
Rumah >Peranti teknologi >AI >Latihan Praktikal Pokok Keputusan Pembelajaran Mesin
Latihan Praktikal Pokok Keputusan Pembelajaran Mesin

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-11 19:16:011146semak imbas
Penterjemah |. Zhu Xianzhong
Pengulas | Sun Shujuan
Pokok keputusan dalam pembelajaran mesin
Moden algoritma pembelajaran mesin mengubah kehidupan harian kita. Sebagai contoh, model bahasa besar seperti BERT menjanakan carian Google dan GPT-3 menjanakan banyak aplikasi bahasa peringkat tinggi.
Sebaliknya, membina algoritma pembelajaran mesin yang kompleks adalah lebih mudah hari ini berbanding sebelum ini. Walau bagaimanapun, tidak kira betapa rumitnya algoritma pembelajaran mesin, ia termasuk dalam salah satu kategori pembelajaran berikut:
- Pembelajaran diselia
- Pembelajaran tanpa pengawasan
- Pembelajaran separuh penyeliaan
- Pembelajaran pengukuhan
Sebenarnya, Keputusan trees ialah salah satu algoritma pembelajaran mesin tertua yang diselia dan boleh menyelesaikan pelbagai masalah dunia sebenar. Penyelidikan menunjukkan bahawa ciptaan terawal algoritma pepohon keputusan boleh dikesan kembali ke 1963.
Seterusnya, mari kita teliti butiran algoritma ini dan lihat sebab algoritma jenis ini masih begitu popular hari ini.
Apakah pokok keputusan?
Algoritma pepohon keputusan ialah algoritma pembelajaran mesin diselia yang popular kerana cara pengendalian set data yang kompleks yang agak mudah. Pokok keputusan mendapat namanya daripada persamaannya dengan struktur pokok yang terdiri daripada beberapa komponen seperti akar, dahan, dan daun dalam bentuk nod dan tepi. Ia digunakan untuk analisis keputusan, sama seperti carta aliran keputusan berasaskan if-else, di mana keputusan akan menghasilkan ramalan yang diingini. Pepohon keputusan boleh mempelajari peraturan keputusan if-else ini untuk memisahkan set data dan akhirnya menjana model data seperti pepohon.
Pokok keputusan digunakan dalam ramalan keputusan diskret untuk masalah pengelasan dan ramalan keputusan berangka berterusan untuk masalah regresi. Selama bertahun-tahun saintis telah membangunkan banyak algoritma yang berbeza seperti CART, C4.5 dan algoritma ensemble seperti hutan rawak dan pokok yang dirangsang kecerunan.
Anatomi pelbagai komponen pepohon keputusan
Matlamat algoritma pepohon keputusan adalah untuk meramalkan hasil daripada set data input. Set data pokok dibahagikan kepada tiga bentuk: atribut, nilai atribut dan jenis yang akan diramalkan. Seperti mana-mana algoritma pembelajaran yang diselia, set data dibahagikan kepada dua jenis: set latihan dan set ujian. Antaranya, set latihan mentakrifkan peraturan keputusan yang dipelajari oleh algoritma dan digunakan pada set ujian.
Sebelum kita memperkenalkan langkah algoritma pepohon keputusan bersama-sama, mari kita fahami komponen pepohon keputusan terlebih dahulu:
- Nod Akar: Ia adalah nod permulaan di bahagian atas pepohon keputusan dan mengandungi semua nilai atribut. Nod akar dibahagikan kepada nod keputusan berdasarkan peraturan keputusan yang dipelajari oleh algoritma.
- Cawangan: Cawangan ialah penyambung antara nod yang sepadan dengan nilai atribut. Dalam pemisahan binari, cawangan mewakili laluan benar dan salah.
- Nod Keputusan/Nod Dalaman: Nod dalaman ialah nod keputusan antara nod akar dan nod daun, sepadan dengan peraturan keputusan dan laluan jawapannya. Nod mewakili soalan, dan cawangan menunjukkan laluan kepada jawapan yang berkaitan berdasarkan soalan tersebut.
- Nod daun: Nod daun ialah nod terminal yang mewakili ramalan sasaran. Nod ini tidak akan dipecahkan lagi.
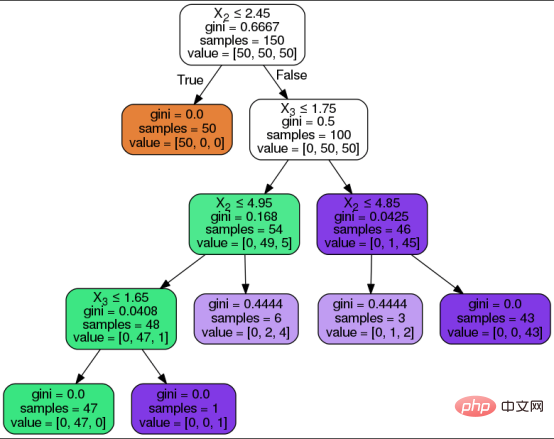
Berikut ialah perwakilan visual pepohon keputusan dan komponennya di atas, algoritma pepohon keputusan melalui langkah-langkah berikut untuk mencapai ramalan yang dikehendaki:
- Algoritma bermula dari nod akar dengan semua nilai atribut.
- Nod punca dibahagikan kepada nod keputusan berdasarkan peraturan keputusan yang dipelajari oleh algoritma daripada set latihan.
- Lulus nod keputusan dalaman melalui cawangan/tepi berdasarkan soalan dan laluan jawapannya.
- Teruskan langkah sebelumnya sehingga nod daun dicapai atau semua atribut digunakan.
Untuk memilih atribut terbaik pada setiap nod, pemisahan akan berdasarkan salah satu daripada dua metrik pemilihan atribut berikut:
- Indeks Gini(Indeks Gini)Mengukur kekotoran Gini ( Kekotoran Gini) untuk menunjukkan kemungkinan bahawa algoritma akan salah mengklasifikasikan label kelas rawak.
- Pendapatan maklumatMengukur peningkatan dalam entropi selepas segmentasi untuk mengelakkan 50/ kelas yang diramalkan 50 berpecah. Entropi ialah ukuran matematik kekotoran dalam sampel data yang diberikan. keadaan huru-hara dalam pepohon keputusan diwakili oleh hampir 50/50 pembahagian .
Kes pengelasan bunga menggunakan algoritma pepohon keputusan
Setelah memahami pengetahuan asas di atas, mari kita mula melaksanakan kes aplikasi. Dalam artikel ini, kami akan melaksanakan model klasifikasi pokok keputusan dalam Python menggunakan perpustakaan Pembelajaran Scikit.
Penjelasan ringkas tentang set data
Set data untuk tutorial ini ialah set data bunga iris. Set data ini telah dibina ke dalam pustaka sumber terbuka Scikit, jadi pembangun tidak perlu memuatkannya secara luaran. Set data termasuk sejumlah empat atribut iris dan nilai atribut yang sepadan, yang akan dimasukkan ke dalam model untuk meramalkan satu daripada tiga jenis bunga iris.
- Atribut/ciri dalam set data: panjang sepal, lebar sepal, panjang kelopak, lebar kelopak.
- Label/jenis bunga yang diramalkan dalam set data: Setosis, Versicolor, Virginica.
Seterusnya, penerangan kod langkah demi langkah bagi pengelas pokok keputusan berdasarkan bahasa python akan diberikan.
Import perpustakaan
Mula-mula, import pustaka yang diperlukan untuk melaksanakan pepohon keputusan melalui sekeping kod berikut.
import pandas as pd import numpy as np from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier
Memuatkan set data Iris
Kod berikut menunjukkan menggunakan fungsi load_iris untuk memuatkan Iris daripada perpustakaan sklearn.dataset yang disimpan dalam set data pembolehubah set data Bunga . Dua baris kod seterusnya akan mencetak jenis iris dan maklumat ciri.
data_set = load_iris()
print('Iris plant classes to predict: ', data_set.target_names)
print('Four features of iris plant: ', data_set.feature_names)
Asingkan atribut dan teg
Barisan kod berikut memisahkan ciri dan maklumat jenis bunga , dan simpannya dalam pembolehubah yang sepadan. Antaranya, fungsi bentuk[0] bertanggungjawab untuk menentukan bilangan atribut yang disimpan dalam pembolehubah X_att jumlah bilangan nilai atribut dalam set data ialah 150.
#提取花的特性和类型信息
X_att = data_set.data
y_label = data_set.target
print('数据集中总的样本数:', X_att.shape[0])Malah, kita juga boleh mencipta jadual visual untuk memaparkan sebahagian daripada nilai atribut dalam set data dengan menambahkan nilai dalam pembolehubah X_att pada Fungsi DataFrame dalam perpustakaan panda Itu sahaja.
data_view=pd.DataFrame({
'sepal length':X_att[:,0],
'sepal width':X_att[:,1],
'petal length':X_att[:,2],
'petal width':X_att[:,3],
'species':y_label
})
data_view.head()Pisah set data
Kod berikut menunjukkan penggunaan fungsi train_test_split untuk membahagikan set data kepada set latihan dan set ujian. Antaranya, parameter random_state dalam fungsi ini digunakan untuk menyediakan benih rawak untuk fungsi memberikan keputusan yang sama untuk set data yang diberikan setiap kali ia dilaksanakan test_size menunjukkan saiz set ujian; menyumbang 25% selepas pembahagian data latihan menyumbang 75%.
#数据集拆分为训练集和测试集两部分 X_att_train, X_att_test, y_label_train, y_label_test = train_test_split(X_att, y_label, random_state = 42, test_size = 0.25)
Gunakan fungsi pengelasan pokok keputusan
Kod di bawah mencipta Fungsi DecisionTreeClassifier 🎜>Model pengelasanUntuk melaksanakana pepohon keputusan, piawaian klasifikasi ditetapkan kepada "entropi " Jalannya. Kriteria membolehkan menetapkan metrik pemilihan atribut kepada (Perolehan maklumat). Kod tersebut kemudiannya memadankan model dengan set latihan atribut dan label kami. 下面的代码负责计算并打印决策树分类模型在训练集和测试集上的准确性。为了计算准确度分数,我们使用了predict函数。测试结果是:训练集和测试集的准确率分别为100%和94.7%。 当今社会,机器学习决策树在许多行业的决策过程中都得到广泛应用。其中,决策树的最常见应用首先是在金融和营销部门,例如可用于如下一些子领域: 作为本文决策树主题讨论的总结,我们有充分的理由安全地假设:决策树的可解释性仍然很受欢迎。决策树之所以容易理解,是因为它们可以被人类以可视化方式展现并便于解释。因此,它们是解决机器学习问题的直观方法,同时也能够确保结果是可解释的。机器学习中的可解释性是我们过去讨论过的一个小话题,它也与即将到来的人工智能伦理主题存在密切联系。 与任何其他机器学习算法一样,决策树自然也可以加以改进,以避免过度拟合和出现过于偏向于优势预测类别。剪枝和ensembling技术是克服决策树算法缺点方案最常采用的方法。决策树尽管存在这些缺点,但仍然是决策分析算法的基础,并将在机器学习领域始终保持重要位置。 朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。 原文标题:An Introduction to Decision Trees for Machine Learning,作者:Stylianos Kampakis#应用决策树分类器
clf_dt = DecisionTreeClassifier(criterion = 'entropy')
clf_dt.fit(X_att_train, y_label_train)
计算模型精度
print('Training data accuracy: ', accuracy_score(y_true=y_label_train, y_pred=clf_dt.predict(X_att_train)))
print('Test data accuracy: ', accuracy_score(y_true=y_label_test, y_pred=clf_dt.predict(X_att_test)))真实世界中的决策树应用程序
如何改进决策树?
译者介绍
Atas ialah kandungan terperinci Latihan Praktikal Pokok Keputusan Pembelajaran Mesin. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI