
Rumah >pangkalan data >tutorial mysql >Membawa anda melalui indeks MySQL
Membawa anda melalui indeks MySQL

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2022-04-22 11:48:382776semak imbas
Artikel ini membawa anda pengetahuan yang berkaitan tentang mysql Ia terutamanya memperkenalkan beberapa isu dalam bab mysql lanjutan, termasuk apa itu indeks, pelaksanaan asas indeks, dsb. Mari kita bincangkan bersama di bawah. Sila lihat, semoga ia membantu semua orang.

Pembelajaran yang disyorkan: tutorial video mysql
MySQL, istilah yang biasa dan tidak dikenali, seawal Semasa kami belajar Javaweb, kami menggunakan pangkalan data MySQL Pada peringkat itu, MySQL nampaknya hanya satu perkara yang baik untuk menyimpan data Apabila menyimpan, kami memasukkan semuanya, dan apabila bertanya, kami juga membuta tuli seluruh jadual (tanpa sedikit maklumat).
Kami sentiasa menipu diri sendiri dan orang lain dengan berfikir bahawa kami boleh mengoptimumkan melalui aspek lain Kami enggan menghadapi MySQL Advanced dan sebaliknya mempelajari sesuatu yang kelihatan lebih maju " perkara, pelajari Redis untuk berkongsi tekanan MySQL, pelajari perisian tengah seperti MyCat, dan laksanakan replikasi tuan-hamba, pemisahan baca-tulis, sub-pangkalan data dan sub -mejaTunggu. (Saya bercakap tentang melo, betul)
Apabila tiba masa untuk membuat persediaan untuk temuduga, saya mendapati bahawa saya tidak tahu semua soalan tentang MySQL dalam soalan temuduga~
Mengenai middleware canggih yang saya pelajari, saya bertanya Dapatkan hampir sangat sedikit! ! Saya hanya tahu cara menggunakannya. Semasa menulis resume saya, saya hanya boleh menulis "pemahaman" xxx middleware dengan lemah...
Sudah tentu, belajar MySQL Advanced Chapter bukanlah hanya untuk Temuduga, dalam projek sebenar, pengoptimuman kawasan ini adalah sangat penting Selepas mengalami downtime pelayan, saya hanya boleh diam...
Mari kita mulakan dari sekarang, masih terlambat untuk pergi ke darat. ! ! Mengambil kesempatan daripada emas tiga dan perak empat, tambah mata pengetahuan MySQL Advanced Chapter dan mulakan perjalanan MySQL Advanced Chapter dari aspek berikut
Adalah disyorkan untuk pergi melalui direktori bar sisi Cari bahagian yang membantu anda Antaranya, dengan awalan emoji ialah bahagian utama Jika anda rasa ia membantu anda, editor akan meneruskan untuk menambah baik artikel ini dan lajur MySQL.
Takrif indeks
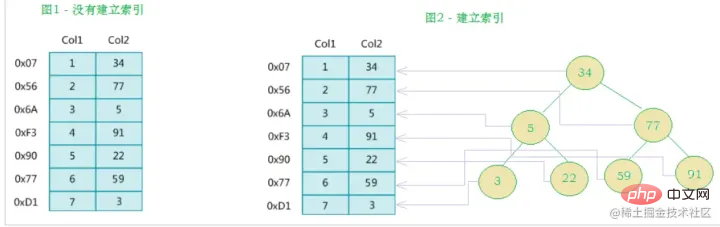
Takrifan rasmi MySQL bagi indeks ialah: Indeks (indeks) ialah struktur data (tersusun) yang membantu MySQL memperoleh data dengan cekap. Indeks ditambahkan pada medan dalam jadual pangkalan data sebagai mekanisme untuk meningkatkan kecekapan pertanyaan. Selain data, sistem pangkalan data juga mengekalkan struktur data yang memenuhi algoritma carian tertentu Struktur data ini merujuk (menunjukkan) data dalam beberapa cara, supaya algoritma carian lanjutan boleh dilaksanakan pada struktur data ini indeks. Seperti yang ditunjukkan dalam rajah di bawah:
Malah, secara ringkasnya, indeks ialah struktur data yang diisih
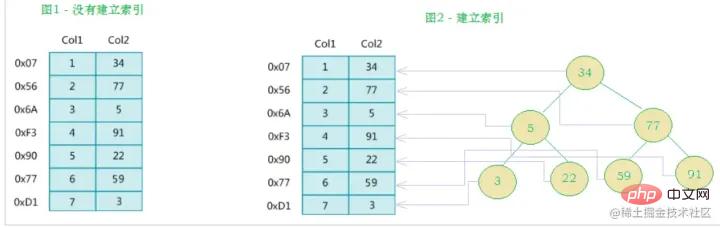
Sebelah kiri ialah Jadual data mempunyai jumlah dua lajur dan tujuh rekod Yang paling kiri ialah alamat fizikal rekod data (perhatikan bahawa rekod bersebelahan secara logik tidak semestinya bersebelahan secara fizikal pada cakera). Untuk mempercepatkan carian Col2, anda boleh mengekalkan pepohon carian binari seperti yang ditunjukkan di sebelah kanan Setiap nod mengandungi nilai kunci indeks dan penunjuk ke alamat fizikal rekod data yang sepadan. , jadi Anda boleh menggunakan carian binari untuk mendapatkan data yang sepadan dengan cepat.
Kelebihan indeks
- Mempercepatkan kelajuan carian dan isih, mengurangkan kos IO pangkalan data dan penggunaan CPU
- Dengan mencipta indeks yang unik, keunikan setiap baris data dalam jadual pangkalan data boleh dijamin.
Kelemahan indeks
- Indeks sebenarnya adalah jadual, yang menyimpan kunci utama dan medan indeks dan menunjuk kepada rekod entiti kelas, yang memerlukan ruang Menduduki
- Walaupun kecekapan pertanyaan ditingkatkan, untuk penambahan, pemadaman dan pengubahsuaian, setiap kali jadual ditukar, indeks perlu dikemas kini: Baharu, nod baharu perlu ditambah dalam pepohon indeks. Padam: Rekod yang ditunjukkan dalam pepohon indeks mungkin akan menjadi tidak sah, yang bermaksud bahawa banyak nod dalam pepohon indeks ini adalah perubahan tidak sah: yang menunjuk ke nod dalam pepohon indeks mungkin perlu ditukar kepada
Tetapi sebenarnya, Kami tidak menggunakan Binary Search Tree untuk menyimpan data dalam MySQL Mengapa?
Anda tahu, dalam pepohon carian binari, nod di sini hanya boleh menyimpan satu keping data dan nod sepadan dengan blok cakera dalam MySQL, jadi kami membaca satu blok cakera setiap kali , hanya satu keping data boleh diperolehi, yang sangat tidak cekap, jadi kami akan memikirkan untuk menggunakan struktur seperti B-tree untuk menyimpannya.
Struktur indeks
Indeks dilaksanakan dalam lapisan enjin storan MySQL, bukan dalam lapisan pelayan. Oleh itu, indeks setiap enjin storan tidak semestinya sama, dan tidak semua enjin menyokong semua jenis indeks.
- Indeks BTREE : Jenis indeks yang paling biasa, kebanyakan indeks menyokong indeks B-tree.
- Indeks HASH: Hanya disokong oleh enjin Memori, senario penggunaannya mudah.
- Indeks R-tree (indeks ruang) : Indeks ruang ialah jenis indeks khas enjin MyISAM Ia digunakan terutamanya untuk jenis data geospatial diperkenalkan khas.
- Teks penuh (indeks teks penuh) : Indeks teks penuh juga merupakan jenis indeks khas MyISAM, terutamanya digunakan untuk indeks teks penuh InnoDB menyokong permulaan indeks teks penuh daripada versi Mysql5.6.
Enjin storan MyISAM, InnoDB dan Memory menyokong pelbagai jenis indeks
|
enjin INNODB | enjin MYISAM | Enjin MEMORI | ||||||||||||||||||||
| Indeks BTREE | Disokong | Disokong | Sokongan | ||||||||||||||||||||
| Indeks HASH | Tiada Sokongan | Tidak menyokong | Sokongan | ||||||||||||||||||||
| Indeks R-tree | Tidak disokong | Disokong | Tidak disokong | ||||||||||||||||||||
| Teks Penuh | Disokong selepas versi 5.6 | Disokong | Tidak disokong |
Apa yang biasanya kita panggil indeks, melainkan dinyatakan sebaliknya, merujuk kepada indeks yang disusun dalam struktur B-tree (pokok carian berbilang hala, tidak semestinya binari). Antaranya, indeks berkelompok, indeks kompaun, indeks awalan dan indeks unik semuanya menggunakan indeks pepohon B secara lalai, secara kolektif dipanggil indeks.
BTREE
Pokok carian seimbang berbilang hala, pesanan m (m-garpu) BTREE memenuhi:
- Setiap nod mempunyai paling banyak m anak daripada kanak-kanak: ceil(m/2) hingga m Bilangan kata kunci: ceil(m/2)-1 hingga m-1
ceil bermaksud pembulatan, ceil(2.3)=3
Masukkan kes kata kunci

Dijamin tidak memusnahkan sifat-sifat m-order B-tree
Disebabkan oleh ke-3 tertib, ia hanya boleh menjadi 2 pada kebanyakan nod, jadi 26 dan 30 bersama-sama pada permulaan, dan kemudian 85 akan mula berpecah 30 akan menjadi kedudukan atas di tengah, 26 akan kekal, dan 85 akan pergi ke kanan
, iaitu: kedudukan atas di tengah , dan kemudian Bahagian kiri kekal di nod lama, dan sebelah kanan pergi ke nod baharu
. Apabila 70 dalam gambar dimasukkan semula, 70 kebetulan berada di kedudukan tengah, kemudian 62 dikekalkan, dan 85 dibahagikan kepada nod baharu. Selepas naik ke atas, ia perlu berpecah
Anda boleh terus berpecah ke atas, perkara yang sama berlaku 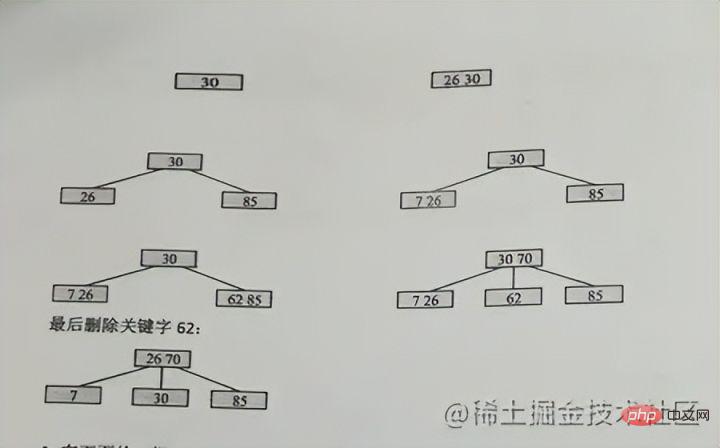
Berbanding dengan pepohon carian binari, ketinggian/kedalaman lebih rendah dan kecekapan pertanyaan semula jadi lebih tinggi.Kelebihan perbandingan
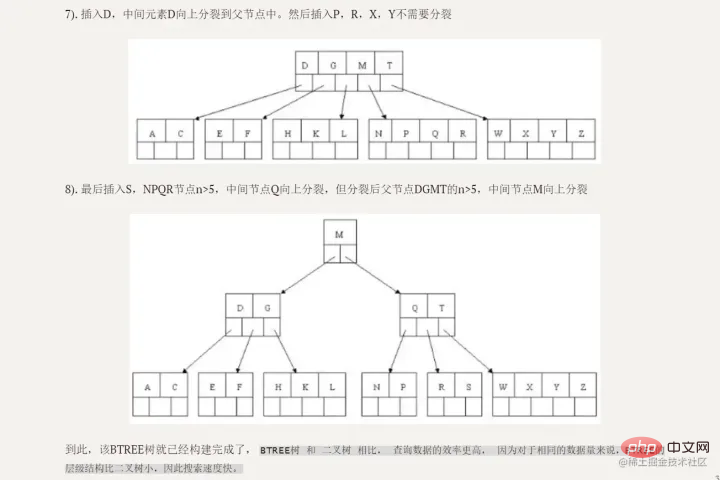 POKOK B
POKOK B
nod indeks
) dannod daun
. Nod dalaman ialah nod bukan daun. Nod dalaman tidak menyimpan data, hanya indeks dan data disimpan dalam nod daun.- Kunci dalam nod dalaman disusun mengikut urutan dari kecil ke besar Untuk kunci dalam nod dalaman, semua kunci dalam pepohon kiri adalah lebih kecil daripadanya, dan semuanya kekunci dalam subpokok kanan lebih kecil daripadanya. Kekunci semuanya lebih besar daripada atau sama dengannya. Rekod dalam nod daun juga disusun mengikut saiz kunci. Setiap nod daun menyimpan penunjuk ke nod daun bersebelahan Nod daun itu sendiri disambungkan mengikut urutan dari kecil ke besar mengikut saiz kata kunci
- . Nod induk menyimpan indeks elemen pertama
- anak kanan.
- Kelebihan Berbanding
Kecekapan pertanyaan B Tree adalah 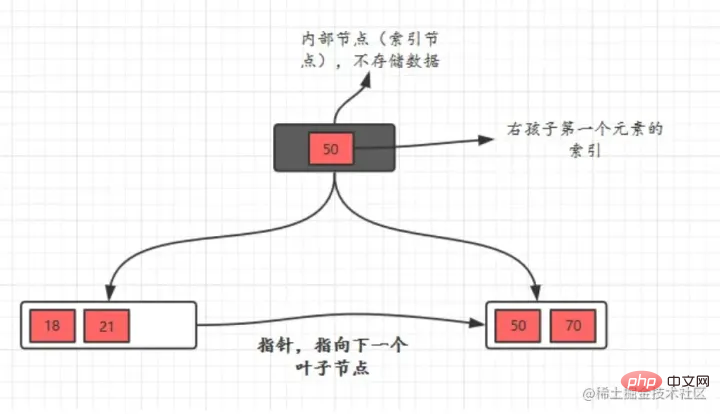 lebih stabil
lebih stabil
- B Tree dalam MySQL Struktur data indeks MySql mengoptimumkan B Tree klasik. Berdasarkan Pokok B asal, menambah
- penuding senarai terpaut yang menghala ke nod daun bersebelahan (struktur keseluruhan adalah serupa dengan senarai terpaut berganda) membentuk Pokok B dengan penuding berjujukan untuk meningkatkan prestasi akses selang waktu.
Beralih daripada
pokok carian binari kepada B-tree
- Rajah struktur indeks B pokok dalam MySQL:
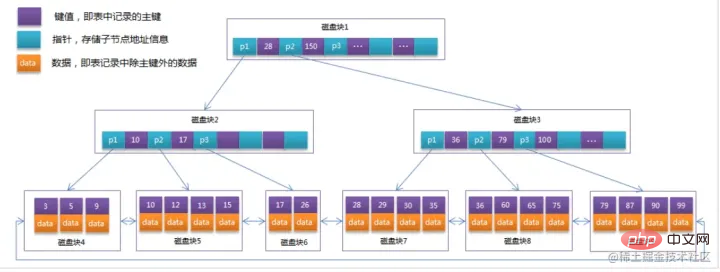
BTREE INDEX:
 Pengenalan Inisialisasi
Pengenalan Inisialisasi
Blue cahaya yang dipanggil blok cakera item (ditunjukkan dalam warna biru tua) dan penunjuk (ditunjukkan dalam warna kuning)
Contohnya, blok cakera 1 mengandungi item data 17 dan 35, termasuk penunjuk P1, P2 dan P3P1 mewakili blok cakera kurang daripada 17 , dan P2 Mewakili blok cakera antara 17 dan 35, P3 mewakili blok cakera lebih daripada 35.
- Data sebenar wujud dalam nod daun iaitu 3, 5, 9, 10, 13, 15, 28, 29, 36, 60, 75, 79, 90, 99. `
- Nod bukan daun tidak menyimpan data sebenar, tetapi hanya menyimpan item data yang memandu arah carian Contohnya, 17 dan 35 sebenarnya tidak wujud dalam jadual data. `
Proses carian
Jika anda ingin mencari data item 29, maka blok cakera 1 mula-mula akan dimuatkan dari cakera ke memori, dan IO akan berlaku pada masa ini . Gunakan carian binari dalam ingatan untuk menentukan bahawa 29 adalah antara 17 dan 35, dan kunci penunjuk P2 bagi blok cakera 1. Masa memori boleh diabaikan kerana ia sangat singkat (berbanding dengan IO cakera alamat penuding P2 blok cakera 1 ke blok cakera 3 dimuatkan dari cakera ke dalam memori IO kedua berlaku di antara 26 dan 30. Penunjuk P2 blok cakera 8 dimuatkan ke dalam memori melalui penunjuk IO ketiga berlaku Pada masa yang sama, memori berlalu Carian binari mencapai 29 dan menamatkan pertanyaan, menghasilkan sejumlah tiga IO.
Situasi sebenar ialah pokok B 3 lapisan boleh mewakili berjuta-juta data Jika berjuta-juta carian data hanya memerlukan tiga IO, peningkatan prestasi akan menjadi besar Jika tiada indeks, setiap data Jika IO berlaku untuk setiap item, sejumlah berjuta-juta IO akan diperlukan. Jelas sekali, kosnya sangat tinggi.
Klasifikasi indeks
Dalam InnoDB, jadual disimpan dalam bentuk indeks mengikut susunan kunci utama Jadual yang disimpan dengan cara ini dipanggil jadual tersusun indeks. Dan kerana kami nyatakan sebelum ini, InnoDB menggunakan model indeks B-tree, jadi data disimpan dalam B-tree.
Setiap indeks sepadan dengan pokok B dalam InnoDB.
Katakan, kita mempunyai jadual dengan lajur kunci utama sebagai ID, terdapat medan k dalam jadual, dan terdapat indeks pada k.
Pernyataan penciptaan jadual bagi jadual ini ialah:
mysql> create table T( id int primary key, k int not null, name varchar(16), index (k))engine=InnoDB; 复制代码
Nilai (ID,k) bagi R1~R5 dalam jadual ialah (100,1), (200,2 ), (300,3) masing-masing ), (500,5) dan (600,6), contoh rajah skematik kedua-dua pokok adalah seperti berikut:
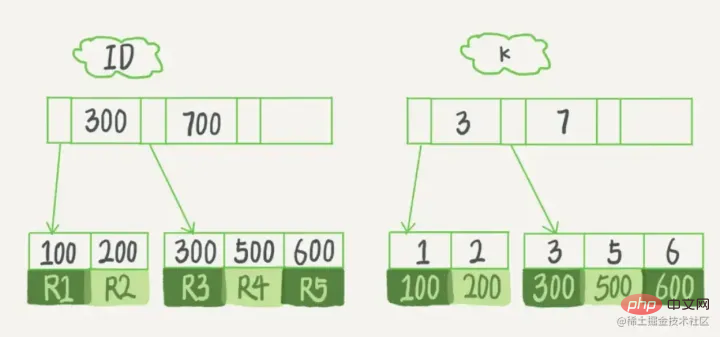
Tidak sukar untuk melihat dari rajah bahawa mengikut nod daun Kandungan, jenis indeks dibahagikan kepada indeks kunci utama dan indeks kunci bukan utama.
Indeks kunci utama
Lajur kunci utama jadual data menggunakan indeks kunci utama dan dicipta secara lalai Inilah sebabnya, sebelum kami mempelajari pengindeksan, guru sering menyuruh kami membuat pertanyaan berdasarkan kunci utama Ia akan menjadi lebih cepat Ternyata kunci utama itu sendiri diindeks. Nod daun
indeks kunci utama menyimpan keseluruhan baris data. Dalam InnoDB, indeks kunci utama juga dipanggil indeks berkelompok (indeks berkelompok). Kandungan nod daun
indeks tambahan
indeks tambahan ialah nilai kunci utama. Dalam InnoDB, indeks tambahan juga dipanggil indeks kedua (indeks kedua).
Seperti yang ditunjukkan di bawah:
- Indeks kunci utama menyimpan keseluruhan baris data
- Indeks tambahan hanya menyimpan dirinya sendiri dan id Kunci utama digunakan untuk pertanyaan jadual
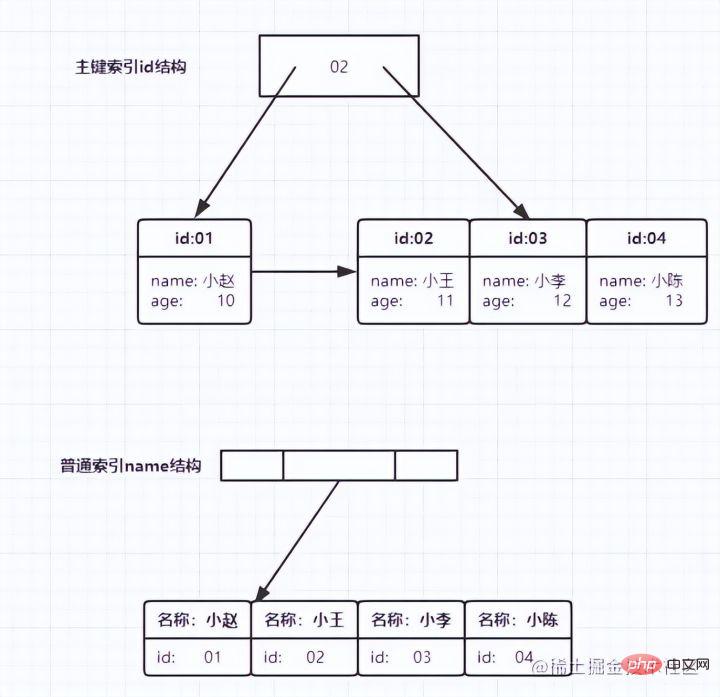
Mengikut struktur indeks di atas, mari kita bincangkan soalan: Apakah perbezaan antara pertanyaan berdasarkan indeks kunci primer dan indeks tambahan ?
- Jika penyataan dipilih * daripada T dengan ID=500, yang merupakan kaedah pertanyaan kunci utama, anda hanya perlu mencari pepohon B ID
- Jika pernyataan Ia pilih * daripada T di mana k=5, iaitu kaedah pertanyaan indeks biasa Anda perlu mencari pohon indeks k dahulu, dan dapatkan nilai ID 500. kemudian cari sekali dalam pepohon indeks ID . Proses ini dipanggil Kembali ke Jadual.
indeks tertutup-iaitu, lajur indeks mengandungi Semua data kami kepada dipersoalkan.
Pada masa yang sama, indeks sekunder dibahagikan kepada jenis berikut (langkau sahaja buat masa ini, kami akan mengetahui lebih lanjut mengenainya kemudian):
- Kunci Unik: Indeks unik juga merupakan kekangan. Data pendua tidak boleh muncul dalam lajur atribut indeks unik, tetapi data dibenarkan menjadi NULL. Jadual membolehkan penciptaan berbilang indeks unik. Selalunya, tujuan mewujudkan indeks unik adalah untuk keunikan data dalam lajur atribut, bukannya untuk kecekapan pertanyaan.
- Indeks Biasa (Indeks) : Satu-satunya fungsi indeks biasa ialah untuk menanya data dengan cepat Sesuatu jadual membenarkan penciptaan berbilang indeks biasa, dan membenarkan penduaan data dan NULL .
- Indeks Awalan (Awalan): Indeks awalan hanya terpakai pada data jenis rentetan. Indeks awalan mencipta indeks pada beberapa aksara pertama teks Berbanding dengan indeks biasa, data yang dibuat adalah lebih kecil kerana hanya beberapa aksara pertama diambil.
- Indeks Teks Penuh (Teks Penuh): Indeks teks penuh digunakan terutamanya untuk mendapatkan maklumat kata kunci dalam data teks besar Ia adalah teknologi yang digunakan oleh pangkalan data enjin carian. Sebelum Mysql5.6, hanya enjin MYISAM yang menyokong indeks teks penuh Selepas 5.6, InnoDB turut menyokong indeks teks penuh
Sambungan--tekan bawah indeks
Apa yang dipanggil pushdown. , seperti namanya, sebenarnya Tunda operasi pemulangan jadual kami , MySQL tidak akan membenarkan kami memulangkan jadual dengan mudah, kerana ia sangat membazir. Apakah maksudnya? Pertimbangkan contoh berikut.
Kami telah menubuhkan indeks komposit (nama, status, alamat), yang juga disimpan mengikut medan ini, sama seperti gambar:
Pokok indeks kompaun (hanya menyimpan lajur indeks dan Kunci utama digunakan untuk mengembalikan jadual)
|
status | alamat | id (kunci utama) | ||||||||||||
| Xiaomi 1 | 0 | 1 | 1 | ||||||||||||
| Xiaomi 2 | 1 | 1 | 2 |
我们执行这样一条语句:
SELECT name FROM tb_seller WHERE name like '小米%' and status ='1' ; 复制代码
- 首先我们在复合索引树上,找到了第一个以小米开头的name -- 小米1
- 此时我们不着急回表(回到主键索引树搜索的过程,我们称为回表),而是先在复合索引树判断status是否=1,此时status=0,我们直接就不回表了,直接继续找下一个以小米开头的name
- 找到第二个-- 小米2,判断status=1,则根据id=2去主键索引树上找,得到所有的数据
这种先在自身索引树上判断是否满足其他的where条件,不满足则直接pass掉,不进行回表的操作,就叫做索引下推。
最左前缀原则
所谓最左前缀,可以想象成一个爬楼梯的过程,假设我们有一个复合索引:name,status,address,那这个楼梯由低到高依次顺序是:name,status,address,最左前缀,要求我们不能出现跳跃楼梯的情况,否则会导致我们的索引失效:
- 按楼梯从低到高,无出现跳跃的情况--此时符合最左前缀原则,索引不会失效

- 出现跳跃的情况

- 直接第一层name都不走,当然都失效
- 走了第一层,但是后续直接第三层,只有出现跳跃情况前的不会失效(此处就只有name成功)
- 同时,这个顺序并不是由我们where中的排列顺序决定,比如: where name='小米科技' and status='1' and address='北京市' where status='1' and name='小米科技' and address='北京市'

这两个尽管where中字段的顺序不一样,第二个看起来越级了,但实际上效果是一样的
其实是因为我们MySQL有一个Optimizer(查询优化器),查询优化器会将SQL进行优化,选择最优的查询计划来执行。
- 关于这个查询优化器,后续文章我们也会谈谈MySQL的逻辑架构与存储引擎
索引设计原则
针对表
- 查询频次高,且数据量多的表
针对字段
- 最好从where子句的条件中提取,如果where子句中的组合比较多,那么应当挑选最常用、过滤效果最好的列的组合。
其他原则
- 最好用唯一索引,区分度越高,使用索引的效率越高
- 不是越多越好,维护也需要时间和空间代价,建议单张表索引不超过 5 个
因为 MySQL 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
比如:
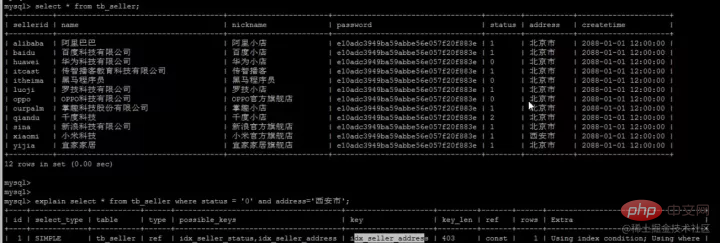
我们创建了三个单列索引,name,status,address
当我们where中根据status和address两个字段来查询时,数据库只会选择最优的一个索引,不会所有单列索引都使用。
最优的索引:具体是指所查询表中,辨识度最高(所占比例最少)的索引列,比如此处address中有一个辨识度很高的 '西安市'数据;
- 使用短索引,索引创建之后也是使用硬盘来存储的,因此提升索引访问的I/O效率,也可以提升总体的访问效率。假如构成索引的字段总长度比较短,那么在给定大小的存储块内可以存储更多的索引值,相应的可以有效的提升MySQL访问索引的I/O效率。
- 利用最左前缀,比如有N个字段,我们不一定需要创建N个索引,可以用复合索引
也就是说,我们尽量创建复合索引,而不是单列索引
创建复合索引: CREATE INDEX idx_name_email_status ON tb_seller(name,email,status); 就相当于 对name 创建索引 ; 对name , email 创建了索引 ; 对name , email, status 创建了索引 ; 复制代码
举个栗子
假设我们有这么一个表,id为主键,没有创建索引:
CREATE TABLE `tuser` ( `id` int(11) NOT NULL, `name` varchar(32) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`), ) ENGINE=InnoDB 复制代码
如果要在此处建立复合索引,我们要遵循什么原则呢?
通过调整顺序,可以少维护一个索引
- 比如我们的业务需求里边,有如下两种查询方式: 根据name查询 根据name和age查询
如果我们建立索引(age,name),由于最左前缀原则,我们这个索引能实现的是根据age,根据age和name查询,并不能单纯根据name查询(因为跳跃了),为了实现我们的需求,我们还得再建立一个name索引;
而如果我们通过调整顺序,改成(name,age),就能实现我们的需求了,无需再维护一个name索引,这就是通过调整顺序,可以少维护一个索引。
考虑空间->短索引
- 比如我们的业务需求里边,有以下两种查询方式: 根据name查询 根据age查询 根据name和age查询
我们有两种方案:
- 建立联合索引(name,age),建立单列索引:age索引。
- 建立联合索引(age,name),建立单列索引:name索引。
这两种方案都能实现我们的需求,这个时候我们就要考虑空间了,name字段是比age字段大的,显然方案1所耗费的空间是更小的,所以我们更倾向于方案1。
何时建立索引
- where中的查询字段
- 查询中与其他表关联的字段,比如外键
- 排序的字段
- 统计或分组的字段
何时达咩索引
- 表中数据量很少
- 经常改动的表
- 频繁更新的字段
- 数据重复且分布均匀的表字段(比如包含了很多重复数据,那此时多叉树的二分查找,其实用处不大,可以理解为O(logn)退化了)
索引相关语法
创建索引
默认会为主键创建索引--primary
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name [USING index_type] ON tbl_name(index_col_name,...) index_col_name : column_name[(length)][ASC | DESC] 复制代码
查找索引
结尾加上\G,可以变成竖屏显示
select index from tbl_name\G; 复制代码
删除索引
drop INDEX index_name on tbl_name ; 复制代码
变更索引
1). alter table tb_name add primary key(column_list); 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL 2). alter table tb_name add unique index_name(column_list); 这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次) 3). alter table tb_name add index index_name(column_list); 添加普通索引, 索引值可以出现多次。 4). alter table tb_name add fulltext index_name(column_list); 该语句指定了索引为FULLTEXT, 用于全文索引 复制代码
查看索引使用情况
show status like 'Handler_read%'; -- 查看当前会话索引使用情况 show global status like 'Handler_read%'; -- 查看全局索引使用情况 复制代码
Handler_read_first:索引中第一条被读的次数。如果较高,表示服务器正执行大量全索引扫描(这个值越低越好)。
Handler_read_key:如果索引正在工作,这个值代表一个行被索引值读的次数,如果值越低,表示索引得到的性能改善不高,因为索引不经常使用(这个值越高越好)。
Handler_read_next :按照键顺序读下一行的请求数。如果你用范围约束或如果执行索引扫描来查询索引列,该值增加。
Handler_read_prev:按照键顺序读前一行的请求数。该读方法主要用于优化ORDER BY ... DESC。
Handler_read_rnd :根据固定位置读一行的请求数。如果你正执行大量查询并需要对结果进行排序该值较高。你可能使用了大量需要MySQL扫描整个表的查询或你的连接没有正确使用键。这个值较高,意味着运行效率低,应该建立索引来补救。
Handler_read_rnd_next:在数据文件中读下一行的请求数。如果你正进行大量的表扫描,该值较高。通常说明你的表索引不正确或写入的查询没有利用索引。
总结
- 索引简单来说就是一个排好序的数据结构,可以方便我们检索数据,而不需要盲目的进行全表扫描。
- 索引底层有很多种实现结构,这篇主要只是讲解了BTREE索引,如果对树这一数据结构还不太熟悉的小伙伴,可以关注我后续数据结构专栏,会整理关于普通树,二叉树,二叉排序树的文章。
- 索引分类:
- 主键索引
- 辅助索引
这里我们还扩展了索引下推,是一个十分重要的知识点,需要仔细回味。
- 索引的相关设计原则,索引虽好,但也不可贪杯,不能为了用索引而建索引。
- 索引的相关语法,很容易上手的。
- 查看索引的使用情况。
推荐学习:mysql视频教程
Atas ialah kandungan terperinci Membawa anda melalui indeks MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!