
 Peranti teknologiAITransformer menyatukan perwakilan berasaskan voxel untuk pengesanan objek 3D
Peranti teknologiAITransformer menyatukan perwakilan berasaskan voxel untuk pengesanan objek 3DTransformer menyatukan perwakilan berasaskan voxel untuk pengesanan objek 3D

kertas arXiv "Menyatukan Perwakilan berasaskan Voxel dengan Transformer untuk Pengesanan Objek 3D", 22 Jun, Universiti China Hong Kong, Universiti Hong Kong, Teknologi Megvii (sebagai ingatan Dr. Sun Jian) dan Teknologi Simou, dll.

Kertas kerja ini mencadangkan rangka kerja pengesanan objek 3-D berbilang mod bersatu, dipanggil UVTR. Kaedah ini bertujuan untuk menyatukan perwakilan berbilang mod ruang voxel dan membolehkan pengesanan 3-D mod tunggal atau rentas mod tunggal yang tepat dan mantap. Untuk tujuan ini, ruang khusus modaliti direka bentuk untuk mewakili input yang berbeza kepada ruang ciri voxel. Kekalkan ruang voxel tanpa pemampatan ketinggian, mengurangkan kekaburan semantik dan membolehkan interaksi spatial. Berdasarkan pendekatan bersatu ini, interaksi rentas modal dicadangkan untuk menggunakan sepenuhnya ciri-ciri sedia ada bagi penderia yang berbeza, termasuk pemindahan pengetahuan dan gabungan modal. Dengan cara ini, ekspresi awan titik yang sedar geometri dan ciri kaya konteks dalam imej boleh dieksploitasi dengan baik, menghasilkan prestasi dan keteguhan yang lebih baik.
Penyahkod pengubah digunakan untuk mencuba ciri secara cekap daripada ruang bersatu dengan lokasi yang boleh dipelajari, yang memudahkan interaksi peringkat objek. Secara umumnya, UVTR mewakili percubaan awal untuk mewakili modaliti yang berbeza dalam rangka kerja yang bersatu, mengatasi prestasi sebelumnya pada input modal tunggal dan berbilang modal, mencapai prestasi terkemuka pada set ujian nuScenes, lidar, kamera dan NDS keluaran berbilang modal. ialah 69.7%, 55.1% dan 71.1% masing-masing.
Kod:https://github.com/dvlab-research/UVTR.
Seperti yang ditunjukkan dalam rajah:
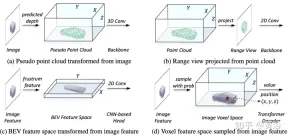
Dalam proses penyatuan perwakilan, ia boleh dibahagikan secara kasar kepada perwakilan aliran peringkat input dan aliran peringkat ciri. Untuk pendekatan pertama, data multimodal diselaraskan pada permulaan rangkaian. Khususnya, awan titik pseudo dalam (a) ditukar daripada imej bantuan kedalaman yang diramalkan, manakala imej paparan julat dalam (b) diunjurkan daripada awan titik. Disebabkan oleh ketidaktepatan kedalaman dalam awan titik pseudo dan keruntuhan geometri 3-D dalam imej paparan julat, struktur spatial data dimusnahkan, yang membawa kepada hasil yang buruk. Untuk kaedah peringkat ciri, kaedah biasa ialah menukar ciri imej kepada frustum dan kemudian memampatkannya ke dalam ruang BEV, seperti ditunjukkan dalam Rajah (c). Walau bagaimanapun, disebabkan trajektori seperti sinarnya, maklumat ketinggian (ketinggian) mampatan pada setiap kedudukan mengagregatkan ciri pelbagai sasaran, sekali gus memperkenalkan kekaburan semantik. Pada masa yang sama, pendekatan tersiratnya sukar untuk menyokong interaksi ciri eksplisit dalam ruang 3-D dan mengehadkan pemindahan pengetahuan selanjutnya. Oleh itu, perwakilan yang lebih bersatu diperlukan untuk merapatkan jurang modal dan memudahkan interaksi pelbagai rupa.
Rangka kerja yang dicadangkan dalam artikel ini menyatukan perwakilan berasaskan voxel dan pengubah. Khususnya, perwakilan ciri dan interaksi imej dan awan titik dalam ruang eksplisit berasaskan voxel. Untuk imej, ruang voxel dibina dengan ciri pensampelan dari satah imej mengikut kedalaman yang diramalkan dan kekangan geometri, seperti ditunjukkan dalam Rajah (d). Untuk awan titik, lokasi yang tepat secara semula jadi membolehkan ciri dikaitkan dengan voxel. Kemudian, pengekod voxel diperkenalkan untuk interaksi spatial untuk mewujudkan hubungan antara ciri bersebelahan. Dengan cara ini, interaksi rentas modal diteruskan secara semula jadi dengan ciri dalam setiap ruang voxel. Untuk interaksi peringkat sasaran, pengubah boleh ubah bentuk digunakan sebagai penyahkod untuk mencontohi ciri khusus pertanyaan sasaran pada setiap kedudukan (x, y, z) dalam ruang voxel bersatu, seperti yang ditunjukkan dalam Rajah (d). Pada masa yang sama, pengenalan kedudukan pertanyaan 3-D dengan berkesan mengurangkan kekaburan semantik yang disebabkan oleh mampatan maklumat ketinggian (ketinggian) dalam ruang BEV.
Seperti yang ditunjukkan dalam rajah ialah seni bina UVTR bagi input berbilang modal: diberikan bingkai tunggal atau imej berbilang bingkai dan awan titik, ia mula-mula diproses dalam tulang belakang tunggal dan ditukarkan kepada spatial VI khusus modaliti dan VP, di mana transformasi paparan digunakan untuk imej. Dalam pengekod voxel, ciri berinteraksi secara spatial, dan pemindahan pengetahuan mudah disokong semasa latihan. Bergantung pada tetapan, pilih ciri mod tunggal atau berbilang modal melalui suis modal. Akhir sekali, ciri diambil sampel daripada VU spatial bersatu dengan lokasi yang boleh dipelajari dan diramalkan menggunakan penyahkod pengubah.
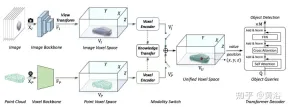
Gambar menunjukkan butiran transformasi pandangan:

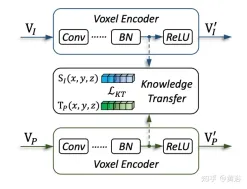
Gambar menunjukkan butiran pemindahan pengetahuan:
Keputusan percubaan adalah seperti berikut:


Atas ialah kandungan terperinci Transformer menyatukan perwakilan berasaskan voxel untuk pengesanan objek 3D. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Let's Dance: Gerakan berstruktur untuk menyempurnakan jaring saraf manusia kitaApr 27, 2025 am 11:09 AM
Let's Dance: Gerakan berstruktur untuk menyempurnakan jaring saraf manusia kitaApr 27, 2025 am 11:09 AMPara saintis telah mengkaji secara meluas rangkaian saraf manusia dan mudah (seperti yang ada di C. elegans) untuk memahami fungsi mereka. Walau bagaimanapun, soalan penting timbul: Bagaimana kita menyesuaikan rangkaian saraf kita sendiri untuk berfungsi dengan berkesan bersama -sama dengan novel AI s
 New Google Leak mendedahkan perubahan langganan untuk Gemini AIApr 27, 2025 am 11:08 AM
New Google Leak mendedahkan perubahan langganan untuk Gemini AIApr 27, 2025 am 11:08 AMGemini Google Advanced: Tahap Langganan Baru di Horizon Pada masa ini, mengakses Gemini Advanced memerlukan pelan premium AI $ 19.99/bulan. Walau bagaimanapun, laporan Pihak Berkuasa Android menunjukkan perubahan yang akan datang. Kod dalam google terkini p
 Bagaimana Pecutan Analisis Data Menyelesaikan Bots Tersembunyi AIApr 27, 2025 am 11:07 AM
Bagaimana Pecutan Analisis Data Menyelesaikan Bots Tersembunyi AIApr 27, 2025 am 11:07 AMWalaupun gembar -gembur di sekitar keupayaan AI maju, satu cabaran penting bersembunyi dalam perusahaan AI perusahaan: kesesakan pemprosesan data. Walaupun CEO merayakan kemajuan AI, jurutera bergelut dengan masa pertanyaan yang perlahan, saluran paip yang terlalu banyak, a
 Markitdown MCP boleh menukar mana -mana dokumen ke Markdowns!Apr 27, 2025 am 09:47 AM
Markitdown MCP boleh menukar mana -mana dokumen ke Markdowns!Apr 27, 2025 am 09:47 AMDokumen pengendalian tidak lagi hanya mengenai pembukaan fail dalam projek AI anda, ia mengenai mengubah kekacauan menjadi kejelasan. Dokumen seperti PDF, PowerPoints, dan perkataan banjir aliran kerja kami dalam setiap bentuk dan saiz. Mengambil semula berstruktur
 Bagaimana cara menggunakan Google ADK untuk ejen bangunan? - Analytics VidhyaApr 27, 2025 am 09:42 AM
Bagaimana cara menggunakan Google ADK untuk ejen bangunan? - Analytics VidhyaApr 27, 2025 am 09:42 AMMemanfaatkan kuasa Kit Pembangunan Ejen Google (ADK) untuk membuat ejen pintar dengan keupayaan dunia sebenar! Tutorial ini membimbing anda melalui membina ejen perbualan menggunakan ADK, menyokong pelbagai model bahasa seperti Gemini dan GPT. W
 Penggunaan SLM Over LLM untuk Penyelesaian Masalah Berkesan - Analisis VidhyaApr 27, 2025 am 09:27 AM
Penggunaan SLM Over LLM untuk Penyelesaian Masalah Berkesan - Analisis VidhyaApr 27, 2025 am 09:27 AMRingkasan: Model bahasa kecil (SLM) direka untuk kecekapan. Mereka lebih baik daripada model bahasa yang besar (LLM) dalam persekitaran yang kurang sensitif, masa nyata dan privasi. Terbaik untuk tugas-tugas berasaskan fokus, terutamanya di mana kekhususan domain, kawalan, dan tafsiran lebih penting daripada pengetahuan umum atau kreativiti. SLMs bukan pengganti LLM, tetapi mereka sesuai apabila ketepatan, kelajuan dan keberkesanan kos adalah kritikal. Teknologi membantu kita mencapai lebih banyak sumber. Ia sentiasa menjadi promoter, bukan pemandu. Dari era enjin stim ke era gelembung internet, kuasa teknologi terletak pada tahap yang membantu kita menyelesaikan masalah. Kecerdasan Buatan (AI) dan AI Generatif Baru -baru ini tidak terkecuali
 Bagaimana cara menggunakan model Google Gemini untuk tugas penglihatan komputer? - Analytics VidhyaApr 27, 2025 am 09:26 AM
Bagaimana cara menggunakan model Google Gemini untuk tugas penglihatan komputer? - Analytics VidhyaApr 27, 2025 am 09:26 AMMemanfaatkan kekuatan Google Gemini untuk Visi Komputer: Panduan Komprehensif Google Gemini, chatbot AI terkemuka, memanjangkan keupayaannya di luar perbualan untuk merangkumi fungsi penglihatan komputer yang kuat. Panduan ini memperincikan cara menggunakan
 Gemini 2.0 Flash vs O4-Mini: Bolehkah Google lebih baik daripada Openai?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs O4-Mini: Bolehkah Google lebih baik daripada Openai?Apr 27, 2025 am 09:20 AMLandskap AI pada tahun 2025 adalah elektrik dengan kedatangan Flash Gemini 2.0 Google dan Openai's O4-mini. Model-model canggih ini, yang dilancarkan minggu-minggu, mempunyai ciri-ciri canggih yang setanding dan skor penanda aras yang mengagumkan. Perbandingan mendalam ini


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

Dreamweaver CS6
Alat pembangunan web visual

EditPlus versi Cina retak
Saiz kecil, penyerlahan sintaks, tidak menyokong fungsi gesaan kod

Dreamweaver Mac版
Alat pembangunan web visual

SublimeText3 versi Inggeris
Disyorkan: Versi Win, menyokong gesaan kod!

