
Rumah >Operasi dan penyelenggaraan >operasi dan penyelenggaraan linux >Bagaimana untuk memasang hadoop dalam linux
Bagaimana untuk memasang hadoop dalam linux

- 藏色散人asal
- 2021-12-17 17:03:5611968semak imbas
Cara memasang Hadoop pada Linux: 1. Pasang perkhidmatan ssh; 2. Gunakan ssh untuk log masuk tanpa pengesahan kata laluan; 4. Buka zip pakej pemasangan Hadoop; fail Hadoop Just yang sepadan.

Persekitaran pengendalian artikel ini: sistem ubuntu 16.04, Hadoop versi 2.7.1, komputer Dell G3.
Bagaimana untuk memasang hadoop dalam linux?
[Data Besar] Penjelasan terperinci tentang memasang Hadoop (2.7.1) dan menjalankan WordCount di bawah Linux
1 Selepas mengkonfigurasi persekitaran Storm, saya ingin memikirkan pemasangan Hadoop Terdapat banyak tutorial di Internet, tetapi tiada satu pun yang sesuai, jadi saya masih menghadapi banyak masalah semasa proses pemasangan , saya akhirnya menyelesaikannya. Soalan itu masih terasa baik.
Persekitaran konfigurasi mesin ini adalah seperti berikut: Hadoop (2.7.1) Ubuntu Linux (sistem 64-bit) Yang berikut terbahagi kepada beberapa langkah Mari jelaskan proses konfigurasi secara terperinci.2. Pasang perkhidmatan ssh
Masukkan arahan shell dan masukkan arahan berikut untuk menyemak sama ada perkhidmatan ssh telah dipasang, gunakan arahan berikut untuk memasangnya:
Proses pemasangan agak mudah dan menyeronokkan. sudo apt-get install ssh openssh-server
3. Gunakan ssh untuk log masuk pengesahan tanpa kata laluan
1. Cipta ssh-key Di sini kita menggunakan kaedah rsa dan gunakan arahan berikut:
2. Grafik yang dipaparkan ialah kata laluannya ssh-keygen -t rsa -P ""
3. Kemudian anda boleh. log masuk tanpa pengesahan kata laluan. Seperti berikut: cat ~/.ssh/id_rsa.pub >> authorized_keys(好像是可以省略的)
Tangkapan skrin yang berjaya adalah seperti berikut: ssh localhost
 4 . Muat turun pakej pemasangan Hadoop
4 . Muat turun pakej pemasangan Hadoop
Terdapat dua cara untuk memuat turun dan memasang Hadoop
1. Pergi terus ke tapak web rasmi untuk memuat turun, http://mirrors.hust.edu .cn/apache/hadoop/core/stable/hadoop-2.7.1 .tar.gz 2. Gunakan shell untuk memuat turun, arahannya adalah seperti berikut: Akhirnya muat turun selesai .5. Nyahmampat pakej pemasangan Hadoop wget http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz
Gunakan arahan berikut untuk menyahmampat pakej pemasangan Hadoop
tar -zxvf hadoop-2.7.1. tar. gz Selepas penyahmampatan selesai, folder hadoop2.7.1 muncul
6. Konfigurasikan fail yang sepadan dalam HadoopFail yang memerlukan yang akan dikonfigurasikan adalah seperti berikut, hadoop-env.sh, core-site.xml, mapred-site.xml.template, hdfs-site.xml, semua fail terletak di bawah hadoop2.7.1/etc/hadoop adalah seperti berikut:
1.core-site.xml dikonfigurasikan seperti berikut:
Laluan hadoop.tmp.dir boleh ditetapkan mengikut tabiat anda sendiri. 2.mapred-site.xml.template dikonfigurasikan seperti berikut:<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/home/leesf/program/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>3.hdfs-site.xml dikonfigurasikan seperti berikut:
Di mana dfs.namenode Laluan .name.dir dan dfs.datanode.data.dir boleh ditetapkan secara bebas, sebaik-baiknya di bawah direktori hadoop.tmp.dir.
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>Di samping itu, jika anda mendapati bahawa jdk tidak boleh ditemui semasa menjalankan Hadoop, anda boleh terus meletakkan laluan jdk dalam hadoop.env.sh, seperti berikut: eksport JAVA_HOME="/ home/ leesf/program/java/jdk1.8.0_60"
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/leesf/program/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/leesf/program/hadoop/tmp/dfs/data</value> </property> </configuration>7. Jalankan Hadoop
Selepas konfigurasi selesai, jalankan hadoop.
1. Mulakan sistem HDFS Gunakan arahan berikut dalam direktori hadop2.7.1:
Tangkapan skrin adalah seperti berikut:bin/hdfs namenode -formatProses ini memerlukan pengesahan ssh Anda telah log masuk sebelum ini, jadi taipkan y di antara proses permulaan. Tangkapan skrin yang berjaya adalah seperti berikut:

dan  daemon
daemon
Gunakan arahan berikut untuk membuka:
NameNode 3. Lihat maklumat proses DataNode
sbin/start-dfs.sh,成功的截图如下:
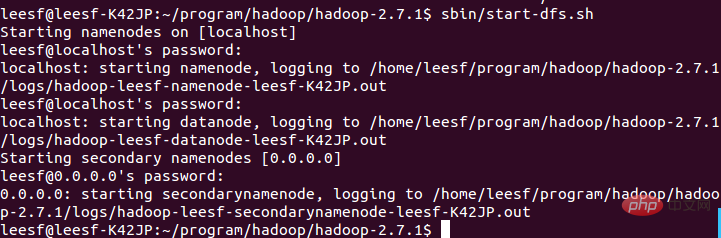 Mewakili data DataNode dan NameNode telah dimulakan
Mewakili data DataNode dan NameNode telah dimulakan
4. Lihat UI Web
Masukkan http://localhost:50070 dalam penyemak imbas untuk melihat maklumat yang berkaitan adalah seperti berikut:
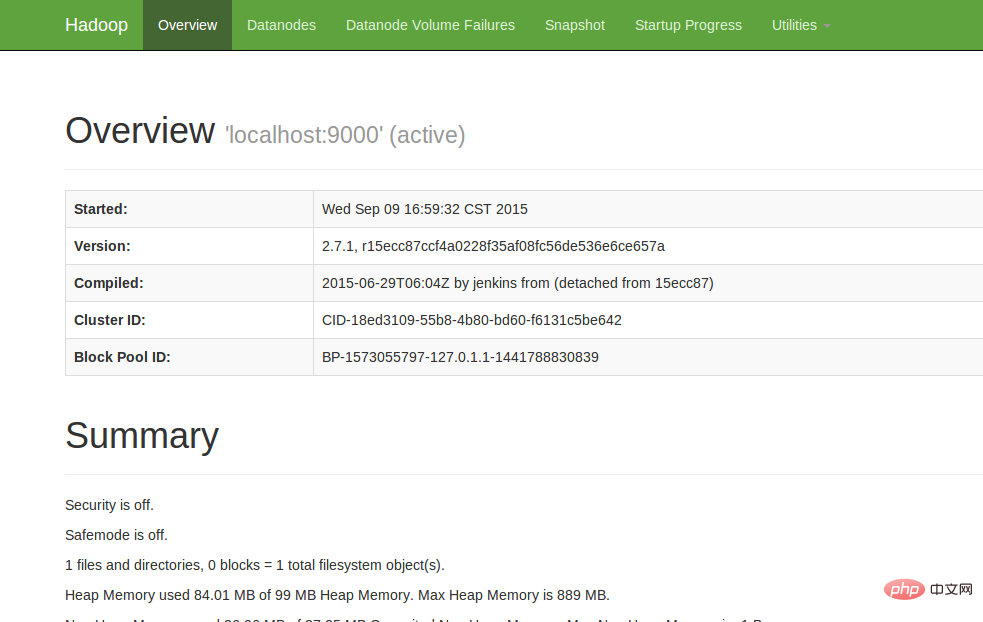
Pada ketika ini, persekitaran hadoop telah disediakan. Mari mulakan menggunakan hadoop untuk menjalankan contoh WordCount.
8. Jalankan WordCount Demo
1. Buat fail baharu secara setempat Pengarang mencipta dokumen perkataan baharu dalam direktori home/leesf kandungan yang anda suka.
2. Cipta folder baharu dalam HDFS untuk memuat naik dokumen perkataan tempatan Masukkan arahan berikut dalam direktori hadoop2.7.1:
bin/hdfs dfs -mkdir /test, bermaksud Direktori ujian. telah dicipta dalam direktori root hdfs
Gunakan arahan berikut untuk melihat struktur direktori dalam direktori root HDFS
bin/hdfs dfs -ls /
Tangkapan skrin khusus Seperti berikut:

Ini bermakna direktori ujian telah dibuat dalam direktori akar HDFS
3. Muat naik dokumen perkataan tempatan ke direktori ujian
Gunakan arahan berikut untuk memuat naik:
bin/hdfs dfs -put /home/leesf/words /test/
Gunakan arahan berikut untuk melihat
bin/ hdfs dfs -ls /test/
Tangkapan skrin keputusan adalah seperti berikut:

 Tangkapan skrin adalah seperti berikut:
Tangkapan skrin adalah seperti berikut:
Sudah ada direktori fail bernama Out di bawah
Masukkan arahan berikut untuk melihat fail dalam direktori out:
bin/hdfs dfs -ls /test/out, tangkapan skrin keputusan adalah seperti berikut:

Menunjukkan bahawa ia telah berjaya dijalankan dan hasilnya disimpan dalam bahagian-r-00000.
5. Semak hasil yang sedang dijalankan
Gunakan arahan berikut untuk menyemak hasil yang sedang dijalankan:
bin/hadoop fs -cat /test/out/part-r-00000 
Pada ketika ini, proses berjalan telah selesai.
9. Ringkasan Saya menghadapi banyak masalah semasa proses konfigurasi hadoop ini masih menyelesaikan masalah satu demi satu, konfigurasi berjaya, dan saya mendapat banyak saya ingin berkongsi pengalaman konfigurasi ini untuk kemudahan semua tukang kebun yang ingin mengkonfigurasi persekitaran Hadoop proses konfigurasi, sila berasa bebas untuk membincangkannya , terima kasih kerana menonton~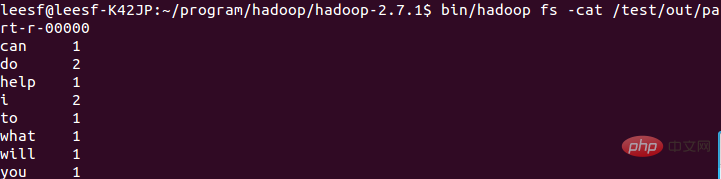
tutorial video linux
"Atas ialah kandungan terperinci Bagaimana untuk memasang hadoop dalam linux. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!