
Rumah >masalah biasa >数据归一化处理的目的是什么
数据归一化处理的目的是什么

- 青灯夜游asal
- 2021-05-07 16:33:1827845semak imbas
数据归一化处理的目的是:使得预处理的数据被限定在一定的范围内,从而消除奇异样本数据导致的不良影响。数据归一化处理后,可以加快梯度下降求最优解的速度,且有可能提高精度(如KNN)。

本教程操作环境:windows7系统、Dell G3电脑。
在机器学习领域中,不同评价指标(即特征向量中的不同特征就是所述的不同评价指标)往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。其中,最典型的就是数据的归一化处理。(可以参考学习:数据标准化/归一化)
简而言之,归一化的目的就是使得预处理的数据被限定在一定的范围内(比如[0,1]或者[-1,1]),从而消除奇异样本数据导致的不良影响。
1)在统计学中,归一化的具体作用是归纳统一样本的统计分布性。归一化在0~1之间是统计的概率分布,归一化在-1~+1之间是统计的坐标分布。
2)奇异样本数据是指相对于其他输入样本特别大或特别小的样本矢量(即特征向量),譬如,下面为具有两个特征的样本数据x1、x2、x3、x4、x5、x6(特征向量—>列向量),其中x6这个样本的两个特征相对其他样本而言相差比较大,因此,x6认为是奇异样本数据。
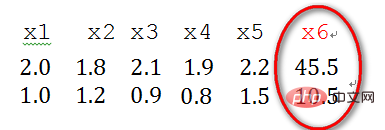
奇异样本数据的存在会引起训练时间增大,同时也可能导致无法收敛,因此,当存在奇异样本数据时,在进行训练之前需要对预处理数据进行归一化;反之,不存在奇异样本数据时,则可以不进行归一化。
--如果不进行归一化,那么由于特征向量中不同特征的取值相差较大,会导致目标函数变“扁”。这样在进行梯度下降的时候,梯度的方向就会偏离最小值的方向,走很多弯路,即训练时间过长。
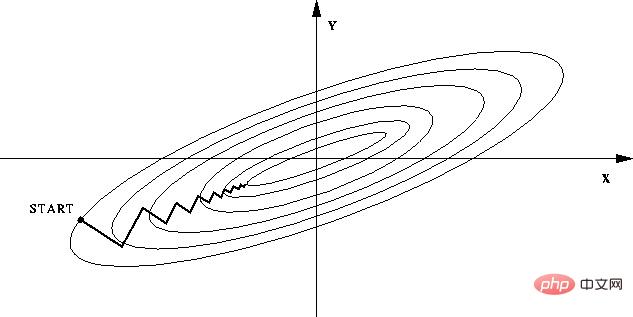
--如果进行归一化以后,目标函数会呈现比较“圆”,这样训练速度大大加快,少走很多弯路。
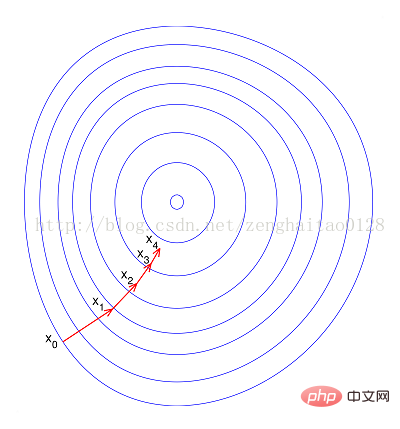
综上可知,归一化有如下好处,即
1)归一化后加快了梯度下降求最优解的速度;
2)归一化有可能提高精度(如KNN)
注:没有一种数据标准化的方法,放在每一个问题,放在每一个模型,都能提高算法精度和加速算法的收敛速度。
更多相关知识,请访问常见问题栏目!
Atas ialah kandungan terperinci 数据归一化处理的目的是什么. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!