
Rumah >Peranti teknologi >AI >Kaedah pengesanan sasaran BEV gabungan pelbagai mod AutoJajarkan V1 dan V2
Kaedah pengesanan sasaran BEV gabungan pelbagai mod AutoJajarkan V1 dan V2

- PHPzke hadapan
- 2023-04-08 14:41:151242semak imbas
Dalam pemanduan autonomi, pengesanan sasaran melalui imej RGB atau awan titik lidar telah diterokai secara meluas. Walau bagaimanapun, bagaimana untuk menjadikan kedua-dua sumber data ini saling melengkapi dan bermanfaat antara satu sama lain masih menjadi cabaran. AutoAlignV1 dan AutoAlignV2 kebanyakannya adalah hasil kerja Universiti Sains dan Teknologi China, Institut Teknologi Harbin dan SenseTime (pada mulanya termasuk Universiti China Hong Kong dan Universiti Tsinghua).
AutoAlignV1 berasal daripada kertas arXiv "AutoAlign: Pixel-Instance Feature Agregation for Multi-Modal 3D Object Detection", yang dimuat naik pada April 2022.

Abstrak
Kertas kerja ini mencadangkan strategi gabungan ciri automatik AutoAlign V1 untuk pengesanan sasaran 3D. Gunakan peta penjajaran yang boleh dipelajari untuk memodelkan hubungan pemetaan antara imej dan awan titik, dan bukannya mewujudkan korespondensi deterministik dengan matriks unjuran kamera. Graf ini membolehkan model menjajarkan ciri bukan homomorfik secara automatik dalam cara yang dinamik dan dipacu data. Khususnya, modul penjajaran ciri tumpuan silang direka bentuk untuk mengagregat secara adaptif ciri imej tahap piksel bagi setiap voxel. Untuk mempertingkatkan ketekalan semantik dalam proses penjajaran ciri, modul interaksi ciri merentas mod yang diselia sendiri juga direka bentuk, yang melaluinya model boleh mempelajari pengagregatan ciri berpandukan ciri peringkat contoh.
Pengenalan latar belakang
Pengesan objek 3-D berbilang mod boleh dibahagikan secara kasar kepada dua kategori: gabungan peringkat keputusan dan gabungan peringkat ciri. Yang pertama mengesan objek dalam mod masing-masing dan kemudian membawa kotak sempadan bersama-sama dalam ruang 3D. Tidak seperti gabungan peringkat keputusan, gabungan peringkat ciri menggabungkan ciri berbilang modal ke dalam satu perwakilan untuk mengesan objek. Oleh itu, pengesan boleh menggunakan sepenuhnya ciri daripada modaliti yang berbeza semasa peringkat inferens. Memandangkan ini, lebih banyak kaedah gabungan peringkat ciri telah dibangunkan baru-baru ini.
Sesuatu kerja memproyeksikan setiap titik ke satah imej dan memperoleh ciri imej yang sepadan melalui interpolasi dwilinear. Walaupun pengagregatan ciri dilakukan dengan halus pada tahap piksel, corak padat dalam domain imej akan hilang disebabkan oleh ketandusan titik pelakuran, iaitu konsistensi semantik dalam ciri imej dimusnahkan.
Kerja lain menggunakan penyelesaian awal yang disediakan oleh pengesan 3D untuk mendapatkan ciri RoI daripada modaliti yang berbeza dan menyambungkannya bersama-sama untuk gabungan ciri. Ia mengekalkan ketekalan semantik dengan melakukan gabungan peringkat contoh, tetapi mengalami masalah seperti pengagregatan ciri kasar dan kehilangan maklumat 2D dalam peringkat penjanaan cadangan awal.
Untuk menggunakan sepenuhnya kedua-dua kaedah ini, penulis mencadangkan rangka kerja gabungan ciri berbilang mod bersepadu untuk pengesanan objek 3-D, dinamakan AutoAlign. Ia membolehkan pengesan untuk mengagregatkan ciri-ciri rentas mod dalam cara penyesuaian, terbukti berkesan dalam memodelkan hubungan antara perwakilan bukan homomorfik. Pada masa yang sama, ia mengeksploitasi pengagregatan ciri berbutir halus tahap piksel sambil mengekalkan konsistensi semantik melalui interaksi ciri peringkat contoh.
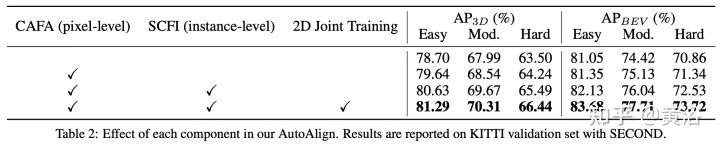
Seperti yang ditunjukkan dalam rajah: interaksi ciri beroperasi pada dua peringkat: (i) pengagregatan ciri peringkat piksel; (ii) interaksi ciri peringkat contoh.
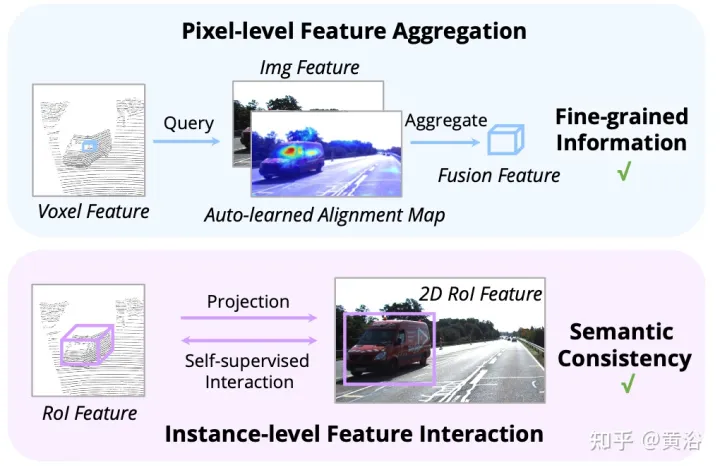
Kaedah AutoAlign
Kerja sebelumnya menggunakan matriks unjuran kamera untuk menjajarkan ciri imej dan titik dengan cara yang pasti. Pendekatan ini berkesan, tetapi mungkin memperkenalkan dua masalah yang berpotensi: 1) titik tidak boleh mendapatkan pandangan yang lebih luas tentang data imej, dan 2) hanya konsistensi kedudukan dikekalkan, manakala korelasi semantik diabaikan. Oleh itu, AutoAlign mereka bentuk modul Cross Attention Feature Alignment (CAFA) untuk menyesuaikan ciri secara adaptif antara perwakilan bukan homomorfik. CAFA (Penjajaran Ciri Silang Perhatian) Modul ini tidak menggunakan mod padanan satu dengan satu, tetapi menjadikan setiap voxel menyedari keseluruhan imej dan memfokus secara dinamik pada tahap piksel berdasarkan peta penjajaran yang boleh dipelajari ciri 2D.
Seperti yang ditunjukkan dalam rajah: AutoAlign terdiri daripada dua komponen teras CAFA melakukan pengagregatan ciri pada satah imej dan mengekstrak maklumat tahap piksel berbutir halus bagi setiap ciri voxel SCFI (Self-supervised Cross -Modal Interaksi Ciri) Melaksanakan penyeliaan kendiri merentas modal dan menggunakan panduan peringkat contoh untuk meningkatkan ketekalan semantik modul CAFA.
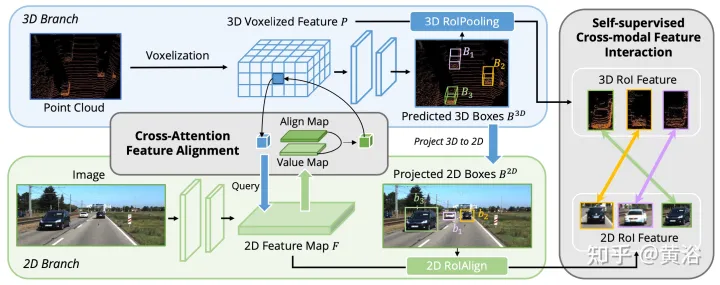
CAFA ialah paradigma terperinci untuk mengagregatkan ciri imej. Walau bagaimanapun, ia tidak dapat menangkap maklumat peringkat contoh. Sebaliknya, gabungan ciri berasaskan RoI mengekalkan integriti objek semasa mengalami pengagregatan ciri kasar dan kehilangan maklumat 2D semasa peringkat penjanaan cadangan.
Untuk merapatkan jurang antara gabungan aras piksel dan aras contoh, modul Interaksi Ciri Merentas Moda Sendiri (SCFI) diperkenalkan untuk membimbing pembelajaran CAFA. Ia secara langsung menggunakan ramalan akhir pengesan 3D sebagai cadangan, memanfaatkan ciri imej dan titik untuk penjanaan cadangan yang tepat. Tambahan pula, daripada menggabungkan ciri rentas mod bersama untuk pengoptimuman kotak sempadan selanjutnya, kekangan persamaan ditambah pada pasangan ciri rentas modal sebagai panduan peringkat contoh untuk penjajaran ciri.
Memandangkan peta ciri 2D dan ciri voksel 3D yang sepadan, bingkai pengesanan 3D serantau N diambil secara rawak, dan kemudian diunjurkan pada satah 2D menggunakan matriks unjuran kamera, dengan itu menghasilkan set pasangan bingkai 2D. Setelah kotak berpasangan diperoleh, 2DRoIAlign dan 3DRoIPooling digunakan dalam ruang ciri 2D dan 3D untuk mendapatkan ciri RoI masing-masing.
Untuk setiap pasangan ciri RoI 2D dan 3D, lakukan Interaksi Ciri Silang Mod (SCFI) Penyeliaan Sendiri . Kedua-dua ciri dimasukkan ke dalam kepala unjuran, yang mengubah output satu modaliti untuk dipadankan dengan yang lain. Memperkenalkan kepala ramalan dengan dua lapisan bersambung sepenuhnya. Seperti yang ditunjukkan dalam rajah:
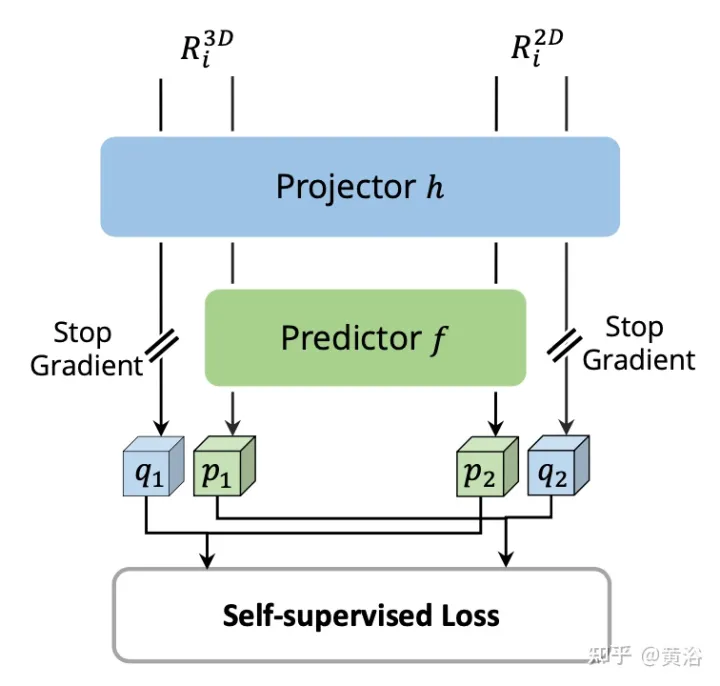
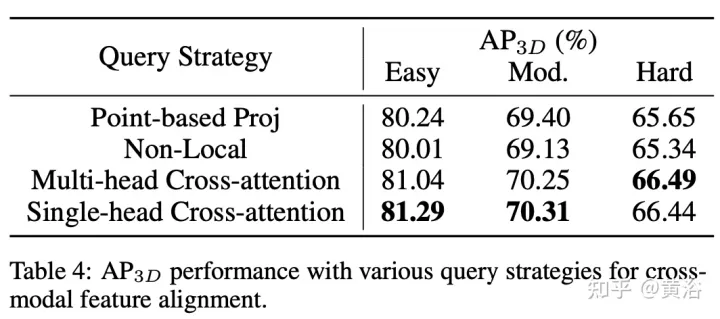

Cross-domain DeformCAFA (Cross-Attention Feature Alignment). Ia memfokuskan pada titik persampelan yang boleh dipelajari yang jarang untuk model perhubungan silang modal, yang meningkatkan toleransi terhadap ralat penentukuran dan mempercepatkan pengagregatan ciri merentas modaliti. Untuk mengatasi kompleks GT-AUG dalam tetapan berbilang modal, strategi peningkatan rentas modal yang mudah dan berkesan direka untuk gabungan cembung berdasarkan tampungan imej yang diberikan maklumat kedalaman. Selain itu, melalui skim latihan keciciran peringkat imej, model ini dapat melakukan inferens secara dinamik.
Kod akan menjadi sumber terbuka:https://github.com/zehuichen123/AutoAlignV2.
Nota: GT-AUG ("KEDUA: Pengesanan konvolusi yang jarang terbenam". Sensors, 2018), kaedah penambahan data
Latar BelakangCara untuk menggabungkan perwakilan heterogen lidar dan kamera dengan berkesan untuk pengesanan objek 3-D belum diterokai sepenuhnya. Kesukaran semasa dalam melatih pengesan rentas modal dikaitkan dengan dua aspek. Di satu pihak, strategi gabungan yang menggabungkan imej dan maklumat spatial masih tidak optimum. Disebabkan oleh perwakilan heterogen antara imej RGB dan awan titik, penjajaran berhati-hati diperlukan sebelum ciri dikelompokkan bersama. AutoAlign mencadangkan modul penjajaran global yang boleh dipelajari untuk pendaftaran automatik dan mencapai prestasi yang baik. Walau bagaimanapun, ia mesti dilatih dengan bantuan modul CSFI untuk mendapatkan hubungan pemadanan kedudukan dalaman antara titik dan piksel imej.Tambahan pula, ambil perhatian bahawa kerumitan operasi gaya adalah kuadratik dalam saiz imej, jadi adalah tidak praktikal untuk menggunakan pertanyaan pada peta ciri resolusi tinggi. Had ini mungkin membawa kepada maklumat imej yang kasar dan tidak tepat, serta kehilangan perwakilan hierarki yang dibawa oleh FPN. Sebaliknya, penambahan data, terutamanya GT-AUG, merupakan langkah utama untuk pengesan 3D untuk mencapai hasil yang kompetitif. Dari segi pendekatan multimodal, isu penting ialah bagaimana untuk mengekalkan penyegerakan antara imej dan awan titik apabila melakukan operasi potong dan tampal. MoCa menggunakan anotasi topeng intensif buruh dalam domain 2D untuk mendapatkan ciri imej yang tepat. Anotasi peringkat sempadan juga sesuai, tetapi memerlukan penapisan titik yang canggih.
Kaedah AutoAlignV2
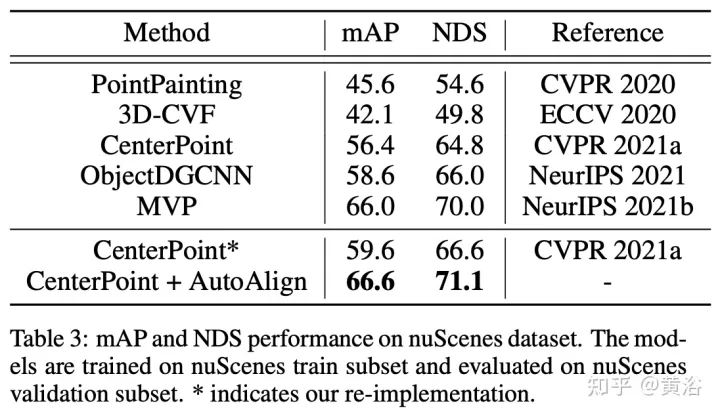
Tujuan AutoAlignV2 adalah untuk mengagregatkan ciri imej secara berkesan untuk meningkatkan lagi prestasi pengesan objek 3D. Bermula daripada seni bina asas AutoAlign: masukkan imej berpasangan ke dalam rangkaian tulang belakang ringan ResNet, dan kemudian masukkannya ke dalam FPN untuk mendapatkan peta ciri. Kemudian, maklumat imej yang berkaitan diagregatkan melalui peta penjajaran yang boleh dipelajari untuk memperkayakan perwakilan 3D bagi voxel bukan kosong dalam peringkat voxelization. Akhir sekali, ciri yang dipertingkatkan dimasukkan ke dalam saluran pengesanan 3D berikutnya untuk menjana ramalan contoh.
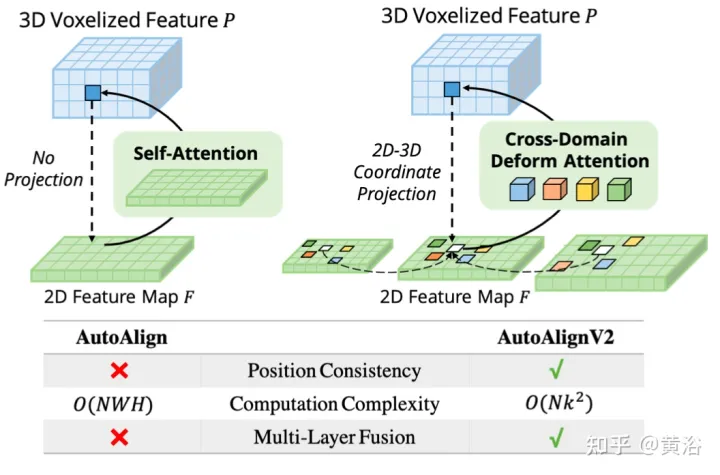
Gambar menunjukkan perbandingan antara AutoAlignV1 dan AutoAlignV2: AutoAlignV2 menggesa modul penjajaran supaya mempunyai hubungan pemetaan umum yang dijamin oleh matriks unjuran deterministik, sambil mengekalkan keupayaan untuk melaraskan kedudukan pengagregatan ciri secara automatik. Disebabkan oleh kos pengiraan yang ringan, AutoAlignV2 dapat mengagregatkan ciri berbilang lapisan maklumat imej hierarki.
Paradigma ini boleh mengagregatkan ciri heterogen dalam cara dipacu data. Walau bagaimanapun, dua kesesakan utama masih menghalang prestasi. Yang pertama ialah pengagregatan ciri yang tidak cekap. Walaupun peta perhatian global secara automatik mencapai penjajaran ciri antara imej RGB dan titik LiDAR, kos pengiraan adalah tinggi. Yang kedua ialah penyegerakan dipertingkatkan data yang kompleks antara imej dan titik. GT-AUG ialah langkah utama untuk pengesan objek 3D berprestasi tinggi, tetapi cara mengekalkan konsistensi semantik antara titik dan imej semasa latihan masih menjadi masalah yang kompleks.
Seperti yang ditunjukkan dalam rajah, AutoAlignV2 terdiri daripada dua bahagian: Modul Cross-domain DeformCAFA dan Depth-aware GT-AUGstrategi peningkatan data, dan juga mencadangkan Strategi latihan keciciran peringkat imej membolehkan model melakukan inferens dengan cara yang lebih dinamik.
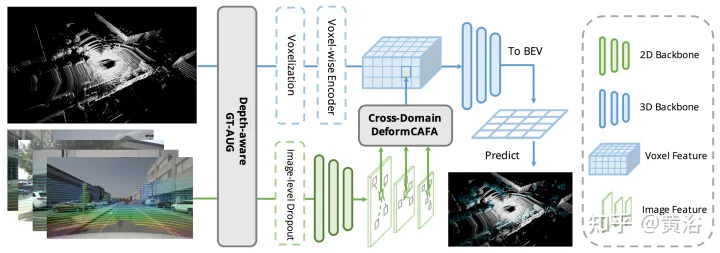
- Penggabungan ciri ubah bentuk
Hambatan CAFA adalah untuk menganggap semua piksel sebagai lokasi spatial yang mungkin. Berdasarkan sifat imej 2D, maklumat yang paling berkaitan terletak terutamanya di lokasi bersebelahan secara geometri. Oleh itu, ia tidak perlu untuk mempertimbangkan semua lokasi, tetapi hanya beberapa kawasan perkara utama. Seperti yang ditunjukkan dalam rajah, operasi DeformCAFA rentas domain baharu diperkenalkan di sini, yang sangat mengurangkan calon pensampelan dan secara dinamik menentukan kawasan titik utama satah imej untuk setiap ciri pertanyaan voxel.
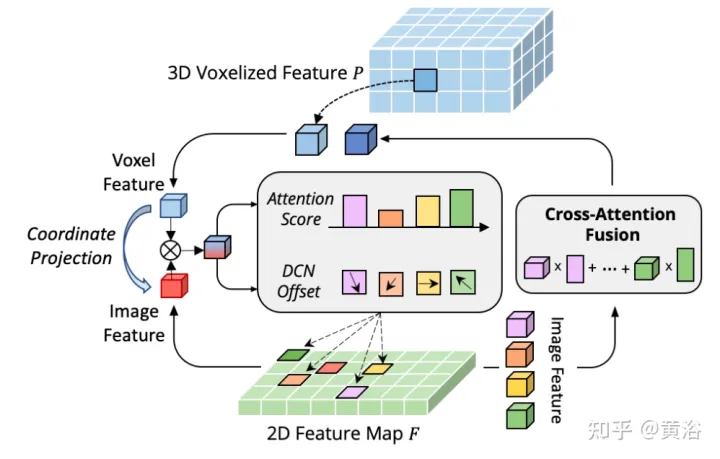
Dengan bantuan offset pensampelan yang dijana secara dinamik, DeformCAFA dapat memodelkan perhubungan merentas domain lebih pantas daripada operasi biasa. Mampu melakukan pengagregatan ciri berbilang lapisan, iaitu, menggunakan sepenuhnya maklumat hierarki yang disediakan oleh lapisan FPN. Satu lagi kelebihan DeformCAFA ialah ia secara eksplisit mengekalkan ketekalan kedudukan dengan matriks unjuran kamera untuk mendapatkan titik rujukan. Oleh itu, DeformCAFA boleh menghasilkan penjajaran konsisten secara semantik dan kedudukan walaupun tanpa menggunakan modul CFSI yang dicadangkan dalam AutoAlign.
Berbanding dengan operasi bukan tempatan biasa, DeformCAFA gaya jarang meningkatkan kecekapan. Walau bagaimanapun, apabila ciri voxel digunakan secara langsung sebagai token untuk menjana pemberat perhatian dan ofset boleh ubah bentuk, prestasi pengesanan hampir tidak setanding dengan, atau lebih teruk daripada, interpolasi dwilinear. Selepas analisis yang teliti, terdapat masalah terjemahan pengetahuan merentas domain dalam proses penjanaan token. Tidak seperti operasi ubah bentuk asal, yang biasanya dilakukan dalam tetapan unimodal, perhatian merentas domain memerlukan maklumat daripada kedua-dua modaliti. Walau bagaimanapun, ciri voxel hanya terdiri daripada perwakilan domain spatial, dan sukar untuk melihat maklumat dalam domain imej. Oleh itu, adalah penting untuk mengurangkan interaksi antara modaliti yang berbeza.
Anggap bahawa perwakilan setiap sasaran boleh diuraikan dengan jelas kepada dua komponen: maklumat khusus domain dan maklumat khusus contoh. Yang pertama merujuk kepada data yang berkaitan dengan perwakilan itu sendiri, termasuk atribut terbina dalam ciri domain, manakala yang kedua mewakili maklumat ID tentang sasaran tanpa mengira domain mana sasaran dikodkan.
- Deep-Aware GT-AUG
Bagi kebanyakan model pembelajaran mendalam, penambahan data merupakan bahagian penting dalam mencapai keputusan yang kompetitif. Walau bagaimanapun, dari segi pengesanan objek 3D berbilang modal, apabila menggabungkan awan titik dan imej dalam penambahan data, sukar untuk mengekalkan penyegerakan antara kedua-duanya, terutamanya disebabkan oleh oklusi objek atau perubahan sudut pandang. Untuk menyelesaikan masalah ini, algoritma pembesaran data rentas modal yang mudah tetapi berkesan dinamakan GT-AUG sedar mendalam direka bentuk. Kaedah ini meninggalkan keperluan untuk proses penapisan awan titik kompleks atau anotasi topeng halus bagi domain imej. Sebaliknya, maklumat kedalaman diperkenalkan daripada anotasi objek 3D kepada kawasan imej bercampur.
Khususnya, memandangkan sasaran maya P untuk ditampal, ikuti pelaksanaan 3D GT-AUG yang sama. Bagi domain imej pula, ia disusun terlebih dahulu dari jauh ke dekat. Untuk setiap sasaran yang akan ditampal, kawasan yang sama dipotong daripada imej asal dan digabungkan pada imej sasaran dengan nisbah campuran α. Pelaksanaan terperinci ditunjukkan dalam Algoritma 1 di bawah.

Depth-aware GT-AUG mengikuti strategi pembesaran hanya dalam domain 3D, tetapi pada masa yang sama mengekalkannya melalui gabungan potong-dan-tampal Penyegerakan pesawat imej. Perkara utama ialah selepas menampal tampalan yang dipertingkatkan pada imej 2D asal, teknologi MixUp tidak akan mengalih keluar sepenuhnya maklumat yang sepadan. Sebaliknya, ia melemahkan kekompakan maklumat tersebut berbanding kedalaman untuk memastikan ciri-ciri titik yang sepadan wujud. Khususnya, jika sasaran disekat n kali oleh keadaan lain, ketelusan kawasan sasaran mereput dengan faktor (1− α)^n mengikut susunan kedalamannya.
Seperti yang ditunjukkan dalam rajah ialah beberapa contoh yang dipertingkatkan:

- Strategi latihan keciciran peringkat imej
Sebenarnya, imej biasanya merupakan pilihan input yang tidak disokong oleh semua sistem pemeriksaan 3D. Oleh itu, penyelesaian pengesanan berbilang modal yang lebih realistik dan terpakai harus menggunakan pendekatan gabungan dinamik: apabila imej tidak tersedia, model mengesan sasaran berdasarkan awan titik asal apabila imej tersedia, model melakukan gabungan ciri dan menghasilkan ramalan yang lebih baik. Untuk mencapai matlamat ini, strategi latihan keciciran peringkat imej dicadangkan untuk menggugurkan ciri imej berkelompok secara rawak pada tahap imej dan mengisinya dengan sifar semasa latihan. Seperti yang ditunjukkan dalam rajah: (a) gabungan imej; (b) gabungan keciciran peringkat imej.
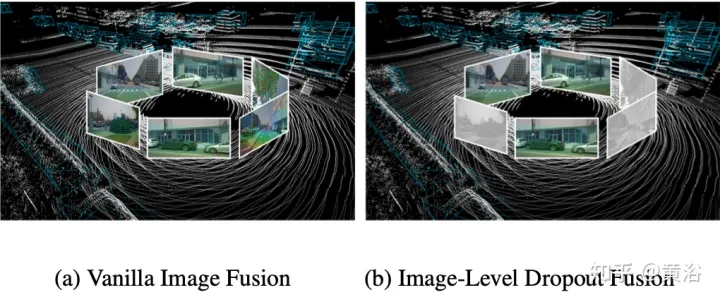
Disebabkan kehilangan maklumat imej yang sekejap-sekejap, model harus belajar secara beransur-ansur menggunakan ciri 2D sebagai input alternatif.
Hasil eksperimen

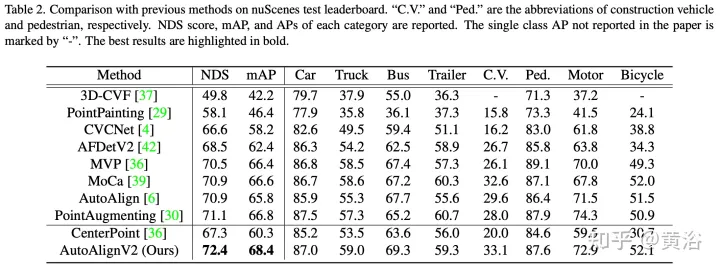


Atas ialah kandungan terperinci Kaedah pengesanan sasaran BEV gabungan pelbagai mod AutoJajarkan V1 dan V2. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI