
Rumah >Peranti teknologi >AI >Intel membantu membina enjin latihan/ramalan model jarang berskala besar sumber terbuka DeepRec
Intel membantu membina enjin latihan/ramalan model jarang berskala besar sumber terbuka DeepRec

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-08 22:01:101618semak imbas
DeepRec (PAI-TF) ialah enjin cadangan sumber terbuka bersatu Alibaba Group (https://github.com/alibaba/DeepRec Ia digunakan terutamanya untuk latihan dan ramalan model yang jarang, dan boleh menyokong ratusan berbilion-bilion ciri, latihan jarang berskala ultra besar dengan bertrillion sampel mempunyai kelebihan yang jelas dari segi prestasi dan kesan latihan DeepRec kini menyokong carian Taobao, pengesyoran, pengiklanan dan senario lain, dan digunakan secara meluas dalam Taobao, Tmall, Alimama, Amap dan perniagaan lain.
Intel telah bekerjasama rapat dengan pasukan Alibaba PAI sejak 2019 untuk menggunakan teknologi Intel Artificial Intelligence (AI) pada DeepRec, menyasarkan pengendali, subgraf dan masa jalan , lapisan rangka kerja dan model sepenuhnya memanfaatkan kelebihan perisian dan perkakasan Intel untuk membantu Alibaba mempercepatkan prestasi perniagaan AI dalaman dan luaran.
Kelebihan utama DeepRec
Enjin sumber terbuka arus perdana semasa masih mempunyai had tertentu dalam menyokong senario latihan jarang berskala besar contohnya, mereka tidak menyokong latihan dalam talian, ciri tidak boleh dimuatkan secara dinamik, dan penggunaan dalam talian dan lelaran adalah menyusahkan, khususnya, prestasi sukar untuk memenuhi keperluan perniagaan. Untuk menyelesaikan masalah di atas, DeepRec telah disesuaikan dan dioptimumkan secara mendalam untuk senario model yang jarang berdasarkan TensorFlow1.15 Langkah utama termasuk tiga kategori berikut:
Model. kesan: Terutamanya diluluskan fungsi ciri anjal dinamik Added EmbeddingVariable (EV) dan Pengoptimum Adagrad yang dipertingkatkan untuk mencapai pengoptimuman. Fungsi EV menyelesaikan masalah seperti kesukaran dalam menganggar saiz Pembolehubah asli dan konflik ciri, dan menyediakan pelbagai ciri lanjutan seperti strategi kemasukan dan penyingkiran ciri Pada masa yang sama, ia secara automatik mengkonfigurasi dimensi ciri panas dan sejuk berdasarkan kekerapan kejadian ciri, menambah Ekspresi ciri frekuensi tinggi mengurangkan pemasangan yang berlebihan dan boleh meningkatkan kesan model jarang dengan ketara; senario, DeepRec berada dalam distributed , subgraf, operator, masa jalan dan aspek lain adalah pengoptimuman prestasi yang mendalam, termasuk pengoptimuman strategi teragih, saluran paip automatik SmartStage, gabungan graf automatik, Embedding dan Perhatian dan pengoptimuman graf lain, pengoptimuman operator jarang biasa, memori pengoptimuman pengurusan, mengurangkan penggunaan Memori dengan ketara mempercepatkan latihan hujung-ke-hujung dan prestasi inferens; Tahap 10TB Latihan dalam talian peringkat minit dan kemas kini model yang sangat besar dilancarkan, yang memenuhi keperluan ketepatan masa yang tinggi bagi perniagaan memandangkan ciri-ciri senget panas dan sejuk dalam model jarang, DeepRec menyediakan storan hibrid berbilang peringkat (naik; kepada storan hibrid empat peringkat, iaitu, keupayaan HBM+DRAM+PMem+SSD) boleh meningkatkan prestasi model besar sambil mengurangkan kos.
Teknologi Intel membantu DeepRec mencapai prestasi tinggi Kerjasama rapat antara Intel dan pasukan PAI Alibaba memainkan peranan penting dalam mencapai tiga kelebihan unik DeepRec di atas kelebihan juga mencerminkan sepenuhnya nilai besar teknologi Intel:
Dari segi pengoptimuman prestasi, pasukan perisian awan hiperskala Intel bekerjasama rapat dengan Alibaba untuk menyasarkan platform CPU, mengoptimumkan daripada operator, subgraf, rangka kerja, masa jalan dan peringkat lain, gunakan sepenuhnya pelbagai ciri baharu pemproses Intel® Xeon® Scalable, dan memaksimumkan kelebihan perkakasan; >meningkatkan kemudahan penggunaan DeepRec pada platform CPU, modelzoo juga dibina untuk menyokong kebanyakan model pengesyoran arus perdana, dan fungsi EV unik DeepRec telah digunakan pada model ini untuk mencapai pembangunan Pengalaman pengguna di luar kotak.
Pada masa yang sama, sebagai tindak balas kepada keperluan khas model latihan jarang berskala ultra-besar EV untuk penyimpanan dan operasi carian KV, pasukan Intel Optane Innovation Center menyediakan penyelesaian berdasarkan Intel® Optane TM Penyelesaian pengurusan memori dan storan memori berterusan ("PMem" singkatannya) menyokong dan bekerjasama dengan penyelesaian storan hibrid pelbagai peringkat DeepRec untuk memenuhi keperluan memori yang besar dan kos rendah
Pasukan Bahagian Penyelesaian Boleh Diprogramkan Menggunakan FPGA untuk melaksanakan fungsi carian KV untuk Benamkan meningkatkan keupayaan pertanyaan Benamkan dan mengeluarkan lebih banyak sumber CPU. Digabungkan dengan ciri perkakasan CPU, PMem dan FPGA yang berbeza, dari perspektif sistem, kelebihan perisian dan perkakasan Intel boleh digunakan sepenuhnya untuk keperluan yang berbeza, yang boleh mempercepatkan pelaksanaan DeepRec dalam perniagaan AI Alibaba dan menyediakan penyelesaian yang lebih baik untuk keseluruhan yang jarang. ekosistem perniagaan senario.
Intel® DL Boost menyediakan pecutan prestasi kritikal untuk DeepRec
Pengoptimuman DeepRec oleh Intel® DL Boost (Intel® Deep Learning Acceleration) terutamanya ditunjukkan dalam empat peringkat pengoptimuman rangka kerja, pengoptimuman operator, pengoptimuman subgraf dan pengoptimuman model .
- Intel x86 Platform AI Capability Evolution - Intel® DL Boost
Dari Intel® Xeon® Pemprosesan Boleh Skala Sejak kemunculan pemproses, Intel telah menggandakan keupayaan AVX dengan menaik taraf daripada AVX 256 kepada AVX-512, meningkatkan keupayaan latihan pembelajaran mendalam dan inferens dan pemproses Intel® Xeon® Scalable generasi kedua telah Pengenalan DL Boost_VNNI telah banyak; meningkatkan prestasi pengiraan pendaraban dan penambahan INT8 sejak pemproses Intel® Xeon® Scalable generasi ketiga, Intel telah melancarkan set arahan yang menyokong jenis data BFloat16 (BF16) untuk meningkatkan lagi latihan pembelajaran mendalam dan prestasi inferens . Dengan inovasi berterusan dan pembangunan teknologi perkakasan, Intel akan melancarkan teknologi pemprosesan AI baharu dalam pemproses Xeon® Scalable generasi akan datang untuk meningkatkan lagi keupayaan VNNI dan BF16 daripada vektor 1 dimensi kepada matriks 2 dimensi. Teknologi set arahan perkakasan yang disebutkan di atas telah digunakan dalam pengoptimuman DeepRec, membolehkan ciri perkakasan yang berbeza digunakan untuk keperluan pengkomputeran yang berbeza Ia juga mengesahkan bahawa Intel® AVX-512 dan BF16 sangat sesuai untuk latihan dan pecutan inferens secara jarang. senario.
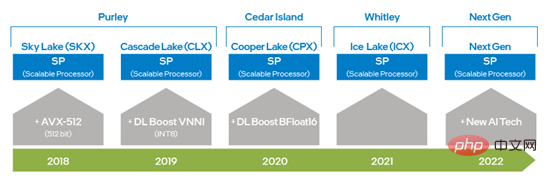
Rajah 1 rajah evolusi keupayaan AI platform Intel x86
- Pengoptimuman rangka kerja
DeepRec menyepadukan pustaka pecutan prestasi pembelajaran mendalam merentas platform sumber terbuka Intel oneDNN (oneAPI Deep Neural Network Library ), dan mengubah suai kumpulan benang asal oneDNN untuk menyatukannya ke dalam kumpulan benang Eigen DeepRec, yang mengurangkan overhed penukaran kumpulan benang dan mengelakkan kemerosotan prestasi yang disebabkan oleh persaingan antara kumpulan benang yang berbeza. oneDNN telah melaksanakan pengoptimuman prestasi untuk sebilangan besar pengendali arus perdana, termasuk MatMul, BiasAdd, LeakyReLU dan pengendali biasa lain dalam senario yang jarang, yang boleh memberikan sokongan prestasi yang kukuh untuk model carian dan promosi, dan pengendali dalam oneDNN juga menyokong jenis Data BF16, digunakan bersama pemproses Intel® Xeon® Scalable generasi ketiga yang dilengkapi dengan set arahan BF16, boleh meningkatkan prestasi latihan dan inferens model dengan ketara.
Dalam pilihan kompilasi DeepRec, cuma tambah "--config=mkl_threadpool" untuk mendayakan pengoptimuman oneDNN dengan mudah.
- Pengoptimuman Pengendali
Walaupun oneDNN boleh digunakan untuk meningkatkan prestasi pengendali intensif pengiraan , tetapi terdapat sebilangan besar pengendali jarang dalam model pengesyoran pengiklanan carian, seperti Select, DynamicStitch, Transpose, Tile, SparseSegmentMean, dll. Kebanyakan pelaksanaan asli pengendali ini mempunyai ruang tertentu untuk pengoptimuman akses memori, yang mana disasarkan Penyelesaian mencapai pengoptimuman tambahan. Pengoptimuman ini memanggil arahan AVX-512 dan boleh dihidupkan dengan menambahkan "--copt=-march=skylake-avx512" pada arahan kompilasi. Berikut ialah dua daripada kes pengoptimuman.
Kes 1: Prinsip pelaksanaan pengendali Pilih adalah untuk memilih elemen berdasarkan syarat Dalam kes ini, kaedah pemuatan topeng Intel® AVX-512 boleh digunakan, seperti yang ditunjukkan dalam gambar kiri Rajah 2, untuk mengurangkan overhed masa yang disebabkan oleh bilangan besar pertimbangan yang disebabkan oleh keadaan if, dan kemudian meningkatkan kecekapan membaca dan menulis data melalui pemilihan kelompok Ujian akhir dalam talian menunjukkan bahawa prestasi meningkat dengan ketara;

Rajah 2 Pilih kes pengoptimuman operator
Kes 2: Sama, anda boleh menggunakan arahan unpack dan shuffle Intel® AVX-512 untuk mengoptimumkan operator transpose, iaitu, transpose matriks melalui blok kecil, seperti yang ditunjukkan dalam gambar Rajah yang betul 2. Ujian akhir dalam talian menunjukkan peningkatan prestasi juga amat ketara.
- Pengoptimuman subgraf
Pengoptimuman graf ialah cara berkesan utama pengoptimuman prestasi AI semasa satu. Begitu juga, apabila DeepRec digunakan dalam senario jarang berskala besar, biasanya terdapat sejumlah besar pemprosesan maklumat ciri terutamanya membenamkan ciri, dan pembenaman mengandungi sejumlah besar pengendali kecil untuk mencapai peningkatan prestasi umum, langkah pengoptimuman dilaksanakan dalam DeepRec Fungsi fused_embedding_lookup ditambah pada subgraf pembenaman fius, mengurangkan sejumlah besar operasi berlebihan Pada masa yang sama, menggunakan arahan Intel® AVX-512 untuk mempercepatkan pengiraan, prestasi subgraf dibenamkan dengan ketara.
Dengan menetapkan do_fusion kepada True dalam API tf.feature_column.embedding_column(..., do_fusion=True), anda boleh menghidupkan fungsi pengoptimuman subgraf.
- Pengoptimuman model
Berdasarkan platform CPU, Intel membina DeepRec meliputi WDL, DeepFM, DLRM, DIEN, Satu set unik model yang disyorkan untuk berbilang model arus perdana seperti DIN, DSSM, BST, MMoE, DBMTL, ESMM, dsb., yang melibatkan pelbagai senario biasa seperti penarikan balik, pengisihan dan berbilang objektif dan pengoptimuman prestasi untuk platform perkakasan , berbanding dengan rangka kerja lain , yang membawa peningkatan prestasi yang hebat kepada model ini pada platform CPU berdasarkan set data sumber terbuka seperti Criteo.
Prestasi yang paling cemerlang sudah pasti adalah pelaksanaan pengoptimuman bagi ketepatan campuran BF16 dan Float32. Dengan menambah fungsi menyesuaikan jenis data lapisan DNN dalam DeepRec, kami boleh memenuhi keperluan prestasi tinggi dan ketepatan tinggi bagi adegan jarang Cara untuk membolehkan pengoptimuman adalah seperti yang ditunjukkan dalam Rajah 3. Jenis data pembolehubah semasa ialah dikekalkan sebagai Float32 melalui keep_weights Cegah penurunan ketepatan yang disebabkan oleh pengumpulan kecerunan, dan kemudian gunakan dua operasi tuang untuk menukar operasi DNN kepada BF16 untuk pengiraan Bergantung pada unit pengkomputeran perkakasan BF16 pemproses Intel® Xeon® Scalable generasi ketiga. Pengkomputeran DNN sangat dipertingkatkan prestasi, sambil meningkatkan lagi prestasi melalui operasi tuang gabungan graf.

Rajah 3 Bagaimana untuk mendayakan pengoptimuman ketepatan campuran
Untuk menunjukkan kesan BF16 pada ketepatan model AUC (Area Under Curve) dan prestasi Gsteps/s, kaedah pengoptimuman ketepatan campuran di atas digunakan pada model modelzoo sedia ada. Penilaian pasukan Alibaba PAI menggunakan DeepRec pada platform Alibaba Cloud menunjukkan bahawa [1], berdasarkan set data Criteo dan dioptimumkan dengan BF16, model ketepatan WDL atau AUC boleh mendekati FP32, dan prestasi latihan model BF16 dipertingkatkan sehingga 1.4 kali ganda, yang merupakan kesan yang ketara.
Pada masa hadapan, untuk memaksimumkan kelebihan perkakasan platform CPU, terutamanya untuk memaksimumkan kesan ciri perkakasan baharu, DeepRec akan terus melaksanakan pengoptimuman dari sudut berbeza, termasuk operator pengoptimum , subgraf perhatian, menambah model berbilang objektif, dsb. untuk mencipta penyelesaian CPU berprestasi tinggi untuk adegan jarang.
Gunakan PMem untuk melaksanakan storan Benamkan
Untuk sangat skala besar Jika enjin latihan dan ramalan model jarang (ratusan bilion ciri, trilion sampel dan tahap model 10TB) semuanya disimpan dalam memori akses rawak dinamik (DynamicRandomAccessMemory, DRAM), jumlah kos pemilikan (TotalCost of Ownership) akan meningkat dengan banyak , TCO), pada masa yang sama, ia memberi tekanan besar kepada operasi dan pengurusan IT perusahaan, menjadikan pelaksanaan penyelesaian AI menghadapi cabaran.
PMem mempunyai kelebihan ketumpatan storan dan ketekalan data yang lebih tinggi, prestasi I/Onya hampir dengan DRAM, dan kosnya lebih menjimatkan sepenuhnya dan prestasi tinggi untuk latihan jarang berskala besar dan ramalan keperluan kapasiti besar dalam kedua-dua aspek.
PMem menyokong dua mod pengendalian, iaitu Mod Memori dan Mod Terus Apl. Dalam mod memori, ia adalah sama dengan storan sistem yang tidak menentu (tidak berterusan), tetapi pada kos yang lebih rendah, membolehkan kapasiti yang lebih tinggi sambil mengekalkan belanjawan sistem, dan menyediakan terabait memori dalam satu pelayan Jumlah kapasiti berbanding dengan mod memori, aplikasi mod akses langsung boleh memanfaatkan ciri kegigihan PMem. Dalam mod capaian terus aplikasi, PMem dan memori DRAM yang bersebelahan akan dikenali sebagai memori boleh alamat bait Sistem pengendalian boleh menggunakan perkakasan PMem sebagai dua peranti berbeza Satu ialah mod FSDAX, PMem Ia dikonfigurasikan sebagai peranti blok, dan pengguna boleh formatkannya ke dalam sistem fail untuk digunakan; yang satu lagi ialah mod DEVDAX, PMem didorong sebagai peranti aksara tunggal, bergantung pada ciri KMEM DAX yang disediakan oleh kernel (5.1 atau lebih tinggi), dan menganggap PMem sebagai tidak menentu Ia menggunakan bukan standard memori dan disambungkan kepada sistem pengurusan memori Sebagai nod NUMA memori yang lebih perlahan dan lebih besar sama dengan DRAM, aplikasi boleh mengaksesnya secara telus.
Dalam latihan ciri berskala sangat besar, Membenamkan storan berubah-ubah mengambil lebih daripada 90% memori, dan kapasiti memori akan menjadi salah satu halangannya. Menyimpan EV ke PMem boleh memecahkan kesesakan ini dan mencipta pelbagai nilai, seperti meningkatkan kapasiti penyimpanan memori latihan teragih berskala besar, menyokong latihan dan ramalan model yang lebih besar, mengurangkan komunikasi antara berbilang mesin dan meningkatkan prestasi latihan model mengurangkan TCO.
Dalam Membenamkan storan hibrid berbilang peringkat, PMem juga merupakan pilihan terbaik untuk memecahkan kesesakan DRAM. Pada masa ini, terdapat tiga cara untuk menyimpan EV ke dalam PMem, dan apabila menjalankan penanda aras mikro, model WDL dan model proksi WDL dalam tiga cara berikut, prestasinya sangat hampir dengan prestasi menyimpan EV ke dalam DRAM, yang sudah pasti menjadikan TCOnya. Lebih baik. Kelebihan besar:
- Konfigurasikan PMem ke dalam mod memori untuk menyimpan EV; , dan gunakan pengalokasi berdasarkan perpustakaan Libpmem untuk menyimpan EV;
- Konfigurasikan PMem sebagai nod NUMA dan gunakan pengalokasi berdasarkan pustaka Memkind untuk menyimpan EV.
- Pasukan PAI Alibaba menggunakan 3 cara untuk menyimpan EV pada instance dipertingkatkan memori Alibaba Cloud ecs.re7p.16xlarge untuk menjalankan ujian perbandingan model bersendirian WDL dalam Modelzoo

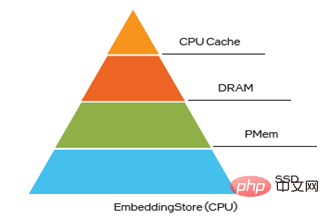 Rajah 4 Menanamkan storan hibrid berbilang peringkat
Rajah 4 Menanamkan storan hibrid berbilang peringkat
Oleh itu, pelan pengoptimuman seterusnya akan menggunakan PMem untuk menyimpan model dan menyimpan fail titik pemeriksaan model jarang ke dalam memori berterusan untuk mencapai berbilang susunan peningkatan prestasi magnitud dan menyingkirkan SSD semasa penjimatan dan pemulihan. Model yang sangat besar mengambil masa yang lama, dan ramalan latihan akan terganggu dalam tempoh ini.
Pencarian Pembenaman Dipercepat FPGABesar Latihan dan ramalan jarang berskala merangkumi pelbagai senario, seperti latihan teragih, mesin tunggal dan ramalan teragih, dan latihan pengkomputeran heterogen. Berbanding dengan Rangkaian Neural Convolutional (CNN) atau Rangkaian Neural Berulang (RNN) tradisional, mereka mempunyai perbezaan utama, iaitu pemprosesan jadual benam dan keperluan pemprosesan jadual Benam dalam senario ini berhadapan dengan Cabaran Baharu:
Keperluan kapasiti storan yang besar (sehingga 10TB atau lebih); ketumpatan pengkomputeran;
- Corak akses memori yang tidak teratur.
- DeepRec menyokong senario tugas berskala ultra besar melalui seni bina PS-worker. Dalam seni bina PS-pekerja, storan dan pengiraan dipisahkan dalam (puluhan atau ratusan) Pelayan Parameter dalam bentuk Nilai-Kekunci PS ini menyediakan akses kepada (ratusan atau ribuan) Pekerja , perkhidmatan yang dikemas kini parameter model, penunjuk utamanya ialah volum peredaran dan kelewatan akses. Dalam menghadapi latihan dan ramalan model jarang berskala besar, pelaksanaan PS-worker dalam rangka kerja sedia ada mendedahkan kesesakannya:
- Gunakan perisian melalui pelbagai- threading Enjin KV yang dilaksanakan telah menjadi hambatan untuk peredaran; .
- Untuk menyelesaikan masalah kesesakan dan kelewatan peredaran, Intel® Agilex menyokong CXL (Compute Express Link) telah diperkenalkan dalam pengoptimuman
- TM I siri FPGA, laluan pelaksanaan ditunjukkan dalam Rajah 5:
Rajah 5 memperkenalkan Intel® AgilexTM I siri pengoptimuman pelaksanaan FPGA
- Enjin KV yang melaksanakan perkakasan melalui FPGA boleh memenuhi jalur lebar memori atau rangkaian dan menyelesaikan masalah kesesakan lalu lintas; > Dengan menyesuaikan protokol lapisan pengangkutan yang menyokong penghantaran yang boleh dipercayai, enjin KV dan protokol rangkaian diproses dalam FPGA yang sama, dan nilai diproses secara langsung berdasarkan kekunci tanpa melalui CPU hos, dengan kependaman yang sangat rendah dan jitter minimum, menghapuskan keperluan untuk Pelayan Parameter untuk diedarkan Latensi dan kesesakan prestasi semasa pengembangan rasmi; disediakan oleh CXL, dan bahagian peranti (FPGA DDR4 digunakan pada kad) untuk menyokong keperluan prestasi tinggi bagi akses data panas, dan PMem digunakan pada bahagian hos untuk menyokong penyimpanan data sejuk, mengurangkan TCO dengan ketara; >
- kepada FPGA boleh melaksanakan selanjutnya pemprosesan dalam talian bagi jadual pembenaman, seperti operasi tensor, atau mencapai kejayaan dalam pemampatan dan penyahmampatan dari segi pengehadan jalur lebar rangkaian.
- Penyelesaian pecutan berdasarkan Intel® AgilexTM siri I FPGA boleh menyokong semua senario di atas pada satu platform perkakasan, dengan ketara meningkatkan throughput. Ia juga menyediakan kependaman akses yang lebih rendah.
- Ringkasan Artikel sebelum ini memperkenalkan pelaksanaan DeepRec yang dioptimumkan pada perkakasan CPU, PMem dan FPGA yang berbeza, dan berjaya menggunakannya untuk berbilang senario perniagaan dalaman dan luaran bagi Alibaba , ia juga telah mencapai pecutan prestasi hujung ke hujung yang ketara dalam perniagaan sebenar, dan menyelesaikan masalah dan cabaran yang dihadapi oleh senario jarang berskala ultra besar dari sudut yang berbeza. Seperti yang kita sedia maklum, Intel menyediakan pilihan perkakasan yang pelbagai untuk aplikasi AI, membolehkan pelanggan memilih penyelesaian AI yang lebih kos efektif pada masa yang sama, Intel, Alibaba dan pelanggannya bekerjasama untuk melaksanakan inovasi perisian-perkakasan berdasarkan; perkakasan yang pelbagai Bekerjasama dan mengoptimumkan untuk merealisasikan nilai teknologi dan platform Intel dengan lebih lengkap. Intel juga berharap untuk terus bekerjasama dengan rakan kongsi industri untuk membangunkan kerjasama yang lebih mendalam dan terus menyumbang kepada penggunaan teknologi AI.
Intel tidak mengawal atau mengaudit data pihak ketiga. Sila semak kandungan ini, rujuk sumber lain dan sahkan bahawa data yang dinyatakan adalah tepat.
Keputusan ujian prestasi adalah berdasarkan ujian yang dijalankan pada 27 April 2022 dan 23 Mei 2022, dan mungkin tidak menggambarkan semua kemas kini keselamatan yang tersedia secara terbuka. Lihat Pendedahan Konfigurasi untuk butiran. Tiada produk atau komponen yang benar-benar selamat.
Senario pengurangan kos yang diterangkan bertujuan untuk menggambarkan cara produk Intel tertentu boleh memberi kesan kepada kos masa hadapan dan memberikan penjimatan kos dalam situasi dan konfigurasi tertentu. Setiap situasi berbeza. Intel tidak menjamin sebarang kos atau pengurangan kos.
Ciri dan faedah teknologi Intel bergantung pada konfigurasi sistem dan mungkin memerlukan perkakasan, perisian atau perkhidmatan yang didayakan untuk diaktifkan. Prestasi produk akan berbeza-beza berdasarkan konfigurasi sistem. Tiada produk atau komponen yang benar-benar selamat. Maklumat lanjut tersedia daripada pengeluar atau peruncit peralatan asal, atau lihat intel.com.
Intel, logo Intel dan tanda dagangan Intel lain ialah tanda dagangan Intel Corporation atau anak syarikatnya di Amerika Syarikat dan/atau negara lain.
© Hak Cipta Intel Corporation
[1]
Jika anda mahu Untuk mengetahui lebih lanjut tentang ujian prestasi, sila lawati https://github.com/alibaba/DeepRec/tree/main/modelzoo/WDL
[2]
Untuk butiran lanjut tentang ujian prestasi, sila lawati https://help.aliyun.com/document_detail/25378.html?spm=5176.2020520101.0.0.787c4df5FgibRE#re7p >
Atas ialah kandungan terperinci Intel membantu membina enjin latihan/ramalan model jarang berskala besar sumber terbuka DeepRec. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI