
Rumah >Peranti teknologi >AI >Google telah mencipta sistem terjemahan mesin untuk 1,000+ bahasa 'ekor panjang' dan sudah menyokong beberapa bahasa khusus
Google telah mencipta sistem terjemahan mesin untuk 1,000+ bahasa 'ekor panjang' dan sudah menyokong beberapa bahasa khusus

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-08 15:21:131789semak imbas
Kualiti sistem terjemahan mesin (MT) akademik dan komersial telah meningkat secara mendadak sepanjang dekad yang lalu. Peningkatan ini sebahagian besarnya disebabkan oleh kemajuan dalam pembelajaran mesin dan ketersediaan set data perlombongan web berskala besar. Pada masa yang sama, kemunculan model pembelajaran mendalam (DL) dan E2E, set data bahasa tunggal selari berskala besar yang diperoleh daripada perlombongan web, kaedah peningkatan data seperti terjemahan balik dan latihan kendiri, dan pelbagai skala besar. pemodelan bahasa telah menghasilkan keupayaan untuk menyokong lebih daripada 100 sistem terjemahan mesin berkualiti tinggi untuk bahasa.
Walau bagaimanapun, walaupun terdapat kemajuan besar dalam terjemahan mesin sumber rendah, bilangan bahasa yang telah dibina secara meluas dan sistem terjemahan mesin umum adalah terhad kepada kira-kira 100 , dan mereka jelas hanya tersedia hari ini beberapa daripada lebih 7,000 bahasa yang dituturkan di dunia. Selain bilangan bahasa yang terhad, pengedaran bahasa yang disokong oleh sistem terjemahan mesin semasa juga sangat condong ke arah bahasa Eropah.
Kita dapat melihat bahawa walaupun populasi mereka besar, terdapat lebih sedikit perkhidmatan untuk bahasa yang dituturkan di Afrika, Asia Selatan dan Tenggara serta bahasa asli Amerika. Contohnya, Terjemahan Google menyokong Frisian, Malta, Icelandic dan Corsica, yang kesemuanya mempunyai kurang daripada 1 juta penutur asli. Sebagai perbandingan, populasi dialek Bihar yang tidak dilayan oleh Terjemahan Google adalah kira-kira 51 juta, populasi Oromo adalah kira-kira 24 juta, populasi Quechua adalah kira-kira 9 juta, dan populasi Tigrinya adalah kira-kira 9 juta (2022). Bahasa-bahasa ini dikenali sebagai bahasa "ekor panjang", dan kekurangan data memerlukan penerapan teknik pembelajaran mesin yang boleh melangkaui bahasa dengan data latihan yang mencukupi.
Membina sistem penterjemahan mesin untuk bahasa ekor panjang ini sebahagian besarnya terhad oleh kekurangan set data digital yang tersedia dan alatan NLP seperti model pengenalan bahasa (LangID). Ini ada di mana-mana untuk bahasa sumber tinggi.
Dalam kertas kerja Google baru-baru ini "Membina Sistem Terjemahan Mesin untuk Seribu Bahasa Seterusnya", lebih daripada dua dozen penyelidik menunjukkan usaha mereka untuk membina mesin praktikal yang menyokong lebih daripada 1,000 bahasa keputusan.

Alamat kertas: https://arxiv.org/pdf/2205.03983.pdf
Khusus Secara khusus, penyelidik menerangkan keputusan mereka daripada tiga bidang penyelidikan berikut.
Pertama, set data yang dilombong web yang bersih dicipta untuk 1500+ bahasa melalui latihan pra-separa penyeliaan untuk pengecaman bahasa dan teknik penapisan dipacu data.
Kedua, melalui model berbilang bahasa berskala besar yang dilatih dengan data selari yang diselia untuk lebih daripada 100 bahasa sumber tinggi dan set data eka bahasa untuk 1000+ bahasa lain, Mencipta terjemahan mesin yang praktikal dan berkesan model untuk bahasa yang kurang mendapat perkhidmatan.
Ketiga, kaji pengehadan metrik penilaian dalam bahasa ini, jalankan analisis kualitatif keluaran model terjemahan mesin dan fokus pada beberapa corak ralat biasa model sedemikian.
Para penyelidik berharap kerja ini akan memberikan pandangan yang berguna kepada pengamal yang bekerja membina sistem terjemahan mesin untuk bahasa yang kurang diselidiki pada masa ini. Di samping itu, penyelidik berharap kerja ini boleh membawa kepada arah penyelidikan yang menangani kelemahan model berbilang bahasa berskala besar dalam tetapan data yang jarang.
Pada persidangan I/O pada 12 Mei, Google mengumumkan bahawa sistem terjemahannya telah menambah 24 bahasa baharu, termasuk beberapa bahasa asli Amerika yang khusus Contohnya, dialek Bihar, Oromo. Quechua dan Tigrinya yang disebutkan di atas.

Kertas Keseluruhan
Kerja ini terbahagi kepada empat bab utama di sini kita hanya membincangkan setiap satu bab. Kandungan setiap bab diperkenalkan secara ringkas.
Buat set data teks web 1000 bahasa
Bab ini memperincikan usaha penyelidik untuk merangkak teks satu bahasa untuk 1500+ bahasa Kaedah yang digunakan dalam proses set data. Kaedah ini memfokuskan pada memulihkan data berketepatan tinggi (iaitu, bahagian tinggi teks bersih dalam bahasa), jadi sebahagian besarnya adalah pelbagai kaedah penapisan.
Secara umumnya, kaedah yang digunakan oleh penyelidik termasuk yang berikut:
- Alih keluar bahasa dengan kualiti data latihan yang lemah dan prestasi LangID yang lemah daripada model LangID dan latih model LangID CLD3 1629 bahasa dan model LangID (SSLID) separa seliaan
- Lakukan operasi pengelompokan mengikut kadar ralat bahasa dalam model CLD3; 🎜 > Tapis ayat menggunakan konsistensi dokumen;
- Tapis semua korpora menggunakan senarai perkataan ambang peratusan
- Gunakan LangID separa diselia; (SSLID) ) untuk menapis semua korpora;
- Gunakan ingatan relatif untuk mengesan bahasa luar dan menapis menggunakan Term-Frequency-Inverse-Internet-Frequency (TF-IIF) ;
- Gunakan skor Keanomalian Frekuensi Token untuk mengesan bahasa terpencil dan mereka bentuk penapis secara manual untuknya;
- Hadapi semua korpora pada peringkat ayat Lakukan deduplikasi operasi.
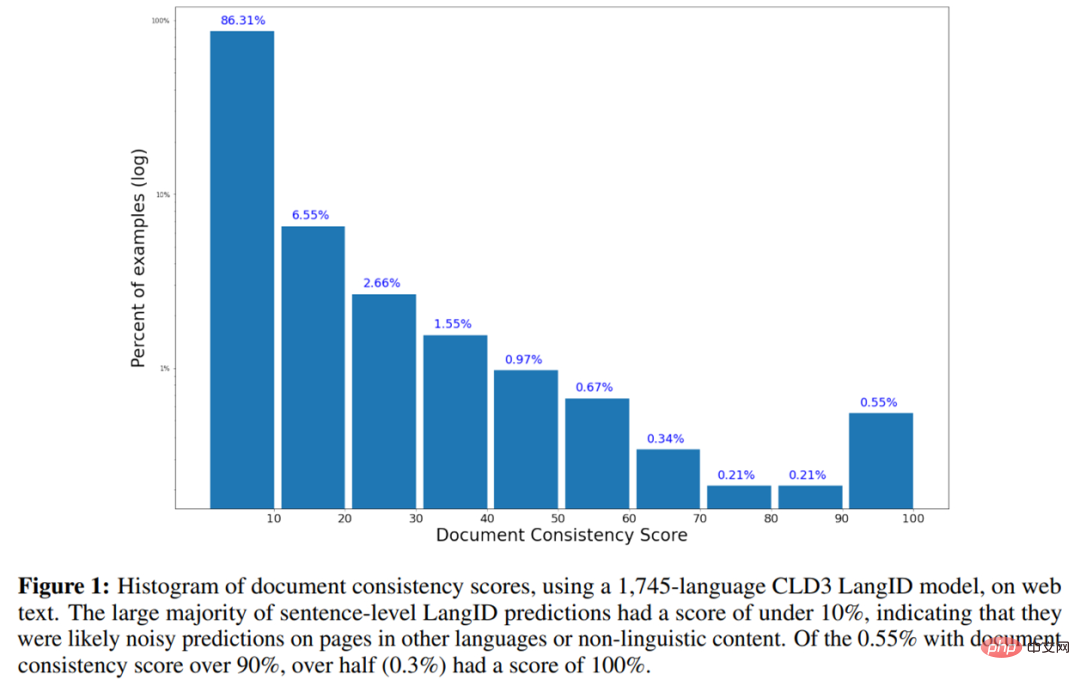
- Berikut ialah histogram skor ketekalan dokumen menggunakan model CLD3 LangID bagi 1745-bahasa pada teks web.
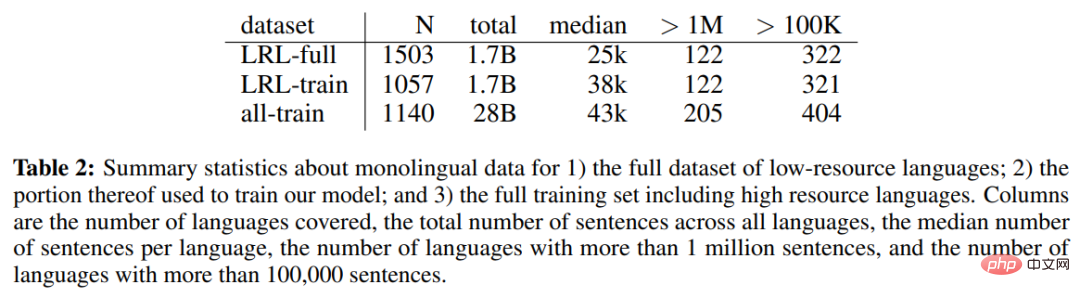
Jadual 2 di bawah menunjukkan data bahasa tunggal set data bahasa sumber rendah (LRL) lengkap, sebahagian daripada data bahasa tunggal digunakan untuk melatih model, dan termasuk statistik bahasa tunggal untuk set latihan lengkap termasuk bahasa sumber tinggi.
Direktori bab adalah seperti berikut:
ialah bahasa ekor panjang Membina Model Terjemahan Mesin
 Untuk data ekabahasa yang dilombong daripada web, cabaran seterusnya ialah mencipta model terjemahan mesin am berkualiti tinggi daripada jumlah ekabahasa yang terhad data latihan. Untuk tujuan ini, para penyelidik menggunakan pendekatan pragmatik untuk memanfaatkan semua data selari yang tersedia untuk bahasa sumber yang lebih tinggi untuk meningkatkan kualiti bahasa ekor panjang di mana hanya data eka bahasa tersedia. Mereka memanggil persediaan ini "sumber sifar" kerana tiada pengawasan langsung untuk bahasa ekor panjang.
Untuk data ekabahasa yang dilombong daripada web, cabaran seterusnya ialah mencipta model terjemahan mesin am berkualiti tinggi daripada jumlah ekabahasa yang terhad data latihan. Untuk tujuan ini, para penyelidik menggunakan pendekatan pragmatik untuk memanfaatkan semua data selari yang tersedia untuk bahasa sumber yang lebih tinggi untuk meningkatkan kualiti bahasa ekor panjang di mana hanya data eka bahasa tersedia. Mereka memanggil persediaan ini "sumber sifar" kerana tiada pengawasan langsung untuk bahasa ekor panjang.
Penyelidik telah menggunakan beberapa teknik yang dibangunkan untuk terjemahan mesin sejak beberapa tahun lalu untuk meningkatkan kualiti terjemahan sumber sifar bagi bahasa ekor panjang. Teknik ini termasuk pembelajaran diselia sendiri daripada data eka bahasa, pembelajaran seliaan berbilang bahasa berskala besar, terjemahan belakang berskala besar dan latihan kendiri, model berkapasiti tinggi. Mereka memanfaatkan alatan ini untuk mencipta model terjemahan mesin yang mampu menterjemah 1000+ bahasa, memanfaatkan korpora selari sedia ada yang meliputi kira-kira 100 bahasa dan set data ekabahasa 1000 bahasa yang dibina daripada web.
Secara khusus, penyelidik mula-mula menekankan kepentingan kapasiti model dalam model berbilang bahasa dengan membandingkan prestasi 1.5 bilion dan 6 bilion parameter Transformers pada terjemahan sumber sifar (3.2), dan kemudian meningkatkan bilangan bahasa yang diselia sendiri kepada 1000, mengesahkan bahawa apabila lebih banyak data eka bahasa daripada bahasa yang sama tersedia, prestasi bertambah baik untuk kebanyakan bahasa ekor panjang (3.3). Walaupun model 1000 bahasa penyelidik menunjukkan prestasi yang munasabah, mereka menggabungkan penambahan data berskala besar untuk memahami kekuatan dan batasan pendekatan mereka.
Selain itu, penyelidik memperhalusi model generatif pada subset 30 bahasa dengan sejumlah besar data sintetik melalui latihan kendiri dan terjemahan belakang (3.4). Mereka seterusnya menerangkan kaedah praktikal untuk menapis data sintetik untuk meningkatkan keteguhan model yang diperhalusi ini kepada halusinasi dan terjemahan bahasa yang salah (3.5).
Kami juga menggunakan penyulingan peringkat jujukan untuk memperhalusi model ini kepada seni bina yang lebih kecil dan lebih mudah untuk alasan dan menyerlahkan jurang prestasi antara model guru dan pelajar (3.6).
Jadual kandungan bab adalah seperti berikut:
Penilaian
 Untuk menilai model terjemahan mesin mereka, para penyelidik mula-mula menterjemah ayat bahasa Inggeris ke dalam bahasa ini dan membina set penilaian (4.1) untuk 38 bahasa ekor panjang yang dipilih. Mereka menyerlahkan batasan BLEU dalam tetapan ekor panjang dan menilai bahasa ini menggunakan CHRF (4.2).
Untuk menilai model terjemahan mesin mereka, para penyelidik mula-mula menterjemah ayat bahasa Inggeris ke dalam bahasa ini dan membina set penilaian (4.1) untuk 38 bahasa ekor panjang yang dipilih. Mereka menyerlahkan batasan BLEU dalam tetapan ekor panjang dan menilai bahasa ini menggunakan CHRF (4.2).
Para penyelidik juga mencadangkan anggaran metrik bebas rujukan berdasarkan terjemahan pergi balik untuk memahami kualiti model dalam bahasa di mana set rujukan tidak tersedia, dan Kualiti daripada model seperti yang diukur oleh metrik ini dilaporkan (4.3). Mereka melakukan penilaian manusia terhadap model pada subset 28 bahasa dan melaporkan hasilnya, mengesahkan bahawa adalah mungkin untuk membina sistem terjemahan mesin yang berguna mengikut pendekatan yang diterangkan dalam kertas (4.4).
Untuk memahami kelemahan model sumber sifar berbilang bahasa berskala besar, penyelidik menjalankan analisis ralat kualitatif pada beberapa bahasa. Didapati model tersebut sering mengelirukan perkataan dan konsep yang serupa dalam pengedaran, seperti "harimau" menjadi "buaya kecil" (4.5). Dan di bawah tetapan sumber yang lebih rendah (4.6), keupayaan model untuk menterjemah token berkurangan pada token yang kelihatan kurang kerap.
Para penyelidik juga mendapati bahawa model ini selalunya tidak dapat menterjemah input pendek atau satu perkataan (4.7) dengan tepat. Penyelidikan ke atas model yang diperhalusi menunjukkan bahawa semua model lebih berkemungkinan untuk menguatkan bias atau hingar yang terdapat dalam data latihan (4.8).
Jadual kandungan Bab adalah seperti berikut:

Eksperimen dan nota tambahan
Para penyelidik menjalankan beberapa eksperimen tambahan pada model di atas, menunjukkan bahawa mereka secara amnya berprestasi lebih baik dalam menterjemah secara langsung antara bahasa yang serupa tanpa menggunakan bahasa Inggeris sebagai pangsi (5.1), dan bahawa mereka boleh digunakan antara bahasa yang berbeza. skrip Transliterasi sampel sifar bagi (5.2).
Mereka menerangkan helah praktikal untuk menambahkan tanda baca terminal pada sebarang input, dipanggil "helah tempoh", yang boleh digunakan untuk meningkatkan kualiti terjemahan (5.3) .
Selain itu, kami menunjukkan bahawa model ini teguh kepada penggunaan glif Unicode bukan standard dalam beberapa tetapi bukan semua bahasa (5.4), dan meneroka beberapa fon bukan Unicode ( 5.5).
Direktori bab adalah seperti berikut:

Untuk butiran penyelidikan lanjut, sila rujuk asal kertas.
Atas ialah kandungan terperinci Google telah mencipta sistem terjemahan mesin untuk 1,000+ bahasa 'ekor panjang' dan sudah menyokong beberapa bahasa khusus. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI