
Rumah >pangkalan data >tutorial mysql >Mari kita bincangkan tentang lapisan bawah dan pengoptimuman indeks Mysql
Mari kita bincangkan tentang lapisan bawah dan pengoptimuman indeks Mysql

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2022-02-14 18:47:541963semak imbas
Artikel ini memberi anda pengetahuan tentang indeks dan pengoptimuman asas dalam mysql Di bawah kami akan menyusun mata pengetahuan pengindeksan dalam mysql, dengan harapan ia dapat membantu semua orang.

Indeks Mysql
Baru-baru ini, saya telah membaca tentang ilmu pengindeksan di banyak laman web, tetapi ia tidak menyeluruh samar-samar. Berikut ialah mata pengetahuan indeks Mysql yang disusun oleh editor.
1. Mula-mula, mari kita bincangkan tentang apa itu indeks dan mengapa kita perlu menggunakan indeks
Indeks digunakan untuk mencari baris dengan nilai tertentu dalam lajur index, MySQL mesti bermula dari Rekod pertama mula membaca keseluruhan jadual sehingga baris yang berkaitan ditemui Lebih besar jadual, lebih banyak masa yang diperlukan untuk menanyakan data Jika lajur yang ditanya dalam jadual mempunyai indeks, MySQL boleh dengan cepat mencapai lokasi untuk mencari data dan bukannya perlu melihat semua data, yang akan menjimatkan banyak masa.
2. Jenis indeks terbahagi kepada dua kategori:
1.indeks cincang
2.bTree
3. Mari analisa secara ringkas indeks cincang dan bIndeks pokok.
1. Jadual cincang ialah struktur yang menyimpan data dalam istilah nilai kunci Kita hanya perlu memasukkan kunci untuk ditemui, iaitu kunci, untuk mencari Nilai yang sepadan ialah Nilai. Idea pencincangan adalah sangat mudah Letakkan nilai dalam tatasusunan, gunakan fungsi cincang untuk menukar kunci kepada kedudukan tertentu, dan kemudian letakkan nilai pada kedudukan ini dalam tatasusunan.
Tidak dapat dielakkan, berbilang nilai kunci akan mempunyai nilai yang sama selepas ditukar oleh fungsi cincang. Satu cara untuk menangani situasi ini ialah dengan mengeluarkan senarai terpaut.
2. Bercakap tentang bTree, kita perlu menyebut pokok binari terbahagi kepada banyak kategori, seperti: Pokok Carian Binari, Pokok Binari Seimbang, dll. Sudah tentu, terdapat juga perkara utama pokok merah dan hitam.
1) Ciri-ciri pokok carian binari ialah: Nilai semua nod dalam subpohon kiri nod induk adalah kurang daripada nilai nod induk. Nilai semua nod dalam subpokok kanan adalah lebih besar daripada nilai nod induk. Mari kita ambil gambar sebagai contoh untuk menggambarkan pepohon carian binari.
| ID | name |
|---|---|
| 5 | 张五 |
| 6 | 张六 |
| 7 | 张七 |
| 2 | 张二 |
| 1 | 张一 |
| 4 | 张四 |
| 3 | 张三 |
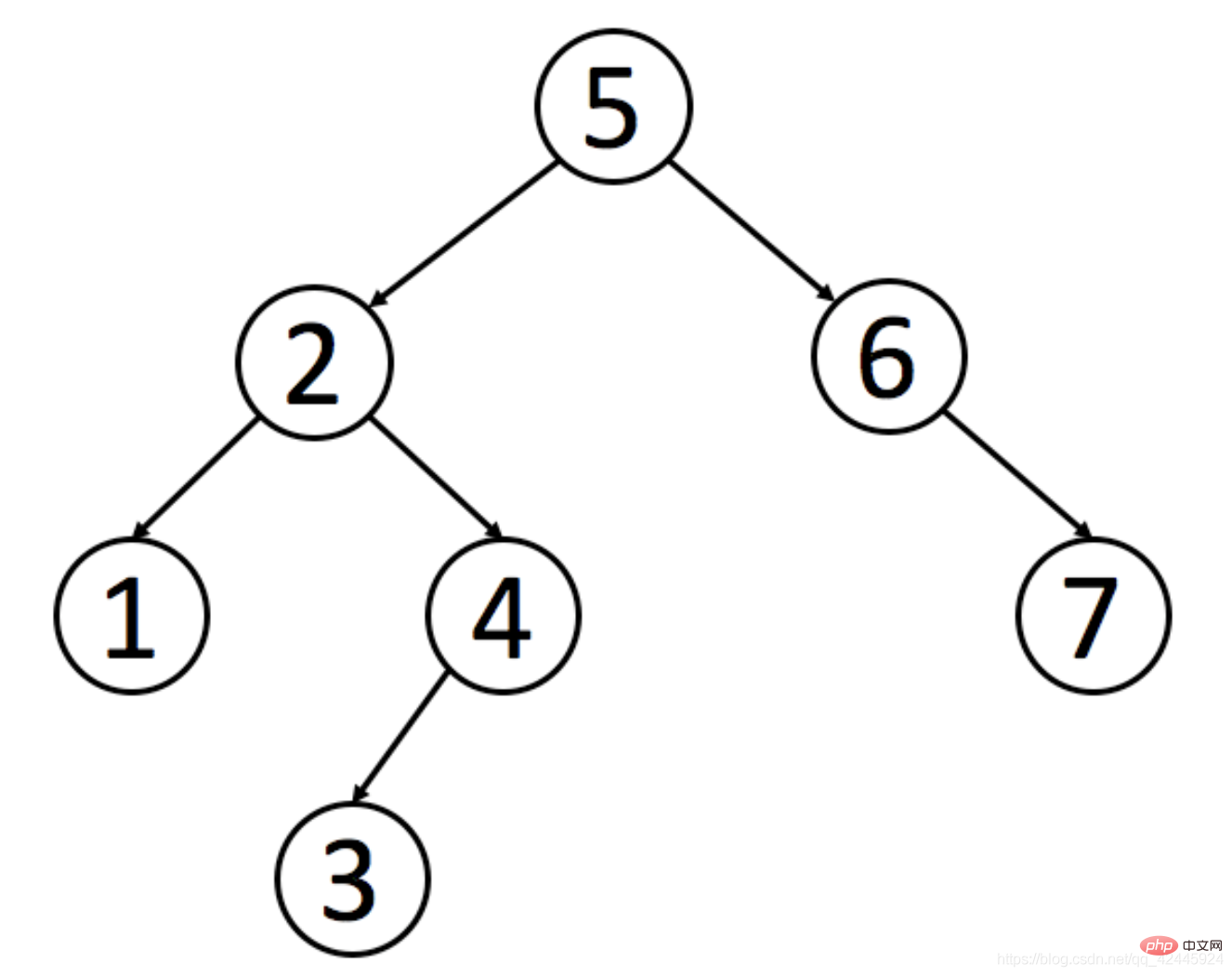 Ada keperluan untuk mencari Zhang San Jika kita tidak menggunakan pokok carian binari, kita perlu mencari 7 kali menggunakan pokok carian binari, kita hanya perlu mencari 4 kali untuk mencari nilai yang kita mahu.
Ada keperluan untuk mencari Zhang San Jika kita tidak menggunakan pokok carian binari, kita perlu mencari 7 kali menggunakan pokok carian binari, kita hanya perlu mencari 4 kali untuk mencari nilai yang kita mahu.
Menurut di atas, menggunakan pepohon carian binari memang boleh mengurangkan bilangan pertanyaan, tetapi pernahkah anda terfikir bagaimana jika data dalam pangkalan data meningkat mengikut urutan seperti 1, 2, 3, 4, 5, 6 , dan 7? Jika anda terus menggunakan pepohon carian binari, ia akan menjadi senarai terpaut. Jadi jika kita ingin mencari 7, kita perlu mencari 7 kali, dan mengimbas jadual 7 kali. Ini tidak berbeza dengan tidak mencipta indeks, yang juga merupakan salah satu kelemahan. Rajah berikut adalah contoh. 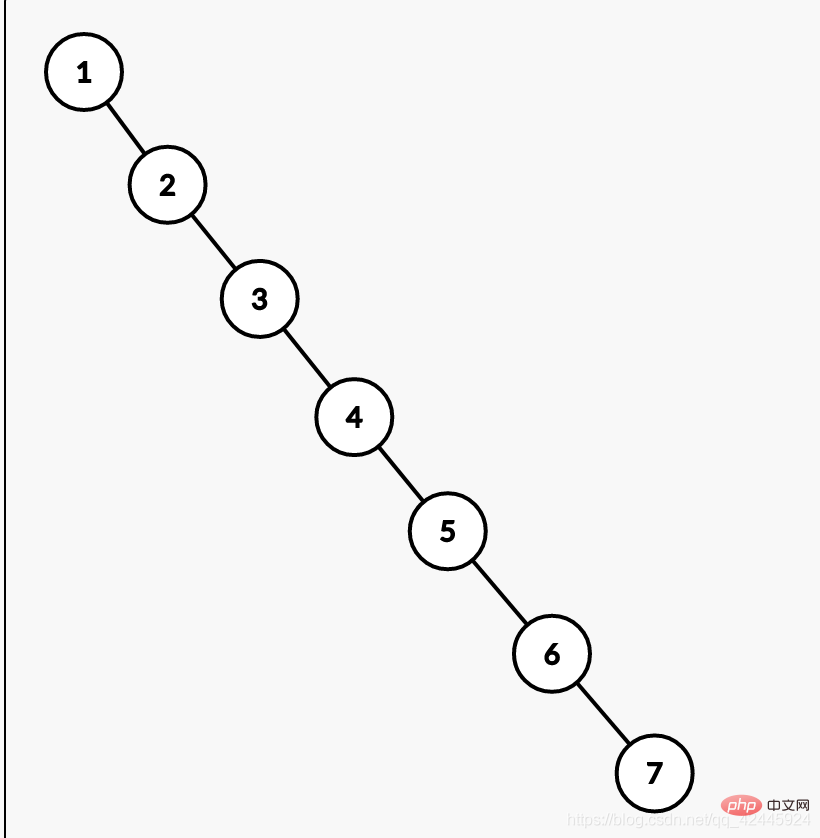
2) Pokok binari seimbang : juga dikenali sebagai pokok AVL, nilai mutlak perbezaan ketinggian antara subpokok kiri dan kanannya tidak melebihi 1 , dan Subpokok kiri dan kanan ialah kedua-dua pokok binari seimbang, dan pokok AVL ialah pokok carian binari pengimbangan diri yang terawal dicipta. Dalam pokok AVL, perbezaan ketinggian maksimum antara dua subpokok bagi mana-mana nod hanya boleh 1, jadi ia juga dipanggil pokok seimbang ketinggian. Menyoal, menambah dan memadam adalah O(log n) dalam kes purata dan terburuk. Penambahan dan pemadaman mungkin memerlukan satu atau lebih putaran pokok untuk mengimbangi semula pokok.
Tujuan kami memperkenalkan pokok binari adalah untuk meningkatkan kecekapan carian pokok binari, dengan itu mengurangkan purata panjang carian pokok Untuk tujuan ini, kami mesti melaraskan struktur pokok apabila memasukkan nod ke dalam setiap pokok binari supaya bahawa carian pokok binari boleh mengekalkan keseimbangan , dengan itu memungkinkan untuk mengurangkan ketinggian pokok dan mengurangkan purata panjang carian pokok.
Ciri-ciri pokok binari seimbang adalah seperti berikut:
1. Subtree kiri dan subtree kanan adalah kedua-dua pokok AVL
2. Perbezaan ketinggian antara subtree kiri dan subtree kanan tidak boleh melebihi 1
Contoh: 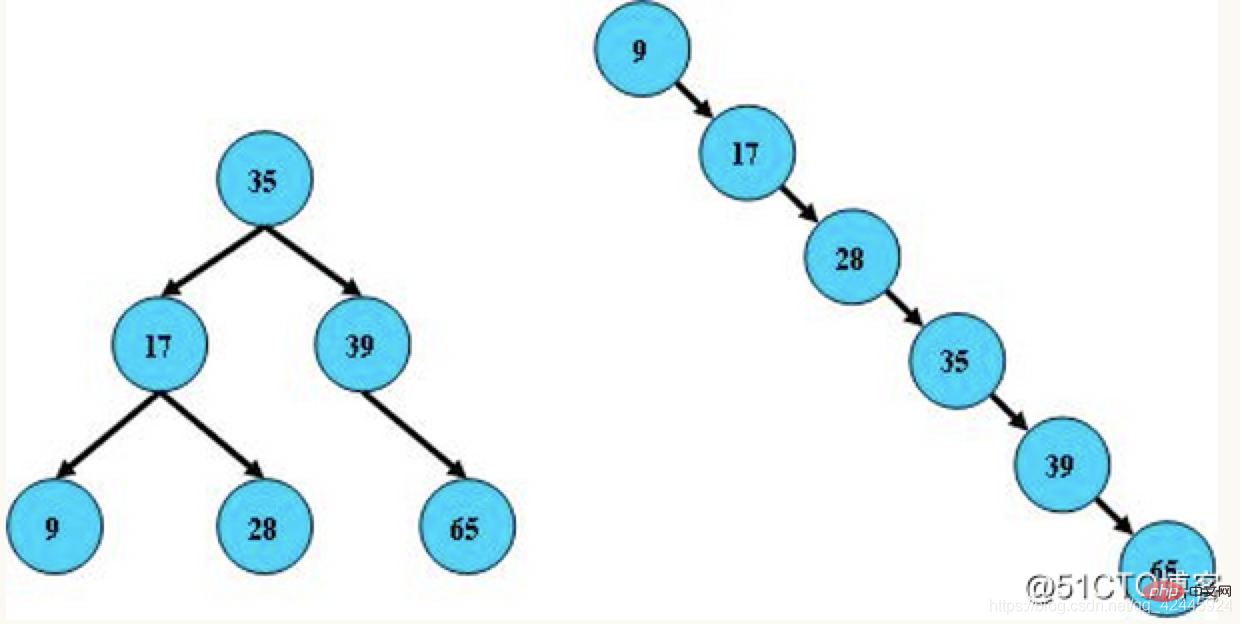 3) Pokok merah-hitam: Dapat difahami pokok merah-hitam ialah pokok yang berada di atas. pokok binari yang seimbang Merah-hitam Pokok itu tidak mengejar "keseimbangan lengkap", ia hanya bertujuan untuk mencapai sebahagian keperluan keseimbangan, mengurangkan keperluan untuk putaran, dengan itu meningkatkan prestasi. Tambahan pula, disebabkan reka bentuknya, sebarang ketidakseimbangan boleh diselesaikan dalam tiga pusingan. Dalam pokok merah-hitam, kerumitan masa algoritmanya adalah sama dengan AVL, dan prestasi statistik akan memaksa pokok AVL menjadi lebih tinggi. Oleh itu, berbanding dengan pokok binari seimbang, pokok merah-hitam bukanlah pokok binari seimbang dalam erti kata yang ketat Kecekapan pemasukan dan pemadaman pokok merah-hitam adalah lebih tinggi, dan kecekapan pertanyaan adalah lebih rendah daripada binari seimbang. pokok Walau bagaimanapun, perbezaan dalam kecekapan pertanyaan antara kedua-duanya adalah Sebagai perbandingan, ia pada asasnya boleh diabaikan. Ciri-ciri pokok merah-hitam adalah seperti berikut:
3) Pokok merah-hitam: Dapat difahami pokok merah-hitam ialah pokok yang berada di atas. pokok binari yang seimbang Merah-hitam Pokok itu tidak mengejar "keseimbangan lengkap", ia hanya bertujuan untuk mencapai sebahagian keperluan keseimbangan, mengurangkan keperluan untuk putaran, dengan itu meningkatkan prestasi. Tambahan pula, disebabkan reka bentuknya, sebarang ketidakseimbangan boleh diselesaikan dalam tiga pusingan. Dalam pokok merah-hitam, kerumitan masa algoritmanya adalah sama dengan AVL, dan prestasi statistik akan memaksa pokok AVL menjadi lebih tinggi. Oleh itu, berbanding dengan pokok binari seimbang, pokok merah-hitam bukanlah pokok binari seimbang dalam erti kata yang ketat Kecekapan pemasukan dan pemadaman pokok merah-hitam adalah lebih tinggi, dan kecekapan pertanyaan adalah lebih rendah daripada binari seimbang. pokok Walau bagaimanapun, perbezaan dalam kecekapan pertanyaan antara kedua-duanya adalah Sebagai perbandingan, ia pada asasnya boleh diabaikan. Ciri-ciri pokok merah-hitam adalah seperti berikut:
1 Nod berwarna merah atau hitam.
2. Nod akar berwarna hitam.
3. Setiap dua nod anak nod merah berwarna hitam. (Anak nod merah mestilah nod hitam)
4. Semua laluan dari mana-mana nod ke setiap daunnya mengandungi bilangan nod hitam yang sama.
Oleh itu, pokok merah-hitam ialah pokok seimbang hitam, dan perbezaan ketinggian antara pokok kecil kiri dan pokok kecil kanan tidak akan melebihi 2. Nod induk dan nod anak bagi nod merah hanya boleh menjadi nod hitam.
Contoh: 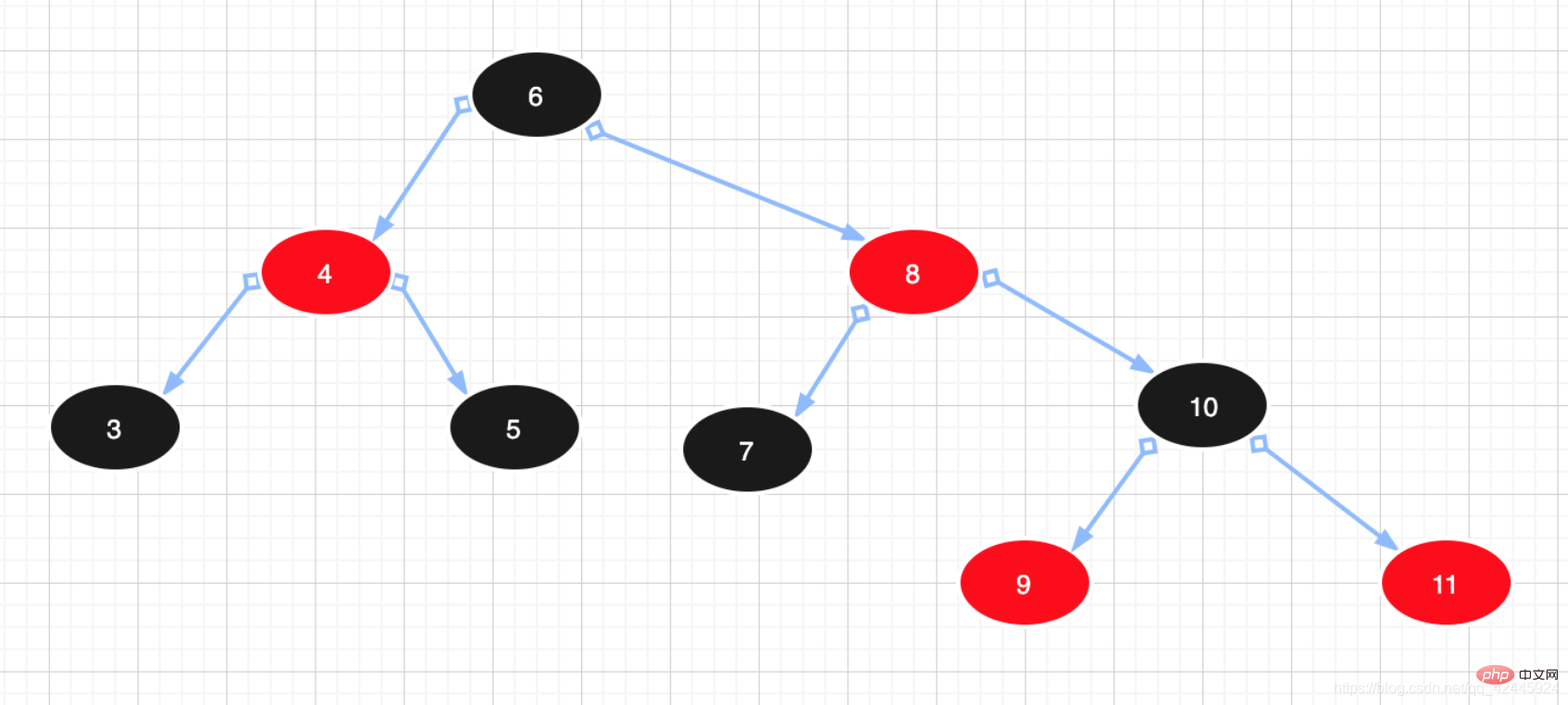
4) BTree (B-tree) : Sudah tentu, pokok merah-hitam yang disebutkan di atas, persembahannya sangat tinggi. Mengambil gambar di atas sebagai contoh, ketinggian maksimum pokok ialah 4, dengan jumlah 9 keping data Namun, untuk pangkalan data Mysql, jika terdapat berjuta-juta keping data atau berpuluh juta keping data. maka ketinggian pokok akan menjadi tidak boleh diukur, contohnya, ratusan keping data Sepuluh ribu keping data memerlukan 30-50 kali cakera IO untuk menanyakan data, atau lebih banyak kali, yang jelas tidak dapat memenuhi kecekapan pertanyaan yang cekap. indeks mysql. Jadi jika kita mengawal ketinggian pokok, ini akan mengurangkan bilangan permintaan IO cakera Jika ketinggian dikawal pada 4, maka hanya 4 IO cakera diperlukan untuk menanyakan data.
Tetapi bagaimana untuk mengawal ketinggian pokok merah-hitam hanya menyimpan satu elemen bagi setiap nod. Ini boleh menyelesaikan masalah ketinggian semua elemen diletakkan pada satu nod, nilai ketinggian akan menjadi 1. Bukankah lebih cepat? Adalah salah untuk berfikir dengan cara ini Mysql mempunyai had saiz setiap kali ia berurusan dengan cakera IO. Mysql mengehadkan saiz setiap nod kepada 16K. Pelajar yang ingin menyemak had saiz nod Mysql mereka boleh melaksanakan sql berikut.
tunjukkan status global seperti 'Innodb_page_size'
Gambar berikut digunakan sebagai contoh untuk menggambarkan ciri-ciri BTree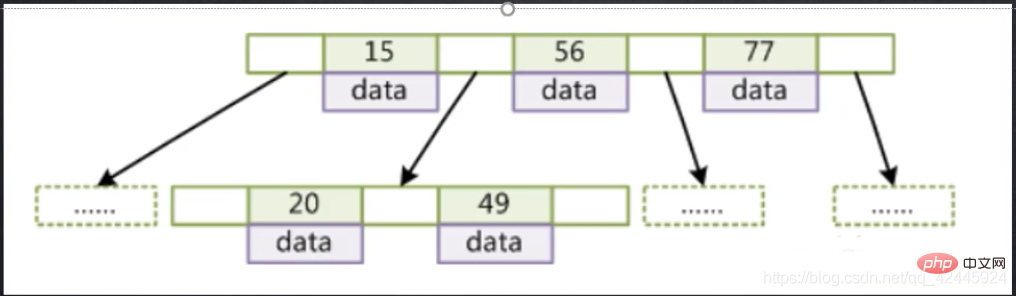 BTree:
BTree:
1. Semua elemen indeks tidak berulang
2. Indeks Data Nod meningkat dari kiri ke kanan
3. Nod daun mempunyai kedalaman yang sama, dan penunjuk nod daun kosong
4. Kedua-dua nod daun dan nod bukan daun menyimpan indeks dan data
5) B tree : Seperti yang dinyatakan di atas, BTree mengawal ketinggian pokok, yang boleh memenuhi keperluan indeks Mysql, tetapi pada akhirnya pelaksanaan indeks Mysq bukan BTree tetapi B Tree, Mysql telah membuat sedikit pengubahsuaian pada B-tree dan memperoleh B-tree Ia juga boleh difahamkan bahawa B-tree adalah versi upgrade dari B-tree.
Mari kita ambil gambar sebagai contoh: 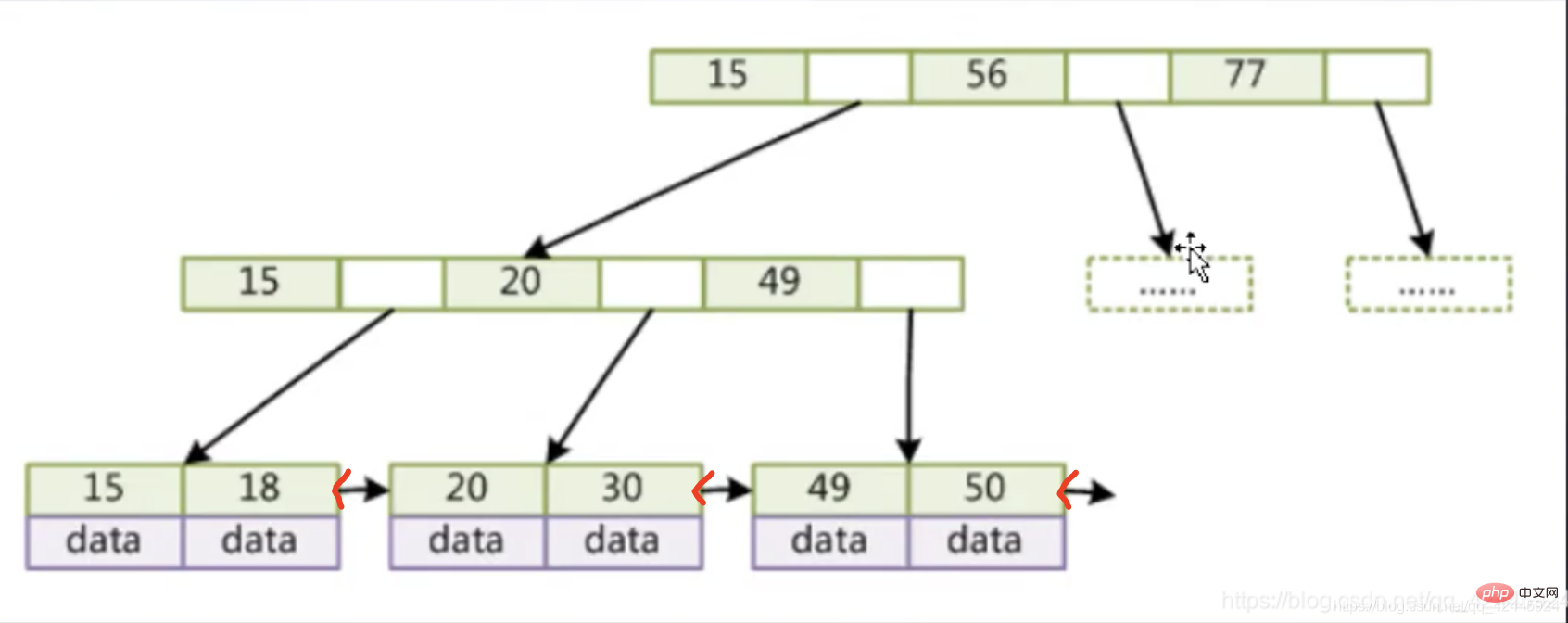
Seperti yang anda lihat dari gambar ini, nod bukan daun kami hanya menyimpan indeks dan tidak menyimpan data, dan penunjuk digunakan antara nod daun bersambung. Kedua-dua nod daun dan nod bukan daun bagi indeks dan data stor B-tree, dan penunjuk nod daun adalah kosong lebih banyak indeks, setiap kali Lebih banyak indeks juga boleh diperoleh daripada cakera IO.
Ciri pokok B adalah seperti berikut:
1. Nod bukan daun tidak menyimpan data, hanya indeks (berlebihan) dan penunjuk peringkat bawah, dan lebih banyak indeks boleh diletakkan.
2 .Nod daun mengandungi semua medan indeks dan data
3. Nod daun disambungkan dengan penunjuk berganda untuk meningkatkan prestasi akses selang
B-tree yang dilukis pada Baidu dan banyak blog Ia adalah salah. Anda mesti mengelakkan pit.
Jika anda berminat untuk melihat penjelasan rasmi Mysql tentang B-trees, anda boleh menyemaknya.
Pautan: laman web rasmi Mysql.
4. Klasifikasi indeks
1. > 1.) Indeks berkelompok (indeks berkelompok)
: Nod daun mengandungi rekod data yang lengkap dan tidak perlu dikembalikan ke jadual. 2.) Indeks tidak berkelompok: Perlu mengembalikan jadual
dan melakukan carian pepohon dua kali, yang menjejaskan prestasi.
Semua orang tahu bahawa MySQL mempunyai dua enjin storan yang biasa digunakan: MyISAM dan InnoDB, tetapi adakah anda benar-benar memahami struktur storan data yang mendasari kedua-dua enjin storan? Mari kita ambil gambar sebagai contoh untuk menggambarkan:
Jadual test.myisam ialah enjin storan MyISAM, dan jadual pelakon ialah enjin storan InnoDB Anda boleh melihat bahawa enjin storan MyISAM mempunyai tiga fail, iaitu frm dan MYD , MYI, mudah untuk memahami singkatan frm-frame Ia menyimpan struktur jadual MYI-MYIndex secara berasingan. InnoDB hanya mempunyai frm dan IBD , di mana frm juga mempunyai struktur jadual yang disimpan, dan fail IBD menyimpan indeks dan data, yang berbeza daripada InnoDB dan MyISAM.
Gambar berikut digunakan sebagai contoh untuk menggambarkan bahawa indeks kunci utama enjin storan MyISAM memerlukan operasi pengembalian jadual (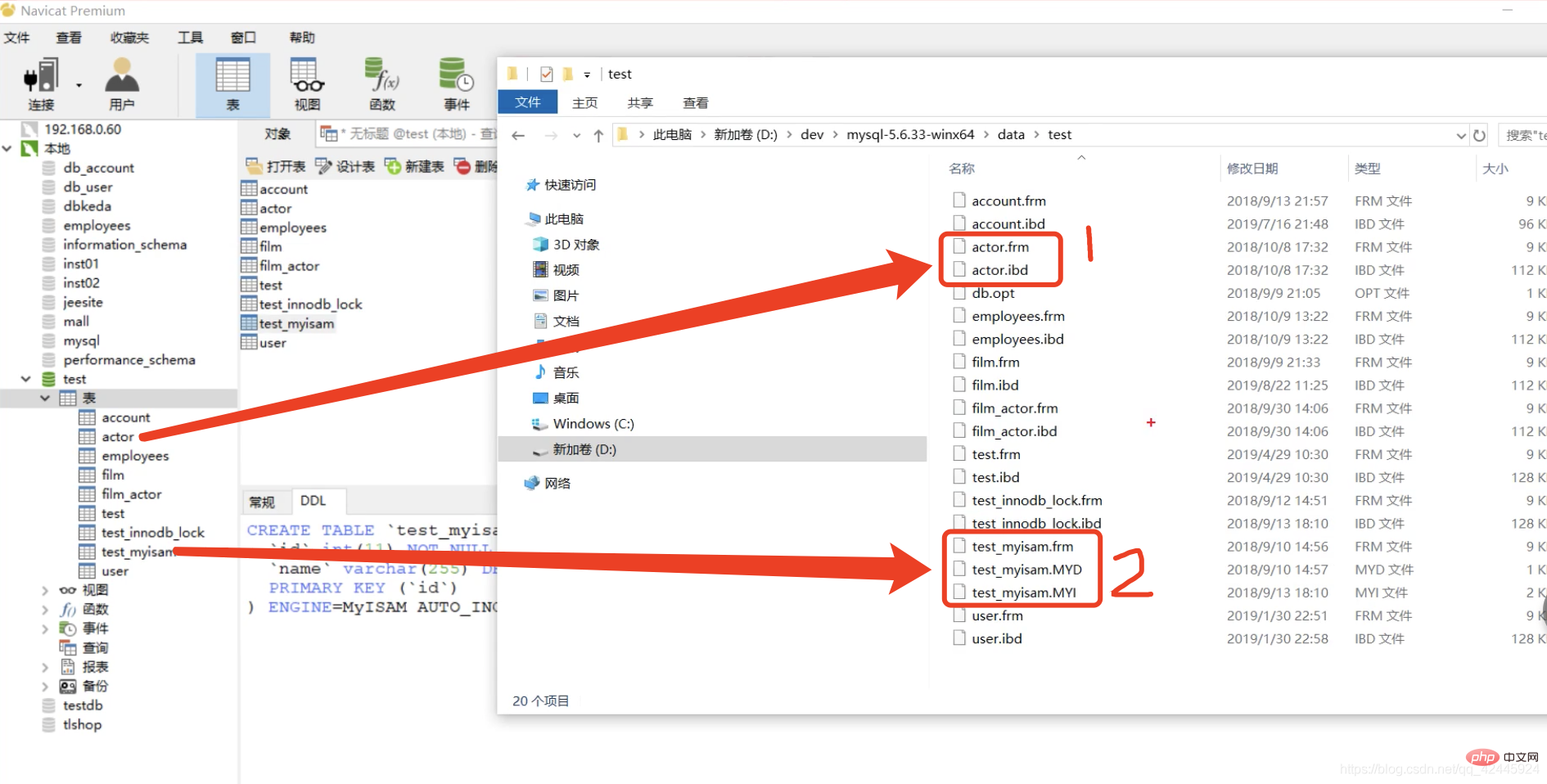 indeks bukan berkelompok
indeks bukan berkelompok
) Antaranya, 15 menyimpan indeks kunci utama, dan 0x07 menyimpan lokasi 15 Penunjuk alamat fail cakera bagi rekod baris Sebagai contoh, jika kita ingin mencari data 15, kita harus mencari penuding yang sepadan dengan 15 melalui pokok indeks kunci utama. dan kemudian cari penunjuk ini dan kemudian pergi ke fail MyD untuk mencari data tertentu Dua langkah diperlukan. 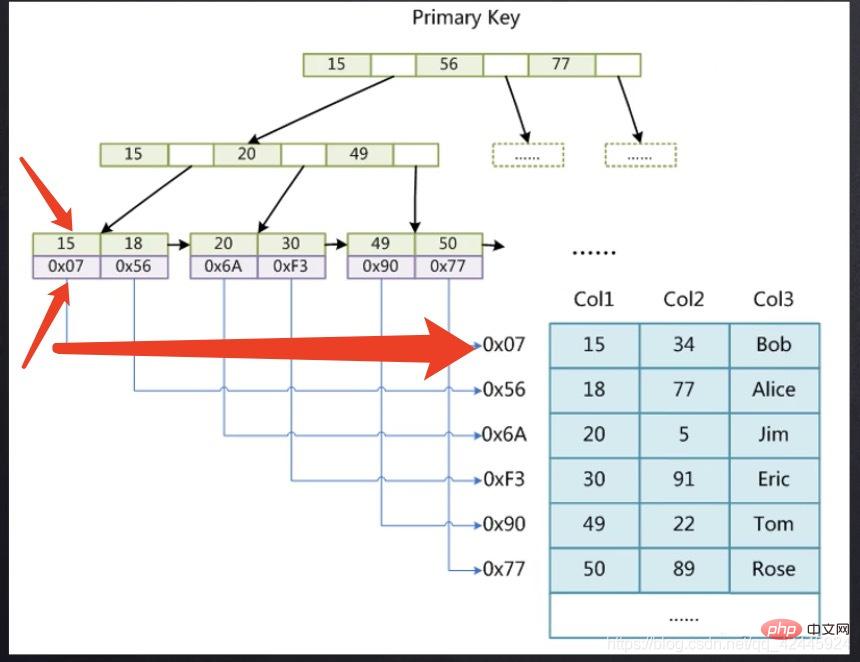 2.1)
2.1)
Rajah berikut digunakan sebagai contoh untuk menggambarkan bahawa indeks kunci utama enjin storan InnoDB tidak memerlukan operasi pemulangan jadual. (Indeks Berkelompok)Sub-nod enjin storan InnoDB Baris pertama 15 menyimpan indeks, dan lajur di bawah 15 menyimpan semua medan lain baris di mana indeks terletak kami mahu Data 15 boleh didapati terus tanpa perlu melalui carian pokok kedua. 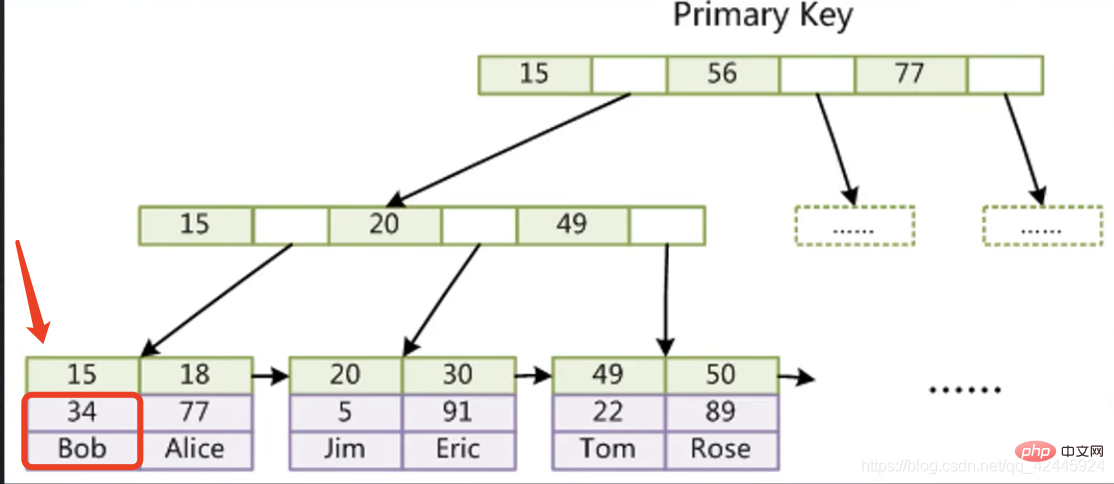
Mengikut klasifikasi fungsi: terutamanya dibahagikan kepada lima kategori 2.1
Indeks kunci utama: Indeks kunci utama InnoDB tidak memerlukan operasi pemulangan jadual 2.2
Indeks biasa (indeks kedua): Indeks biasa InnoDB memerlukan operasi pemulangan jadual Untuk indeks sekunder, ia akan menjadi indeks bersama dengan kunci utama secara lalai. 2.3
Indeks unik 2.4
Indeks teks penuh 2.5
Indeks kesatuan: perlu memenuhi prinsip awalan paling kiri
Telah disebutkan dalam 2.2 bahawa indeks biasa memerlukan operasi pemulangan jadual. Adakah terdapat sebarang indeks biasa yang tidak memerlukan operasi pemulangan jadual. Jawapannya ialah ya keperluan pertanyaan kami , kami memanggilnya indeks penutup. Pada masa ini, tidak perlu kembali ke meja. Memandangkan indeks meliputi boleh mengurangkan bilangan carian pepohon dan meningkatkan prestasi pertanyaan dengan ketara, menggunakan indeks penutup ialah prestasi biasa pengoptimuman
bermakna. Contohnya: Berikut ialah penyataan permulaan jadual ini.
mysql> create table T ( ID int primary key, k int NOT NULL DEFAULT 0, s varchar(16) NOT NULL DEFAULT '', index k(k)) engine=InnoDB; insert into T values(100,1, 'aa'),(200,2,'bb'), (300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg');
Dalam jadual T di atas, jika saya melaksanakan pilih * daripada T di mana k antara 3 dan 5, berapa banyak operasi carian pokok yang perlu dilakukan dan berapa banyak baris yang akan diimbas?
Sekarang, mari kita lihat aliran pelaksanaan pernyataan pertanyaan SQL ini. Tengok gambar kat bawah ni. 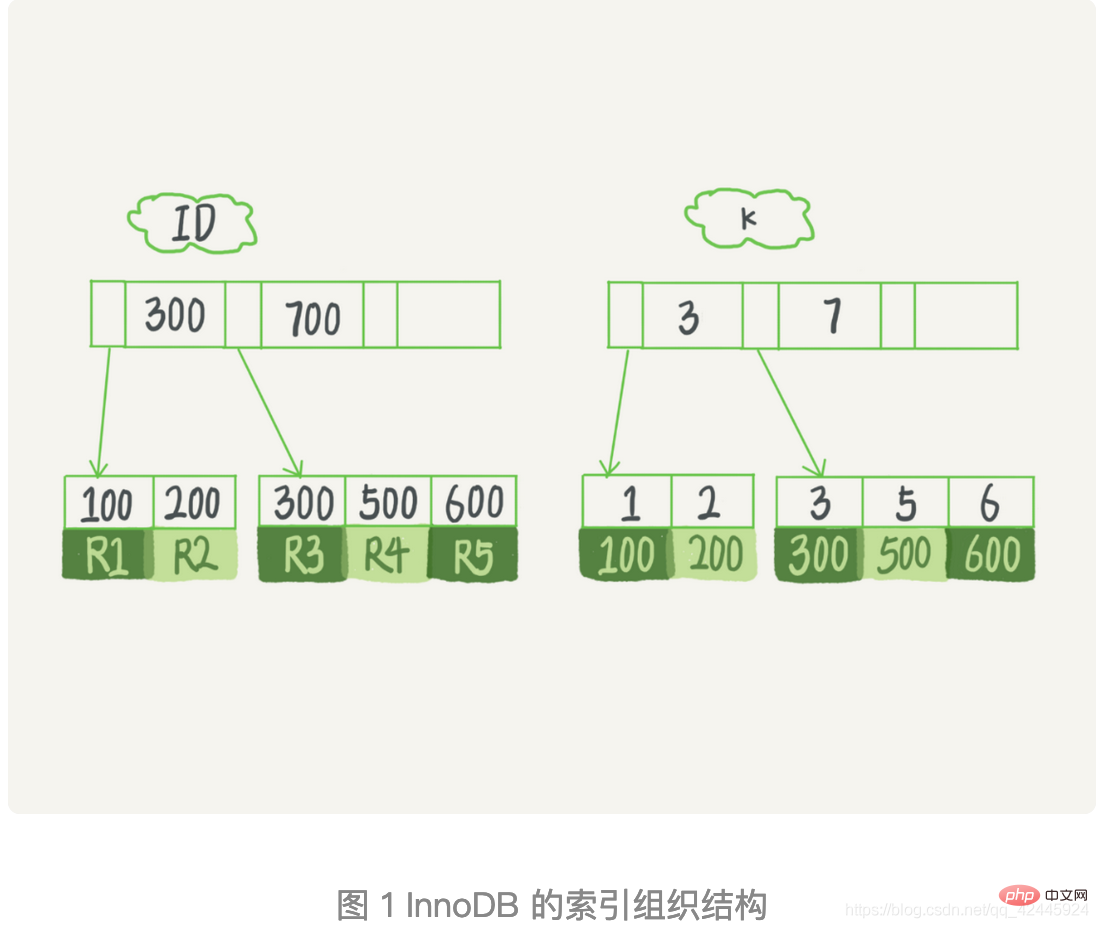
1.) Cari rekod k=3 dalam pokok indeks k dan dapatkan ID = 300;
2.) Kemudian pergi ke ID Pokok indeks mencari R3 yang sepadan dengan ID=300; .)
Kembali ke pepohon indeks ID dan cari R4 yang sepadan dengan ID=500; 5.)
Dapatkan nilai seterusnya k=6 dalam pokok indeks k tidak dipenuhi, gelung berakhir. Dalam proses ini,
kembali ke proses carian pokok indeks kunci utama, yang kami panggil pulangan jadual . Dapat dilihat bahawa proses pertanyaan ini membaca 3 rekod pokok indeks k (langkah 1, 3 dan 5) dan mengembalikan jadual dua kali (langkah 2 dan 4).
Jika pernyataan yang dilaksanakan ialah pilih ID daripada T di mana k antara 3 dan 5, Pada masa ini, anda hanya perlu menyemak nilai ID dan nilai ID sudah berada dalam indeks k pokok, jadi ia boleh diberikan terus Hasil pertanyaan tidak perlu dikembalikan ke jadual
. Maksudnya, dalam pertanyaan ini, indeks k mempunyai "meliputi
" keperluan pertanyaan kami, yang kami panggil indeks penutup.Dalam InnoDB, jadual disimpan dalam bentuk indeks berdasarkan susunan kunci utama Jadual yang disimpan dengan cara ini dipanggil jadual tersusun indeks. Dan kerana kami nyatakan sebelum ini, InnoDB menggunakan model indeks B-tree, jadi data disimpan dalam B-tree. Setiap indeks sepadan dengan pokok B dalam InnoDB. 5. Pengoptimuman indeks
1 di atas menerangkan konsep asas, klasifikasi dan pengetahuan asas yang berkaitan dengan indeks. Mari kita bincangkan tentang pengetahuan berkaitan pengoptimuman indeks.1.)
Apabila hanya satu lajur dalam indeks gabungan mengandungi nilai nol, indeks menjadi tidak sah 2.) Indeks menjadi tidak sah apabila mengira pada lajur, selepas julat Semua indeks tidak sah 3.)
Menggunakan fungsi pada keadaan pertanyaan akan menyebabkan kegagalan indeks 4.)
Menggunakan != atau di mana klausa pengendali, menyebabkan kegagalan indeks 5.)
Elakkan menggunakan atau, yang akan menyebabkan kegagalan indeks 6.)
Menggunakan pertanyaan kabur juga akan menyebabkan indeks kegagalan, anda boleh menggunakan seperti ' a%' dan bukannya suka '%a%'7.)
Cuba gunakan indeks penutup dan kurangkan pernyataan * pilihan8.)
Penuhi peraturan awalan paling kiri, Mulakan dengan lajur paling kiri dan jangan langkau lajur dalam indeks 9.)
Indeks akan gagal jika rentetan tidak disertakan dalam petikan tunggal 2. Berikut ialah penjelasan praktikal tentang pengoptimuman indeks.
Buat jadual pekerja baharu dengan 5 atribut, seperti berikut.
Nilai jenis sql 1 ialah ref, bait ialah 288 dan ref mempunyai 3 const, kesemuanya adalah sah.
create table employees(
id int primary key auto_increment comment '主键自增',
name varchar(30) not null default '' comment'名字',
age int not null default 1 comment '年龄',
id_card varchar(40) not null default '' comment '身份证号',
position varchar(40) not null default '' comment '位置'
);
-- 创建联合索引
create index name_index on employees (name,age,position);
-- 插入一条数据
insert into employees(name,age,id_card,position) values('张三',15,
'201124199011035321','北京');
-- 下面以10条sql测试,注意建立的联合索引顺序是 name,age,position 1.explain select * from employees where age=15 and position='北京' and name='张三'; 2.explain select * from employees where name='张三' and age=15 and position='北京'; 3.explain select * from employees where age=15 and name='张三'; 4.explain select * from employees where position='北京' and name='张三'; 5.explain select * from employees where position='北京' and age=15; 6.explain select * from employees where position='北京' and age>15 and name='张三'; 7.explain select * from employees where position='北京'; 8.explain select * from employees where age=15; 9.explain select * from employees where name='张三'; 10.explain select * from employees where name != '张三';
以上10条sql有哪些是索引失效,有哪些是索引没有失效的呢? 相信同学们已经有了答案,但是答案对不对呢,下面我们一起分析下。 首先说第1条,查询条件把3个索引全部用上了,但是索引的顺序有变化,由name,age,position变成 了age,position,name,想到这里肯定有很多同学给出的答案就是索引失效,但是事实证明这个结果 是错的,索引生效,肯定有很多同学疑惑,为什么呢,这条sql不满足最左原则法则呀,这就要涉及到sql 的执行流程了,这里博主简单说下,sql执行有1个优化器的过程,优化器的作用之一就是索引的选择优化, 所以优化器帮我们把索引的顺序变成正确的了,所以索引生效。 下面是第1条按照索引顺序sql和第2条没有按照索引顺序sql的执行结果。 执行结果入下图:可以发现全部生效。Nilai jenis sql kedua ialah ref, bait ialah 288, dan ref mempunyai 3 const, kesemuanya adalah sah.

Anda boleh mendapati bahawa nilai jenis sql ketiga ialah ref, bait ialah 126 dan ref mempunyai 2 const, semuanya berkesan . 
想学习sql的执行流程的可以看博主的另一篇关于sql执行流程的文章哦。 有的同学有疑问了,那最左原则没有用了吗? 答案:有用的。
现在我们说下第3、4、5条sql 第3条: explain select * from employees where age=15 and name='张三'; sql在执行的时候,优化器替我们把索引的顺序优化了,由 age -> name 变成 name -> age,这时 索引是生效的。 第4条: explain select * from employees where position='北京' and name='张三'; 索引顺序优化为name - > position,但是这时索引只有name索引生效,position没有生效,因为我 们建立的索引顺序是 name -> age - > position,你会发现跳过了age,索引本质也是一棵树,少 了一个节点,下面的索引当然不会生效了,这就没有满足最左原则法则。 第5条: explain select * from employees where position='北京' and age=15; 这就和第4条sql一样的道理了,第一个索引都不见了,后面的不可能生效。 执行结果如下:Sql keempat hanya mempunyai 122 bait dan ref hanya mempunyai 1 const, dan hanya indeks nama yang berkuat kuasa.
 Nilai jenis sql ke-5 ialah semua, bait dan ref adalah kosong dan semuanya tidak sah.
Nilai jenis sql ke-5 ialah semua, bait dan ref adalah kosong dan semuanya tidak sah.


下面说第6条sql,剩下的sql都是和之前的sql一样的道理。 explain select * from employees where position='北京' and age>15 and name='张三'; 这条sql我们会发现,把索引字段全部使用了并且当作条件查询,不一样的是age是范围查找,优化器替我 们把索引顺序优化成 name -> age - > position ,按照我们索引优化第2条:在列上做计算索引失效,范围之后的索引全部失效,想必答案同学们都知道了。 执行结果如下:
Pembelajaran yang disyorkan:
tutorial video mysql
Atas ialah kandungan terperinci Mari kita bincangkan tentang lapisan bawah dan pengoptimuman indeks Mysql. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Mari kita bincangkan tentang asas pertanyaan sambungan MySQL
- Mari kita bincangkan tentang tahap pengasingan yang dicapai oleh transaksi MySQL dan MVCC
- Penjelasan terperinci tentang kaedah pembukaan sebenar Kumpulan MySql mengikut fungsi!
- Selepas membaca, fahami ketekunan dan rollback MySQL (penjelasan terperinci dengan gambar dan teks)
- Apa yang perlu dilakukan jika centos mysqld gagal dimulakan