
Rumah >pembangunan bahagian belakang >Tutorial Python >Amalan automasi Python untuk saringan resume
Amalan automasi Python untuk saringan resume

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2022-06-07 18:59:263721semak imbas
Artikel ini membawa anda pengetahuan yang berkaitan tentang python terutamanya memperkenalkan isu yang berkaitan dengan saringan semula, termasuk menentukan kelas ReadDoc untuk membaca fail perkataan dan mentakrifkan fungsi search_word tayangan ini, saya harap ia dapat membantu semua orang.

Pembelajaran yang disyorkan: Tutorial video Python
Saringan resume
Maklumat resume yang berkaitan adalah seperti berikut:

Tentukan kelas ReadDoc untuk membaca fail perkataan
Syarat yang diketahui:
Ingin mencari fail mengandungi resume Kata Kunci yang ditentukan (seperti Python, Java)
Idea pelaksanaan:
Baca setiap fail perkataan dalam kelompok (dapatkan maklumat perkataan melalui glob), dan tukar semua kandungan boleh dibaca mereka Dapatkan dan tapis melalui kata kunci untuk mendapatkan alamat resume sasaran.
这里有个需要注意的地方就是,并不是所有的 "简历" 都是以段落的形式呈现的,比如从 "猎聘" 网下载下来的简历就是 "表格形式" 的,而 "boss" 上下载的简历就是 "段落形式" 的,这里再进行读取的时候需要注意下,我们做的演示脚本练习就是 "表格形式" 的。
这里的话,我们就可以专门定义一个 "ReadDoc" 的类,里面定义两个函数,分别用于读取 "段落" 和 "表格" 。
Skrip kes praktikal adalah seperti berikut:
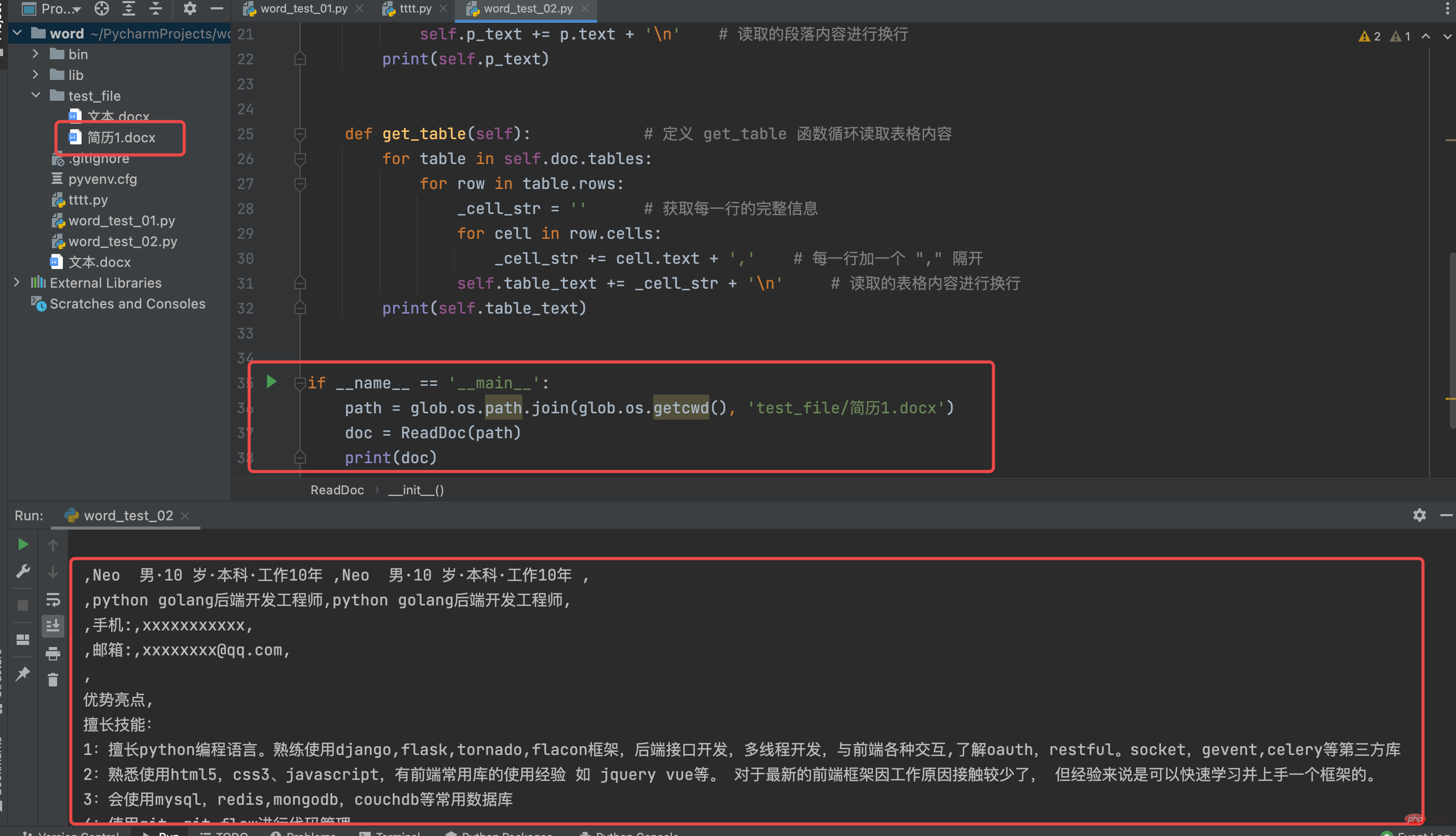
# coding:utf-8from docx import Documentclass ReadDoc(object): # 定义一个 ReadDoc ,用以读取 word 文件 def __init__(self, path): # 构造函数默认传入读取 word 文件的路径 self.doc = Document(path) self.p_text = '' self.table_text = '' self.get_para() self.get_table() def get_para(self): # 定义 get_para 函数用以读取 word 文件的段落 for p in self.doc.paragraphs: self.p_text += p.text + '\n' # 读取的段落内容进行换行 print(self.p_text) def get_table(self): # 定义 get_table 函数循环读取表格内容 for table in self.doc.tables: for row in table.rows: _cell_str = '' # 获取每一行的完整信息 for cell in row.cells: _cell_str += cell.text + ',' # 每一行加一个 "," 隔开 self.table_text += _cell_str + '\n' # 读取的表格内容进行换行 print(self.table_text)if __name__ == '__main__': path = glob.os.path.join(glob.os.getcwd(), 'test_file/简历1.docx') doc = ReadDoc(path) print(doc)
Lihatlah ReadDoc Keputusan operasi kelas
Tentukan fungsi search_word untuk menapis kandungan fail perkataan agar sepadan dengan resume yang diingini
OK, Dokumen perkataan resume telah berjaya dibaca di atas Seterusnya, kita perlu menapis resume yang mengandungi kata kunci dengan memilih maklumat kata kunci daripada kandungan yang dibaca.
Skrip kes praktikal adalah seperti berikut:
# coding:utf-8import globfrom docx import Documentclass ReadDoc(object): # 定义一个 ReadDoc ,用以读取 word 文件
def __init__(self, path): # 构造函数默认传入读取 word 文件的路径
self.doc = Document(path)
self.p_text = ''
self.table_text = ''
self.get_para()
self.get_table()
def get_para(self): # 定义 get_para 函数用以读取 word 文件的段落
for p in self.doc.paragraphs:
self.p_text += p.text + '\n' # 读取的段落内容进行换行
# print(self.p_text) # 调试打印输出 word 文件的段落内容
def get_table(self): # 定义 get_table 函数循环读取表格内容
for table in self.doc.tables:
for row in table.rows:
_cell_str = '' # 获取每一行的完整信息
for cell in row.cells:
_cell_str += cell.text + ',' # 每一行加一个 "," 隔开
self.table_text += _cell_str + '\n' # 读取的表格内容进行换行
# print(self.table_text) # 调试打印输出 word 文件的表格内容def search_word(path, targets): # 定义 search_word 用以筛选符合内容的简历;传入 path 与 targets(targets 为列表)
result = glob.glob(path)
final_result = [] # 定义一个空列表,用以后续存储文件的信息
for i in result: # for 循环获取 result 内容
isuse = True # 是否可用
if glob.os.path.isfile(i): # 判断是否是文件
if i.endswith('.docx'): # 判断文件后缀是否是 "docx" ,若是,则利用 ReadDoc类 实例化该文件对象
doc = ReadDoc(i)
p_text = doc.p_text # 获取 word 文件内容
table_text = doc.table_text
all_text = p_text + table_text for target in targets: # for 循环判断关键字信息内容是否存在
if target not in all_text:
isuse = False
break
if not isuse:
continue
final_result.append(i)
return final_resultif __name__ == '__main__':
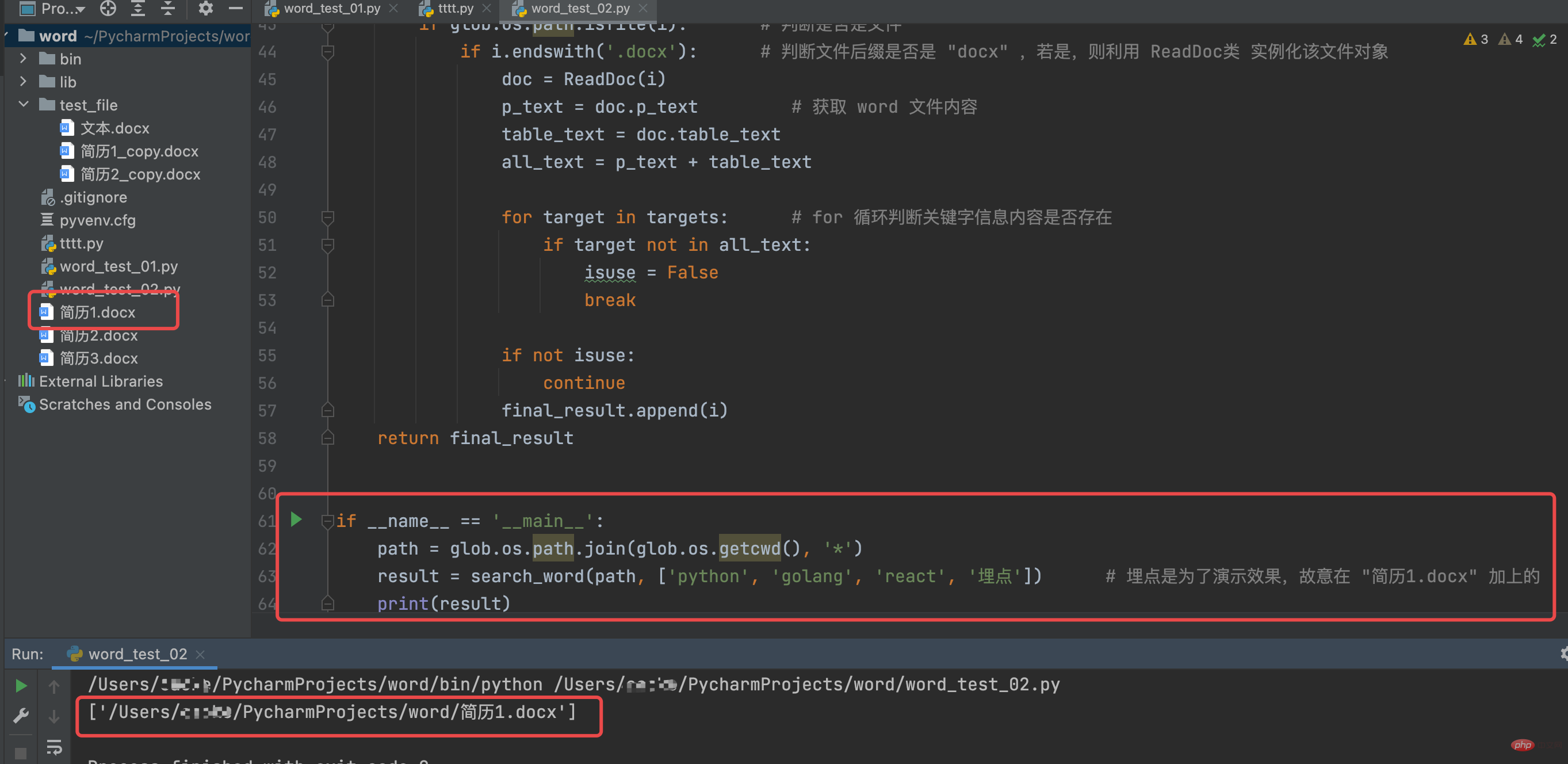
path = glob.os.path.join(glob.os.getcwd(), '*')
result = search_word(path, ['python', 'golang', 'react', '埋点']) # 埋点是为了演示效果,故意在 "简历1.docx" 加上的
print(result)
Keputusan yang dijalankan adalah seperti berikut:
Pembelajaran yang disyorkan: tutorial video python
Atas ialah kandungan terperinci Amalan automasi Python untuk saringan resume. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Pengenalan terperinci kepada modul numpy python
- Memperkenalkan enam fungsi terbina dalam Python yang sangat mudah digunakan
- Penjelasan grafik terperinci tentang cara menggunakan Python untuk melukis carta visualisasi dinamik
- Pelajari aksara dan senarai Python secara ringkas (contoh terperinci)
- Contoh terperinci bagi empat ciri berorientasikan objek Python