
Rumah >pangkalan data >tutorial mysql >Fahami semua mata pengetahuan indeks MySQL dalam satu artikel (disyorkan untuk dikumpulkan)
Fahami semua mata pengetahuan indeks MySQL dalam satu artikel (disyorkan untuk dikumpulkan)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2021-12-20 14:25:112086semak imbas
Artikel ini membawa anda pengetahuan tentang pengindeksan dalam pangkalan data mysql Ia mengandungi hampir semua mata pengetahuan tentang pengindeksan. Saya harap ia akan membantu semua orang.

Indeks MySQL
Pengenalan kepada indeks
Apakah itu indeks
Pengenalan rasmi daripada indeks ialah struktur data yang membantu MySQLmendapatkan data dengan cekap. Secara umum, indeks pangkalan data adalah seperti jadual kandungan di hadapan buku, yang boleh mempercepatkan pertanyaan pangkalan data .
Secara umumnya, indeks itu sendiri juga sangat besar dan tidak boleh disimpan sepenuhnya dalam ingatan, jadi indeks selalunya disimpan dalam fail pada cakera (mungkin disimpan Dalam fail indeks yang berasingan, atau mungkin disimpan bersama-sama dengan data dalam fail data).
Apa yang biasa kita panggil indeks termasuk indeks berkelompok, meliputi indeks, indeks gabungan, indeks awalan, indeks unik, dll. Tanpa arahan khas, struktur B-tree digunakan oleh lalai Indeks tersusun (pokok carian berbilang hala, tidak semestinya binari).
Kebaikan dan Kelemahan Pengindeksan
Kelebihan:
Ya Tingkatkan kecekapan pengambilan data dan kurangkan kos IO pangkalan data , serupa dengan jadual kandungan buku.
-
Isih data melalui lajur indeks, mengurangkan kos pengisihan data dan mengurangkan penggunaan CPU.
- Lajur yang diindeks akan diisih secara automatik, termasuk [indeks lajur tunggal] dan [indeks gabungan], tetapi pengisihan indeks gabungan adalah lebih rumit.
- Jika anda mengisih mengikut susunan lajur indeks, kecekapan akan bertambah baik untuk susunan demi pernyataan.
Kelemahan:
-
Indeks akan menduduki ruang cakera
Walaupun indeks akan meningkatkan kecekapan pertanyaan, ia akan mengurangkan kecekapan mengemas kini jadual. Sebagai contoh, setiap kali jadual ditambah, dipadam atau diubah suai, MySQL bukan sahaja mesti menyimpan data, tetapi juga menyimpan atau mengemas kini fail indeks yang sepadan.
Jenis indeks
Indeks kunci utama
Nilai dalam lajur indeks mestilah unik dan nilai nol tidak dibenarkan.
Indeks biasa
Jenis indeks asas dalam MySQL, tiada sekatan, membenarkan nilai pendua dan nilai nol dimasukkan ke dalam lajur di mana indeks ditakrifkan.
Indeks Unik
Nilai dalam lajur indeks mestilah unik, tetapi nilai nol dibenarkan.
Indeks teks penuh
Indeks teks penuh hanya boleh dibuat pada medan jenis teks CHAR, VARCHAR dan TEXT. Apabila panjang medan agak besar, jika anda mencipta indeks biasa, ia akan menjadi kurang cekap apabila melakukan seperti pertanyaan kabur Dalam kes ini, anda boleh mencipta indeks teks penuh. Indeks teks penuh boleh digunakan dalam kedua-dua MyISAM dan InnoDB.
Indeks Spatial
MySQL menyokong indeks spatial dalam versi selepas 5.7 dan menyokong model data geometri OpenGIS. MySQL mengikut peraturan model data geometri OpenGIS dari segi pengindeksan spatial.
Indeks awalan
Apabila membuat indeks pada lajur jenis teks seperti CHAR, VARCHAR dan TEXT, anda boleh menentukan panjang lajur indeks, tetapi anda tidak boleh menentukan jenis angka.
Lain-lain (dikelaskan mengikut bilangan lajur indeks)
Indeks lajur tunggal
-
Indeks gabungan
Indeks gabungan Untuk menggunakan, anda perlu mengikut prinsip padanan awalan paling kiri (prinsip padanan paling kiri) . Secara amnya, indeks gabungan digunakan dan bukannya indeks berbilang lajur tunggal apabila keadaan membenarkan.
Struktur data indeks
Jadual hash
Jadual hash, HashMap dan TreeMap dalam Java ialah struktur jadual Hash, dengan pasangan nilai kunci cara untuk menyimpan data. Kami menggunakan jadual Hash untuk menyimpan data jadual Key boleh menyimpan lajur indeks, dan Nilai boleh menyimpan rekod baris atau alamat cakera baris. Jadual cincang sangat cekap dalam pertanyaan setara, dengan kerumitan masa O(1); walau bagaimanapun, ia tidak menyokong carian julat pantas dan carian julat hanya boleh dilakukan dengan mengimbas keseluruhan jadual.
Jelas sekali ini tidak sesuai digunakan sebagai indeks pangkalan data yang selalunya memerlukan carian dan carian julat.
Pokok carian binari
Pokok binari, saya rasa semua orang akan mempunyai gambaran dalam fikiran mereka.
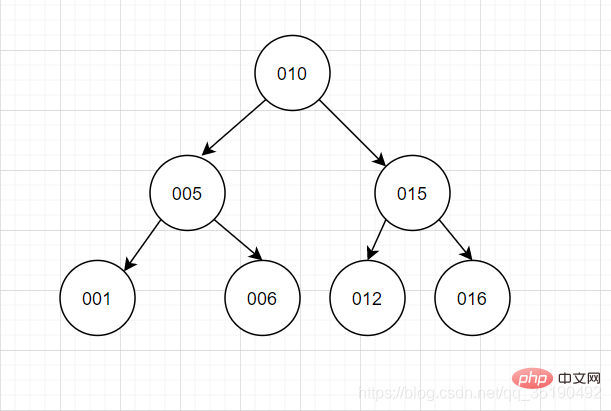
Ciri pokok binari: Setiap nod mempunyai sehingga 2 garpu, dan susunan data subpokok kiri dan subpokok kanan adalah kecil di sebelah kiri dan besar di sebelah kanan.
Ciri ini adalah untuk memastikan setiap carian boleh dikurangkan separuh dan mengurangkan bilangan kali IO Walau bagaimanapun, pokok binari adalah ujian nilai nod akar pertama, kerana ia adalah mudah untuk mempunyai konkurensi kita mahu berlaku di bawah ciri ini Keadaan "pokok tidak bercabang" adalah sangat tidak selesa dan tidak stabil.
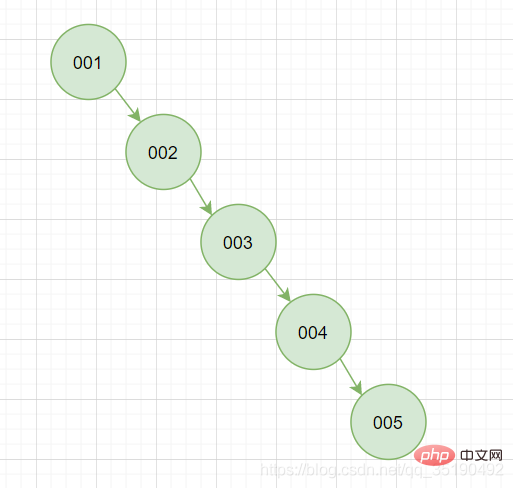
Jelas sekali keadaan ini tidak stabil dan kami akan memilih reka bentuk yang akan mengelakkan situasi ini
Pokok Binari Seimbang
Pokok binari seimbang mengamalkan pemikiran dikotomi Selain mempunyai ciri-ciri pokok binari, ciri yang paling penting bagi pokok carian binari seimbang ialah tahap subpokok kiri dan kanan pokok berbeza paling banyak 1. Apabila memasukkan dan memadam data, operasi belok kiri/belok kanan digunakan untuk mengekalkan keseimbangan pokok binari, supaya subpokok kiri tidak terlalu tinggi dan subpokok kanan akan pendek.
Prestasi pertanyaan menggunakan pepohon carian binari seimbang adalah hampir dengan kaedah carian binari, dan kerumitan masa ialah O(log2n). Pertanyaan id=6 memerlukan hanya dua IO.
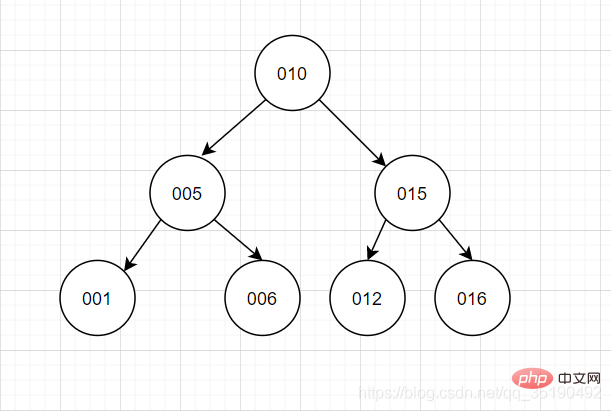
Melihat ciri ini, anda mungkin fikir ini sangat bagus dan boleh mencapai situasi ideal pokok binari. Walau bagaimanapun, masih terdapat beberapa masalah:
Kerumitan masa berkaitan dengan ketinggian pokok. Berapa kali pokok itu perlu diambil bergantung pada ketinggiannya. Bacaan setiap nod sepadan dengan operasi IO cakera. Ketinggian pokok adalah sama dengan bilangan operasi IO cakera setiap kali data ditanya. Setiap masa carian cakera ialah 10ms Apabila jumlah data jadual adalah besar, prestasi pertanyaan akan menjadi sangat lemah. (1 juta volum data, log2n adalah lebih kurang sama dengan 20 masa IO cakera, masa 20*10=0.2s)
Pokok binari seimbang tidak menyokong pertanyaan julat untuk pertanyaan Julat pantas perlu dilakukan dari Nod akar dilalui beberapa kali, dan kecekapan pertanyaan tidak tinggi.
B tree: mengubah pokok binari
Data MySQL disimpan dalam fail cakera Apabila membuat pertanyaan dan memproses data, anda perlu memuatkan data daripada cakera ke dalam ingatan dahulu, operasi IO cakera sangat memakan masa, jadi tumpuan pengoptimuman kami adalah untuk meminimumkan operasi IO cakera. Mengakses setiap nod pokok binari akan menyebabkan IO Jika anda ingin mengurangkan operasi cakera IO, anda perlu mengurangkan ketinggian pokok itu sebanyak mungkin. Jadi bagaimana untuk mengurangkan ketinggian pokok?
Jika kunci adalah bigint=8 bait, setiap nod mempunyai dua penuding, setiap penuding ialah 4 bait dan satu nod menduduki 16 bait ruang (8 4*2=16).
Oleh kerana enjin storan InnoDB MySQL akan membaca jumlah data satu halaman (halaman lalai ialah 16K) dalam satu IO, manakala jumlah data berkesan dalam satu IO pokok binari hanya 16 bait, jadi penggunaan ruang adalah sangat rendah. Untuk memaksimumkan penggunaan satu ruang IO, idea mudah adalah untuk menyimpan berbilang elemen dalam setiap nod dan menyimpan sebanyak mungkin data dalam setiap nod. Setiap nod boleh menyimpan 1000 indeks (16k/16=1000), sekali gus mengubah pokok binari menjadi pokok berbilang garpu Dengan meningkatkan pokok garpu pokok itu, pokok itu ditukar daripada tinggi dan kurus kepada pendek dan gemuk. Untuk membina 1 juta keping data, ketinggian pokok hanya memerlukan 2 tahap (1000*1000=1 juta), yang bermaksud hanya 2 cakera IO diperlukan untuk menanyakan data. Bilangan IO cakera dikurangkan, dan kecekapan data pertanyaan dipertingkatkan.
Kami memanggil struktur data ini sebagai B-tree ialah pepohon carian seimbang berbilang garpu, seperti yang ditunjukkan di bawah:
Nod pokok B disimpan dalam Dengan berbilang elemen, setiap nod dalaman mempunyai berbilang garpu.
Elemen dalam nod mengandungi nilai kunci dan data Nilai kunci dalam nod disusun dari besar ke kecil. Dengan kata lain, data disimpan pada semua nod.
Elemen dalam nod induk tidak akan muncul dalam nod anak.
Semua nod daun terletak pada lapisan yang sama, nod daun mempunyai kedalaman yang sama, dan tiada sambungan penunjuk antara nod daun.
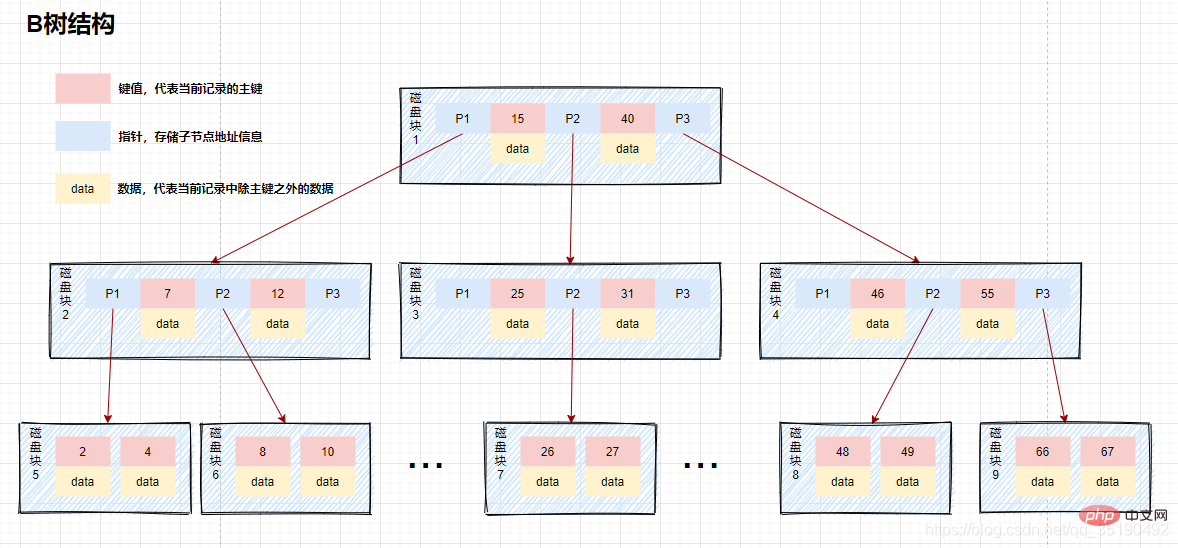
Contohnya, apabila menanyakan data dalam b-tree:
Jika kita menanyakan nilai yang sama dengan 10 data. Jalan pertanyaan blok cakera 1->blok cakera 2->blok cakera 5.
IO cakera pertama: Muatkan blok cakera 1 ke dalam memori, lintasi dan bandingkan dalam ingatan dari awal, 10
IO cakera kedua: muatkan blok cakera 2 ke dalam memori, lintasi dan bandingkan dalam memori dari awal, 7
IO cakera ketiga: muatkan blok cakera 5 ke dalam memori, lintasi dan bandingkan dalam memori dari awal, 10=10, cari 10, keluarkan data, jika rekod baris yang disimpan dalam data adalah dibawa keluar, pertanyaan tamat . Jika alamat cakera disimpan, data perlu diambil dari cakera mengikut alamat cakera, dan pertanyaan ditamatkan.
Berbanding dengan pepohon carian seimbang binari, semasa keseluruhan proses carian, walaupun bilangan perbandingan data tidak berkurangan dengan ketara, bilangan IO cakera akan dikurangkan dengan banyaknya. Pada masa yang sama, memandangkan perbandingan kami dilakukan dalam ingatan, masa perbandingan boleh diabaikan. Ketinggian pokok B biasanya 2 hingga 3 lapisan, yang boleh memenuhi kebanyakan senario aplikasi, jadi menggunakan pokok B untuk membina indeks boleh meningkatkan kecekapan pertanyaan dengan banyak.
Prosesnya adalah seperti yang ditunjukkan dalam gambar:
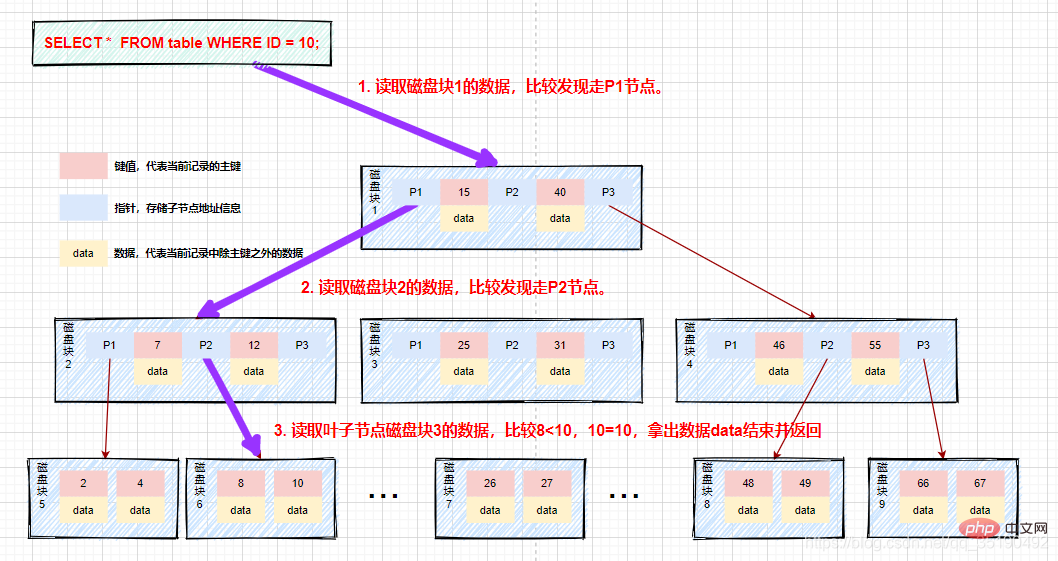
Melihat ini, anda mesti berfikir bahawa B-tree adalah ideal, tetapi yang senior akan memberitahu anda bahawa ia masih wujud dan boleh dioptimumkan Tempat:
Pokok B tidak menyokong carian pantas pertanyaan julat Jika anda memikirkan situasi ini, jika kita mahu mencari data antara 10 dan 35, kami akan menemui 15 Selepas itu, anda perlu kembali ke nod akar dan melintasi carian semula Anda perlu melintasi beberapa kali dari nod akar, dan kecekapan pertanyaan perlu dipertingkatkan.
Jika data menyimpan rekod baris, saiz baris akan meningkat apabila bilangan lajur bertambah dan ruang yang diduduki akan bertambah. Pada masa ini, jumlah data yang boleh disimpan dalam halaman akan berkurangan, pokok akan menjadi lebih tinggi, dan bilangan IO cakera akan meningkat.
Pokok B: Mengubah pokok B
Pokok B, sebagai versi pepohon B yang dinaik taraf, berdasarkan pepohon B, MySQL terus berubah berdasarkan pepohon B , Bina indeks menggunakan pokok B. Perbezaan utama antara B-tree dan B-tree ialah sama ada nod bukan daun menyimpan data
- B-tree: kedua-dua nod bukan daun dan nod daun menyimpan data.
- Pokok B: Hanya nod daun menyimpan data dan nod bukan daun menyimpan nilai kunci. Nod daun disambungkan menggunakan penunjuk dua hala, dan nod daun terendah membentuk senarai terpaut tersusun dua hala.
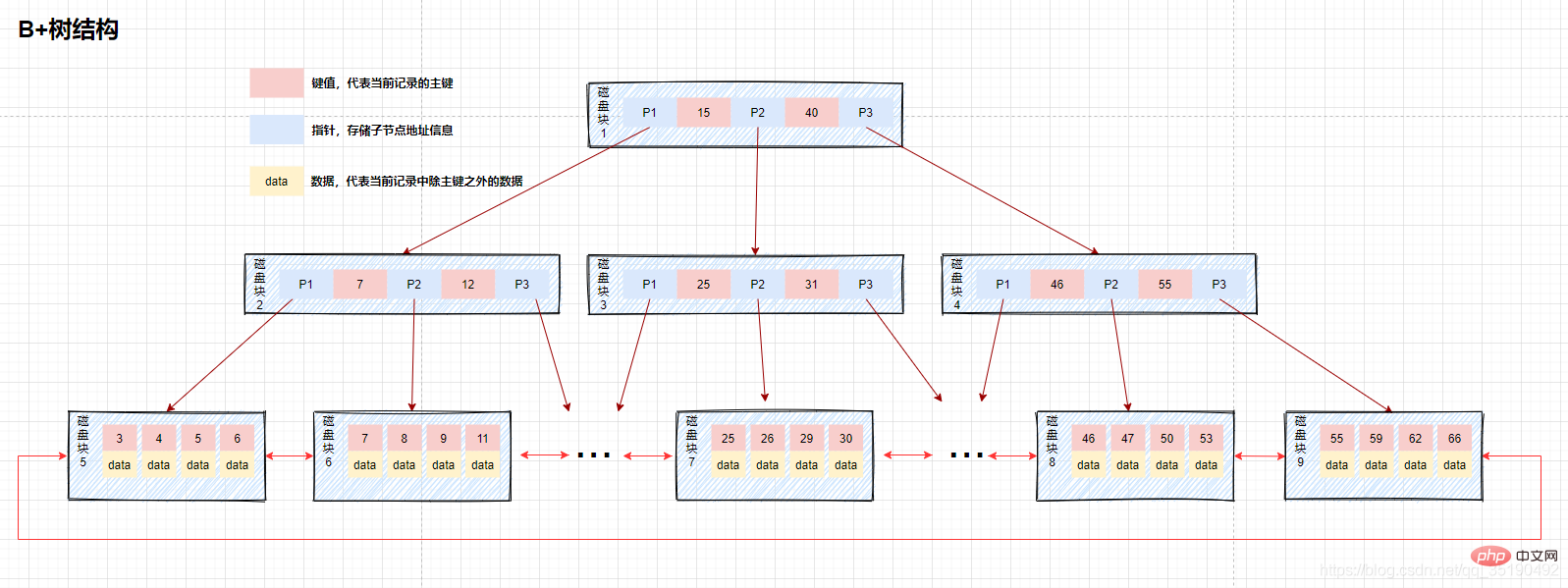
Nod daun terendah pokok B mengandungi semua item indeks. Seperti yang dapat dilihat daripada rajah, apabila B-tree mencari data, memandangkan data disimpan pada nod daun di bahagian bawah, setiap carian perlu mendapatkan semula nod daun untuk menanyakan data. Oleh itu, apabila data perlu ditanya, setiap cakera IO berkaitan secara langsung dengan ketinggian pokok Tetapi sebaliknya, kerana data diletakkan dalam nod daun, bilangan indeks yang disimpan dalam kunci blok cakera indeks. adalah Ia akan meningkat dengan ini, jadi berbanding dengan pokok B, ketinggian pokok B secara teorinya lebih pendek daripada pokok B. Terdapat juga kes di mana indeks meliputi pertanyaan Data dalam indeks memenuhi semua data yang diperlukan oleh pernyataan pertanyaan semasa Dalam kes ini, anda hanya perlu mencari indeks untuk kembali dengan segera, tanpa mendapatkan nod daun terendah.
Contohnya:
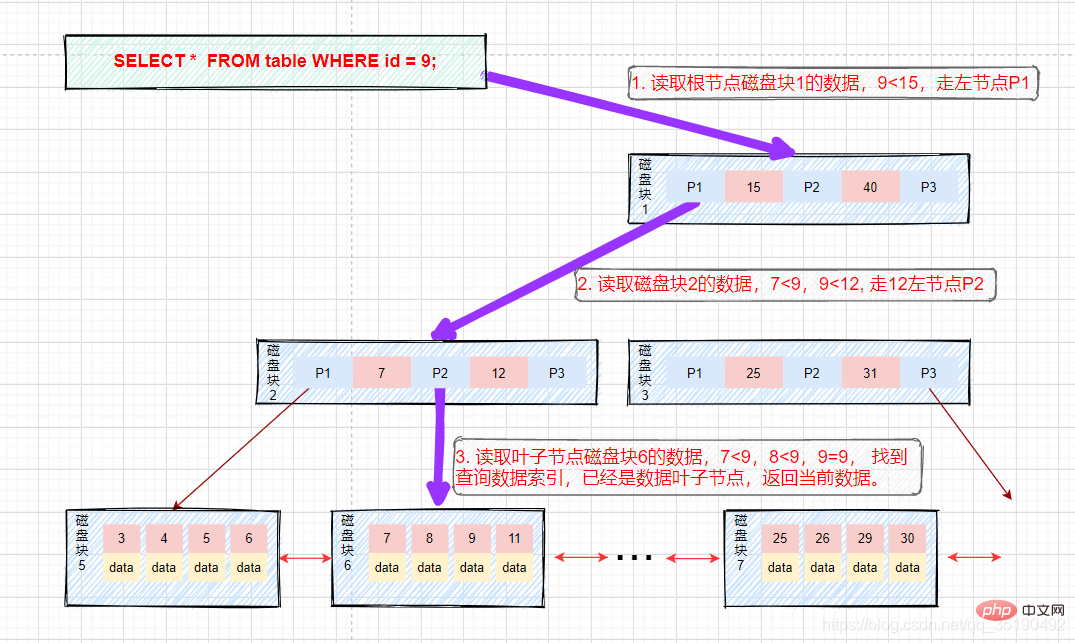
- Pertanyaan nilai yang sama:
Jika kita menanyakan nilai yang sama dengan 9 data. Blok cakera laluan pertanyaan 1->blok cakera 2->blok cakera 6.
IO cakera pertama: Muatkan blok cakera 1 ke dalam memori, lintasi dan bandingkan dalam ingatan dari awal, 9
IO cakera kedua: muatkan blok cakera 2 ke dalam memori, lintasi dan bandingkan dalam ingatan dari awal, 7
IO cakera ketiga: muatkan blok cakera 6 ke dalam memori, lintasi dan bandingkan dalam memori dari awal, cari 9 dalam indeks ketiga, keluarkan data, jika data disimpan Baris rekod, keluarkan data dan pertanyaan tamat. Jika alamat cakera disimpan, data perlu diambil dari cakera mengikut alamat cakera, dan pertanyaan ditamatkan. (Apa yang perlu dibezakan di sini ialah Data dalam InnoDB menyimpan data baris, manakala MyIsam menyimpan alamat cakera.)
Prosesnya adalah seperti yang ditunjukkan dalam rajah:
- Pertanyaan julat:
Andaikan kita ingin mencari data antara 9 dan 26. Laluan carian ialah blok cakera 1->blok cakera 2->blok cakera 6->blok cakera 7.
Mula-mula cari data dengan nilai yang sama dengan 9, dan cache data dengan nilai yang sama dengan 9 ke set hasil. Langkah ini adalah sama seperti proses pertanyaan setara sebelumnya, dan tiga IO cakera berlaku.
Selepas mencari 15, nod daun asas ialah senarai tersusun Kami bermula dari blok cakera 6 dan nilai kunci 9 dan melintasi ke belakang untuk menapis semua data yang memenuhi syarat penapisan.
IO cakera keempat: Alamat dan cari blok cakera 7 mengikut penunjuk pengganti cakera 6, muatkan cakera 7 ke dalam ingatan, lalui dan bandingkan dalam memori dari awal, 9< ;25
Kunci utama adalah unik (tidak akan ada
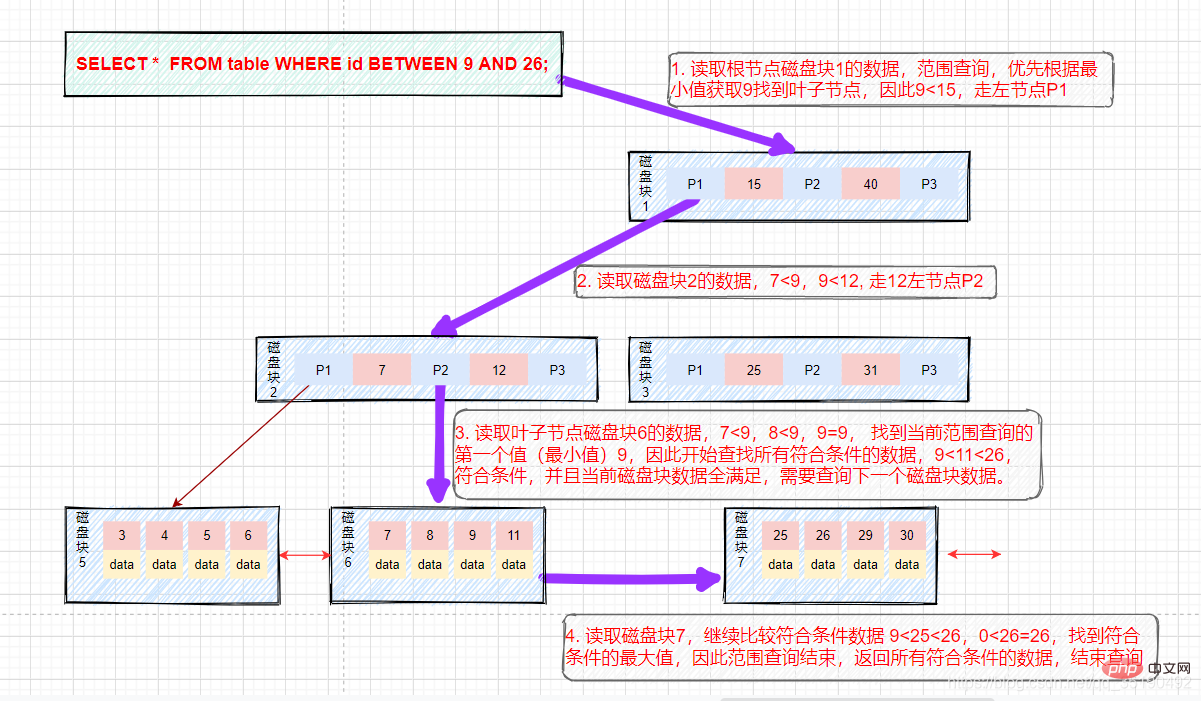
Anda boleh melihat bahawa B-tree boleh memastikan carian pantas bagi nilai yang sama dan pertanyaan julat menggunakan B Tree struktur data.
Pelaksanaan indeks Mysql
Selepas memperkenalkan struktur data indeks, ia mesti dibawa ke dalam Mysql untuk melihat senario penggunaan sebenar, jadi di sini kita menganalisis dua kaedah penyimpanan pelaksanaan Indeks Mysql daripada enjin: Indeks MyISAM dan Indeks InnoDB
Indeks MyIsam
Ambil jadual pengguna ringkas sebagai contoh. Terdapat dua indeks dalam jadual pengguna, lajur id ialah indeks kunci utama, dan lajur umur ialah indeks biasa
CREATE TABLE `user`( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(20) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, KEY `idx_age` (`age`) USING BTREE) ENGINE = MyISAM AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
Fail data dan fail indeks MyISAM disimpan secara berasingan. Apabila MyISAM menggunakan B-tree untuk membina pepohon indeks, nilai kunci yang disimpan dalam nod daun ialah nilai lajur indeks dan data ialah alamat cakera bagi baris di mana indeks terletak.
Indeks kunci utama

Indeks pengguna jadual disimpan dalam fail indeks user.MYI dan fail data disimpan dalam fail data user.MYD.
Analisis ringkas situasi IO cakera semasa pertanyaan:
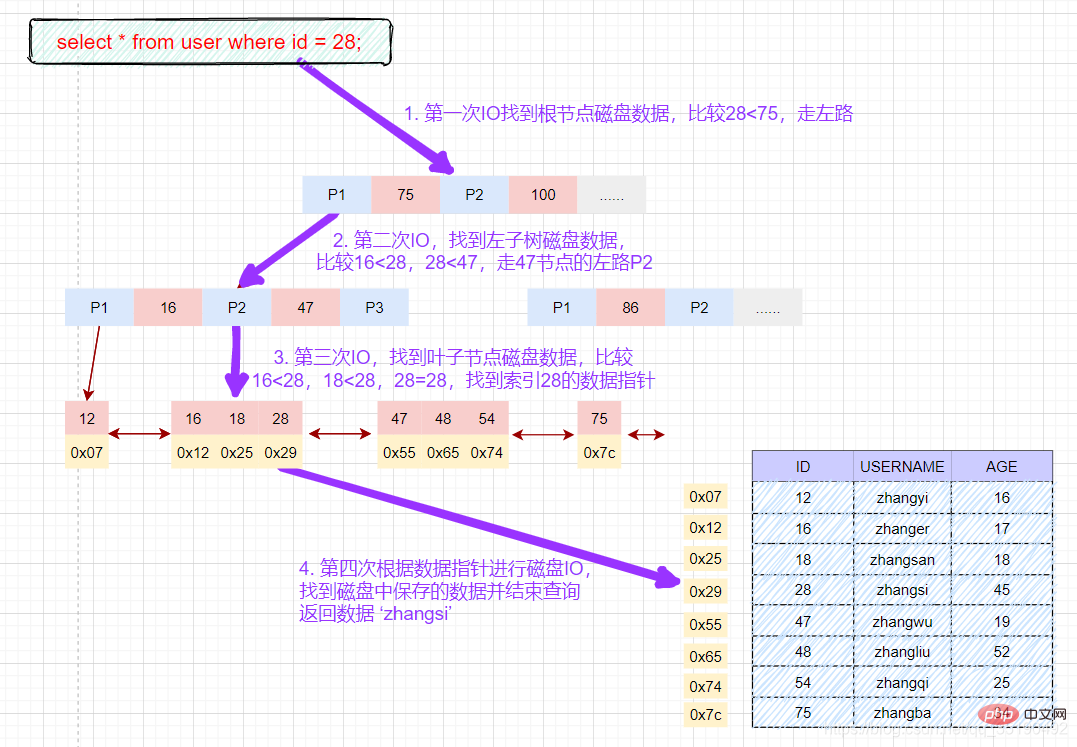
Data pertanyaan berdasarkan persamaan kunci primer:
select * from user where id = 28;
- 先在主键树中从根节点开始检索,将根节点加载到内存,比较28
- 将左子树节点加载到内存中,比较16
- 检索到叶节点,将节点加载到内存中遍历,比较16
- 从索引项中获取磁盘地址,然后到数据文件user.MYD中获取对应整行记录。(1次磁盘IO)
- 将记录返给客户端。
磁盘IO次数:3次索引检索+记录数据检索。
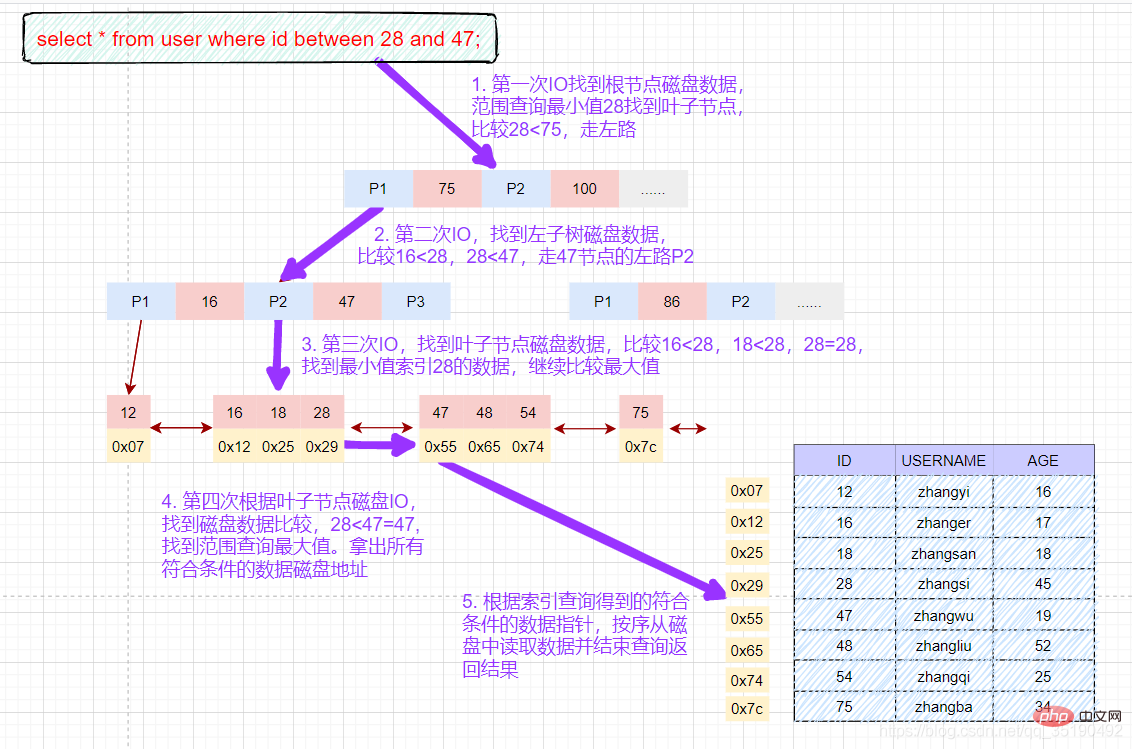
根据主键范围查询数据:
select * from user where id between 28 and 47;
先在主键树中从根节点开始检索,将根节点加载到内存,比较28
将左子树节点加载到内存中,比较16
-
检索到叶节点,将节点加载到内存中遍历比较16
根据磁盘地址从数据文件中获取行记录缓存到结果集中。(1次磁盘IO)
我们的查询语句时范围查找,需要向后遍历底层叶子链表,直至到达最后一个不满足筛选条件。
向后遍历底层叶子链表,将下一个节点加载到内存中,遍历比较,28
最后得到两条符合筛选条件,将查询结果集返给客户端。
磁盘IO次数:4次索引检索+记录数据检索。
**备注:**以上分析仅供参考,MyISAM在查询时,会将索引节点缓存在MySQL缓存中,而数据缓存依赖于操作系统自身的缓存,所以并不是每次都是走的磁盘,这里只是为了分析索引的使用过程。
辅助索引
在 MyISAM 中,辅助索引和主键索引的结构是一样的,没有任何区别,叶子节点的数据存储的都是行记录的磁盘地址。只是主键索引的键值是唯一的,而辅助索引的键值可以重复。
查询数据时,由于辅助索引的键值不唯一,可能存在多个拥有相同的记录,所以即使是等值查询,也需要按照范围查询的方式在辅助索引树中检索数据。
InnoDB索引
主键索引(聚簇索引)
每个InnoDB表都有一个聚簇索引 ,聚簇索引使用B+树构建,叶子节点存储的数据是整行记录。一般情况下,聚簇索引等同于主键索引,当一个表没有创建主键索引时,InnoDB会自动创建一个ROWID字段来构建聚簇索引。InnoDB创建索引的具体规则如下:
- 在表上定义主键PRIMARY KEY,InnoDB将主键索引用作聚簇索引。
- 如果表没有定义主键,InnoDB会选择第一个不为NULL的唯一索引列用作聚簇索引。
- 如果以上两个都没有,InnoDB 会使用一个6 字节长整型的隐式字段 ROWID字段构建聚簇索引。该ROWID字段会在插入新行时自动递增。
除聚簇索引之外的所有索引都称为辅助索引。在中InnoDB,辅助索引中的叶子节点存储的数据是该行的主键值都。 在检索时,InnoDB使用此主键值在聚簇索引中搜索行记录。
这里以user_innodb为例,user_innodb的id列为主键,age列为普通索引。
CREATE TABLE `user_innodb`( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(20) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, KEY `idx_age` (`age`) USING BTREE) ENGINE = InnoDB;
InnoDB的数据和索引存储在一个文件t_user_innodb.ibd中。InnoDB的数据组织方式,是聚簇索引。
主键索引的叶子节点会存储数据行,辅助索引只会存储主键值。
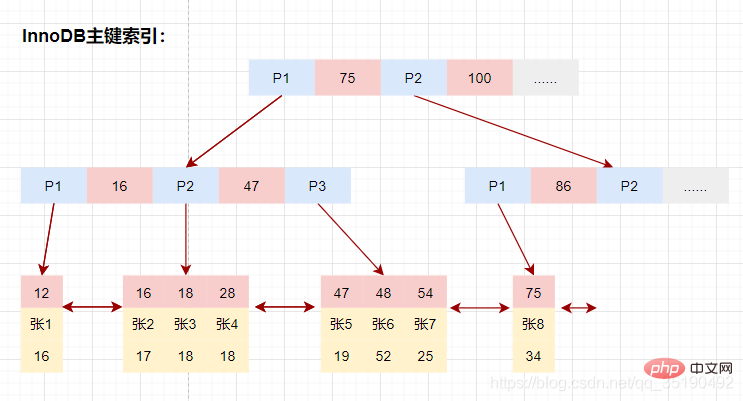
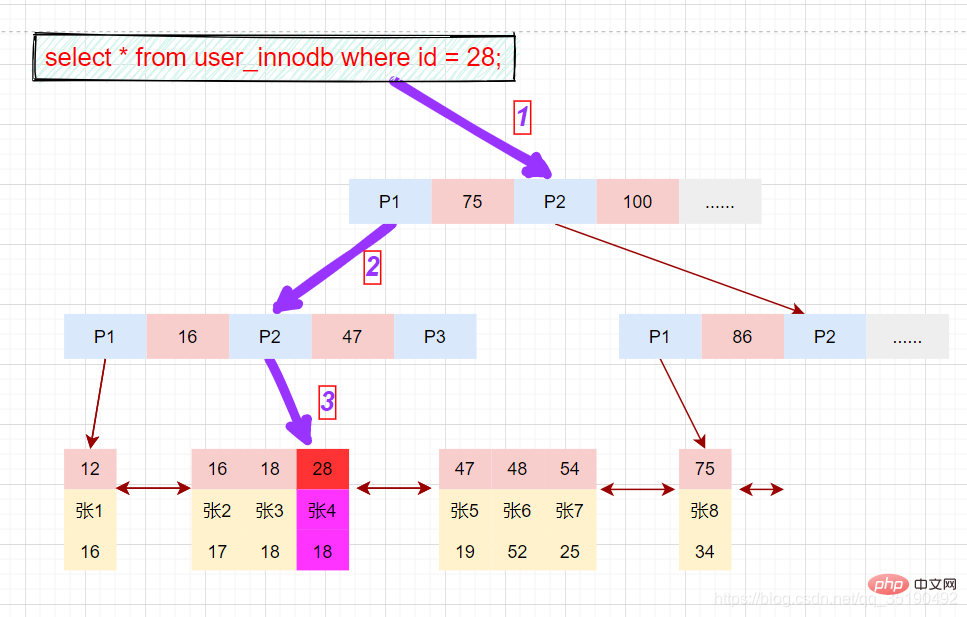
等值查询数据:
select * from user_innodb where id = 28;
先在主键树中从根节点开始检索,将根节点加载到内存,比较28
将左子树节点加载到内存中,比较16
-
检索到叶节点,将节点加载到内存中遍历,比较16
磁盘IO数量:3次。
辅助索引
除聚簇索引之外的所有索引都称为辅助索引,InnoDB的辅助索引只会存储主键值而非磁盘地址。
以表user_innodb的age列为例,age索引的索引结果如下图。
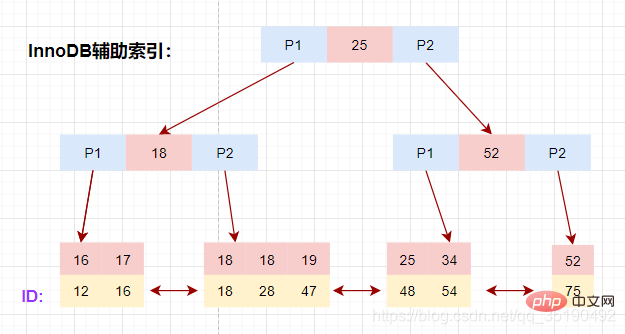
底层叶子节点的按照(age,id)的顺序排序,先按照age列从小到大排序,age列相同时按照id列从小到大排序。
使用辅助索引需要检索两遍索引:首先检索辅助索引获得主键,然后使用主键到主索引中检索获得记录。
画图分析等值查询的情况:
select * from t_user_innodb where age=19;
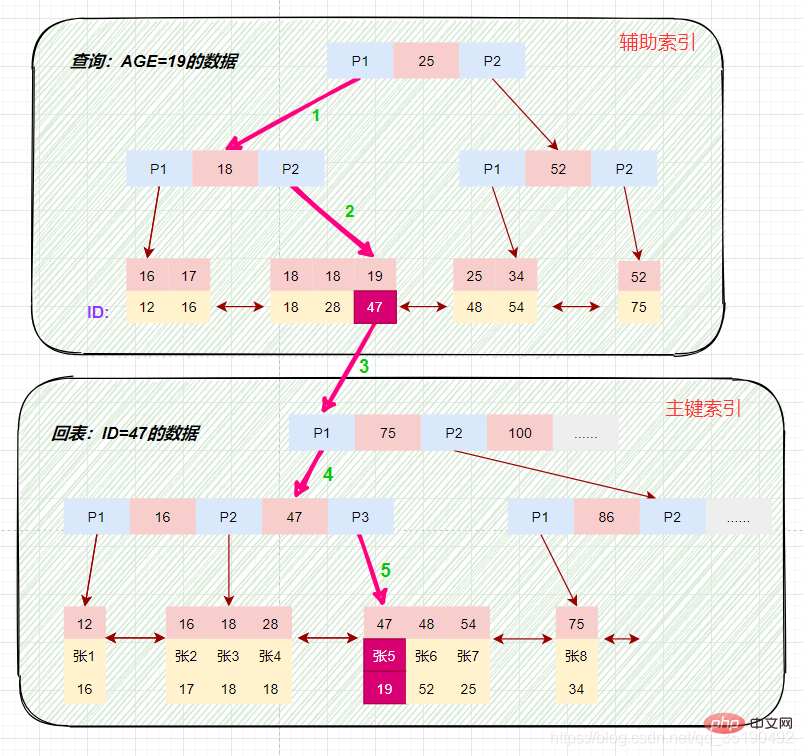
根据在辅助索引树中获取的主键id,到主键索引树检索数据的过程称为回表查询。
磁盘IO数:辅助索引3次+获取记录回表3次
组合索引
还是以自己创建的一个表为例:表 abc_innodb,id为主键索引,创建了一个联合索引idx_abc(a,b,c)。
CREATE TABLE `abc_innodb`( `id` int(11) NOT NULL AUTO_INCREMENT, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, `c` varchar(10) DEFAULT NULL, `d` varchar(10) DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, KEY `idx_abc` (`a`, `b`, `c`)) ENGINE = InnoDB;
select * from abc_innodb order by a, b, c, id;
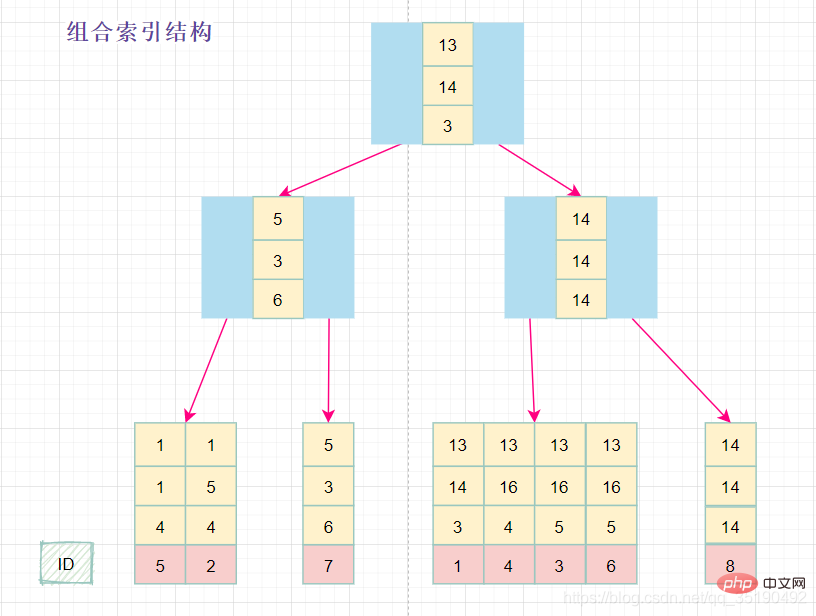
组合索引的数据结构:
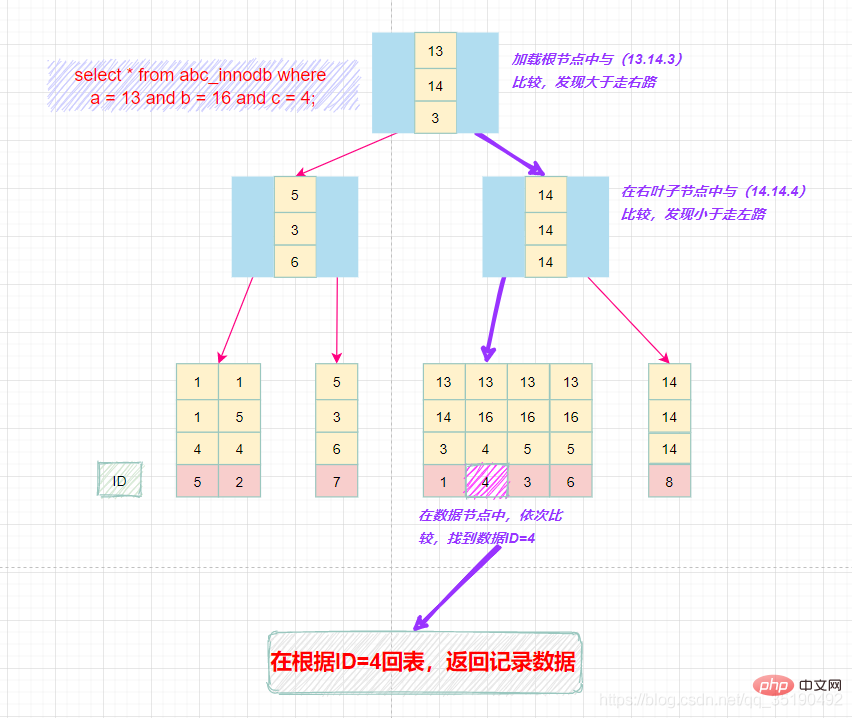
组合索引的查询过程:
select * from abc_innodb where a = 13 and b = 16 and c = 4;
最左匹配原则:
最左前缀匹配原则和联合索引的索引存储结构和检索方式是有关系的。
在组合索引树中,最底层的叶子节点按照第一列a列从左到右递增排列,但是b列和c列是无序的,b列只有在a列值相等的情况下小范围内递增有序,而c列只能在a,b两列相等的情况下小范围内递增有序。
就像上面的查询,B+树会先比较a列来确定下一步应该搜索的方向,往左还是往右。如果a列相同再比较b列。但是如果查询条件没有a列,B+树就不知道第一步应该从哪个节点查起。
可以说创建的idx_abc(a,b,c)索引,相当于创建了(a)、(a,b)(a,b,c)三个索引。、
组合索引的最左前缀匹配原则:使用组合索引查询时,mysql会一直向右匹配直至遇到范围查询(>、
覆盖索引
覆盖索引并不是说是索引结构,覆盖索引是一种很常用的优化手段。因为在使用辅助索引的时候,我们只可以拿到主键值,相当于获取数据还需要再根据主键查询主键索引再获取到数据。但是试想下这么一种情况,在上面abc_innodb表中的组合索引查询时,如果我只需要abc字段的,那是不是意味着我们查询到组合索引的叶子节点就可以直接返回了,而不需要回表。这种情况就是覆盖索引。
可以看一下执行计划:
覆盖索引的情况:

未使用到覆盖索引:

总结
看到这里,你是不是对于自己的sql语句里面的索引的有了更多优化想法呢。比如:
避免回表
在InnoDB的存储引擎中,使用辅助索引查询的时候,因为辅助索引叶子节点保存的数据不是当前记录的数据而是当前记录的主键索引,索引如果需要获取当前记录完整数据就必然需要根据主键值从主键索引继续查询。这个过程我们成位回表。想想回表必然是会消耗性能影响性能。那如何避免呢?
使用索引覆盖,举个例子:现有User表(id(PK),name(key),sex,address,hobby…)
Jika dalam senario, select id,name,sex from user where name ='zhangsan'; penyataan ini kerap digunakan dalam perniagaan dan medan lain dalam jadual pengguna digunakan lebih kurang kerap daripadanya. Dalam kes ini, jika kita mencipta indeks pada medan nama , bukannya menggunakan indeks tunggal, gunakan indeks bersama (nama, jantina). Dalam kes ini, jika anda melaksanakan pernyataan pertanyaan ini sekali lagi, anda boleh mendapatkan data lengkap pernyataan semasa berdasarkan hasil pertanyaan indeks tambahan. Ini dengan berkesan boleh mengelak daripada kembali ke meja untuk mendapatkan data seks.
Berikut ialah strategi pengoptimuman biasa menggunakan indeks penutup untuk mengurangkan kembali jadual.
Penggunaan indeks bersama
Indeks bersama Semasa membina indeks, cuba menilai sama ada indeks bersama boleh digunakan pada berbilang indeks lajur tunggal. Penggunaan indeks bersama bukan sahaja menjimatkan ruang, tetapi juga memudahkan penggunaan liputan indeks. Bayangkan, lebih banyak medan diindeks, lebih mudah untuk memenuhi data yang dikembalikan oleh pertanyaan. Sebagai contoh, indeks bersama (a_b_c) adalah bersamaan dengan tiga indeks: a, a_b, a_b_c Adakah ini menjimatkan ruang Sudah tentu, ruang yang disimpan bukan tiga kali ganda daripada tiga indeks (a, a_b, a_b_c). Kerana data dalam pepohon indeks tidak berubah, tetapi data dalam medan data indeks memang disimpan.
Prinsip untuk mencipta indeks bersama Apabila mencipta indeks bersama, lajur dan lajur yang kerap digunakan harus diletakkan di hadapan butiran penapisan besar Ini adalah senario pengoptimuman yang perlu dipertimbangkan semasa membuat indeks yang sering dikembalikan kerana pertanyaan juga boleh ditambahkan pada indeks bersama dan liputan digunakan Indeks Saya mengesyorkan menggunakan indeks bersama dalam kes ini.
Penggunaan indeks bersama
- Pertimbangkan sama ada sudah terdapat berbilang indeks lajur tunggal yang boleh digabungkan Jika ya, buat berbilang lajur tunggal semasa indeks sebagai indeks bersama.
Indeks semasa mengandungi lajur yang kerap digunakan sebagai medan kembali Pada masa ini, anda boleh mempertimbangkan sama ada lajur semasa boleh ditambahkan pada indeks sedia ada supaya pernyataan pertanyaan boleh menggunakan indeks penutup. .
[Disyorkan: tutorial video mysql]
Atas ialah kandungan terperinci Fahami semua mata pengetahuan indeks MySQL dalam satu artikel (disyorkan untuk dikumpulkan). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Apakah yang perlu saya lakukan jika saya terlupa kata laluan saya dalam mysql 5.7?
- Bagaimana untuk menyelesaikan masalah mysql jsp aksara bercelaru
- Bagaimana untuk menutup mysql dalam linux
- Bagaimana untuk menggunakan PHP Mysql untuk melaksanakan fungsi tambah, padam, ubah suai dan pertanyaan asas? (contoh terperinci)
- Fokus pada merekodkan proses pemindahan data peringkat juta Mysql!