
Rumah >Peranti teknologi >AI >'Pembenaman Lokasi”: Rahsia Di Sebalik Transformer
'Pembenaman Lokasi”: Rahsia Di Sebalik Transformer

- 王林ke hadapan
- 2023-04-10 10:01:031105semak imbas
Penterjemah |. Cui Hao
Pengulas |. >
Pengenalan- Membenamkan konsep dalam NLP
- Memerlukan benam kedudukan dalam Transformers
- Pelbagai jenis percubaan percubaan dan ralat awal
- Pembenaman kedudukan berdasarkan frekuensi
- Ringkasan
- Rujukan
- Pengenalan Pengenalan seni bina Transformer dalam bidang pembelajaran mendalam sudah pasti membuka jalan kepada revolusi senyap . Melicinkan jalan adalah penting terutamanya untuk cawangan NLP. Bahagian yang paling penting dalam seni bina Transformer ialah "pembenaman kedudukan", yang memberikan rangkaian saraf keupayaan untuk memahami susunan perkataan dalam ayat yang panjang dan kebergantungan di antara mereka.
Membenamkan konsep dalam NLP
Membenam ialah proses dalam pemprosesan bahasa semula jadi yang menukar teks mentah kepada vektor matematik. Ini kerana model pembelajaran mesin tidak akan dapat mengendalikan format teks secara langsung dan menggunakannya untuk pelbagai proses pengkomputeran dalaman.
Proses pembenaman untuk algoritma seperti Word2vec dan Glove dipanggil pembenaman perkataan atau pembenaman statik.Dengan cara ini korpus teks yang mengandungi sejumlah besar perkataan boleh dihantar ke dalam model untuk latihan. Model akan memberikan nilai matematik yang sepadan kepada setiap perkataan, dengan mengandaikan bahawa perkataan yang lebih kerap muncul adalah serupa. Selepas proses ini, nilai matematik yang terhasil digunakan untuk pengiraan selanjutnya.
Sebagai contoh, pertimbangkan bahawa korpus teks kita mempunyai 3 ayat, seperti berikut: Raja dan permaisuri mengeluarkan subsidi yang besar dan menuntut beberapa kawalan ke atas pentadbiran.
Selain raja dan permaisuri, ahli keluarga diraja juga termasuk anak perempuan mereka Marie-Theresa Charlotte (Madame Royale), saudara perempuan raja Lady Elizabeth, dan valet Clay ri dan lain-lain .
Ini terganggu oleh berita pengkhianatan Mordred, Lancelot tidak mengambil bahagian dalam konflik maut terakhir, dia selamat daripada raja dan permaisuri, dan Meja Bulat Begitu juga merosot.
- Di sini kita
- dapat melihat bahawa perkataan "Raja" dan "Permaisuri" sering muncul. Oleh itu, model akan menganggap bahawa mungkin terdapat beberapa persamaan antara perkataan ini. Apabila perkataan ini ditukar kepada nilai matematik, ia diletakkan pada jarak yang kecil apabila diwakili dalam ruang berbilang dimensi.
Dengan mengandaikan terdapat perkataan lain "jalan", maka secara logiknya bercakap , ia tidak muncul sekerap dalam korpus teks besar ini sebagai "raja" dan "ratu". Oleh itu, perkataan itu akan jauh dari "Raja" dan "Ratu" dan diletakkan jauh di tempat lain di angkasa.
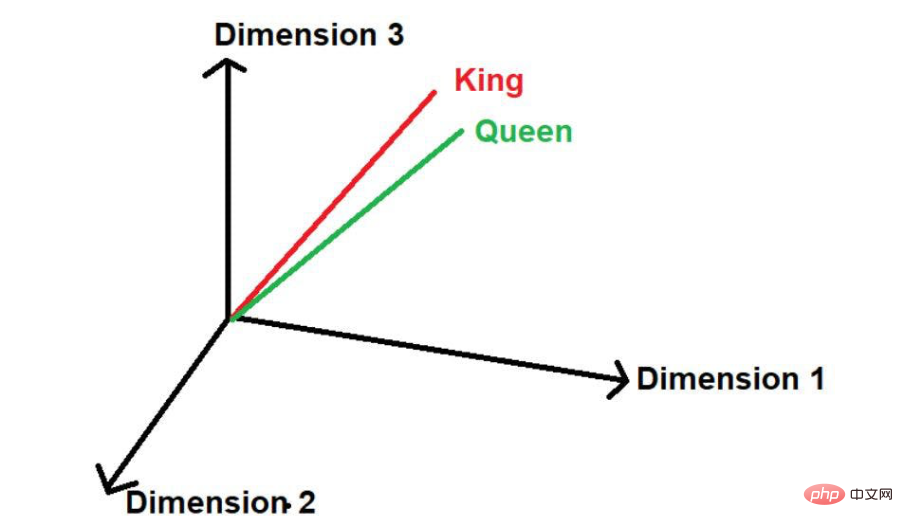 Sumber imej: Ilustrasi disediakan oleh pengarang
Sumber imej: Ilustrasi disediakan oleh pengarang
Dalam matematik, vektor diwakili oleh satu siri nombor, di mana setiap nombor mewakili saiz perkataan dalam dimensi tertentu. Sebagai contoh: Kami meletakkan di sini, "raja" diwakili dalam bentuk [0.21, 0.45, 0.67] dalam ruang tiga dimensi.
Perkataan "ratu" boleh dinyatakan sebagai [0.24,0.41,0.62].
Perkataan "Jalan" boleh dinyatakan sebagai [0.97,0.72,0.36]. 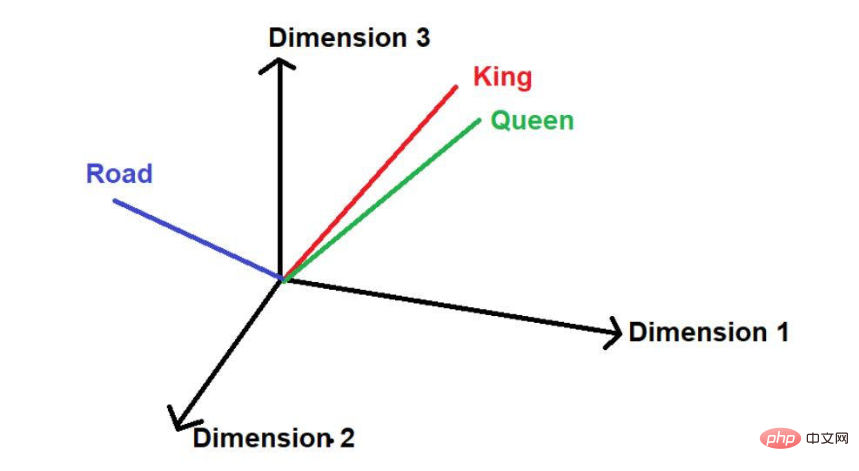
Oleh itu, dalam projek NLP, memahami maklumat lokasi adalah sangat kritikal. Jika model hanya menggunakan nombor dalam ruang berbilang dimensi dan salah faham konteks, ini boleh membawa akibat yang serius, terutamanya dalam model ramalan.
Untuk mengatasi cabaran ini, seni bina rangkaian saraf seperti RNN (Recurrent Neural Network) dan LSTM (Long Short-Term Memory) telah diperkenalkan. Sedikit sebanyak, seni bina ini sangat berjaya dalam memahami maklumat lokasi. Rahsia utama di sebalik kejayaan mereka ialah mempelajari ayat yang panjang dengan mengekalkan susunan perkataan. Di samping itu, mereka juga mempunyai maklumat tentang perkataan yang hampir dengan "kata minat" dan perkataan yang jauh dari "kata minat".
Sebagai contoh, pertimbangkan ayat berikut--
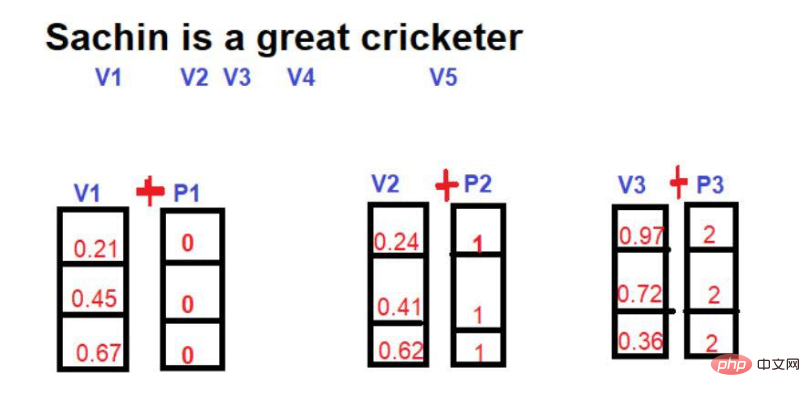
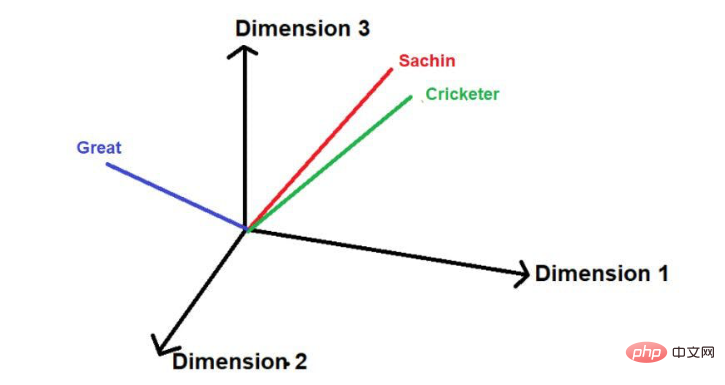
"Sachin ialah pemain kriket terhebat sepanjang zaman".

Sumber imej: Ilustrasi disediakan oleh pengarang
Perkataan yang bergaris merah ialah ini. Anda boleh melihat di sini bahawa "kata-kata yang menarik" dilalui dalam susunan teks asal.
Selain itu, mereka juga boleh belajar dengan mengingati

Sumber imej: Ilustrasi disediakan oleh pengarang
Walaupun, dengan teknik ini, RNN / LSTM boleh memahami maklumat lokasi dalam korpora teks besar. Walau bagaimanapun, masalah sebenar ialah melakukan traversal perkataan secara berurutan dalam korpus besar teks. Bayangkan bahawa kita mempunyai korpus teks yang sangat besar dengan 1 juta perkataan, dan ia akan mengambil masa yang sangat lama untuk membaca setiap perkataan dalam urutan. Kadang-kadang ia tidak boleh dilakukan untuk memberikan begitu banyak masa pengiraan untuk melatih model.
Untuk mengatasi cabaran ini, seni bina termaju baharu - "Transformer" diperkenalkan.
Ciri penting seni bina Transformer ialah korpus teks boleh dipelajari dengan memproses semua perkataan secara selari. Sama ada korpus teks mengandungi 10 perkataan atau 1 juta perkataan, seni bina Transformer tidak peduli.

Sumber imej: Ilustrasi disediakan oleh pengarang

Sumber imej: Ilustrasi disediakan oleh pengarang
Kini kita perlu menghadapi cabaran memproses perkataan secara selari. Kerana semua perkataan diakses secara serentak, maklumat tentang kebergantungan antara perkataan hilang. Oleh itu, model tidak dapat mengingati maklumat berkaitan perkataan tertentu dan tidak dapat menyimpannya dengan tepat. Soalan ini sekali lagi membawa kita kepada cabaran asal untuk mengekalkan kebergantungan konteks walaupun sangat mengurangkan masa pengiraan/latihan model.
Jadi bagaimana untuk menyelesaikan masalah di atas? Penyelesaiannya ialah
percubaan dan ralat berterusan
Pada mulanya, apabila konsep ini diperkenalkan, penyelidik sangat bersemangat untuk menghasilkan kaedah yang dioptimumkan yang boleh mengekalkan maklumat kedudukan dalam struktur Transformer. Sebagai sebahagian daripada percubaan percubaan dan kesilapan, kaedah pertama yang dicuba ialah
Di sini ideanya adalah untuk memperkenalkan vektor matematik baharu semasa menggunakan vektor perkataan, yang mengandungi indeks perkataan.
Sumber imej: Ilustrasi disediakan oleh pengarang
Anggap bahawa gambar berikut ialah perwakilan perkataan dalam ruang berbilang dimensi
Sumber imej: Ilustrasi disediakan oleh pengarang
Selepas menambah vektor kedudukan, saiz dan arahnya mungkin mengubah kedudukan setiap perkataan seperti yang ditunjukkan di bawah.
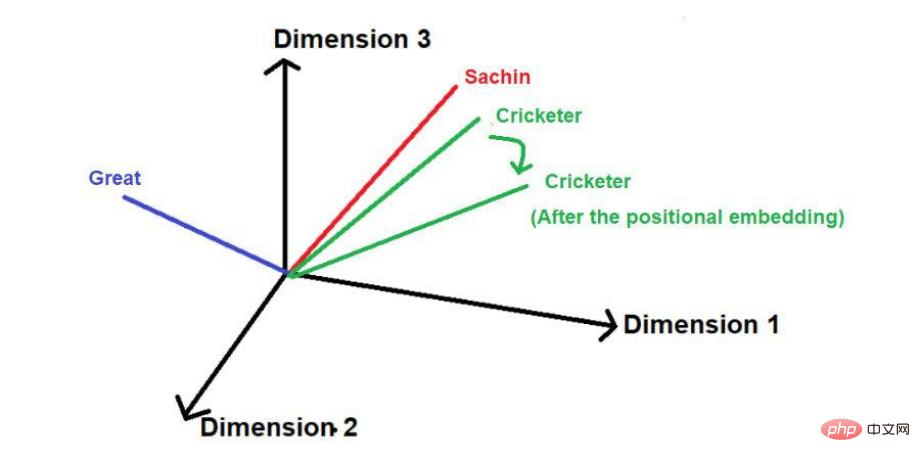
Sumber imej: Ilustrasi disediakan oleh pengarang
Kelemahan teknik ini ialah jika ayat itu sangat panjang, vektor kedudukan akan meningkat secara berkadar. Katakan ayat mempunyai 25 perkataan, maka perkataan pertama akan mempunyai vektor kedudukan dengan magnitud 0 ditambah, dan perkataan terakhir akan mempunyai vektor kedudukan dengan magnitud 24 ditambah. Ketidakpastian yang besar ini boleh menyebabkan masalah apabila kami mengunjurkan nilai ini dalam dimensi yang lebih tinggi.
Satu lagi teknik yang digunakan untuk mengurangkan vektor kedudukan ialah
Di sini, nilai pecahan setiap perkataan berbanding dengan panjang ayat dikira sebagai magnitud vektor kedudukan.
Formula untuk mengira nilai pecahan ialah
Nilai=1/N-1
di mana "N" ialah kedudukan perkataan tertentu.
Sebagai contoh, mari kita pertimbangkan contoh berikut -
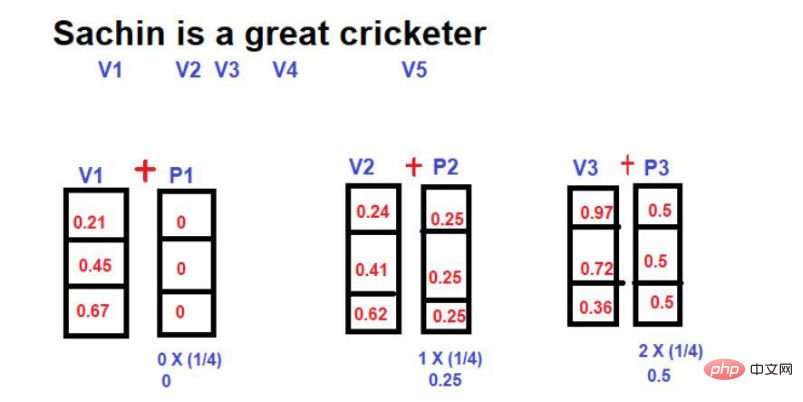
Sumber imej: Ilustrasi disediakan oleh pengarang
Dalam teknik ini, tidak kira Tanpa mengira panjang ayat, magnitud maksimum vektor kedudukan boleh dihadkan kepada 1. Walau bagaimanapun, terdapat kelemahan besar. Jika anda membandingkan dua ayat dengan panjang yang berbeza, nilai benam perkataan pada kedudukan tertentu akan berbeza. Perkataan tertentu atau kedudukannya yang sepadan harus mempunyai nilai benam yang sama di seluruh korpus teks untuk memudahkan pemahaman konteksnya. Jika perkataan yang sama dalam ayat yang berbeza mempunyai nilai benam yang berbeza, mewakili maklumat korpus teks dalam ruang berbilang dimensi menjadi tugas yang sangat kompleks. Walaupun ruang yang kompleks seperti itu dilaksanakan, kemungkinan besar model itu akan runtuh pada satu ketika disebabkan oleh herotan maklumat yang berlebihan. Oleh itu, teknik ini telah dikecualikan daripada pembangunan benam kedudukan Transformer.
Akhirnya, penyelidik mencadangkan seni bina Transformer dan disebut dalam kertas putih terkenal-"Perhatian adalah segala-galanya yang anda perlukan".
Pembenaman kedudukan berdasarkan frekuensi
Menurut teknologi ini, para penyelidik mengesyorkan kaedah pembenaman teks berasaskan frekuensi gelombang, menggunakan formula berikut---
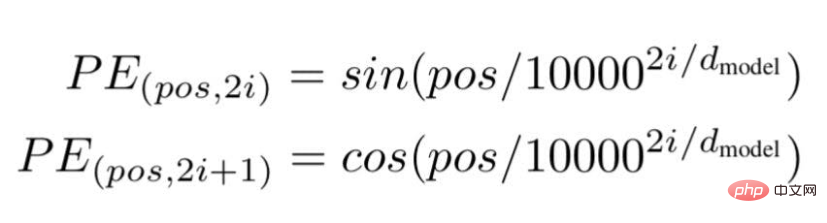
Sumber imej: Ilustrasi disediakan oleh pengarang
"pos" ialah kedudukan atau nilai indeks bagi perkataan tertentu dalam ayat.
"d" ialah panjang/dimensi maksimum vektor yang mewakili perkataan tertentu dalam ayat.
"i" mewakili indeks dimensi pembenaman setiap kedudukan. Ia juga bermaksud kekerapan. Apabila i=0 ia dianggap sebagai frekuensi tertinggi, untuk nilai berikutnya frekuensi dianggap sebagai magnitud yang semakin berkurangan.
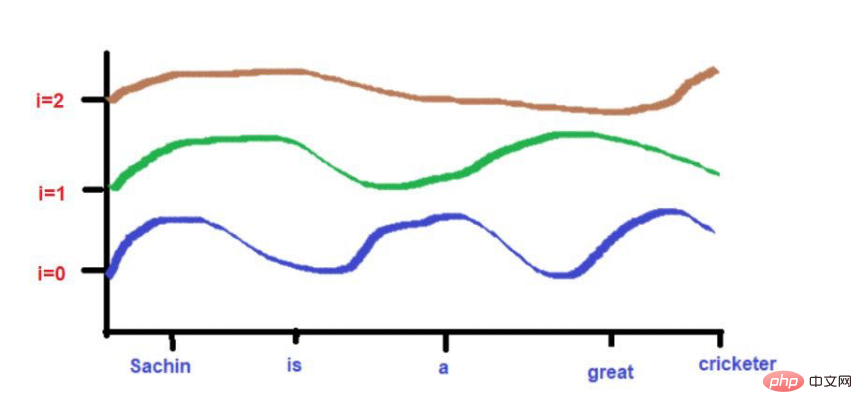
Sumber imej: Ilustrasi disediakan oleh pengarang
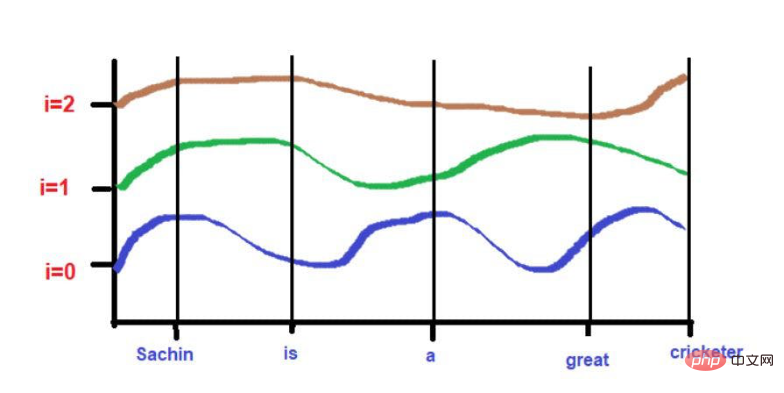
Sumber imej: Ilustrasi disediakan oleh pengarang
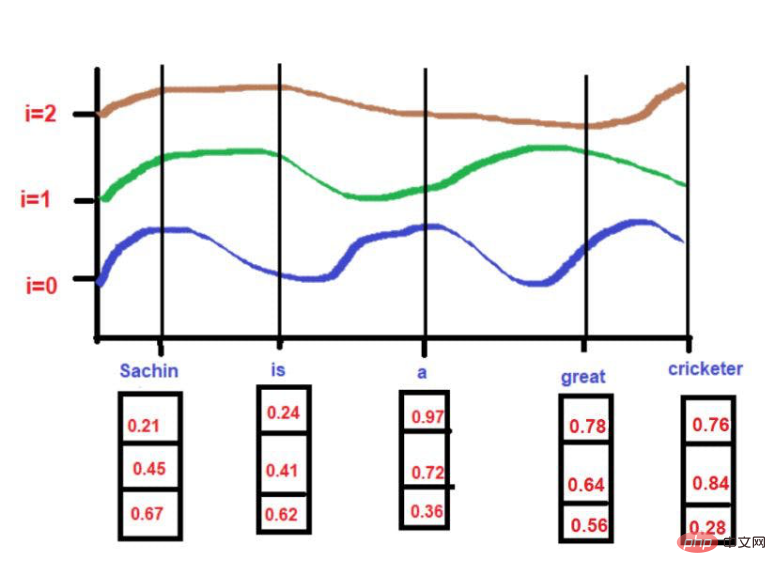
Sumber imej: Ilustrasi disediakan oleh pengarang
Memandangkan ketinggian lengkung bergantung pada kedudukan perkataan yang diterangkan pada paksi-X, ketinggian lengkung boleh digunakan sebagai proksi untuk kedudukan perkataan. Jika dua perkataan sangat serupa, maka kita boleh menganggap kedekatannya dalam ayat itu sebagai sangat tinggi. Begitu juga, jika dua perkataan sangat berbeza ketinggian, maka kita boleh menganggap kedekatannya dalam ayat itu rendah.
Berdasarkan teks contoh kami--"Sachin ialah pemain kriket yang hebat".
Untuk
pos = 0
d = 3
i[0] = 0.21, i[1] = 0.45, i[2] = 0.67
Semasa menggunakan formula.
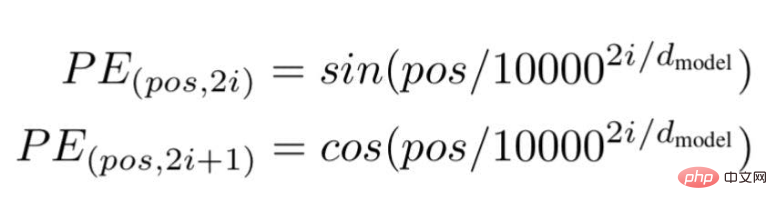
Sumber imej: Ilustrasi disediakan oleh pengarang
Apabila i =0,
PE(0,0) = sin(0 / 10000^2(0)/3)
PE(0,0) = sin(0)
PE(0,0) = 0
apabila i = 1 ,
PE(0,1) = cos(0/10000^2(1)/3)
PE(0,1) = cos(0)
PE(0,1) = 1
apabila i =2,
PE(0,2) = sin(0/10000^2(2)/3)
PE(0,2) = sin(0)
PE(0,2) = 0
untuk
pos = 3
d = 3
i[0] = 0.78, i[1] = 0.64, i[2] = 0.56
Semasa menggunakan formula.
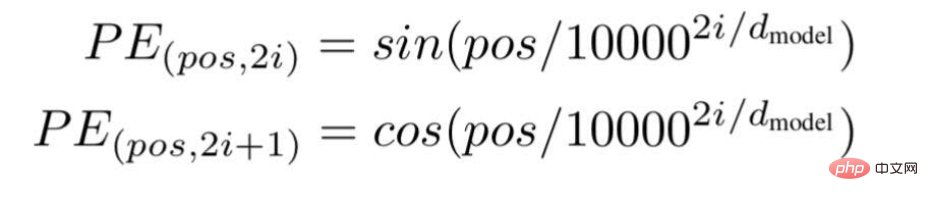
Sumber imej: Ilustrasi disediakan oleh pengarang
Apabila i =0,
PE(3,0) = sin(3 / 10000^2(0)/3)
PE(3,0) = sin(3/1)
PE(3,0) = 0.05
apabila i =1,
PE(3,1) = cos(3/10000^2(1)/3)
PE(3,1) = cos(3/436)
PE(3,1) = 0.99
Apabila i =2,
PE(3,2) = sin(3/10000^2(2)/3)
PE(3,2) = sin(3/1.4)
PE(3,2) = 0.03
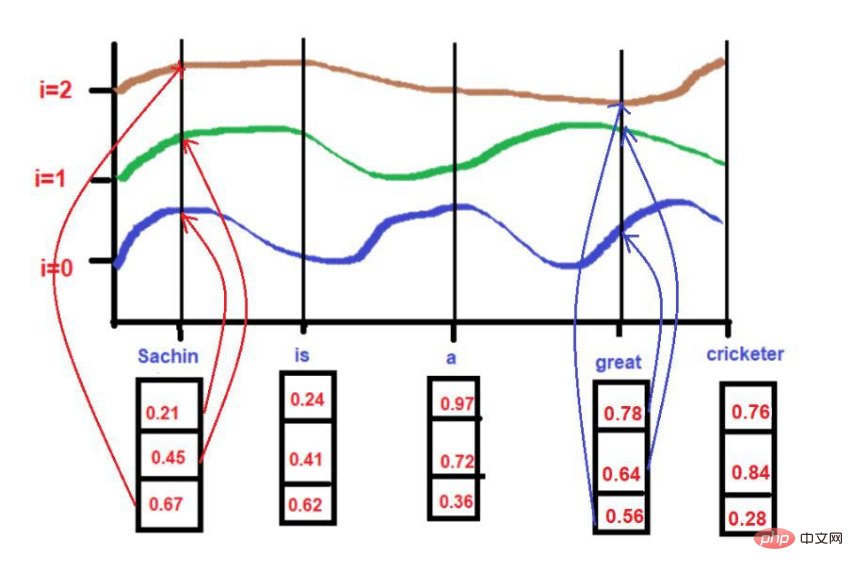
Sumber imej : Ilustrasi disediakan oleh penulis
Di sini, nilai maksimum akan dihadkan kepada 1 (kerana kita menggunakan fungsi sin/cos). Oleh itu, tiada masalah dengan vektor kedudukan magnitud tinggi dalam teknik terdahulu.
Selain itu, perkataan yang sangat dekat antara satu sama lain mungkin jatuh pada ketinggian yang sama pada frekuensi yang lebih rendah, manakala ketinggiannya akan berbeza sedikit pada frekuensi yang lebih tinggi.
Jika perkataan sangat dekat antara satu sama lain, maka ketinggiannya akan sangat berbeza walaupun pada frekuensi yang lebih rendah, dan perbezaan ketinggiannya akan meningkat dengan kekerapan .
Sebagai contoh, pertimbangkan ayat ini--"Raja dan permaisuri sedang berjalan di jalan raya."
Perkataan "Raja" dan "Jalan" diletakkan lebih jauh.
Pertimbangkan bahawa kedua-dua perkataan itu mempunyai ketinggian yang hampir sama selepas menggunakan formula frekuensi gelombang. Apabila kita sampai ke frekuensi yang lebih tinggi (seperti 0), ketinggiannya akan menjadi lebih berbeza.
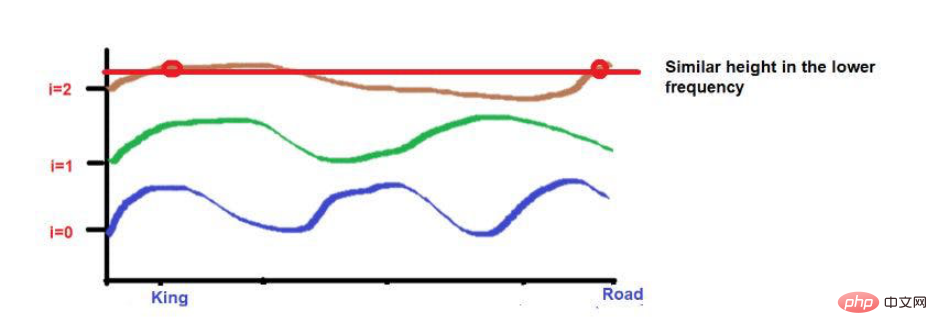
Sumber imej: Ilustrasi disediakan oleh pengarang
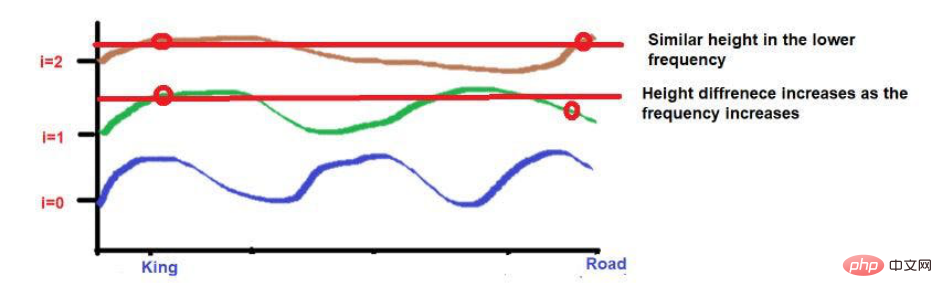
Sumber imej: Ilustrasi disediakan oleh pengarang
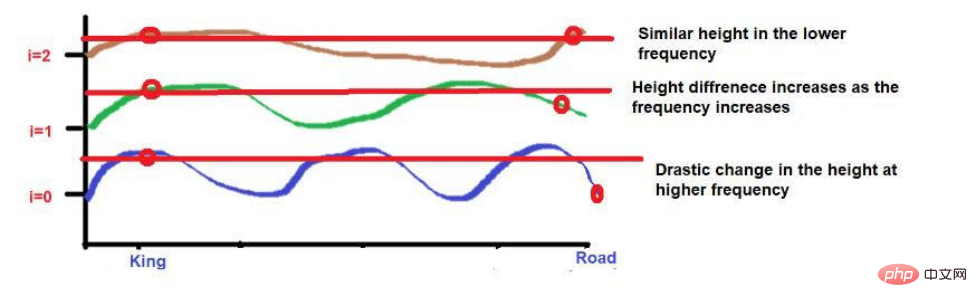
Sumber imej: Ilustrasi disediakan oleh pengarang
Perkataan "Raja" dan "Permaisuri" diletakkan lebih rapat.
2 perkataan ini akan diletakkan pada ketinggian yang sama pada frekuensi yang lebih rendah (seperti 2 di sini). Apabila kita sampai ke frekuensi yang lebih tinggi (seperti 0), perbezaan ketinggian mereka meningkat sedikit untuk menjadikannya boleh dibezakan.
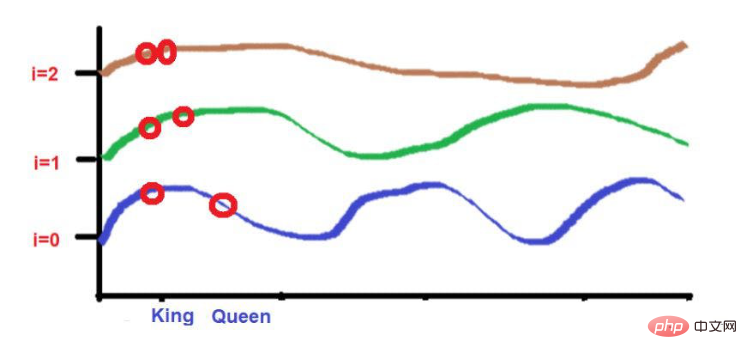
Sumber imej: Ilustrasi disediakan oleh pengarang
Tetapi apa yang perlu kita ambil perhatian ialah jika kedekatan perkataan ini rendah, apabila berkembang ke arah tinggi kekerapan , ketinggian mereka akan sangat berbeza. Jika kata-kata itu sangat rapat, maka hanya terdapat sedikit perbezaan dalam ketinggiannya apabila anda bergerak ke arah frekuensi yang lebih tinggi.
Ringkasan
Melalui artikel ini, saya harap anda mempunyai pemahaman intuitif tentang pengiraan matematik yang kompleks di sebalik pembenaman kedudukan dalam pembelajaran mesin. Ringkasnya, kami membincangkan keperluan untuk mencapai matlamat tertentu.
Bagi peminat teknologi yang berminat dengan "Pemprosesan Bahasa Asli", saya rasa kandungan ini membantu dalam memahami kaedah pengkomputeran yang kompleks. Untuk maklumat yang lebih terperinci, anda boleh merujuk kepada kertas penyelidikan terkenal-"Perhatian Adalah Semua yang Anda Perlukan".
Pengenalan penterjemah
Cui Hao, editor komuniti 51CTO dan arkitek kanan, mempunyai 18 tahun pengalaman pembangunan perisian dan seni bina serta 10 tahun pengalaman seni bina yang diedarkan.
Tajuk asal: Pembenaman Kedudukan: Rahsia di sebalik Ketepatan Rangkaian Neural Transformer , Pengarang: Sanjay Kumar
Atas ialah kandungan terperinci 'Pembenaman Lokasi”: Rahsia Di Sebalik Transformer. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI