
Rumah >pangkalan data >tutorial mysql >Ketahui lebih lanjut tentang pengasingan master-standby, master-slave dan read-write dalam MySQL
Ketahui lebih lanjut tentang pengasingan master-standby, master-slave dan read-write dalam MySQL

- 青灯夜游asal
- 2021-09-01 18:46:572801semak imbas
Artikel ini akan membawa anda melalui pemisahan master-slave, master-slave dan baca-tulis dalam MySQL. Saya harap ia akan membantu anda!
1 Prinsip asas MySQL utama dan sandaran
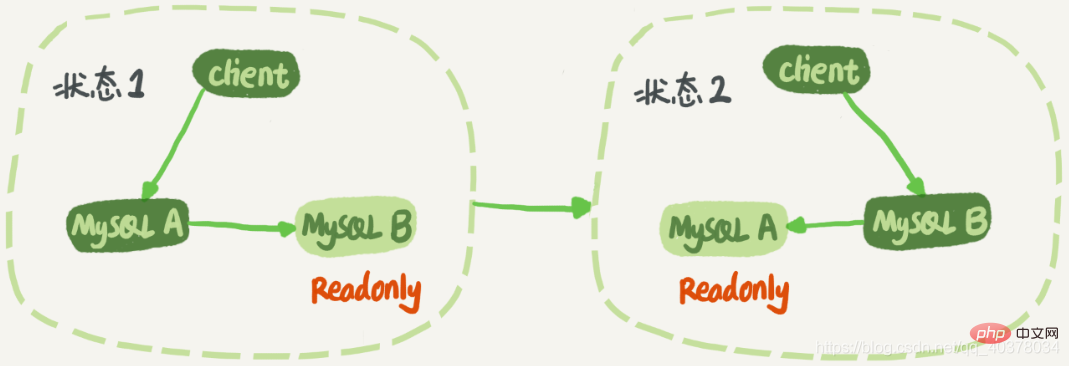
Dalam keadaan 1, pelanggan mengakses secara langsung nod A untuk membaca dan menulis, manakala nod B Ia adalah pangkalan data siap sedia A. Ia hanya menyegerakkan semua kemas kini A dan melaksanakannya secara tempatan. Ini memastikan data nod B dan A sama. Apabila penukaran diperlukan, tukar kepada keadaan 2. Pada masa ini, pelanggan membaca dan menulis ke nod B, dan nod A ialah pangkalan data siap sedia B. [Cadangan berkaitan: tutorial video mysql]
Dalam keadaan 1, walaupun nod B tidak diakses secara langsung, adalah disyorkan untuk menetapkan nod siap sedia B kepada mod baca sahaja. Terdapat beberapa sebab:
1 Kadangkala beberapa pernyataan pertanyaan operasi akan diletakkan pada pangkalan data sedia untuk pertanyaan Menetapkannya kepada baca sahaja boleh mengelakkan salah operasi
2 pepijat
3. Anda boleh menggunakan status baca sahaja untuk menentukan peranan nod
Bagaimana untuk memastikan pangkalan data siap sedia dikemas kini secara serentak dengan pangkalan data utama jika ia ditetapkan kepada baca sahaja?
Tetapan baca sahaja tidak sah untuk pengguna istimewa super, dan urutan yang digunakan untuk kemas kini disegerakkan mempunyai keistimewaan super
Rajah berikut menunjukkan pernyataan kemas kini yang dilaksanakan pada nod A, dan kemudian disegerakkan ke nod B Carta alir lengkap: 
Sambungan yang panjang dikekalkan antara pangkalan data siap sedia B dan pangkalan data utama A. Terdapat benang di dalam perpustakaan utama A, yang dikhaskan untuk menyediakan sambungan panjang perpustakaan siap sedia B. Proses lengkap penyegerakan log transaksi adalah seperti berikut:
1 Gunakan arahan induk tukar pada pangkalan data siap sedia B untuk menetapkan IP, port, nama pengguna, kata laluan pangkalan data utama A dan lokasi dari mana untuk bermula. meminta binlog. Lokasi ini mengandungi nama fail dan log offset
2. Jalankan arahan hamba mula pada pangkalan data siap sedia B. Pada masa ini, pangkalan data siap sedia akan memulakan dua utas, iaitu io_thread dan sql_thread dalam rajah. Antaranya, io_thread bertanggungjawab untuk mewujudkan sambungan dengan perpustakaan utama
3 Selepas perpustakaan utama A mengesahkan nama pengguna dan kata laluan, ia mula membaca binlog dari tempatan mengikut lokasi yang dilalui oleh pihak tersebut. pustaka sandaran B, dan menghantarnya ke B
4 Selepas pangkalan data siap sedia B mendapat binlog, ia menulisnya ke fail setempat, dipanggil log transit
5 , menghuraikan arahan dalam log dan melaksanakan
Disebabkan pengenalan skema replikasi berbilang benang, sql_thread berkembang menjadi berbilang benang
2
Struktur M Berganda: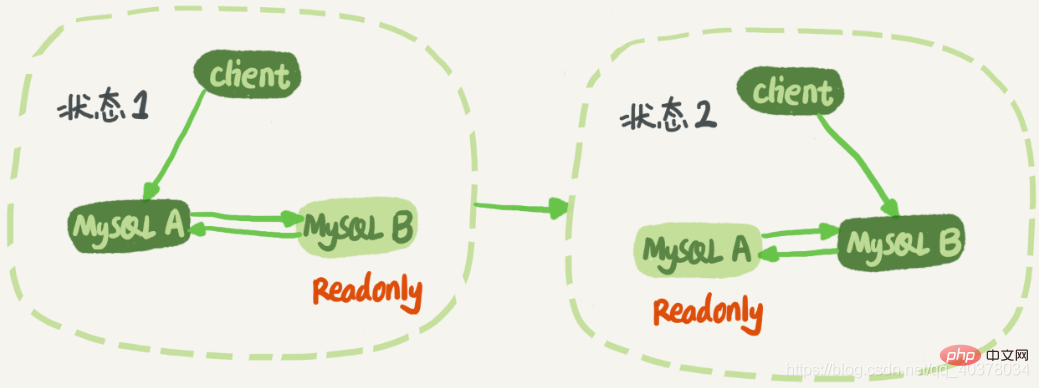 Nod A dan nod B mempunyai hubungan siap sedia induk antara satu sama lain. Dengan cara ini, tidak perlu mengubah suai perhubungan siap sedia aktif semasa suis
Nod A dan nod B mempunyai hubungan siap sedia induk antara satu sama lain. Dengan cara ini, tidak perlu mengubah suai perhubungan siap sedia aktif semasa suis
<.>Aliran pelaksanaan log struktur M berganda adalah seperti berikut:
1 Untuk transaksi yang dikemas kini dari nod A, id pelayan A direkodkan dalam binlog
2 dihantar ke nod B dan dilaksanakan sekali, id pelayan binlog yang dijana oleh nod B juga adalah A. Id pelayan
3 Kemudian ia dihantar semula ke nod A. A menentukan bahawa id pelayan ialah sama seperti miliknya dan tidak akan memproses log lagi. Oleh itu, gelung tak terhingga dipecahkan di sini
3. Kelewatan utama dan sandaran1. Apakah yang utama Persediaan untuk kelewatan?
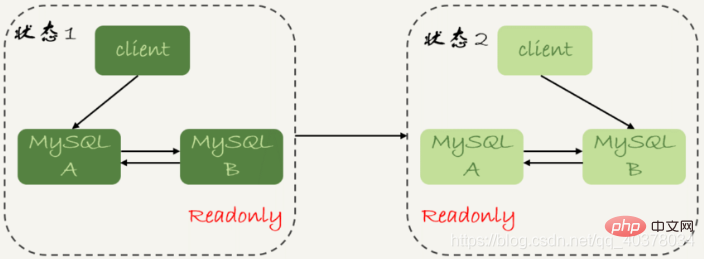 Titik masa yang berkaitan dengan penyegerakan data terutamanya termasuk tiga berikut:
Titik masa yang berkaitan dengan penyegerakan data terutamanya termasuk tiga berikut:
1 Pustaka utama A melengkapkan transaksi dan menulisnya ke binlog 🎜> 2. Kemudian hantar ke pangkalan data siap sedia B. Masa apabila pangkalan data siap sedia B menerima binlog direkodkan sebagai T2
3 Apa yang dipanggil kelewatan tuan-hamba ialah perbezaan antara masa apabila pangkalan data hamba dilaksanakan dan masa apabila pangkalan data induk selesai untuk transaksi yang sama, iaitu T3-T1 boleh melaksanakan paparan pada pangkalan data hamba perintah status hamba, hasil pengembaliannya akan memaparkan seconds_behind_master, yang digunakan untuk menunjukkan berapa saat pangkalan data siap sedia semasa ditangguhkan Kaedah pengiraan seconds_behind_master adalah seperti berikut:1. Terdapat medan masa dalam binlog setiap transaksi, yang digunakan untuk merekodkan masa yang ditulis pada pangkalan data utama
2 sedang melaksanakan urus niaga dan mengira Perbezaan di antaranya dan masa sistem semasa ialah seconds_behind_master
Jika tetapan masa sistem mesin pangkalan data utama dan siap sedia tidak konsisten, ia tidak akan membawa kepada nilai yang tidak tepat dari utama dan kelewatan sedia. Apabila pangkalan data siap sedia disambungkan ke pangkalan data utama, ia akan memperoleh masa sistem pangkalan data utama semasa melalui fungsi SELECTUNIX_TIMESTAMP(). Jika didapati bahawa masa sistem pangkalan data utama tidak konsisten dengan pangkalan datanya sendiri, pangkalan data siap sedia akan secara automatik menolak perbezaan apabila melakukan pengiraan seconds_behind_master
Di bawah keadaan rangkaian biasa, punca utama kelewatan dalam utama dan pangkalan data siap sedia ialah pangkalan data siap sedia telah menerima Perbezaan masa antara binlog dan pelaksanaan transaksi ini
Manifestasi paling langsung kelewatan sandaran induk ialah kelajuan di mana pangkalan data sandaran menggunakan log pemindahan adalah lebih perlahan daripada kelajuan pangkalan data utama menghasilkan binlog
2 Asal kelewatan antara pangkalan data aktif dan sandaran
1 daripada mesin di mana pangkalan data sandaran terletak lebih teruk daripada prestasi mesin di mana pangkalan data utama berada
2 Prestasi pangkalan data sandaran adalah Menekan. Pangkalan data utama menyediakan keupayaan menulis, dan pangkalan data siap sedia menyediakan beberapa keupayaan membaca. Mengabaikan kawalan tekanan pangkalan data siap sedia menyebabkan pertanyaan pada pangkalan data siap sedia menggunakan banyak sumber CPU, menjejaskan kelajuan penyegerakan dan menyebabkan kelewatan dalam pangkalan data primer dan sekunder
Boleh dikendalikan seperti berikut:
- Satu tuan, ramai hamba. Sebagai tambahan kepada pangkalan data siap sedia, anda boleh menyambungkan beberapa lagi perpustakaan hamba untuk berkongsi tekanan bacaan
- Output ke sistem luaran melalui binlog, seperti Hadoop, supaya sistem luaran boleh menyediakan keupayaan pertanyaan statistik
3. Kerana pangkalan data utama mesti menunggu transaksi dilaksanakan sebelum ia ditulis ke binlog dan kemudian dihantar ke pangkalan data siap sedia. Oleh itu, jika pernyataan pada pangkalan data utama dilaksanakan selama 10 minit, maka transaksi ini berkemungkinan menyebabkan kelewatan selama 10 minit pada pangkalan data hamba
Senario transaksi besar biasa: menggunakan pernyataan padam untuk memadam terlalu banyak data dan jadual besar sekaligus DDL
4. Strategi penukaran aktif/siap sedia
1 Strategi keutamaan kebolehpercayaan
Di bawah struktur M berganda, daripada Proses terperinci menukar dari keadaan 1 ke keadaan 2 adalah seperti berikut:
1 Tentukan detik semasa_behind_master pangkalan data siap sedia B. Jika kurang daripada nilai tertentu, teruskan ke. langkah seterusnya, jika tidak, teruskan mencuba semula langkah ini
2 Tukar pustaka utama A kepada keadaan baca sahaja, iaitu, tetapkan baca sahaja kepada benar
3 pustaka siap sedia B sehingga nilai menjadi 0
4 Tukar pustaka B kepada keadaan baca-tulis, iaitu, tetapkan baca sahaja kepada palsu
5
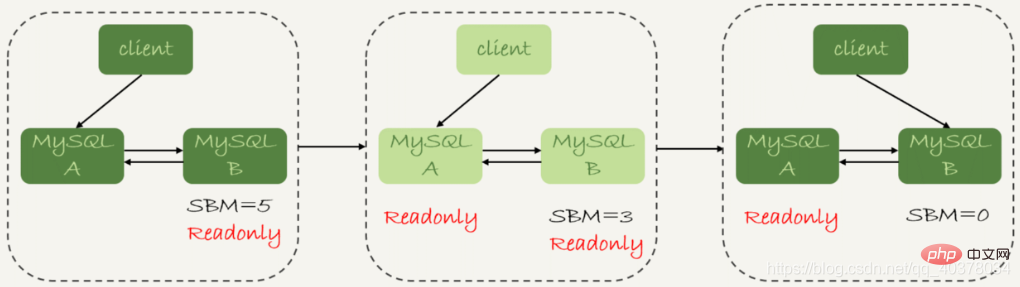
Terdapat beberapa langkah dalam proses penukaran ini Masa tidak tersedia. Selepas langkah 2, kedua-dua pangkalan data utama A dan pangkalan data siap sedia B berada dalam keadaan baca sahaja, yang bermaksud bahawa sistem berada dalam keadaan tidak boleh ditulis pada masa ini dan tidak boleh dipulihkan sehingga langkah 5 selesai. Dalam keadaan tidak tersedia ini, langkah yang lebih memakan masa ialah langkah 3, yang mungkin mengambil masa beberapa saat. Inilah sebabnya mengapa perlu membuat pertimbangan terlebih dahulu dalam langkah 1 untuk memastikan bahawa nilai seconds_behind_master cukup kecil
Masa ketidaktersediaan sistem ditentukan oleh strategi keutamaan kebolehpercayaan data ini
2. Strategi Keutamaan Ketersediaan
Strategi keutamaan ketersediaan: Jika langkah 4 dan 5 strategi keutamaan kebolehpercayaan dilaraskan secara paksa untuk dilaksanakan pada permulaan, iaitu sambungan akan terus bertukar ke pangkalan data siap sedia tanpa menunggu data utama dan siap sedia disegerakkan, dan membenarkan pangkalan data siap sedia B membaca dan menulis, maka sistem akan mempunyai hampir tiada masa yang tidak tersedia. Kos proses penukaran ini ialah ketidakkonsistenan data mungkin berlaku
mysql> CREATE TABLE `t` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `c` int(11) unsigned DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB;insert into t(c) values(1),(2),(3);
Jadual t mentakrifkan id kunci utama peningkatan automatik Selepas data dimulakan, terdapat 3 baris data dalam kedua-dua pangkalan data utama dan pangkalan data siap sedia. Teruskan melaksanakan dua arahan penyata sisipan pada jadual t, mengikut urutan:
insert into t(c) values(4);insert into t(c) values(5);
Andaikan terdapat sejumlah besar kemas kini pada jadual data lain pada pangkalan data utama, menyebabkan kelewatan siap sedia utama mencapai 5 detik. Selepas memasukkan pernyataan dengan c=4, penukaran aktif/siap sedia dimulakan
Rajah berikut menunjukkan proses penukaran dan hasil data apabila strategi keutamaan ketersediaan tersedia dan binlog_format=mixed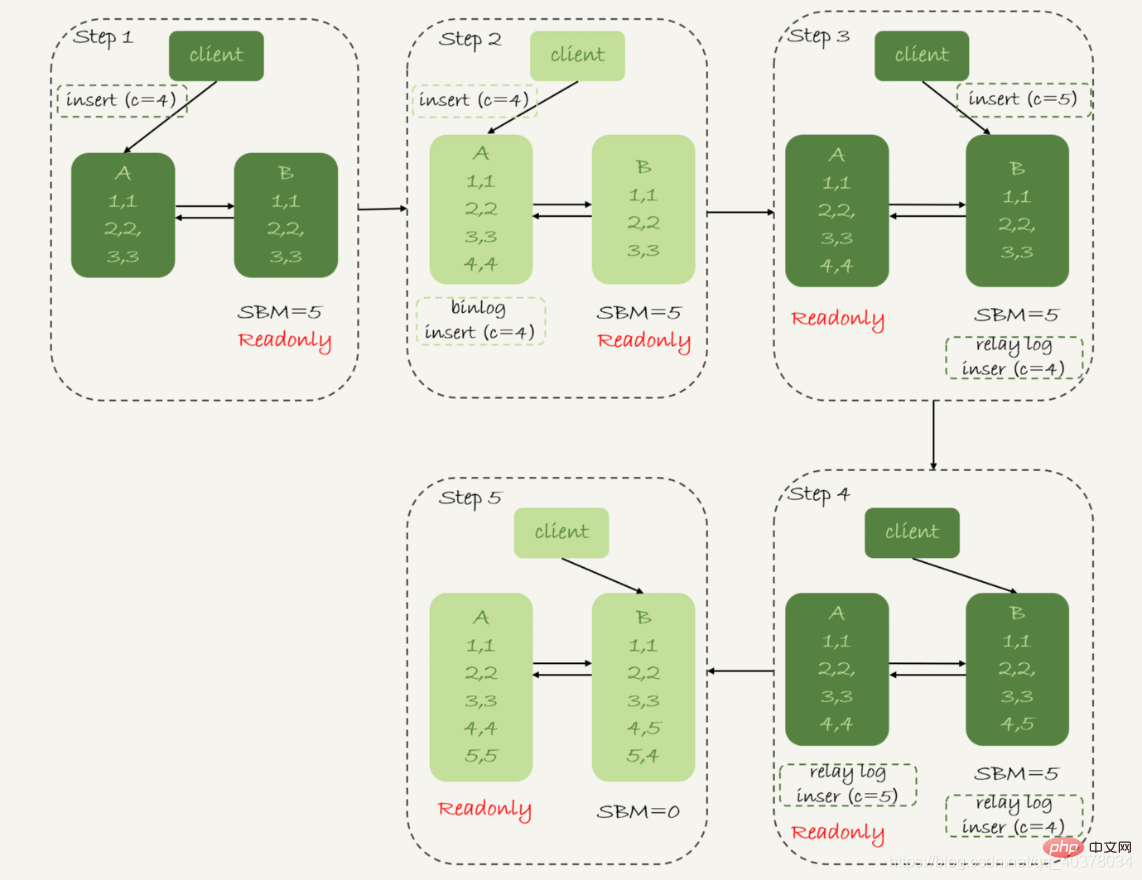
1. Dalam langkah 2, pangkalan data utama A selesai melaksanakan penyata sisipan dan memasukkan baris data (4,4), dan kemudian memulakan pertukaran siap sedia aktif
2 kepada kelewatan 5 saat antara aktif dan siap sedia , jadi sebelum pangkalan data siap sedia B mempunyai masa untuk menggunakan log pemindahan yang memasukkan c=4, ia mula menerima arahan pelanggan untuk memasukkan c=5
3. Dalam langkah 4, pangkalan data siap sedia B memasukkan baris data (4, 5), dan menghantar binlog ini ke pangkalan data utama A
4. Dalam langkah 5, pangkalan data siap sedia B memasukkan log pemindahan c=4 dan memasukkan baris data (5,4). Penyata sisipan c=5 yang dilaksanakan secara langsung dalam pangkalan data siap sedia B dihantar ke pangkalan data utama A, dan baris data baharu (5,5)
disisipkan Hasil akhir ialah pangkalan data utama A dan pangkalan data siap sedia B Dua baris data tidak konsisten muncul
Strategi keutamaan ketersediaan, tetapkan binlog_format=row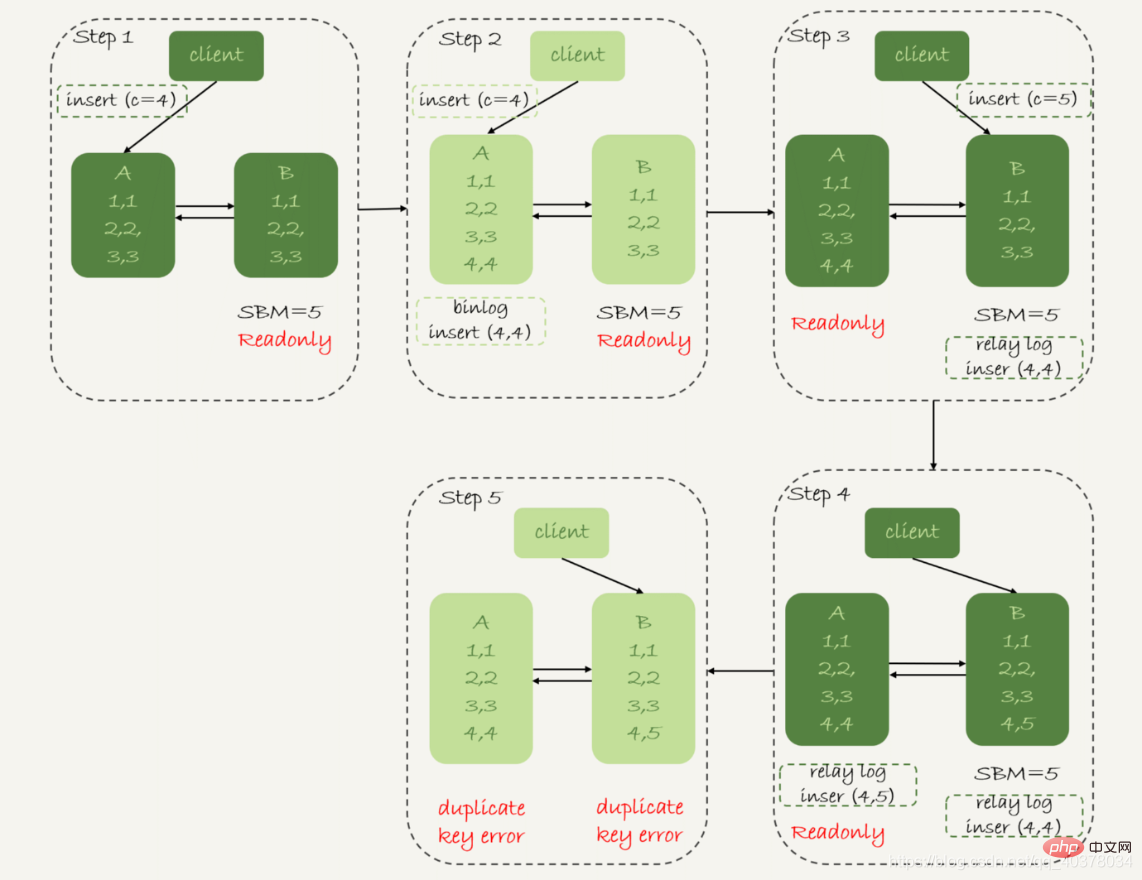
Oleh itu, apabila format baris merekodkan binlog, ia akan merekodkan semua nilai medan baris yang baru dimasukkan, jadi pada akhirnya hanya akan ada satu baris yang tidak konsisten. Selain itu, rangkaian aplikasi penyegerakan aktif dan siap sedia pada kedua-dua belah pihak akan melaporkan ralat kunci pendua dan berhenti. Dalam erti kata lain, dalam kes ini, dua baris data (5,4) dalam pangkalan data siap sedia B dan (5,5) dalam pangkalan data primer A tidak akan dilaksanakan oleh pihak lain
3 . Ringkasan
1 Apabila menggunakan binlog dalam format baris, masalah ketidakkonsistenan data lebih mudah dicari. Apabila menggunakan binlog format campuran atau pernyataan, mungkin mengambil masa yang lama untuk menemui masalah ketidakkonsistenan data
2. Strategi keutamaan ketersediaan pertukaran aktif/siap sedia akan membawa kepada ketidakkonsistenan data. Oleh itu, dalam kebanyakan kes, adalah disyorkan untuk menggunakan strategi keutamaan kebolehpercayaan
5. Strategi replikasi selari MySQL
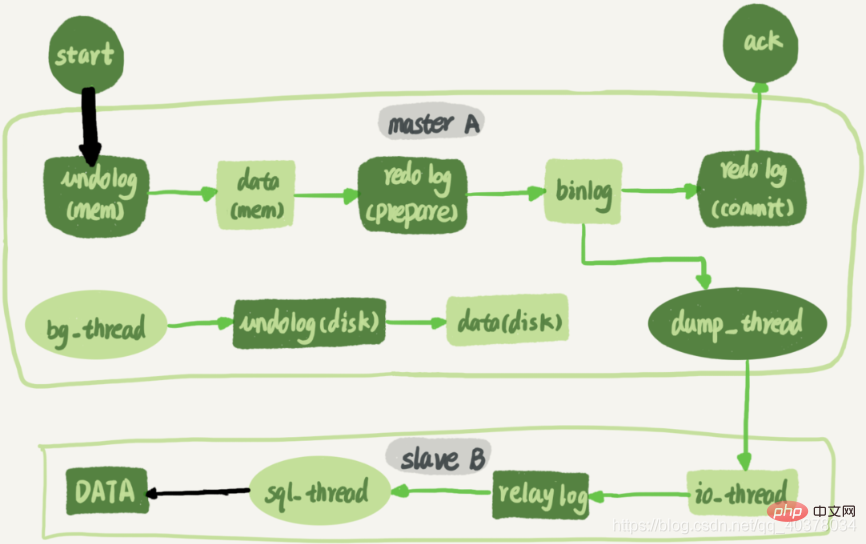
Utama dan sekunder Berkenaan dengan keupayaan replikasi selari, perkara yang perlu anda perhatikan ialah dua anak panah hitam dalam gambar di atas. Satu mewakili klien menulis ke pangkalan data utama, dan satu lagi mewakili log pemindahan pelaksanaan sql_thread pada pangkalan data siap sedia
Sebelum MySQL versi 5.6, MySQL hanya menyokong replikasi satu benang, jadi apabila konkurensi pangkalan data utama adalah tinggi dan TPS adalah tinggi, Masalah kelewatan sandaran induk yang serius akan berlaku
Mekanisme replikasi berbilang benang membahagikan sql_thread dengan hanya satu utas kepada berbilang utas, yang konsisten dengan model berikut:
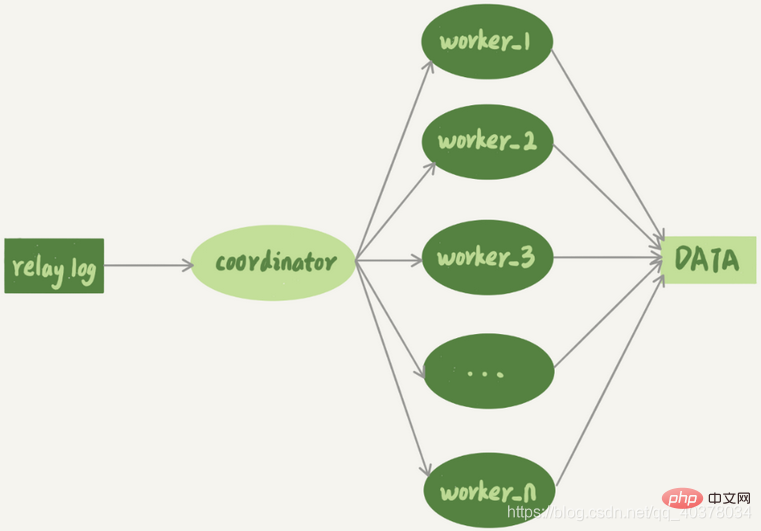
Penyelaras ialah sql_thread asal, tetapi kini ia tidak lagi mengemas kini data secara langsung, ia hanya bertanggungjawab untuk membaca log transit dan mengedarkan transaksi. Perkara yang sebenarnya mengemas kini log menjadi benang pekerja. Bilangan rangkaian pekerja ditentukan oleh parameter slave_parallel_workers
Semasa mengedar, penyelaras perlu memenuhi dua keperluan asas berikut:
- tidak boleh menyebabkan liputan kemas kini. Ini memerlukan dua transaksi yang mengemas kini baris yang sama mesti diedarkan kepada pekerja yang sama
- Transaksi yang sama tidak boleh dipisahkan dan mesti diletakkan dalam pekerja yang sama
1 . Strategi replikasi selari versi MySQL 5.6
Versi MySQL 5.6 menyokong replikasi selari, tetapi butiran yang disokong adalah selari dengan pangkalan data. Dalam jadual cincang yang digunakan untuk menentukan strategi pengedaran, kuncinya ialah nama pangkalan data
Kesan selari strategi ini bergantung pada model tekanan. Jika terdapat berbilang DB pada pangkalan data utama, dan tekanan setiap DB adalah seimbang, kesan penggunaan strategi ini akan menjadi sangat baik
Dua kelebihan strategi ini:
- Membina nilai cincang Ia sangat pantas Ia hanya memerlukan nama perpustakaan
- dan tidak memerlukan format binlog, kerana format penyata binlog juga boleh mendapatkan nama perpustakaan dengan mudah
untuk mencipta Jadual DB yang berbeza dengan populariti yang sama dibahagikan secara sama rata kepada DB yang berbeza ini, dan strategi ini terpaksa digunakan
Strategi replikasi selari MariaDB
buat semula pengoptimuman penyerahan kumpulan log, manakala MariaDB Strategi replikasi selari memanfaatkan ciri ini:
- Transaksi yang boleh diserahkan dalam kumpulan yang sama tidak akan mengubah suai baris yang sama
- Transaksi yang boleh dilaksanakan secara selari pada pangkalan data utama, Pangkalan data siap sedia juga mesti boleh dilaksanakan secara selari
Dari segi pelaksanaan, MariaDB melakukan ini:
1 diserahkan bersama dalam kumpulan mempunyai commit_id yang sama, kumpulan seterusnya ialah commit_id 1
2 Commit_id ditulis terus ke dalam binlog
3 Apabila dihantar ke aplikasi siap sedia, transaksi dengan yang sama commit_id diedarkan kepada berbilang pekerja untuk pelaksanaan
4 Selepas semua pelaksanaan kumpulan ini selesai, penyelaras akan mengambil satu kelompok
Dalam rajah di bawah, diandaikan bahawa pelaksanaan bagi. tiga kumpulan transaksi dalam perpustakaan utama, apabila trx1, trx2 dan trx3 diserahkan, trx4, trx5 dan trx6 sedang dilaksanakan. Dengan cara ini, apabila kumpulan pertama transaksi diserahkan, kumpulan transaksi seterusnya akan memasuki keadaan komit tidak lama lagi
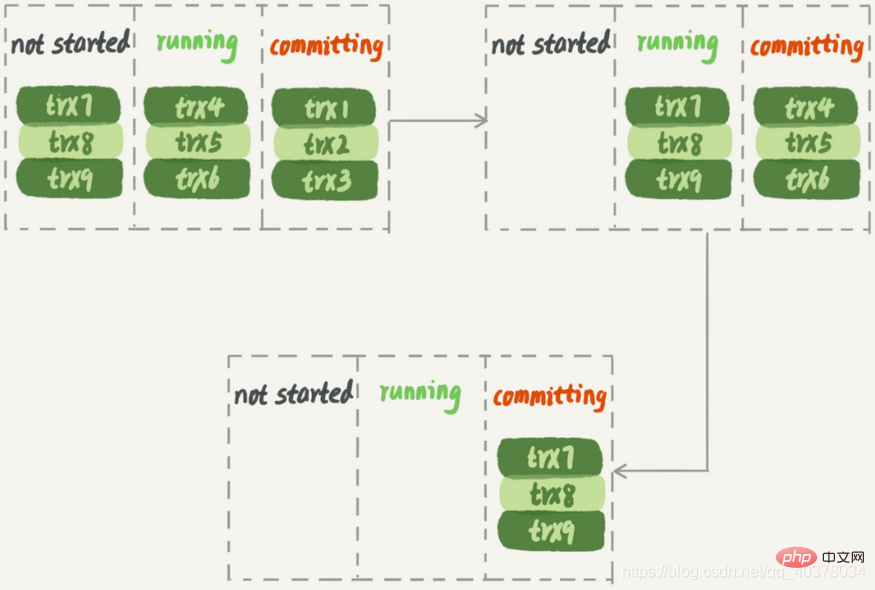
Menurut strategi replikasi selari MariaDB, kesan pelaksanaan pada pangkalan data siap sedia adalah seperti berikut :
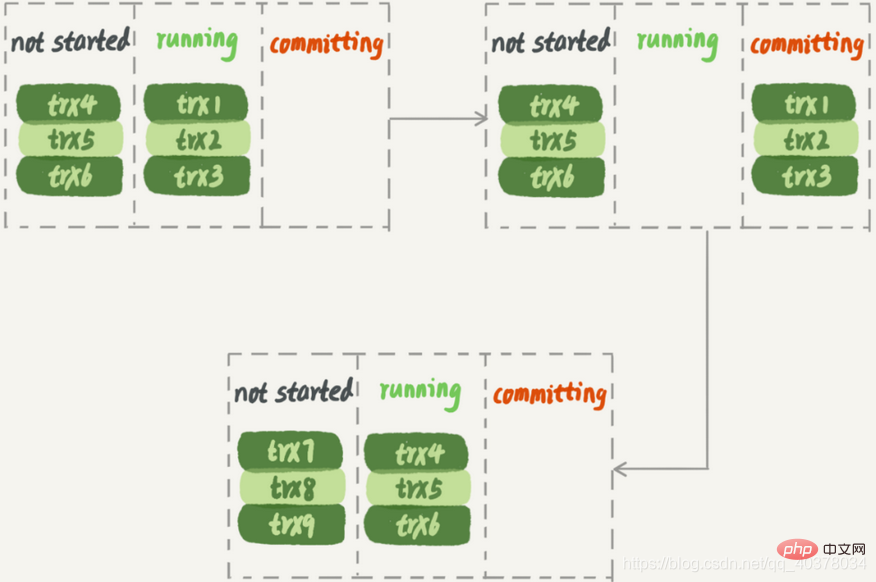
Apabila melaksanakan pada pangkalan data siap sedia, set transaksi kedua mesti menunggu sehingga set transaksi pertama dilaksanakan sepenuhnya sebelum set transaksi kedua boleh bermula melaksanakan. Dengan cara ini, daya pengeluaran sistem tidak akan mencukupi
Selain itu, rancangan ini mudah dihalang oleh acara besar. Dengan mengandaikan bahawa trx2 adalah transaksi yang sangat besar, apabila pangkalan data siap sedia digunakan, selepas pelaksanaan trx1 dan trx3 selesai, kumpulan seterusnya boleh memulakan pelaksanaan. Hanya satu utas pekerja berfungsi, yang merupakan pembaziran sumber
3 Strategi replikasi selari versi MySQL5.7
Versi MySQL5.7 ditentukan oleh. parameter slave-parallel-type untuk mengawal strategi replikasi selari:
- dikonfigurasikan sebagai DATABASE, yang bermaksud menggunakan versi MySQL5.6 bagi strategi selari setiap pangkalan data
- ialah dikonfigurasikan sebagai LOGICAL_CLOCK, yang bermaksud strategi yang serupa dengan MariaDB. MySQL telah membuat pengoptimuman berdasarkan ini
Bolehkah semua transaksi yang berada dalam keadaan pelaksanaan pada masa yang sama diselaraskan?
不可以,因为这里面可能有由于锁冲突而处于锁等待状态的事务。如果这些事务在备库上被分配到不同的worker,就会出现备库跟主库不一致的情况
而MariaDB这个策略的核心是所有处于commit状态的事务可以并行。事务处于commit状态表示已经通过了锁冲突的检验了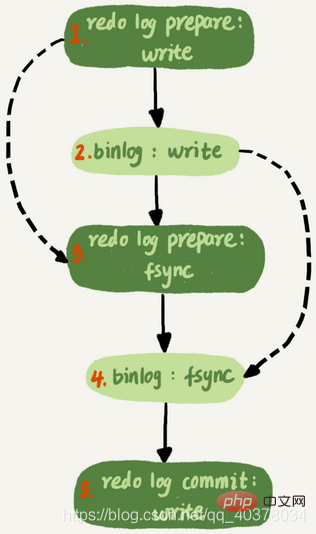
其实只要能够达到redo log prepare阶段就表示事务已经通过锁冲突的检验了
因此,MySQL5.7并行复制策略的思想是:
1.同时处于prepare状态的事务,在备库执行时是可以并行的
2.处于prepare状态的事务,与处于commit状态的事务之间,在备库执行时也是可以并行的
binlog组提交的时候有两个参数:
- binlog_group_commit_sync_delay参数表示延迟多少微妙后才调用fsync
- binlog_group_commit_sync_no_delay_count参数表示基类多少次以后才调用fsync
这两个参数是用于故意拉长binlog从write到fsync的时间,以此减少binlog的写盘次数。在MySQL5.7的并行复制策略里,它们可以用来制造更多的同时处于prepare阶段的事务。这样就增加了备库复制的并行度。也就是说,这两个参数既可以故意让主库提交得慢些,又可以让备库执行得快些
4、MySQL5.7.22的并行复制策略
MySQL5.7.22增加了一个新的并行复制策略,基于WRITESET的并行复制,新增了一个参数binlog-transaction-dependency-tracking用来控制是否启用这个新策略。这个参数的可选值有以下三种:
- COMMIT_ORDER,根据同时进入prepare和commit来判断是否可以并行的策略
- WRITESET,表示的是对于事务涉及更新的每一行,计算出这一行的hash值,组成集合writeset。如果两个事务没有操作相同的行,也就是说它们的writeset没有交集,就可以并行
- WRITESET_SESSION,是在WRITESET的基础上多了一个约束,即在主库上同一个线程先后执行的两个事务,在备库执行的时候,要保证相同的先后顺序
为了唯一标识,hash值是通过库名+表名+索引名+值计算出来的。如果一个表上除了有主键索引外,还有其他唯一索引,那么对于每个唯一索引,insert语句对应的writeset就要多增加一个hash值
1.writeset是在主库生成后直接写入到binlog里面的,这样在备库执行的时候不需要解析binlog内容
2.不需要把整个事务的binlog都扫一遍才能决定分发到哪个worker,更省内存
3.由于备库的分发策略不依赖于binlog内容,索引binlog是statement格式也是可以的
对于表上没主键和外键约束的场景,WRITESET策略也是没法并行的,会暂时退化为单线程模型
六、主库出问题了,从库怎么办?
下图是一个基本的一主多从结构
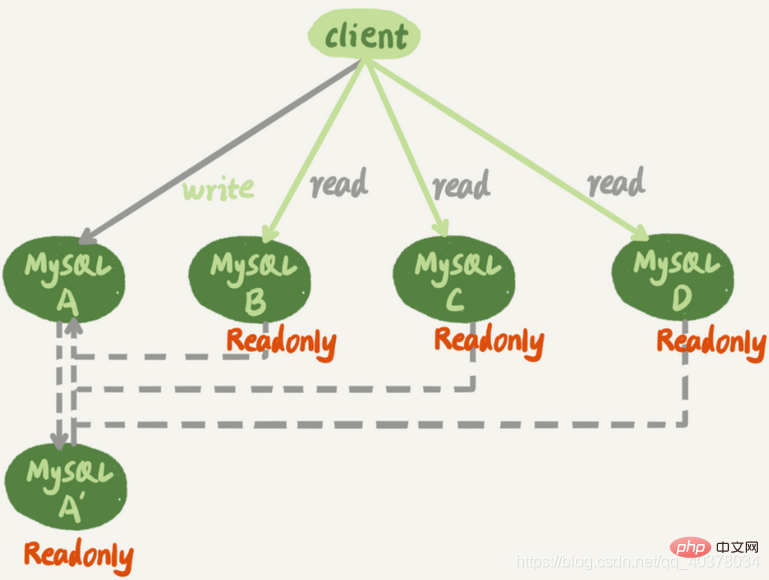
图中,虚线箭头表示的是主备关系,也就是A和A’互为主备,从库B、C、D指向的是主库A。一主多从的设置,一般用于读写分离,主库负责所有的写入和一部分读,其他的读请求则由从库分担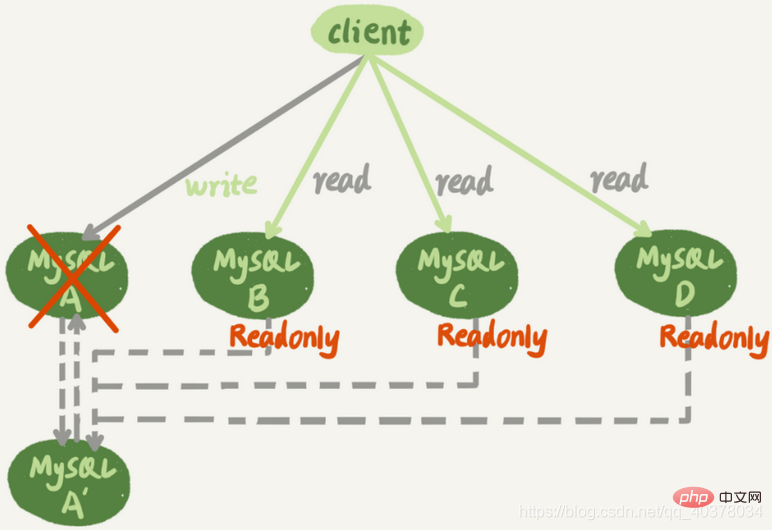
一主多从结构在切换完成后,A’会成为新的主库,从库B、C、D也要改接到A’
1、基于位点的主备切换
当我们把节点B设置成节点A’的从库的时候,需要执行一条change master命令:
CHANGE MASTER TO MASTER_HOST=$host_name MASTER_PORT=$port MASTER_USER=$user_name MASTER_PASSWORD=$password MASTER_LOG_FILE=$master_log_name MASTER_LOG_POS=$master_log_pos
- MASTER_HOST、MASTER_PORT、MASTER_USER和MASTER_PASSWORD四个参数,分别代表了主库A’的IP、端口、用户名和密码
- 最后两个参数MASTER_LOG_FILE和MASTER_LOG_POS表示,要从主库的master_log_name文件的master_log_pos这个位置的日志继续同步。而这个位置就是所说的同步位点,也就是主库对应的文件名和日志偏移量
找同步位点很难精确取到,只能取一个大概位置。一种去同步位点的方法是这样的:
1.等待新主库A’把中转日志全部同步完成
2.在A’上执行show master status命令,得到当前A’上最新的File和Position
3.取原主库A故障的时刻T
4.用mysqlbinlog工具解析A’的File,得到T时刻的位点,这个值就可以作为$master_log_pos
这个值并不精确,有这么一种情况,假设在T这个时刻,主库A已经执行完成了一个insert语句插入了一行数据R,并且已经将binlog传给了A’和B,然后在传完的瞬间主库A的主机就掉电了。那么,这时候系统的状态是这样的:
1.在从库B上,由于同步了binlog,R这一行已经存在
2.在新主库A’上,R这一行也已经存在,日志是写在master_log_pos这个位置之后的
3.在从库B上执行change master命令,指向A’的File文件的master_log_pos位置,就会把插入R这一行数据的binlog又同步到从库B去执行,造成主键冲突,然后停止tongue
通常情况下,切换任务的时候,要先主动跳过这些错误,有两种常用的方法
一种是,主动跳过一个事务
set global sql_slave_skip_counter=1;start slave;
另一种方式是,通过设置slave_skip_errors参数,直接设置跳过指定的错误。这个背景是,我们很清楚在主备切换过程中,直接跳过这些错误是无损的,所以才可以设置slave_skip_errors参数。等到主备间的同步关系建立完成,并稳定执行一段时间之后,还需要把这个参数设置为空,以免之后真的出现了主从数据不一致,也跳过了
2、GTID
MySQL5.6引入了GTID,是一个全局事务ID,是一个事务提交的时候生成的,是这个事务的唯一标识。它的格式是:
GTID=source_id:transaction_id
- source_id是一个实例第一次启动时自动生成的,是一个全局唯一的值
- transaction_id是一个整数,初始值是1,每次提交事务的时候分配给这个事务,并加1
GTID模式的启动只需要在启动一个MySQL实例的时候,加上参数gtid_mode=on和enforce_gtid_consistency=on就可以了
在GTID模式下,每个事务都会跟一个GTID一一对应。这个GTID有两种生成方式,而使用哪种方式取决于session变量gtid_next的值
1.如果gtid_next=automatic,代表使用默认值。这时,MySQL就把GTID分配给这个事务。记录binlog的时候,先记录一行SET@@SESSION.GTID_NEXT=‘GTID’。把这个GTID加入本实例的GTID集合
2.如果gtid_next是一个指定的GTID的值,比如通过set gtid_next=‘current_gtid’,那么就有两种可能:
- 如果current_gtid已经存在于实例的GTID集合中,接下里执行的这个事务会直接被系统忽略
- 如果current_gtid没有存在于实例的GTID集合中,就将这个current_gtid分配给接下来要执行的事务,也就是说系统不需要给这个事务生成新的GTID,因此transaction_id也不需要加1
一个current_gtid只能给一个事务使用。这个事务提交后,如果要执行下一个事务,就要执行set命令,把gtid_next设置成另外一个gtid或者automatic
这样每个MySQL实例都维护了一个GTID集合,用来对应这个实例执行过的所有事务
3、基于GTID的主备切换
在GTID模式下,备库B要设置为新主库A’的从库的语法如下:
CHANGE MASTER TO MASTER_HOST=$host_name MASTER_PORT=$port MASTER_USER=$user_name MASTER_PASSWORD=$password master_auto_position=1
其中master_auto_position=1就表示这个主备关系使用的是GTID协议
实例A’的GTID集合记为set_a,实例B的GTID集合记为set_b。我们在实例B上执行start slave命令,取binlog的逻辑是这样的:
1.实例B指定主库A’,基于主备协议建立连接
2.实例B把set_b发给主库A’
3.实例A’算出set_a与set_b的差集,也就是所有存在于set_a,但是不存在于set_b的GTID的集合,判断A’本地是否包含了这个差集需要的所有binlog事务
- 如果不包含,表示A’已经把实例B需要的binlog给删掉了,直接返回错误
- 如果确认全部包含,A’从自己的binlog文件里面,找出第一个不在set_b的事务,发给B
4.之后从这个事务开始,往后读文件,按顺序取binlog发给B去执行
4、GTID和在线DDL
如果是由于索引缺失引起的性能问题,可以在线加索引来解决。但是,考虑到要避免新增索引对主库性能造成的影响,可以先在备库加索引,然后再切换,在双M结构下,备库执行的DDL语句也会传给主库,为了避免传回后对主库造成影响,要通过set sql_log_bin=off关掉binlog,但是操作可能会导致数据和日志不一致
两个互为主备关系的库实例X和实例Y,且当前主库是X,并且都打开了GTID模式。这时的主备切换流程可以变成下面这样:
- 在实例X上执行stop slave
- 在实例Y上执行DDL语句。这里不需要关闭binlog
- 执行完成后,查出这个DDL语句对应的GTID,记为source_id_of_Y:transaction_id
- 到实例X上执行一下语句序列:
set GTID_NEXT="source_id_of_Y:transaction_id";begin;commit;set gtid_next=automatic;start slave;
这样做的目的在于,既可以让实例Y的更新有binlog记录,同时也可以确保不会在实例X上执行这条更新
七、MySQL读写分离
读写分离的基本结构如下图:
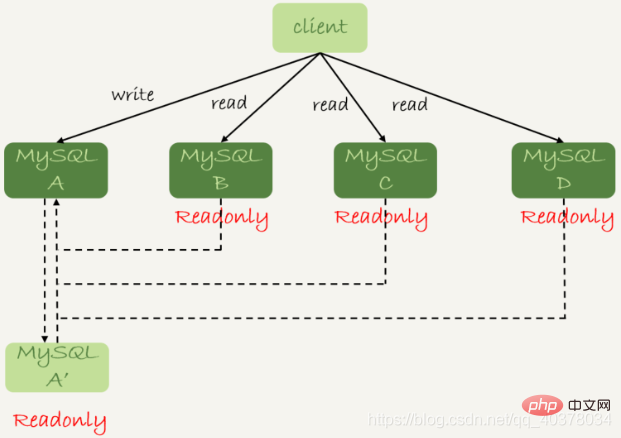
读写分离的主要目的就是分摊主库的压力。上图中的结构是客户端主动做负载均衡,这种模式下一般会把数据库的连接信息放在客户端的连接层。由客户端来选择后端数据库进行查询
还有一种架构就是在MySQL和客户端之间有一个中间代理层proxy,客户端只连接proxy,由proxy根据请求类型和上下文决定请求的分发路由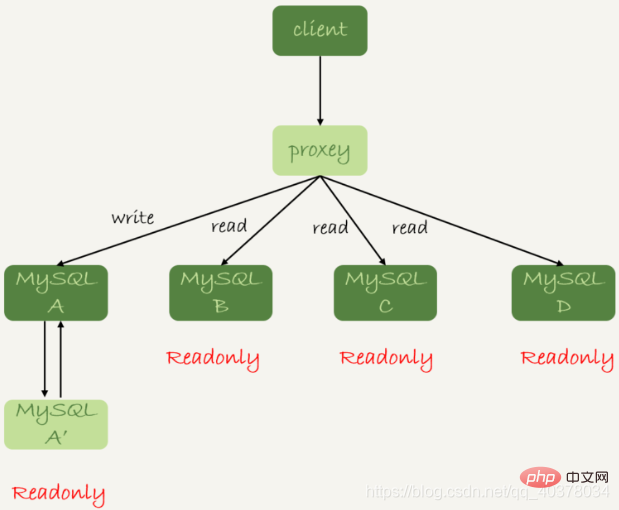
1.客户端直连方案,因此少了一层proxy转发,所以查询性能稍微好一点,并且整体架构简单,排查问题更方便。但是这种方案,由于要了解后端部署细节,所以在出现主备切换、库迁移等操作的时候,客户端都会感知到,并且需要调整数据库连接信息。一般采用这样的架构,一定会伴随一个负责管理后端的组件,比如Zookeeper,尽量让业务端只专注于业务逻辑开发
2.带proxy的架构,对客户端比较友好。客户端不需要关注后端细节,连接维护、后端信息维护等工作,都是由proxy完成的。但这样的话,对后端维护团队的要求会更高,而且proxy也需要有高可用架构
在从库上会读到系统的一个过期状态的现象称为过期读
1、强制走主库方案
强制走主库方案其实就是将查询请求做分类。通常情况下,可以分为这么两类:
1.对于必须要拿到最新结果的请求,强制将其发到主库上
2.对于可以读到旧数据的请求,才将其发到从库上
这个方案最大的问题在于,有时候可能会遇到所有查询都不能是过期读的需求,比如一些金融类的业务。这样的话,就需要放弃读写分离,所有读写压力都在主库,等同于放弃了扩展性
2、Sleep方案
主库更新后,读从库之前先sleep一下。具体的方案就是,类似于执行一条select sleep(1)命令。这个方案的假设是,大多数情况下主备延迟在1秒之内,做一个sleep可以很大概率拿到最新的数据
以买家发布商品为例,商品发布后,用Ajax直接把客户端输入的内容作为最新商品显示在页面上,而不是真正地去数据库做查询。这样,卖家就可以通过这个显示,来确认产品已经发布成功了。等到卖家再刷新页面,去查看商品的时候,其实已经过了一段时间,也就达到了sleep的目的,进而也就解决了过期读的问题
但这个方案并不精确:
1.如果这个查询请求本来0.5秒就可以在从库上拿到正确结果,也会等1秒
2.如果延迟超过1秒,还是会出现过期读
3、判断主备无延迟方案
show slave status结果里的seconds_behind_master参数的值,可以用来衡量主备延迟时间的长短
1.第一种确保主备无延迟的方法是,每次从库执行查询请求前,先判断seconds_behind_master是否已经等于0。如果还不等于0,那就必须等到这个参数变为0才能执行查询请求
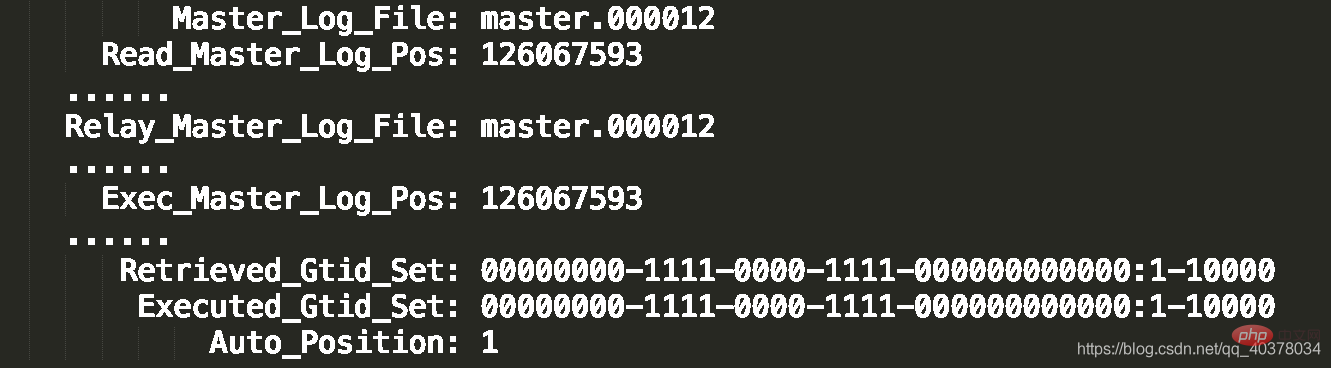
show slave status结果的部分截图如下:
2.第二种方法,对比位点确保主备无延迟:
- Master_Log_File和Read_Master_Log_Pos表示的是读到的主库的最新位点
- Relay_Master_Log_File和Exec_Master_Log_Pos表示的是备库执行的最新位点
如果Master_Log_File和Read_Master_Log_Pos和Relay_Master_Log_File和Exec_Master_Log_Pos这两组值完全相同,就表示接收到的日志已经同步完成
3.第三种方法,对比GTID集合确保主备无延迟:
- Auto_Position=1表示这堆主备关系使用了GTID协议
- Retrieved_Gitid_Set是备库收到的所有日志的GTID集合
- Executed_Gitid_Set是备库所有已经执行完成的GTID集合
如果这两个集合相同,也表示备库接收到的日志都已经同步完成
4.一个事务的binlog在主备库之间的状态:
1)主库执行完成,写入binlog,并反馈给客户端
2)binlog被从主库发送给备库,备库收到
3)在备库执行binlog完成
上面判断主备无延迟的逻辑是备库收到的日志都执行完成了。但是,从binlog在主备之间状态的分析中,有一部分日志,处于客户端已经收到提交确认,而备库还没收到日志的状态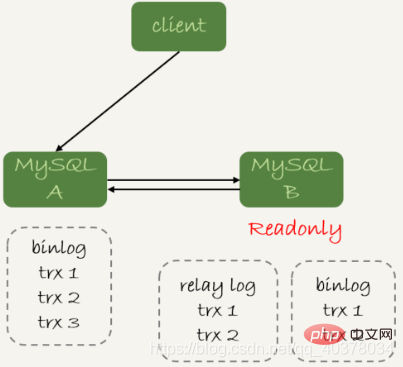
这时,主库上执行完成了三个事务trx1、trx2和trx3,其中:
- trx1和trx2已经传到从库,并且已经执行完成了
- trx3在主库执行完成,并且已经回复给客户端,但是还没有传到从库中
如果这时候在从库B上执行查询请求,按照上面的逻辑,从库认为已经没有同步延迟,但还是查不到trx3的
4、配合semi-sync
要解决上面的问题,就要引入半同步复制。semi-sync做了这样的设计:
1.事务提交的时候,主库把binlog发送给从库
2.从库收到binlog以后,发回给主库一个ack,表示收到了
3.主库收到这个ack以后,才能给客户端返回事务完成的确认
如果启用了semi-sync,就表示所有给客户端发送过确认的事务,都确保了备库已经收到了这个日志
semi-sync+位点判断的方案,只对一主一备的场景是成立的。在一主多从场景中,主库只要等到一个从库的ack,就开始给客户端返回确认。这时,在从库上执行查询请求,就有两种情况:
1.如果查询是落在这个响应了ack的从库上,是能够确保读到最新数据
2.但如果查询落到其他从库上,它们可能还没有收到最新的日志,就会产生过期读的问题
判断同步位点的方案还有另外一个潜在的问题,即:如果在业务更新的高峰期,主库的位点或者GTID集合更新很快,那么上面的两个位点等值判断就会一直不成立,很有可能出现从库上迟迟无法响应查询请求的情况
上图从状态1到状态4,一直处于延迟一个事务的状态。但是,其实客户端是在发完trx1更新后发起的select语句,我们只需要确保trx1已经执行完成就可以执行select语句了。也就是说,如果在状态3执行查询请求,得到的就是预期结果了
semi-sync配合主备无延迟的方案,存在两个问题:
1.一主多从的时候,在某些从库执行查询请求会存在过期读的现象
2.在持续延迟的情况下,可能出现过度等待的问题
5、等主库位点方案
select master_pos_wait(file, pos[, timeout]);
这条命令的逻辑如下:
1.它是在从库执行的
2.参数file和pos指的是主库上的文件名和位置
3.timeout可选,设置为正整数N表示这个函数最多等待N秒
这个命令正常返回的结果是一个正整数M,表示从命令开始执行,到应用完file和pos表示的binlog位置,执行了多少事务
1.如果执行期间,备库同步线程发生异常,则返回NULL
2.如果等待超过N秒,就返回-1
3.如果刚开始执行的时候,就发现已经执行过这个位置了,则返回0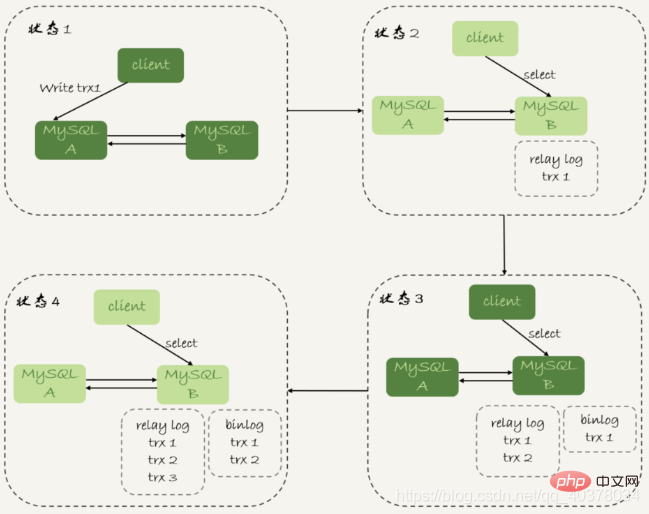
对于上图中先执行trx1,再执行一个查询请求的逻辑,要保证能够查到正确的数据,可以使用这个逻辑:
1.trx1事务更新完成后,马上执行show master status得到当前主库执行到的File和Position
2.选定一个从库执行查询语句
3.在从库上执行select master_pos_wait(file, pos, 1)
4.如果返回值是>=0的正整数,则在这个从库执行查询语句
5.否则,到主库执行查询语句
流程如下:
6、GTID方案
select wait_for_executed_gtid_set(gtid_set, 1);
这条命令的逻辑如下:
1.等待,直到这个库执行的事务中包含传入的gtid_set,返回0
2.超时返回1
等主库位点方案中,执行完事务后,还要主动去主库执行show master status。而MySQL5.7.6版本开始,允许在执行完更新类事务后,把这个事务的GTID返回给客户端,这样等GTID的方案可以减少一次查询
等GTID的流程如下:
1.trx1事务更新完成后,从返回包直接获取这个事务的GTID,记为gtid1
2.选定一个从库执行查询语句
3. Jalankan pilih wait_for_executed_gtid_set(gtid1, 1);
4 Jika nilai pulangan ialah 0, laksanakan pernyataan pertanyaan pada pustaka hamba ini
5 pangkalan data utama untuk melaksanakan pernyataan pertanyaan 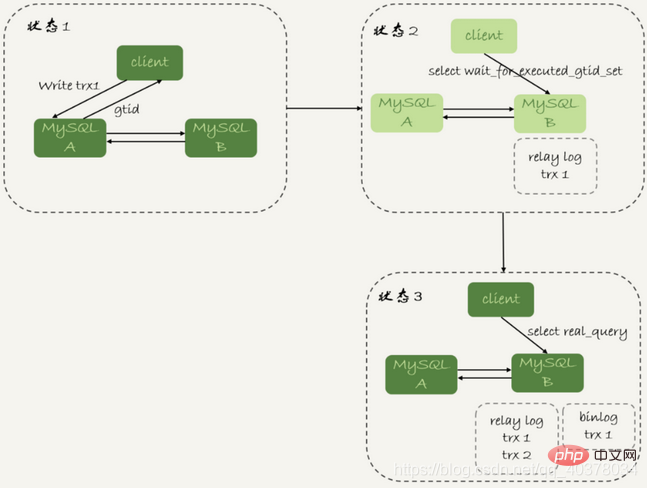
Untuk lebih banyak pengetahuan berkaitan pengaturcaraan, sila lawati: Pengenalan kepada Pengaturcaraan! !
Atas ialah kandungan terperinci Ketahui lebih lanjut tentang pengasingan master-standby, master-slave dan read-write dalam MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Ketahui lebih lanjut tentang auto-increment kunci utama dalam MySQL
- Pemahaman mendalam tentang algoritma pernyataan gabungan dan kaedah pengoptimuman dalam MySQL
- Mari berbincang dengan anda tentang pengasingan transaksi dalam MySQL
- Pemahaman mendalam tentang kunci dalam MySQL (kunci global, kunci peringkat jadual, kunci baris)