
Rumah >pangkalan data >tutorial mysql >记录MySQL日志模块
记录MySQL日志模块

- coldplay.xixike hadapan
- 2021-02-12 09:58:293506semak imbas
免费学习推荐:mysql视频教程
目录
一、简介
二、redo log
三. binlog
四. 内部工作流程
MySql学习专栏
1. MySQL基础架构详解
2. MySQL索引底层数据结构与算法
3. MySQL5.7开启binlog日志,及数据恢复简单示例
4. MySQL日志模块
一、简介
MySQL 有两大重要的日志模块:redo log(重做日志)和 binlog(归档日志)。
redo log是InnoDB存储引擎层的日志,binlog是MySQL Server层记录的日志, 两者都是记录了某些操作的日志,但两者记录的格式不同。
二、redo log
redo log: 又称(重做日志)文件,用于记录事务操作的变化,记录的是数据修改之后的值,不管事务是否提交都会记录下来。
在media failure时,redo log文件就能派上用场,如数据库掉电,InnoDB存储引擎会使用redo log恢复到掉电前的时刻,以此来保证数据的完整性。
当有一条记录需要更新的时候,InnoDB 引擎就会先把记录写到 redo log 里面,并更新内存,这个时候更新就算完成了。
InnoDB 引擎会在适当的时候,将这个操作记录更新到磁盘里面,而这个更新一般是在系统比较空闲的时候完成的,以此来提升更新效率。
这里涉及到 WAL 即 Write-Ahead Logging 技术,他的关键点就是 先写日志,再写磁盘。
InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么总共就可以记录 4GB 的操作。
redo log会从头开始写,写到末尾就又回到开头循环写,如下图所示。
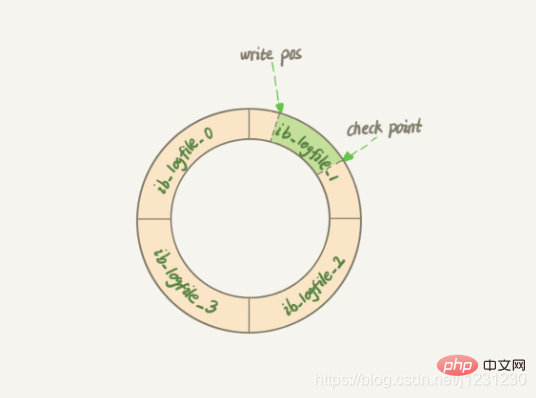
write pos 是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头。
check point 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件。
write pos 和 check point 之间的是未使用的部分,可以用来记录新的操作。
如果 write pos 追上 check point,表示redo log记录满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 check point 推进一下。
有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为 crash-safe。
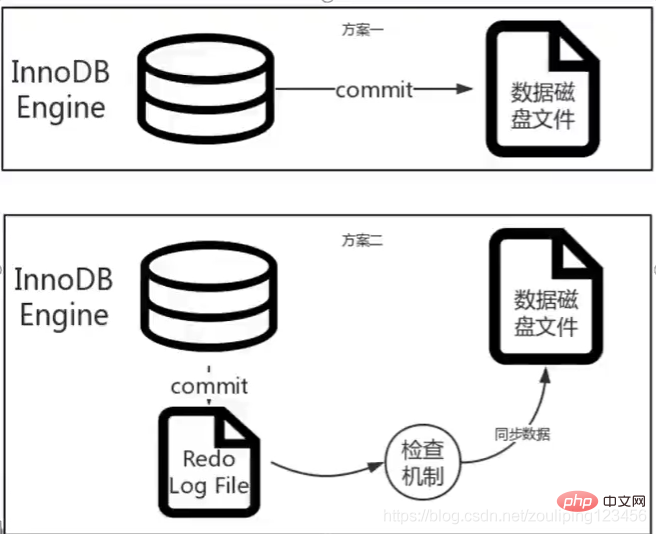
为什么要使用redo log日志?
假如我们对数据库进行DML操作,直接把执行SQL写入磁盘,当写入并发较大时,对数据写入磁盘的压力会造成一定影响,
当我们插入操作是,发现当前非叶子节点一页数据量不够时,要进行分页算法,效率会比较低;
当我使用redo log日志,先把我们DML操作写入日志,通过一个"中转站",空闲时候再通过check point 写入磁盘,效率会高很多;
MySQL设置Redo Log
- 写入日innodb_log_buffer_size的大小:(默认8M)
- innodb_log_file_size 重做日志文件的大小。
- innodb_log_files_in_group 指定重做日志文件组中文件的数量,默认2
- innodb_mirrored_log_groups 指定了日志镜像文件组的数量,默认1
- innodb_log_group_home_dir 指定日志文件组所在的路径,默认./,表示在数据库的数据目录下
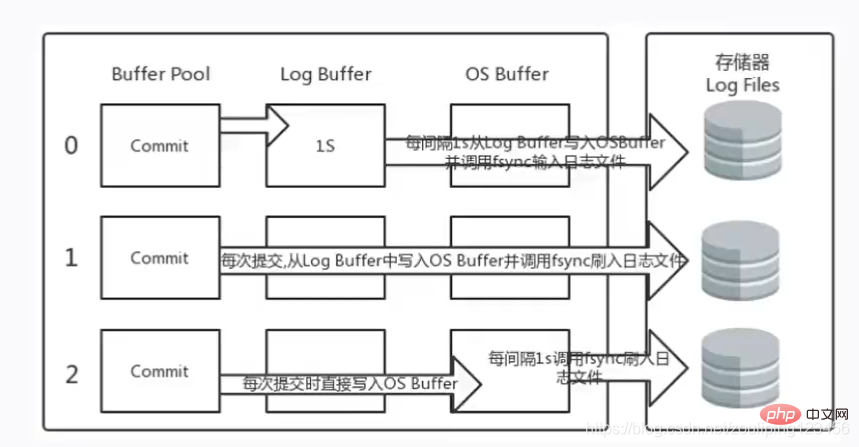
- innodb_flush_log_at_trx_commit 设置commit时如何将log buffer中日志刷log file中 (值0、1、2)默认1
三. binlog
redo log 是 InnoDB 引擎特有的日志,而 Server 层也有自己的日志,称为 binlog(归档日志)。
为什么会有两份日志呢?
因为最开始 MySQL 里并没有 InnoDB 引擎。MySQL 自带的引擎是 MyISAM,但是 MyISAM 没有 crash-safe 的能力,binlog 日志只能用于归档。
而 InnoDB 是另一个公司以插件形式引入 MySQL 的,既然只依靠 binlog 是没有 crash-safe 能力的,所以 InnoDB 使用另外一套日志系统——也就是 redo log 来实现 crash-safe 能力。
这两种日志有以下三点不同。
- redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
- redo log 是物理日志,记录的是 "在某个数据页上做了什么修改" ;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如 "给 ID=2 这一行的 c 字段加 1" 。
- redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。 "追加写" 是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
四. 内部工作流程
以一个表的更新语句为例,来看一下执行器和 InnoDB 引擎的内部工作流程:
mysql> update T set c=c+1 where ID=2;
如下图所示,浅色框表示是在 InnoDB 内部执行的,深色框表示是在执行器中执行的:
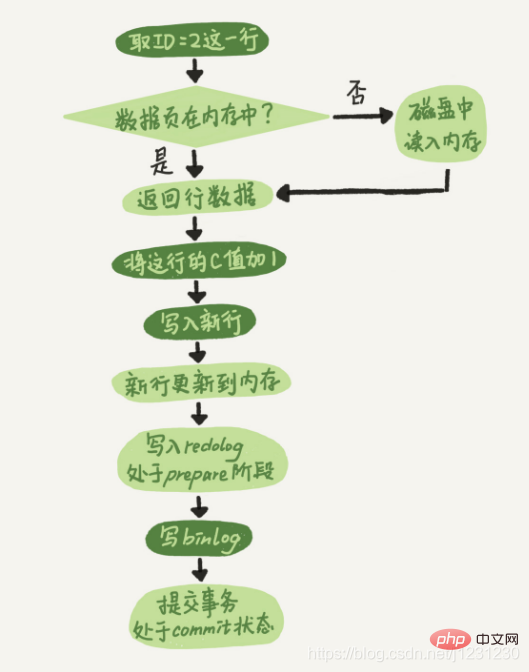
- 执行器先找引擎取 ID=2 这一行。ID 是主键,引擎直接用树搜索找到这一行。如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,把这个值加上 1,比如原来是 N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
最后三步看上去有点“绕”,将 redo log 的写入拆成了两个步骤:prepare 和 commit,其实这就是 "两阶段提交"。
为什么日志需要 "两阶段提交"?这里可以用反证法来进行解释。
由于 redo log 和 binlog 是两个独立的逻辑,如果不用两阶段提交,要么就是先写完 redo log 再写 binlog,或者采用反过来的顺序。用前面的 update 语句来做例子,我们看看这两种方式会有什么问题。
假设当前 ID=2 的行,字段 c 的值是 0,再假设执行 update 语句过程中在写完第一个日志后,第二个日志还没有写完期间发生了 crash,会出现什么情况呢?
1. 先写 redo log 后写 binlog。假设在 redo log 写完,binlog 还没有写完的时候,MySQL 进程异常重启。redo log 写完之后,系统即使崩溃,仍然能够把数据恢复回来,所以恢复后这一行 c 的值是 1。
但是由于 binlog 没写完就 crash 了,这时候 binlog 里面就没有记录这个语句。因此,之后备份日志的时候,存起来的 binlog 里面就没有这条语句。
然后你会发现,如果需要用这个 binlog 来恢复临时库的话,由于这个语句的 binlog 丢失,这个临时库就会少了这一次更新,恢复出来的这一行 c 的值就是 0,与原库的值不同。
2. 先写 binlog 后写 redo log。如果在 binlog 写完之后 crash,由于 redo log 还没写,崩溃恢复以后这个事务无效,所以这一行 c 的值是 0。
但是 binlog 里面已经记录了“把 c 从 0 改成 1”这个日志。所以,在之后用 binlog 来恢复的时候就多了一个事务出来,恢复出来的这一行 c 的值就是 1,与原库的值不同。
可以看到,如果不使用“两阶段提交”,那么数据库的状态就有可能和用它的日志恢复出来的库的状态不一致。
相关免费学习推荐:mysql数据库(视频)
Atas ialah kandungan terperinci 记录MySQL日志模块. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!