
Rumah >pangkalan data >tutorial mysql >SERTAI operasi analisis sistematik Mysql
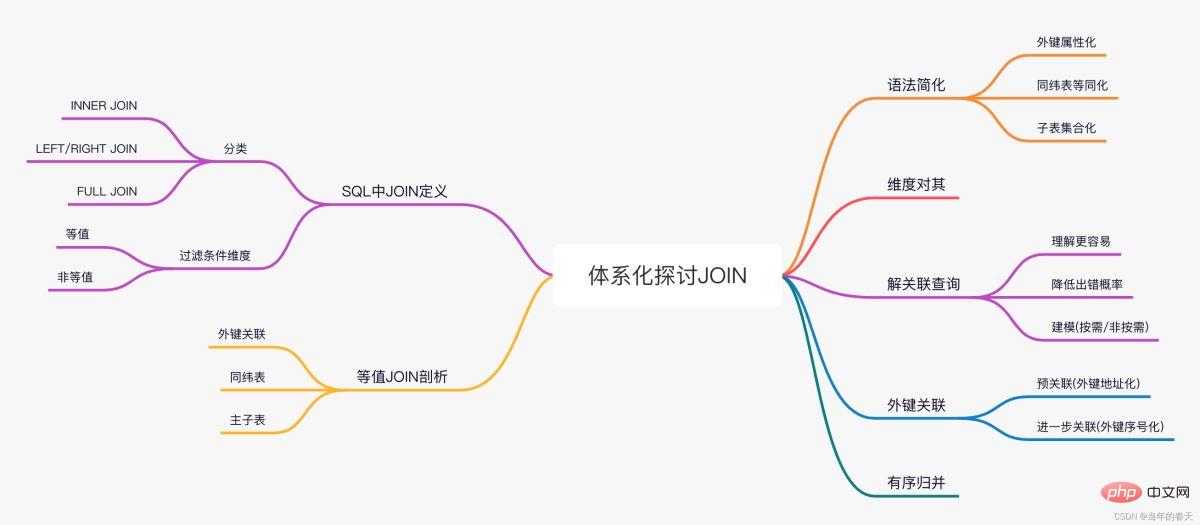
SERTAI operasi analisis sistematik Mysql

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2022-07-29 15:02:282023semak imbas
Artikel ini membawa anda pengetahuan yang berkaitan tentang mysql Ia terutamanya memperkenalkan perbincangan sistematik tentang operasi JOIN yang menyusahkan Artikel ini akan menjalankan perbincangan yang sistematik dan mendalam mengikut operasi anda sendiri Berdasarkan pengalaman kerja dan rujukan kepada kes klasik dalam industri, metodologi untuk penyederhanaan tatabahasa dan pengoptimuman prestasi dicadangkan dalam cara yang disasarkan. Saya harap ia akan membantu semua orang.

Pembelajaran yang disyorkan: tutorial video mysql
Kata Pengantar
- Pernah mengalami dari sifar hingga satu sebelum ini Terdapat juga projek permulaan dan projek data besar-besaran secara amnya, cara membina storan data yang selamat, boleh dipercayai dan stabil semasa projek itu berkembang secara beransur-ansur sentiasa menjadi bahagian teras, paling penting dan paling kritikal dalam projek, dan tiada perkara sedemikian
- Seterusnya, saya akan menulis satu siri artikel mengenai storan keluaran sistematik dalam artikel ini, kita akan bercakap tentang salah satu operasi sambungan yang paling menyusahkan dalam data—SERTAI SERTAI sentiasa menjadi masalah lama dalam SQL. Apabila terdapat sedikit lagi jadual yang berkaitan, penulisan kod menjadi sangat terdedah kepada ralat Kerana kerumitan kenyataan JOIN, pertanyaan berkaitan sentiasa menjadi kelemahan perisian BI yang membolehkan pengguna perniagaan menyelesaikan pelbagai dengan lancar -persatuan meja. Begitu juga dengan pengoptimuman prestasi Apabila terdapat banyak jadual berkaitan atau jumlah data yang banyak, adalah sukar untuk meningkatkan prestasi JOIN
- Berdasarkan perkara di atas, artikel ini akan menjalankan secara sistematik dan mendalam. perbincangan operasi JOIN, berdasarkan pengalaman kerja saya sendiri dan rujukan kes klasik dalam industri, metodologi yang dicadangkan secara khusus untuk penyederhanaan sintaks dan pengoptimuman prestasi, harap ia akan membantu semua orang
- Secara teorinya, set hasil produk Cartesian hendaklah terdiri daripada dua ahli set Walau bagaimanapun, memandangkan set dalam SQL ialah jadual, ahlinya sentiasa mempunyai rekod medan Selain itu, jenis data generik tidak disokong untuk menerangkan tupel yang ahlinya adalah rekod, jadi set hasil hanya diproses menjadi koleksi rekod baharu yang dibentuk dengan menggabungkan medan rekod dalam dua jadual.
- Ini juga merupakan makna asal perkataan JOIN dalam bahasa Inggeris (iaitu, menyambungkan medan dua rekod), dan tidak bermaksud pendaraban (produk Cartesian). Walau bagaimanapun, sama ada ahli produk Cartesian difahami sebagai tuple atau rekod medan yang digabungkan tidak menjejaskan perbincangan kami yang seterusnya.
definisi JOIN
- Definasi JOIN tidak bersetuju dengan bentuk syarat penapis, selagi set hasil adalah subset daripada produk Cartesian daripada dua set sumber, Semua adalah operasi JOIN yang munasabah.
- Contoh: Katakan set A={1,2},B={1,2,3}, hasil A JOIN B ON A
JOIN klasifikasi
- Kami memanggil kesamaan JOIN jika keadaan penapisan ialah kesamaan dan bukan kesetaraan JOIN jika keadaan penapis bukan sambungan kesetaraan. Daripada dua contoh ini, yang pertama ialah JOIN tidak setara dan yang kedua ialah JOIN yang setara.
SERTAI SAMA
- Syarat mungkin terdiri daripada berbilang persamaan dengan hubungan AND, bentuk sintaks ialah A JOIN B ON A.ai=B.bi AND…, Di mana ai dan bi ialah medan A dan B masing-masing.
- Pengaturcara yang berpengalaman tahu bahawa pada hakikatnya, sebahagian besar JOIN adalah JOIN yang setara adalah lebih jarang, dan kebanyakan kes boleh ditukar kepada JOIN yang setara, jadi Kami memfokuskan pada JOIN yang setara di sini, dan dalam. perbincangan seterusnya kita akan menggunakan jadual dan rekod dan bukannya set dan ahli sebagai contoh.
Klasifikasi di bawah peraturan pemprosesan nilai nol
- Menurut peraturan pemprosesan nilai nol, JOIN kesaksamaan ketat juga dipanggil INNER JOIN, dan juga boleh diperoleh daripada LEFT JOIN dan FULL JOIN, terdapat tiga situasi (RIGHT JOIN boleh difahami sebagai perkaitan terbalik LEFT JOIN, dan bukan lagi jenis yang berasingan).
- Apabila bercakap tentang JOIN, ia biasanya dibahagikan kepada satu-dengan-satu, satu-ke-banyak, banyak-ke-satu dan banyak-ke-banyak berdasarkan bilangan rekod yang berkaitan (iaitu, tupel yang memenuhi syarat penapisan) dalam dua jadual Dalam beberapa kes, istilah umum ini diperkenalkan dalam SQL dan bahan pangkalan data, jadi ia tidak akan diulang di sini.
Pelaksanaan JOIN
Cara bodoh
- Cara paling mudah untuk difikirkan ialah melakukan traversal yang sukar mengikut definisi, tanpa membezakan antara JOIN yang sama dan tidak sama nilai JOIN JOIN. Katakan jadual A mempunyai n rekod dan jadual B mempunyai m rekod Untuk mengira A SERTAI B PADA A.a=B.b, kerumitan traversal keras ialah nm, iaitu, masa nm pengiraan keadaan penapis akan dilakukan.
- Jelas sekali algoritma ini akan menjadi lebih perlahan. Walau bagaimanapun, alat pelaporan yang menyokong berbilang sumber data kadangkala menggunakan kaedah perlahan ini untuk mencapai perkaitan, kerana perkaitan set data dalam laporan (iaitu, syarat penapis dalam JOIN) akan dipecahkan dan ditakrifkan dalam ungkapan pengiraan sel itu tidak lagi dapat dilihat bahawa ia adalah operasi JOIN antara beberapa set data, jadi kami hanya boleh menggunakan kaedah traversal untuk mengira ungkapan berkaitan ini.
Pangkalan data dioptimumkan untuk JOIN
- Untuk JOIN yang setara, pangkalan data biasanya menggunakan algoritma HASH JOIN. Iaitu, rekod dalam jadual persatuan dibahagikan kepada beberapa kumpulan mengikut nilai HASH kunci persatuan mereka (bersamaan dengan medan yang sama dalam keadaan penapis, iaitu, A.a dan B.b), dan rekod dengan nilai HASH yang sama dikumpulkan ke dalam satu kumpulan. Jika julat nilai HASH ialah 1...k, maka kedua-dua jadual A dan B dibahagikan kepada k subset A1,...,Ak dan B1,...,Bk. Nilai HASH bagi kunci berkaitan a yang direkodkan dalam Ai ialah i, dan nilai HASH bagi kunci berkaitan b yang direkodkan dalam Bi juga ialah i. Kemudian, buat sambungan lintasan antara Ai dan Bi.
- Oleh kerana nilai medan mesti berbeza apabila HASH berbeza, apabila i!=j, rekod dalam Ai tidak boleh dikaitkan dengan rekod dalam Bj. Jika bilangan rekod Ai ialah ni dan bilangan rekod Bi ialah mi, maka bilangan pengiraan keadaan penapis ialah SUM(ni*mi Dalam kebanyakan kes purata, ni=n/k, mi=). m/k, maka jumlah Kerumitan hanya 1/k daripada kaedah traversal keras asal, yang boleh meningkatkan prestasi pengkomputeran dengan berkesan!
- Oleh itu, jika anda ingin mempercepatkan laporan korelasi sumber berbilang data, anda juga perlu melakukan korelasi dalam peringkat penyediaan data, jika tidak prestasi akan menurun secara mendadak apabila jumlah data lebih besar sedikit.
- Walau bagaimanapun, fungsi HASH tidak selalu menjamin pemisahan yang sama Jika anda tidak bernasib baik, kumpulan yang sangat besar mungkin berlaku, dan kesan peningkatan prestasi akan menjadi lebih teruk. Dan anda tidak boleh menggunakan fungsi HASH yang terlalu kompleks, jika tidak, ia akan mengambil lebih banyak masa untuk mengira HASH.
- Apabila jumlah data melebihi memori, pangkalan data akan menggunakan kaedah penimbunan HASH, yang merupakan generalisasi algoritma HASH JOIN. Lintas jadual A dan B, bahagikan rekod kepada beberapa subset kecil mengikut nilai HASH bagi kunci yang berkaitan, dan cachekannya dalam memori luaran, yang dipanggil timbunan . Kemudian lakukan operasi JOIN memori antara timbunan yang sepadan. Dengan cara yang sama, apabila nilai HASH berbeza, nilai kunci juga mestilah berbeza dan perkaitan mesti berlaku antara timbunan yang sepadan. Dengan cara ini, JOIN data besar ditukar menjadi JOIN beberapa data kecil.
- Tetapi begitu juga, fungsi HASH mempunyai masalah nasib. Mungkin berlaku timbunan tertentu terlalu besar untuk dimuatkan ke dalam ingatan Pada masa ini, mungkin perlu melakukan timbunan HASH kedua ialah, tukar kepada fungsi HASH Lakukan semula algoritma timbunan HASH pada kumpulan timbunan yang terlalu besar ini. Oleh itu, operasi JOIN memori luaran mungkin dicache beberapa kali, dan prestasi operasinya agak tidak terkawal.
SERTAI dalam sistem yang diedarkan
- SERTAI dalam sistem yang diedarkan adalah serupa Rekod diedarkan kepada setiap mesin nod berdasarkan nilai HASH bagi kunci yang berkaitan, iaitu dipanggil Tindakan Kocok, dan kemudian lakukan JOIN bersendirian secara berasingan.
- Apabila terdapat banyak nod, kelewatan yang disebabkan oleh volum penghantaran rangkaian akan mengimbangi faedah perkongsian tugas berbilang mesin, jadi sistem pangkalan data yang diedarkan biasanya mempunyai had pada bilangan nod Selepas mencapai had, lebih Banyak nod tidak menghasilkan prestasi yang lebih baik.
Anatomi yang setara JOIN
Tiga jenis JOIN yang setara:
Persatuan kunci asing
- Medan jadual tertentu A It dikaitkan dengan medan kunci utama jadual B (perkaitan medan yang dipanggil bermakna medan yang sama mesti sepadan dengan syarat penapis JOIN yang sama seperti yang dinyatakan dalam bahagian sebelumnya). Jadual A dipanggil jadual fakta dan jadual B dipanggil jadual dimensi . Medan dalam jadual A yang dikaitkan dengan kunci utama jadual B dipanggil kunci asing A yang menunjuk ke B, dan B juga dipanggil jadual kunci asing A.
- Kunci primer yang disebut di sini merujuk kepada kunci primer logik, iaitu medan (kumpulan) dengan nilai unik dalam jadual yang boleh digunakan untuk merekod rekod tertentu secara unik tidak semestinya perlu diwujudkan pada jadual pangkalan data.
- Jadual kunci asing mempunyai hubungan banyak dengan satu, dan hanya JOIN dan LEFT JOIN, dan FULL JOIN sangat jarang berlaku.
- Kes biasa: jadual transaksi produk dan jadual maklumat produk.
- Jelas sekali, persatuan utama asing adalah tidak simetri. Lokasi jadual fakta dan jadual dimensi tidak boleh ditukar ganti.
Jadual dimensi yang sama
- Kunci utama jadual A berkaitan dengan kunci utama jadual B. A dan B dipanggil antara satu sama lain Jadual dimensi yang sama . Jadual dengan dimensi yang sama mempunyai hubungan satu dengan satu, dan JOIN, LEFT JOIN dan FULL JOIN semuanya akan wujud Walau bagaimanapun, dalam kebanyakan penyelesaian reka bentuk struktur data, FULL JOIN agak jarang berlaku.
- Kes biasa: meja pekerja dan meja pengurus.
- Jadual dengan dimensi yang sama adalah simetri dan kedua-dua jadual mempunyai status yang sama. Jadual dengan dimensi yang sama juga membentuk hubungan kesetaraan A dan B adalah jadual dengan dimensi yang sama, dan B dan C adalah jadual dengan dimensi yang sama.
Jadual induk dan anak
- Kunci utama jadual A berkaitan dengan beberapa kunci utama jadual B. A dipanggil jadual utama, dan B dipanggil Subjadual . Jadual anak induk mempunyai hubungan satu-dengan-banyak. Hanya ada JOIN dan LEFT JOIN, tetapi tidak akan ada FULL JOIN.
- Kes biasa: pesanan dan butiran pesanan.
- Jadual utama dan sub-jadual juga tidak simetri dan mempunyai arah yang jelas.
- Dalam sistem konseptual SQL, tiada perbezaan antara jadual kunci asing dan jadual anak-anak Dari sudut SQL, banyak-ke-satu dan satu-ke-banyak hanya mempunyai arah perkaitan yang berbeza dan pada asasnya adalah perkara yang sama. Malah, pesanan juga boleh difahami sebagai jadual kunci asing bagi butiran pesanan. Walau bagaimanapun, kami ingin membezakannya di sini, dan cara yang berbeza akan digunakan apabila memudahkan sintaks dan mengoptimumkan prestasi pada masa hadapan.
- Kami mengatakan bahawa ketiga-tiga jenis JOIN ini telah merangkumi sebahagian besar situasi JOIN yang setara, malah boleh dikatakan bahawa hampir semua JOIN yang setara dengan kepentingan perniagaan tergolong dalam tiga kategori JOIN yang setara ini ketiga-tiga situasi, skop penyesuaian mereka hampir tidak dikurangkan.
- Melihat dengan teliti ketiga-tiga JOIN ini, kami mendapati bahawa semua persatuan melibatkan kunci utama, dan tidak ada situasi banyak-ke-banyak Bolehkah keadaan ini diabaikan?
- Ya! JOIN setara banyak-ke-banyak hampir tiada makna perniagaan.
- Jika medan yang berkaitan semasa mencantumkan dua jadual tidak melibatkan sebarang kunci utama, situasi banyak-ke-banyak akan berlaku, dan dalam kes ini hampir pasti terdapat jadual yang lebih besar yang menggabungkan kedua-dua jadual ini adalah berkaitan sebagai jadual dimensi. Sebagai contoh, apabila jadual pelajar dan jadual subjek berada dalam JOIN, akan ada jadual gred yang menggunakan jadual pelajar dan jadual subjek sebagai jadual dimensi A JOIN dengan hanya jadual pelajar dan jadual subjek tidak mempunyai kepentingan perniagaan.
- Apabila anda menemui situasi banyak-ke-banyak semasa menulis pernyataan SQL, terdapat kebarangkalian tinggi bahawa pernyataan itu ditulis dengan salah! Atau ada masalah dengan data! Peraturan ini sangat berkesan untuk menghapuskan ralat JOIN.
- Walau bagaimanapun, kami telah mengatakan "hampir" tanpa menggunakan pernyataan yang benar-benar pasti, iaitu, ramai-ke-banyak juga akan masuk akal perniagaan dalam kes yang sangat jarang berlaku. Sebagai contoh, apabila menggunakan SQL untuk melaksanakan pendaraban matriks, JOIN setara banyak-ke-banyak akan berlaku Kaedah penulisan khusus boleh ditambah oleh pembaca.
- Takrifan SERTAI produk Cartesian dan kemudian penapisan sememangnya sangat mudah, dan konotasi mudah akan mempunyai sambungan yang lebih besar, dan boleh termasuk SERTAI banyak-ke-banyak yang setara dan juga SERTAI yang tidak setara. Walau bagaimanapun, konotasi yang terlalu mudah tidak dapat mencerminkan sepenuhnya ciri-ciri operasi JOIN setara yang paling biasa. Ini akan mengakibatkan ketidakupayaan untuk memanfaatkan ciri ini semasa menulis kod dan melaksanakan operasi Apabila operasi lebih kompleks (melibatkan banyak jadual yang berkaitan dan situasi bersarang), adalah sangat sukar untuk menulis atau mengoptimumkan. Dengan menggunakan sepenuhnya ciri ini, kami boleh mencipta borang penulisan yang lebih ringkas dan memperoleh prestasi pengkomputeran yang lebih cekap, yang akan diterangkan secara beransur-ansur dalam kandungan berikut.
- Daripada mentakrifkan operasi dalam bentuk yang lebih umum untuk memasukkan kes yang jarang berlaku, adalah lebih munasabah untuk mentakrifkan kes ini sebagai operasi lain.
SERTAI pemudahan sintaks
Bagaimana untuk menggunakan ciri yang mengaitkan kekunci utama untuk memudahkan penulisan kod JOIN? Contoh
Atribut kunci asing
, dengan dua jadual berikut:
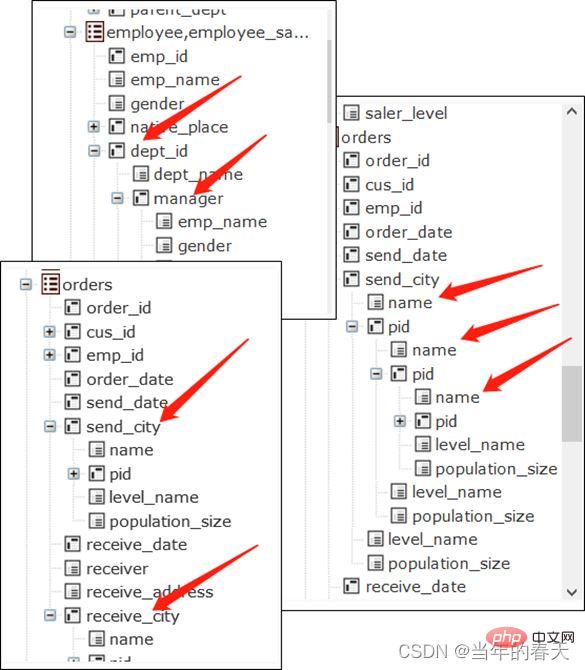
employee 员工表
id 员工编号
name 姓名
nationality 国籍
department 所属部门
department 部门表
id 部门编号
name 部门名称
manager 部门经理- Kunci utama jadual pekerja dan jadual jabatan ialah kedua-dua medan id Medan jabatan bagi jadual pekerja ialah kunci asing yang menunjuk ke meja jabatan dan medan pengurus bagi jadual jabatan ialah kunci asing yang menunjuk ke meja pekerja ( Kerana pengurus juga seorang pekerja). Ini adalah reka bentuk struktur meja yang sangat konvensional.
- Sekarang kami ingin bertanya: Pekerja Amerika manakah yang mempunyai pengurus Cina? Ditulis dalam SQL, ia adalah penyataan JOIN tiga jadual:
SELECT A.* FROM employee A JOIN department B ON A.department=B.id JOIN employee C ON B.manager=C.id WHERE A.nationality='USA' AND C.nationality='CHN'
- Pertama, FROM pekerja digunakan untuk mendapatkan maklumat pekerja, dan kemudian jadual pekerja digabungkan dengan jabatan untuk mendapatkan maklumat jabatan pekerja , dan kemudian jadual jabatan perlu DISERTAI dengan jadual pekerja untuk mendapatkan maklumat pengurus Dengan cara ini, jadual pekerja perlu menyertai JOIN dua kali membezakannya, dan keseluruhan ayat menjadi lebih rumit dan sukar untuk difahami.
- Jika kita memahami secara langsung medan kunci asing sebagai rekod jadual dimensi yang berkaitan, kita boleh menulisnya dengan cara lain:
SELECT * FROM employee WHERE nationality='USA' AND department.manager.nationality='CHN'
Sudah tentu, ini bukan pernyataan SQL standard .
- Bahagian tebal dalam ayat kedua menunjukkan "kewarganegaraan pengurus jabatan" pekerja semasa. Selepas kita memahami medan kunci asing sebagai rekod jadual dimensi, medan jadual dimensi difahami sebagai atribut jabatan kunci asing. pengurus ialah "pengurus jabatan", dan medan ini masih asing kunci dalam jabatan, maka ia Medan rekod jadual dimensi yang sepadan boleh terus difahami sebagai atributnya, dan terdapat juga jabatan.pengurus.kewarganegaraan, iaitu, "kewarganegaraan pengurus jabatan tempat dia berada".
- Atribusi kunci asing: Cara pemahaman seperti objek ini ialah atribusi kunci asing, yang jelas lebih semula jadi dan intuitif daripada cara pemahaman penapisan produk Cartesian. SERTAI jadual kunci asing tidak melibatkan pendaraban kedua-dua jadual Medan kunci asing hanya digunakan untuk mencari rekod yang sepadan dalam jadual kunci dimensi, dan tidak melibatkan operasi dengan ciri pendaraban seperti hasil Cartesan.
- Kami bersetuju sebelum ini bahawa kunci yang berkaitan dalam jadual dimensi kunci asing mestilah kunci utama Dengan cara ini, rekod jadual dimensi yang dikaitkan dengan medan kunci asing bagi setiap rekod dalam jadual fakta adalah unik maksudnya, dalam jadual pekerja Medan jabatan setiap rekod dikaitkan secara unik dengan rekod dalam jadual jabatan, dan medan pengurus setiap rekod dalam jadual jabatan juga dikaitkan secara unik dengan rekod dalam jadual pekerja. Ini memastikan bahawa untuk setiap rekod dalam jadual pekerja, department.manager.nationality mempunyai nilai unik dan boleh ditakrifkan dengan jelas.
- Walau bagaimanapun, tiada perjanjian kunci utama dalam definisi SQL JOIN Jika ia berdasarkan peraturan SQL, ia tidak dapat ditentukan bahawa rekod jadual dimensi yang dikaitkan dengan kunci asing dalam jadual fakta adalah unik. dan berbilang rekod boleh berlaku Persatuan, untuk rekod dalam jadual pekerja, jabatan.pengurus.kewarganegaraan tidak boleh digunakan jika ia tidak ditakrifkan dengan jelas.
- Malah, penulisan berasaskan objek seperti ini sangat biasa dalam bahasa peringkat tinggi (seperti C, Java Dalam bahasa sedemikian, data disimpan dalam mod objek). Nilai medan jabatan dalam jadual pekerja hanyalah objek, bukan nombor. Malah, nilai kunci utama banyak jadual itu sendiri tidak mempunyai kepentingan perniagaan Ia hanya untuk membezakan rekod, dan medan kunci asing hanyalah untuk mencari rekod yang sepadan dalam jadual dimensi Jika medan kunci asing secara langsung adalah objek. tidak perlu menggunakan penomboran. Walau bagaimanapun, SQL tidak dapat menyokong mekanisme storan ini dan memerlukan bantuan nombor.
- Kami telah mengatakan bahawa perkaitan kunci asing adalah tidak simetri, iaitu jadual fakta dan jadual dimensi tidak sama, dan medan jadual dimensi hanya boleh didapati berdasarkan jadual fakta, dan bukan yang lain. jalan sekitar.
Penyamaan jadual dengan dimensi yang sama
Situasi jadual dengan dimensi yang sama agak mudah Mari kita mulakan dengan contoh >
employee 员工表
id 员工编号
name 姓名
salary 工资
...
manager 经理表
id 员工编号
allowance 岗位津贴
....Kunci utama kedua-dua jadual ialah id, dan pengurus juga merupakan pekerja Kedua-dua jadual tersebut berkongsi nombor pekerja yang sama Pengurus akan mempunyai lebih banyak atribut daripada pekerja biasa dan jadual pengurus lain akan digunakan untuk menyimpannya. - Sekarang kami ingin mengira jumlah pendapatan (tambah elaun) semua pekerja (termasuk pengurus). JOIN masih akan digunakan semasa menulis dalam SQL:
SELECT employee.id, employee.name, employy.salary+manager.allowance FROM employee LEFT JOIN manager ON employee.id=manager.id
SELECT id,name,salary+allowance FROM employeeBegitu juga, mengikut perjanjian kami, apabila jadual dimensi yang sama adalah JOIN, kedua-dua jadual dikaitkan dengan kunci utama, rekod yang sepadan adalah sepadan secara unik, dan elaun gaji dikira secara unik untuk setiap rekod dalam jadual pekerja. , tidak akan ada kekaburan. Penyederhanaan ini dipanggil
- penyamaan jadual sama dimensi
- . Hubungan antara jadual dimensi yang sama adalah sama dan medan jadual lain dengan dimensi yang sama boleh dirujuk dari mana-mana jadual.
- Koleksi subjadual
Pesanan & butiran pesanan ialah subjadual induk biasa:
Kunci utama jadual Pesanan ialah id dan kunci utama daripada jadual OrderDetail ialah (id,no), kunci utama yang pertama adalah sebahagian daripada yang terakhir.Orders 订单表
id 订单编号
customer 客户
date 日期
...
OrderDetail 订单明细
id 订单编号
no 序号
product 订购产品
price 价格
...Sekarang kami ingin mengira jumlah keseluruhan setiap pesanan. Ditulis dalam SQL ia akan kelihatan seperti ini:
SELECT Orders.id, Orders.customer, SUM(OrderDetail.price) FROM Orders JOIN OrderDetail ON Orders.id=OrderDetail.id GROUP BY Orders.id, Orders.customer
- 要完成这个运算,不仅要用到JOIN,还需要做一次GROUP BY,否则选出来的记录数太多。
- 如果我们把子表中与主表相关的记录看成主表的一个字段,那么这个问题也可以不再使用JOIN以及GROUP BY:
SELECT id, customer, OrderDetail.SUM(price) FROM Orders
- 与普通字段不同,OrderDetail被看成Orders表的字段时,其取值将是一个集合,因为两个表是一对多的关系。所以要在这里使用聚合运算把集合值计算成单值。这种简化方式称为子表集合化。
- 这样看待主子表关联,不仅理解书写更为简单,而且不容易出错。
- 假如Orders表还有一个子表用于记录回款情况:
OrderPayment 订单回款表
id 订单编号
date 回款日期
amount 回款金额
....- 我们现在想知道那些订单还在欠钱,也就是累计回款金额小于订单总金额的订单。
- 简单地把这三个表JOIN起来是不对的,OrderDetail和OrderPayment会发生多对多的关系,这就错了(回忆前面提过的多对多大概率错误的说法)。这两个子表要分别先做GROUP,再一起与Orders表JOIN起来才能得到正确结果,会写成子查询的形式:
SELECT Orders.id, Orders.customer,A.x,B.y
FROM Orders
LEFT JOIN ( SELECT id,SUM(price) x FROM OrderDetail GROUP BY id ) A
ON Orders.id=A.id
LEFT JOIN ( SELECT id,SUM(amount) y FROM OrderPayment GROUP BY id ) B
ON Orders.id=B.id
WHERE A.x>B.y如果我们继续把子表看成主表的集合字段,那就很简单了:
SELECT id,customer,OrderDetail.SUM(price) x,OrderPayment.SUM(amount) y FROM Orders WHERE x>y
- 这种写法也不容易发生多对多的错误。
- 主子表关系是不对等的,不过两个方向的引用都有意义,上面谈了从主表引用子表的情况,从子表引用主表则和外键表类似。
- 我们改变对JOIN运算的看法,摒弃笛卡尔积的思路,把多表关联运算看成是稍复杂些的单表运算。这样,相当于把最常见的等值JOIN运算的关联消除了,甚至在语法中取消了JOIN关键字,书写和理解都要简单很多。
维度对齐语法
我们再回顾前面的双子表例子的SQL:
SELECT Orders.id, Orders.customer, A.x, B.y
FROM Orders
LEFT JOIN (SELECT id,SUM(price) x FROM OrderDetail GROUP BY id ) A
ON Orders.id=A.id
LEFT JOIN (SELECT id,SUM(amount) y FROM OrderPayment GROUP BY id ) B
ON Orders.id=B.id
WHERE A.x > B.y- 那么问题来了,这显然是个有业务意义的JOIN,它算是前面所说的哪一类呢?
- 这个JOIN涉及了表Orders和子查询A与B,仔细观察会发现,子查询带有GROUP BY id的子句,显然,其结果集将以id为主键。这样,JOIN涉及的三个表(子查询也算作是个临时表)的主键是相同的,它们是一对一的同维表,仍然在前述的范围内。
- 但是,这个同维表JOIN却不能用前面说的写法简化,子查询A,B都不能省略不写。
- 可以简化书写的原因:我们假定事先知道数据结构中这些表之间的关联关系。用技术术语的说法,就是知道数据库的元数据(metadata)。而对于临时产生的子查询,显然不可能事先定义在元数据中了,这时候就必须明确指定要JOIN的表(子查询)。
- 不过,虽然JOIN的表(子查询)不能省略,但关联字段总是主键。子查询的主键总是由GROUP BY产生,而GROUP BY的字段一定要被选出用于做外层JOIN;并且这几个子查询涉及的子表是互相独立的,它们之间不会再有关联计算了,我们就可以把GROUP动作以及聚合式直接放到主句中,从而消除一层子查询:
SELECT Orders.id, Orders.customer, OrderDetail.SUM(price) x, OrderParyment.SUM(amount) y FROM Orders LEFT JOIN OrderDetail GROUP BY id LEFT JOIN OrderPayment GROUP BY id WHERE A.x > B.y
- 这里的JOIN和SQL定义的JOIN运算已经差别很大,完全没有笛卡尔积的意思了。而且,也不同于SQL的JOIN运算将定义在任何两个表之间,这里的JOIN,OrderDetail和OrderPayment以及Orders都是向一个共同的主键id对齐,即所有表都向某一套基准维度对齐。而由于各表的维度(主键)不同,对齐时可能会有GROUP BY,在引用该表字段时就会相应地出现聚合运算。OrderDetail和OrderPayment甚至Orders之间都不直接发生关联,在书写运算时当然就不用关心它们之间的关系,甚至不必关心另一个表是否存在。而SQL那种笛卡尔积式的JOIN则总要找一个甚至多个表来定义关联,一旦减少或修改表时就要同时考虑关联表,增大理解难度。
- 维度对齐:这种JOIN称即为维度对齐,它并不超出我们前面说过的三种JOIN范围,但确实在语法描述上会有不同,这里的JOIN不象SQL中是个动词,却更象个连词。而且,和前面三种基本JOIN中不会或很少发生FULL JOIN的情况不同,维度对齐的场景下FULL JOIN并不是很罕见的情况。
- 虽然我们从主子表的例子抽象出维度对齐,但这种JOIN并不要求JOIN的表是主子表(事实上从前面的语法可知,主子表运算还不用写这么麻烦),任何多个表都可以这么关联,而且关联字段也完全不必要是主键或主键的部分。
- 设有合同表,回款表和发票表:
Contract 合同表
id 合同编号
date 签订日期
customer 客户
price 合同金额
...
Payment 回款表
seq 回款序号
date 回款日期
source 回款来源
amount 金额
...
Invoice 发票表
code 发票编号
date 开票日期
customer 客户
amount 开票金额
...现在想统计每一天的合同额、回款额以及发票额,就可以写成:
SELECT Contract.SUM(price), Payment.SUM(amount), Invoice.SUM(amount) ON date FROM Contract GROUP BY date FULL JOIN Payment GROUP BY date FULL JOIN Invoice GROUP BY date
- 这里需要把date在SELECT后单独列出来表示结果集按日期对齐。
- 这种写法,不必关心这三个表之间的关联关系,各自写各自有关的部分就行,似乎这几个表就没有关联关系,把它们连到一起的就是那个要共同对齐的维度(这里是date)。
- 这几种JOIN情况还可能混合出现。
- 继续举例,延用上面的合同表,再有客户表和销售员表
Customer 客户表
id 客户编号
name 客户名称
area 所在地区
...
Sales 销售员表
id 员工编号
name 姓名
area 负责地区
...- 其中Contract表中customer字段是指向Customer表的外键。
- 现在我们想统计每个地区的销售员数量及合同额:
SELECT Sales.COUNT(1), Contract.SUM(price) ON area FROM Sales GROUP BY area FULL JOIN Contract GROUP BY customer.area
- 维度对齐可以和外键属性化的写法配合合作。
- 这些例子中,最终的JOIN都是同维表。事实上,维度对齐还有主子表对齐的情况,不过相对罕见,我们这里就不深入讨论了。
- 另外,目前这些简化语法仍然是示意性,需要在严格定义维度概念之后才能相应地形式化,成为可以解释执行的句子。
- 我们把这种简化的语法称为DQL(Dimensional Query Languange),DQL是以维度为核心的查询语言。我们已经将DQL在工程上做了实现,并作为润乾报表的DQL服务器发布出来,它能将DQL语句翻译成SQL语句执行,也就是可以在任何关系数据库上运行。
- 对DQL理论和应用感兴趣的读者可以关注乾学院上发布的论文和相关文章。
解决关联查询
多表JOIN问题
- 我们知道,SQL允许用WHERE来写JOIN运算的过滤条件(回顾原始的笛卡尔积式的定义),很多程序员也习惯于这么写。
- 当JOIN表只有两三个的时候,那问题还不大,但如果JOIN表有七八个甚至十几个的时候,漏写一个JOIN条件是很有可能的。而漏写了JOIN条件意味着将发生多对多的完全叉乘,而这个SQL却可以正常执行,会有以下两点危害:
- 一方面计算结果会出错:回忆一下以前说过的,发生多对多JOIN时,大概率是语句写错了
- 另一方面,如果漏写条件的表很大,笛卡尔积的规模将是平方级的,这极有可能把数据库直接“跑死”!
简化JOIN运算好处:
- 一个直接的效果显然是让语句书写和理解更容易
- 外键属性化、同维表等同化和子表集合化方案直接消除了显式的关联运算,也更符合自然思维
- 维度对齐则可让程序员不再关心表间关系,降低语句的复杂度
- 简化JOIN语法的好处不仅在于此,还能够降低出错率,采用简化后的JOIN语法,就不可能发生漏写JOIN条件的情况了。因为对JOIN的理解不再是以笛卡尔积为基础,而且设计这些语法时已经假定了多对多关联没有业务意义,这个规则下写不出完全叉乘的运算。
- 对于多个子表分组后与主表对齐的运算,在SQL中要写成多个子查询的形式。但如果只有一个子表时,可以先JOIN再GROUP,这时不需要子查询。有些程序员没有仔细分析,会把这种写法推广到多个子表的情况,也先JOIN再GROUP,可以避免使用子查询,但计算结果是错误的。
- 使用维度对齐的写法就不容易发生这种错误了,无论多少个子表,都不需要子查询,一个子表和多个子表的写法完全相同。
关联查询
- 重新看待JOIN运算,最关键的作用在于实现关联查询。
- 当前BI产品是个热门,各家产品都宣称能够让业务人员拖拖拽拽就完成想要的查询报表。但实际应用效果会远不如人意,业务人员仍然要经常求助于IT部门。造成这个现象的主要原因在于大多数业务查询都是有过程的计算,本来也不可能拖拽完成。但是,也有一部分业务查询并不涉及多步过程,而业务人员仍然难以完成。
- 这就是关联查询,也是大多数BI产品的软肋。在之前的文章中已经讲过为什么关联查询很难做,其根本原因就在于SQL对JOIN的定义过于简单。
- 结果,BI产品的工作模式就变成先由技术人员构建模型,再由业务人员基于模型进行查询。而所谓建模,就是生成一个逻辑上或物理上的宽表。也就是说,建模要针对不同的关联需求分别实现,我们称之为按需建模,这时候的BI也就失去敏捷性了。
- 但是,如果我们改变了对JOIN运算的看法,关联查询可以从根本上得到解决。回忆前面讲过的三种JOIN及其简化手段,我们事实上把这几种情况的多表关联都转化成了单表查询,而业务用户对于单表查询并没有理解障碍。无非就是表的属性(字段)稍复杂了一些:可能有子属性(外键字段指向的维表并引用其字段),子属性可能还有子属性(多层的维表),有些字段取值是集合而非单值(子表看作为主表的字段)。发生互相关联甚至自我关联也不会影响理解(前面的中国经理的美国员工例子就是互关联),同表有相同维度当然更不碍事(各自有各自的子属性)。
- 在这种关联机制下,技术人员只要一次性把数据结构(元数据)定义好,在合适的界面下(把表的字段列成有层次的树状而不是常规的线状),就可以由业务人员自己实现JOIN运算,不再需要技术人员的参与。数据建模只发生于数据结构改变的时刻,而不需要为新的关联需求建模,这也就是非按需建模,在这种机制支持下的BI才能拥有足够的敏捷性。
外键预关联
- 我们再来研究如何利用JOIN的特征实现性能优化,这些内容的细节较多,我们挑一些易于理解的情况来举例,更完善的连接提速算法可以参考乾学院上的《性能优化》图书和SPL学习资料中的性能优化专题文章。
全内存下外键关联情况
设有两个表:
customer 客户信息表
key 编号
name 名称
city 城市
...
orders 订单表
seq 序号
date 日期
custkey 客户编号
amount 金额
...- 其中orders表中的custkey是指向customer表中key字段的外键,key是customer表的主键。
- 现在我们各个城市的订单总额(为简化讨论,就不再设定条件了),用SQL写出来:
SELECT customer.city, SUM(orders.amount) FROM orders JOIN customer ON orders.custkey=customer.key GROUP BY customer.city
- 数据库一般会使用HASH JOIN算法,需要分别两个表中关联键的HASH值并比对。
- 我们用前述的简化的JOIN语法(DQL)写出这个运算:
SELECT custkey.city, SUM(amount) FROM orders GROUP BY custkey.city
- 这个写法其实也就预示了它还可以有更好的优化方案,下面来看看怎样实现。
- 如果所有数据都能够装入内存,我们可以实现外键地址化。
- 将事实表orders中的外键字段custkey,转换成维表customer中关联记录的地址,即orders表的custkey的取值已经是某个customer表中的记录,那么就可以直接引用记录的字段进行计算了。
- 用SQL无法描述这个运算的细节过程,我们使用SPL来描述、并用文件作为数据源来说明计算过程:
| A | |
|---|---|
| 1 | =file(“customer.btx”).import@b() |
| 2 | >A1.keys@i(key) |
| 3 | =file(“orders.btx”).import@b() |
| 4 | >A3.switch(custkey,A1) |
| 5 | =A3.groups(custkey.city;sum(amount)) |
- A1 membaca jadual pelanggan, dan A2 menetapkan kunci utama dan mencipta indeks untuk jadual pelanggan.
- A3 membaca jadual pesanan, dan tindakan A4 adalah untuk menukar kustkey medan kunci asing A3 ke dalam rekod sepadan A1 Selepas pelaksanaan, kustkey medan jadual pesanan akan menjadi rekod jadual pelanggan. A2 membina indeks untuk menjadikan suis lebih pantas, kerana jadual fakta biasanya jauh lebih besar daripada jadual dimensi, dan indeks ini boleh digunakan semula berkali-kali.
- A5 boleh melakukan ringkasan kumpulan Apabila melintasi jadual pesanan, memandangkan nilai medan kunci cust kini menjadi rekod, anda boleh terus menggunakan operator .
- Selepas melengkapkan tindakan suis dalam A4, kandungan yang disimpan dalam medan kunci cust jadual fakta A3 dalam ingatan sudah pun menjadi alamat rekod dalam jadual dimensi A1 Tindakan ini dipanggil pengalamatan kunci asing. Pada masa ini, apabila merujuk medan jadual dimensi, ia boleh diambil secara langsung tanpa menggunakan nilai kunci asing untuk mencari dalam A1 Ini adalah bersamaan dengan mendapatkan medan jadual dimensi dalam masa yang tetap, mengelakkan pengiraan dan perbandingan nilai HASH.
- Walau bagaimanapun, A2 secara amnya menggunakan kaedah HASH untuk membina indeks kunci utama dan mengira nilai HASH untuk kunci Apabila A4 menukar alamat, ia juga mengira nilai HASH kunci cust dan membandingkannya dengan HASH. jadual indeks A2. Jika hanya satu operasi korelasi dilakukan, amaun pengiraan skim alamat dan skim pembahagian HASH tradisional pada asasnya adalah sama, dan tiada kelebihan asas.
- Tetapi perbezaannya ialah jika data boleh diletakkan di dalam memori, alamat ini boleh digunakan semula setelah ditukar dengan kata lain, A1 ke A4 hanya perlu dilakukan sekali, dan operasi yang berkaitan pada kedua-dua ini medan akan dilakukan pada masa akan datang. Tidak perlu mengira nilai HASH dan membandingkannya, dan prestasi boleh dipertingkatkan.
- boleh melakukan ini dengan mengambil kesempatan daripada keunikan perkaitan kunci asing yang dinyatakan sebelum ini dalam jadual dimensi Nilai medan kunci asing hanya akan sepadan secara unik dengan rekod jadual satu dimensi Setiap kekunci cust boleh ditukar kepada hanya rekod A1 yang sepadan dengannya. Walau bagaimanapun, jika kami terus menggunakan definisi JOIN dalam SQL, kami tidak boleh menganggap bahawa kunci asing menunjukkan keunikan rekod, dan perwakilan ini tidak boleh digunakan. Selain itu, SQL tidak merekodkan jenis data alamat Akibatnya, nilai HASH mesti dikira dan dibandingkan untuk setiap persatuan.
- Selain itu, jika terdapat berbilang kunci asing dalam jadual fakta yang menunjuk kepada jadual berbilang dimensi, penyelesaian HASH segmented JOIN tradisional hanya boleh menghuraikan satu demi satu Jika terdapat berbilang JOIN, berbilang tindakan mesti dilakukan. Selepas setiap perkaitan, keputusan perantaraan perlu disimpan untuk pusingan penggunaan seterusnya Proses pengiraan adalah lebih rumit dan data akan dilalui beberapa kali. Apabila menghadapi berbilang kunci asing, skim pengalamatan kunci asing hanya perlu merentasi jadual fakta sekali sahaja, tanpa hasil perantaraan, dan proses pengiraan adalah lebih jelas.
- Satu lagi perkara ialah ingatan pada asalnya sangat sesuai untuk pengkomputeran selari, tetapi algoritma HASH segmented JOIN tidak mudah untuk disejajarkan. Walaupun data dibahagikan dan nilai HASH dikira secara selari, rekod dengan nilai HASH yang sama mesti dikumpulkan bersama untuk pusingan perbandingan seterusnya, dan preemption sumber dikongsi akan berlaku, yang akan mengorbankan banyak kelebihan pengkomputeran selari. Di bawah model JOIN kunci asing, status kedua-dua jadual berkaitan adalah tidak sama Selepas membezakan jadual dimensi dan jadual fakta dengan jelas, pengiraan selari boleh dilakukan dengan hanya membahagikan jadual fakta.
- Selepas mengubah teknologi pembahagian HASH dengan merujuk kepada skema atribut kunci asing, ia juga boleh meningkatkan keupayaan parsing dan selari sekali bagi beberapa kunci asing ke tahap tertentu Sesetengah pangkalan data boleh melaksanakan pengoptimuman ini di peringkat kejuruteraan. Walau bagaimanapun, pengoptimuman ini bukanlah masalah besar apabila hanya terdapat dua jadual JOIN Apabila terdapat banyak jadual dan pelbagai JOIN bercampur, tidak mudah bagi pangkalan data untuk mengenal pasti jadual mana yang harus digunakan sebagai jadual fakta untuk traversal selari. dan jadual lain harus dilalui secara selari Apabila mencipta indeks HASH sebagai jadual dimensi, pengoptimuman tidak selalu berkesan. Oleh itu, kita sering mendapati bahawa apabila bilangan jadual JOIN meningkat, prestasi akan menurun secara mendadak (ia sering berlaku apabila terdapat empat atau lima jadual, dan set keputusan tidak meningkat dengan ketara). Selepas konsep kunci asing diperkenalkan daripada model JOIN, apabila JOIN jenis ini diproses secara khusus, jadual fakta dan jadual dimensi sentiasa boleh dibezakan Lebih banyak jadual JOIN hanya akan membawa kepada penurunan linear dalam prestasi.
- Pangkalan data dalam memori pada masa ini merupakan teknologi yang hangat, tetapi analisis di atas menunjukkan bahawa pangkalan data dalam memori yang menggunakan model SQL sukar untuk melaksanakan operasi JOIN dengan cepat!
Persatuan kunci asing lanjut
- Kami terus membincangkan SERTAI kunci asing dan terus menggunakan contoh dari bahagian sebelumnya.
- Apabila jumlah data terlalu besar untuk dimuatkan ke dalam memori, kaedah pengalamatan yang disebutkan di atas tidak lagi berkesan, kerana alamat yang diprakira tidak boleh disimpan dalam memori luaran.
- Secara umumnya, jadual dimensi yang ditunjuk oleh kunci asing mempunyai kapasiti yang lebih kecil, manakala jadual fakta yang semakin meningkat adalah lebih besar. Jika memori masih boleh memegang jadual dimensi, kita boleh menggunakan kaedah penunjuk sementara untuk mengendalikan kunci asing.
| A | |
|---|---|
| 1 | =file(“customer.btx”).import@b() |
| 2 | =file(“orders.btx”).cursor@b() |
| 3 | >A2.switch(custkey,A1:#) |
| 4 | =A2.groups(custkey.city;sum(amount)) |
- Dua langkah pertama adalah sama seperti dalam memori penuh Penukaran alamat dalam langkah 4 dilakukan semasa membaca, dan hasil penukaran tidak boleh dikekalkan dan digunakan semula HASH dan nisbah mesti dikira sekali lagi masa persatuan dibuat Ya, prestasinya lebih teruk daripada penyelesaian memori penuh. Dari segi jumlah pengiraan, berbanding dengan algoritma HASH JOIN, terdapat satu pengiraan yang kurang bagi nilai HASH jadual dimensi Jika jadual dimensi ini sering digunakan semula, ia akan menjadi agak berfaedah, tetapi kerana jadual dimensi agak kecil. kelebihan keseluruhannya tidaklah hebat. Walau bagaimanapun, algoritma ini juga mempunyai ciri-ciri algoritma memori penuh yang boleh menghuraikan semua kunci asing sekaligus dan mudah untuk diselaraskan Dalam senario sebenar, ia masih mempunyai kelebihan prestasi yang lebih besar daripada algoritma HASH JOIN.
Siri kunci asing
Berdasarkan algoritma ini, kami juga boleh membuat varian: siri kunci asing.
Jika kita boleh menukar kekunci utama jadual dimensi kepada nombor asli bermula daripada 1, maka kita boleh menggunakan nombor siri untuk mencari terus rekod jadual dimensi, tanpa perlu mengira dan membandingkan nilai HASH, jadi bahawa kita boleh mendapatkan sesuatu seperti Prestasi menangani dalam ingatan penuh.
| A | |
|---|---|
| 1 | =file(“customer.btx”).import@b() |
| 2 | =file(“orders.btx”).cursor@b() |
| 3 | >A2.switch(custkey,A1:#) |
| 4 | =A2.groups(custkey.city;sum(amount)) |
- Apabila kunci utama jadual dimensi ialah nombor siri, tidak perlu melakukan langkah asal 2 membina indeks HASH.
- Siri kunci asing pada asasnya adalah bersamaan dengan pengalamatan dalam memori luaran. Penyelesaian ini memerlukan menukar medan kunci asing dalam jadual fakta kepada nombor siri, yang serupa dengan proses pengalamatan semasa operasi memori penuh ini juga boleh digunakan semula. Perlu diingat bahawa apabila perubahan besar berlaku dalam jadual dimensi, medan kunci asing jadual fakta perlu disusun secara serentak, jika tidak, surat-menyurat mungkin tidak sejajar. Walau bagaimanapun, kekerapan perubahan jadual dimensi am adalah rendah, dan kebanyakan tindakan adalah penambahan dan pengubahsuaian berbanding pemadaman, jadi tidak banyak situasi di mana jadual fakta perlu disusun semula. Untuk butiran mengenai kejuruteraan, anda juga boleh merujuk kepada maklumat di Akademi Kader.
- SQL menggunakan konsep set tidak tersusun Walaupun kami membuat siri kunci asing terlebih dahulu, pangkalan data tidak boleh memanfaatkan ciri ini Mekanisme kedudukan pantas mengikut nombor bersiri tidak boleh digunakan pada set tidak tertib, dan hanya indeks carian boleh digunakan, dan pangkalan data tidak mengetahui bahawa kunci asing adalah bersiri, dan masih akan mengira nilai HASH dan perbandingan.
- Bagaimana jika jadual dimensi terlalu besar untuk dimuatkan dalam ingatan?
- Jika kita menganalisis algoritma di atas dengan teliti, kita akan mendapati bahawa akses kepada jadual fakta adalah berterusan, tetapi akses kepada jadual dimensi adalah rawak. Apabila kami membincangkan ciri prestasi cakera keras sebelum ini, kami menyebut bahawa memori luaran tidak sesuai untuk akses rawak, jadi jadual dimensi dalam memori luaran tidak lagi boleh menggunakan algoritma di atas.
- Jadual dimensi dalam memori luaran boleh diisih dan disimpan mengikut kekunci primer terlebih dahulu, supaya kami boleh terus menggunakan ciri bahawa kunci yang berkaitan dengan jadual dimensi adalah kunci utama untuk mengoptimumkan prestasi.
- Jika jadual fakta kecil dan boleh dimuatkan dalam ingatan, maka menggunakan kekunci asing untuk mengaitkan rekod jadual dimensi sebenarnya akan menjadi tindakan carian memori luaran (kelompok). Selagi terdapat indeks pada kunci utama pada jadual dimensi, ia boleh dicari dengan cepat Ini boleh mengelakkan merentasi jadual dimensi besar dan memperoleh prestasi yang lebih baik. Algoritma ini juga boleh menyelesaikan berbilang kunci asing secara serentak. SQL tidak membezakan antara jadual dimensi dan jadual fakta Apabila berhadapan dengan dua jadual, satu besar dan satu kecil, HASH JOIN yang dioptimumkan tidak lagi melakukan heap caching Jadual kecil biasanya akan dibaca ke dalam memori dan jadual besar akan dilalui. Ini masih akan menyebabkan Jika terdapat tindakan melintasi jadual dimensi yang besar, prestasinya akan jauh lebih teruk daripada algoritma carian memori luaran yang baru disebut.
- Jika jadual fakta juga sangat besar, anda boleh menggunakan algoritma timbunan satu sisi. Oleh kerana jadual dimensi telah dipesan oleh kunci yang berkaitan (iaitu, kunci utama), ia boleh dibahagikan secara logik kepada beberapa segmen dan mengeluarkan nilai sempadan setiap segmen (nilai maksimum dan minimum kunci utama setiap segmen) , dan kemudian bahagikan jadual fakta kepada longgokan mengikut nilai sempadan ini, setiap longgokan boleh dikaitkan dengan setiap segmen jadual dimensi. Dalam proses itu, hanya bahagian jadual fakta perlu di-cache secara fizikal, dan jadual dimensi tidak perlu di-cache secara fizikal Selain itu, fungsi HASH tidak digunakan, dan pembahagian adalah mustahil untuk fungsi HASH bernasib malang dan menyebabkan segmentasi sekunder, prestasi boleh dikawal. Algoritma timbunan HASH pangkalan data akan melakukan cache timbunan fizikal untuk kedua-dua jadual besar, iaitu timbunan dua hala Mungkin juga terdapat fenomena timbunan sekunder yang disebabkan oleh nasib malang dalam fungsi HASH, dan prestasinya lebih teruk daripada timbunan unilateral. Terlalu banyak dan masih tidak terkawal.
Gunakan kuasa kelompok untuk menyelesaikan masalah jadual berdimensi besar.
- Jika ingatan satu mesin tidak dapat ditampung, anda boleh membina beberapa mesin lagi untuk menampungnya dan menyimpan jadual dimensi pada berbilang mesin yang dibahagikan mengikut nilai kunci utama untuk membentuk jadual dimensi kluster, kemudian anda boleh terus menggunakan algoritma di atas untuk jadual dimensi memori, dan anda juga boleh mendapatkan faedah menghuraikan berbilang kunci asing pada satu masa dan penyelarasan yang mudah. Begitu juga, jadual dimensi kelompok juga boleh menggunakan teknologi bersiri. Di bawah algoritma ini, jadual fakta tidak perlu dihantar, jumlah penghantaran rangkaian yang dihasilkan tidak besar, dan tidak perlu menyimpan data secara tempatan pada nod. Walau bagaimanapun, jadual dimensi tidak boleh dibezakan di bawah sistem SQL Kaedah pemisahan HASH memerlukan kocok kedua-dua jadual, dan jumlah penghantaran rangkaian adalah lebih besar.
- Butiran algoritma ini masih agak rumit dan tidak dapat dijelaskan secara terperinci di sini kerana keterbatasan ruang. Pembaca yang berminat boleh menyemak maklumat di Akademi Qian.
Penggabungan tertib
Sertai kaedah pengoptimuman dan mempercepatkan untuk jadual dimensi sama & sub-jadual induk
- Kami telah membincangkan sebelum itu tentang kerumitan pengiraan algoritma HASH JOIN (Iaitu, bilangan perbandingan kunci yang berkaitan) ialah SUM(nimi), yang jauh lebih kecil daripada kerumitan nm traversal penuh, tetapi ia bergantung kepada nasib fungsi HASH.
- Jika kedua-dua jadual diisih untuk kunci yang berkaitan, maka kita boleh menggunakan algoritma gabungan untuk memproses perkaitan Kerumitan pada masa ini ialah n m apabila n dan m kedua-duanya besar (umumnya jauh lebih besar (dalam julat nilai fungsi HASH), nombor ini juga akan jauh lebih kecil daripada kerumitan algoritma HASH JOIN. Terdapat banyak bahan yang memperkenalkan butiran algoritma penggabungan, jadi saya tidak akan membincangkan butiran di sini.
- Walau bagaimanapun, kaedah ini tidak boleh digunakan apabila kunci asing JOIN digunakan, kerana jadual fakta mungkin mempunyai berbilang medan kunci asing yang perlu mengambil bahagian dalam perkaitan, dan adalah mustahil untuk memesan jadual fakta yang sama untuk berbilang medan pada masa yang sama.
- Meja dimensi yang sama dan meja anak-anak boleh digunakan! Oleh kerana jadual dimensi yang sama dan jadual anak induk sentiasa berkaitan dengan kunci utama atau sebahagian daripada kunci utama, kami boleh mengisih data dalam jadual berkaitan ini mengikut kunci utamanya terlebih dahulu. Walaupun kos pengisihan lebih tinggi, ia adalah sekali sahaja. Setelah pengisihan selesai, anda sentiasa boleh menggunakan algoritma gabungan untuk melaksanakan JOIN pada masa hadapan dan prestasi boleh dipertingkatkan dengan banyak.
- Ini masih mengambil kesempatan daripada fakta bahawa kunci yang berkaitan ialah kunci utama (dan bahagiannya).
- Penggabungan tertib amat berkesan untuk data besar.Induk dan sub-jadual seperti pesanan dan butirannya adalah jadual fakta yang semakin berkembang, yang sering terkumpul kepada saiz yang sangat besar dari semasa ke semasa dan boleh melebihi kapasiti memori dengan mudah.
- Algoritma timbunan HASH untuk storan luaran data besar memerlukan banyak cache Data dibaca dua kali dan ditulis sekali dalam memori luaran, menghasilkan overhed IO yang tinggi. Dalam algoritma gabungan, data dalam kedua-dua jadual hanya perlu dibaca sekali sahaja, tanpa menulis. Bukan sahaja jumlah pengiraan CPU dikurangkan, tetapi jumlah IO memori luaran juga berkurangan dengan ketara. Selain itu, memori yang sangat sedikit diperlukan untuk melaksanakan algoritma gabungan Selagi beberapa rekod cache disimpan dalam ingatan untuk setiap jadual, ia tidak akan menjejaskan keperluan memori tugas serentak yang lain. Timbunan HASH memerlukan memori yang lebih besar dan membaca lebih banyak data setiap kali untuk mengurangkan bilangan masa timbunan.
- SQL mengguna pakai operasi JOIN yang ditakrifkan oleh produk Cartesian dan tidak membezakan antara jenis JOIN Tanpa mengandaikan bahawa sesetengah JOIN sentiasa untuk kunci utama, tidak ada cara untuk memanfaatkan ciri ini dari peringkat algoritma dan boleh. hanya dioptimumkan pada peringkat kejuruteraan. Sesetengah pangkalan data akan menyemak sama ada jadual data dipesan secara fizikal untuk medan yang berkaitan, dan jika ya, gunakan algoritma gabungan Walau bagaimanapun, pangkalan data hubungan berdasarkan konsep set tidak tersusun tidak akan memastikan keteraturan fizikal data dan banyak operasi. akan memusnahkan syarat pelaksanaan algoritma. Menggunakan indeks boleh mencapai susunan data yang logik, tetapi kecekapan traversal masih akan dikurangkan dengan ketara apabila data bercelaru secara fizikal.
- Premis cantuman tertib adalah untuk mengisih data mengikut kunci utama, dan jenis data ini selalunya ditambah secara berterusan Pada dasarnya, ia mesti diisih semula selepas setiap tambahan, dan kami tahu bahawa kosnya pengisihan data besar biasanya sangat tinggi Ini Adakah ia akan menyukarkan untuk menambah data? Malah, proses menambahkan data dan kemudian menambahkannya juga merupakan gabungan tertib Data baharu diisih secara berasingan dan digabungkan dengan data sejarah tersusun Kerumitannya adalah linear, yang bersamaan dengan menulis semula semua data sekali, tidak seperti Big konvensional. pengisihan data memerlukan penulisan dan pembacaan cache. Membuat beberapa tindakan pengoptimuman dalam kejuruteraan juga boleh menghapuskan keperluan untuk menulis semula segala-galanya setiap kali, meningkatkan lagi kecekapan penyelenggaraan. Ini diperkenalkan di Akademi Kader.
Pesejajaran Bersegmen
- Faedah gabungan tersusun ialah mudah untuk melakukan penyejajaran bersegmen.
- Komputer moden mempunyai CPU berbilang teras, dan pemacu keras SSD juga mempunyai keupayaan serentak yang kukuh Menggunakan pengkomputeran selari berbilang benang boleh meningkatkan prestasi dengan ketara. Walau bagaimanapun, sukar untuk mencapai keselarian dengan teknologi timbunan HASH tradisional Apabila melakukan timbunan HASH dengan berbilang benang, data perlu ditulis pada timbunan tertentu pada masa yang sama, menyebabkan konflik dalam sumber yang dikongsi kumpulan tertentu timbunan dikaitkan, sejumlah besar data akan digunakan memori, tidak membenarkan melaksanakan jumlah yang lebih besar selari.
- Apabila menggunakan cantuman tertib untuk mencapai pengkomputeran selari, data perlu dibahagikan kepada berbilang segmen Pembahagian jadual tunggal adalah agak mudah, tetapi dua jadual yang berkaitan mesti diselaraskan secara serentak apabila membahagikan, jika tidak, data kedua-dua jadual. akan disalah jajaran semasa hasil pengiraan yang betul tidak boleh diperoleh, tetapi memesan data boleh memastikan penjajaran penjajaran berprestasi tinggi.
- Mula-mula bahagikan jadual utama (yang lebih besar sudah cukup untuk jadual dengan dimensi yang sama, perbincangan lain tidak akan terjejas) kepada beberapa segmen, baca nilai kunci utama rekod pertama dalam setiap segmen, dan kemudian gunakan nilai utama ini Pergi ke subjadual dan gunakan kaedah dikotomi untuk mencari kedudukan (kerana ia juga tersusun), untuk mendapatkan titik segmentasi subjadual. Ini memastikan bahawa segmen utama dan sub-jadual diselaraskan secara serentak.
- Oleh kerana nilai kunci adalah teratur, nilai kunci rekod dalam setiap segmen jadual utama tergolong dalam selang berterusan tertentu dengan nilai kunci di luar selang tidak akan berada dalam ini segmen, dan rekod dengan nilai utama dalam selang mesti berada dalam Dalam bahagian ini, nilai kunci rekod yang sepadan dengan segmen dalam subjadual juga mempunyai ciri ini, jadi salah jajaran tidak akan berlaku dan juga kerana nilai kunci teratur, carian binari yang cekap boleh dilakukan dalam subjadual untuk mencari titik pembahagian dengan cepat. Iaitu, susunan data memastikan rasional dan kecekapan pembahagian, supaya algoritma selari dapat dilaksanakan dengan yakin.
- Satu lagi ciri perhubungan perkaitan kunci utama antara jadual induk dan anak ialah jadual anak hanya akan dikaitkan dengan satu jadual utama pada kunci primer (malah, terdapat juga jadual dengan dimensi yang sama, tetapi ia adalah mudah untuk menerangkan menggunakan jadual induk dan anak), ia tidak akan Terdapat berbilang jadual induk yang tidak berkaitan antara satu sama lain (mungkin terdapat jadual induk jadual induk). Pada masa ini, anda juga boleh menggunakan mekanisme storan bersepadu untuk menyimpan rekod sub-jadual sebagai nilai medan jadual utama. Dengan cara ini, dalam satu pihak, jumlah storan dikurangkan (kunci yang berkaitan hanya perlu disimpan sekali), dan ia juga bersamaan dengan membuat persatuan terlebih dahulu, dan tidak perlu membandingkannya lagi. Untuk data besar, prestasi yang lebih baik boleh diperolehi.
- Kami telah melaksanakan kaedah pengoptimuman prestasi di atas dalam esProc SPL dan menggunakannya dalam senario sebenar, dan telah mencapai hasil yang sangat baik. SPL kini adalah sumber terbuka Pembaca boleh pergi ke laman web dan forum rasmi Syarikat Shusu atau Syarikat Runqian untuk memuat turun dan mendapatkan maklumat lanjut.
Pembelajaran yang disyorkan: tutorial video mysql
Atas ialah kandungan terperinci SERTAI operasi analisis sistematik Mysql. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!