
Rumah >pembangunan bahagian belakang >Tutorial Python >Panduan lengkap untuk pembersihan data dengan Python
Panduan lengkap untuk pembersihan data dengan Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-11 20:16:212481semak imbas
Anda pasti pernah mendengar petikan sains data terkenal ini:
Dalam projek sains data, 80% daripada masa adalah pemprosesan data.
Jika anda belum pernah mendengarnya, ingat: pembersihan data ialah asas aliran kerja sains data. Model pembelajaran mesin berprestasi berdasarkan data yang anda berikan kepada mereka Data yang tidak kemas boleh menyebabkan prestasi yang lemah atau malah hasil yang salah, manakala data yang bersih adalah prasyarat untuk prestasi model yang baik. Sudah tentu, data yang bersih tidak bermakna prestasi yang baik sepanjang masa Pemilihan model yang betul (baki 20%) juga penting, tetapi tanpa data yang bersih, walaupun model yang paling berkuasa tidak dapat mencapai tahap yang diharapkan.
Dalam artikel ini, kami akan menyenaraikan masalah yang perlu diselesaikan dalam pembersihan data dan menunjukkan penyelesaian yang mungkin melalui artikel ini, anda boleh belajar cara melakukan pembersihan data langkah demi langkah.
Nilai Hilang
Apabila set data mengandungi data yang tiada, beberapa analisis data boleh dilakukan sebelum mengisi. Kerana kedudukan sel kosong itu sendiri boleh memberitahu kami beberapa maklumat yang berguna. Contohnya:
- Nilai NA hanya muncul di bahagian ekor atau tengah set data. Ini bermakna mungkin terdapat isu teknikal semasa proses pengumpulan data. Ia mungkin perlu untuk menganalisis proses pengumpulan data untuk urutan sampel tertentu dan cuba mengenal pasti punca masalah.
- Jika bilangan NA dalam lajur melebihi 70–80%, anda boleh memadamkan lajur.
- Jika nilai NA berada dalam lajur sebagai soalan pilihan dalam borang, lajur itu boleh dikodkan sebagai tambahan apabila pengguna menjawab (1) atau tidak menjawab (0).
missingno Pustaka ular sawa ini boleh digunakan untuk menyemak situasi di atas, dan ia sangat mudah digunakan Sebagai contoh, garis putih dalam gambar di bawah ialah NA:
import missingno as msno msno.matrix(df)

Terdapat banyak kaedah untuk mengisi nilai yang hilang, seperti:
- Min, median, mod
- kNN
- Sifar atau Pemalar dsb.
Kaedah yang berbeza mempunyai kelebihan dan kekurangan antara satu sama lain, dan tiada teknik "terbaik" yang berfungsi dalam semua situasi. Untuk butiran, sila rujuk artikel kami yang diterbitkan sebelum ini
Outlier
Outlier ialah nilai yang sangat besar atau sangat kecil berbanding dengan titik lain dalam set data. Kehadiran mereka sangat mempengaruhi prestasi model matematik. Mari lihat contoh mudah ini:
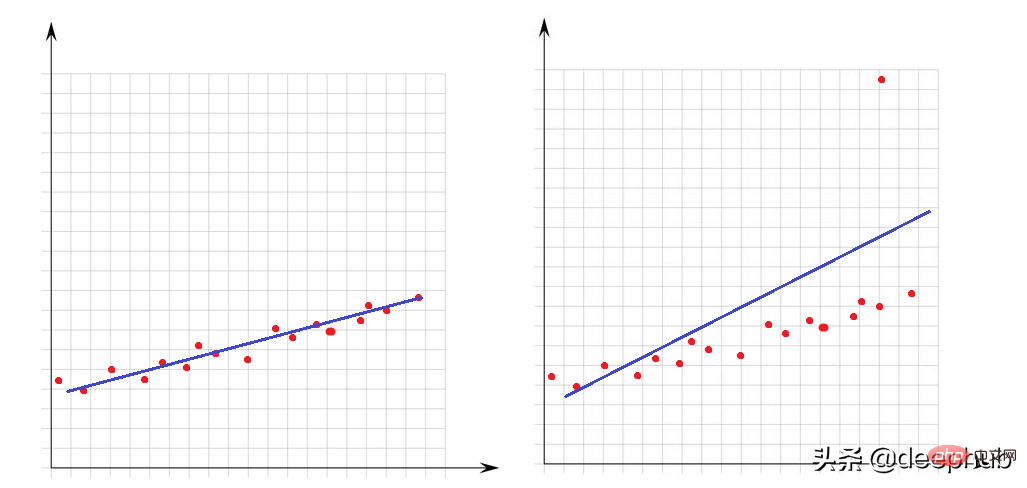
Dalam graf kiri tiada outlier dan model linear kami sangat sesuai dengan titik data. Dalam imej di sebelah kanan terdapat outlier, apabila model cuba menutup semua titik set data, kehadiran outlier ini mengubah cara model sesuai dan menjadikan model kami tidak sesuai untuk sekurang-kurangnya separuh daripada titik.
Untuk outlier, kami perlu memperkenalkan cara untuk menentukan anomali Ini memerlukan penjelasan apa yang maksimum atau minimum dari perspektif matematik.
Sebarang nilai yang lebih besar daripada Q3+1.5 x IQR atau kurang daripada Q1-1.5 x IQR boleh dianggap sebagai outlier. IQR (julat antara kuartil) ialah perbezaan antara Q3 dan Q1 (IQR = Q3-Q1).
Fungsi berikut boleh digunakan untuk menyemak bilangan outlier dalam set data:
def number_of_outliers(df): df = df.select_dtypes(exclude = 'object') Q1 = df.quantile(0.25) Q3 = df.quantile(0.75) IQR = Q3 - Q1 return ((df < (Q1 - 1.5 * IQR)) | (df > (Q3 + 1.5 * IQR))).sum()
Salah satu cara untuk menangani outlier adalah dengan menjadikannya sama dengan Q3 atau Q1. Fungsi lower_upper_range di bawah menggunakan pustaka panda dan numpy untuk mencari julat dengan outlier di luarnya, dan kemudian menggunakan fungsi klip untuk memotong nilai ke julat yang ditentukan.
def lower_upper_range(datacolumn): sorted(datacolumn) Q1,Q3 = np.percentile(datacolumn , [25,75]) IQR = Q3 - Q1 lower_range = Q1 - (1.5 * IQR) upper_range = Q3 + (1.5 * IQR) return lower_range,upper_range for col in columns: lowerbound,upperbound = lower_upper_range(df[col]) df[col]=np.clip(df[col],a_min=lowerbound,a_max=upperbound)
Data tidak konsisten
Masalah luar biasa ialah mengenai ciri berangka, kini mari kita lihat ciri jenis aksara (kategori). Data tidak konsisten bermakna kelas lajur yang unik mempunyai perwakilan yang berbeza. Sebagai contoh, dalam lajur jantina, terdapat kedua-dua m/f dan lelaki/perempuan. Dalam kes ini, terdapat 4 kelas, tetapi sebenarnya terdapat dua kelas.
Pada masa ini tiada penyelesaian automatik untuk masalah ini, jadi analisis manual diperlukan. Fungsi unik panda disediakan untuk analisis ini Mari kita lihat contoh jenama kereta:
df['CarName'] = df['CarName'].str.split().str[0] print(df['CarName'].unique())
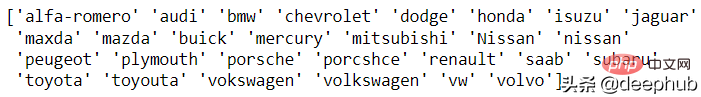
maxda-mazda, Nissan-nissan, porcshce-porsche. , toyouta -Toyota, dsb. boleh digabungkan.
df.loc[df['CarName'] == 'maxda', 'CarName'] = 'mazda' df.loc[df['CarName'] == 'Nissan', 'CarName'] = 'nissan' df.loc[df['CarName'] == 'porcshce', 'CarName'] = 'porsche' df.loc[df['CarName'] == 'toyouta', 'CarName'] = 'toyota' df.loc[df['CarName'] == 'vokswagen', 'CarName'] = 'volkswagen' df.loc[df['CarName'] == 'vw', 'CarName'] = 'volkswagen'
Data tidak sah
Data tidak sah mewakili nilai yang tidak betul secara logik sama sekali. Contohnya,
- Umur seseorang ialah 560;
- Pembedahan tertentu mengambil masa -8 jam;
- Ketinggian seseorang ialah 1200 cm, dsb.;
Untuk lajur angka, fungsi huraikan panda boleh digunakan untuk mengenal pasti ralat tersebut:
df.describe()
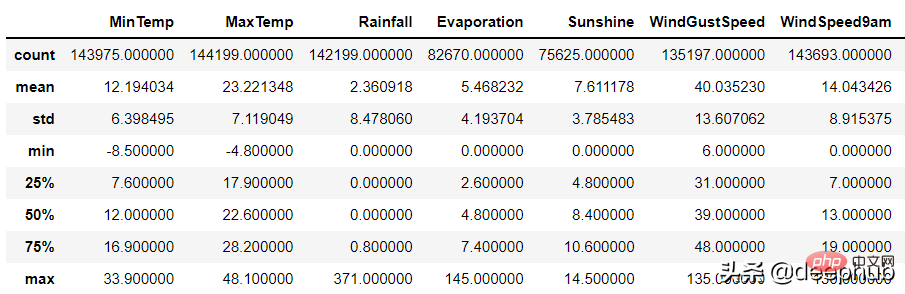
Mungkin terdapat dua sebab untuk data tidak sah:
1. Ralat pengumpulan data: Contohnya, julat tidak dinilai semasa input Apabila memasukkan ketinggian, 1799cm telah dimasukkan dengan salah dan bukannya 179cm, tetapi program tidak menilai julat data.
2. Ralat operasi data
数据集的某些列可能通过了一些函数的处理。 例如,一个函数根据生日计算年龄,但是这个函数出现了BUG导致输出不正确。
以上两种随机错误都可以被视为空值并与其他 NA 一起估算。
重复数据
当数据集中有相同的行时就会产生重复数据问题。 这可能是由于数据组合错误(来自多个来源的同一行),或者重复的操作(用户可能会提交他或她的答案两次)等引起的。 处理该问题的理想方法是删除复制行。
可以使用 pandas duplicated 函数查看重复的数据:
df.loc[df.duplicated()]
在识别出重复的数据后可以使用pandas 的 drop_duplicate 函数将其删除:
df.drop_duplicates()
数据泄漏问题
在构建模型之前,数据集被分成训练集和测试集。 测试集是看不见的数据用于评估模型性能。 如果在数据清洗或数据预处理步骤中模型以某种方式“看到”了测试集,这个就被称做数据泄漏(data leakage)。 所以应该在清洗和预处理步骤之前拆分数据:
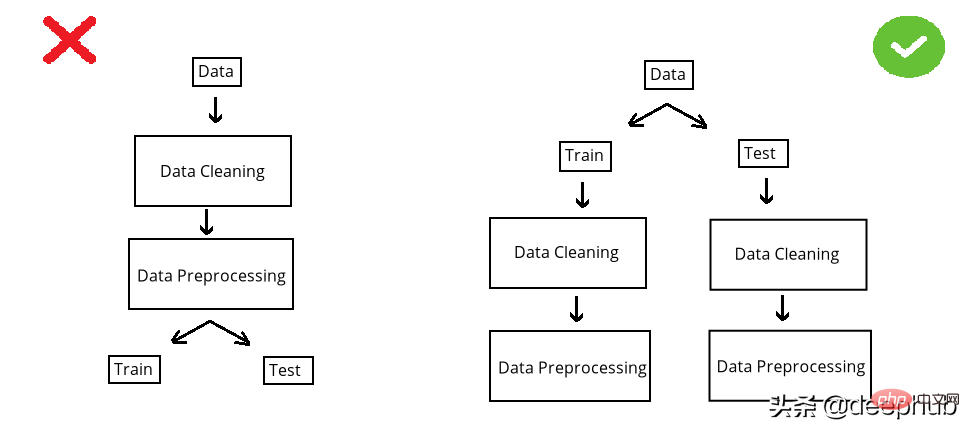
以选择缺失值插补为例。数值列中有 NA,采用均值法估算。在 split 前完成时,使用整个数据集的均值,但如果在 split 后完成,则使用分别训练和测试的均值。
第一种情况的问题是,测试集中的推算值将与训练集相关,因为平均值是整个数据集的。所以当模型用训练集构建时,它也会“看到”测试集。但是我们拆分的目标是保持测试集完全独立,并像使用新数据一样使用它来进行性能评估。所以在操作之前必须拆分数据集。
虽然训练集和测试集分别处理效率不高(因为相同的操作需要进行2次),但它可能是正确的。因为数据泄露问题非常重要,为了解决代码重复编写的问题,可以使用sklearn 库的pipeline。简单地说,pipeline就是将数据作为输入发送到的所有操作步骤的组合,这样我们只要设定好操作,无论是训练集还是测试集,都可以使用相同的步骤进行处理,减少的代码开发的同时还可以减少出错的概率。
Atas ialah kandungan terperinci Panduan lengkap untuk pembersihan data dengan Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!