

Pembelajaran pengukuhan mendalam menangani pemanduan autonomi dunia sebenar

Kertas arXiv "Tackling Real-World Autonomous Driving using Deep Reinforcement Learning" telah dimuat naik pada 5 Julai 2022. Pengarangnya adalah dari Vislab dari Universiti Parma di Itali dan Ambarella (pemerolehan Vislab).

Dalam barisan pemasangan pemanduan autonomi biasa, sistem kawalan mewakili dua komponen paling kritikal, di mana data yang diambil oleh penderia dan data yang diproses oleh algoritma persepsi digunakan untuk mencapai keselamatan Tingkah laku memandu sendiri yang selesa. Khususnya, modul perancangan meramalkan laluan yang perlu diikuti oleh kereta pandu sendiri untuk melakukan tindakan peringkat tinggi yang betul, manakala sistem kawalan melakukan satu siri tindakan peringkat rendah, mengawal stereng, pendikit dan brek.
Kerja ini mencadangkan perancang Pembelajaran Pengukuhan Dalam (DRL) tanpa model untuk melatih rangkaian saraf untuk meramalkan pecutan dan sudut stereng, dengan itu memperoleh data autonomi yang didorong oleh kedudukan kereta dan algoritma persepsi mengeluarkan data yang didorong oleh modul individu kenderaan. Khususnya, sistem yang telah disimulasikan dan dilatih sepenuhnya boleh memandu dengan lancar dan selamat dalam persekitaran bebas halangan simulasi dan sebenar (kawasan bandar Palma), membuktikan bahawa sistem itu mempunyai keupayaan generalisasi yang baik dan juga boleh memandu dalam persekitaran selain daripada senario latihan. Di samping itu, untuk menggunakan sistem pada kenderaan autonomi sebenar dan mengurangkan jurang antara prestasi simulasi dan prestasi sebenar, penulis juga membangunkan modul yang diwakili oleh rangkaian neural kecil yang mampu menghasilkan semula tingkah laku persekitaran sebenar semasa latihan simulasi Tingkah laku dinamik kereta.
Sejak beberapa dekad yang lalu, kemajuan besar telah dicapai dalam meningkatkan tahap automasi kenderaan, daripada pendekatan mudah berasaskan peraturan kepada melaksanakan sistem pintar berasaskan AI. Khususnya, sistem ini bertujuan untuk menangani batasan utama pendekatan berasaskan peraturan, iaitu kekurangan rundingan dan interaksi dengan pengguna jalan raya lain dan pemahaman yang lemah tentang dinamika adegan.
Pembelajaran Pengukuhan (RL) digunakan secara meluas untuk menyelesaikan tugasan yang menggunakan output ruang kawalan diskret, seperti Go, permainan Atari atau catur, serta pemanduan autonomi dalam ruang kawalan berterusan. Khususnya, algoritma RL digunakan secara meluas dalam bidang pemanduan autonomi untuk membangunkan sistem perlaksanaan membuat keputusan dan manuver, seperti pertukaran lorong aktif, menjaga lorong, manuver memotong, persimpangan dan pemprosesan bulatan, dsb.
Artikel ini menggunakan versi tertunda D-A3C, yang tergolong dalam keluarga algoritma Actor-Critics yang dipanggil. Khususnya terdiri daripada dua entiti berbeza: Pelakon dan Pengkritik. Tujuan Pelakon adalah untuk memilih tindakan yang perlu dilakukan oleh ejen, manakala Pengkritik menganggarkan fungsi nilai keadaan, iaitu, sejauh mana keadaan khusus ejen itu. Dalam erti kata lain, Pelakon ialah taburan kebarangkalian π(a|s; θπ) ke atas tindakan (di mana θ ialah parameter rangkaian), dan pengkritik adalah anggaran fungsi nilai keadaan v(st; θv) = E(Rt|st), di mana R ialah Pulangan yang dijangkakan.
Peta definisi tinggi yang dibangunkan secara dalaman melaksanakan simulator simulasi; contoh adegan ditunjukkan dalam Rajah a, yang merupakan sebahagian daripada kawasan peta sistem ujian kereta pandu sendiri, manakala Rajah B menunjukkan pandangan sekeliling yang dilihat oleh ejen, Sesuai dengan kawasan seluas 50 × 50 meter, ia dibahagikan kepada empat saluran: halangan (Rajah c), ruang boleh dipandu (Rajah d), laluan yang harus diikuti oleh ejen ( Rajah e) dan garisan berhenti (Rajah f). Peta definisi tinggi dalam simulator membolehkan mendapatkan beberapa maklumat tentang persekitaran luaran, seperti lokasi atau bilangan lorong, had laju jalan raya, dsb.
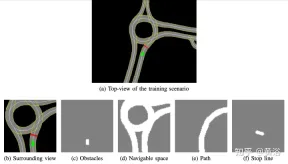
Memfokuskan pada mencapai gaya pemanduan yang lancar dan selamat, jadi ejen dilatih dalam adegan statik, tidak termasuk halangan atau pengguna jalan raya lain, belajar mengikut laluan dan mematuhi had laju .
Gunakan rangkaian saraf seperti yang ditunjukkan dalam rajah untuk melatih ejen dan meramalkan sudut stereng dan pecutan setiap 100 milisaat. Ia dibahagikan kepada dua sub-modul: sub-modul pertama boleh menentukan sudut stereng sa, dan sub-modul kedua digunakan untuk menentukan acc pecutan. Input kepada dua submodul ini diwakili oleh 4 saluran (ruang pandu, laluan, halangan dan garisan henti), sepadan dengan pandangan sekeliling ejen. Setiap saluran input visual mengandungi empat imej 84×84 piksel untuk memberikan ejen sejarah keadaan lalu. Bersama-sama dengan input visual ini, rangkaian menerima 5 parameter skalar, termasuk kelajuan sasaran (had kelajuan jalan raya), kelajuan semasa ejen, nisbah kelajuan sasaran kelajuan semasa dan tindakan terakhir yang berkaitan dengan sudut stereng dan pecutan.
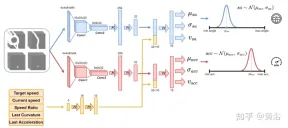
Untuk memastikan penerokaan, dua taburan Gaussian digunakan untuk sampel keluaran dua sub-modul untuk mendapatkan pecutan relatif (acc=N (μacc, σacc) ) dan Sudut stereng (sa=N(μsa,σsa)). Sisihan piawai σacc dan σsa diramalkan dan dimodulasi oleh rangkaian saraf semasa fasa latihan untuk menganggarkan ketidakpastian model. Di samping itu, rangkaian menggunakan dua fungsi ganjaran berbeza R-acc-t dan R-sa-t, masing-masing berkaitan dengan pecutan dan sudut stereng, untuk menjana anggaran nilai keadaan yang sepadan (vacc dan vsa).
Rangkaian saraf dilatih pada empat adegan di bandar Palma. Untuk setiap senario, berbilang kejadian dibuat dan ejen adalah bebas antara satu sama lain pada kejadian ini. Setiap ejen mengikut model basikal kinematik, dengan sudut stereng [-0.2, +0.2] dan pecutan [-2.0 m, +2.0 m]. Pada permulaan segmen, setiap ejen mula memandu pada kelajuan rawak ([0.0, 8.0]) dan mengikut laluan yang dimaksudkan, mematuhi had laju jalan. Had laju jalan raya di kawasan bandar ini berjulat dari 4 ms hingga 8.3 ms.
Akhir sekali, memandangkan tiada halangan dalam adegan latihan, klip boleh berakhir di salah satu keadaan terminal berikut:
- Matlamat dicapai : Ejen mencapai lokasi sasaran akhir.
- Memandu di luar jalan: Ejen melangkaui laluan yang dimaksudkan dan tersilap meramal sudut stereng.
- Masa Sudah Tamat: Masa untuk melengkapkan serpihan tamat; ini terutamanya disebabkan oleh ramalan berhati-hati terhadap keluaran pecutan semasa memandu di bawah had laju jalan.
Untuk mendapatkan strategi yang boleh memandu kereta dengan jayanya dalam persekitaran simulasi dan sebenar, pembentukan ganjaran adalah penting untuk mencapai tingkah laku yang diingini. Khususnya, dua fungsi ganjaran berbeza ditakrifkan untuk menilai kedua-dua tindakan masing-masing: R-acc-t dan R-sa-t masing-masing berkaitan dengan pecutan dan sudut stereng, ditakrifkan seperti berikut:
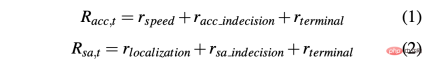
di mana
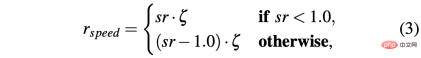
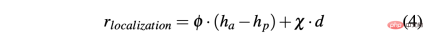
R-sa-t dan R-acc-t kedua-duanya mempunyai unsur dalam formula Penalize dua tindakan berturut-turut yang perbezaan dalam pecutan dan sudut stereng adalah lebih besar daripada ambang tertentu δacc dan δsa masing-masing. Khususnya, perbezaan antara dua pecutan berturut-turut dikira seperti berikut: Δacc=| acc (t) − acc (t− 1) | , manakala rac_indecision ditakrifkan seperti berikut:
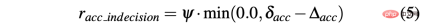
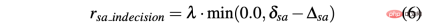
- Matlamat dicapai: Ejen mencapai kedudukan matlamat, jadi kedua-duanya memberi ganjaran rterminal ditetapkan kepada +1.0;
- Memandu di luar jalan: Ejen menyimpang dari laluannya, terutamanya disebabkan oleh ramalan sudut stereng yang tidak tepat. Oleh itu, tetapkan isyarat negatif -1.0 kepada Rsa,t dan isyarat negatif 0.0 kepada R-acc-t; ramalan pecutan terlalu berhati-hati; oleh itu, rterminal menganggap −1.0 untuk R-acc-t dan 0.0 untuk R-sa-t.
- Salah satu masalah utama yang dikaitkan dengan simulator ialah perbezaan antara data simulasi dan sebenar, yang disebabkan oleh kesukaran untuk menghasilkan semula situasi dunia sebenar dalam simulator secara realistik. Untuk mengatasi masalah ini, simulator sintetik digunakan untuk memudahkan input kepada rangkaian saraf dan mengurangkan jurang antara data simulasi dan sebenar. Malah, maklumat yang terkandung dalam 4 saluran (halangan, ruang memandu, laluan dan garisan henti) sebagai input kepada rangkaian saraf boleh dihasilkan semula dengan mudah oleh algoritma persepsi dan penyetempatan dan peta definisi tinggi yang dibenamkan pada kenderaan autonomi sebenar.
Malah, titik pecutan dan sudut stereng yang dipratetap oleh rangkaian saraf bukanlah arahan yang boleh dilaksanakan, dan tidak mengambil kira beberapa faktor, seperti inersia sistem, kelewatan penggerak dan faktor bukan ideal yang lain. Oleh itu, untuk menghasilkan semula dinamik kenderaan sebenar secara realistik yang mungkin, model yang terdiri daripada rangkaian saraf kecil yang terdiri daripada 3 lapisan bersambung sepenuhnya (tindak balas mendalam) telah dibangunkan. Graf kelakuan tindak balas kedalaman ditunjukkan sebagai garis putus-putus merah dalam rajah di atas Ia boleh diperhatikan bahawa ia sangat serupa dengan lengkung oren yang mewakili kereta autonomi sebenar. Memandangkan adegan latihan tidak mempunyai halangan dan kenderaan lalu lintas, masalah yang diterangkan adalah lebih ketara untuk aktiviti sudut stereng, tetapi idea yang sama telah digunakan untuk output pecutan.
Latih model tindak balas mendalam menggunakan set data yang dikumpulkan pada kereta pandu sendiri, di mana input sepadan dengan arahan yang diberikan kepada kenderaan oleh pemandu manusia (tekanan pemecut dan pusingan stereng) dan output sepadan dengan pendikit, brek dan lentur kenderaan, boleh diukur menggunakan GPS, odometer atau teknologi lain. Dengan cara ini, membenamkan model sedemikian dalam simulator menghasilkan sistem yang lebih berskala yang menghasilkan semula gelagat kenderaan autonomi. Oleh itu modul tindak balas kedalaman adalah penting untuk pembetulan sudut stereng, tetapi walaupun dalam cara yang kurang jelas, ia adalah perlu untuk pecutan, dan ini akan menjadi jelas kelihatan dengan pengenalan halangan.
Dua strategi berbeza telah diuji pada data sebenar untuk mengesahkan kesan model tindak balas mendalam pada sistem. Selepas itu, sahkan bahawa kenderaan mengikut laluan dengan betul dan mematuhi had laju yang diperoleh daripada peta HD. Akhir sekali, terbukti bahawa pra-latihan rangkaian saraf melalui Pembelajaran Peniruan boleh mengurangkan jumlah masa latihan dengan ketara.
Strateginya adalah seperti berikut:
- Strategi 1: Jangan gunakan model tindak balas dalam untuk latihan, tetapi gunakan penapis laluan rendah untuk mensimulasikan tindak balas kenderaan sebenar kepada tindakan sasaran.
- Strategi 2: Pastikan dinamik yang lebih realistik dengan memperkenalkan model tindak balas yang mendalam untuk latihan.
Ujian yang dilakukan dalam simulasi menghasilkan keputusan yang baik untuk kedua-dua strategi. Malah, sama ada dalam adegan terlatih atau kawasan peta yang tidak terlatih, ejen boleh mencapai matlamat dengan tingkah laku yang lancar dan selamat 100% pada setiap masa.
Dengan menguji strategi dalam senario sebenar, keputusan yang berbeza diperolehi. Strategi 1 tidak boleh mengendalikan dinamik kenderaan dan melakukan tindakan yang diramalkan secara berbeza daripada ejen dalam simulasi dengan cara ini, Strategi 1 akan melihat keadaan ramalannya yang tidak dijangka, yang membawa kepada tingkah laku bising pada kenderaan autonomi dan tingkah laku yang tidak selesa.
Tingkah laku ini juga menjejaskan kebolehpercayaan sistem, dan sebenarnya, bantuan manusia kadangkala diperlukan untuk mengelakkan kereta pandu sendiri lari dari jalan.
Sebaliknya, dalam semua ujian dunia sebenar bagi kereta pandu sendiri, Strategi 2 tidak memerlukan manusia untuk mengambil alih, mengetahui dinamik kenderaan dan cara sistem akan berkembang untuk meramalkan tindakan. Satu-satunya situasi yang memerlukan campur tangan manusia adalah untuk mengelakkan pengguna jalan raya yang lain, bagaimanapun, situasi ini tidak dianggap sebagai kegagalan kerana kedua-dua strategi 1 dan 2 dilatih dalam senario bebas halangan.
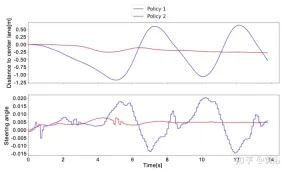
Untuk lebih memahami perbezaan antara Strategi 1 dan Strategi 2, berikut ialah sudut stereng yang diramalkan oleh rangkaian saraf dan jarak ke lorong tengah dalam tetingkap pendek ujian dunia sebenar. Dapat diperhatikan bahawa kedua-dua strategi berkelakuan berbeza sama sekali .
Untuk mengatasi had RL, yang memerlukan berjuta-juta segmen untuk mencapai penyelesaian optimum, pra-latihan dilakukan melalui Pembelajaran Tiruan (IL). Tambahan pula, walaupun trend dalam IL adalah untuk melatih model besar, rangkaian saraf kecil yang sama (~1 juta parameter) digunakan, kerana ideanya adalah untuk meneruskan latihan sistem menggunakan rangka kerja RL untuk memastikan lebih banyak keteguhan dan keupayaan generalisasi. Dengan cara ini, penggunaan sumber perkakasan tidak meningkat, yang penting memandangkan kemungkinan latihan berbilang ejen pada masa hadapan.
Data data yang digunakan dalam fasa latihan IL dijana oleh ejen simulasi yang mengikut pendekatan berasaskan peraturan untuk pergerakan. Khususnya, untuk lenturan, algoritma penjejakan pengejaran tulen digunakan, di mana ejen bertujuan untuk bergerak di sepanjang titik laluan tertentu. Sebaliknya, gunakan model IDM untuk mengawal pecutan membujur ejen.
Untuk mencipta set data, ejen berasaskan peraturan telah dialihkan ke atas empat senario latihan, menyimpan parameter skalar dan empat input visual setiap 100 milisaat. Sebaliknya, output diberikan oleh algoritma pengejaran tulen dan model IDM.
Dua kawalan mendatar dan menegak yang sepadan dengan output hanya mewakili tupel (μacc, μsa). Oleh itu, semasa fasa latihan IL, nilai sisihan piawai (σacc, σsa) tidak dianggarkan, begitu juga fungsi nilai (vacc, vsa) dianggarkan. Ciri-ciri ini dan modul tindak balas mendalam dipelajari dalam fasa latihan IL+RL.
Seperti yang ditunjukkan dalam rajah, ia menunjukkan latihan rangkaian saraf yang sama bermula dari peringkat pra-latihan (lengkung biru, IL+RL), dan membandingkannya dengan RL (lengkung merah, RL tulen) mengakibatkan empat kes. Walaupun latihan IL+RL memerlukan lebih sedikit masa daripada RL tulen dan arah alirannya lebih stabil, kedua-dua kaedah mencapai kadar kejayaan yang baik (Rajah a).

Tambahan pula, keluk ganjaran yang ditunjukkan dalam Rajah b membuktikan bahawa polisi yang diperoleh menggunakan pendekatan RL tulen (lengkung merah) tidak mencapai penyelesaian yang boleh diterima untuk lebih banyak masa latihan, manakala IL+ The Strategi RL mencapai penyelesaian optimum dalam beberapa segmen (lengkung biru dalam panel b). Dalam kes ini, penyelesaian optimum diwakili oleh garis putus-putus oren. Garis dasar ini mewakili purata ganjaran yang diperoleh oleh ejen simulasi yang melaksanakan 50,000 segmen merentas 4 senario. Ejen simulasi mengikut peraturan deterministik, yang sama seperti yang digunakan untuk mengumpul set data pra-latihan IL, iaitu, peraturan mengejar tulen digunakan untuk lenturan dan peraturan IDM digunakan untuk pecutan membujur. Jurang antara kedua-dua pendekatan mungkin lebih ketara, sistem latihan untuk melakukan manuver yang lebih kompleks di mana interaksi kecerdasan-badan mungkin diperlukan.
Atas ialah kandungan terperinci Pembelajaran pengukuhan mendalam menangani pemanduan autonomi dunia sebenar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Jurang kemahiran AI memperlahankan rantaian bekalanApr 26, 2025 am 11:13 AM
Jurang kemahiran AI memperlahankan rantaian bekalanApr 26, 2025 am 11:13 AMIstilah "tenaga kerja siap sedia" sering digunakan, tetapi apakah maksudnya dalam industri rantaian bekalan? Menurut Abe Eshkenazi, Ketua Pegawai Eksekutif Persatuan Pengurusan Rantaian Bekalan (ASCM), ia menandakan profesional yang mampu mengkritik
 Bagaimana satu syarikat secara senyap -senyap bekerja untuk mengubah AI selama -lamanyaApr 26, 2025 am 11:12 AM
Bagaimana satu syarikat secara senyap -senyap bekerja untuk mengubah AI selama -lamanyaApr 26, 2025 am 11:12 AMRevolusi AI yang terdesentralisasi secara senyap -senyap mendapat momentum. Jumaat ini di Austin, Texas, Sidang Kemuncak Endgame Bittensor menandakan momen penting, beralih ke desentralisasi AI (DEAI) dari teori kepada aplikasi praktikal. Tidak seperti iklan mewah
 NVIDIA Melepaskan Microservices Nemo Untuk Menyebarkan Pembangunan Agen AIApr 26, 2025 am 11:11 AM
NVIDIA Melepaskan Microservices Nemo Untuk Menyebarkan Pembangunan Agen AIApr 26, 2025 am 11:11 AMPerusahaan AI menghadapi cabaran integrasi data Penggunaan perusahaan AI menghadapi cabaran utama: sistem bangunan yang dapat mengekalkan ketepatan dan kepraktisan dengan terus belajar data perniagaan. Microservices NEMO menyelesaikan masalah ini dengan mewujudkan apa yang NVIDIA menggambarkan sebagai "Flywheel Data", yang membolehkan sistem AI tetap relevan melalui pendedahan berterusan kepada maklumat perusahaan dan interaksi pengguna. Toolkit yang baru dilancarkan ini mengandungi lima microservices utama: Nemo Customizer mengendalikan penalaan model bahasa yang besar dengan latihan yang lebih tinggi. NEMO Evaluator menyediakan penilaian ringkas model AI untuk tanda aras tersuai. Nemo Guardrails Melaksanakan Kawalan Keselamatan untuk mengekalkan pematuhan dan kesesuaian
 AI melukis gambar baru untuk masa depan seni dan reka bentukApr 26, 2025 am 11:10 AM
AI melukis gambar baru untuk masa depan seni dan reka bentukApr 26, 2025 am 11:10 AMAI: Masa Depan Seni dan Reka Bentuk Kecerdasan Buatan (AI) mengubah bidang seni dan reka bentuk dengan cara yang belum pernah terjadi sebelumnya, dan impaknya tidak lagi terhad kepada amatur, tetapi lebih mempengaruhi profesional. Skim karya seni dan reka bentuk yang dihasilkan oleh AI dengan cepat menggantikan imej dan pereka bahan tradisional dalam banyak aktiviti reka bentuk transaksional seperti pengiklanan, generasi imej media sosial dan reka bentuk web. Walau bagaimanapun, artis dan pereka profesional juga mendapati nilai praktikal AI. Mereka menggunakan AI sebagai alat tambahan untuk meneroka kemungkinan estetik baru, menggabungkan gaya yang berbeza, dan membuat kesan visual baru. AI membantu artis dan pereka mengautomasikan tugas berulang, mencadangkan elemen reka bentuk yang berbeza dan memberikan input kreatif. AI menyokong pemindahan gaya, iaitu menggunakan gaya gambar
 Bagaimana Zoom merevolusikan kerja dengan Agentic AI: Dari mesyuarat ke tonggakApr 26, 2025 am 11:09 AM
Bagaimana Zoom merevolusikan kerja dengan Agentic AI: Dari mesyuarat ke tonggakApr 26, 2025 am 11:09 AMZoom, yang pada mulanya dikenali untuk platform persidangan video, memimpin revolusi tempat kerja dengan penggunaan inovatif AIS AI. Perbualan baru -baru ini dengan CTO Zoom, XD Huang, mendedahkan penglihatan yang bercita -cita tinggi syarikat itu. Menentukan Agentic AI Huang d
 Ancaman eksistensi ke universitiApr 26, 2025 am 11:08 AM
Ancaman eksistensi ke universitiApr 26, 2025 am 11:08 AMAdakah AI akan merevolusikan pendidikan? Soalan ini mendorong refleksi serius di kalangan pendidik dan pihak berkepentingan. Penyepaduan AI ke dalam pendidikan memberikan peluang dan cabaran. Sebagai Matthew Lynch dari Nota Edvocate Tech, Universit
 Prototaip: saintis Amerika mencari pekerjaan di luar negaraApr 26, 2025 am 11:07 AM
Prototaip: saintis Amerika mencari pekerjaan di luar negaraApr 26, 2025 am 11:07 AMPembangunan penyelidikan dan teknologi saintifik di Amerika Syarikat mungkin menghadapi cabaran, mungkin disebabkan oleh pemotongan anggaran. Menurut Alam, bilangan saintis Amerika yang memohon pekerjaan di luar negara meningkat sebanyak 32% dari Januari hingga Mac 2025 berbanding dengan tempoh yang sama pada tahun 2024. Pungutan sebelumnya menunjukkan bahawa 75% penyelidik yang ditinjau sedang mempertimbangkan untuk mencari pekerjaan di Eropah dan Kanada. Beratus-ratus geran NIH dan NSF telah ditamatkan dalam beberapa bulan yang lalu, dengan geran baru NIH turun kira-kira $ 2.3 bilion tahun ini, setitik hampir satu pertiga. Cadangan belanjawan yang bocor menunjukkan bahawa pentadbiran Trump sedang mempertimbangkan untuk memotong belanjawan secara mendadak untuk institusi saintifik, dengan kemungkinan pengurangan sehingga 50%. Kegawatan dalam bidang penyelidikan asas juga telah menjejaskan salah satu kelebihan utama Amerika Syarikat: menarik bakat luar negara. 35
 Semua Mengenai Keluarga GPT 4.1 Terbuka AI - Analytics VidhyaApr 26, 2025 am 10:19 AM
Semua Mengenai Keluarga GPT 4.1 Terbuka AI - Analytics VidhyaApr 26, 2025 am 10:19 AMOpenAI melancarkan siri GPT-4.1 yang kuat: keluarga tiga model bahasa lanjutan yang direka untuk aplikasi dunia nyata. Lompat penting ini menawarkan masa tindak balas yang lebih cepat, pemahaman yang lebih baik, dan kos yang dikurangkan secara drastik berbanding t


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

DVWA
Damn Vulnerable Web App (DVWA) ialah aplikasi web PHP/MySQL yang sangat terdedah. Matlamat utamanya adalah untuk menjadi bantuan bagi profesional keselamatan untuk menguji kemahiran dan alatan mereka dalam persekitaran undang-undang, untuk membantu pembangun web lebih memahami proses mengamankan aplikasi web, dan untuk membantu guru/pelajar mengajar/belajar dalam persekitaran bilik darjah Aplikasi web keselamatan. Matlamat DVWA adalah untuk mempraktikkan beberapa kelemahan web yang paling biasa melalui antara muka yang mudah dan mudah, dengan pelbagai tahap kesukaran. Sila ambil perhatian bahawa perisian ini

mPDF
mPDF ialah perpustakaan PHP yang boleh menjana fail PDF daripada HTML yang dikodkan UTF-8. Pengarang asal, Ian Back, menulis mPDF untuk mengeluarkan fail PDF "dengan cepat" dari tapak webnya dan mengendalikan bahasa yang berbeza. Ia lebih perlahan dan menghasilkan fail yang lebih besar apabila menggunakan fon Unicode daripada skrip asal seperti HTML2FPDF, tetapi menyokong gaya CSS dsb. dan mempunyai banyak peningkatan. Menyokong hampir semua bahasa, termasuk RTL (Arab dan Ibrani) dan CJK (Cina, Jepun dan Korea). Menyokong elemen peringkat blok bersarang (seperti P, DIV),

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

