
Rumah >Peranti teknologi >AI >Alamat perkhidmatan penyeragaman model pembelajaran mendalam AI amalan pengoptimuman inferens
Alamat perkhidmatan penyeragaman model pembelajaran mendalam AI amalan pengoptimuman inferens

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-11 19:28:111881semak imbas
Pengenalan
Pembelajaran mendalam telah dilaksanakan secara meluas dalam senario perniagaan sebenar dalam bidang seperti pemprosesan bahasa semula jadi, dan mengoptimumkan prestasi inferensnya telah menjadi bahagian penting dalam proses penempatan. Peningkatan prestasi penaakulan: Di satu pihak, ia boleh memberikan permainan sepenuhnya kepada keupayaan perkakasan yang digunakan, mengurangkan masa tindak balas pengguna, dan menjimatkan kos sebaliknya, ia boleh menggunakan model pembelajaran mendalam dengan struktur yang lebih kompleks sambil mengekalkan masa tindak balas; tidak berubah dengan itu meningkatkan penunjuk ketepatan perniagaan.
Artikel ini menjalankan kerja pengoptimuman prestasi inferens untuk model pembelajaran mendalam dalam perkhidmatan penyeragaman alamat. Melalui kaedah pengoptimuman seperti pengendali berprestasi tinggi, pengkuantitian dan pengoptimuman kompilasi, model kelajuan inferens hujung ke hujung model AI boleh dicapai sehingga 4.11 kali tanpa mengurangkan indeks ketepatan peningkatan.
1. Metodologi pengoptimuman prestasi inferens model
Pengoptimuman prestasi inferens model ialah salah satu aspek penting apabila menggunakan perkhidmatan AI. Di satu pihak, ia boleh meningkatkan kecekapan inferens model dan melepaskan sepenuhnya prestasi perkakasan. Sebaliknya, ia boleh membolehkan perniagaan menggunakan model yang lebih kompleks sambil mengekalkan kelewatan penaakulan tidak berubah, sekali gus meningkatkan indeks ketepatan. Walau bagaimanapun, terdapat beberapa kesukaran dalam mengoptimumkan prestasi penaakulan dalam senario sebenar.
1.1 Kesukaran dalam mengoptimumkan senario pemprosesan bahasa semula jadi
Dalam tugas pemprosesan bahasa semula jadi (NLP) biasa, rangkaian saraf berulang ( Rangkaian Neural Berulang, RNN) dan BERT [7] (Perwakilan Pengekod Dua Arah daripada Transformers.) ialah dua jenis struktur model dengan kadar penggunaan yang tinggi. Untuk memudahkan mekanisme penskalaan anjal dan keberkesanan kos yang tinggi bagi penggunaan perkhidmatan dalam talian, tugas pemprosesan bahasa semula jadi biasanya digunakan pada platform CPU x86 seperti pemproses Intel® Xeon®. Walau bagaimanapun, apabila senario perniagaan menjadi lebih kompleks, keperluan prestasi pengkomputeran inferens bagi perkhidmatan semakin tinggi dan lebih tinggi. Dengan mengambil model RNN dan BERT di atas sebagai contoh, cabaran prestasi apabila digunakan pada platform CPU adalah seperti berikut:
- RNN
Rangkaian saraf berulang ialah sejenis rangkaian saraf rekursif yang mengambil data jujukan sebagai input, melakukan rekursi dalam arah evolusi jujukan dan mempunyai semua nod (unit kitaran) disambungkan dalam rantai. RNN yang biasa digunakan dalam penggunaan sebenar termasuk LSTM, GRU dan beberapa varian terbitan. Semasa proses pengiraan, seperti yang ditunjukkan dalam rajah di bawah, setiap output peringkat seterusnya dalam struktur RNN bergantung pada input yang sepadan dan output peringkat sebelumnya. Oleh itu, RNN boleh menyelesaikan tugasan jenis urutan dan telah digunakan secara meluas dalam bidang NLP dan juga penglihatan komputer dalam beberapa tahun kebelakangan ini. Berbanding dengan BERT, RNN memerlukan kurang pengiraan dan berkongsi parameter model, tetapi kebergantungan pemasaan pengiraannya menjadikannya mustahil untuk melakukan pengiraan selari pada jujukan.
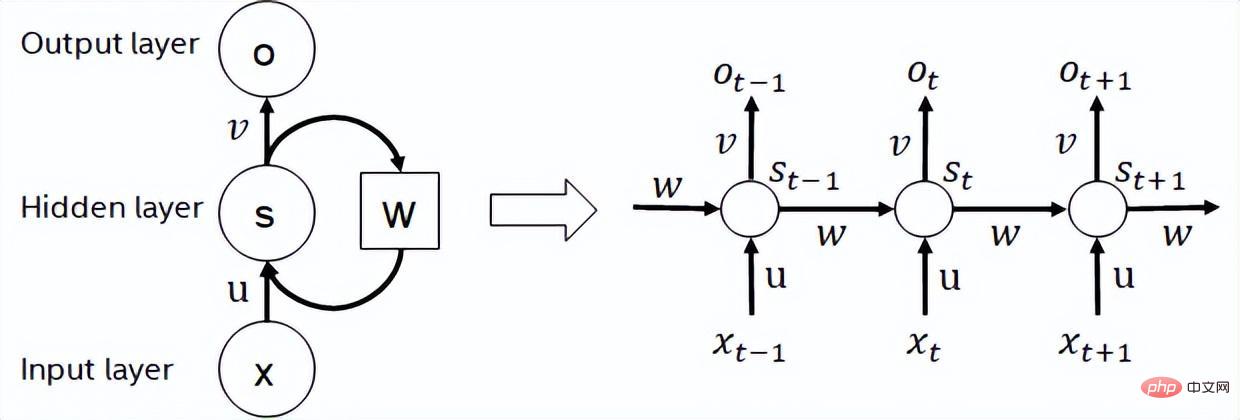
Rajah struktur RNN
- BERT
BERT[7] membuktikan bahawa ia boleh melengkapkan pra-latihan tanpa pengawasan (Unsupervised Pre-training) pada set data yang besar dengan struktur rangkaian yang lebih mendalam, dengan itu menyediakan model untuk penalaan halus (finetune) untuk tugasan tertentu . Ia bukan sahaja meningkatkan ketepatan tugas-tugas khusus ini, tetapi juga memudahkan proses latihan. Struktur model BERT adalah ringkas dan mudah dikembangkan Dengan hanya mendalami dan meluaskan rangkaian, anda boleh memperoleh ketepatan yang lebih baik daripada struktur RNN. Sebaliknya, peningkatan ketepatan datang dengan kos overhed pengkomputeran yang lebih besar Terdapat sejumlah besar operasi pendaraban matriks dalam model BERT, yang merupakan cabaran besar untuk CPU.
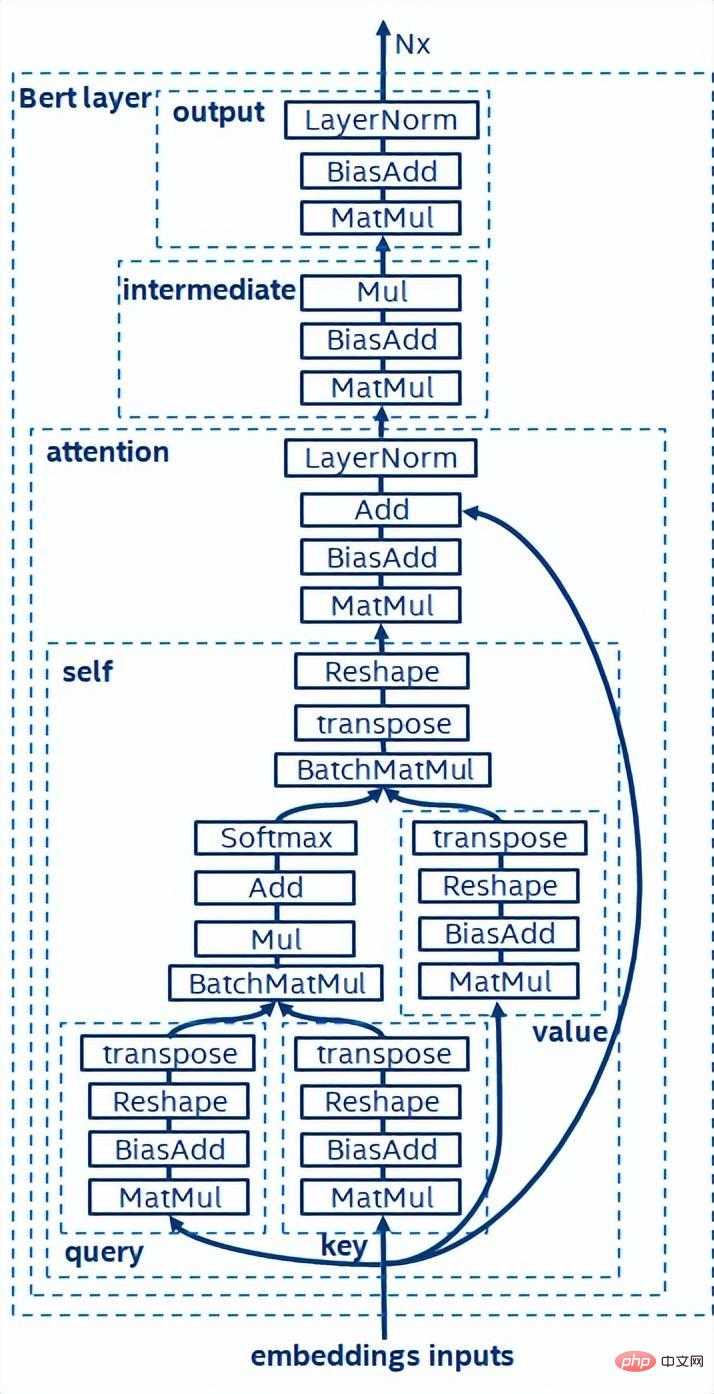
Gambarajah struktur model BERT
1.2 Strategi pengoptimuman inferens model
Berdasarkan di atas Untuk menganalisis cabaran prestasi inferens, kami percaya bahawa pengoptimuman inferens model daripada tahap tindanan perisian terutamanya merangkumi strategi berikut:
- Mampatan model: termasuk kuantiti, jarang, pemangkasan, dsb.
- Pengendali berprestasi tinggi untuk senario tertentu
- Pengoptimuman pengkompil AI
Kuantiti
Kuantasi model merujuk kepada menganggarkan nilai pengaktifan titik terapung atau pemberat (biasanya diwakili oleh nombor titik terapung 32-bit) ke dalam integer bit rendah (16-bit atau 8-bit), dan kemudian melengkapkan pengiraan dalam proses perwakilan bit rendah. Secara umumnya, pengkuantitian model boleh memampatkan parameter model , dengan itu mengurangkan overhed storan model dan dengan mengurangkan akses memori dan menggunakan arahan pengkomputeran bit rendah secara berkesan (seperti Intel® Deep Learning Boost Vector Neural Network Instructions, VNNI) , Dapatkan peningkatan inferens.
Memandangkan nilai titik terapung, kita boleh memetakannya kepada nilai bit yang rendah dengan formula berikut:
di mana jumlahnya diperolehi dengan algoritma kuantisasi. Berdasarkan ini, mengambil operasi Gemm sebagai contoh, dengan mengandaikan terdapat proses pengiraan titik terapung:
Kita boleh melengkapkan proses pengiraan yang sepadan dalam domain bit rendah:
Pengendali berprestasi tinggi
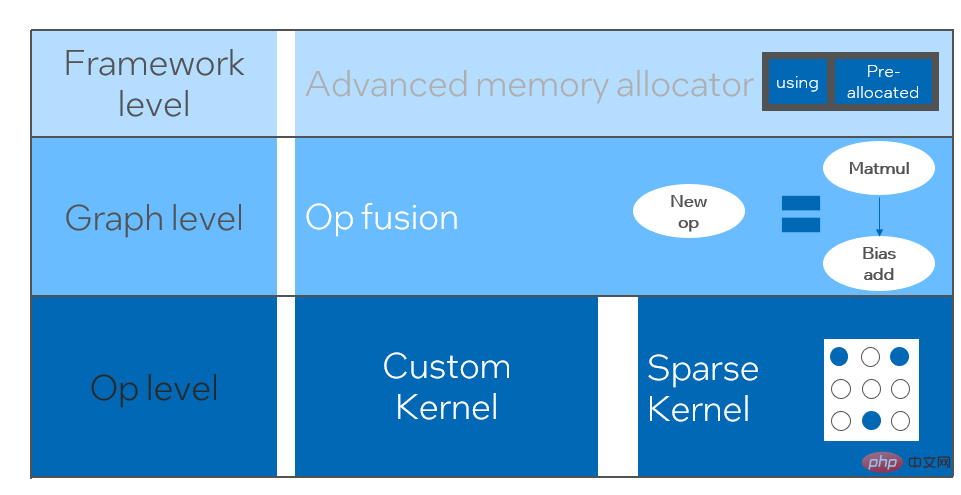
Dalam rangka kerja pembelajaran mendalam, untuk mengekalkan serba boleh sambil mengambil kira pelbagai proses (seperti sebagai latihan), inferens overhed pengendali Terdapat lebihan. Apabila struktur model ditentukan, proses penaakulan operator hanyalah subset daripada proses penuh asal. Oleh itu, apabila struktur model ditentukan, kita boleh melaksanakan pengendali inferens berprestasi tinggi dan menggantikan pengendali am dalam model asal untuk meningkatkan kelajuan inferens.
Kunci untuk melaksanakan pengendali berprestasi tinggi pada CPU adalah untuk mengurangkan akses memori dan menggunakan set arahan yang lebih cekap. Dalam proses pengiraan pengendali asal, dalam satu tangan, terdapat sejumlah besar pembolehubah perantaraan, dan pembolehubah ini akan melakukan sejumlah besar operasi baca dan tulis pada memori, sekali gus memperlahankan kelajuan penaakulan. Sebagai tindak balas kepada situasi ini, kami boleh mengubah suai logik pengiraannya untuk mengurangkan kos pembolehubah perantaraan sebaliknya, kami boleh terus memanggil set arahan vektor untuk mempercepatkan beberapa langkah pengiraan di dalam operator, seperti pemprosesan Intel® Xeon® Cekap; Set arahan AVX512 pada pemproses.
Pengoptimuman pengkompil AI
Dengan pembangunan bidang pembelajaran mendalam, struktur model dan penggunaan perkakasan dipersembahkan menunjukkan trend evolusi kepelbagaian. Apabila menggunakan model ke pelbagai platform perkakasan, kami biasanya memanggil masa jalan yang dilancarkan oleh setiap pengeluar perkakasan. Dalam senario perniagaan sebenar, ini mungkin menghadapi beberapa cabaran, seperti:
- Kelajuan lelaran struktur model dan jenis operator akan lebih tinggi daripada masa jalan pengilang, menjadikan Sesetengah model tidak boleh digunakan dengan cepat berdasarkan masa jalan vendor. Pada masa ini, anda perlu bergantung pada pengilang untuk kemas kini, atau menggunakan mekanisme seperti pemalam untuk melaksanakan pengendali yang hilang.
- Perniagaan mungkin mengandungi berbilang model dan model ini mungkin dilatih oleh berbilang rangka kerja pembelajaran mendalam Selain itu, model mungkin perlu digunakan pada berbilang platform perkakasan. Pada masa ini, adalah perlu untuk menukar model ini dengan format yang berbeza ke dalam format yang diperlukan oleh setiap platform perkakasan Pada masa yang sama, isu seperti perubahan dalam ketepatan model dan prestasi yang disebabkan oleh perbezaan dalam pelaksanaan setiap rangka kerja inferens mesti dipertimbangkan. , terutamanya kuantifikasi, yang sangat sensitif kepada kaedah berangka.
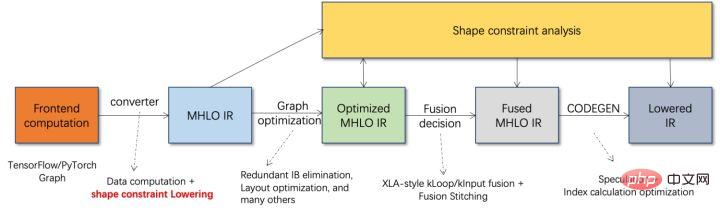
Pengkompil AI dicadangkan untuk menyelesaikan masalah di atas. Ia mengabstrak beberapa peringkat untuk menyelesaikan beberapa masalah di atas. Pertama, ia menerima graf pengiraan model setiap rangka kerja bahagian hadapan sebagai input, dan menjana perwakilan perantaraan bersatu melalui pelbagai Penukar. Selepas itu, pas pengoptimuman graf seperti gabungan operator dan pengembangan gelung akan digunakan pada perwakilan perantaraan untuk meningkatkan prestasi penaakulan. Akhir sekali, pengkompil AI akan melaksanakan codegen untuk platform perkakasan tertentu berdasarkan graf pengiraan yang dioptimumkan untuk menjana kod boleh laku Dalam proses ini, strategi pengoptimuman seperti jahitan dan kekangan bentuk akan diperkenalkan. Pengkompil AI sangat teguh, boleh disesuaikan, mudah digunakan, dan boleh meraih faedah pengoptimuman yang ketara.
Dalam artikel ini, pasukan PAI platform pembelajaran mesin Alibaba Cloud bekerjasama dengan pasukan perisian pusat data Intel, pasukan kecerdasan dan analisis buatan Intel dan pasukan penyeragaman alamat DAMO Academy NLP untuk melaksanakan kesimpulan mengenai perkhidmatan penyeragaman menangani cabaran prestasi, kami bekerjasama untuk melaksanakan penyelesaian pengoptimuman inferens berprestasi tinggi.
2. Pengenalan untuk menangani penyeragaman
Pembangunan perniagaan dalam keselamatan awam dan hal ehwal kerajaan, logistik e-dagang, tenaga (air, elektrik dan gas), pengendali, baharu industri runcit, kewangan, perubatan dan lain-lain Proses ini selalunya melibatkan sejumlah besar data alamat, dan data ini selalunya tidak membentuk spesifikasi struktur standard, dan terdapat masalah seperti kehilangan alamat dan berbilang nama di satu tempat. Dengan peningkatan pendigitalan, masalah alamat bandar yang tidak standard telah menjadi semakin ketara.
Masalah sedia ada dalam permohonan alamat
Penyawaian alamat[2] (Pemurnian Alamat)adalah pasukan NLP dari Alibaba Damo Academy bergantung pada korpus alamat besar Alibaba Cloud dan algoritma NLP yang berkuasa menyediakan perkhidmatan algoritma alamat standard berprestasi tinggi dan ketepatan tinggi. Produk penyeragaman alamat menyediakan algoritma alamat berprestasi tinggi dari perspektif menyeragamkan data alamat dan mewujudkan perpustakaan alamat standard bersatu.
Kelebihan penyeragaman alamat
Perkhidmatan algoritma alamat ini boleh menyeragamkan data alamat secara automatik dan boleh menyelesaikan masalah berbilang alamat dalam satu tempat, pengenalan alamat, pengenalan keaslian alamat dan data alamat lain tidak diseragamkan, pengurusan manual memakan masa dan intensif buruh, dan menangani masalah pembinaan pertindihan pangkalan data menyediakan perusahaan, agensi kerajaan dan pemaju dengan keupayaan pembersihan data alamat dan penyeragaman alamat. untuk menjadikan data alamat lebih baik Memberi sokongan kepada perniagaan. Produk penyeragaman alamat mempunyai ciri-ciri berikut:
- Ketepatan tinggi: Ia mempunyai korpus alamat besar-besaran dan teknologi algoritma super NLP, dan terus mengoptimumkan dan berulang, serta ketepatan algoritma alamat Tinggi
- Prestasi super: pengalaman kaya terkumpul dalam pembinaan projek, mampu membawa sejumlah besar data secara stabil
- Perkhidmatan komprehensif: lebih daripada 20 jenis alamat disediakan Perkhidmatan untuk memenuhi keperluan senario perniagaan yang berbeza
- Penyerahan yang fleksibel: menyokong awan awam, awan hibrid dan penggunaan yang diswastakan.
Modul yang dioptimumkan kali ini tergolong dalam modul carian dalam penyeragaman alamat. Carian alamat bermaksud bahawa pengguna memasukkan maklumat yang berkaitan dengan teks alamat Berdasarkan perpustakaan alamat dan enjin carian, input teks alamat oleh pengguna dicari dan dikaitkan, dan maklumat Tempat Menarik (POI) yang berkaitan dikembalikan. Fungsi carian alamat bukan sahaja meningkatkan pengalaman pemprosesan data pengguna, tetapi juga merupakan asas untuk perkhidmatan hiliran berbilang alamat, seperti pertanyaan latitud dan longitud, penyeragaman alamat pintu, normalisasi alamat, dll., jadi ia memainkan peranan penting dalam keseluruhan alamat. sistem perkhidmatan.
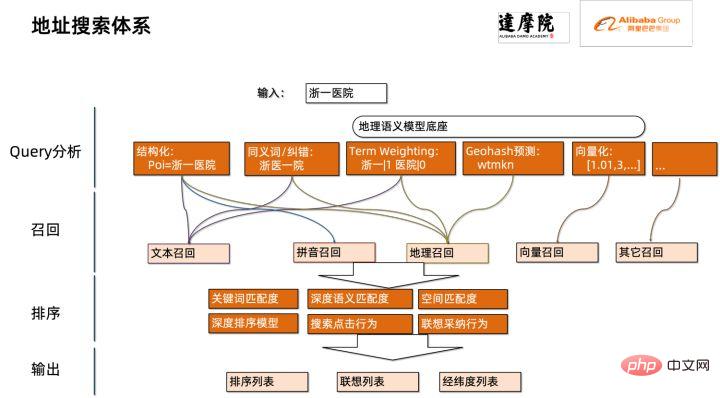
Rajah skematik sistem carian perkhidmatan alamat
Secara khusus, model yang dioptimumkan adalah berdasarkan ramalan geografi pelbagai tugas Pangkalan model bahasa latihan menghasilkan model ingat semula vektor berbilang tugas dan model kedudukan halus .
Asas model bahasa pra-latihan geografi berbilang tugasBerdasarkan tugasan Model Bahasa Bertopeng (MLM), ia menggabungkan klasifikasi mata minat yang berkaitan dan pengenalan Elemen alamat ( wilayah, bandar, daerah, POI, dsb.), dan melalui pembelajaran meta (Pembelajaran Meta), kebarangkalian pensampelan pelbagai tugasan dilaraskan secara adaptif, dan pengetahuan alamat am disepadukan ke dalam model bahasa.
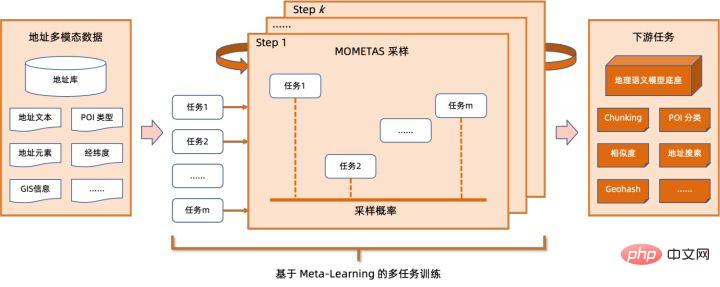
Rajah skematik asas model pra-latihan alamat berbilang tugas
Model ingat semula vektor berbilang tugasDilatih berdasarkan asas di atas Hasilnya termasuk empat tugasan: kesamaan menara berkembar, ramalan Geohash (pengekodan alamat), pembahagian perkataan dan Pemberat Jangka (berat perkataan).
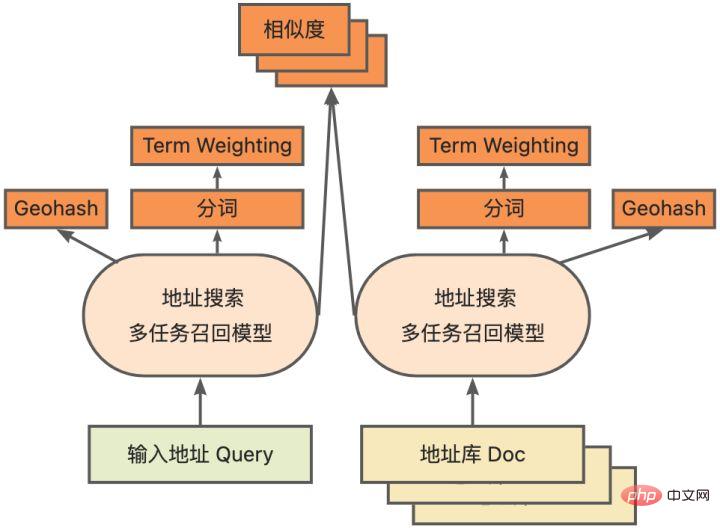
Rajah skematik model ingat semula vektor berbilang tugas
Sebagai modul teras untuk mengira padanan persamaan alamat, Baik model ranking Berdasarkan asas yang disebutkan di atas, ia memperkenalkan hasil latihan data klik besar-besaran dan data anotasi [3], dan meningkatkan kecekapan model melalui teknologi penyulingan model [4]. Akhirnya disusun semula dengan dokumen pustaka alamat yang digunakan untuk mengingat kembali model. Model tunggal 4 lapisan yang dilatih berdasarkan proses di atas boleh mencapai hasil yang lebih baik daripada model garis dasar 12 lapisan pada tugas korelasi alamat NLP Cina CCKS2021 [5] (lihat bahagian Demonstrasi Prestasi untuk butiran).
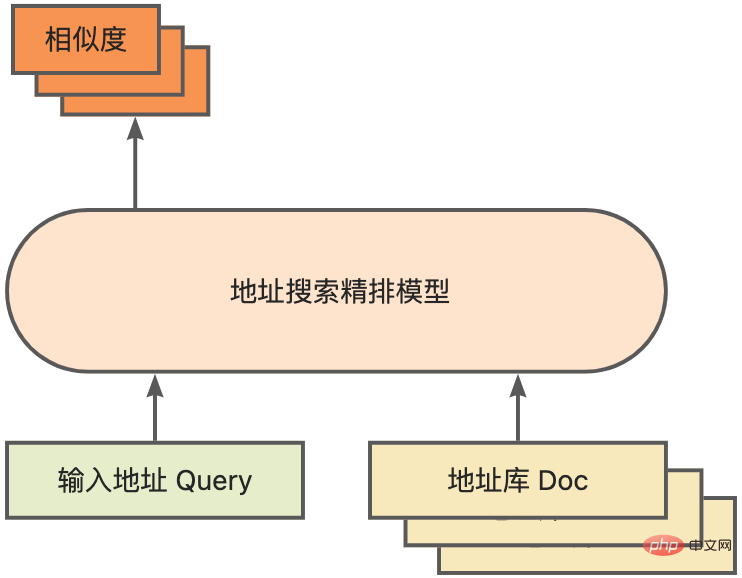
Rajah skematik model yang diperhalusi
3. Penyelesaian pengoptimuman inferens model
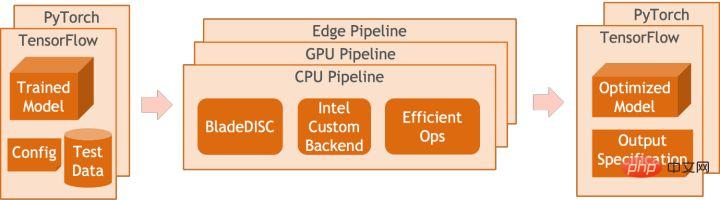
Sokongan produk Blade dilancarkan oleh pasukan PAI platform pembelajaran mesin Alibaba Cloud. Semua penyelesaian pengoptimuman yang dinyatakan di atas menyediakan antara muka pengguna bersatu dan mempunyai berbilang bahagian belakang perisian, seperti pengendali berprestasi tinggi, Intel Custom Backend, BladeDISC, dsb.

Gambar rajah seni bina pengoptimuman inferens model bilah
3.1 Bilah
Blade ialah alat pengoptimuman inferens umum yang dilancarkan oleh pasukan pembelajaran mesin Alibaba Cloud PAI (Platform Kecerdasan Buatan Ia boleh mengoptimumkan sistem model secara bersama untuk mencapai prestasi inferens yang optimum). Ia menyepadukan secara organik pengoptimuman graf pengiraan, pustaka pengoptimuman vendor seperti Intel® oneDNN, pengoptimuman kompilasi BladeDISC, pustaka pengendali berprestasi tinggi Blade, Costom Backend, Ketepatan campuran Blade dan kaedah pengoptimuman lain. Pada masa yang sama, penggunaan mudah merendahkan ambang untuk pengoptimuman model dan meningkatkan pengalaman pengguna dan kecekapan pengeluaran.
PAI-Blade menyokong berbilang format input, termasuk Tensorflow pb, PyTorch torchscript, dsb. Untuk model dioptimumkan, PAI-Blade akan menganalisisnya, kemudian menggunakan pelbagai kaedah pengoptimuman yang mungkin, dan pilih kaedah yang mempunyai kesan pecutan paling jelas daripada pelbagai hasil pengoptimuman sebagai hasil pengoptimuman akhir.
Rajah pengoptimuman bilah
Untuk mendapatkan kesan pengoptimuman maksimum sambil memastikan kadar kejayaan penggunaan, PAI-Blade telah menerima pakai Optimumkan dalam cara "graf bulatan", iaitu:
- Tukar bahagian graf sub-pengiraan untuk dioptimumkan yang boleh disokong oleh inferens backend/high- operator prestasi ke dalam subgraf Dioptimumkan yang sepadan;
- Subgraf yang tidak boleh dioptimumkan sandaran kepada rangka kerja asli yang sepadan (TF/Torch) untuk pelaksanaan.
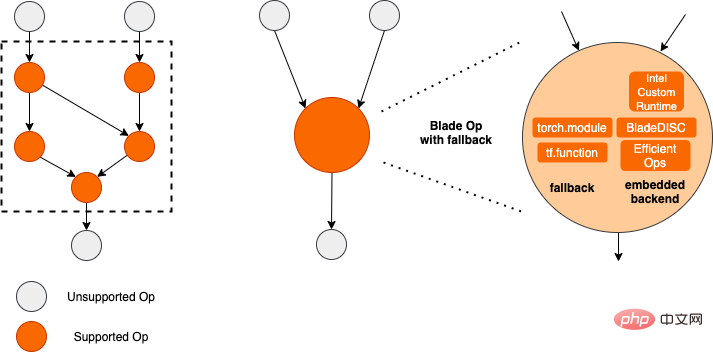
Rajah rajah bulatan bilah
Mampatan Bilah ialah model model mampatan yang dilancarkan oleh Blade Kit alat direka untuk membantu pembangun dalam pengoptimuman pemampatan model yang cekap. Ia mengandungi pelbagai fungsi pemampatan model, termasuk kuantisasi, pemangkasan, sparsifikasi, dsb. Model termampat boleh dioptimumkan lagi dengan mudah melalui Blade untuk mendapatkan pengoptimuman muktamad gabungan sistem model.
Dari segi kuantifikasi, Mampatan Bilah:
- menyediakan antara muka penggunaan mudah dengan memanggil beberapa Dengan API yang mudah, anda boleh melengkapkan langkah seperti pengubahsuaian imej kuantitatif, penentukuran, latihan kuantitatif (Latihan sedar Kuantiti, QAT) dan eksport model kuantitatif.
- menyediakan sokongan untuk pelbagai hujung belakang Melalui konfigurasi fail konfigurasi, proses kuantifikasi untuk peranti yang berbeza dan hujung belakang yang berbeza boleh diselesaikan.
- Sepadukan pelbagai algoritma yang dibangunkan sendiri oleh pasukan PAI-Blade dalam operasi pengeluaran sebenar untuk mendapatkan ketepatan kuantifikasi yang lebih tinggi.
Pada masa yang sama, kami menyediakan API keupayaan atom yang kaya untuk memudahkan pembangunan tersuai untuk situasi tertentu.
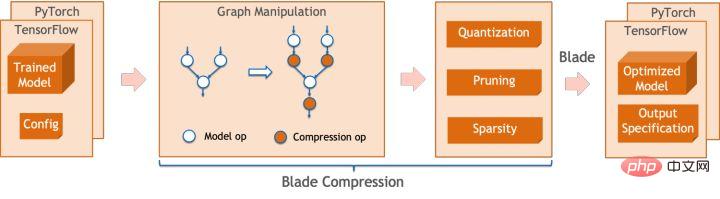
Rajah Mampatan Bilah
BladeDISC ialah produk berorientasikan pembelajaran mesin yang dilancarkan oleh mesin Alibaba Cloud platform pembelajaran pasukan PAI Penyusun pembelajaran mendalam bentuk dinamik bagi pemandangan ialah salah satu bahagian belakang Blade. Ia menyokong rangka kerja bahagian hadapan arus perdana (TensorFlow, PyTorch) dan perkakasan bahagian belakang (CPU, GPU), dan juga menyokong pengoptimuman inferens dan latihan.
Rajah Seni Bina BladeDISC
3.2 Intel® dan kesejagatan, seperti Lapisan Linear dan Lapisan Berulang dalam PyTorch, dsb., yang merupakan modul asas pembinaan model dan bertanggungjawab untuk pelbagai fungsi model boleh diperolehi melalui kombinasi modul ini yang berbeza, dan modul ini juga menjadi tumpuan pengoptimuman oleh pengkompil AI. Sehubungan itu, untuk mendapatkan modul asas berprestasi terbaik dan dengan itu mencapai model berprestasi terbaik, Intel telah menjalankan pengoptimuman pelbagai peringkat modul asas ini untuk seni bina X86, termasuk membolehkan arahan AVX512 yang cekap, penjadualan pengiraan dalaman pengendali, pengendali. Gabungan, pengoptimuman cache, pengoptimuman selari, dsb.
Dalam perkhidmatan penyeragaman alamat, model Rangkaian Neural Berulang (RNN) sering muncul dan modul yang paling mempengaruhi prestasi dalam model RNN ialah modul seperti LSTM atau GRU yang digunakan oleh bab ini LSTM sebagai Contoh menunjukkan cara untuk mencapai pengoptimuman prestasi muktamad LSTM apabila input adalah panjang berubah-ubah dan berbilang kelompok.
Biasanya, untuk memenuhi keperluan dan permintaan pengguna yang berbeza, perkhidmatan awan yang mengejar prestasi tinggi dan kos rendah akan mengumpulkan permintaan pengguna yang berbeza untuk memaksimumkan penggunaan sumber pengkomputeran. Seperti yang ditunjukkan dalam rajah di bawah, terdapat sejumlah tiga ayat benam, dan kandungan dan panjang input adalah berbeza.
Data input asal

Data input asal

Langkah pengiraan LSTM untuk input

Penyatuan pengkomputeran LSTM [8]
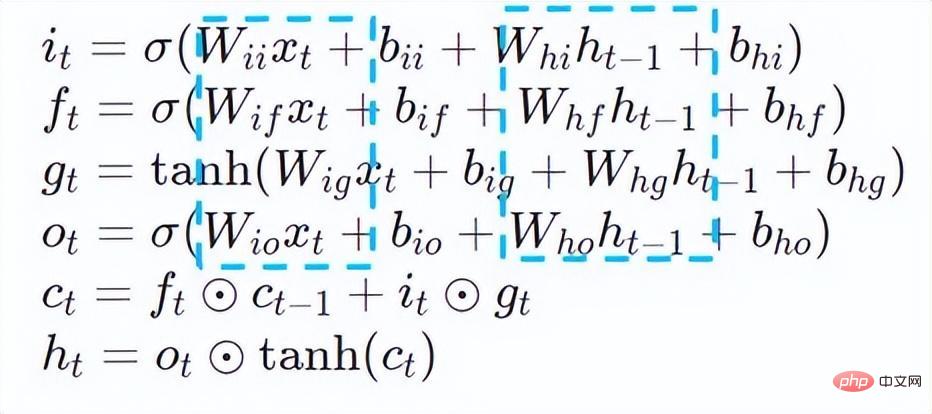
Bahagian belakang tersuai Intel[9], sebagai bahagian belakang perisian Blade, mempercepatkan kuantifikasi model dan prestasi penaakulan yang jarang, dan terutamanya merangkumi tiga tahap pengoptimuman. Pertama, strategi Cache Primitif digunakan untuk mengoptimumkan memori Kedua, pengoptimuman gabungan graf dilakukan Akhir sekali, pada peringkat operator, perpustakaan pengendali yang cekap termasuk operator jarang dan terkuantiti dilaksanakan.
Gambarajah Seni Bina Bahagian Belakang Tersuai Intel
Kuantiti Ketepatan Rendah
Pengendali berkelajuan tinggi seperti jarang dan kuantisasi mendapat manfaat daripada set arahan pecutan Intel® DL Boost, seperti set arahan VNNI.
Pengenalan arahan VNNI
Gambar di atas menunjukkan arahan VNNI 8bit boleh dipercepatkan menggunakan tiga arahan AVX512 BW terlebih dahulu mendarab dan menambah 2 pasang tatasusunan yang terdiri daripada 8bit untuk mendapatkan 16bit. , VPMADDWD menambah data bersebelahan untuk mendapatkan data 32bit Akhirnya, VPADDD menambah pemalar ini boleh membentuk AVX512_VNNI Arahan ini boleh digunakan untuk mempercepatkan pendaraban matriks.
Penyatuan graf
Selain itu, Custom Backend juga menyediakan gabungan graf, seperti pendaraban matriks Keadaan perantaraan sementara Tensor bukan output, tetapi arahan berikut dijalankan secara langsung, iaitu, op pos bagi item berikutnya digabungkan dengan operator sebelumnya, dengan itu mengurangkan pengendalian data dan mengurangkan masa berjalan Rajah berikut adalah contoh, operator dalam kotak merah Selepas gabungan, pergerakan data tambahan boleh dihapuskan dan ia menjadi pengendali baharu.
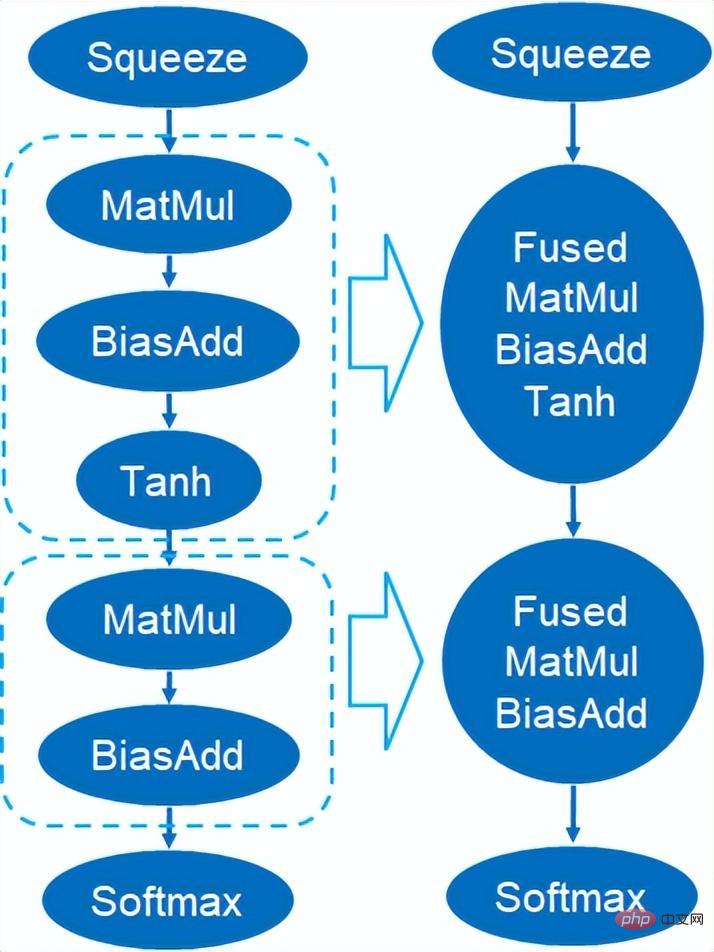
Graph Fusion
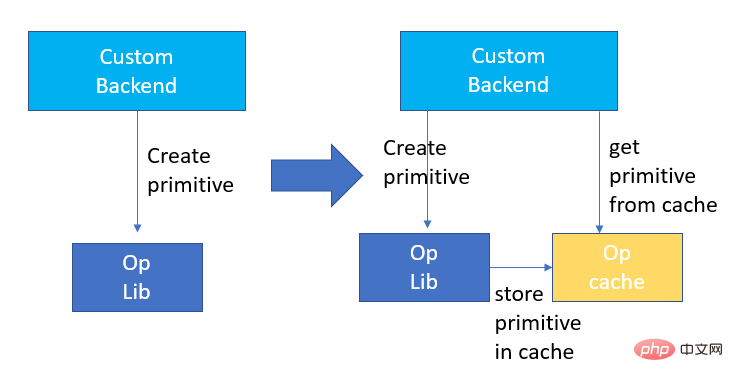
Pengoptimuman Memori
Memori Peruntukan dan keluaran akan berkomunikasi dengan sistem pengendalian, mengakibatkan kelewatan masa jalan yang meningkat Untuk mengurangkan bahagian overhed ini, Bahagian Belakang Tersuai telah menambah reka bentuk Cache Primitif digunakan untuk cache Primitif yang telah dibuat, supaya Primitif tidak boleh Dikitar Semula oleh sistem, mengurangkan overhed penciptaan untuk panggilan seterusnya.
Pada masa yang sama, mekanisme cache diwujudkan untuk pengendali yang memakan masa untuk mempercepatkan operasi pengendali, seperti yang ditunjukkan dalam rajah berikut:
 4. Paparan prestasi keseluruhan
4. Paparan prestasi keseluruhan
Kami memilih dua struktur model biasa dalam perkhidmatan carian alamat untuk mengesahkan kesan penyelesaian pengoptimuman di atas. Persekitaran ujian adalah seperti berikut:
Model pelayan: Alibaba Cloud ecs.g7.large, 2 vCPUUji model CPU : Intel® 🎜>
- versi onnx: 1.11.0
- versi onnxruntime: 1.11.1
- 4.1 ESIM
- ESIM [6] ialah versi LSTM yang dipertingkatkan yang direka untuk inferens bahasa semula jadi. Blade menggunakan pengendali LSTM tujuan am berprestasi tinggi
- yang dibangunkan oleh pasukan perisian pusat data Intel untuk mempercepatkannya, menggantikan LSTM lalai (Baseline) dalam modul PyTorch. ESIM yang diuji kali ini mengandungi dua struktur LSTM Prestasi sebelum dan selepas pengoptimuman operator tunggal ditunjukkan dalam jadual:
Struktur LSTM
RT Dioptimumkan |
Nisbah pecutan |
|||
LSTM - A |
7x200 |
0.199 ms |
0.066ms |
+3.02x |
202x200 |
0.914 ms |
0.307ms |
+2.98x |
|
LSTM - B |
70x50 |
0.266ms |
0.098ms |
+2.71x |
202x50 |
0.804ms |
0.209ms |
+3.85x |
Pengoptimuman operator tunggal LSTM sebelum dan selepas prestasi inferens
Sebelum dan selepas pengoptimuman, kelajuan inferens hujung ke hujung ESIM adalah seperti yang ditunjukkan dalam jadual, manakala ketepatan model sebelum dan selepas pengoptimuman kekal tidak berubah.
模型结构 |
ESIM[6] |
ESIM[6]+Blade算子优化 |
加速比 |
RT |
6.3ms |
3.4ms |
+1.85x |
Pengoptimuman model ESIM sebelum dan selepas prestasi inferens
4.2 BERT
BERT[7] telah digunakan secara meluas dalam alam semula jadi pemprosesan bahasa (NLP) dalam beberapa tahun kebelakangan ini ), penglihatan komputer (CV) dan bidang lain telah diterima pakai secara meluas. Blade mempunyai pelbagai kaedah seperti pengoptimuman kompilasi (FP32) dan kuantisasi (INT8) untuk struktur ini.
Dalam ujian kelajuan, bentuk data ujian ditetapkan pada 10x53 Prestasi kelajuan pelbagai hujung belakang dan pelbagai kaedah pengoptimuman adalah seperti yang ditunjukkan dalam jadual di bawah. Ia boleh dilihat bahawa kelajuan inferens model selepas penyusunan dan pengoptimuman bilah atau selepas kuantisasi INT8 adalah lebih baik daripada libtorch dan onnxruntime, dan bahagian belakang inferens ialah Intel Custom Backend & BladeDisc. Perlu diingat bahawa kelajuan BERT 4 lapisan selepas pecutan kuantitatif adalah 1.5 kali ganda berbanding BERT 2 lapisan, yang bermaksud bahawa semasa mempercepatkan, perniagaan boleh menggunakan model yang lebih besar dan memperoleh ketepatan perniagaan yang lebih baik.
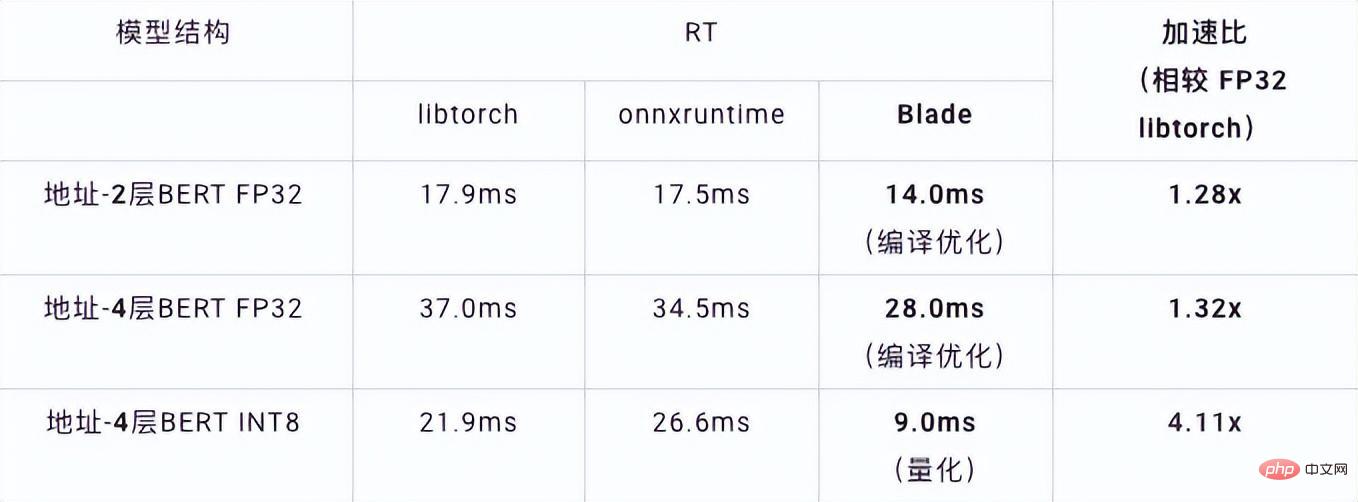
Alamat paparan prestasi inferens BERT
Dari segi ketepatan, kami menunjukkan model berkaitan berdasarkan tugas korelasi alamat NLP Cina CCKS2021 [5] prestasi, seperti yang ditunjukkan dalam jadual di bawah. Ketepatan 4 lapisan BERT makro F1 yang dibangunkan sendiri oleh pasukan alamat Akademi DAMO adalah lebih tinggi daripada asas BERT 12 lapisan standard. Pengoptimuman kompilasi bilah boleh mencapai ketepatan tanpa kerugian, dan ketepatan model terkuantisasi sebenar selepas latihan pengkuantitian Mampatan Bilah adalah lebih tinggi sedikit daripada model titik terapung asal.
Struktur model |
makro F1 (semakin tinggi, semakin baik) |
12 lapis asas BERT |
77.24 |
|
Alamat - Aras 4 BERT 🎜> |
78.72(+1.48) |
Alamat - 4 lapisan BERT + Pengoptimuman kompilasi Blade |
78.72(+1.48) |
Alamat - ke-4 lantai BERT + Kuantiti Bilah |
78.85(+1.61) |
Alamat keputusan ketepatan berkaitan BERT
Atas ialah kandungan terperinci Alamat perkhidmatan penyeragaman model pembelajaran mendalam AI amalan pengoptimuman inferens. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI