
Rumah >pangkalan data >tutorial mysql >Fahami cara membuat sandaran dan memulihkan pangkalan data MySQL dalam satu artikel
Fahami cara membuat sandaran dan memulihkan pangkalan data MySQL dalam satu artikel

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2022-05-06 18:53:254445semak imbas
Artikel ini membawa anda pengetahuan yang berkaitan tentang mysql, yang terutamanya memperkenalkan isu berkaitan sandaran dan pemulihan pangkalan data, termasuk mysqldump untuk melaksanakan sandaran logik, perintah mysql untuk memulihkan data dan sandaran fizikal pemulihan dan kandungan lain, mari kita lihat di bawah ini saya harap ia akan membantu semua orang.

Pembelajaran yang disyorkan: tutorial video mysql
Dalam sebarang persekitaran pangkalan data, akan sentiasa ada 不确定的意外 situasi, seperti pengecualian Gangguan kuasa, pelbagai kegagalan perisian dan perkakasan dalam sistem komputer, sabotaj manusia, salah operasi pentadbir, dsb. Situasi ini boleh membawa kepada akibat yang serius seperti 数据的丢失 dan 服务器瘫痪. Apabila terdapat berbilang pelayan, akan ada 数据同步问题 antara pelayan tuan dan hamba.
Untuk mencegah kehilangan data dengan berkesan dan meminimumkan kehilangan, anda harus 定期melakukan 备份 pada pelayan pangkalan data MySQL. Jika data dalam pangkalan data hilang atau ralat berlaku, data yang disandarkan boleh digunakan 进行恢复. Penyegerakan data antara pelayan tuan dan hamba boleh dicapai melalui fungsi replikasi.
1. Sandaran fizikal dan sandaran logik
Sandaran fizikal : Sandarkan fail data dan buang fail fizikal pangkalan data ke direktori tertentu. Kelajuan pemulihan sandaran fizikal agak pantas, tetapi ia mengambil banyak ruang Anda boleh menggunakan alat xtrabackup dalam MySQL untuk melakukan sandaran fizikal.
Sandaran logik : Gunakan alatan untuk mengeksport objek pangkalan data dan meringkaskannya ke dalam fail sandaran. Kelajuan pemulihan sandaran logik adalah perlahan, tetapi ia mengambil sedikit ruang dan lebih fleksibel. Alat sandaran logik yang biasa digunakan dalam MySQL ialah mysqldump. Sandaran logik ialah 备份sql语句 Semasa pemulihan, pernyataan SQL sandaran dilaksanakan untuk menghasilkan semula data pangkalan data.
2. Mysqldump melaksanakan sandaran logik
Mysqldump ialah alat sandaran pangkalan data yang sangat berguna yang disediakan oleh MySQL.
2.1 Sandarkan pangkalan data
Apabila arahan mysqldump dilaksanakan, pangkalan data boleh disandarkan ke dalam 文本文件 Fail ini sebenarnya mengandungi berbilang pernyataan CREATE dan INSERT. Gunakan Pernyataan ini boleh mencipta semula jadual dan memasukkan data.
- Ketahui struktur jadual yang perlu disandarkan, dan jana pernyataan CREATE dalam fail teks
- Tukar semua rekod dalam jadual kepada pernyataan INSERT.
Sintaks asas:
mysqldump –u 用户名称 –h 主机名称 –p密码 待备份的数据库名称[tbname, [tbname...]]> 备份文件名称.sql
Contoh: Gunakan pengguna akar untuk menyandarkan pangkalan data atguigu:
mysqldump -uroot -p atguigu>atguigu.sql #备份文件存储在当前目录下
mysqldump -uroot -p atguigudb1 > /var/lib/mysql/atguigu.sql
Analisis fail sandaran:
-- MySQL dump 10.13 Distrib 8.0.26, for Linux (x86_64) -- -- Host: localhost Database: atguigu -- ------------------------------------------------------ -- Server version 8.0.26 /*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */; /*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */; /*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */; /*!50503 SET NAMES utf8mb4 */; /*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */; /*!40103 SET TIME_ZONE='+00:00' */; /*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */; /*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */; /*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */; /*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */; -- -- Current Database: `atguigu` -- CREATE DATABASE /*!32312 IF NOT EXISTS*/ `atguigu` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */; USE `atguigu`; -- -- Table structure for table `student` -- DROP TABLE IF EXISTS `student`; /*!40101 SET @saved_cs_client = @@character_set_client */; /*!50503 SET character_set_client = utf8mb4 */; CREATE TABLE `student` ( `studentno` int NOT NULL, `name` varchar(20) DEFAULT NULL, `class` varchar(20) DEFAULT NULL, PRIMARY KEY (`studentno`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3; /*!40101 SET character_set_client = @saved_cs_client */; INSERT INTO `student` VALUES (1,'张三_back','一班'),(3,'李四','一班'),(8,'王五','二班'), (15,'赵六','二班'),(20,'钱七','>三班'),(22,'zhang3_update','1ban'),(24,'wang5','2ban'); /*!40000 ALTER TABLE `student` ENABLE KEYS */; UNLOCK TABLES; . . . . /*!40101 SET SQL_MODE=@OLD_SQL_MODE */; /*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */; /*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */; /*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */; /*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */; /*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */; /*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */; -- Dump completed on 2022-01-07 9:58:23
-
--bermula dengan ulasan pernyataan SQL; 🎜> Pernyataan yang bermula dengan dan berakhir dengan - adalah ulasan MySQL boleh laku ini boleh dilaksanakan oleh MySQL, tetapi diabaikan sebagai ulasan dalam sistem pengurusan pangkalan data lain, yang boleh meningkatkan kemudahalihan pangkalan data
/* !Permulaan fail menunjukkan nombor versi alat MySQLdump yang digunakan untuk menyandarkan fail diikuti dengan nama dan maklumat hos akaun sandaran, serta nama pangkalan data yang disandarkan; nombor versi pelayan MySQL, iaitu 8.0.26 dalam kes ini.*/Bahagian seterusnya bagi fail sandaran ialah beberapa penyata SET, yang memberikan beberapa nilai pembolehubah sistemkepada pembolehubah yang ditentukan pengguna untuk memastikan pembolehubah sistem pangkalan data yang dipulihkan adalah sama seperti yang terdapat dalam sandaran asal, contohnya: -
Beberapa baris terakhir fail sandaran MySQL menggunakan pernyataan SET untuk memulihkan nilai asal pembolehubah sistem pelayan, contohnya: Penyataan DROP , CIPTA pernyataan dan INSERT pernyataan selepas semuanya dipulihkan digunakan apabila. Sebagai contoh, penyataan
semuanya dipulihkan digunakan apabila. Sebagai contoh, penyataan - digunakan untuk menentukan sama ada terdapat jadual bernama pelajar dalam pangkalan data Jika ia wujud, padamkan penyataan CREATE digunakan untuk membuat jadual INSERT digunakan untuk memulihkan data .
- Sesetengah pernyataan pada permulaan fail sandaran bermula dengan nombor. Nombor ini mewakili nombor versi MySQL, memberitahu kami bahawa pernyataan ini hanya boleh dilaksanakan dalam versi MySQL yang ditentukan atau lebih tinggi daripada itu. Sebagai contoh, 40101 menunjukkan bahawa pernyataan ini hanya boleh dilaksanakan apabila nombor versi MySQL ialah 4.01.01 atau lebih tinggi. Masa sandaran direkodkan pada penghujung fail.
DROPTABLE IF EXISTS 'student' - 2.2 Sandarkan semua pangkalan data

atau
:--all-databases-A2.3 Pangkalan data bahagian sandaran
mysqldump -uroot -pxxxxxx --all-databases > all_database.sql mysqldump -uroot -pxxxxxx -A > all_database.sqlmenggunakan parameter
atau
Parameter ini diikuti dengan nama pangkalan data berbilang dipisahkan oleh ruang. Jika parameter pangkalan data ditentukan, pernyataan untuk mencipta pangkalan data akan wujud dalam fail sandaran Jika parameter tidak dinyatakan, ia tidak akan wujud. Sintaksnya adalah seperti berikut:--databases-B Contoh
mysqldump –u user –h host –p --databases [数据库的名称1 [数据库的名称2...]] > 备份文件名称.sql
atau
mysqldump -uroot -p -B atguigu atguigu12 > two_database.sql
2.4 备份部分表
比如,在表变更前做个备份。语法如下:
mysqldump –u user –h host –p 数据库的名称 [表名1 [表名2...]] > 备份文件名称.sql
举例:备份atguigu数据库下的book表
mysqldump -uroot -p atguigu book> book.sql#备份多张表 mysqldump -uroot -p atguigu book account > 2_tables_bak.sql
book.sql文件内容如下
mysqldump -uroot -p atguigu book> book.sql^C [root@node1 ~]# ls kk kubekey kubekey-v1.1.1-linux-amd64.tar.gz README.md test1.sql two_database.sql [root@node1 ~]# mysqldump -uroot -p atguigu book> book.sql Enter password: [root@node1 ~]# ls book.sql kk kubekey kubekey-v1.1.1-linux-amd64.tar.gz README.md test1.sql two_database.sql [root@node1 ~]# vi book.sql -- MySQL dump 10.13 Distrib 8.0.26, for Linux (x86_64) -- -- Host: localhost Database: atguigu -- ------------------------------------------------------ -- Server version 8.0.26 /*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */; /*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */; /*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */; /*!50503 SET NAMES utf8mb4 */; /*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */; /*!40103 SET TIME_ZONE='+00:00' */; /*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */; /*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */; /*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */; /*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */; -- -- Table structure for table `book` -- DROP TABLE IF EXISTS `book`; /*!40101 SET @saved_cs_client = @@character_set_client */; /*!50503 SET character_set_client = utf8mb4 */; CREATE TABLE `book` ( `bookid` int unsigned NOT NULL AUTO_INCREMENT, `card` int unsigned NOT NULL, `test` varchar(255) COLLATE utf8_bin DEFAULT NULL, PRIMARY KEY (`bookid`), KEY `Y` (`card`) ) ENGINE=InnoDB AUTO_INCREMENT=101 DEFAULT CHARSET=utf8mb3 COLLATE=utf8_bin; /*!40101 SET character_set_client = @saved_cs_client */; -- -- Dumping data for table `book` -- LOCK TABLES `book` WRITE; /*!40000 ALTER TABLE `book` DISABLE KEYS */; INSERT INTO `book` VALUES (1,9,NULL),(2,10,NULL),(3,4,NULL),(4,8,NULL),(5,7,NULL), (6,10,NULL),(7,11,NULL),(8,3,NULL),(9,1,NULL),(10,17,NULL),(11,19,NULL),(12,4,NULL), (13,1,NULL),(14,14,NULL),(15,5,NULL),(16,5,NULL),(17,8,NULL),(18,3,NULL),(19,12,NULL), (20,11,NULL),(21,9,NULL),(22,20,NULL),(23,13,NULL),(24,3,NULL),(25,18,NULL), (26,20,NULL),(27,5,NULL),(28,6,NULL),(29,15,NULL),(30,15,NULL),(31,12,NULL), (32,11,NULL),(33,20,NULL),(34,5,NULL),(35,4,NULL),(36,6,NULL),(37,17,NULL), (38,5,NULL),(39,16,NULL),(40,6,NULL),(41,18,NULL),(42,12,NULL),(43,6,NULL), (44,12,NULL),(45,2,NULL),(46,12,NULL),(47,15,NULL),(48,17,NULL),(49,2,NULL), (50,16,NULL),(51,13,NULL),(52,17,NULL),(53,7,NULL),(54,2,NULL),(55,9,NULL), (56,1,NULL),(57,14,NULL),(58,7,NULL),(59,15,NULL),(60,12,NULL),(61,13,NULL), (62,8,NULL),(63,2,NULL),(64,6,NULL),(65,2,NULL),(66,12,NULL),(67,12,NULL),(68,4,NULL), (69,5,NULL),(70,10,NULL),(71,16,NULL),(72,8,NULL),(73,14,NULL),(74,5,NULL), (75,4,NULL),(76,3,NULL),(77,2,NULL),(78,2,NULL),(79,2,NULL),(80,3,NULL),(81,8,NULL), (82,14,NULL),(83,5,NULL),(84,4,NULL),(85,2,NULL),(86,20,NULL),(87,12,NULL), (88,1,NULL),(89,8,NULL),(90,18,NULL),(91,3,NULL),(92,3,NULL),(93,6,NULL),(94,1,NULL), (95,4,NULL),(96,17,NULL),(97,15,NULL),(98,1,NULL),(99,20,NULL),(100,15,NULL); /*!40000 ALTER TABLE `book` ENABLE KEYS */; UNLOCK TABLES; /*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */;
可以看到, book文件和备份的库文件类似。不同的是,book文件只包含book表的DROP、CREATE和INSERT语句。
备份多张表使用下面的命令,比如备份book和account表:
#备份多张表mysqldump -uroot -p atguigu book account > 2_tables_bak.sql
2.5 备份单表的部分数据
有些时候一张表的数据量很大,我们只需要部分数据。这时就可以使用--where选项了。where后面附带需要满足的条件。
举例:备份student表中id小于10的数据:
mysqldump -uroot -p atguigu student --where="id student_part_id10_low_bak.sql
内容如下所示,insert语句只有id小于10的部分
LOCK TABLES `student` WRITE; /*!40000 ALTER TABLE `student` DISABLE KEYS */; INSERT INTO `student` VALUES (1,100002,'JugxTY',157,280),(2,100003,'QyUcCJ',251,277), (3,100004,'lATUPp',80,404),(4,100005,'BmFsXI',240,171),(5,100006,'mkpSwJ',388,476), (6,100007,'ujMgwN',259,124),(7,100008,'HBJTqX',429,168),(8,100009,'dvQSQA',61,504), (9,100010,'HljpVJ',234,185);
2.6 排除某些表的备份
如果我们想备份某个库,但是某些表数据量很大或者与业务关联不大,这个时候可以考虑排除掉这些表,同样的,选项--ignore-table可以完成这个功能。
mysqldump -uroot -p atguigu --ignore-table=atguigu.student > no_stu_bak.sql
通过如下指定判定文件中没有student表结构:
grep "student" no_stu_bak.sql
2.7 只备份结构或只备份数据
只备份结构的话可以使用--no-data简写为--d选项;只备份数据可以使用--no-create-info简写为--t选项。
- 只备份结构
mysqldump -uroot -p atguigu --no-data > atguigu_no_data_bak.sql #使用grep命令,没有找到insert相关语句,表示没有数据备份。 [root@node1 ~]# grep "INSERT" atguigu_no_data_bak.sql [root@node1 ~]#
- 只备份数据
mysqldump -uroot -p atguigu --no-data > atguigu_no_data_bak.sql #使用grep命令,没有找到insert相关语句,表示没有数据备份。 [root@node1 ~]# grep "INSERT" atguigu_no_data_bak.sql [root@node1 ~]#
- 只备份数据
mysqldump -uroot -p atguigu --no-create-info > atguigu_no_create_info_bak.sql #使用grep命令,没有找到create相关语句,表示没有数据结构。 [root@node1 ~]# grep "CREATE" atguigu_no_create_info_bak.sql [root@node1 ~]#
2.8 备份中包含存储过程、函数、事件
mysqldump备份默认是不包含存储过程,自定义函数及事件的。可以使用--routines或-R选项来备份存储过程及函数,使用--events或-E参数来备份事件。
举例:备份整个atguigu库,包含存储过程及事件:
- 使用下面的SQL可以查看当前库有哪些存储过程或者函数
mysql> SELECT SPECIFIC_NAME,ROUTINE_TYPE ,ROUTINE_SCHEMA FROM information_schema.Routines WHERE ROUTINE_SCHEMA="atguigu"; +---------------+--------------+----------------+ | SPECIFIC_NAME | ROUTINE_TYPE | ROUTINE_SCHEMA | +---------------+--------------+----------------+ | rand_num | FUNCTION | atguigu | | rand_string | FUNCTION | atguigu | | BatchInsert | PROCEDURE | atguigu | | insert_class | PROCEDURE | atguigu | | insert_order | PROCEDURE | atguigu | | insert_stu | PROCEDURE | atguigu | | insert_user | PROCEDURE | atguigu | | ts_insert | PROCEDURE | atguigu | +---------------+--------------+----------------+ 9 rows in set (0.02 sec)
下面备份atguigu库的数据,函数以及存储过程。
mysqldump -uroot -p -R -E --databases atguigu > fun_atguigu_bak.sql
查询备份文件中是否存在函数,如下所示,可以看到确实包含了函数。
grep -C 5 "rand_num" fun_atguigu_bak.sql
--
--
-- Dumping routines for database 'atguigu'--
/*!50003 DROP FUNCTION IF EXISTS `rand_num` */;/*!50003 SET @saved_cs_client = @@character_set_client */ ;/*!50003 SET @saved_cs_results = @@character_set_results */ ;/*!50003 SET @saved_col_connection = @@collation_connection */ ;/*!50003 SET character_set_client = utf8mb3 */ ;/*!50003 SET character_set_results = utf8mb3 */ ;/*!50003 SET collation_connection = utf8_general_ci */ ;/*!50003 SET @saved_sql_mode = @@sql_mode */ ;/*!50003 SET sql_mode ='ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_pISIO
N_BY_ZERO,NO_ENGINE_SUBSTITUTION' */ ;DELIMITER ;;CREATE DEFINER=`root`@`%` FUNCTION `rand_num`(from_num BIGINT ,to_num BIGINT) RETURNS
bigint
BEGIN
DECLARE i BIGINT DEFAULT 0;SET i = FLOOR(from_num +RAND()*(to_num - from_num+1)) ;RETURN i;END ;;--
BEGIN
DECLARE i INT DEFAULT 0;SET autocommit = 0;REPEAT
SET i = i + 1;INSERT INTO class ( classname,address,monitor ) VALUES(rand_string(8),rand_string(10),rand_num());UNTIL i = max_num
END REPEAT;COMMIT;END ;;DELIMITER ;--
BEGIN
DECLARE i INT DEFAULT 0;SET autocommit = 0; #设置手动提交事务REPEAT #循环SET i = i + 1; #赋值INSERT INTO order_test (order_id, trans_id ) VALUES(rand_num(1,7000000),rand_num(100000000000000000,700000000000000000));UNTIL i = max_num
END REPEAT;COMMIT; #提交事务END ;;DELIMITER ;--
BEGIN
DECLARE i INT DEFAULT 0;SET autocommit = 0; #设置手动提交事务REPEAT #循环SET i = i + 1; #赋值INSERT INTO student (stuno, name ,age ,classId ) VALUES((START+i),rand_string(6),rand_num(),rand_num());UNTIL i = max_num
END REPEAT;COMMIT; #提交事务END ;;DELIMITER ;--
BEGIN
DECLARE i INT DEFAULT 0;SET autocommit = 0;REPEAT
SET i = i + 1;INSERT INTO `user` ( name,age,sex ) VALUES ("atguigu",rand_num(1,20),"male");UNTIL i = max_num
END REPEAT;COMMIT;END ;;DELIMITER ;
三、mysql命令恢复数据
使用mysqldump命令将数据库中的数据备份成一个文本文件。需要恢复时,可以使用mysql命令来恢复备份的数据。
mysql命令可以执行备份文件中的CREATE语句和INSERT语句。通过CREATE语句来创建数据库和表。通过INSERT语句来插入备份的数据。
基本语法:
mysql –u root –p [dbname] <p>其中,dbname参数表示数据库名称。该参数是可选参数,可以指定数据库名,也可以不指定。指定数据库名时,表示还原该数据库下的表。此时需要确保MySQL服务器中已经创建了该名的数据库。不指定数据库名时,表示还原文件中所有的数据库。此时sql文件中包含有CREATE DATABASE语句,不需要MysQL服务器中已存在这些数据库。</p><h2>3.1 单库备份中恢复单库</h2><p>使用root用户,将之前练习中备份的atguigu.sql文件中的备份导入数据库中,命令如下:</p><p>如果备份文件中包含了创建数据库的语句,则恢复的时候不需要指定数据库名称,如下所示</p><pre class="brush:php;toolbar:false">#备份文件中包含了创建数据库的语句mysql -uroot -p <p>否则需要指定数据库名称,如下所示</p><pre class="brush:php;toolbar:false">#备份文件中不包含了创建数据库的语句mysql -uroot -p atguigu4<h2>3.2 全量备份恢复</h2><p>如果我们现在有昨天的全量备份,现在想整个恢复,则可以这样操作:</p><pre class="brush:php;toolbar:false">mysql –u root –p <pre class="brush:php;toolbar:false">mysql -uroot -pxxxxxx <p>执行完后,MySQL数据库中就已经恢复了all.sql文件中的所有数据库。</p><blockquote><p>补充:<br> 如果使用<code>--all-databases</code>参数备份了所有的数据库,那么恢复时不需要指定数据库。对应的sql文件包含有CREATE DATABASE语句,可通过该语句创建数据库。创建数据库后,可以执行sql文件中的USE语句选择数据库,再创建表并插入记录。</p></blockquote><h2>3.3 从全量备份中恢复单库</h2><p>可能有这样的需求,比如说我们只想恢复某一个库,但是我们有的是整个实例的备份,这个时候我们可以从全量备份中分离出单个库的备份。</p><p>举例:</p><pre class="brush:php;toolbar:false">sed -n '/^-- Current Database: `atguigu`/,/^-- Current Database: `/p' all_database.sql > atguigu.sql #分离完成后我们再导入atguigu.sql即可恢复单个库
3.4 从单库备份中恢复单表
这个需求还是比较常见的。比如说我们知道哪个表误操作了,那么就可以用单表恢复的方式来恢复。
举例:我们有atguigu整库的备份,但是由于class表误操作,需要单独恢复出这张表。
cat atguigu.sql | sed -e '/./{H;$!d;}' -e 'x;/CREATE TABLE `class`/!d;q' > class_structure.sql
cat atguigu.sql | grep --ignore-case 'insert into `class`' > class_data.sql
#用shell语法分离出创建表的语句及插入数据的语句后 再依次导出即可完成恢复
use atguigu;
mysql> source class_structure.sql;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> source class_data.sql;
Query OK, 1 row affected (0.01 sec)四、物理备份:直接复制整个数据库
直接将MySQL中的数据库文件复制出来。这种方法最简单,速度也最快。MySQL的数据库目录位置不一定相同:
- 在Windows平台下,MySQL 8.0存放数据库的目录通常默认为
C:\ProgramData\MySQL\MySQL Server 8.0\Data或者其他用户自定义目录; - 在Linux平台下,数据库目录位置通常为/var/lib/mysql/;
- 在MAC OSX平台下,数据库目录位置通常为“/usr/local/mysql/data”
但为了保证备份的一致性。需要保证:
- 方式1:备份前,将服务器停止。
- 方式2:备份前,对相关表执行
FLUSH TABLES WITH READ LOCK操作。这样当复制数据库目录中的文件时,允许其他客户继续查询表。同时,FLUSH TABLES语句来确保开始备份前将所有激活的索引页写入硬盘。
这种方式方便、快速,但不是最好的备份方法,因为实际情况可能不允许停止MySQL服务器或者锁住表,而且这种方法对InnoDB存储引擎的表不适用。对于MyISAM存储引擎的表,这样备份和还原很方便,但是还原时最好是相同版本的MySQL数据库,否则可能会存在文件类型不同的情况。
注意,物理备份完毕后,执行UNLOCK TABLES来结算其他客户对表的修改行为。
说明: 在MySQL版本号中,第一个数字表示主版本号,主版本号相同的MySQL数据库文件格式相同。
此外,还可以考虑使用相关工具实现备份。比如,MySQLhotcopy工具。MySQLhotcopy是一个Perl脚本,它使用LOCK TABLES、FLUSH TABLES和cp或scp来快速备份数据库。它是备份数据库或单个表最快的途径,但它只能运行在数据库目录所在的机器上,并且只能备份MyISAM类型的表。多用于mysql5.5之前。
五、物理恢复:直接复制到数据库目录
步骤:
- 演示删除备份的数据库中指定表的数据
- 将备份的数据库数据拷贝到数据目录下,并重启MySQL服务器
- 查询相关表的数据是否恢复。需要使用下面的 chown 操作。
要求:
- 必须确保备份数据的数据库和待恢复的数据库服务器的主版本号相同。
- 因为只有MySQL数据库主版本号相同时,才能保证这两个MySQL数据库文件类型是相同的。
- 这种方式对
MyISAM类型的表比较有效,对于InnoDB类型的表则不可用。- 因为InnoDB表的表空间不能直接复制。
- 在Linux操作系统下,复制到数据库目录后,一定要将数据库的用户和组变成mysql,命令如下:
chown -R mysql.mysql /var/lib/mysql/dbname
其中,两个mysql分别表示组和用户;“-R”参数可以改变文件夹下的所有子文件的用户和组;“dbname”参数表示数据库目录。
提示 Linux操作系统下的权限设置非常严格。通常情况下,MySQL数据库只有root用户和mysql用户组下的mysql用户才可以访问,因此将数据库目录复制到指定文件夹后,一定要使用chown命令将文件夹的用户组变为mysql,将用户变为mysql。
六、表的导出与导入
6.1 表的导出
1. 使用SELECT…INTO OUTFILE导出文本文件
在MySQL中,可以使用SELECT…INTO OUTFILE语句将表的内容导出成一个文本文件。
举例:使用SELECT…INTO OUTFILE将atguigu数据库中account表中的记录导出到文本文件。
(1)选择数据库atguigu,并查询account表,执行结果如下所示。
use atguigu; select * from account; mysql> select * from account; +----+--------+---------+ | id | name | balance | +----+--------+---------+ | 1 | 张三 | 90 | | 2 | 李四 | 100 | | 3 | 王五 | 0 | +----+--------+---------+ 3 rows in set (0.01 sec)
(2)mysql默认对导出的目录有权限限制,也就是说使用命令行进行导出的时候,需要指定目录进行操作。
查询secure_file_priv值:
mysql> SHOW GLOBAL VARIABLES LIKE '%secure%'; +--------------------------+-----------------------+ | Variable_name | Value | +--------------------------+-----------------------+ | require_secure_transport | OFF | | secure_file_priv | /var/lib/mysql-files/ | +--------------------------+-----------------------+ 2 rows in set (0.02 sec)
参数secure_file_priv的可选值和作用分别是:
- 如果设置为empty,表示不限制文件生成的位置,这是不安全的设置;
- 如果设置为一个表示路径的字符串,就要求生成的文件只能放在这个指定的目录,或者它的子目录;
- 如果设置为NULL,就表示禁止在这个MySQL实例上执行select … into outfile操作。
(3)上面结果中显示,secure_file_priv变量的值为/var/lib/mysql-files/,导出目录设置为该目录,SQL语句如下。
SELECT * FROM account INTO OUTFILE "/var/lib/mysql-files/account.txt";
(4)查看 /var/lib/mysql-files/account.txt`文件。
1 张三 902 李四 1003 王五 0
2. 使用mysqldump命令导出文本文件
举例1:使用mysqldump命令将将atguigu数据库中account表中的记录导出到文本文件:
mysqldump -uroot -p -T "/var/lib/mysql-files/" atguigu account
mysqldump命令执行完毕后,在指定的目录/var/lib/mysql-files/下生成了account.sql和account.txt文件。
打开account.sql文件,其内容包含创建account表的CREATE语句。
[root@node1 mysql-files]# cat account.sql -- MySQL dump 10.13 Distrib 8.0.26, for Linux (x86_64) -- -- Host: localhost Database: atguigu -- ------------------------------------------------------ -- Server version 8.0.26 /*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */; /*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */; /*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */; /*!50503 SET NAMES utf8mb4 */; /*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */; /*!40103 SET TIME_ZONE='+00:00' */; /*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='' */; /*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */; -- -- Table structure for table `account` -- DROP TABLE IF EXISTS `account`; /*!40101 SET @saved_cs_client = @@character_set_client */; /*!50503 SET character_set_client = utf8mb4 */; CREATE TABLE `account` ( `id` int NOT NULL AUTO_INCREMENT, `name` varchar(255) NOT NULL, `balance` int NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb3; /*!40101 SET character_set_client = @saved_cs_client */; /*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */; /*!40101 SET SQL_MODE=@OLD_SQL_MODE */; /*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */; /*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */; /*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */; /*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */; -- Dump completed on 2022-01-07 23:19:27
打开account.txt文件,其内容只包含account表中的数据。
[root@node1 mysql-files]# cat account.txt1 张三 902 李四 1003 王五 0
举例2:使用mysqldump将atguigu数据库中的account表导出到文本文件,使用FIELDS选项,要求字段之间使用逗号“,”间隔,所有字符类型字段值用双引号括起来:
mysqldump -uroot -p -T "/var/lib/mysql-files/" atguigu account --fields-terminatedby=',' --fields-optionally-enclosed-by='\"'
语句mysqldump语句执行成功之后,指定目录下会出现两个文件account.sql和account.txt。
打开account.sql文件,其内容包含创建account表的CREATE语句。
[root@node1 mysql-files]# cat account.sql -- MySQL dump 10.13 Distrib 8.0.26, for Linux (x86_64) -- -- Host: localhost Database: atguigu -- ------------------------------------------------------ -- Server version 8.0.26 /*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */; /*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */; /*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */; /*!50503 SET NAMES utf8mb4 */; /*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */; /*!40103 SET TIME_ZONE='+00:00' */; /*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='' */; /*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */; -- -- Table structure for table `account` -- DROP TABLE IF EXISTS `account`; /*!40101 SET @saved_cs_client = @@character_set_client */; /*!50503 SET character_set_client = utf8mb4 */; CREATE TABLE `account` ( `id` int NOT NULL AUTO_INCREMENT, `name` varchar(255) NOT NULL, `balance` int NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb3; /*!40101 SET character_set_client = @saved_cs_client */; /*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */; /*!40101 SET SQL_MODE=@OLD_SQL_MODE */; /*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */; /*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */; /*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */; /*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */; -- Dump completed on 2022-01-07 23:36:39
打开account.txt文件,其内容包含创建account表的数据。从文件中可以看出,字段之间用逗号隔开,字符类型的值被双引号括起来。
[root@node1 mysql-files]# cat account.txt1,"张三",902,"李四",1003,"王五",0
3. 使用mysql命令导出文本文件
举例1:使用mysql语句导出atguigu数据中account表中的记录到文本文件:
mysql -uroot -p --execute="SELECT * FROM account;" atguigu> "/var/lib/mysqlfiles/account.txt"
打开account.txt文件,其内容包含创建account表的数据。
[root@node1 mysql-files]# cat account.txtid name balance1 张三 902 李四 1003 王五 0
举例2:将atguigu数据库account表中的记录导出到文本文件,使用–veritcal参数将该条件记录分为多行显示:
mysql -uroot -p --vertical --execute="SELECT * FROM account;" atguigu >"/var/lib/mysql-files/account_1.txt"
打开account_1.txt文件,其内容包含创建account表的数据。
[root@node1 mysql-files]# cat account_1.txt*************************** 1. row *************************** id: 1name: 张三 balance: 90*************************** 2. row *************************** id: 2name: 李四 balance: 100*************************** 3. row *************************** id: 3name: 王五 balance: 0
举例3:将atguigu数据库account表中的记录导出到xml文件,使用–xml参数,具体语句如下。
mysql -uroot -p --xml --execute="SELECT * FROM account;" atguigu>"/var/lib/mysqlfiles/account_3.xml"
[root@node1 mysql-files]# cat account_3.xml <?xml version="1.0"?> <resultset xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <row> <field>1</field> <field>张三</field> <field>90</field> </row> <row> <field>2</field> <field>李四</field> <field>100</field> </row> <row> <field>3</field> <field>王五</field> <field>0</field> </row> </resultset>
说明:如果要将表数据导出到html文件中,可以使用--html选项。然后可以使用浏览器打开。
6.2 表的导入
1. 使用LOAD DATA INFILE方式导入文本文件
举例1:
使用SELECT…INTO OUTFILE将atguigu数据库中account表的记录导出到文本文件
SELECT * FROM atguigu.account INTO OUTFILE '/var/lib/mysql-files/account_0.txt';
删除account表中的数据:
DELETE FROM atguigu.account;
从文本文件account.txt中恢复数据:
LOAD DATA INFILE '/var/lib/mysql-files/account_0.txt' INTO TABLE atguigu.account;
查询account表中的数据:
mysql> select * from account; +----+--------+---------+ | id | name | balance | +----+--------+---------+ | 1 | 张三 | 90 | | 2 | 李四 | 100 | | 3 | 王五 | 0 | +----+--------+---------+ 3 rows in set (0.00 sec)
举例2: 选择数据库atguigu,使用SELECT…INTO OUTFILE将atguigu数据库account表中的记录导出到文本文件,使用FIELDS选项和LINES选项,要求字段之间使用逗号","间隔,所有字段值用双引号括起来:
SELECT * FROM atguigu.account INTO OUTFILE '/var/lib/mysql-files/account_1.txt' FIELDS TERMINATED BY ',' ENCLOSED BY '\"';
删除account表中的数据:
DELETE FROM atguigu.account;
从/var/lib/mysql-files/account.txt中导入数据到account表中:
LOAD DATA INFILE '/var/lib/mysql-files/account_1.txt' INTO TABLE atguigu.account FIELDS TERMINATED BY ',' ENCLOSED BY '\"';
查询account表中的数据,具体SQL如下:
select * from account; mysql> select * from account; +----+--------+---------+ | id | name | balance | +----+--------+---------+ | 1 | 张三 | 90 | | 2 | 李四 | 100 | | 3 | 王五 | 0 | +----+--------+---------+ 3 rows in set (0.00 sec)
2. 使用mysqlimport方式导入文本文件
举例:
导出文件account.txt,字段之间使用逗号","间隔,字段值用双引号括起来:
SELECT * FROM atguigu.account INTO OUTFILE '/var/lib/mysql-files/account.txt' FIELDS TERMINATED BY ',' ENCLOSED BY '\"';
删除account表中的数据:
DELETE FROM atguigu.account;
使用mysqlimport命令将account.txt文件内容导入到数据库atguigu的account表中:
mysqlimport -uroot -p atguigu '/var/lib/mysql-files/account.txt' --fields-terminatedby=',' --fields-optionally-enclosed-by='\"'
查询account表中的数据:
select * from account; mysql> select * from account; +----+--------+---------+ | id | name | balance | +----+--------+---------+ | 1 | 张三 | 90 | | 2 | 李四 | 100 | | 3 | 王五 | 0 | +----+--------+---------+ 3 rows in set (0.00 sec)
七、数据库迁移
7.1 概述
数据迁移(data migration)是指选择、准备、提取和转换数据,并 将数据从一个计算机存储系统永久地传输到另一个计算机存储系统的过程 。此外,验证迁移数据的完整性和退役原来旧的数据存储,也被认为是整个数据迁移过程的一部分。
数据库迁移的原因是多样的,包括服务器或存储设备更换、维护或升级,应用程序迁移,网站集成,灾难恢复和数据中心迁移。
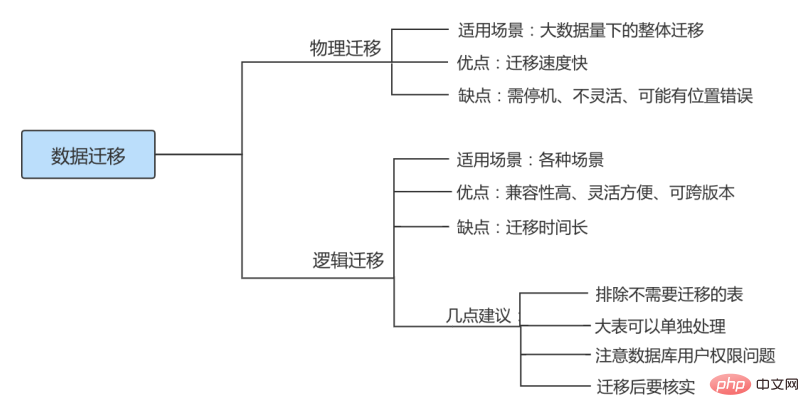
根据不同的需求可能要采取不同的迁移方案,但总体来讲,MySQL 数据迁移方案大致可以分为物理迁移和逻辑迁移两类。通常以尽可能自动化的方式执行,从而将人力资源从繁琐的任务中解放出来。
7.2 迁移方案
物理迁移
物理迁移适用于大数据量下的整体迁移。使用物理迁移方案的优点是比较快速,但需要停机迁移并且要求 MySQL 版本及配置必须和原服务器相同,也可能引起未知问题。
物理迁移包括拷贝数据文件和使用 XtraBackup 备份工具两种。
不同服务器之间可以采用物理迁移,我们可以在新的服务器上安装好同版本的数据库软件,创建好相同目录,建议配置文件也要和原数据库相同,然后从原数据库方拷贝来数据文件及日志文件,配置好文件组权限,之后在新服务器这边使用 mysqld 命令启动数据库。
逻辑迁移
逻辑迁移适用范围更广,无论是 部分迁移 还是 全量迁移 ,都可以使用逻辑迁移。逻辑迁移中使用最多的就是通过 mysqldump 等备份工具。
7.3 迁移注意点
① 相同版本的数据库之间迁移注意点
指的是在主版本号相同的MySQL数据库之间进行数据库移动。
方式1: 因为迁移前后MySQL数据库的主版本号相同,所以可以通过复制数据库目录来实现数据库迁移,但是物理迁移方式只适用于MyISAM引擎的表。对于InnoDB表,不能用直接复制文件的方式备份数据库。
方式2: 最常见和最安全的方式是使用mysqldump命令导出数据,然后在目标数据库服务器中使用MySQL命令导入。
举例:
#host1的机器中备份所有数据库,并将数据库迁移到名为host2的机器上mysqldump –h host1 –uroot –p –-all-databases|mysql –h host2 –uroot –p
在上述语句中,|符号表示管道,其作用是将mysqldump备份的文件给mysql命令;--all-databases表示要迁移所有的数据库。通过这种方式可以直接实现迁移。
② 不同版本的数据库之间迁移注意点
例如,原来很多服务器使用5.7版本的MySQL数据库,在8.0版本推出来以后,改进了5.7版本的很多缺陷,因此需要把数据库升级到8.0版本
旧版本与新版本的MySQL可能使用不同的默认字符集,例如有的旧版本中使用latin1作为默认字符集,而最新版本的MySQL默认字符集为utf8mb4。如果数据库中有中文数据,那么迁移过程中需要对默认字符集进行修改 ,不然可能无法正常显示数据。
高版本的MySQL数据库通常都会兼容低版本,因此可以从低版本的MySQL数据库迁移到高版本的MySQL数据库。
③ 不同数据库之间迁移注意点
不同数据库之间迁移是指从其他类型的数据库迁移到MySQL数据库,或者从MySQL数据库迁移到其他类型的数据库。这种迁移没有普适的解决方法。
迁移之前,需要了解不同数据库的架构,比较它们之间的差异。不同数据库中定义相同类型的数据的关键字可能会不同。例如,MySQL中日期字段分为DATE和TIME两种,而ORACLE日期字段只有DATE;SQL Server数据库中有ntext、Image等数据类型,MySQL数据库没有这些数据类型;MySQL支持的ENUM和SET类型,这些SQL Server数据库不支持。
另外,数据库厂商并没有完全按照SQL标准来设计数据库系统,导致不同的数据库系统的SQL语句有差别。例如,微软的SQL Server软件使用的是T-SQL语句,T-SQL中包含了非标准的SQL语句,不能和MySQL的SQL语句兼容。
不同类型数据库之间的差异造成了互相迁移的困难,这些差异其实是商业公司故意造成的技术壁垒。但是不同类型的数据库之间的迁移并不是完全不可能 。例如,可以使用MyODBC实现MySQL和SQL Server之间的迁移。MySQL官方提供的工具MySQL Migration Toolkit也可以在不同数据之间进行数据迁移。MySQL迁移到Oracle时,需要使用mysqldump命令导出sql文件,然后,手动更改sql文件中的CREATE语句。
7.4 迁移小结
八、删库了不敢跑,能干点啥?
传统的高可用架构是不能预防误删数据的,因为主库的一个drop table命令,会通过binlog传给所有从库和级联从库,进而导致整个集群的实例都会执行这个命令。
为了找到解决误删数据的更高效的方法,我们需要先对和MySQL相关的误删数据,做下分类:
- 使用delete语句误删数据行;
- 使用drop table或者truncate table语句误删数据表;
- 使用drop database语句误删数据库;
- 使用rm命令误删整个MySQL实例。
8.1 delete:误删行
处理措施1:数据恢复
使用Flashback工具恢复数据。
原理:修改binlog内容,拿回原库重放。如果误删数据涉及到了多个事务的话,需要将事务的顺序调过来再执行。
使用前提:binlog_format=row和binlog_row_image=FULL。
处理措施2:预防
代码上线前,必须
SQL审查、审计。建议可以打开
安全模式,把sql_safe_updates参数设置为on。强制要求加where条件且where后需要是索引字段,否则必须使用limit。否则就会报错。
8.2 truncate/drop: Pemadaman pangkalan data/jadual secara tidak sengaja
Latar Belakang:
Memadamkan keseluruhan jadual adalah sangat perlahan . Ia adalah perlu untuk menjana log rollback, menulis buat semula, dan menulis binlog. Oleh itu, dari perspektif prestasi, beri keutamaan untuk menggunakan perintah truncatetable atau drop table.
Anda juga boleh menggunakan Flashback untuk memulihkan data yang dipadam menggunakan arahan padam. Data yang dipadam menggunakan perintah truncate /drop table dan drop pangkalan data tidak boleh dipulihkan melalui Flashback. Kerana, walaupun kita mengkonfigurasi binlog_format=row, apabila melaksanakan ketiga-tiga arahan ini, binlog yang direkodkan masih dalam format pernyataan. Hanya terdapat satu penyataan truncate/drop dalam binlog, dan data tidak boleh dipulihkan daripada maklumat ini.
Penyelesaian :
Dalam kes ini, anda perlu menggunakan gabungan sandaran penuh dan log tambahan untuk memulihkan data.
Premis penyelesaian: sandaran penuh biasa dan sandaran masa nyata binlog.
Contoh: Seseorang telah tersilap memadam pustaka pada pukul 3 petang. Langkah-langkahnya adalah seperti berikut:
- Dapatkan yang terkini
全量备份. Andaikan bahawa pangkalan data disediakan untuk disandarkan sekali sehari, dan data sandaran terkini ialah hari itu凌晨2点; - Pulihkan satu daripada sandaran
临时库(Nota: Pilih pangkalan data sementara di sini bukannya mengendalikan pangkalan data utama secara langsung) - Keluarkan log binlog selepas 2 pagi;
- Kecuali pernyataan yang memadamkan data secara tidak sengaja, semua pernyataan lain digunakan pada pustaka sementara. (Saya bercakap tentang pemulihan binlog sebelum ini)
- Akhirnya pulihkan ke pangkalan data utama
8.3 Halang penggunaan truncate /drop untuk memadam pangkalan data/jadual secara tidak sengaja
Kami menyebut penggunaan di atas Pelan pemulihan untuk memadam perpustakaan/jadual secara tidak sengaja dengan penyataan truncate/drop boleh digunakan dalam persekitaran pengeluaran untuk mengelakkan salah operasi yang serupa sebanyak mungkin melalui penyelesaian yang dicadangkan berikut.
① Pemisahan kebenaran
- Hadkan kebenaran akaun pada umumnya
不能随便分配写权限. anda perlukan审批. Contohnya, hanya kebenaran DML diberikan kepada pembangun perniagaan, tetapi kebenaran memotong/menggugurkan tidak diberikan. Malah ahli pasukan DBA dikehendaki hanya menggunakan只读账号setiap hari dan hanya menggunakan akaun dengan kebenaran kemas kini apabila perlu. - Akaun yang berbeza dan data yang berbeza mesti
权限分离ed untuk mengelakkan satu akaun daripada memadamkan semua pustaka.
② Bangunkan spesifikasi pengendalian
Contohnya, sebelum memadamkan jadual data, anda mesti menamakan semula jadual terlebih dahulu (seperti menambah _to_be_deleted). Kemudian, amati untuk tempoh masa untuk memastikan tiada kesan ke atas perniagaan sebelum memadamkan jadual.
③ Tetapkan tunggu sedia replikasi tertunda
Ringkasnya, replikasi tertunda adalah untuk menetapkan masa tunda tetap, seperti 1 jam, supaya budak Perpustakaan adalah satu jam di belakang perpustakaan utama. Dalam masa 1 jam selepas operasi pemadaman tidak sengaja berlaku, laksanakan stop slave pada pangkalan data siap sedia ini, dan kemudian gunakan kaedah yang diperkenalkan sebelum ini untuk melangkau perintah operasi tidak sengaja untuk memulihkan data yang diperlukan. Di sini, melalui perintah CHANGE MASTER TO MASTER_DELAY = N, anda boleh menentukan bahawa pangkalan data siap sedia akan terus mengalami kelewatan N saat daripada pangkalan data utama. Sebagai contoh, tetapkan N kepada 3600, yang mewakili 1 jam.
Selain itu, replikasi tertunda juga boleh digunakan untuk menyelesaikan masalah berikut:
digunakan untuk melakukan
延迟测试, seperti pengasingan pangkalan data membaca dan menulis, menggunakan pangkalan data hamba sebagai Membaca perpustakaan, jika anda ingin tahu apa yang akan berlaku apabila data ditangguhkan, anda boleh menggunakan ciri ini untuk mensimulasikan kelewatan.digunakan untuk
老数据的查询等需求Contohnya, jika anda sering perlu menyemak nilai jadual atau medan pada hari tertentu, anda mungkin perlu memulihkan sandaran dan menyemaknya. . Jika terdapat kelewatan dari pangkalan data, contohnya Delay selama seminggu, maka keperluan serupa seperti ini dapat diselesaikan.
8.4 rm: Instance MySQL telah dipadam secara tidak sengaja
Untuk kluster MySQL dengan mekanisme ketersediaan tinggi, tidak perlu risau rm删除数据. Kerana jika hanya satu data nod dipadamkan, sistem HA akan memilih pangkalan data utama baharu untuk memastikan operasi normal keseluruhan kluster. Selepas kami memulihkan data pada nod ini, kami kemudian boleh menyambungkannya ke seluruh kluster.
Tetapi jika keseluruhan kluster dipadamkan secara berniat jahat, maka anda perlu mempertimbangkan sandaran bilik merentas mesin dan sandaran merentas bandar.
Pembelajaran yang disyorkan: tutorial video mysql
Atas ialah kandungan terperinci Fahami cara membuat sandaran dan memulihkan pangkalan data MySQL dalam satu artikel. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!