
Rumah >pembangunan bahagian belakang >Tutorial Python >Applet pejabat automatik Python: merealisasikan automasi laporan dan menghantarnya secara automatik ke peti mel destinasi
Applet pejabat automatik Python: merealisasikan automasi laporan dan menghantarnya secara automatik ke peti mel destinasi

- PHPzke hadapan
- 2023-04-11 23:49:142241semak imbas

Hello semua! Saya Abang Tiger.
Latar Belakang Projek
Sebagai penganalisis data, kami perlu kerap membuat carta analisis statistik. Tetapi apabila terdapat terlalu banyak laporan, kami selalunya mengambil masa yang paling banyak untuk menciptanya. Ini melengahkan kami daripada menggunakan banyak masa untuk menjalankan analisis data. Tetapi sebagai penganalisis data, kita harus mencuba yang terbaik untuk mencungkil maklumat berkaitan yang tersembunyi di sebalik data dalam jadual dan carta, bukannya hanya membuat jadual dan carta statistik dan kemudian menghantar laporan.
1. Tujuan automasi laporan
1. Menjimatkan masa dan meningkatkan kecekapan
Automasi sentiasa boleh menjimatkan masa dan meningkatkan kecekapan kerja kami. Biarkan pengaturcaraan kami mengurangkan gandingan setiap kod pelaksanaan fungsi sebanyak mungkin dan mengekalkan kod tersebut dengan lebih baik. Ini akan menjimatkan banyak masa dan membebaskan kita untuk melakukan kerja yang lebih berharga dan bermakna.
2. Kurangkan ralat
Jika kesan pengekodan betul, ia boleh digunakan selama-lamanya Jika dilakukan secara manual, beberapa kesilapan mungkin dilakukan. Adalah lebih meyakinkan untuk menyerahkannya kepada program tetap Apabila keperluan berubah, hanya sebahagian daripada kod boleh diubah suai untuk menyelesaikan masalah.
2. Skop automasi laporan
Pertama sekali, kami perlu merumuskan laporan yang kami perlukan mengikut keperluan perniagaan Tidak setiap laporan perlu diautomasikan, dan beberapa data penunjuk pembangunan sekunder yang kompleks Ia agak rumit untuk melaksanakan pengaturcaraan automatik, dan pelbagai pepijat mungkin disembunyikan. Oleh itu, kami perlu meringkaskan ciri-ciri laporan yang kami gunakan dalam kerja kami Berikut adalah beberapa aspek yang perlu kami pertimbangkan secara menyeluruh:
1 Kekerapan
Bagi sesetengah perniagaan, ia adalah Jadual yang sering digunakan yang mungkin kami ingin sertakan dalam skop prosedur automatik. Contohnya, senarai maklumat pelanggan, laporan aliran jualan, laporan kerugian perniagaan, laporan bulan ke bulan dan tahun ke tahun, dsb.
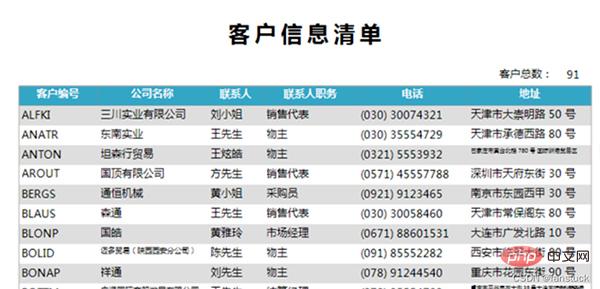
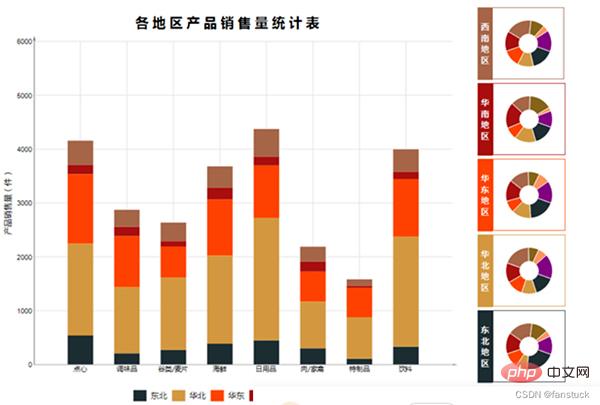
Ia adalah perlu untuk mengautomasikan laporan yang kerap digunakan ini. Bagi laporan yang perlu digunakan sekali-sekala, atau untuk penunjuk pembangunan sekunder, atau laporan yang perlu menyalin statistik, tidak perlu mengautomasikan laporan ini.
2. Masa pembangunan
Ini bersamaan dengan kos dan kadar faedah Jika sukar untuk mengautomasikan beberapa laporan dan melebihi masa yang diperlukan untuk analisis statistik biasa kami, tidak perlu mengautomasikan. ia. Oleh itu, apabila memulakan kerja automasi, anda perlu mengukur sama ada masa yang digunakan untuk membangunkan skrip atau masa yang dihabiskan untuk membuat jadual secara manual adalah lebih pendek. Sudah tentu, saya akan menyediakan satu set penyelesaian pelaksanaan, tetapi hanya untuk beberapa laporan yang biasa digunakan dan mudah.
3. Proses
Untuk setiap proses dan langkah laporan kami, setiap syarikat adalah berbeza Kami perlu kod mengikut senario perniagaan untuk melaksanakan fungsi setiap langkah. Oleh itu, proses yang kami buat harus konsisten dengan logik perniagaan, dan program yang kami buat juga harus logik.
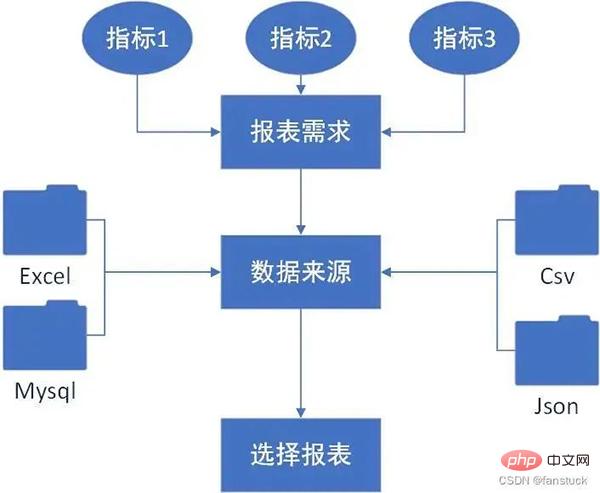
3. Langkah-langkah pelaksanaan
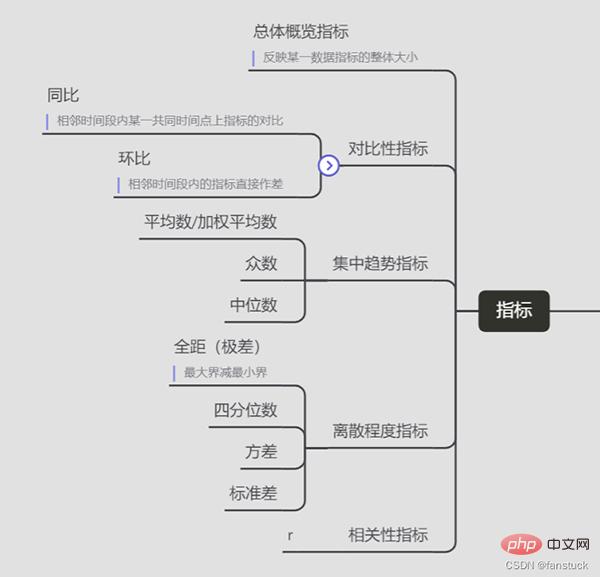
Mula-mula kita perlu tahu apakah indikator yang kita perlukan:
Petunjuk
- Penunjuk gambaran keseluruhan
Mencerminkan saiz keseluruhan penunjuk data tertentu
- Penunjuk perbandingan
- Monogram
Bersebelahan Perbezaan langsung antara penunjuk dalam tempoh masa
- YoY
Perbandingan penunjuk pada titik masa biasa dalam tempoh masa bersebelahan
- Kecenderungan pusat penunjuk
- Median
- Mod
- Min/Min Wajaran
- Penunjuk serakan
- Sisihan piawai
- Variance
- Kuartil
- Julat penuh (julat)
- Julat maksimum tolak batas minimum
- Indeks korelasi
- r
Kami mengambil laporan ringkas untuk mensimulasikan:
Langkah 1: Baca fail sumber data
Mula-mula kita perlu memahami dari mana data kita datang, itu ialah, sumber data. Pemprosesan data akhir kami ditukar kepada DataFrame untuk analisis, jadi sumber data perlu ditukar kepada bentuk DataFrame:
import pandas as pd
import json
import pymysql
from sqlalchemy import create_engine
# 打开数据库连接
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
passwd='xxxx',
charset = 'utf8'
)
engine=create_engine('mysql+pymysql://root:xxxx@localhost/mysql?charset=utf8')
def read_excel(file):
df_excel=pd.read_excel(file)
return df_excel
def read_json(file):
with open(file,'r')as json_f:
df_json=pd.read_json(json_f)
return df_json
def read_sql(table):
sql_cmd ='SELECT * FROM %s'%table
df_sql=pd.read_sql(sql_cmd,engine)
return df_sql
def read_csv(file):
df_csv=pd.read_csv(file)
return df_csvKod di atas boleh digunakan secara normal selepas lulus ujian, tetapi fungsi baca panda adalah untuk Bentuk bacaan fail yang berbeza mempunyai makna yang berbeza untuk parameter fungsi baca, yang perlu diselaraskan terus mengikut bentuk jadual.
Fungsi baca lain akan ditambah selepas artikel ditulis Kecuali read_sql perlu disambungkan ke pangkalan data, yang lain adalah agak mudah.
Langkah 2: Pengiraan DataFrame
Mari kita ambil maklumat pengguna sebagai contoh:
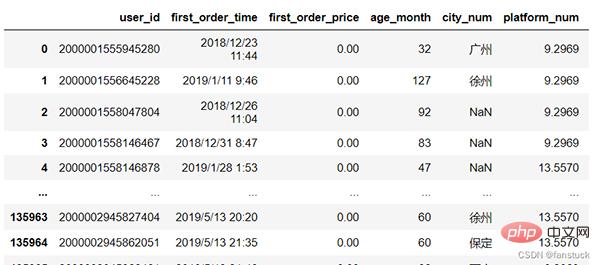
我们需要统计的指标为:
- #指标说明
- 单表图:
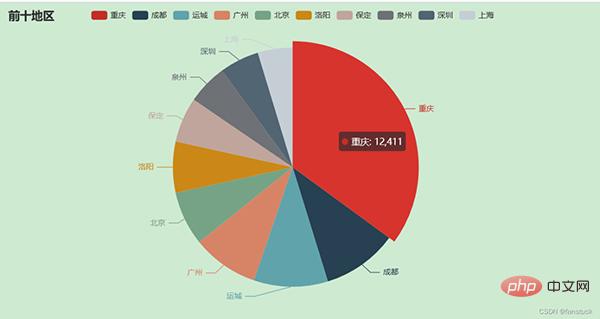
- 前十个产品受众最多的地区
#将城市空值的一行删除 df=df[df['city_num'].notna()] #删除error df=df.drop(df[df['city_num']=='error'].index) #统计df = df.city_num.value_counts()

我们仅获取前10名的城市就好了,封装为饼图:
def pie_chart(df):
#将城市空值的一行删除
df=df[df['city_num'].notna()]
#删除error
df=df.drop(df[df['city_num']=='error'].index)
#统计
df = df.city_num.value_counts()
df.head(10).plot.pie(subplots=True,figsize=(5, 6),autopct='%.2f%%',radius = 1.2,startangle = 250,legend=False)
pie_chart(read_csv('user_info.csv'))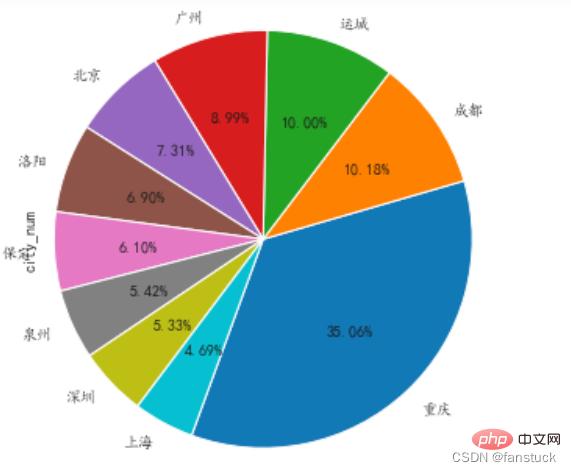
将图表保存起来:
plt.savefig('fig_cat.png')要是你觉得matplotlib的图片不太美观的话,你也可以换成echarts的图片,会更加好看一些:
pie = Pie()
pie.add("",words)
pie.set_global_opts(title_opts=opts.TitleOpts(title="前十地区"))
#pie.set_series_opts(label_opts=opts.LabelOpts(user_df))
pie.render_notebook()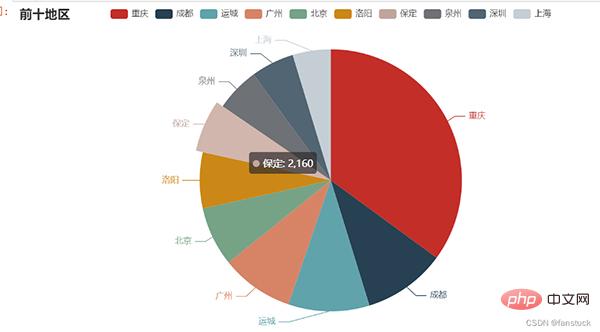
封装后就可以直接使用了:
def echart_pie(user_df):
user_df=user_df[user_df['city_num'].notna()]
user_df=user_df.drop(user_df[user_df['city_num']=='error'].index)
user_df = user_df.city_num.value_counts()
name=user_df.head(10).index.tolist()
value=user_df.head(10).values.tolist()
words=list(zip(list(name),list(value)))
pie = Pie()
pie.add("",words)
pie.set_global_opts(title_opts=opts.TitleOpts(title="前十地区"))
#pie.set_series_opts(label_opts=opts.LabelOpts(user_df))
return pie.render_notebook()
user_df=read_csv('user_info.csv')
echart_pie(user_df)可以进行保存,可惜不是动图:
from snapshot_selenium import snapshot make_snapshot(snapshot,echart_pie(user_df).render(),"test.png")
保存为网页的形式就可以自动加载JS进行渲染了:
echart_pie(user_df).render('problem.html')
os.system('problem.html')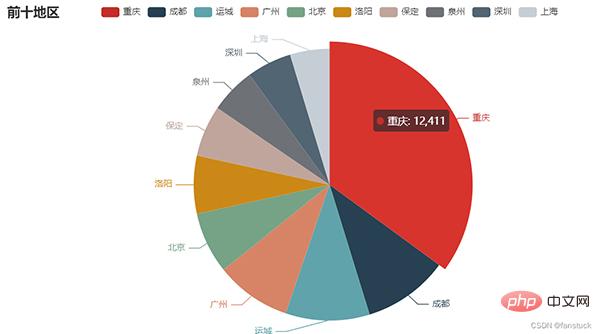
第三步:自动发送邮件
做出来的一系列报表一般都要发给别人看的,对于一些每天需要发送到指定邮箱或者需要发送多封报表的可以使用Python来自动发送邮箱。
在Python发送邮件主要借助到smtplib和email这个两个模块。
- smtplib:主要用来建立和断开与服务器连接的工作。
- email:主要用来设置一些些与邮件本身相关的内容。
不同种类的邮箱服务器连接地址不一样,大家根据自己平常使用的邮箱设置相应的服务器进行连接。这里博主用网易邮箱展示:
首先需要开启POP3/SMTP/IMAP服务:
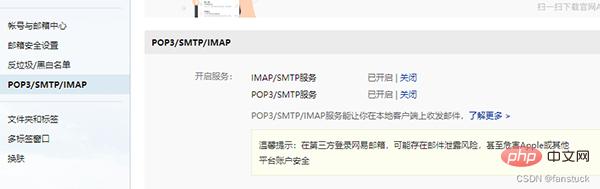
之后便可以根据授权码使用python登入了。
import smtplib
from email import encoders
from email.header import Header
from email.utils import parseaddr,formataddr
from email.mime.application import MIMEApplication
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
#发件人邮箱
asender="fanstuck@163.com"
#收件人邮箱
areceiver="1079944650@qq.com"
#抄送人邮箱
acc="fanstuck@163.com"
#邮箱主题
asubject="谢谢关注"
#发件人地址
from_addr="fanstuck@163.com"
#邮箱授权码
password="####"
#邮件设置
msg=MIMEMultipart()
msg['Subject']=asubject
msg['to']=areceiver
msg['Cc']=acc
msg['from']="fanstuck"
#邮件正文
body="你好,欢迎关注fanstuck,您的关注就是我继续创作的动力!"
msg.attach(MIMEText(body,'plain','utf-8'))
#添加附件
htmlFile = 'C:/Users/10799/problem.html'
html = MIMEApplication(open(htmlFile , 'rb').read())
html.add_header('Content-Disposition', 'attachment', filename='html')
msg.attach(html)
#设置邮箱服务器地址和接口
smtp_server="smtp.163.com"
server = smtplib.SMTP(smtp_server,25)
server.set_debuglevel(1)
#登录邮箱
server.login(from_addr,password)
#发生邮箱
server.sendmail(from_addr,areceiver.split(',')+acc.split(','),msg.as_string())
#断开服务器连接
server.quit()运行测试:
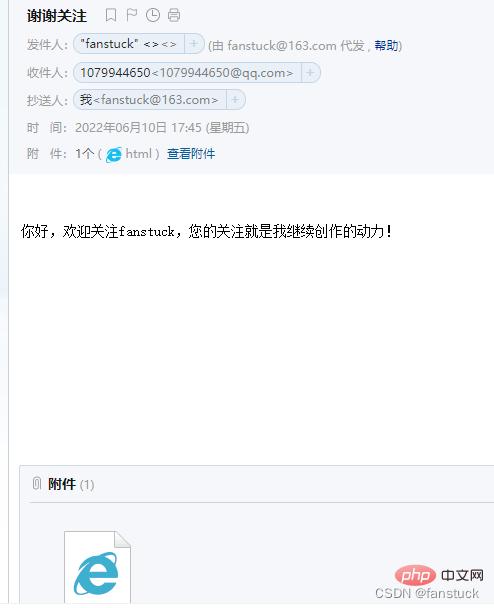
下载文件:
完全没问题!!!
Atas ialah kandungan terperinci Applet pejabat automatik Python: merealisasikan automasi laporan dan menghantarnya secara automatik ke peti mel destinasi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!