
Rumah >pangkalan data >tutorial mysql >Analisis mendalam indeks dalam mysql (penjelasan terperinci tentang prinsip)
Analisis mendalam indeks dalam mysql (penjelasan terperinci tentang prinsip)

- 青灯夜游ke hadapan
- 2022-07-01 10:07:232944semak imbas
Artikel ini akan memberi anda analisis mendalam tentang indeks dalam mysql dan membantu anda memahami prinsip indeks mysql saya harap ia akan membantu anda!

1 Apakah itu indeks
Indeks ialah struktur data tersusun yang membantu MySQL memperoleh data dengan cekap
Pengetahuan prasyarat: The rendahkan ketinggian pokok, lebih tinggi kecekapan pertanyaan
2. Struktur data indeks
Laman web simulasi struktur data: https://www.cs.usfca.edu/~galles/visualization /Algoritma.html
(1) Pokok binari
Masalah: Ia tidak boleh mengimbangi diri, dan kecondongan berlaku dalam kes yang melampau Kecekapan pertanyaan adalah serupa dengan senarai terpaut 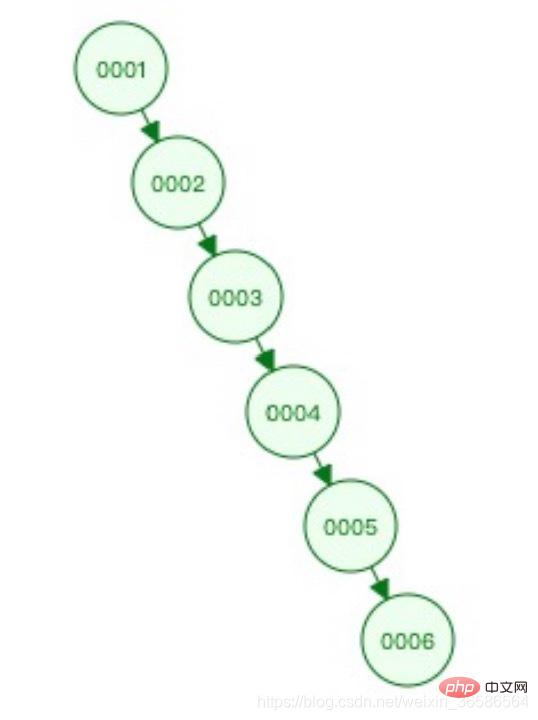
(2) Pokok merah-hitam
Merah dan hitam Pokok mengimbangi data dan menyelesaikan masalah pertumbuhan unilateral;
Masalah: Ia tidak sesuai untuk jumlah data yang besar adalah besar, ketinggian pokok tidak terkawal Dari nod akar ke nod daun, pelbagai traversal diperlukan , kecekapan adalah rendah. 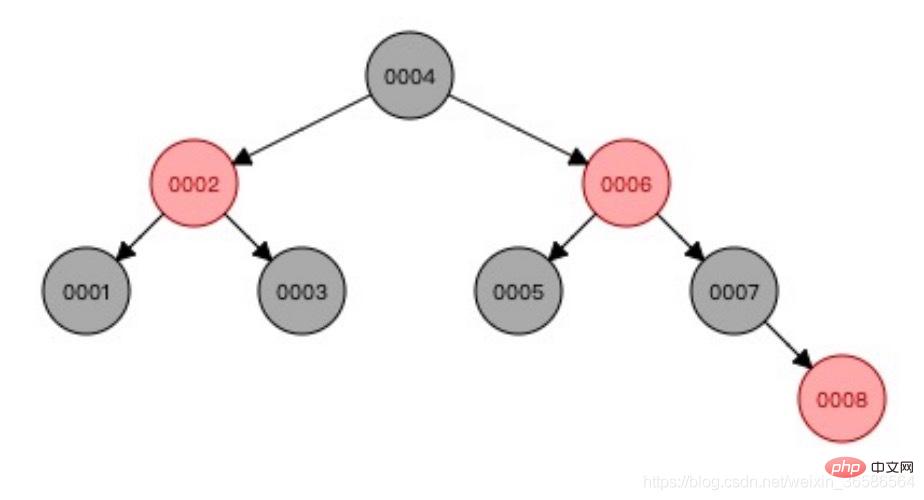
(3) Hash
1. Lakukan pengiraan cincang pada kunci indeks untuk mencari lokasi storan data
2. Dalam banyak kes, indeks Hash lebih baik daripada B pokok Indeks adalah lebih cekap
3. Ia hanya boleh memenuhi "=" dan "IN", dan tidak menyokong pertanyaan julat
4. Masalah konflik cincang 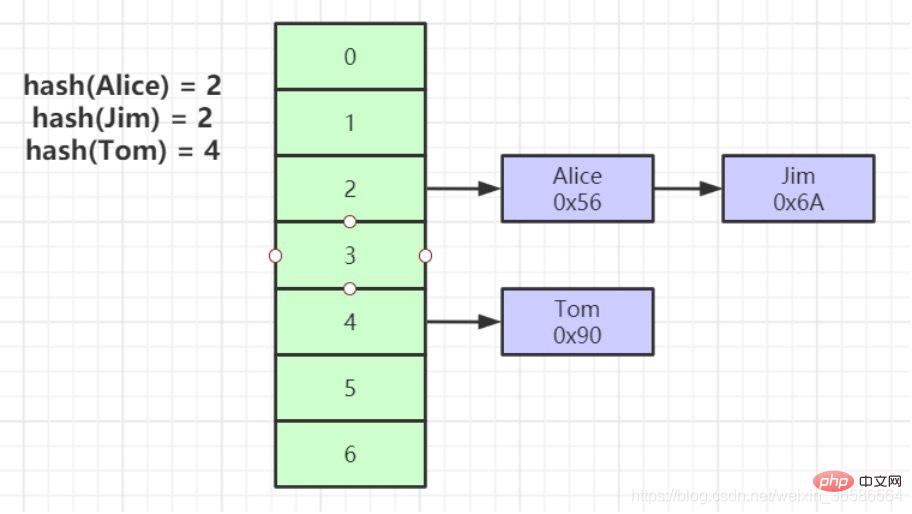
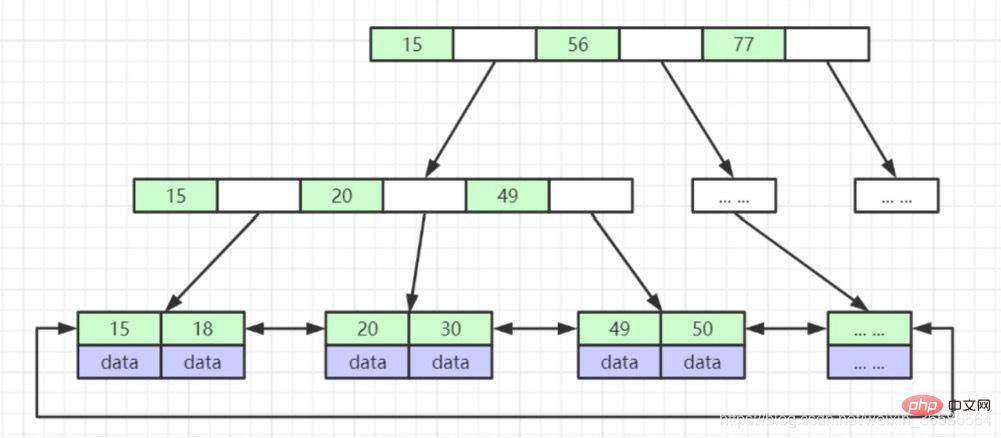
(4) B-Tree
1. Nod daun mempunyai kedalaman yang sama, dan penunjuk nod daun kosong; 2. Semua elemen indeks tidak berulang; disusun dalam susunan menaik dari kiri ke kanan; 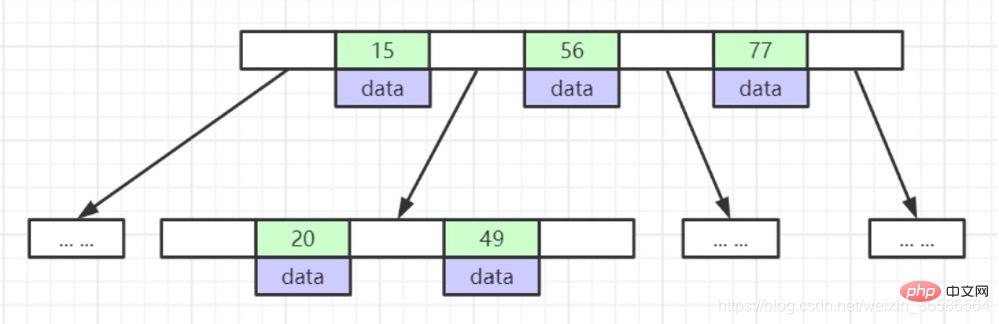 (5) B Tree (varian B-Tree)
(5) B Tree (varian B-Tree)
2. Nod daun mengandungi semua medan indeks
3. Nod daun disambungkan dengan penunjuk untuk meningkatkan prestasi akses selang
 3. Berapa banyak baris data yang boleh disimpan oleh pokok B InnoDB?
3. Berapa banyak baris data yang boleh disimpan oleh pokok B InnoDB?
Jawapan mudah untuk soalan ini ialah: kira-kira 20 juta
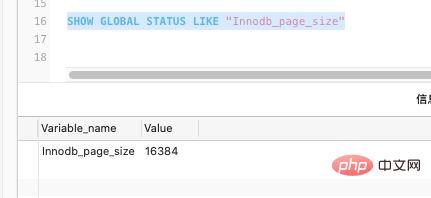
Saiz lalai halaman InnoDB kami dalam MySQL ialah 16k, sudah tentu ia juga boleh ditetapkan melalui parameter:SHOW GLOBAL STATUS LIKE "Innodb_page_size"
 Data dalam jadual data disimpan dalam halaman, jadi berapa banyak baris data boleh disimpan dalam satu halaman? Dengan mengandaikan saiz baris data ialah 1k, maka halaman boleh menyimpan 16 baris data tersebut.
Data dalam jadual data disimpan dalam halaman, jadi berapa banyak baris data boleh disimpan dalam satu halaman? Dengan mengandaikan saiz baris data ialah 1k, maka halaman boleh menyimpan 16 baris data tersebut.
Jika pangkalan data hanya disimpan dengan cara ini, maka cara mencari data menjadi masalah
Kerana kita tidak tahu halaman mana data yang kita cari wujud, dan mustahil untuk merentasi semua halaman terlalu perlahan. Jadi orang terfikir cara untuk menyusun data ini dalam bentuk B-tree. Seperti yang ditunjukkan dalam rajah: 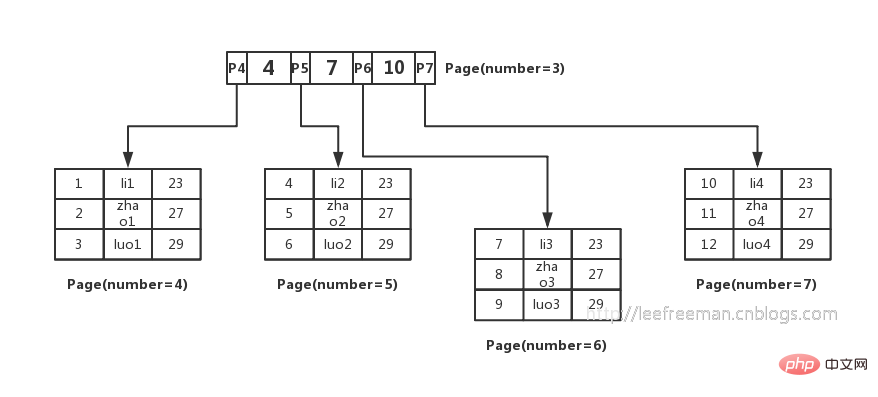 Cara indeks kunci utama B-tree dalam InnoDB menyusun data dan data pertanyaan Mari kita ringkaskan:
Cara indeks kunci utama B-tree dalam InnoDB menyusun data dan data pertanyaan Mari kita ringkaskan:
2. Jadual tersusun indeks menentukan halaman mana data berada melalui kaedah carian binari nod dan penunjuk bukan daun, dan kemudian mencari data yang diperlukan dalam halaman data; Kemudian kembali kepada kami Soalan permulaan ialah, berapa banyak baris data yang boleh disimpan oleh pokok B?
Di sini mula-mula kita anggap ketinggian pokok B ialah 2, iaitu terdapat nod akar dan beberapa nod daun Kemudian jumlah rekod yang disimpan dalam pokok B ini ialah: nombor penunjuk nod akar * bilangan baris rekod nod daun tunggal.
Kami telah menyatakan di atas bahawa bilangan rekod dalam satu nod daun (halaman) = 16K/1K=16. (Di sini diandaikan bahawa saiz data satu baris rekod ialah 1K. Malah, saiz rekod banyak data perniagaan Internet biasanya kira-kira 1K).
Jadi sekarang kita perlu mengira berapa banyak penunjuk boleh disimpan dalam nod bukan daun?
Malah, ini mudah dikira Kami menganggap bahawa ID kunci utama adalah jenis besar dan panjangnya ialah 8 bait, dan saiz penunjuk ditetapkan kepada 6 bait dalam kod sumber InnoDB, jadi a jumlah 14 bait
Berapa banyak unit sebegitu yang boleh kita simpan dalam halaman sebenarnya mewakili jumlah penunjuk yang ada, iaitu, 16384/14=1170.
Kemudian boleh dikira bahawa pokok B dengan ketinggian 2 boleh menyimpan 1170*16=18720 rekod data tersebut.
Berdasarkan prinsip yang sama, kita boleh mengira bahawa pokok B dengan ketinggian 3 boleh menyimpan: 1170* 1170 *16=21902400 rekod sedemikian.
Jadi dalam InnoDB, ketinggian B-tree biasanya 1-3 lapisan, yang boleh memenuhi berpuluh-puluh juta storan data.
Apabila mencari data, satu carian halaman mewakili satu IO, jadi pertanyaan melalui indeks kunci utama biasanya hanya memerlukan 1-3 operasi IO untuk mencari data.
4. Mengapakah indeks MySQL menggunakan B-tree dan bukannya struktur pokok lain?
B-tree
Nod daun mempunyai kedalaman yang sama, dan penunjuk nod daun kosong
Semua elemen indeks tidak berulang
Indeks data dalam nod adalah dari kiri ke kanan Susunan tambahan
Indeks pokok B
Nod bukan daun tidak menyimpan data, hanya indeks (berlebihan), lebih banyak indeks boleh diletakkan
Nod daun mengandungi semua medan indeks
Nod daun disambungkan dengan penunjuk untuk meningkatkan prestasi akses selang
Mengapa nod data dialihkan ke nod daun, satu nod boleh menyimpan lebih banyak indeks
16^n=20 juta, n Ia adalah ketinggian pokok Ia menyimpan data yang sama Ketinggian B-tree jauh lebih kecil daripada B-tree
kerana B-tree akan menyimpan data tanpa mengira daun. nod atau nod bukan daun, yang menghasilkan lebih sedikit penunjuk yang boleh disimpan dalam nod bukan daun (Sesetengah maklumat juga dipanggil fan-out)
Untuk menyimpan sejumlah besar data apabila terdapat sedikit penunjuk. , anda hanya boleh meningkatkan ketinggian pokok, menghasilkan lebih banyak operasi IO dan prestasi pertanyaan yang lebih rendah;
5 , Pelaksanaan indeks enjin penyimpanan
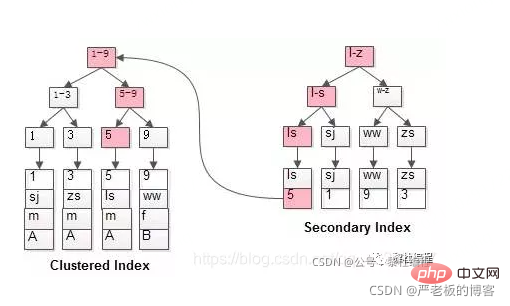
Maksud indeks berkelompok: nod daun menyimpan indeks dan data; , juga dipanggil indeks berkelompok.
Indeks tidak berkelompok juga dipanggil indeks jarang. Indeks kunci utama ialah indeks berkelompok!
(1) Fail indeks dan fail data MyISAM diasingkan (bukan agregat)
Fail indeks MyISAM dan fail data diasingkan (bukan agregat), dan enjin storan bertindak di atas meja; > Fail indeks menyimpan indeks, dan fail data menyimpan data Indeks dan data tidak disimpan bersama 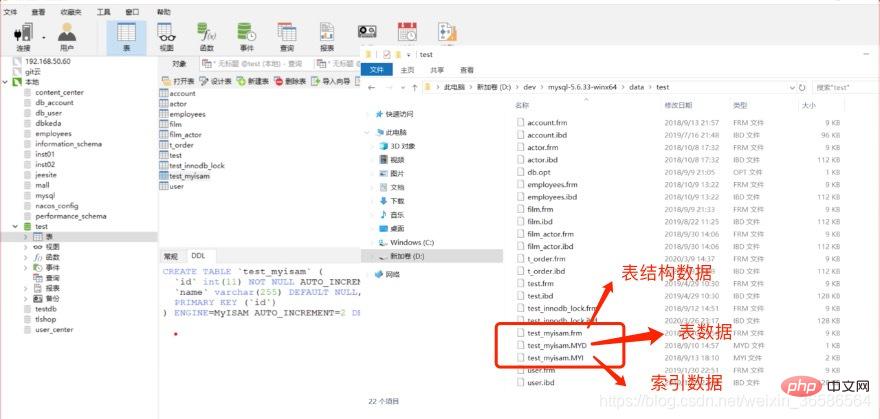 Pertanyaan: Pertama tanya indeks pada pokok B, dan kemudian tanya fail data menggunakan. lokasi yang ditanya
Pertanyaan: Pertama tanya indeks pada pokok B, dan kemudian tanya fail data menggunakan. lokasi yang ditanya 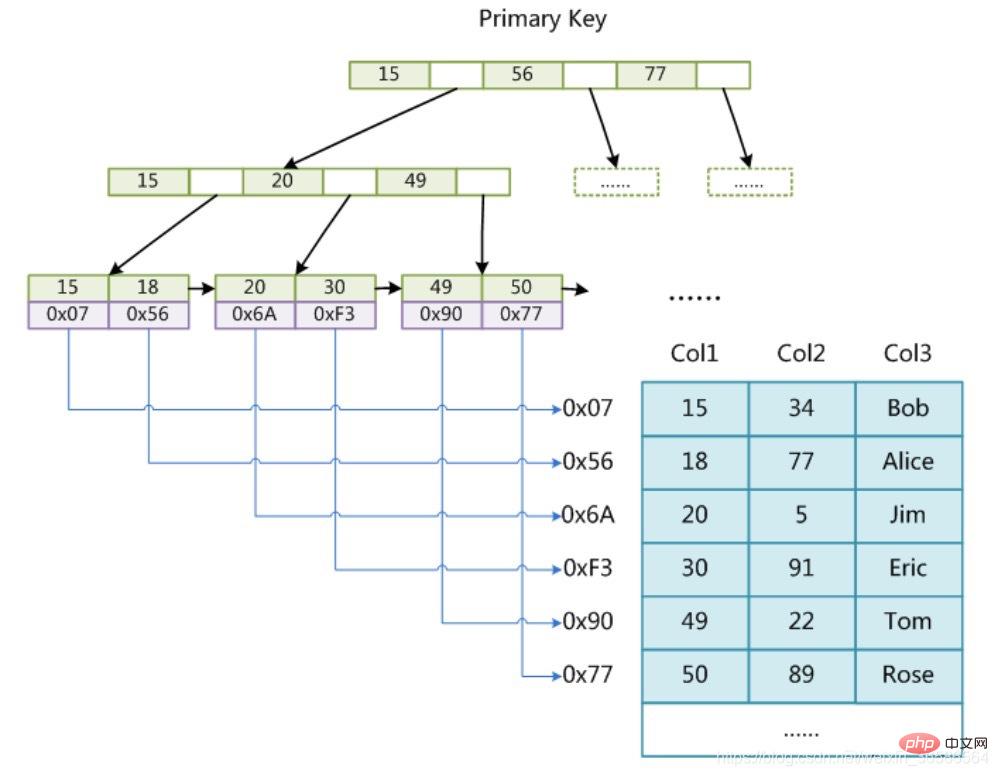
Data indeks data jadual disimpan dalam fail .ibd 
2. Indeks berkelompok - nod daun mengandungi rekod data lengkap
(1) Indeks kunci utama: 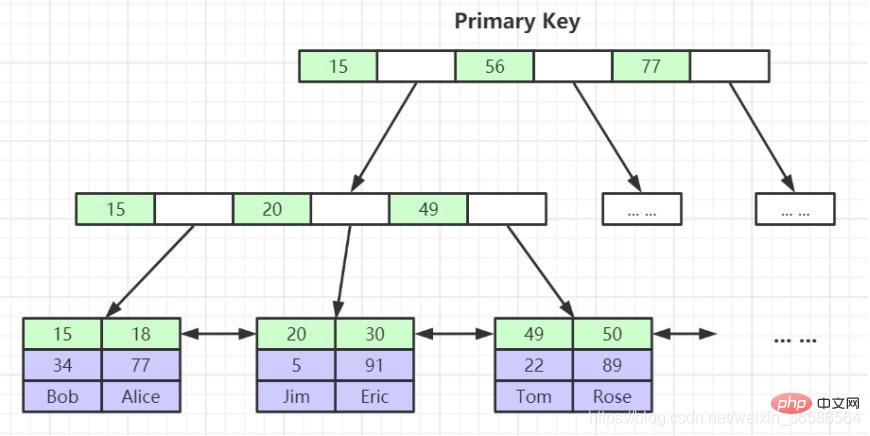
Nod daun indeks kunci utama menyimpan baris data lengkap, manakala nod daun indeks bukan kunci utama menyimpan nilai indeks kunci primer Apabila menanyakan data melalui kunci bukan utama indeks, indeks kunci utama akan ditemui dahulu, dan kemudian indeks kunci utama akan dicari Untuk mencari data yang sepadan, proses ini dipanggil pulangan jadual (akan disebut semula di bawah).
- Isih mengikut nilai lajur indeks yang ditentukan
- Storan nod daun tidak lengkap Rekod pengguna adalah hanya
- diindeks pada kunci utama lajur. Rekod kemasukan direktori bukan nombor halaman kunci utama, tetapi menjadi
- nombor halaman lajur indeks. Apabila mencari data dalam indeks sekunder, anda perlu mencari rekod pengguna yang lengkap dalam indeks berkelompok berdasarkan nilai kunci utama Proses ini dipanggil
- pulangan jadual
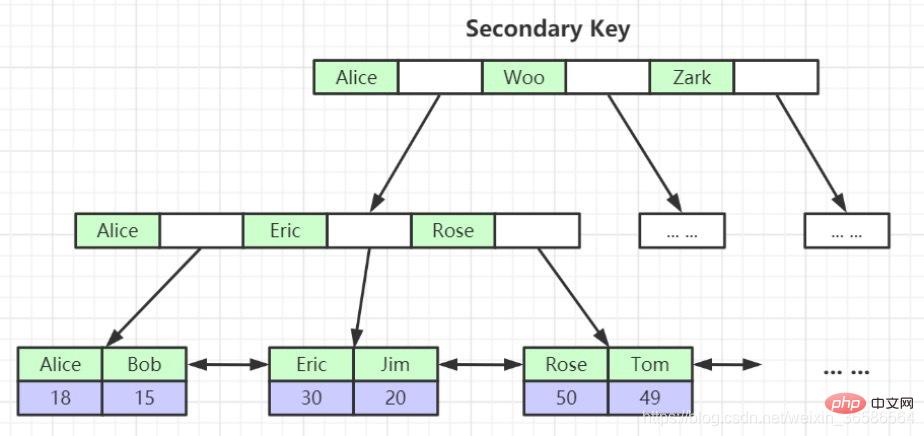
Pokok B yang ditubuhkan berdasarkan saiz berbilang lajur sebagai peraturan pengisihan dipanggil indeks bersama, yang pada asasnya adalah indeks sekunder. 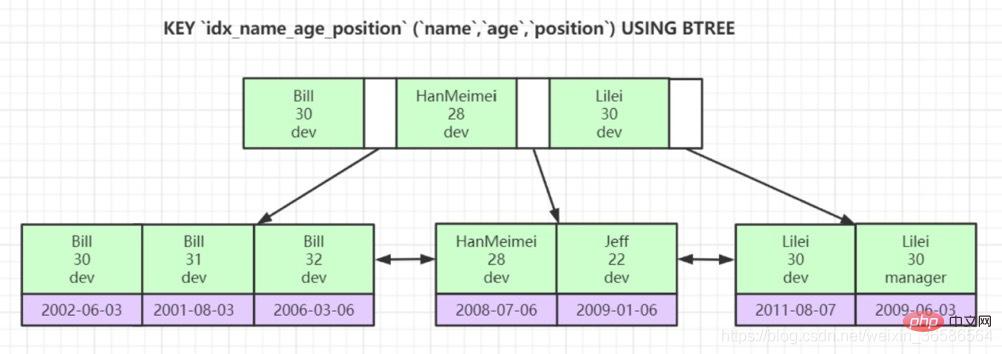
(1) Kunci utama digunakan oleh InnoDB untuk membina B-tree. Jika tiada kunci utama, lajur unik akan digunakan sebagai indeks Jika masih tiada kunci utama, lajur tersembunyi akan dibuat sebagai lajur indeks.
(2) Apakah yang berlaku jika anda tidak menggunakan kunci utama penambahan automatik integer dan menggunakan UUID sebagai kunci utama?
UUID ialah jenis rentetan Operasi perbandingan integer lebih pantas daripada UUID tidak meningkat secara automatik pada nilai. Nilai akhir dan lokasi storan dipetakan satu demi satu
Mengapa tidak menggunakan Hash?
Hash tidak menyokong pertanyaan julat dengan baik. Data dalam lajur tertentu tidak tersusun, dan B-tree boleh membuat data teratur semasa membina.
4. Mengapakah nod daun bagi struktur indeks bukan kunci utama menyimpan nilai kunci utama? (Ketekalan dan penjimatan penyimpanan)
6. Ringkasan indeks pokok B
1. Rekod pengguna disimpan dalam nod daun pokok B, dan semua rekod direktori disimpan dalam nod bukan daun.
2. Enjin storan InnoDB secara automatik akan mencipta indeks berkelompok untuk kunci utama (jika tidak wujud, ia akan menambahkannya secara automatik untuk kami Nod daun indeks berkelompok mengandungi rekod pengguna yang lengkap).
3. Indeks sekunder boleh diwujudkan untuk lajur yang ditentukan Rekod pengguna yang terkandung dalam nod daun indeks sekunder terdiri daripada kunci utama lajur indeks Oleh itu, jika anda ingin mencari rekod pengguna yang lengkap indeks sekunder, diperlukan Melalui operasi pengembalian jadual , iaitu selepas mencari nilai kunci primer melalui indeks sekunder, rekod pengguna yang lengkap ditemui dalam indeks berkelompok.
4. Nod pada setiap peringkat dalam pokok B diisih mengikut tertib menaik nilai lajur indeks untuk membentuk senarai berganda berpaut , dan rekod dalam setiap halaman (sama ada rekod pengguna atau entri direktori Rekod) dibentuk menjadi senarai terpaut tunggal dalam tertib menaik nilai lajur indeks. Jika ia adalah indeks bersama, halaman dan rekod diisih terlebih dahulu mengikut lajur sebelum indeks bersama Jika nilai lajur adalah sama, maka ia diisih mengikut lajur selepas indeks bersama.
Mencari rekod melalui indeks bermula dari nod akar pokok B dan mencari ke bawah lapisan demi lapisan. Memandangkan setiap halaman mempunyai direktori halaman berdasarkan nilai lajur indeks, carian dalam halaman ini sangat pantas.
7. Ringkasan beberapa situasi di mana indeks Mysql akan gagal
Lihat blog: Ringkasan beberapa situasi di mana indeks Mysql akan gagal
https:// blog. csdn.net/weixin_36586564/article/details/79641748
[Cadangan berkaitan: tutorial video mysql]
Atas ialah kandungan terperinci Analisis mendalam indeks dalam mysql (penjelasan terperinci tentang prinsip). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Bagaimana untuk menanyakan pengekodan set aksara jadual dalam mysql
- Ketahui lebih lanjut tentang kunci dalam Mysql dan bercakap tentang senario penggunaan!
- Kuasai sepenuhnya penyelesaian kepada kelewatan tuan-hamba MySQL
- Bagaimanakah pernyataan SQL dilaksanakan dalam Pembelajaran MySQL? Mari kita bercakap tentang proses pelaksanaan
- Penjelasan terperinci tentang asas kekangan MySQL dan pertanyaan berbilang jadual