
Rumah >pembangunan bahagian belakang >Tutorial Python >Menggunakan Pytorch untuk melaksanakan pembelajaran kontrastif SimCLR untuk pra-latihan yang diselia sendiri
Menggunakan Pytorch untuk melaksanakan pembelajaran kontrastif SimCLR untuk pra-latihan yang diselia sendiri

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-10 14:11:032214semak imbas
SimCLR (Rangka Kerja Mudah untuk Pembelajaran Perwakilan Kontrastif) ialah teknologi yang diselia sendiri untuk mempelajari perwakilan imej. Tidak seperti kaedah pembelajaran tradisional yang diselia, SimCLR tidak bergantung pada data berlabel untuk mempelajari perwakilan yang berguna. Ia menggunakan rangka kerja pembelajaran kontras untuk mempelajari satu set ciri berguna yang boleh menangkap maklumat semantik peringkat tinggi daripada imej tidak berlabel.
SimCLR telah terbukti mengungguli kaedah pembelajaran tanpa pengawasan yang canggih pada pelbagai penanda aras klasifikasi imej. Dan perwakilan yang dipelajarinya boleh dipindahkan dengan mudah ke tugas hiliran seperti pengesanan objek, pembahagian semantik dan pembelajaran beberapa pukulan dengan penalaan halus minimum pada set data berlabel yang lebih kecil.

Idea utama SimCLR adalah untuk mempelajari perwakilan imej yang baik dengan membandingkannya dengan versi lain yang dipertingkatkan bagi imej yang sama melalui modul peningkatan T. Ini dilakukan dengan memetakan imej melalui rangkaian pengekod f(.) dan kemudian menayangkannya. head g(.) memetakan ciri yang dipelajari ke dalam ruang berdimensi rendah. Kehilangan kontras kemudian dikira antara perwakilan dua versi dipertingkatkan bagi imej yang sama untuk menggalakkan perwakilan serupa bagi imej yang sama dan perwakilan berbeza bagi imej berbeza.
Dalam artikel ini kita akan menyelidiki rangka kerja SimCLR dan meneroka komponen utama algoritma, termasuk penambahan data, fungsi kehilangan kontrastif dan seni bina kepala pengekod dan unjuran.
Di sini kami menggunakan set data klasifikasi sampah daripada Kaggle untuk menjalankan eksperimen
Modul peningkatan
Perkara yang paling penting dalam SimCLR ialah modul peningkatan untuk menukar imej. Penulis kertas SimCLR mencadangkan bahawa penambahan data yang berkuasa berguna untuk pembelajaran tanpa pengawasan. Oleh itu, kami akan mengikuti pendekatan yang disyorkan dalam kertas.
- Pemotongan rawak untuk mengubah saiz
- Balik mendatar rawak dengan kebarangkalian 50%
- Herotan warna rawak (kebarangkalian dithering warna 80%, kebarangkalian jatuh warna 20% )
- 50% kebarangkalian kabur Gaussian rawak
def get_complete_transform(output_shape, kernel_size, s=1.0): """ Color distortion transform Args: s: Strength parameter Returns: A color distortion transform """ rnd_crop = RandomResizedCrop(output_shape) rnd_flip = RandomHorizontalFlip(p=0.5) color_jitter = ColorJitter(0.8*s, 0.8*s, 0.8*s, 0.2*s) rnd_color_jitter = RandomApply([color_jitter], p=0.8) rnd_gray = RandomGrayscale(p=0.2) gaussian_blur = GaussianBlur(kernel_size=kernel_size) rnd_gaussian_blur = RandomApply([gaussian_blur], p=0.5) to_tensor = ToTensor() image_transform = Compose([ to_tensor, rnd_crop, rnd_flip, rnd_color_jitter, rnd_gray, rnd_gaussian_blur, ]) return image_transform class ContrastiveLearningViewGenerator(object): """ Take 2 random crops of 1 image as the query and key. """ def __init__(self, base_transform, n_views=2): self.base_transform = base_transform self.n_views = n_views def __call__(self, x): views = [self.base_transform(x) for i in range(self.n_views)] return views
Langkah seterusnya ialah mentakrifkan Set Data PyTorch.
class CustomDataset(Dataset): def __init__(self, list_images, transform=None): """ Args: list_images (list): List of all the images transform (callable, optional): Optional transform to be applied on a sample. """ self.list_images = list_images self.transform = transform def __len__(self): return len(self.list_images) def __getitem__(self, idx): if torch.is_tensor(idx): idx = idx.tolist() img_name = self.list_images[idx] image = io.imread(img_name) if self.transform: image = self.transform(image) return image
Sebagai contoh, kami menggunakan model ResNet18 yang lebih kecil sebagai tulang belakang, jadi inputnya ialah imej 224x224 Kami menetapkan beberapa parameter seperti yang diperlukan dan menjana pemuat data
out_shape = [224, 224]
kernel_size = [21, 21] # 10% of out_shape
# Custom transform
base_transforms = get_complete_transform(output_shape=out_shape, kernel_size=kernel_size, s=1.0)
custom_transform = ContrastiveLearningViewGenerator(base_transform=base_transforms)
garbage_ds = CustomDataset(
list_images=glob.glob("/kaggle/input/garbage-classification/garbage_classification/*/*.jpg"),
transform=custom_transform
)
BATCH_SZ = 128
# Build DataLoader
train_dl = torch.utils.data.DataLoader(
garbage_ds,
batch_size=BATCH_SZ,
shuffle=True,
drop_last=True,
pin_memory=True)
SimCLR
Kami telah menyediakan data dan mula menghasilkan semula model tersebut. Modul peningkatan di atas menyediakan dua paparan imej yang dipertingkatkan, yang dihantar ke hadapan melalui pengekod untuk mendapatkan perwakilan yang sepadan. Matlamat SimCLR adalah untuk memaksimumkan persamaan antara perwakilan yang dipelajari berbeza ini dengan menggalakkan model mempelajari perwakilan umum objek daripada dua pandangan tambahan yang berbeza.
Pilihan rangkaian pengekod tidak terhad dan boleh dari mana-mana seni bina. Seperti yang dinyatakan di atas, untuk demonstrasi mudah, kami menggunakan ResNet18. Perwakilan yang dipelajari oleh model pengekod menentukan pekali persamaan, dan untuk meningkatkan kualiti perwakilan ini, SimCLR menggunakan kepala unjuran untuk menayangkan vektor pengekodan ke dalam ruang terpendam yang lebih kaya. Di sini kami menayangkan ciri 512 dimensi ResNet18 ke dalam ruang 256 dimensi Ia kelihatan sangat rumit, tetapi sebenarnya ia hanya menambah mlp dengan relu.
class Identity(nn.Module): def __init__(self): super(Identity, self).__init__() def forward(self, x): return x class SimCLR(nn.Module): def __init__(self, linear_eval=False): super().__init__() self.linear_eval = linear_eval resnet18 = models.resnet18(pretrained=False) resnet18.fc = Identity() self.encoder = resnet18 self.projection = nn.Sequential( nn.Linear(512, 512), nn.ReLU(), nn.Linear(512, 256) ) def forward(self, x): if not self.linear_eval: x = torch.cat(x, dim=0) encoding = self.encoder(x) projection = self.projection(encoding) return projection
Kehilangan Kontras
Fungsi kehilangan kontras, juga dikenali sebagai Normalized Temperature Scaled Cross-Entropy Loss (NT-Xent), ialah kunci kepada komponen SimCLR , yang menggalakkan model mempelajari perwakilan yang serupa untuk imej yang sama dan perwakilan yang berbeza untuk imej yang berbeza. Kehilangan NT-Xent dikira menggunakan paparan tambahan bagi sepasang imej yang melalui rangkaian pengekod untuk mendapatkan perwakilan sepadannya. Matlamat kehilangan kontras adalah untuk menggalakkan perwakilan dua paparan tambahan bagi imej yang sama menjadi serupa sambil memaksa perwakilan imej yang berbeza menjadi tidak serupa.
NT-Xent menggunakan fungsi softmax untuk meningkatkan persamaan berpasangan bagi perwakilan pandangan. Fungsi softmax digunakan pada semua pasangan perwakilan dalam kelompok mini untuk mendapatkan taburan kebarangkalian persamaan bagi setiap imej. Parameter suhu digunakan untuk menskalakan persamaan berpasangan sebelum menggunakan fungsi softmax, yang membantu mendapatkan kecerunan yang lebih baik semasa pengoptimuman.
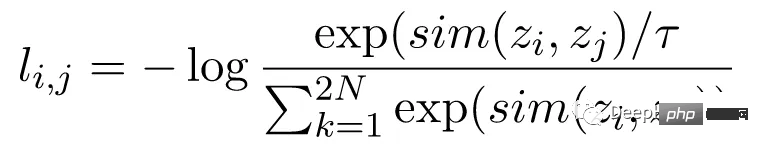 Selepas memperoleh taburan kebarangkalian persamaan, kerugian NT-Xent dikira dengan memaksimumkan kemungkinan log padanan representasi imej yang sama dan meminimumkan kemungkinan log representasi tidak sepadan bagi imej berbeza.
Selepas memperoleh taburan kebarangkalian persamaan, kerugian NT-Xent dikira dengan memaksimumkan kemungkinan log padanan representasi imej yang sama dan meminimumkan kemungkinan log representasi tidak sepadan bagi imej berbeza.
Semua persiapan sudah lengkap, mari latih SimCLR dan lihat kesannya!
LABELS = torch.cat([torch.arange(BATCH_SZ) for i in range(2)], dim=0) LABELS = (LABELS.unsqueeze(0) == LABELS.unsqueeze(1)).float() #one-hot representations LABELS = LABELS.to(DEVICE) def ntxent_loss(features, temp): """ NT-Xent Loss. Args: z1: The learned representations from first branch of projection head z2: The learned representations from second branch of projection head Returns: Loss """ similarity_matrix = torch.matmul(features, features.T) mask = torch.eye(LABELS.shape[0], dtype=torch.bool).to(DEVICE) labels = LABELS[~mask].view(LABELS.shape[0], -1) similarity_matrix = similarity_matrix[~mask].view(similarity_matrix.shape[0], -1) positives = similarity_matrix[labels.bool()].view(labels.shape[0], -1) negatives = similarity_matrix[~labels.bool()].view(similarity_matrix.shape[0], -1) logits = torch.cat([positives, negatives], dim=1) labels = torch.zeros(logits.shape[0], dtype=torch.long).to(DEVICE) logits = logits / temp return logits, labelsKod di atas dilatih untuk 10 pusingan dengan mengandaikan bahawa kita telah menyelesaikan proses pra-latihan, kita boleh menggunakan pengekod pra-latihan untuk tugasan hiliran yang kita inginkan. Ini boleh dilakukan dengan kod di bawah.
simclr_model = SimCLR().to(DEVICE)
criterion = nn.CrossEntropyLoss().to(DEVICE)
optimizer = torch.optim.Adam(simclr_model.parameters())
epochs = 10
with tqdm(total=epochs) as pbar:
for epoch in range(epochs):
t0 = time.time()
running_loss = 0.0
for i, views in enumerate(train_dl):
projections = simclr_model([view.to(DEVICE) for view in views])
logits, labels = ntxent_loss(projections, temp=2)
loss = criterion(logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# print stats
running_loss += loss.item()
if i%10 == 9: # print every 10 mini-batches
print(f"Epoch: {epoch+1} Batch: {i+1} Loss: {(running_loss/100):.4f}")
running_loss = 0.0
pbar.update(1)
print(f"Time taken: {((time.time()-t0)/60):.3f} mins")Bahagian paling penting dalam kod di atas ialah membaca model simclr yang baru dilatih, kemudian membekukan semua pemberat, dan kemudian mencipta kepala klasifikasi self.linear untuk pemprosesan hiliran Tugas pengelasan
Ringkasan
Artikel ini memperkenalkan rangka kerja SimCLR dan menggunakannya untuk pralatih ResNet18 dengan pemberat yang dimulakan secara rawak. Pralatihan ialah teknik berkuasa yang digunakan dalam pembelajaran mendalam untuk melatih model pada set data yang besar dan mempelajari ciri berguna yang boleh dipindahkan ke tugas lain. Kertas SimCLR percaya bahawa lebih besar saiz kelompok, lebih baik prestasinya. Pelaksanaan kami hanya menggunakan saiz kelompok 128 dan melatih selama 10 zaman sahaja. Jadi ini bukan prestasi terbaik model Jika perbandingan prestasi diperlukan, latihan lanjut diperlukan.
Angka berikut ialah kesimpulan prestasi yang diberikan oleh pengarang kertas kerja:

Atas ialah kandungan terperinci Menggunakan Pytorch untuk melaksanakan pembelajaran kontrastif SimCLR untuk pra-latihan yang diselia sendiri. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!