
Rumah >Peranti teknologi >AI >Amalan algoritma pembelajaran kontrastif di Zhuanzhuan
Amalan algoritma pembelajaran kontrastif di Zhuanzhuan

- 王林ke hadapan
- 2023-04-11 21:25:122044semak imbas
- 1 Apakah pembelajaran kontrastif
- 1.1 Definisi pembelajaran kontrastif
- 1.2 Prinsip pembelajaran kontrastif
- 1.3 Siri Algoritma Pembelajaran Kontrastif Klasik
- 2 Aplikasi Pembelajaran Kontrastif
- 3 Amalan Pembelajaran Kontrastif di Zhuanzhuan
- 3.1 CL dalam amalan ingat semula yang disyorkan
- 3.2 Perancangan masa depan CL di Zhuanzhuan
1 Apakah itu pembelajaran perbandingan
1.1 Definisi pembelajaran perbandingan
Kontras Kontras Pembelajaran (CL) ialah hala tuju penyelidikan yang popular dalam bidang AI sejak beberapa tahun kebelakangan ini, menarik perhatian ramai penyelidik Kaedah pembelajaran penyeliaan sendiri dinamakan AI di ICLR 2020 oleh nama besar seperti Bengio dan LeCun. ia akan mengambil bahagian secara berturut-turut dalam persidangan utama seperti NIPS, ACL, KDD, CIKM, dsb. Google, Facebook, DeepMind, Alibaba, Tencent, Byte dan syarikat utama lain juga telah melabur di dalamnya, dan kerja berkaitan CL juga telah memaksimumkan CV. Malah SOTA beberapa masalah NLP telah menjadi tumpuan dalam kalangan AI untuk seketika.
Sumber teknikal CL berasal daripada pembelajaran metrik Idea umum ialah: tentukan contoh positif dan negatif sampel, serta hubungan pemetaan (memetakan entiti ke ruang baharu), dan pengoptimuman. matlamat adalah untuk membuat contoh positif dalam ruang Jarak antara sampel sasaran dan sampel sasaran adalah lebih dekat, manakala contoh negatif agak jauh. Oleh sebab itu, CL kelihatan sangat mirip dengan idea ingatan semula vektor, tetapi sebenarnya terdapat perbezaan penting antara kedua-dua ingatan semula Vektor adalah sejenis pembelajaran yang diselia, dengan data label yang jelas, dan lebih menekankan pemilihan negatif. sampel ( Dikenali sebagai "doktrin" bahawa sampel negatif adalah raja); dan CL ialah cabang pembelajaran penyeliaan sendiri (paradigma pembelajaran tanpa pengawasan) yang tidak memerlukan maklumat label manual dan secara langsung menggunakan data itu sendiri sebagai maklumat penyeliaan untuk belajar sampel Ungkapan ciri data, dan kemudian dirujuk dalam tugas hiliran. Selain itu, teknologi teras CL ialah penambahan data, yang lebih memfokuskan kepada cara membina sampel positif. Rajah di bawah ialah carta alir keseluruhan CL abstrak

Maklumat label pembelajaran kontrastif datang daripada data itu sendiri, dan modul teras ialah peningkatan data. Teknologi peningkatan data dalam medan imej adalah agak intuitif Contohnya, operasi seperti putaran imej, oklusi, pengekstrakan separa, pewarnaan dan pengaburan boleh menghasilkan imej baharu yang secara amnya serupa dengan imej asal tetapi sebahagiannya berbeza (iaitu, imej. imej baharu yang dipertingkatkan). Rajah di bawah ialah kaedah peningkatan data imej separa (daripada SimCLR[1]).

1.2 Prinsip Pembelajaran Kontrastif
Apabila bercakap tentang prinsip CL, kita perlu menyebut pembelajaran penyeliaan kendiri, yang mengelakkan kos yang tinggi untuk anotasi manual, dan Kesederhanaan liputan label rendah memudahkan untuk mempelajari perwakilan ciri umum. Pembelajaran penyeliaan sendiri boleh dibahagikan kepada dua kategori utama: kaedah generatif dan kaedah kontrastif. Wakil tipikal kaedah generatif ialah pengekod auto, dan wakil klasik pembelajaran kontrastif ialah SimCLR ICLR 2020, yang mempelajari perwakilan ciri melalui perbandingan (dipertingkat) sampel positif dan negatif dalam ruang ciri. Berbanding dengan kaedah generatif, kelebihan kaedah kontrastif ialah mereka tidak perlu membina semula sampel pada tahap piksel, dan hanya perlu mempelajari kebolehbezaan dalam ruang ciri, yang menjadikan pengoptimuman berkaitan mudah. Penulis percaya bahawa keberkesanan CL dicerminkan terutamanya dalam mempelajari kebolehbezaan perwakilan item, dan pembelajaran kebolehbezaan bergantung pada idea pembinaan sampel positif dan negatif, serta struktur model khusus dan matlamat pengoptimuman.
Digabungkan dengan proses pelaksanaan CL,Dr Zhang[2]Ringkasan tiga soalan yang mesti dijawab oleh CL, yang juga merupakan perbezaan antara Ciri-ciri tipikal pembelajaran metrik ialah (1) cara membina contoh positif dan negatif, iaitu bagaimana peningkatan data dilaksanakan; (2) cara membina fungsi pemetaan Pengekod, yang bukan sahaja harus mengekalkan sebanyak mungkin maklumat asal; , tetapi juga menghalang masalah Runtuh; (3) Bagaimana untuk mereka bentuk fungsi kehilangan Kehilangan NCE yang biasa digunakan adalah seperti yang ditunjukkan dalam formula berikut. Tidak sukar untuk melihat bahawa tiga soalan asas ini sepadan dengan tiga elemen pemodelan: sampel, model dan algoritma pengoptimuman.
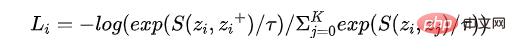
Antara tiga isu asas ini, peningkatan data ialah inovasi teras bagi algoritma CL yang berbeza adalah jaminan asas untuk keberkesanan algoritma dan identiti algoritma CL utama biasanya dilaksanakan dengan bantuan rangkaian saraf; kecuali Selain kehilangan NCE, terdapat variasi kehilangan lain, seperti Google[3] mencadangkan kehilangan kontras yang diawasi.
1.3 Siri Algoritma Pembelajaran Kontrastif Klasik
CL ialah algoritma pembelajaran pembelajaran penyeliaan sendiri Apabila ia berkaitan dengan pembelajaran penyeliaan sendiri, Bert mungkin merupakan topik yang tidak dapat dielakkan dalam bidang NLP pra-latihan + Fine Model -tala telah mencapai kejayaan dalam menyelesaikan banyak masalah Memandangkan penyeliaan kendiri boleh berjaya dalam NLP, tidakkah visi komputer juga boleh melakukannya? Malah, kejayaan Bert dalam bidang NLP juga secara langsung merangsang kejadian dan perkembangan CL dalam bidang imej. Memandangkan fakta bahawa peningkatan data boleh dilakukan secara intuitif dalam bidang imej, CL juga merupakan yang pertama membuat kemajuan dalam bidang CV Sebagai contoh, peluang pembangunan algoritma CL - SimCLR, mata inovasinya terutamanya termasuk (. 1) meneroka gabungan pelbagai teknologi peningkatan data yang berbeza, Yang optimum dipilih; (2) Projektor pemetaan tak linear ditambah selepas Pengekod, terutamanya kerana perwakilan vektor yang dipelajari oleh Pengekod akan merangkumi maklumat yang dipertingkatkan, manakala Projektor bertujuan untuk alih keluar bahagian pengaruh ini dan kembali kepada intipati data. Kemudian, pelajar Hinton melaksanakan SimCLR v2 berdasarkan SimCLR Penambahbaikan utama adalah dalam struktur rangkaian Pengekod Mereka juga menggunakan idea Bank Memori yang digunakan oleh MoCo untuk menambah baik SOTA.
Malah, sebelum SimCLR, Kaiming He mencadangkan satu lagi algoritma klasik untuk pembelajaran kontrastif pada penghujung 2019 MoCo[4] Utama idea ialah memandangkan perbandingan adalah antara sampel positif dan negatif, menambah bilangan sampel negatif boleh meningkatkan kesukaran tugasan pembelajaran dan dengan itu meningkatkan prestasi model Bank Memori adalah idea klasik untuk menyelesaikan masalah ini, tetapi ia tidak dapat mengelakkan ketidakkonsistenan perwakilan . Memandangkan masalah ini, algoritma MoCo mencadangkan untuk menggunakan momentum untuk mengemas kini parameter Pengekod untuk menyelesaikan masalah pengekodan tidak konsisten sampel calon baru dan lama. Kemudian, Kaiming He mencadangkan MoCo v2 berdasarkan MoCo (selepas SimCLR dicadangkan Rangka kerja utama model tidak diubah, dan butiran seperti kaedah peningkatan data, struktur Pengekod dan kadar pembelajaran telah dioptimumkan.
2 Aplikasi Pembelajaran Kontrastif
Pembelajaran kontrastif bukan sahaja hala tuju penyelidikan yang popular dalam akademik dalam banyak bidang seperti imej, teks, dan pelbagai mod, tetapi juga dalam industri yang diwakili oleh sistem pengesyoran dunia telah diterapkan.
Google menggunakan CL pada sistem pengesyoranGoogle SSL[5], bertujuan untuk belajar daripada item yang tidak popular dan khusus Perwakilan vektor berkualiti tinggi untuk membantu menyelesaikan masalah permulaan sejuk cadangan. Teknologi peningkatan datanya terutamanya menggunakan kaedah Random Feature Masking (RFM) dan Correlated Feature masking (CFM) (CFM menyelesaikan masalah yang RFM mungkin membina varian tidak sah pada tahap tertentu), dan kemudian CL digabungkan dengan menara berkembar dalam bentuk sebuah menara tambahan. Tugas utama penarikan balik dilatih bersama, dan proses keseluruhan ditunjukkan dalam rajah di bawah

Semasa proses latihan model, item-item bagi tugas utama terutamanya datang daripada log pendedahan, jadi ia juga adalah kepala Item popular adalah agak mesra Untuk menghapuskan pengaruh kesan Matthew, pembinaan sampel dalam tugas tambahan perlu mempertimbangkan pengedaran yang berbeza daripada tugas utama. CL seterusnya juga menggunakan pemikiran ini dalam proses amalan Zhuanzhuan untuk memastikan hasil pembelajaran model mendapat liputan yang mencukupi.
Peningkatan data tidak terhad kepada bahagian item, Alibaba-Seq2seq[6]Gunakan idea CL pada jujukan masalah cadangan, iaitu Masukkan urutan tingkah laku pengguna dan ramalkan kemungkinan item interaktif seterusnya. Khususnya, peningkatan datanya digunakan terutamanya pada ciri-ciri jujukan tingkah laku pengguna. Urutan tingkah laku sejarah pengguna dibahagikan kepada dua sub-jujukan mengikut siri masa Sebagai perwakilan pengguna selepas peningkatan data, ia dimasukkan ke dalam kembar-. model menara Lebih serupa hasil keluaran akhir, lebih baik. Pada masa yang sama, untuk memodelkan pelbagai minat pengguna secara eksplisit, artikel ini mengekstrak berbilang vektor dalam bahagian Pengekod dan bukannya memampatkannya menjadi satu vektor pengguna. Kerana dengan pemisahan susulan dan pembinaan contoh positif dan negatif, pengguna secara semula jadi mempunyai perwakilan vektor bagi jujukan tingkah laku berbilang Dalam contoh positif, vektor bahagian sebelumnya tingkah laku sejarah pengguna adalah hampir dengan vektor bahagian terakhir. tingkah laku sejarah, dan dalam contoh negatif, jarak antara pengguna yang berbeza adalah agak jauh, dan walaupun untuk pengguna yang sama, perwakilan vektor produk dalam kategori yang berbeza adalah agak jauh.
CL juga boleh digunakan dalam kombinasi dengan paradigma pembelajaran lain, Pembelajaran perbandingan graf[7], rangka kerja keseluruhan ditunjukkan dalam rajah di bawah

GCL biasanya meningkatkan data graf dengan memadamkan titik atau tepi secara rawak dalam graf, manakala pengarang artikel ini cenderung untuk mengekalkan struktur dan atribut penting tidak berubah, dan gangguan berlaku pada tepi atau nod yang tidak penting.
3 Pembelajaran kontrastif telah berjaya dalam amalan Zhuanzhuan
Dalam medan imej, ia juga boleh dilakukan dalam medan teks, sepertiMeituan-ConSERTAlgoritma [8], dalam eksperimen pada tugasan padanan semantik ayat, bertambah baik sebanyak 8% berbanding SOTA sebelumnya (aliran BERT), dan masih boleh menunjukkan peningkatan prestasi yang baik dengan bilangan sampel yang kecil. Algoritma ini menggunakan peningkatan data pada lapisan Embedding dan menggunakan kaedah menjana sampel yang dipertingkatkan secara tersirat Secara khusus, empat kaedah peningkatan data dicadangkan: Adversarial Attack, Token Shuffling, Cutoff dan Dropout, keempat-empat kaedah ini semuanya diperoleh dengan melaraskan matriks Embedding. yang lebih cekap daripada kaedah peningkatan eksplisit.
3.1 Amalan CL dalam mengesyorkan penarikan balik
Platform Zhuanzhuan komited untuk mempromosikan pembangunan ekonomi pekeliling rendah karbon yang lebih baik dan boleh merangkumi semua kategori barangan, terutamanya dalam prestasi pembangunan bidang 3C telefon bimbit dalam beberapa tahun kebelakangan ini. Amalan CL dalam sistem pengesyoran Zhuanzhuan juga memilih idea aplikasi berasaskan teks Memandangkan sifat unik transaksi terpakai, masalah yang perlu diselesaikan termasuk (1) atribut yatim barang terpakai, yang menjadikan vektor. kelas ID tidak berkenaan; (2) Bagaimana peningkatan data dilaksanakan; (3) Bagaimana contoh positif dan negatif dibina; Untuk menangani empat isu ini, penjelasan terperinci diberikan bersama dengan carta alir keseluruhan di bawah
Berkenaan masalah sifat anak yatim produk terpakai, kami menggunakan vektor berasaskan teks sebagai perwakilan produk. Secara khusus, kami menggunakan huraian teks set produk ( Termasuk tajuk dan kandungan), melatih model word2vec dan mendapatkan perwakilan vektor produk melalui pengumpulan berdasarkan vektor perkataan.
Algoritma Pengekod Auto ialah salah satu kaedah peningkatan data yang biasa digunakan dalam bidang pembelajaran perbandingan teks (selain terjemahan mesin, CBERT dan idea lain yang berbeza), kami juga menggunakan algoritma AE untuk melatih model , pelajari vektor produk dan gunakan vektor perantaraan algoritma sebagai perwakilan vektor yang dipertingkatkan bagi produk, dan anda akan mendapat contoh yang positif.
Prinsip pengeluaran contoh negatif ialah memilih produk yang berbeza secara rawak dalam Kelompok Asas untuk menilai produk yang serupa dikira berdasarkan gelagat klik belakang pengguna. Dalam keputusan penarikan balik sistem pengesyoran yang diwakili oleh CF (penapisan kolaboratif), gabungan produk yang boleh dipanggil semula melalui gelagat klik biasa dianggap serupa, jika tidak, gabungan produk itu dianggap tidak serupa. Sebab asas tingkah laku digunakan untuk menentukan persamaan adalah, dalam satu pihak, untuk memperkenalkan tingkah laku pengguna dan mencapai gabungan teks dan tingkah laku organik sebaliknya, ia juga untuk memadankan matlamat perniagaan sebanyak mungkin.
Khusus untuk bahagian Pengekod, kami menggunakan struktur menara berkembar yang serupa dengan rangkaian berkembar Kami menyuapkan vektor teks bagi sampel (positif atau positif atau negatif) untuk melatih model klasifikasi adalah rangkaian Neural tiga lapisan, kedua-dua menara berkongsi parameter rangkaian dan mengoptimumkan parameter model dengan mengoptimumkan kehilangan entropi silang. Dalam dunia perindustrian sebenar, sasaran latihan model menara berkembar dalam kebanyakan sistem pengesyoran ialah tingkah laku belakang pengguna (klik, koleksi, pesanan, dll.), dan sasaran latihan kami ialah sama ada sampelnya serupa atau tidak untuk mengamalkan bentuk rangkaian berkembar adalah, Ini juga kerana berbuat demikian dapat memastikan liputan hasil pembelajaran.
Menurut idea konvensional CL, vektor input bahagian Pengekod akhir diekstrak sebagai perwakilan vektor produk, yang boleh digunakan selanjutnya dalam penarikan balik, penarafan kasar dan juga penarafan halus pengesyoran sistem. Pada masa ini, modul penarikan balik sistem pengesyoran Zhuanzhuan telah dilaksanakan, yang telah meningkatkan pesanan dalam talian dan kadar beg lebih daripada 10%.
3.2 Perancangan masa depan CL di Zhuanzhuan
Melalui penilaian manual dan eksperimen AB dalam talian, keberkesanan perwakilan vektor yang dipelajari CL telah disahkan sepenuhnya Selepas modul panggilan semula dilaksanakan, ia boleh disyorkan Ini boleh diperluaskan kepada modul lain sistem dan juga senario algoritma lain. Mempelajari perwakilan vektor produk dengan cara pra-latihan (sudah tentu, anda juga boleh mempelajari perwakilan vektor pengguna) hanyalah laluan aplikasi CL menyediakan lebih banyak rangka kerja pembelajaran atau idea pembelajaran melalui peningkatan dan perbandingan data kebolehbezaan item. Idea ini secara semula jadi boleh diperkenalkan ke dalam modul pemeringkatan sistem pengesyoran, kerana masalah pemeringkatan juga boleh difahami sebagai masalah kebolehbezaan item.
Mengenai pengarang
Li Guangming, jurutera algoritma kanan. Mengambil bahagian dalam pembinaan sistem algoritma untuk algoritma carian Zhuanzhuan, algoritma pengesyoran, potret pengguna dan sistem lain, dan mempunyai aplikasi praktikal dalam GNN, pembelajaran sampel kecil, pembelajaran perbandingan dan bidang lain yang berkaitan.
Rujukan
[1]SimCLR: A_Kerangka_Mudah_untuk_Pembelajaran_Kontrastif_Perwakilan_Visual
[Jun]🎜>https://www.php.cn/link/be7ecaca534f98c4ca134e527b12d4c8
[3]Google: Google:
[4]MoCo: Momentum_Contrast_for_Unsupervised_Visual_Representation_Learning
[5]SSL: Self-Learning_Representation_LearningSelf-Learning 🎜>
[8]ConSERT: ConSERT:_A_Contrastive_Framework_for_Self-Supervised_Sentence_Representation_Transfer
Atas ialah kandungan terperinci Amalan algoritma pembelajaran kontrastif di Zhuanzhuan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI