunakan lapisan perhatian untuk memodelkan hubungan token.
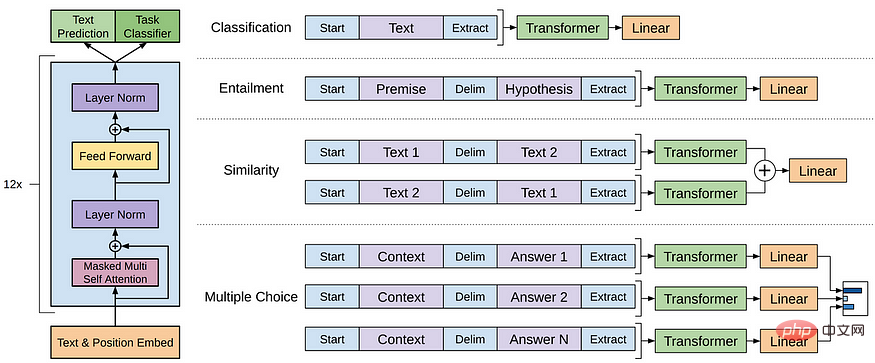
Seni bina model GPT-1
Model GPT kemudiannya menggunakan seni bina yang serupa dengan GPT-1, kecuali mereka menggunakan lebih banyak parameter model dan lebih banyak lapisan panjang konteks, saiz lapisan tersembunyi, dsb.

Apakah itu kecerdasan buatan berpusatkan data
AI berpusatkan data ialah cara pemikiran baharu yang muncul tentang cara membina sistem AI. AI berpusatkan data ialah disiplin mereka bentuk data secara sistematik yang digunakan untuk membina sistem kecerdasan buatan.
Pada masa lalu, kami telah memberi tumpuan terutamanya pada mencipta model yang lebih baik sambil mengekalkan data yang sebahagian besarnya tidak berubah (AI berpusatkan model). Walau bagaimanapun, pendekatan ini boleh menyebabkan masalah di dunia nyata kerana ia tidak mengambil kira isu berbeza yang boleh timbul dalam data, seperti ketidaktepatan label, pertindihan dan berat sebelah. Oleh itu, "overfitting" set data tidak semestinya membawa kepada tingkah laku model yang lebih baik.
Sebaliknya, AI berpusatkan data memfokuskan pada meningkatkan kualiti dan kuantiti data yang digunakan untuk membina sistem AI. Ini bermakna perhatian adalah pada data itu sendiri, dan modelnya secara relatifnya lebih tetap. Menggunakan pendekatan berpusatkan data untuk membangunkan sistem AI mempunyai potensi yang lebih besar dalam senario dunia sebenar, kerana data yang digunakan untuk latihan akhirnya menentukan keupayaan maksimum model.
Perlu diambil perhatian bahawa terdapat perbezaan asas antara "berpusatkan data" dan "berpandukan data". bukannya data.

Perbandingan antara kecerdasan buatan tertumpu data dan kecerdasan buatan tertumpu model
Rangka kerja AI tertumpu data mengandungi tiga Sasaran:
- Melatih pembangunan data ialah pengumpulan dan pengeluaran data yang kaya dan berkualiti tinggi untuk menyokong latihan model pembelajaran mesin.
- Pembangunan data inferens adalah untuk mencipta set penilaian baharu yang boleh memberikan cerapan yang lebih terperinci tentang model atau mencetuskan ciri khusus model melalui input data.
- Penyelenggaraan data adalah untuk memastikan kualiti dan kebolehpercayaan data dalam persekitaran yang dinamik. Penyelenggaraan data adalah penting kerana data dunia sebenar tidak dibuat sekali tetapi memerlukan penyelenggaraan berterusan.

Rangka kerja AI mengutamakan data
Mengapa AI mengutamakan data menjadikan model GPT berjaya
Beberapa bulan yang lalu , Yann LeCun tweet bahawa ChatGPT bukanlah perkara baru. Sebenarnya, semua teknik yang digunakan dalam ChatGPT dan GPT-4 (transformer, pembelajaran pengukuhan daripada maklum balas manusia, dll.) bukanlah baru sama sekali. Walau bagaimanapun, mereka mencapai keputusan yang tidak mungkin dengan model sebelumnya. Jadi, apakah sebab kejayaan mereka?
Melatih pembangunan data. Kuantiti dan kualiti data yang digunakan untuk melatih model GPT telah meningkat dengan ketara melalui pengumpulan data, pelabelan data dan strategi penyediaan data yang lebih baik.
-
GPT-1: Data data BooksCorpus digunakan untuk latihan. Set data mengandungi 4629.00 MB teks mentah yang meliputi pelbagai genre buku seperti pengembaraan, fantasi dan percintaan.
-Strategi AI mengutamakan data: Tiada.
- Keputusan: Menggunakan GPT-1 pada set data ini meningkatkan prestasi tugasan hiliran melalui penalaan halus. -
GPT-2: Gunakan WebText dalam latihan. Ini ialah set data dalaman dalam OpenAI yang dibuat dengan mengikis pautan keluar daripada Reddit.
- Strategi AI Berpusatkan Data: (1) Hanya gunakan pautan keluar daripada Reddit untuk memilih/menapis data yang memperoleh sekurang-kurangnya 3 karma. (2) Gunakan alatan Dragnet dan Newspaper untuk mengekstrak kandungan bersih. (3) Gunakan deduplikasi dan beberapa pembersihan berasaskan heuristik lain.
- Hasil: 40 GB teks selepas penapisan. GPT-2 mencapai hasil tangkapan sifar yang mantap tanpa penalaan halus. -
GPT-3: Latihan GPT-3 terutamanya berdasarkan Common Crawl.
-Strategi AI mengutamakan data: (1) Latih pengelas untuk menapis dokumen berkualiti rendah berdasarkan persamaan setiap dokumen dengan WebText (dokumen berkualiti tinggi). (2) Gunakan MinHashLSH Spark untuk mengaburkan dan menyahduplikasi dokumen. (3) Penambahan data menggunakan WebText, korpus buku dan Wikipedia.
- Keputusan: 570GB teks diperoleh selepas menapis 45TB plaintext (hanya 1.27% daripada data dipilih untuk penapisan kualiti ini). GPT-3 dengan ketara mengatasi GPT-2 dalam tetapan sampel sifar. -
ArahanGPT: Biarkan penilaian manusia melaraskan jawapan GPT-3 agar lebih sepadan dengan jangkaan manusia. Mereka mereka bentuk ujian untuk anotasi dan hanya mereka yang lulus ujian itu layak untuk anotasi. Mereka juga mereka bentuk tinjauan untuk memastikan pencatat terlibat sepenuhnya dalam proses anotasi.
-Strategi AI mengutamakan data: (1) Gunakan jawapan yang disediakan manusia untuk gesaan untuk menala model melalui latihan yang diselia. (2) Kumpul data perbandingan untuk melatih model ganjaran, dan kemudian gunakan model ganjaran ini untuk menala GPT-3 melalui pembelajaran pengukuhan dengan maklum balas manusia (RLHF).
- Keputusan: InstructGPT menunjukkan realisme yang lebih baik dan kurang berat sebelah, iaitu penjajaran yang lebih baik. - ChatGPT/GPT-4: OpenAI tidak mendedahkan butiran. Tetapi seperti yang kita semua tahu, ChatGPT/GPT-4 sebahagian besarnya mengikut reka bentuk model GPT sebelumnya, dan mereka masih menggunakan RLHF untuk menala model (mungkin dengan data/label yang lebih berkualiti dan lebih tinggi). Secara amnya diterima bahawa GPT-4 menggunakan set data yang lebih besar apabila berat model meningkat.
Pembangunan data inferens. Memandangkan model GPT terbaharu cukup berkuasa, kami boleh mencapai pelbagai matlamat dengan melaraskan pembayang atau melaraskan data inferens semasa model dibetulkan. Sebagai contoh, kita boleh melakukan ringkasan teks dengan menyediakan teks untuk diringkaskan dan arahan seperti "ringkaskan" atau "TL;DR" untuk membimbing proses penaakulan.

Laraskan dalam masa
Merancang gesaan penaakulan yang betul ialah tugas yang mencabar. Ia sangat bergantung pada heuristik. Tinjauan yang baik meringkaskan kaedah promosi yang berbeza. Kadangkala, isyarat yang serupa secara semantik pun boleh mempunyai output yang sangat berbeza. Dalam kes ini, penentukuran berasaskan kiu lembut mungkin diperlukan untuk mengurangkan varians.

Penyelidikan mengenai pembangunan data inferens LLM masih di peringkat awal. Dalam masa terdekat, lebih banyak teknik pembangunan data inferensi yang telah digunakan untuk tugasan lain boleh digunakan dalam LLM.
Penyelenggaraan data. Sebagai produk komersial, ChatGPT/GPT-4 bukan sahaja dilatih sekali, tetapi juga dikemas kini dan diselenggara secara berterusan. Jelas sekali, kami tidak mempunyai cara untuk mengetahui cara penyelenggaraan data dilakukan di luar OpenAI. Oleh itu, kami membincangkan beberapa strategi AI berpusatkan data umum yang telah atau mungkin akan digunakan untuk model GPT:
- Pengumpulan data berterusan: Apabila kami menggunakan ChatGPT/GPT-4 Petua/maklum balas kami mungkin seterusnya digunakan oleh OpenAI untuk memajukan lagi model mereka. Metrik kualiti dan strategi jaminan mungkin telah direka dan dilaksanakan untuk mengumpul data berkualiti tinggi semasa proses.
- Alat Memahami Data: Pelbagai alat boleh dibangunkan untuk menggambarkan dan memahami data pengguna, menggalakkan pemahaman yang lebih baik tentang keperluan pengguna dan membimbing arah penambahbaikan masa hadapan.
- Pemprosesan data yang cekap: Dengan pertumbuhan pesat bilangan pengguna ChatGPT/GPT-4, sistem pengurusan data yang cekap diperlukan untuk mencapai pengumpulan data yang pantas.

Gambar di atas adalah contoh ChatGPT/GPT-4 mengumpul maklum balas pengguna melalui "suka" dan "tidak suka".
Apa yang boleh dipelajari oleh komuniti sains data daripada gelombang LLM ini
Kejayaan LLM telah merevolusikan kecerdasan buatan. Melangkah ke hadapan, LLM boleh merevolusikan lagi kitaran hayat sains data. Kami membuat dua ramalan:
- Kepintaran buatan tertumpu data menjadi lebih penting. Selepas bertahun-tahun penyelidikan, reka bentuk model telah menjadi sangat matang, terutamanya selepas Transformer. Data menjadi cara utama untuk menambah baik sistem AI pada masa hadapan. Selain itu, apabila model menjadi cukup berkuasa, kita tidak perlu melatih model itu dalam kerja harian kita. Sebaliknya, kita hanya perlu mereka bentuk data inferens yang sesuai untuk meneroka pengetahuan daripada model. Oleh itu, penyelidikan dan pembangunan AI berpusatkan data akan memacu kemajuan masa depan.
- LLM akan membolehkan penyelesaian kecerdasan buatan berpusatkan data yang lebih baik
Banyak tugas sains data yang membosankan boleh menjadi lebih berkesan dengan bantuan LLM yang dijalankan. Contohnya, ChaGPT/GPT-4 sudah memungkinkan untuk menulis kod kerja untuk memproses dan membersihkan data. Tambahan pula, LLM juga boleh digunakan untuk mencipta data latihan. Contohnya, menggunakan LLM untuk menjana data sintetik boleh meningkatkan prestasi model dalam perlombongan teks.

Atas ialah kandungan terperinci Bercakap tentang AI berpusatkan data di sebalik model GPT. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI