
Rumah >pangkalan data >tutorial mysql >Ringkasan pengetahuan asas MySql yang patut dikumpul (SQL Optimization)
Ringkasan pengetahuan asas MySql yang patut dikumpul (SQL Optimization)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2021-12-27 19:12:231727semak imbas
Kandungan utama artikel ini adalah untuk menganalisis sql langkah demi langkah melalui explain, dan untuk menala pernyataan sql dengan mengubah suai pernyataan sql dan mencipta indeks Anda juga boleh memahami pelaksanaan sql dengan melihat log, dan juga memperkenalkan Pangkalan Data MySQL kunci baris dan kunci meja. Semoga ia membantu semua orang.

1. Jelaskan pengenalan lajur kembali
1 Taipkan kata kunci biasa
sistem > > ref > indeks >
- sistem: Jadual hanya mempunyai satu baris, yang pada dasarnya tidak digunakan;
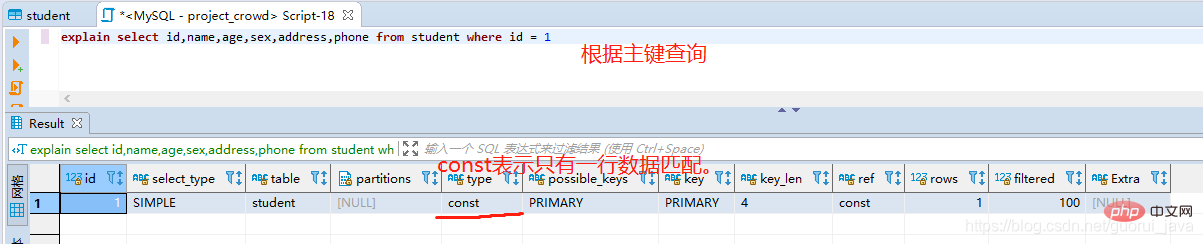
- const: Jadual mempunyai paling banyak satu baris data, yang lebih dicetuskan semasa pertanyaan kunci primer ;
- eq_ref: Untuk setiap gabungan baris daripada jadual sebelumnya, baca satu baris daripada jadual itu. Ini mungkin jenis gabungan terbaik, kecuali untuk jenis const; ref: untuk setiap gabungan baris daripada jadual sebelumnya,
- semua baris dengan nilai indeks yang sepadan akan diambil daripada jadual ini Baca; julat: Dapatkan hanya baris julat yang diberikan, menggunakan indeks untuk memilih baris. Apabila menggunakan operator =, <>, >, >=, <, <=, IS NULL, <=>, ANTARA atau IN, anda boleh menggunakan julat apabila membandingkan lajur utama dengan pemalar
- indeks: Jenis cantuman ini adalah sama seperti SEMUA, kecuali hanya pokok indeks yang diimbas. Ini biasanya lebih pantas daripada SEMUA kerana fail indeks biasanya lebih kecil daripada fail data
- semua: imbasan jadual penuh; .
- 2. Kata kunci tambahan biasa
Menggunakan indeks: hanya dapatkan maklumat daripada pepohon indeks, dan
tidak memerlukan pertanyaan jadual; Klausa WHERE digunakan untuk mengehadkan baris mana yang sepadan dengan jadual seterusnya atau dihantar kepada pelanggan. Melainkan anda secara khusus meminta atau menyemak semua baris daripada jadual, pertanyaan mungkin mempunyai beberapa ralat jika nilai Tambahan tidak Menggunakan tempat dan jenis gabungan jadual ialah SEMUA atau indeks.Perlu kembali ke jadual untuk pertanyaan.
Menggunakan sementara: mysql sering mencipta jadual sementara untuk menampung keputusan Situasi biasa ialah apabila pertanyaan mengandungi klausa GROUP BY dan ORDER BY yang boleh menyenaraikan lajur mengikut situasi yang berbeza 🎜> Untuk prinsip indeks dan terangkan penggunaan, sila rujuk artikel sebelumnya: Prinsip indeks MySQL, terangkan secara terperinci
2. Contoh kod indeks pencetus1 Cipta indeks bersama pernyataan jadual
2. Gunakan pertanyaan kunci utama
3. 4. Indeks bersama, tetapi dengan perintah tidak konsisten indeksCREATE TABLE `student` ( `id` int(10) NOT NULL, `name` varchar(20) NOT NULL, `age` int(10) NOT NULL, `sex` int(11) DEFAULT NULL, `address` varchar(100) DEFAULT NULL, `phone` varchar(100) DEFAULT NULL, `create_time` timestamp NULL DEFAULT NULL, `update_time` timestamp NULL DEFAULT NULL, `deleted` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `student_union_index` (`name`,`age`,`sex`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;Nota: Kerana pengoptimum mysql, jika ia tidak konsisten dengan susunan indeks, indeks juga akan dicetuskan, tetapi dalam projek sebenar, cuba pastikan pesanan itu konsisten.
 ">5. Indeks kesatuan, tetapi salah satu syaratnya ialah>
">5. Indeks kesatuan, tetapi salah satu syaratnya ialah>
 6. Indeks kesatuan, pesanan mengikut
6. Indeks kesatuan, pesanan mengikut
 Apabila menggunakan tempat dan susunan bersama-sama, jangan gunakannya merentasi lajur indeks
Apabila menggunakan tempat dan susunan bersama-sama, jangan gunakannya merentasi lajur indeks
3 Pengoptimuman SQL jadual tunggal
3、更改索引顺序
因为sql的编写过程
select distinct ... from ... join ... on ... where ... group by ... having ... order by ... limit ...
解析过程
from ... on ... join ... where ... group by ... having ... select distinct ... order by ... limit ...
因此我怀疑是联合索引建的顺序问题,导致触发索引的效果不好。are you sure?试一下就知道了。
alter table student add index student_union_index2(age,sex,name);
删除旧的不用的索引:
drop index student_union_index on student
索引改名
ALTER TABLE student RENAME INDEX student_union_index2 TO student_union_index
更改索引顺序之后,发现type级别发生了变化,由index变为了range。
range:只检索给定范围的行,使用一个索引来选择行。

备注:in会导致索引失效,所以触发using where,进而导致回表查询。
4、去掉in

ref:对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取;
index 提升为ref了,优化到此结束。
5、小结
- 保持索引的定义和使用顺序一致性;
- 索引需要逐步优化,不要总想着一口吃成胖子;
- 将含in的范围查询,放到where条件的最后,防止索引失效;
四、双表sql优化
1、建表语句
CREATE TABLE `student` ( `id` int(10) NOT NULL, `name` varchar(20) NOT NULL, `age` int(10) NOT NULL, `sex` int(11) DEFAULT NULL, `address` varchar(100) DEFAULT NULL, `phone` varchar(100) DEFAULT NULL, `create_time` timestamp NULL DEFAULT NULL, `update_time` timestamp NULL DEFAULT NULL, `deleted` int(11) DEFAULT NULL, `teacher_id` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `teacher` ( `id` int(11) DEFAULT NULL, `name` varchar(100) DEFAULT NULL, `course` varchar(100) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2、左连接查询
explain select s.name,t.name from student s left join teacher t on s.teacher_id = t.id where t.course = '数学'

上一篇介绍过,联合查询时,小表驱动大表。小表也称为驱动表。其实就相当于双重for循环,小表就是外循环,第二张表(大表)就是内循环。
虽然最终的循环结果都是一样的,都是循环一样的次数,但是对于双重循环来说,一般建议将数据量小的循环放外层,数据量大的放内层,这是编程语言的优化原则。
再次代码测试:
student数据:四条
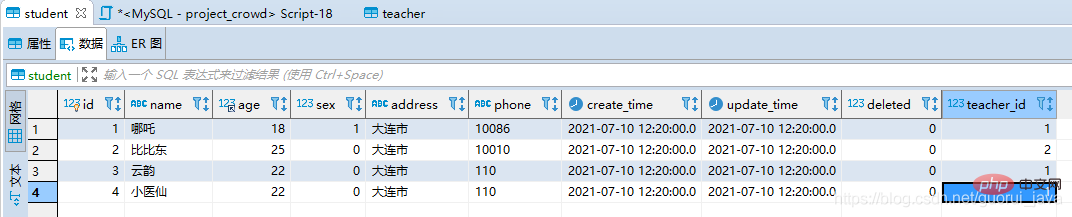
teacher数据:三条

按照理论分析,teacher应该为驱动表。

sql语句应该改为:
explain select teacher.name,student.name from teacher left join student on teacher.id = student.id where teacher.course = '数学'
优化一般是需要索引的,那么此时,索引应该怎么加呢?往哪个表上加索引?
索引的基本理念是:索引要建在经常使用的字段上。
由on teacher.id = student.id可知,teacher表的id字段使用较为频繁。
left join on,一般给左表加索引;因为是驱动表嘛。

alter table teacher add index teacher_index(id); alter table teacher add index teacher_course(course);

备注:如果extra中出现using join buffer,表明mysql底层觉得sql写的太差了,mysql加了个缓存,进行优化了。
3、小结
- 小表驱动大表
- 索引建立在经常查询的字段上
- sql优化,是一种概率层面的优化,是否实际使用了我们的优化,需要通过explain推测。
五、避免索引失效的一些原则
1、复合索引,不要跨列或无序使用(最佳左前缀);
2、符合索引,尽量使用全索引匹配;
3、不要在索引上进行任何操作,例如对索引进行(计算、函数、类型转换),索引失效;
4、复合索引不能使用不等于(!=或<>)或 is null(is not null),否则索引失效;
5、尽量使用覆盖索引(using index);
6、like尽量以常量开头,不要以%开头,否则索引失效;如果必须使用%name%进行查询,可以使用覆盖索引挽救,不用回表查询时可以触发索引;
7、尽量不要使用类型转换,否则索引失效;
8、尽量不要使用or,否则索引失效;
六、一些其他的优化方法
1、exist和in
select name,age from student exist/in (子查询);
如果主查询的数据集大,则使用in;
如果子查询的数据集大,则使用exist;
2、order by 优化
using filesort有两种算法:双路排序、双路排序(根据IO的次数)
MySQL4.1之前,默认使用双路排序;双路:扫描两次磁盘(①从磁盘读取排序字段,对排序字段进行排序;②获取其它字段)。
MySQL4.1之后,默认使用单路排序;单路:只读取一次(全部字段),在buffer中进行排序。但单路排序会有一定的隐患(不一定真的是只有一次IO,有可能多次IO)。
注意:单路排序会比双路排序占用更多的buffer。
单路排序时,如果数据量较大,可以调大buffer的容量大小。
set max_length_for_sort_data = 1024;单位是字节byte。
如果max_length_for_sort_data值太低,MySQL底层会自动将单路切换到双路。
太低指的是列的总大小超过了max_length_for_sort_data定义的字节数。
提高order by查询的策略:
- 选择使用单路或双路,调整buffer的容量大小;
- 避免select * from student;(① MySQL底层需要对*进行翻译,消耗性能;② *永远不会触发索引覆盖 using index);
- 符合索引不要跨列使用,避免using filesort;
- 保证全部的排序字段,排序的一致性(都是升序或降序);
七、sql顺序 -> 慢日志查询
慢查询日志就是MySQL提供的一种日志记录,用于记录MySQL响应时间超过阈值的SQL语句(long_query_time,默认10秒) ;
慢日志默认是关闭的,开发调优时打开,最终部署时关闭。
1、慢查询日志
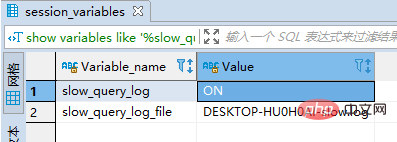
(1)检查是否开启了慢查询日志:
show variables like '%slow_query_log%'
(2)临时开启:
set global slow_query_log = 1;
(3)重启MySQL:
service mysql restart;
(4)永久开启:
/etc/my.cnf中追加配置:
放到[mysqld]下:
slow_query_log=1 slow_query_log_file=/var/lib/mysql/localhost-slow.log
2、阈值
(1)查看默认阈值:
show variables like '%long_query_time%'
(2)临时修改默认阈值:
set global long_query_time = 5;
(3)永久修改默认阈值:
/etc/my.cnf中追加配置:
放到[mysqld]下:
long_query_time = 5;
(4)MySQL中的sleep:
select sleep(5);
(5)查看执行时间超过阈值的sql:
show global status like '%slow_queries%';
八、慢查询日志 --> mysqldumpslow工具
1、mysqldumpslow工具
慢查询的sql被记录在日志中,可以通过日志查看具体的慢sql。
cat /var/lib/mysql/localhost-slow.log
通mysqldumpslow工具查看慢sql,可以通过一些过滤条件,快速查出需要定位的慢sql。
mysqldumpslow --help
参数简要介绍:
s:排序方式
r:逆序
l:锁定时间
g:正则匹配模式
2、查询不同条件下的慢sql
(1)返回记录最多的3个SQL
mysqldumpslow -s r -t 3 /var/lib/mysql/localhost-slow.log
(2)获取访问次数最多的3个SQL
mysqldumpslow -s c -t 3 /var/lib/mysql/localhost-slow.log
(3)按时间排序,前10条包含left join查询语句的SQL
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/localhost-slow.log
九、分析海量数据
1、show profiles
打开此功能:set profiling = on;
show profiles会记录所有profileing打来之后,全部SQL查询语句所花费的时间。
缺点是不够精确,确定不了是执行哪部分所消耗的时间,比如CPU、IO。
2、精确分析,sql诊断
show profile all for query 上一步查询到的query_id。
3、全局查询日志
show variables like '%general_log%'
开启全局日志:
set global general_log = 1;
set global log_output = table;
十、锁机制详解
1、操作分类
读写:对同一个数据,多个读操作可以同时进行,互不干扰。
写锁:如果当前写操作没有完毕,则无法进行其它的读写操作。
2、操作范围
表锁:一次性对一张表整体加锁。
如MyISAM存储引擎使用表锁,开销小、加锁快、无死锁;但锁的范围大,容易发生冲突、并发度低。
行锁:一次性对一条数据加锁。
如InnoDB存储引擎使用的就是行锁,开销大、加锁慢、容易出现死锁;锁的范围较小,不易发生锁冲突,并发度高(很小概率发生高并发问题:脏读、幻读、不可重复读)
lock table 表1 read/write,表2 read/write,...
查看加锁的表:
show open tables;
3、加读锁,代码实例
会话0: lock table student read; select * from student; --查,可以 delete from student where id = 1;--增删改,不可以 select * from user; --查,不可以 delete from user where id = 1;--增删改,不可以
如果某一个会话对A表加了read锁,则该会话可以对A表进行读操作、不能进行写操作。即如果给A表加了读锁,则当前会话只能对A表进行读操作,其它表都不能操作
会话1: select * from student; --查,可以 delete from student where id = 1;--增删改,会“等待”会话0将锁释放 会话1: select * from user; --查,可以 delete from user where id = 1;--增删改,可以
会话0给A表加了锁,其它会话的操作①可以对其它表进行读写操作②对A表:读可以,写需要等待释放锁。
4、加写锁
会话0: lock table student write;
当前会话可以对加了写锁的表,可以进行任何增删改查操作;但是不能操作其它表;
其它会话:
对会话0中对加写锁的表,可以进行增删改查的前提是:等待会话0释放写锁。
5、MyISAM表级锁的锁模式
MyISAM在执行查询语句前,会自动给涉及的所有表加读锁,在执行增删改前,会自动给涉及的表加写锁。
所以对MyISAM表进行操作,会有如下情况发生:
(1)对MyISAM表的读操作(加读锁),不会阻塞其它会话(进程)对同一表的读请求。但会阻塞对同一表的写操作。只有当读锁释放后,才会执行其它进程的写操作。
(2)对MyISAM表的写操作(加写锁),会阻塞其它会话(进程)对同一表的读和写操作,只有当写锁释放后,才会执行其它进程的读写操作。
6、MyISAM分析表锁定
查看哪些表加了锁:
show open tables;1代表被加了锁
分析表锁定的严重程度:
show status like 'table%';
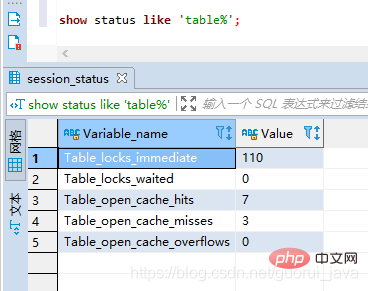
Table_locks_immediate:可能获取到的锁数
Table_locks_waited:需要等待的表锁数(该值越大,说明存在越大的锁竞争)
一般建议:Table_locks_immediate/Table_locks_waited > 5000,建议采用InnoDB引擎,否则采用MyISAM引擎。
7、InnoDB分析表锁定
为了研究行锁,暂时将自动commit关闭,set autocommit = 0;
show status like '%innodb_row_lock%';
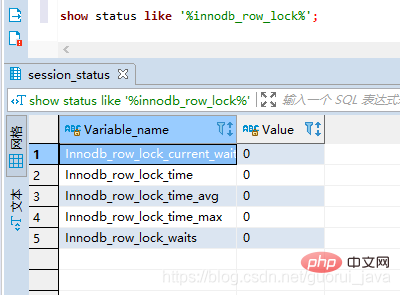
Innodb_row_lock_current_waits:当前正在等待锁的数量
Innodb_row_lock_time:等待总时长。从系统启动到现在一共等待的时间
Innodb_row_lock_time_avg:平均等待时长。从系统启动到现在一共等待的时间
Innodb_row_lock_time_max:最大等待时长。从系统启动到现在一共等待的时间
Innodb_row_lock_waits:等待次数。从系统启动到现在一共等待的时间
8、加行锁代码实例
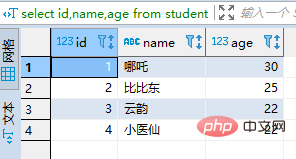
(1)查询student
select id,name,age from student
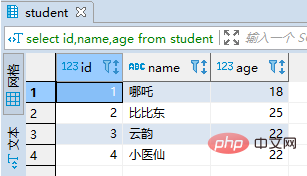
(2)更新student
update student set age = 18 where id = 1
(3)加行锁
通过select id,name,age from student for update;给查询加行锁。
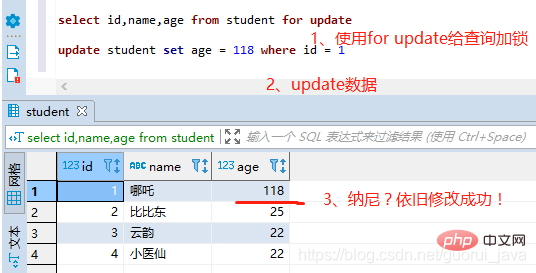
依旧修改成功,原因是MySQL默认是自动提交的,因此需要暂时将自动commit关闭
set autocommit = 0;
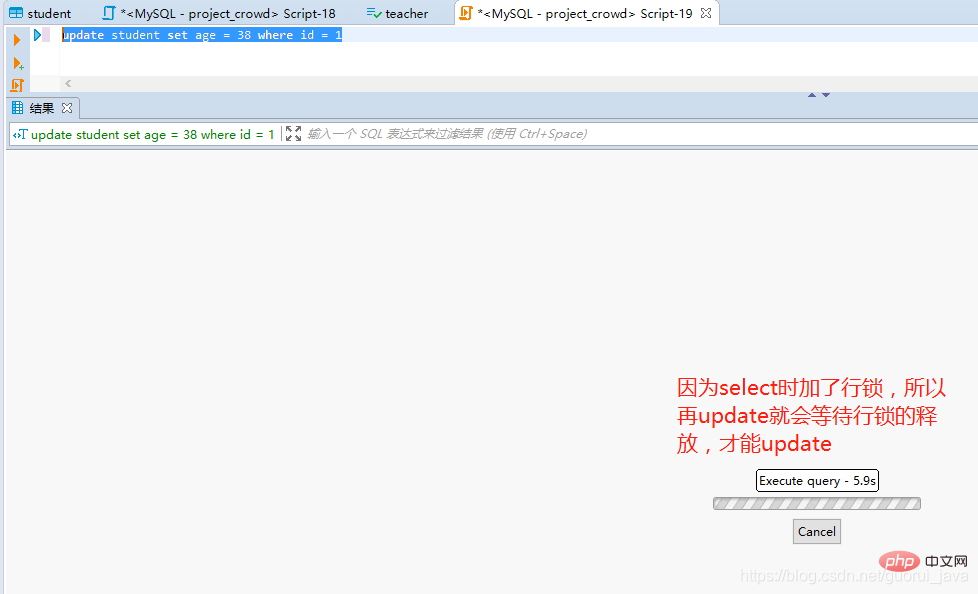
9、行锁的注意事项
(1)如果没有索引,行锁自动转为表锁。
(2)行锁只能通过事务解锁。
(3)InnoDB默认采用行锁
优点:并发能力强,性能高,效率高
缺点:比表锁性能损耗大
高并发用InnoDb,否则用MyISAM。
推荐学习:mysql视频教程
Atas ialah kandungan terperinci Ringkasan pengetahuan asas MySql yang patut dikumpul (SQL Optimization). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!