

 Peranti teknologiAIPenerokaan teknologi berbilang modal dalam senario ingat semula carian utama Taobao
Peranti teknologiAIPenerokaan teknologi berbilang modal dalam senario ingat semula carian utama TaobaoPenerokaan teknologi berbilang modal dalam senario ingat semula carian utama Taobao

Panggilan semula carian, sebagai asas sistem carian, menentukan had atas peningkatan kesan. Cara untuk terus membawa nilai tambahan yang berbeza kepada keputusan penarikan semula besar-besaran sedia ada ialah cabaran utama yang kami hadapi. Gabungan pra-latihan berbilang modal dan penarikan balik membuka ufuk baharu bagi kami dan membawa peningkatan ketara dalam kesan dalam talian.
Kata-kata pengantar
Pra-latihan pelbagai mod ialah tumpuan penyelidikan dalam akademik dan industri Dengan pra-latihan pada data berskala besar, Mendapatkan korespondensi semantik antara modaliti yang berbeza boleh meningkatkan prestasi dalam pelbagai tugasan hiliran seperti menjawab soalan visual, penaakulan visual dan mendapatkan imej dan teks. Di dalam kumpulan, terdapat juga beberapa penyelidikan dan aplikasi pra-latihan pelbagai modal. Dalam senario carian utama Taobao, terdapat keperluan mendapatkan semula rentas modal antara Pertanyaan yang dimasukkan oleh pengguna dan produk yang akan dipanggil semula, bagaimanapun, pada masa lalu, lebih banyak tajuk dan ciri statistik digunakan untuk produk , mengabaikan maklumat yang lebih intuitif seperti imej. Tetapi untuk pertanyaan tertentu dengan elemen visual (seperti pakaian putih, pakaian bunga), saya percaya semua orang akan tertarik dengan imej terlebih dahulu pada halaman hasil carian.


Adegan carian utama Taobao
1 Di satu pihak, imej menduduki kedudukan yang lebih menonjol, sebaliknya, imej mungkin mengandungi maklumat yang tidak termasuk dalam tajuk, seperti elemen visual seperti putih dan bunga. Untuk yang terakhir, dua situasi perlu dibezakan: satu ialah terdapat maklumat dalam tajuk, tetapi ia tidak dapat dipaparkan sepenuhnya kerana sekatan paparan Keadaan ini tidak menjejaskan penarikan semula produk dalam pautan sistem bahawa tiada maklumat dalam tajuk tetapi imej Terdapat, iaitu, imej boleh membawa kenaikan berbanding teks. Yang terakhir inilah yang perlu kita fokuskan.
▐ Masalah teknikal dan penyelesaian
Di utama Terdapat dua masalah utama yang perlu diselesaikan apabila menggunakan teknologi berbilang modal dalam senario carian dan ingat semula:
- Model pra-latihan grafik dan teks berbilang modal secara amnya menyepadukan modaliti imej dan teks carian utama mempunyai kewujudan Pertanyaan, berdasarkan modaliti imej dan teks asal imej dan tajuk produk, modaliti teks tambahan perlu dipertimbangkan. Pada masa yang sama, terdapat jurang semantik antara Query dan tajuk produk adalah agak pendek dan luas, manakala tajuk produk selalunya panjang dan dipenuhi dengan kata kunci kerana penjual melakukan SEO.
- Biasanya hubungan antara tugas pralatihan dan tugas hiliran ialah pralatihan menggunakan data tidak berlabel berskala besar, dan hiliran menggunakan sejumlah kecil data berlabel. Walau bagaimanapun, untuk carian dan penarikan semula utama, skala tugas penarikan balik vektor hiliran adalah besar, dengan data dalam berbilion-bilion Walau bagaimanapun, terhad oleh sumber GPU yang terhad, pra-latihan hanya boleh menggunakan jumlah data yang agak kecil. Dalam kes ini, sama ada pra-latihan juga boleh membawa faedah kepada tugas hiliran.
Penyelesaian kami adalah seperti berikut:
- Pralatihan imej teks : Lulus Pertanyaan dan Item produk masing-masing melalui Pengekod, dan masukkannya ke dalam model silang sebagai pengekod Negeri menara berkembar. Jika kita melihat menara Pertanyaan dan Item, mereka berinteraksi pada peringkat kemudian, serupa dengan model dua aliran Walau bagaimanapun, melihat secara khusus pada menara Item, kedua-dua mod imej dan tajuk berinteraksi pada peringkat awal model aliran tunggal. Oleh itu, struktur model kami berbeza daripada struktur aliran tunggal atau dwi-aliran biasa. Titik permulaan reka bentuk ini adalah untuk mengekstrak vektor Pertanyaan dan vektor Item dengan lebih berkesan, menyediakan input untuk model penarikan semula vektor menara berkembar hiliran, dan memperkenalkan kaedah pemodelan produk dalaman menara berkembar dalam peringkat pra-latihan. Untuk memodelkan sambungan semantik dan jurang antara Pertanyaan dan tajuk, kami berkongsi Pengekod Pertanyaan dan menara berkembar Item, dan kemudian mempelajari model bahasa secara berasingan.
- Hubungan antara tugasan pra-latihan dan panggil balik : Contoh kaedah pembinaan dan reka bentuk kehilangan untuk tugas panggil balik vektor hiliran Tugasan dan kaedah pemodelan dalam peringkat pra-latihan diterangkan. Berbeza daripada tugasan padanan teks imej biasa, kami menggunakan tugasan padanan Item Pertanyaan dan Imej dan menggunakan Item dengan klik paling banyak di bawah Pertanyaan sebagai sampel positif dan menggunakan sampel lain dalam Kumpulan sebagai sampel negatif menara berkembar Query dan Item yang dimodelkan dengan cara produk dalaman. Titik permulaan reka bentuk ini adalah untuk menjadikan pra-latihan lebih dekat dengan tugas mengingat vektor, dan untuk menyediakan input yang berkesan untuk tugas hiliran sebanyak mungkin di bawah sumber yang terhad. Di samping itu, untuk tugas mengingat semula vektor, jika vektor input pra-latihan ditetapkan semasa proses latihan, ia tidak boleh dilaraskan dengan berkesan untuk data berskala besar Atas sebab ini, kami turut memodelkan vektor input pra-latihan dalam vektor tugas mengingat semula.
Model pra-latihan
▐ Kaedah pemodelan
Model pra-latihan berbilang modal perlu mengekstrak ciri daripada imej dan kemudian menggabungkannya dengan ciri teks. Terdapat tiga cara utama untuk mengekstrak ciri daripada imej: menggunakan model yang dilatih dalam medan CV untuk mengekstrak ciri RoI, ciri Grid dan ciri Tampalan imej. Dari perspektif struktur model, terdapat dua jenis utama mengikut kaedah gabungan ciri imej dan ciri teks yang berbeza: model aliran tunggal atau model dwi-strim. Dalam model aliran tunggal, ciri imej dan ciri teks disambungkan bersama dan dimasukkan ke dalam Pengekod pada peringkat awal, manakala dalam model dwi-strim, ciri imej dan ciri teks masing-masing dimasukkan ke dalam dua Pengekod bebas, dan kemudian input ke dalam Pengekod mod silang untuk diproses.
▐ Penerokaan awal
Cara kami mengekstrak ciri imej ialah: bahagikan imej Untuk urutan tampalan, gunakan ResNet untuk mengekstrak ciri imej setiap tampung. Dari segi struktur model, kami mencuba struktur satu aliran, iaitu, menyambung Pertanyaan, tajuk dan imej bersama-sama dan memasukkannya ke dalam Pengekod. Selepas beberapa set percubaan, kami mendapati bahawa di bawah struktur ini, adalah sukar untuk mengekstrak vektor Pertanyaan tulen dan vektor Item sebagai input untuk tugas penarikan semula vektor menara berkembar hiliran. Jika anda menyembunyikan mod yang tidak diperlukan semasa mengekstrak vektor tertentu, ramalan akan tidak konsisten dengan latihan. Masalah ini serupa dengan mengekstrak model menara berkembar secara langsung daripada model interaktif Mengikut pengalaman kami, model ini tidak berkesan seperti model menara berkembar terlatih. Berdasarkan ini, kami mencadangkan struktur model baharu.
▐ Struktur model
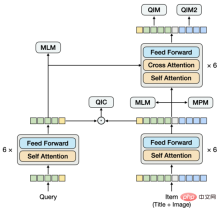
Sama seperti struktur dwi-aliran, bahagian bawah model terdiri daripada menara berkembar, dan bahagian atas disepadukan dengan menara berkembar melalui Pengekod mod silang. Berbeza daripada struktur dwi-aliran, menara berkembar tidak terdiri daripada satu modaliti. Menara Item mengandungi dua modaliti Tajuk dan Imej disambungkan dan dimasukkan ke dalam Pengekod model aliran tunggal. Untuk memodelkan hubungan semantik dan jurang antara Pertanyaan dan Tajuk, kami berkongsi Pengekod Pertanyaan dan menara berkembar Item, dan kemudian mempelajari model bahasa secara berasingan.
Untuk pra-latihan, mereka bentuk tugasan yang sesuai juga penting. Kami telah mencuba tugasan padanan imej-teks yang biasa digunakan bagi Tajuk dan Imej Walaupun ia boleh mencapai tahap padanan yang agak tinggi, ia membawa sedikit keuntungan kepada tugas mengingat vektor hiliran Ini kerana apabila menggunakan Pertanyaan untuk mengingati Item, Tajuk Item dan Sama ada Imej sepadan bukanlah faktor utama. Oleh itu, apabila kami mereka bentuk tugasan, kami memberi lebih pertimbangan kepada hubungan antara Pertanyaan dan Item. Pada masa ini, sebanyak 5 tugasan pra-latihan digunakan.
▐ Tugas pra-latihan
- Pemodelan Bahasa Bertopeng (MLM): Dalam Teks Token , sembunyikan 15% secara rawak dan gunakan baki teks dan imej untuk meramalkan token teks bertopeng. Untuk Pertanyaan dan Tajuk, terdapat tugasan MLM masing-masing. MLM meminimumkan Kehilangan entropi silang:
 di mana mewakili token teks yang tinggal
di mana mewakili token teks yang tinggal
- Pemodelan Tampalan Bertopeng (MPM): Dalam imej Antara Token Patch, 25% bertopeng secara rawak, dan imej dan teks yang selebihnya digunakan untuk meramalkan token imej bertopeng. MPM meminimumkan Kehilangan perbezaan KL: di mana mewakili token imej yang tinggal
-
Klasifikasi Item Pertanyaan (QIC ): Item dengan klik paling banyak di bawah Pertanyaan digunakan sebagai sampel positif, dan sampel lain dalam Kelompok digunakan sebagai sampel negatif. QIC mengurangkan dimensi menara Pertanyaan dan token Menara Item [CLS] kepada 256 dimensi melalui lapisan linear, dan kemudian melakukan pengiraan persamaan untuk mendapatkan kebarangkalian yang diramalkan, meminimumkan Kehilangan entropi silang: di mana boleh dikira dalam pelbagai cara:
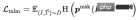
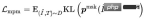
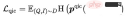


di mana mewakili pengiraan persamaan, mewakili hiperparameter suhu, dan m mewakili masing-masing Faktor penskalaan dan faktor kelonggaran
- Pemadanan Item Pertanyaan (QIM): Item dengan klik paling banyak di bawah Pertanyaan digunakan sebagai sampel positif, dan Item lain yang mempunyai persamaan tertinggi dengan Pertanyaan semasa dalam Kelompok digunakan sebagai sampel negatif. QIM menggunakan token [CLS] bagi Pengekod mod silang untuk mengira kebarangkalian ramalan dan meminimumkan Kehilangan entropi silang:
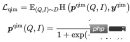
- Pemadanan Imej Pertanyaan (QIM2): Dalam sampel QIM, Mask mengalih keluar Tajuk dan mengukuhkan padanan antara Pertanyaan dan Imej. QIM2 meminimumkan Kehilangan entropi silang:
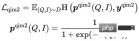
Matlamat latihan model adalah untuk meminimumkan Kehilangan keseluruhan:
Dalam 5 pratetap ini Dalam tugas latihan, tugas MLM dan tugas MPM terletak di atas menara Item, memodelkan keupayaan untuk menggunakan maklumat rentas modal untuk memulihkan satu sama lain selepas sebahagian daripada Token Tajuk atau Imej Bertopeng. Terdapat tugas MLM bebas di atas menara Pertanyaan Dengan berkongsi Pengekod menara Pertanyaan dan menara Item, hubungan semantik dan jurang antara Pertanyaan dan Tajuk dimodelkan. Tugas QIC menggunakan produk dalaman dua menara untuk menjajarkan tugasan mengingat semula vektor pra-latihan dan hiliran ke tahap tertentu, dan menggunakan AM-Softmax untuk menutup jarak antara perwakilan Pertanyaan dan perwakilan item yang paling diklik di bawah Pertanyaan , dan menolak jarak antara Pertanyaan dan item yang paling diklik Jarak Item lain. Tugas QIM terletak di atas Pengekod mod silang dan menggunakan maklumat mod silang untuk memodelkan padanan Pertanyaan dan Item. Disebabkan oleh jumlah pengiraan, nisbah sampel positif dan negatif bagi tugasan NSP biasa ialah 1:1 Untuk meluaskan lagi jarak antara sampel positif dan negatif, sampel negatif yang sukar dibina berdasarkan hasil pengiraan persamaan bagi. tugas QIC. Tugas QIM2 terletak pada kedudukan yang sama dengan tugas QIM, secara eksplisit memodelkan maklumat tambahan yang dibawa oleh imej berbanding teks.
Model ingat semula vektor
▐ Kaedah pemodelan
Dalam sistem perolehan maklumat berskala besar, model panggil semula berada di bahagian bawah dan perlu menjaringkan markah dalam set calon yang besar. Atas sebab prestasi, struktur menara berkembar Pengguna dan Item sering digunakan untuk mengira hasil darab dalam vektor. Isu teras model penarikan semula vektor ialah: cara membina sampel positif dan negatif dan skala persampelan sampel negatif. Penyelesaian kami ialah: gunakan klik pengguna pada Item pada halaman sebagai sampel positif, sampel puluhan ribu sampel negatif berdasarkan pengedaran klik dalam kumpulan produk penuh, dan gunakan Sampled Softmax Loss untuk membuat kesimpulan daripada sampel pensampelan bahawa Item berada dalam kumpulan produk penuh kebarangkalian klik dalam .

di mana mewakili pengiraan persamaan, mewakili Hiperparameter suhu
▐ Penjelajahan awal
Mengikut paradigma FineTune biasa, kami cuba menukar pra-latihan vektor ke Input terus ke MLP Menara Berkembar, digabungkan dengan pensampelan negatif berskala besar dan Softmax Sampel untuk melatih model penarikan semula vektor berbilang modal. Walau bagaimanapun, berbeza dengan tugas hiliran berskala kecil biasa, saiz sampel latihan bagi tugas mengingat vektor adalah besar, dalam susunan berbilion-bilion. Kami mendapati bahawa amaun parameter MLP tidak dapat menyokong latihan model, dan ia akan mencapai keadaan penumpuannya sendiri tidak lama lagi, tetapi kesannya tidak baik. Pada masa yang sama, vektor pra-latihan digunakan sebagai input dan bukannya parameter dalam model ingat semula vektor dan tidak boleh dikemas kini semasa latihan berlangsung. Akibatnya, pra-latihan pada data berskala kecil bercanggah dengan tugas hiliran pada data berskala besar.
Terdapat beberapa penyelesaian Satu kaedah adalah untuk menyepadukan model pra-latihan ke dalam model penarikan semula vektor Walau bagaimanapun, bilangan parameter model pra-latihan adalah terlalu besar, dan ditambah dengan saiz sampel model ingat semula vektor, ia tidak boleh digunakan dalam model ingat semula vektor Di bawah kekangan sumber yang terhad, latihan tetap harus dijalankan dalam masa yang munasabah. Kaedah lain ialah membina matriks parameter dalam model ingat semula vektor, memuatkan vektor pra-latihan ke dalam matriks, dan mengemas kini parameter matriks semasa latihan berlangsung. Selepas siasatan, kaedah ini agak mahal dari segi pelaksanaan kejuruteraan. Berdasarkan ini, kami mencadangkan struktur model yang memodelkan kemas kini vektor pra-latihan dengan mudah dan sesuai.
▐ Struktur model

Mari mulakan dengan Kurangkan dimensi vektor pra-latihan melalui FC Sebab mengapa dimensi dikurangkan di sini dan bukannya dalam pra-latihan adalah kerana vektor dimensi tinggi semasa masih dalam julat prestasi yang boleh diterima untuk pensampelan sampel negatif , Pengurangan dimensi dalam tugas mengingat vektor lebih konsisten dengan matlamat latihan. Pada masa yang sama, kami memperkenalkan matriks Pembenaman ID Pertanyaan dan Item Dimensi Pembenaman adalah konsisten dengan dimensi vektor pra-latihan yang dikurangkan, dan kemudian ID dan vektor pra-latihan digabungkan bersama. Titik permulaan reka bentuk ini adalah untuk memperkenalkan jumlah parameter yang mencukupi untuk menyokong data latihan berskala besar, sambil membenarkan vektor pra-latihan dikemas kini secara adaptif semasa latihan berlangsung.
Apabila hanya ID dan vektor pra-latihan digunakan untuk bercantum, kesan model bukan sahaja melebihi kesan MLP menara berkembar hanya menggunakan vektor pra-latihan, tetapi juga melebihi model garis dasar MGDSPR, yang mengandungi lebih banyak ciri. Melangkah lebih jauh, memperkenalkan lebih banyak ciri atas dasar ini boleh terus meningkatkan kesannya.
Analisis Eksperimen
▐ Petunjuk Penilaian
Untuk kesan model pra-latihan, penunjuk tugasan hiliran biasanya digunakan untuk menilai, dan penunjuk penilaian berasingan jarang digunakan. Walau bagaimanapun, dengan cara ini, kos lelaran model pra-latihan akan menjadi agak tinggi, kerana setiap lelaran versi model memerlukan latihan tugas mengingat vektor yang sepadan, dan kemudian menilai penunjuk tugas mengingat vektor, dan keseluruhan proses akan menjadi sangat lama. Adakah terdapat sebarang metrik yang berkesan untuk menilai model pra-latihan sahaja? Kami mula-mula mencuba Rank@K dalam beberapa kertas kerja Penunjuk ini digunakan terutamanya untuk menilai tugas pemadanan teks imej: mula-mula gunakan model pra-latihan untuk menjaringkan set calon yang dibina secara buatan, dan kemudian mengira keputusan K Teratas yang diisih mengikut skor untuk memukul imej dan teks Perkadaran sampel positif yang sepadan. Kami secara langsung menggunakan Rank@K pada tugas pemadanan item pertanyaan dan mendapati bahawa keputusan tidak selaras dengan jangkaan Model pra-latihan yang lebih baik dengan Rank@K mungkin mencapai keputusan yang lebih buruk dalam model penarikan semula vektor hiliran dan tidak boleh membimbing pra-latihan. latihan. Lelaran melatih model. Berdasarkan ini, kami menyatukan penilaian model pra-latihan dan penilaian model ingat semula vektor, dan menggunakan penunjuk dan proses penilaian yang sama, yang secara relatifnya boleh membimbing lelaran model pra-latihan.
Recall@K : Set data penilaian terdiri daripada data set latihan pada hari berikutnya Pertama, hasil klik dan transaksi pengguna yang berbeza di bawah Agregat Pertanyaan yang sama ke dalam  , dan kemudian hitung perkadaran hasil K Teratas yang diramalkan oleh model memukul :
, dan kemudian hitung perkadaran hasil K Teratas yang diramalkan oleh model memukul :

Dalam proses meramal keputusan K Teratas oleh model, adalah perlu untuk mengekstrak vektor Pertanyaan dan Item daripada pra- model latihan/pengingat semula vektor, dan gunakan pengambilan jiran terdekat untuk mendapatkan item Teratas di bawah Pertanyaan K. Proses ini mensimulasikan penarikan semula vektor dalam enjin dalam talian untuk mengekalkan konsistensi antara luar talian dan dalam talian. Untuk model pra-latihan, perbezaan antara penunjuk ini dan Rank@K ialah vektor Pertanyaan dan Item diekstrak daripada model untuk mendapatkan semula produk dalaman vektor, dan bukannya terus menggunakan model gabungan modal untuk menjaringkan sebagai tambahan, satu Pertanyaan bukan sahaja Untuk memanggil semula item yang sepadan, ia juga perlu untuk memanggil semula klik dan item transaksi pengguna yang berbeza di bawah Pertanyaan ini.
Untuk model ingat semula vektor, selepas Recall@K meningkat ke tahap tertentu, anda juga perlu memberi perhatian kepada korelasi antara Pertanyaan dan Item. Model dengan perkaitan yang lemah, walaupun ia boleh meningkatkan kecekapan carian, juga akan menghadapi kemerosotan dalam pengalaman pengguna dan peningkatan dalam aduan dan pendapat umum yang disebabkan oleh peningkatan dalam Kes Buruk. Kami menggunakan model luar talian yang konsisten dengan model korelasi dalam talian untuk menilai korelasi antara Pertanyaan dan Item dan antara kategori Pertanyaan dan Item.
▐ Percubaan pra-latihan
Kami memilih beberapa kategori 1 A kumpulan produk peringkat bilion dibina untuk membina set data pra-latihan.
Model Baseline kami ialah FashionBert yang dioptimumkan, menambah tugas QIM dan QIM2 Apabila mengekstrak vektor Pertanyaan dan Item, kami hanya menggunakan Mean Pooling untuk Token bukan Padding. Percubaan berikut meneroka keuntungan yang dibawa oleh pemodelan dengan dua menara berbanding dengan menara tunggal, dan memberikan peranan bahagian penting melalui eksperimen ablasi.

Daripada eksperimen ini, kita boleh membuat kesimpulan berikut:
- Eksperimen 8 vs Eksperimen 3: Model Menara Berkembar Ditala , jauh lebih tinggi daripada Garis Dasar menara tunggal dalam Recall@1000.
- Eksperimen 3 lwn Eksperimen 1/2: Untuk model menara tunggal, cara mengekstrak vektor Pertanyaan dan Item adalah penting. Kami cuba menggunakan token [CLS] untuk Pertanyaan dan Item, dan mendapat hasil yang buruk. Percubaan 1 menggunakan Token yang sepadan untuk Pertanyaan dan Item masing-masing untuk melakukan Mean Pooling, dan kesannya lebih baik, tetapi mengalih keluar Padding Token dan kemudian melakukan Mean Pooling akan membawa peningkatan yang lebih baik. Percubaan 2 mengesahkan bahawa pemodelan eksplisit padanan Pertanyaan-Imej untuk menyerlahkan maklumat imej akan membawa peningkatan.
- Eksperimen 6 lwn Eksperimen 4/5: Eksperimen 4 mengalihkan tugasan MLM/MPM menara Item ke Pengekod mod silang, dan kesannya akan menjadi lebih teruk, kerana meletakkan kedua-dua tugas ini dalam menara Item boleh meningkatkan pembelajaran Perwakilan Item; sebagai tambahan, pemulihan rentas modal berdasarkan Tajuk dan Imej dalam menara Item akan mempunyai surat-menyurat yang lebih kukuh. Percubaan 5 mengesahkan bahawa penambahan L2 Norm pada Query dan vektor Item semasa latihan dan ramalan akan membawa peningkatan.
- Percubaan 6/7/8: Menukar kehilangan tugas QIC akan membawa peningkatan Berbanding dengan Sigmoid, Softmax lebih dekat dengan tugas penarikan semula vektor hiliran, dan AM-Softmax terus menolak sampel positif dan negatif. sampel jarak antara.
▐ Percubaan ingat semula vektor
Kami memilih 1 bilion tahap Halaman yang diklik membina set data ingat semula vektor. Setiap halaman mengandungi 3 item klik sebagai sampel positif dan 10,000 sampel negatif diambil daripada kumpulan produk berdasarkan pengedaran klik. Atas dasar ini, tiada peningkatan ketara dalam kesan diperhatikan dengan mengembangkan lagi jumlah data latihan atau pensampelan sampel negatif.
Model Baseline kami ialah model MGDSPR bagi carian utama. Percubaan berikut meneroka keuntungan yang dibawa dengan menggabungkan latihan pra-latihan berbilang modal dengan penarikan semula vektor berbanding Garis Dasar, dan memberikan peranan bahagian penting melalui eksperimen ablasi.
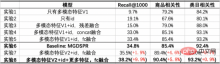
Daripada eksperimen ini, kita boleh membuat kesimpulan berikut:
- Eksperimen 7/8 vs Eksperimen 6: Selepas gabungan ciri berbilang modal dan ID melalui FC, ia mengatasi Baseline dalam tiga petunjuk Sambil meningkatkan Recall@1000, ia juga meningkatkan lagi perkaitan produk. Atas dasar ini, menambah ciri yang sama seperti Baseline boleh meningkatkan lagi tiga penunjuk dan menambah baik Recall@1000 dengan lebih banyak lagi.
- Eksperimen 1 lwn Eksperimen 2: Berbanding dengan hanya ID, hanya ciri berbilang modal yang mempunyai Recall@1000 yang lebih rendah, tetapi korelasi yang lebih tinggi, dan korelasinya hampir dengan tahap yang tersedia dalam talian. Ini menunjukkan bahawa model penarikan balik berbilang modal pada masa ini mempunyai lebih sedikit Kes Buruk daripada hasil penarikan balik, tetapi kecekapan klik dan urus niaga tidak dianggap mencukupi.
- Eksperimen 3/4/5 lwn Eksperimen 1/2: Selepas menggabungkan ciri berbilang modal dengan ID, ia boleh menambah baik ketiga-tiga penunjuk Antaranya, ID dihantar melalui FC dan kemudian digabungkan dengan Multimodal yang dikurangkan secara dimensi ciri ditambah bersama untuk mencapai hasil yang lebih baik. Walau bagaimanapun, berbanding dengan Baseline, masih terdapat jurang dalam Recall@1000.
- Eksperimen 7 lwn Eksperimen 5: Selepas pengoptimuman model pra-latihan bertindih, Recall@1000 dan korelasi produk dipertingkatkan, dan korelasi kategori pada asasnya adalah sama.
Antara 1000 keputusan Teratas model penarikan balik vektor, kami menapis item yang sistem dalam talian dapat memanggil semula, dan mendapati bahawa korelasi hasil tambahan yang selebihnya pada dasarnya tidak berubah . Di bawah sejumlah besar pertanyaan, kami melihat bahawa hasil tambahan ini menangkap maklumat imej di luar Tajuk produk dan memainkan peranan tertentu dalam jurang semantik antara Pertanyaan dan Tajuk .
pertanyaan: sut kacak

pertanyaan: baju cubit pinggang wanita

Ringkasan dan Tinjauan
Mensasarkan keperluan aplikasi bagi senario carian utama, kami mencadangkan model pra-latihan imej teks, menggunakan silang input menara berkembar Pertanyaan dan Item -Modal Encoder, di mana Menara Item ialah model aliran tunggal yang mengandungi grafik dan teks berbilang modal. Tugasan padanan Item Pertanyaan dan Imej Pertanyaan, serta tugas berbilang klasifikasi Item Pertanyaan yang dimodelkan oleh produk dalaman menara berkembar Pertanyaan dan Item, menjadikan pra-latihan lebih dekat dengan tugas mengingat vektor hiliran. Pada masa yang sama, kemas kini vektor pra-latihan dimodelkan dalam penarikan semula vektor. Dalam kes sumber terhad, pra-latihan menggunakan jumlah data yang agak kecil masih boleh meningkatkan prestasi tugasan hiliran yang menggunakan data besar-besaran.
Dalam senario lain carian utama, seperti pemahaman produk, perkaitan dan pengisihan, terdapat juga keperluan untuk menggunakan teknologi berbilang modal. Kami juga telah mengambil bahagian dalam penerokaan senario ini dan percaya bahawa teknologi pelbagai mod akan membawa manfaat kepada lebih banyak senario pada masa hadapan.
Pengenalan pasukan
Pasukan penarikan semula carian utama Taobao: Pasukan bertanggungjawab untuk memanggil balik dan pautan pengisihan kasar dalam pautan carian utama Arah teknikal utama semasa adalah berdasarkan pada sampel ruang penuh Pengingat semula vektor diperibadikan berbilang objektif, ingatan berbilang mod berdasarkan pra-latihan berskala besar, penulisan semula semantik Pertanyaan serupa berdasarkan pembelajaran kontrastif dan model pemeringkatan kasar, dsb.
Atas ialah kandungan terperinci Penerokaan teknologi berbilang modal dalam senario ingat semula carian utama Taobao. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Apakah graf pemikiran dalam kejuruteraan segeraApr 13, 2025 am 11:53 AM
Apakah graf pemikiran dalam kejuruteraan segeraApr 13, 2025 am 11:53 AMPengenalan Dalam kejuruteraan segera, "Grafik Pemikiran" merujuk kepada pendekatan baru yang menggunakan teori graf untuk struktur dan membimbing proses penalaran AI. Tidak seperti kaedah tradisional, yang sering melibatkan linear
 Mengoptimumkan pemasaran e -mel organisasi anda dengan agen genaiApr 13, 2025 am 11:44 AM
Mengoptimumkan pemasaran e -mel organisasi anda dengan agen genaiApr 13, 2025 am 11:44 AMPengenalan Tahniah! Anda menjalankan perniagaan yang berjaya. Melalui laman web anda, kempen media sosial, webinar, persidangan, sumber percuma, dan sumber lain, anda mengumpul 5000 ID e -mel setiap hari. Langkah jelas seterusnya adalah
 Pemantauan Prestasi Aplikasi Masa Nyata dengan Apache PinotApr 13, 2025 am 11:40 AM
Pemantauan Prestasi Aplikasi Masa Nyata dengan Apache PinotApr 13, 2025 am 11:40 AMPengenalan Dalam persekitaran pembangunan perisian pantas hari ini, memastikan prestasi aplikasi yang optimum adalah penting. Memantau metrik masa nyata seperti masa tindak balas, kadar ralat, dan penggunaan sumber dapat membantu utama
 Chatgpt mencecah 1 bilion pengguna? 'Dua kali ganda dalam beberapa minggu' kata Ketua Pegawai Eksekutif OpenaiApr 13, 2025 am 11:23 AM
Chatgpt mencecah 1 bilion pengguna? 'Dua kali ganda dalam beberapa minggu' kata Ketua Pegawai Eksekutif OpenaiApr 13, 2025 am 11:23 AM"Berapa banyak pengguna yang anda ada?" Dia ditakdirkan. "Saya fikir kali terakhir yang kami katakan ialah 500 juta aktif mingguan, dan ia berkembang dengan pesat," jawab Altman. "Anda memberitahu saya bahawa ia seperti dua kali ganda dalam beberapa minggu sahaja," kata Anderson. "Saya mengatakan bahawa priv
 Pixtral -12b: Model Multimodal Pertama Mistral Ai 'Apr 13, 2025 am 11:20 AM
Pixtral -12b: Model Multimodal Pertama Mistral Ai 'Apr 13, 2025 am 11:20 AMPengenalan Mistral telah mengeluarkan model multimodal yang pertama, iaitu Pixtral-12B-2409. Model ini dibina atas parameter 12 bilion Mistral, NEMO 12B. Apa yang membezakan model ini? Ia kini boleh mengambil kedua -dua gambar dan Tex
 Rangka Kerja Agentik untuk Aplikasi AI Generatif - Analytics VidhyaApr 13, 2025 am 11:13 AM
Rangka Kerja Agentik untuk Aplikasi AI Generatif - Analytics VidhyaApr 13, 2025 am 11:13 AMBayangkan mempunyai pembantu berkuasa AI yang bukan sahaja memberi respons kepada pertanyaan anda tetapi juga mengumpulkan maklumat, melaksanakan tugas, dan juga mengendalikan pelbagai jenis teks, imej, dan kod. Bunyi futuristik? Dalam ini a
 Aplikasi AI Generatif di Sektor KewanganApr 13, 2025 am 11:12 AM
Aplikasi AI Generatif di Sektor KewanganApr 13, 2025 am 11:12 AMPengenalan Industri kewangan adalah asas kepada mana -mana pembangunan negara, kerana ia memacu pertumbuhan ekonomi dengan memudahkan urus niaga yang cekap dan ketersediaan kredit. The ease with which transactions occur and credit
 Panduan untuk pembelajaran dalam talian dan algoritma pasif-agresifApr 13, 2025 am 11:09 AM
Panduan untuk pembelajaran dalam talian dan algoritma pasif-agresifApr 13, 2025 am 11:09 AMPengenalan Data dijana pada kadar yang belum pernah terjadi sebelumnya dari sumber seperti media sosial, urus niaga kewangan, dan platform e-dagang. Mengendalikan aliran maklumat yang berterusan ini adalah satu cabaran, tetapi ia menawarkan


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Penyesuai Pelayan SAP NetWeaver untuk Eclipse
Integrasikan Eclipse dengan pelayan aplikasi SAP NetWeaver.

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

ZendStudio 13.5.1 Mac
Persekitaran pembangunan bersepadu PHP yang berkuasa

VSCode Windows 64-bit Muat Turun
Editor IDE percuma dan berkuasa yang dilancarkan oleh Microsoft

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

