
Rumah >pembangunan bahagian belakang >Tutorial Python >Python数据分析实战之 概述数据分析
Python数据分析实战之 概述数据分析

- coldplay.xixike hadapan
- 2021-01-06 09:48:392283semak imbas
Python教程栏目介绍概述数据。

推荐(免费):Python教程
文章目录
- 一、入门数据分析
- 1.大数据时代的基本面
- 2.数据分析师职业前景
- 3.成为数据分析师之路
- 二、Python的安装与环境配置
- 1.Python版本
- 2.不同系统安装Python
- 3.环境变量配置
- 4.安装pip
- 5.集成开发环境选择
- 三、Anaconda的介绍与安装
- 1.Anaconda是什么
- 2.下载和安装Anaconda
- 3.conda工具的介绍和包管理
- 四、Jupyter Notebook
- 1.Jupyter Notebook基本介绍
- 2.Jupyter Notebook的使用
- 3.Jupyter中使用Python
- 4.数据交互案例
- 加载csv数据,处理数据,保存到MongoDB数据库
- 使用Jupyter处理商铺数据
一、入门数据分析
1.大数据时代的基本面
大数据产业发展现状:
现在数据已经呈现出了爆炸式的增长,每一分钟可能就会有:
- 13000+个iPhone应用下载
- Twitter上发布98000+新微博
- 发出1.68亿+条Email
- 淘宝双十一10680+个新订单
- 12306出票1840+张
在大数据时代,出现了三大变革:
- 从随机样本到全量数据
- 从精确性到混杂性
- 从因果关系到相关关系
举一个典型的例子:
男士到超市买尿布会顺带买一些啤酒,通过大数据分析出的结果促使超市在尿布的货架附近放一些啤酒,从而增大销量,买尿布与买啤酒之间没有因果关系,但是存在着某种相关关系。
国内大数据应用状况如下(来自CSDN):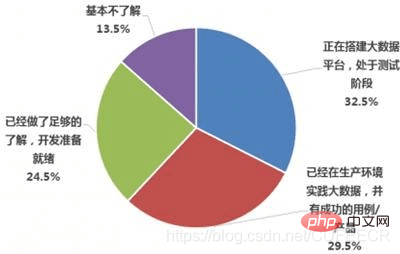
可以看到,大数据的应用已经具有一定规模,但是还有很大的发展空间。
人才方面的需求主要包括:
- 数据分析师
- 统计分析
- 预测分析
- 流程优化
- 大数据工程师
- 平台开发
- 应用开发
- 技术支撑
- 数据架构师
- 业务理解
- 应用部署
- 架构设计
之所以要学习数据分析,是因为数据正变得越来越常见和廉价,分析可以为数据提供稀缺且附带额外价值的服务。
2.数据分析师职业前景
数据分析师需要解决的问题:
预估需求、分配产能
在大数据时代,更需要解读数据的能力。
Q:烤箱的产能有限,该选择生产哪些种类的面包?
A:列出最受欢迎的几种面包,优先生产明星商品。
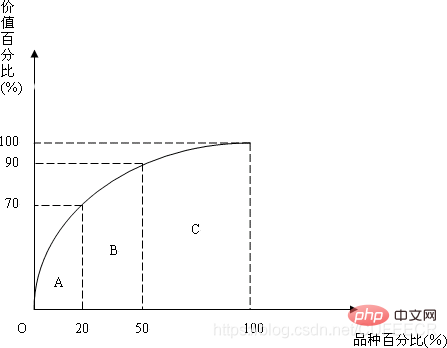
关键是找出明星商品,这需要统计出面包的总营业额,再算出每种面包占总营业额的相对比例,优先生产能囊括七成营业额的产品组合。这会用到统计的次数分配表和直方图,此种分析法也称为ABC分析法,如下:
评估行销方案成效
统计并不是分析数据就好了,从分析的结果推测该如何影响顾客的行为,并且将之拟定为具体的商业计划,并据此行动才是关键。
Q:想在网上销售面包,哪一种广告比较有效?
A:写出两种文案,分别广告一段时间看看成效如何。
要比较广告成效,最好的方法是用统计的随机对照实验,让两种广告随机出现,一段时间后,观察哪种广告的效果比较好,再大范围运用效果比较好的广告。产品品管
发现结果以及形成结果的原因之间的关系非常重要。
Q:怎么从面包判断面包师傅有没有偷工减料?
A:抽查几个面包,秤秤看重量差距有没有过大。
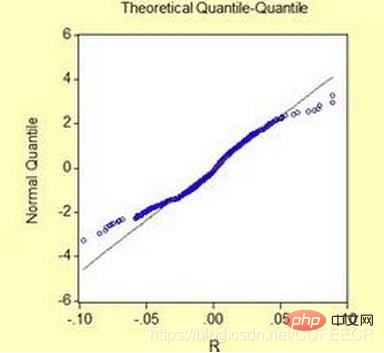
你需要先知道面包的平均重量,再对面包进行抽样,看看面包的重量是否呈现常态分布的钟形曲线?若是偏离曲线,就可能暗示面包品管有问题。如下:
一名好的数据分析师是一个好的产品规划者和行业的领跑者;
在IT企业,优秀的数据分析师很有希望成为公司的高层。
数据分析师的工作流程如下: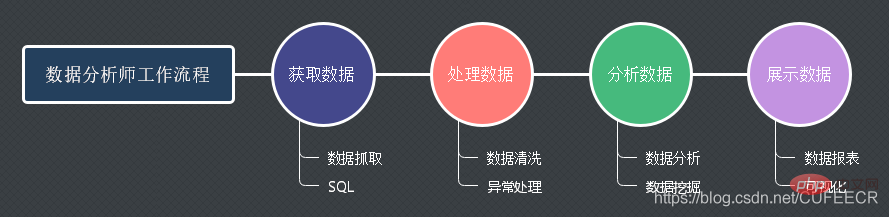
数据分析师的三大任务:
- 分析历史
- 预测未来
- 优化选择
数据分析师要求的8项技能:
- 统计学
- 统计检验、P值、分布、估计
- 基本工具
- Python
- SQL
- 多变量微积分和线性代数
- 数据整理
- 数据可视化
- 软件工程
- 机器学习
- 数据科学家的思维
- 数据驱动
- 问题解决
数据分析师要求的三大能力:
- 统计学基础和分析工具应用
- 计算机编码能力
- 特定应用领域或行业的知识
典型的数据分析师的成长历程: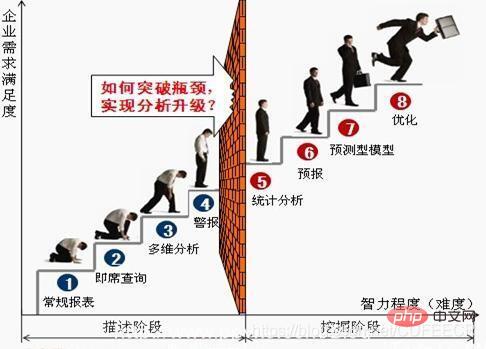
3.成为数据分析师之路
成为数据分析师的自我修养:
- 敏感
- 探究
- 细致
- 务实
数据分析师需要具备的技能如下:
- 熟悉Excel数据处理
- 数据敏感度较强
- 熟悉公司业务和行业知识
- 掌握数据分析方法
-
基本分析方法
- 对比分析法
- 分组分析法
- 交叉分析法
- 结构分析法
- 漏斗图分析法
- 综合评价分析法
- 因素分析法
- 矩阵关联分析
-
高级分析方法
- 相关分析法
- 回归分析法
- 聚类分析法
- 判别分析法
- 主成分分析法
- 因子分析法
- 对应分析法
- 时间序列
-
基本分析方法
在不同行业数据分析从业人员的工作内容和职责:
- 从事数据分析的工作
- 学做日报
- 日销、库存类的表
- 产品销售预测
- 库存计算和预警
- 流量分析相关表
- 复盘
- 数据分析挖掘工作人员
- 给产品优化提供数据支持
- 验证产品改进效果
- 为高层提供邮件和报表
- 互联网+分析
- KPI指标监控
- 各种周期性报表
- 针对某一业务问题做分析报告
- 针对业务进行线下建模和分析
数据分析很重要的学科基础是数学,但是数学不好也没有关系,可以用Python来帮助学习:
Python不仅是一门编程语言,而且是数据挖掘机器学习等技术的基础,方便建立自动化的工作流;
Python入门不难,它对数学要求并不是太高,重要的是需要知道如何用语言表达一个算法逻辑;
Python有很多封装好的工具库和命令,需要做的是用哪些数学方法解决一个问题,并构建出来。
要想快速入门Python数据分析,就要使用好Python相关的工具包:
(1)Python最大的特点是拥有一个巨大而活跃的科学计算社区,采用python进行科学计算的趋势也越来越明显。
(2)由于Python有不断改良的库,使其成为数据处理任务的一大代替方案,结合其在通用编程方面的强大实力,完全可以只是用Python这一种语言去构建以数据为中心的应用程序,其中:
- 常用数据分析库
- Numpy
- Scipy
- Pandas
- matplotlib
- 常用高级数据分析库
- nltk
- igraph
- scikit-learn
(3)作为一个科学计算平台,Python的能够轻松集成C、C++以及Fortran代码。
数据分析的准备工作:
- 了解数据
- 数据清洗与初步分析
- 绘图与可视化
- 数据聚合与分组处理
- 数据挖掘
数据分析与数据挖掘的常用算法:
- 线性回归
- 时间序列分析
- 分类算法
- 聚类算法
- 降维算法
学习和从事数据分析工作的方法为:
- 勤思考
- 多动手
- 多总结
二、Python的安装与环境配置
1.Python版本
Python分为3.X和2.X两个大版本。
Python的3.0版本,常被称为Python 3000,或简称Py3k。相对于Python的早期版本,这是一个较大的升级。
为了不带入过多的累赘,Python 3.X在设计的时候没有考虑向下相容,许多针对早期Python版本设计的程式都无法在Python 3.X上正常执行。
大多数第三方库都正在努力地相容Python 3.X版本。
2.不同系统安装Python
(1)Unix & Linux系统
- 访问http://www.python.org/download/
- 选择适用于Unix/Linux的源码压缩包
- 下载及解压压缩包
- 如果你需要自定义一些选项,修改Modules/Setup
- 执行
./configure脚本 makemake install
(2)Window系统
- 访问http://www.python.org/download/
- 在下载列表中选择Window平台安装包
由于官网下载很缓慢,因此我已经将Python各版本的安装包下载整理好了,可以直接点击加QQ群963624318 在群文件夹Python相关安装包中下载即可。 - 下载后,双击下载包,进入Python安装向导,安装非常简单,只需要使用默认的设置一直点击下一步直到安装完成即可。
(3)Mac系统
自带python 2.7,可以执行brew install python安装新版本。
3.环境变量配置
Windows系统需要配置环境变量。
如果在安装Python时没有选择添加环境变量,则需要手动添加,需要将安装Python的路径XXX\PythonXXX和XXX\PythonXXX\Scripts添加到环境变量,有两种方式:
- 命令行添加
CMD中分别执行path=%path%;XXX\PythonXXX和path=%path%;XXX\PythonXXX\Scripts即可。 - 在系统设置中添加
右键计算机 → 属性 → 高级系统设置 → 系统属性 → 环境变量 → 双击path → 添加XXX\PythonXXX和XXX\PythonXXX\Scripts安装路径,如下:

最后依次点击确认退出即可。
4.安装pip
pip是Python中的包安装和管理工具,在安装Python时可以选择安装pip,在Python 2 >=2.7.9或Python 3 >=3.4中自带。
如果没有安装pip,可以通过命令安装:
- Linux或者Mac
pip install -U pip - Windows(cmd输入)
python -m pip install -U pip
5.集成开发环境选择
Python有很多编辑器,包括PyCharm等,这里选择PyCharm:
PyCharm是由JetBrains打造的一款Python IDE,支Mac OS、Windows、Linux系统。
包含调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制等功能。
可以在https://www.jetbrains.com/pycharm/download/选择合适的版本进行下载安装即可。
三、Anaconda的介绍与安装
1.Anaconda是什么
Anaconda是一个可用于科学计算的Python发行版,支持Linux、Mac、Windows系统,内置了常用的科学计算库。
它解决了官方Python的两大痛点:
(1)提供了包管理功能,Windows平台安装第三方包经常失败的场景得以解决;
(2)提供环境管理的功能,功能类似virtualenv,解决了多版本Python并存、切换的问题 。
2.下载和安装Anaconda
直接在官网https://www.anaconda.com/products/inpidual下载安装包,选择下载Python3.8的安装包个人版即可,但是官网下载速度较慢,因此我已经将Python3.8对应的Anaconda安装包下载整理好了,可以直接点击加QQ群
 963624318 在群文件夹Python相关安装包中下载即可。
963624318 在群文件夹Python相关安装包中下载即可。
下载完成后直接安装,需要注意,在点击过程中会出现添加环境变量的提示,需要勾选,如下: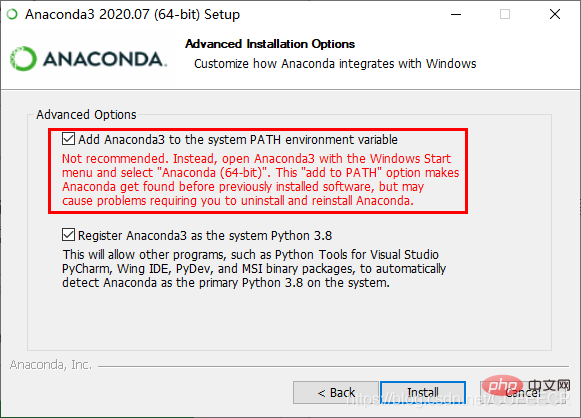
最后依次点击下一步、安装完成后,点击Win键(Windows系统下)可以看到最近添加或应用列表A下如图:
此时可点击Anaconda Navigator,如下所示: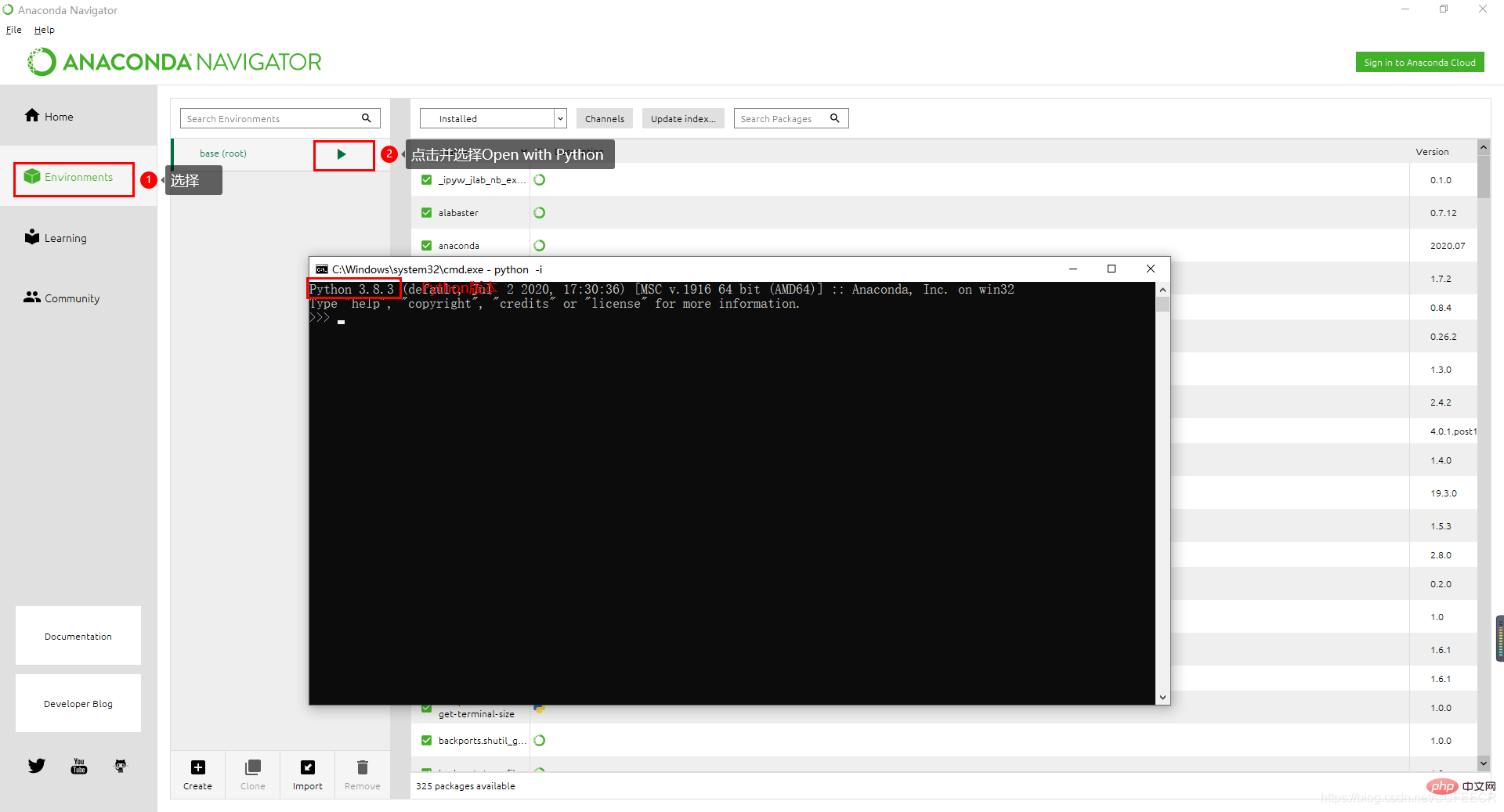
可以看到环境为Python 3.8.3,Anaconda创建的基础环境名为base,也是默认环境,也可以看到默认安装的库。
再打开Anaconda命令行工具Anaconda Powershell Prompt,输入python -V,也打印Python 3.8.3。
还可以通过命令创建新的conda环境,如conda create --name py27 python=2.7执行后即创建了一个名为py27的Python版本为2.7的conda环境。
激活环境执行命令conda activate py27,停用使用命令conda deactivate。
可以在命令行中执行conda list查看已经安装的库,如下:
# packages in environment at E:\Anaconda3: # # Name Version Build Channel _ipyw_jlab_nb_ext_conf 0.1.0 py38_0 alabaster 0.7.12 py_0 anaconda 2020.07 py38_0 anaconda-client 1.7.2 py38_0 anaconda-navigator 1.9.12 py38_0 ... zlib 1.2.11 h62dcd97_4 zope 1.0 py38_1 zope.event 4.4 py38_0 zope.interface 4.7.1 py38he774522_0 zstd 1.4.5 ha9fde0e_0
3.conda工具的介绍和包管理
conda是Anaconda下用于包管理和环境管理的工具,功能上类似pip和virtualenv的组合,conda的环境管理与virtualenv是基本上是类似的操作。
安装成功后conda会默认加入到环境变量中,因此可直接在命令行窗口运行conda命令。
常见的conda命令和含义如下:
| 命令含义 | conda命令 |
|---|---|
| conda –h | 查看帮助 |
| 基于python3.6版本创建名为python36的环境 | conda create --name python36 python=3.6 |
| 激活此环境 | activate python36(Windows)、source activate python36(linux/mac) |
| 查看python版本 | python -V |
| 退出当前环境 | deactivate python36 |
| 删除环境 | conda remove -n py27 --all |
| 查看所有安装的环境 | conda info -e |
conda的包管理常见命令如下:
| 包管理命令意义 | 包管理命令 |
|---|---|
| 安装matplotlib | conda install matplotlib |
| 查看已安装的包 | conda list |
| 包更新 | conda update matplotlib |
| 删除包 | conda remove matplotlib |
在conda中,anything is a package一切皆是包,conda本身可以看作是一个包,python环境可以看作是一个包,anaconda也可以看作是一个包,因此除了普通的第三方包支持更新之外,这3个包也支持如下命令:
| 操作 | 命令 |
|---|---|
| 更新conda本身 | conda update conda |
| 更新anaconda应用 | conda update anaconda |
| 更新python,假设当前python环境是3.8.1,而最新版本是3.8.2,那么就会升级到3.8.2 | conda update python |
四、Jupyter Notebook
1.Jupyter Notebook基本介绍
Jupyter Notebook(此前被称为IPython notebook)是一个交互式笔记本,支持运行40多种编程语言。
在开始使用notebook之前,需要先安装该库:
(1)在命令行中执行pip install jupyter来安装;
(2)安装Anaconda后自带Jupyter Notebook。
在命令行中执行jupyter notebook,就会在当前目录下启动Jupyter服务并使用默认浏览器打开页面,还可以复制链接到其他浏览器中打开,如下:
可以看到,notebook界面由以下部分组成:
(1)notebook名称;
(2)主工具栏,提供了保存、导出、重载notebook,以及重启内核等选项;
(3)notebook主要区域,包含了notebook的内容编辑区。
2.Jupyter Notebook的使用
在Jupyter页面下方的主要区域,由被称为单元格的部分组成。每个notebook由多个单元格构成,而每个单元格又可以有不同的用途。
上图中看到的是一个代码单元格(code cell),以[ ]开头,在这种类型的单元格中,可以输入任意代码并执行。
例如,输入1 + 2并按下Shift + Enter,单元格中的代码就会被计算,光标也会被移动到一个新的单元格中。
如果想新建一个notebook,只需要点击New,选择希望启动的notebook类型即可。
简单使用示意如下: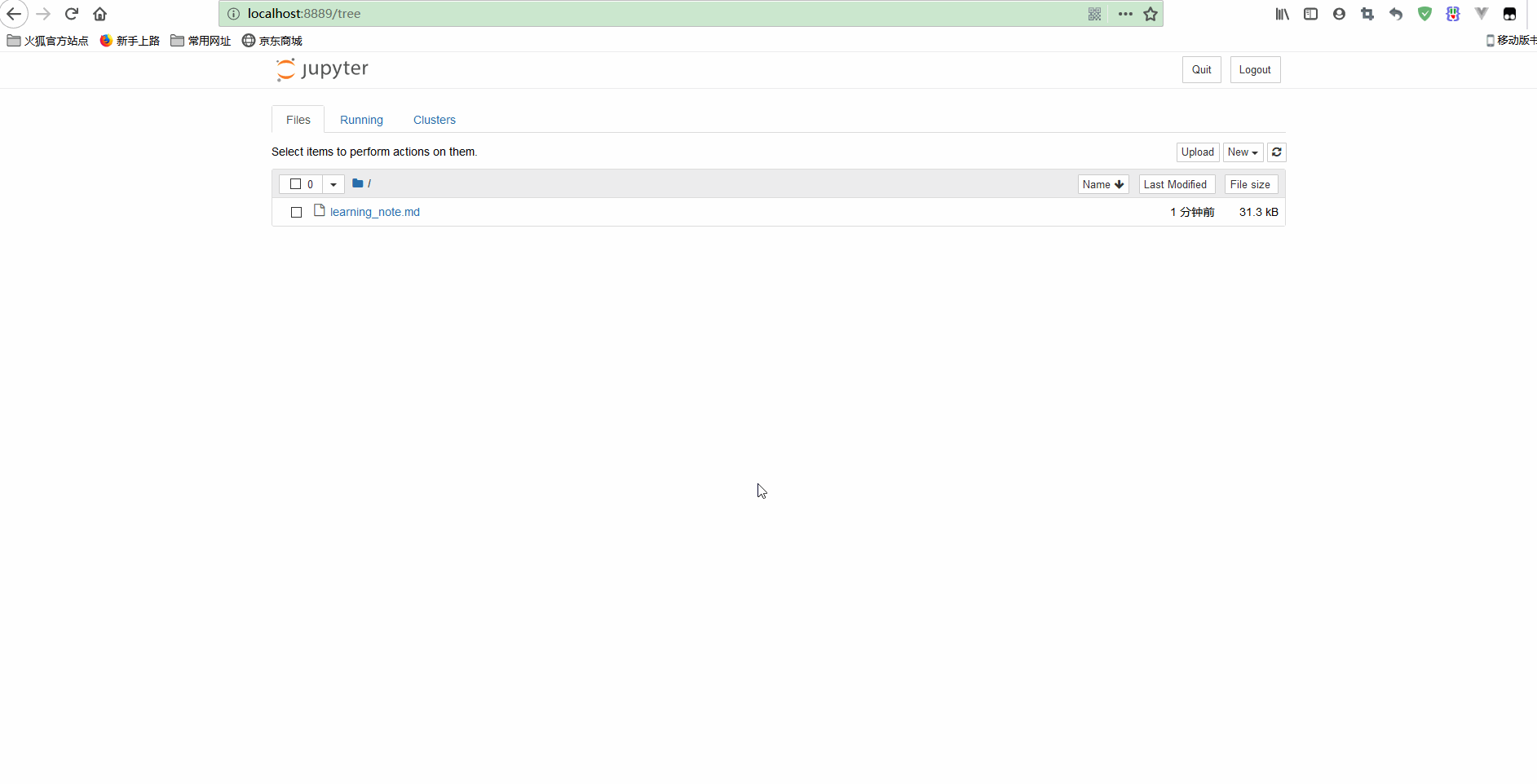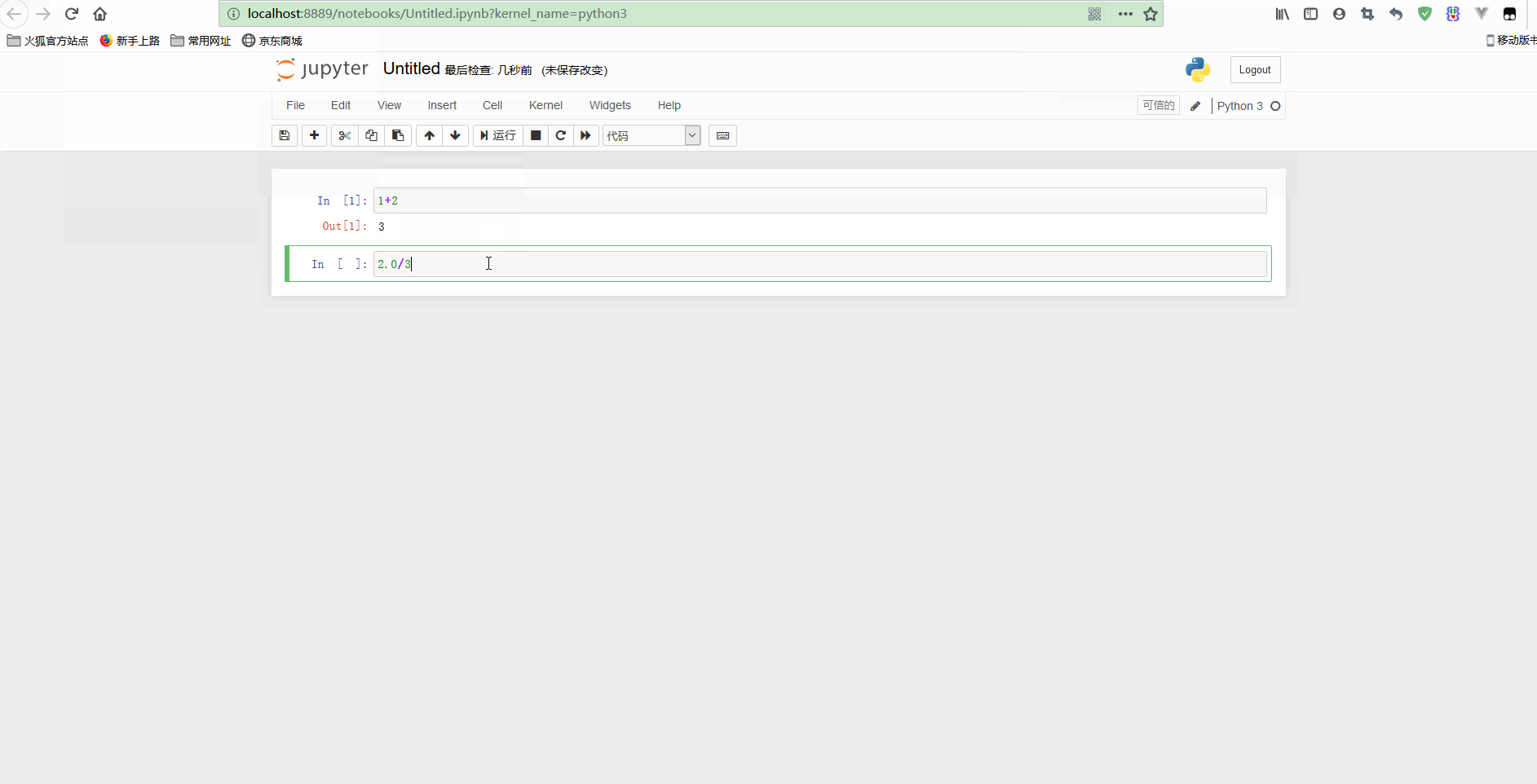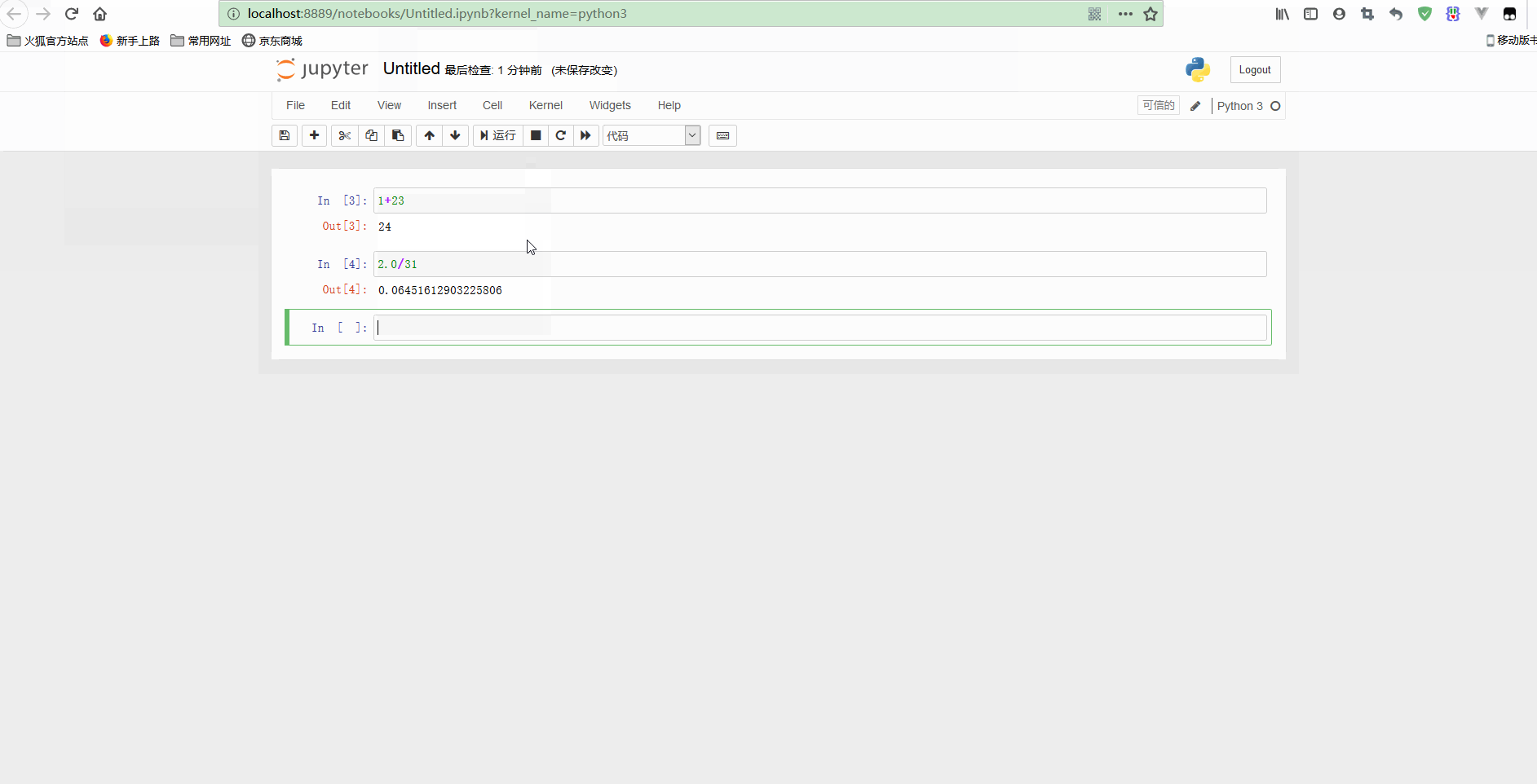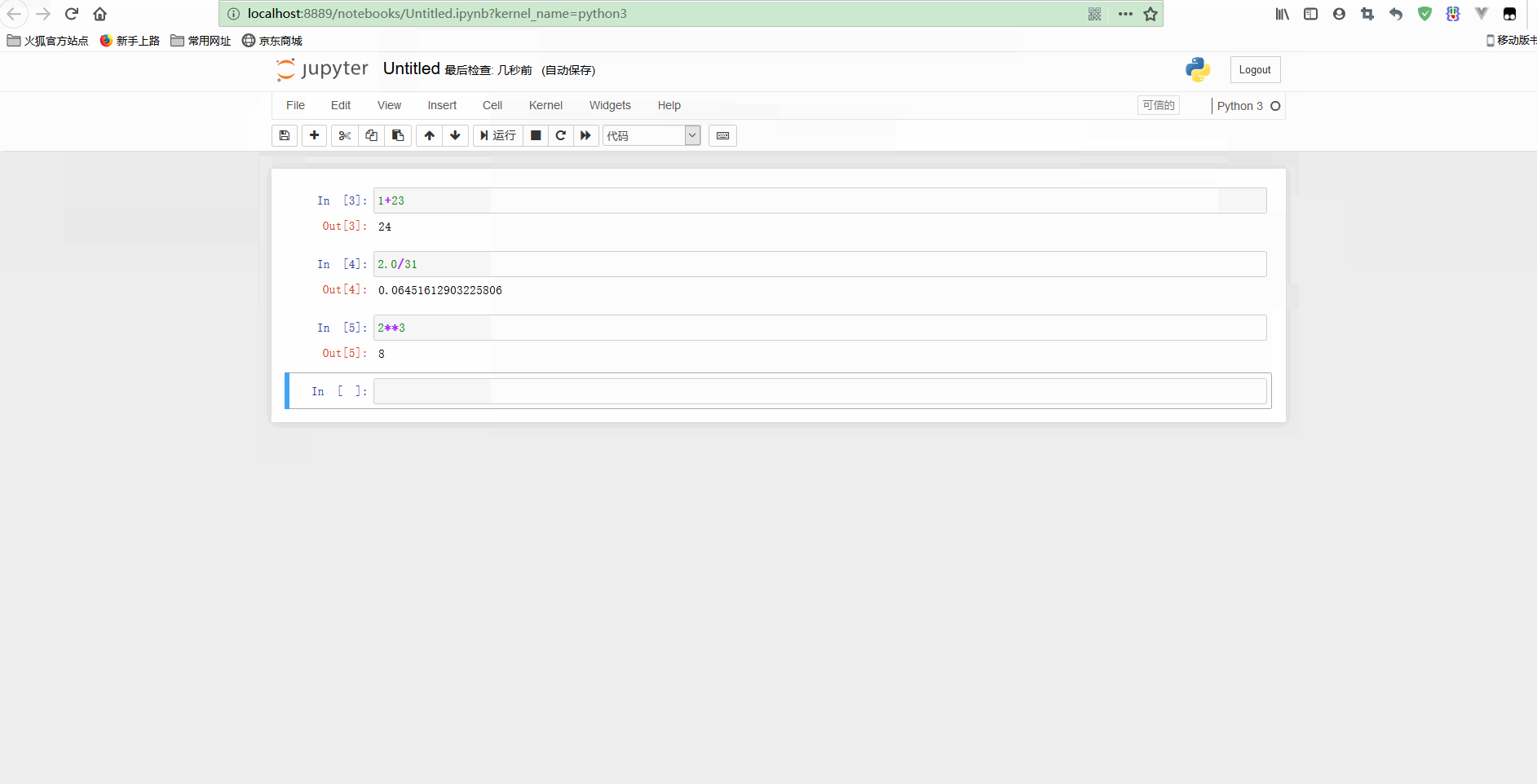
可以看到,notebook可以修改之前的单元格,对其重新计算,这样就可以更新整个文档了。如果你不想重新运行整个脚本,只想用不同的参数测试某个程式的话,这个特性显得尤其强大。
不过,也可以重新计算整个notebook,只要点击Cell -> Run all即可。
再测试标题和其他代码如下: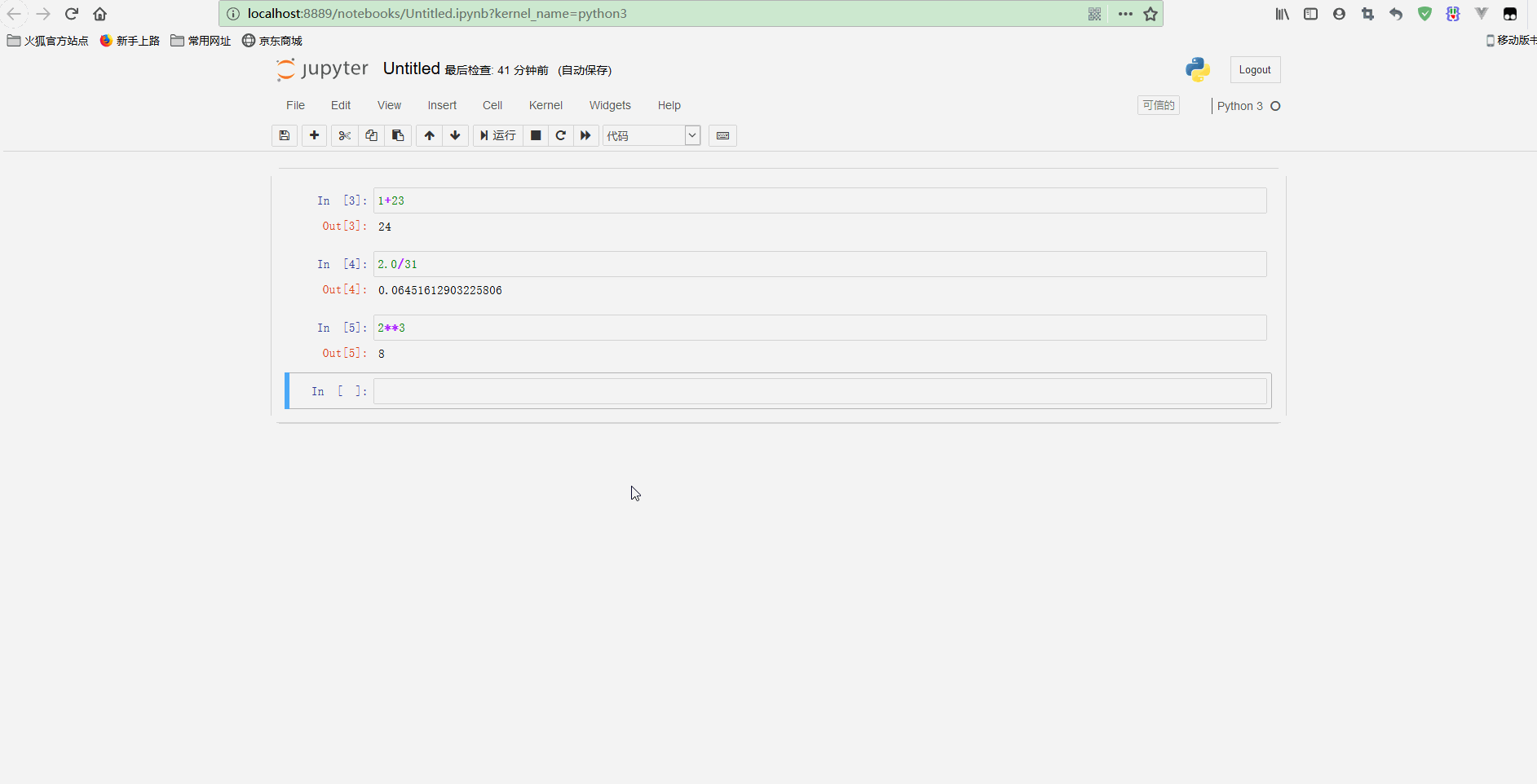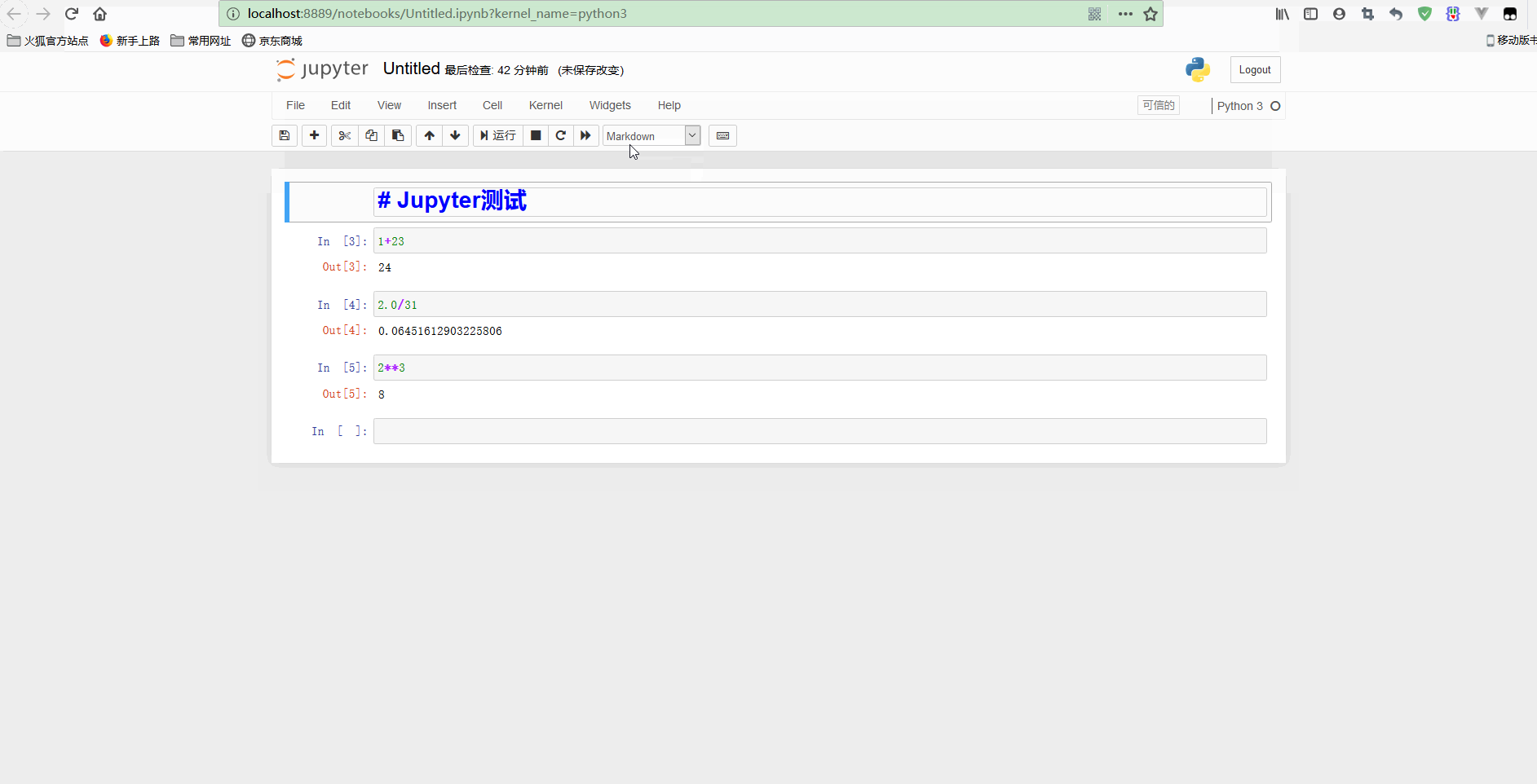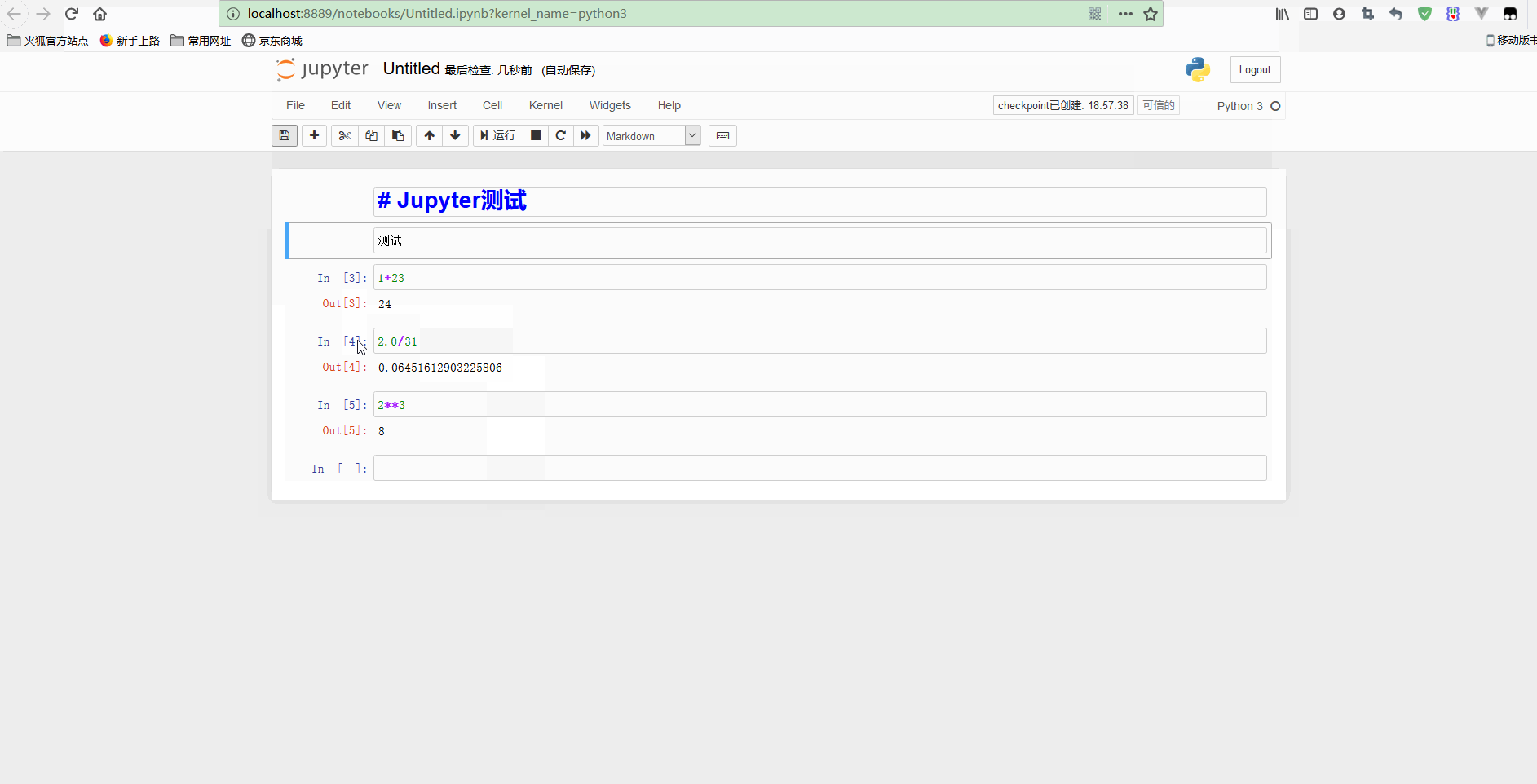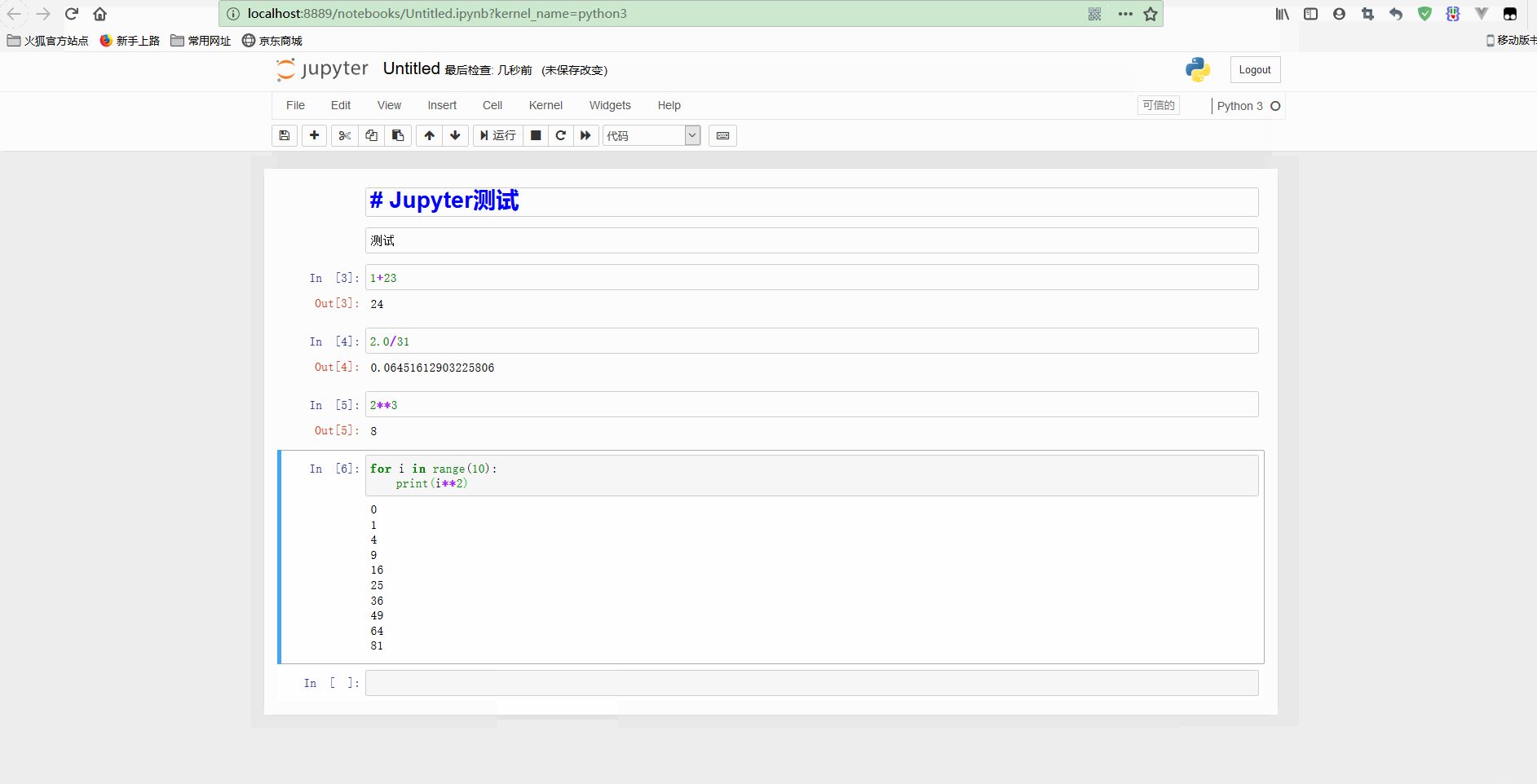
可以看到,在顶部添加了一个notebook的标题,还可以执行for循环等语句。
3.Jupyter中使用Python
Jupyter测试Python变量和数据类型如下:
测试Python函数如下:
测试Python模块如下:
可以看到,在执行出错时,也会抛出异常。
测试数据读写如下:
数据读写很重要,因为进行数据分析时必须先读取数据,进行数据处理后也要进行保存。
4.数据交互案例
加载csv数据,处理数据,保存到MongoDB数据库
有csv文件shopproducts.csv和userratings.csv,分别是商品数据和用户评分数据,如下:
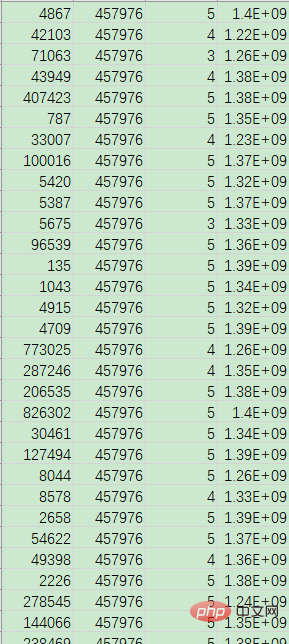
如需获取数据、代码等相关文件进行测试学习,可以直接点击加QQ群
现在需要通过Python将其读取出来,并将指定的字段保存到MongoDB中,需要在Anaconda中执行命令conda install pymongo安装pymongo。
Python代码如下:
import pymongoclass Product:
def __init__(self,productId:int ,name, imageUrl, categories, tags):
self.productId = productId
self.name = name
self.imageUrl = imageUrl
self.categories = categories
self.tags = tags def __str__(self) -> str:
return self.productId +'^' + self.name +'^' + self.imageUrl +'^' + self.categories +'^' + self.tagsclass Rating:
def __init__(self, userId:int, productId:int, score:float, timestamp:int):
self.userId = userId
self.productId = productId
self.score = score
self.timestamp = timestamp def __str__(self) -> str:
return self.userId +'^' + self.productId +'^' + self.score +'^' + self.timestampif __name__ == '__main__':
myclient = pymongo.MongoClient("mongodb://127.0.0.1:27017/")
mydb = myclient["goods-users"]
# val attr = item.split("\\^")
# // 转换成Product
# Product(attr(0).toInt, attr(1).trim, attr(4).trim, attr(5).trim, attr(6).trim)
shopproducts = mydb['shopproducts']
with open('shopproducts.csv', 'r',encoding='UTF-8') as f:
item = f.readline()
while item:
attr = item.split('^')
product = Product(int(attr[0]), attr[1].strip(), attr[4].strip(), attr[5].strip(), attr[6].strip())
shopproducts.insert_one(product.__dict__)
# print(product)
# print(json.dumps(obj=product.__dict__,ensure_ascii=False))
item = f.readline()
# val attr = item.split(",")
# Rating(attr(0).toInt, attr(1).toInt, attr(2).toDouble, attr(3).toInt)
userratings = mydb['userratings']
with open('userratings.csv', 'r',encoding='UTF-8') as f:
item = f.readline()
while item:
attr = item.split(',')
rating = Rating(int(attr[0]), int(attr[1].strip()), float(attr[2].strip()), int(attr[3].strip()))
userratings.insert_one(rating.__dict__)
# print(rating)
item = f.readline()
在启动MongoDB服务后,运行Python代码,运行完成后,再通过Robo 3T查看数据库如下: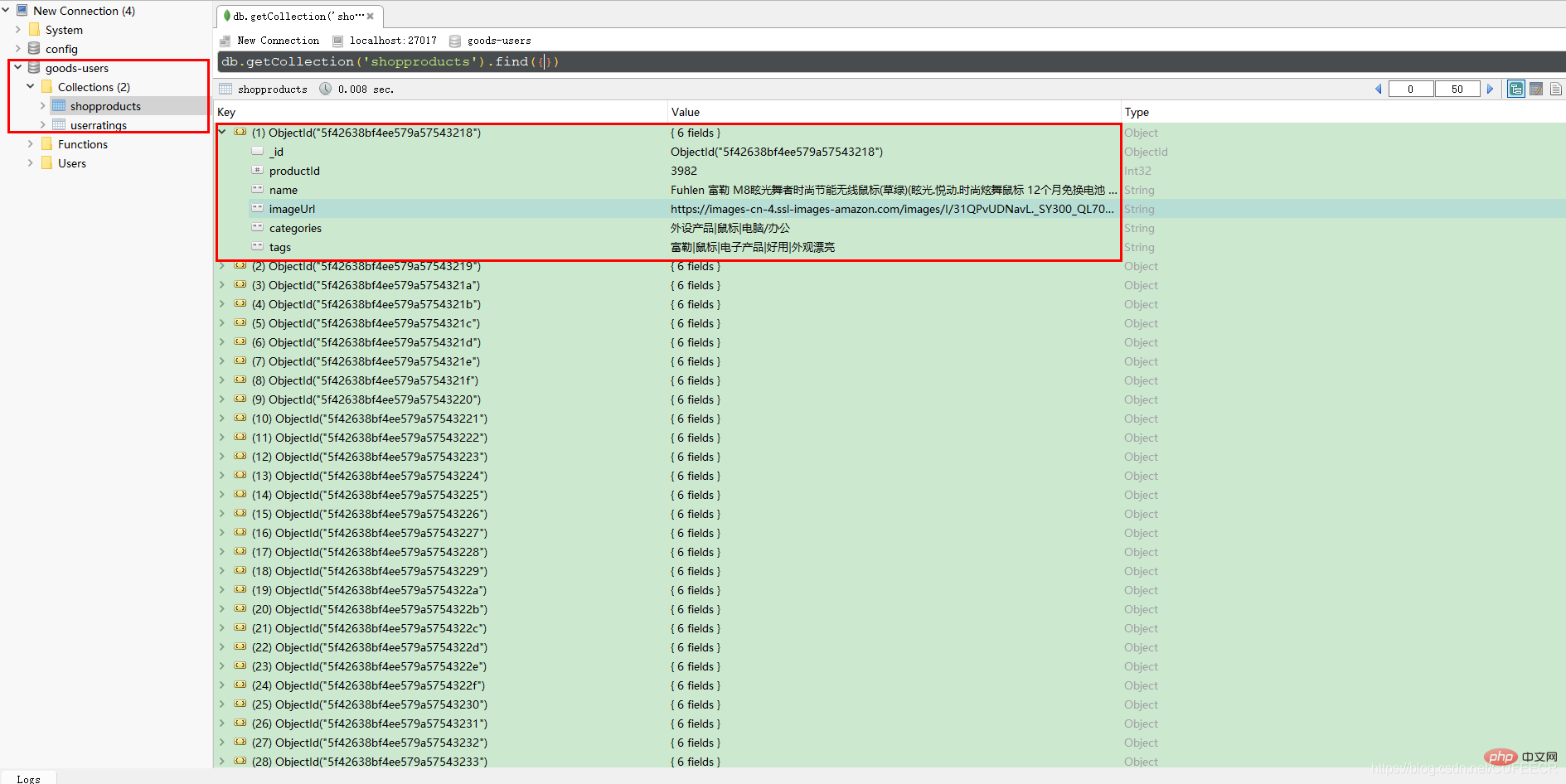
显然,保存数据成功。
使用Jupyter处理商铺数据
待处理的数据是商铺数据,如下: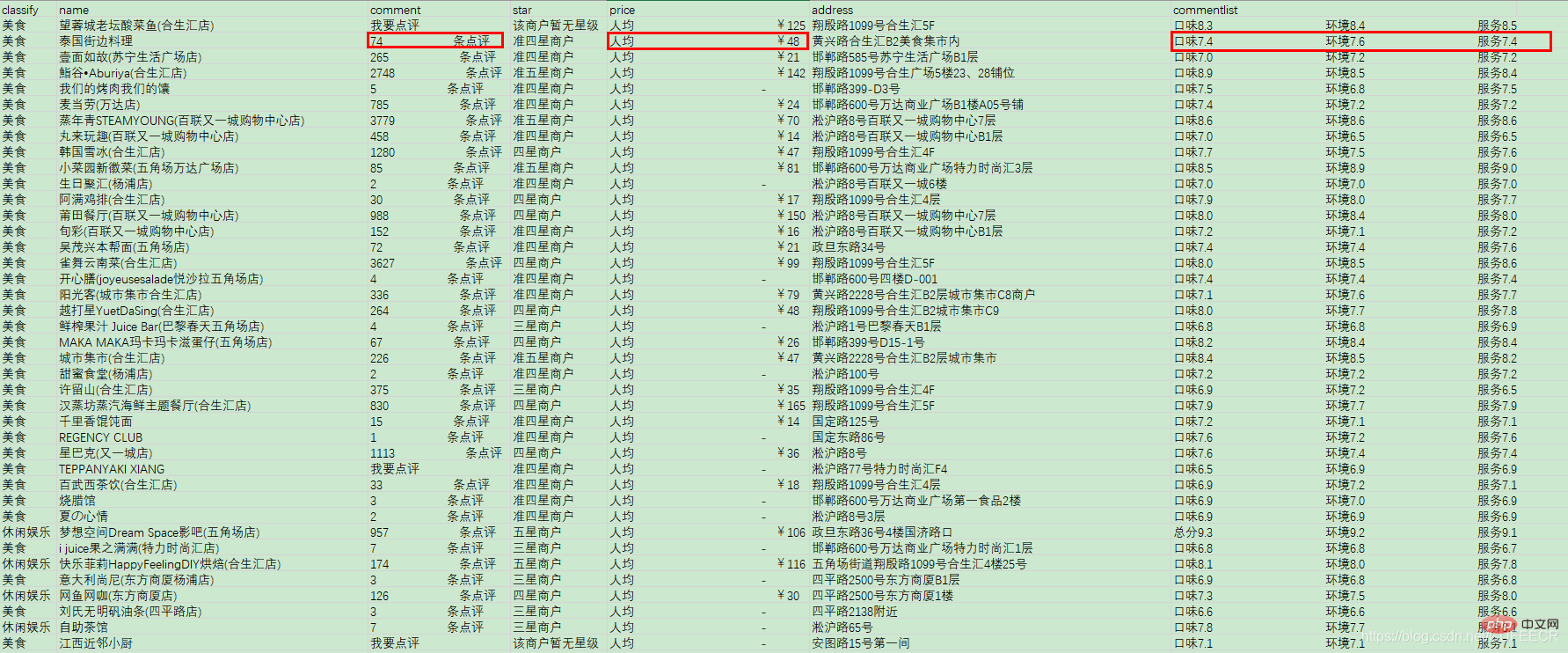
包括名称、评论数、价格、地址、评分列表等,其中评论数、价格和评分均不规则、需要进行数据清洗。
如需获取数据、代码等相关文件进行测试学习,可以直接点击加QQ群
Jupyter中处理如下: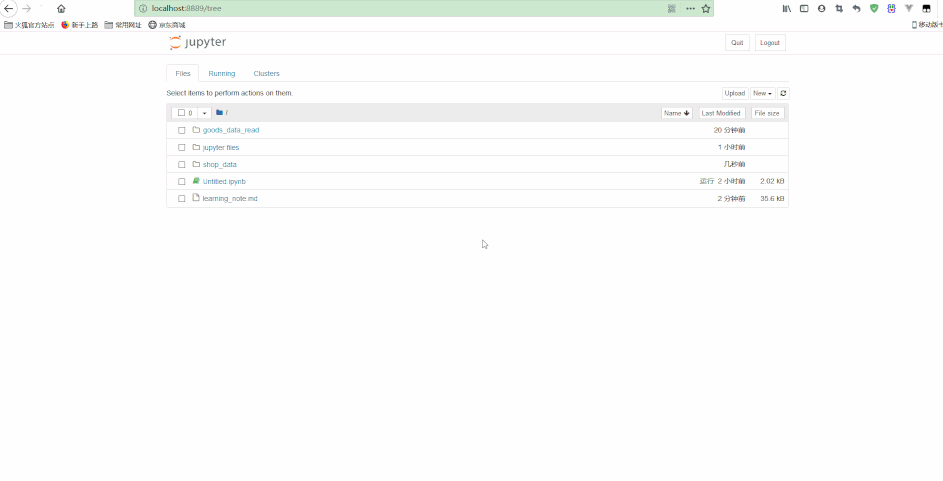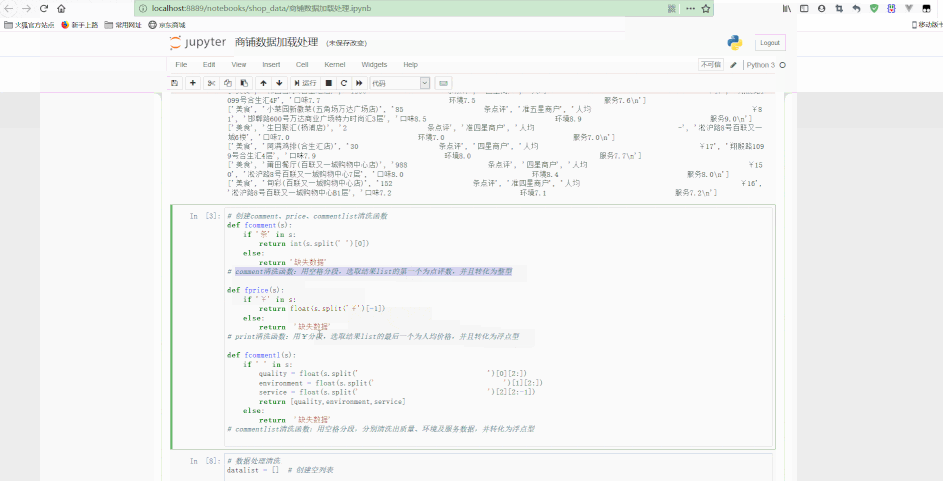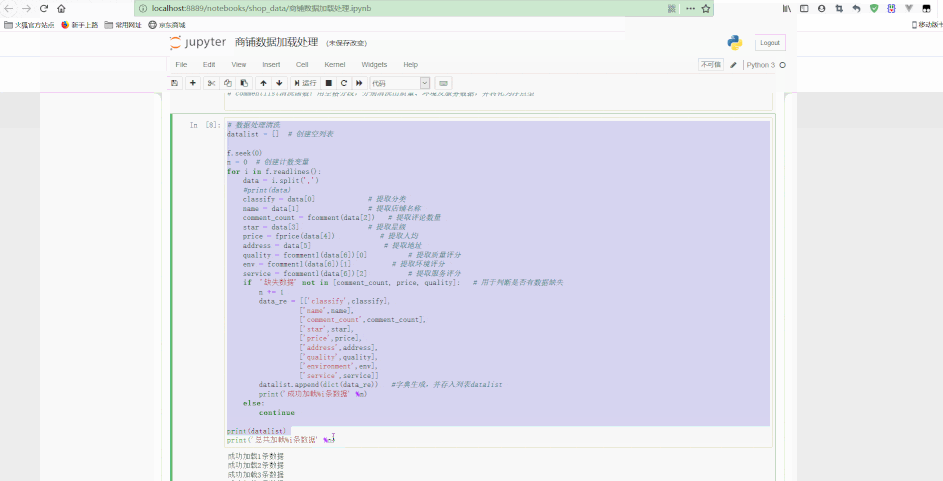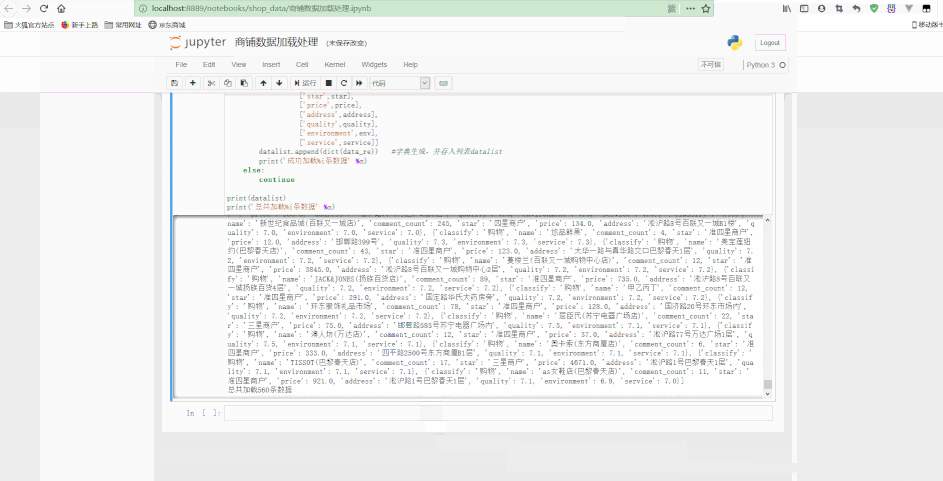
可以看到,最后得到了经过清洗后的规则数据。
完整Python代码如下:
# 数据读取f = open('商铺数据.csv', 'r', encoding='utf8')for i in f.readlines()[1:15]:
print(i.split(','))# 创建comment、price、commentlist清洗函数def fcomment(s):
'''comment清洗函数:用空格分段,选取结果list的第一个为点评数,并且转化为整型'''
if '条' in s:
return int(s.split(' ')[0])
else:
return '缺失数据'def fprice(s):
'''price清洗函数:用¥分段,选取结果list的最后一个为人均价格,并且转化为浮点型'''
if '¥' in s:
return float(s.split('¥')[-1])
else:
return '缺失数据'def fcommentl(s):
'''commentlist清洗函数:用空格分段,分别清洗出质量、环境及服务数据,并转化为浮点型'''
if ' ' in s:
quality = float(s.split(' ')[0][2:])
environment = float(s.split(' ')[1][2:])
service = float(s.split(' ')[2][2:-1])
return [quality, environment, service]
else:
return '缺失数据'# 数据处理清洗datalist = [] # 创建空列表f.seek(0)n = 0 # 创建计数变量for i in f.readlines():
data = i.split(',')
# print(data)
classify = data[0] # 提取分类
name = data[1] # 提取店铺名称
comment_count = fcomment(data[2]) # 提取评论数量
star = data[3] # 提取星级
price = fprice(data[4]) # 提取人均
address = data[5] # 提取地址
quality = fcommentl(data[6])[0] # 提取质量评分
env = fcommentl(data[6])[1] # 提取环境评分
service = fcommentl(data[6])[2] # 提取服务评分
if '缺失数据' not in [comment_count, price, quality]: # 用于判断是否有数据缺失
n += 1
data_re = [['classify', classify],
['name', name],
['comment_count', comment_count],
['star', star],
['price', price],
['address', address],
['quality', quality],
['environment', env],
['service', service]]
datalist.append(dict(data_re)) # 字典生成,并存入列表datalist
print('成功加载%i条数据' % n)
else:
continueprint(datalist)print('总共加载%i条数据' % n)f.close()
更多编程相关知识,请访问:编程教学!!
Atas ialah kandungan terperinci Python数据分析实战之 概述数据分析. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!