



今天javascript栏目介绍前端安全。
前言
Hello,AV8D~今天我们要分享的主题是前端Web安全。web安全的重要性不言而喻,是所有互联网企业都绕不开的话题。
在web前端领域,尽管浏览器已经在系统层面帮我们做了诸多的隔离和保护措施,但是网页代码开放式的特点和html、JS的语言特性使得黑客们依然有非常多的可乘之机,Google、facebook等等都有各自的漏洞悬赏机制,力求在黑客之前发现和修复漏洞,将企业损失降到最低。
web安全是老生常谈的话题,但是常说常新,今天就再次梳(c)理(v)一遍前端的一些web攻击手段,让大家看完这篇文章之后可以学到:
- 常见的前端安全问题以及对应的解决方案;
- 一丢丢网络攻击的小技巧和小知识;
- 一些经典的漏洞攻击案例;
- 以及最近进入我们视野的新的攻击手段;
XSS
1、XSS介绍
XSS的全称是 Cross-Site Scripting,跨站脚本攻击。是指通过利用网页开发时留下的漏洞,通过巧妙的方法注入恶意指令代码到网页,使用户加载并执行攻击者恶意制造的网页程序。通俗一点讲,就是黑客想法设防地让用户在访问的网页里运行自己写的攻击代码,一旦成功运行,黑客就有可能干出以下勾当:
- 获取当前用户在这个网站的
cookies,从而拿到用户的敏感信息; - 以当前用户的身份发起一些非用户本意的操作请求,比如删除网站好友,发帖,发私信等等;
- 实现
DDos攻击;
根据攻击的来源,XSS可以大体分为持久型攻击和非持久型攻击(当然也有分反射型、存储型和Dom型的,我个人更愿意选择第一种分类,因为更便于理解)。
非持久型攻击
非持久型XSS的特点在于即时性,它不需要存储在服务器中,通过巧妙地构造一个带恶意代码的URL,然后引导用户点击访问,即可实现攻击。
举一个简单的小栗子,假设有个网站如下。
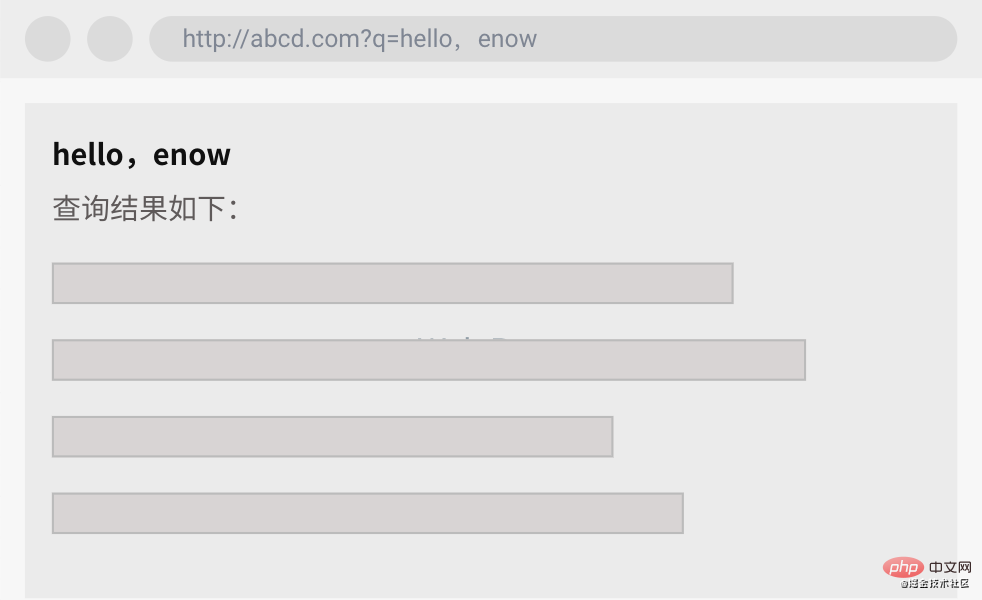
细心的你发现这个页面会把url上面的q参数内容放到网页中,而你打开调试台看到网页的代码实现如下:
<h1 id="query-key"></h1><span>查询结果如下</span>// ...<script>
const reg = new RegExp("(^|&)q=([^&]*)(&|$)", "i"); const res = window.location.search.substr(1).match(reg); if (res != null) { const query = decodeURIComponent(res[2]); document.getElementById('query-key').innerHTML = query;
};</script>复制代码
发现它没有对query做过滤,而且直接用innerHTML方法插入到了DOM中,你看完差点笑出声:一点安全意识都没有!那假如你想针对这个网站设计一个URL来让用户点击后发起一个XSS攻击,从而拿到用户的cookies数据,你会怎么做呢?
那还不是非常的so easy,反手就可以写出一条XSS的链接出来:
http://abcd.com?q=<script>alert(document.cookie)</script>复制代码
这样网页会把q参数中的script标签插入到DOM中执行,进而弹出提示框。
思路肯定是没问题的,不过你可能会发现不起效果,这是因为浏览器针对script等一些危险标签的插入做了拦截过滤,当然了这难不倒我们,毕竟咱们也不能把我要干坏事写在脸上,这不尊重对手,所以咱们换种委婉一点的写法就行了:
http://abcd.com?q=<img src="" onerror="alert(document.cookie)" />复制代码
因为是插入一张图片,浏览器一般不会过滤拦截,然后我们把src置空使其触发onerror事件,间接地执行我们的恶意脚本。done!
持久型攻击
你可能发现非持久型攻击有个不好的地方,那就是在攻击之前你得先让用户能够看到你的这行URL并且诱导他点击,说白了你还得想办法提高这个恶意链接的曝光度!这好麻烦啊,那有没有一劳永逸的方法呢?
假如我们可以想办法把恶意代码放到网站的数据库里边存起来,那接下来这个网站所有访问到我这个恶意数据的用户不就都遭殃了吗?
因此假如某个网站的评论区也未作过滤的安全处理,那么我们就可以通过评论的方式将恶意脚本提交至后台服务器,之后任何访问了此评论页面的用户,都会执行到我的代码,从而达到攻击目的。
A用户在评论里边写入了一条恶意代码并提交后台:
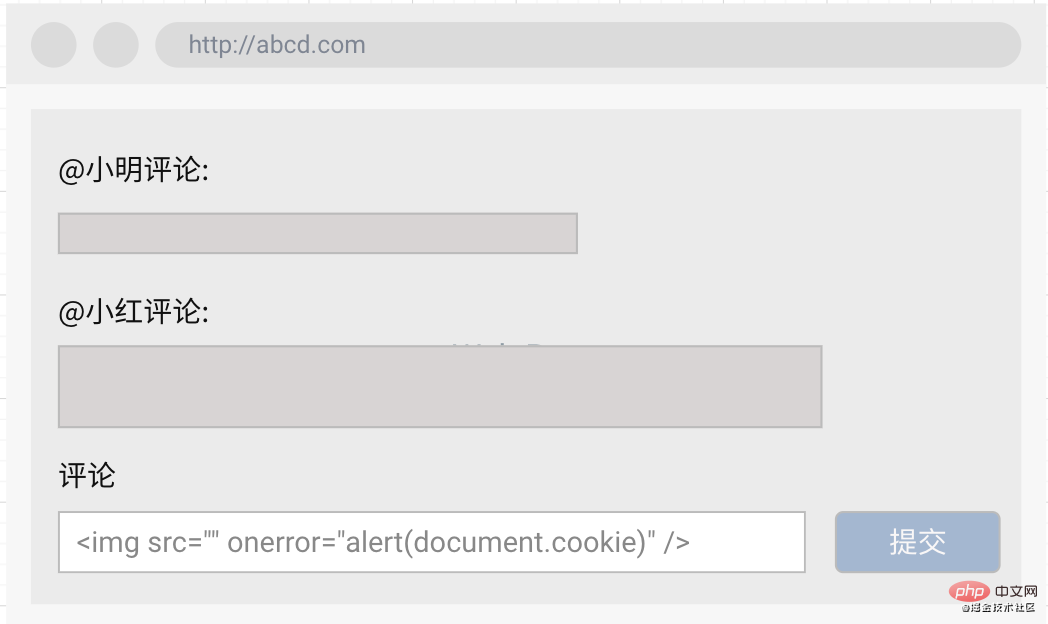
当B用户访问这个评论页面时,网页就会加载A的评论,进而触发恶意代码(而此时B用户其实啥都没做,他只是非常乖巧地打开了这个非常正规的网站,然后他就中招了):
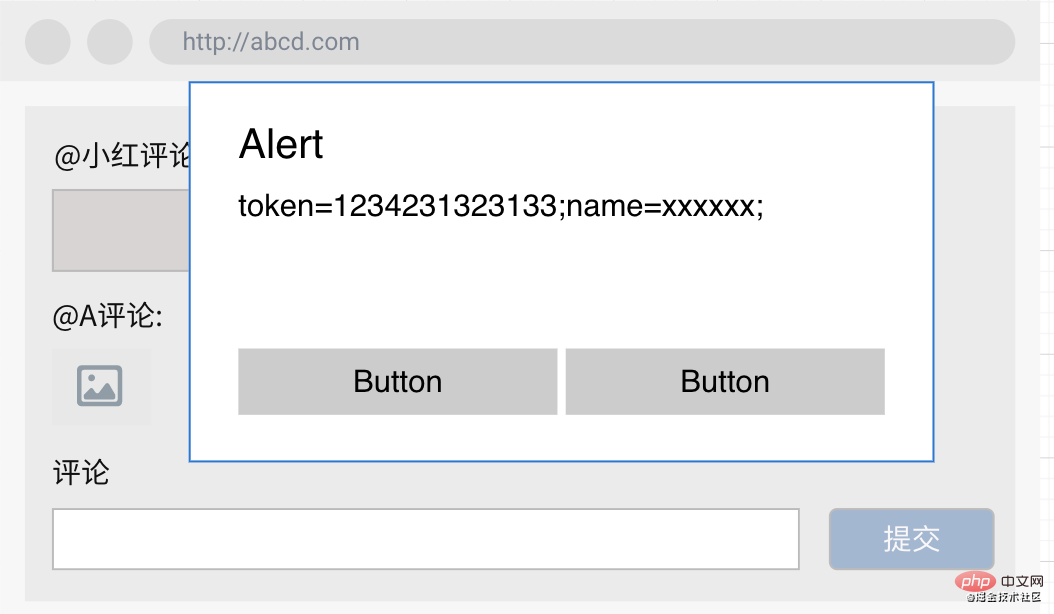
因此我们可以总结一下持久型XXS的特点:
- 因为被保存在了数据库中,因此它具有持久性;
- 由于不需要诱导用户点击恶意链接即可造成攻击,更易达到攻击目的,因此持久型XSS更具危害性;
2、防御方式
介绍完概念,我们可以知道要想抵御XSS攻击,大概可以从两方面入手:
- 想办法阻止恶意代码的注入和执行;
- 用更安全的方法校验和保护用户的身份凭证,以降低XSS攻击之后带来的危害;
1、使用HTML转义。对外部插入的内容要永远保持警惕。
对所有外部插入的代码都应该做一次转义,将script,& < > " ' /等危险字符做过滤和转义替换,同时尽量避免使用innerHTML,document.write,outerHTML,eval等方法,用安全性更高的textContent,setAttribute等方法做替代;
2、开启CSP防护。内容安全策略(CSP)的设计就是为了防御XSS攻击的,通过在HTTP头部中设置Content-Security-Policy,就可以配置该策略,如果将CSP设置成一下模式:
Content-Security-Policy: script-src 'self'复制代码
那么该网站将:
- 不允许内联脚本执行;
- 禁止加载外域代码;
- 禁止外域提交;
这将有效地防范XSS的攻击,当然他也非常严格,可能会对自身的业务开发也造成一定限制,更多关于CSP的内容可以查看MDN。
3、设置HttpOnly。当然这已经是属于降低XSS危害的方法,对于所有包含敏感信息的cookie,都应该在服务端对其设置httpOnly,被设置了httpOnly的cookie字段无法通过JS获取,也就降低了XSS攻击时用户凭据隐私泄漏的风险。
CSRF
1、CSRF介绍
又是一个耳熟能详,面试常问的知识点。
CSRF(Cross-site request forgery)中文名称跨站请求伪造,攻击者诱导受害者进入第三方网站,在第三方网站中,向被攻击网站发送跨站请求。利用受害者在被攻击网站已经获取的注册凭证,绕过后台的用户验证,达到冒充用户对被攻击的网站执行某项操作的目的。
简单介绍一下CSRF的攻击流程:
- 1、受害者登录目标网站A;
- 2、受害者以某种方式接触到恶意网站B的链接;
- 3、受害者点击链接访问网站B, 网站B中的js代码执行, 偷偷向目标网站A发送某个请求;
- 4、由于受害者登录过网站A, 因此请求携带了网站A的相关cookie凭证,最后请求成功执行;
最后在受害者不知情的情况下,恶意网站向目标网站以受害者身份执行了一些带权限的操作,给受害者带来一系列危害和损失。
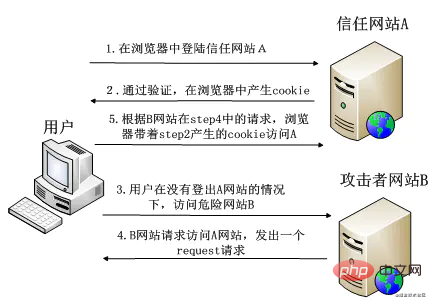
这个过程很好理解,篇幅有限,这里就不举例子做详细的解释了。
至于浏览器存在跨域限制,那么恶意网站如何对目标网站发起请求的问题,这属于如何解决跨域限制的知识点,在这里可以简单总结为以下方法:
- 对于GET请求非常容易了,
img标签链接不受浏览器的跨域限制,因此可以直接以img的形式发起请求; - 对于POST请求,通过CORS方法,还是很容易实现;
2、防御方式
知道了整个攻击的流程,那么我们就可以着手看看在哪些阶段可以对CSRF攻击做防御工作。
- 首先该攻击请求基本是从第三方网站中发起,因此客户端似乎无法通过代码来阻止请求的发起。
- 但是关键的一步在于恶意请求发起必须要带上身份凭据,请求才能被通过和执行,那如何通过一系列措施来加大三方网站对身份凭据的获取难度,以及完善服务端身份凭证的校验方式,成为了防御CSRF的重点工作。
1、 SameSite Cookie
如果能让第三方发起的请求无法携带相关的cookie,那一切问题好像就解决了啊。值得庆幸的是,浏览器针对cookie提供了SameSite的属性,该属性表示 Cookie 不随着跨域请求发送。该提案有google提出,美中不足的是目前还在试行阶段,存在兼容性问题。
2、CSRF Token
既然浏览器暂时无法帮我们解决所有问题,那就自己想办法把身份校验机制搞复杂一点,只靠cookie没有安全保障,那就再加一个校验维度进来。SCRF Token就是这样一种解决方案。
这个方案流程就是:在用户访问网站时,后台服务器根据算法再生成一个Token,然后把这个Token放在seesion中,当网站发起请求时,不仅要携带cookie凭证,还要把这个Token也带上,后台一起校验之后确认身份再执行操作。由于SCRF Token是放在session中,因此当第三方网站发起请求时,无法拿到这个SCRF Token,故身份校验不再通过,就达到了防御攻击的效果。
3、同源检测
由于CSRF都是通过三方网站发起,因此我们如果能判断服务器每次收到的请求来自哪些网站,就可以过滤那些存在安全风险的网站发起的请求,降低被攻击的风险。
Referer和Origin是http请求的头部字段之一,用来标志该请求是从哪个页面链接过来的。因此后台服务器可以通过检查该字段是否是来自自己的网站链接,来避免第三方网站发起CSRF攻击。但是同源检测的可靠性并不高,比如在302重定向的时候,为了保护来源,http请求不会携带Origin字段,而Referer字段会受到Referer Policy规则的限制而不发送。
4、增加二次验证
针对一些有危险性的请求操作(比如删除账号,提现转账)我们可以增加用户的二次,比如发起手机或者邮箱验证码检验,进而降低CSRF打来的危害。
3、一些案例
1)Google Digital Garage是Google的一个在线教育产品,一名国外的安全工程师在他的博客介绍了如何通过CSRF攻击删除该网站的个人账号。
2)这篇文章则介绍了facebook网站上的安全漏洞,如何通过CSRF绕过安全保护实现帐户接管。
XS-Leaks
相信有些小伙伴已经开始犯困,毕竟前面介绍的两种Web攻击手段对很多人来说已经耳熟能详,如数家珍了。那本文的最后一章再介绍一种可能不太常见,但是却开始重新回归大众视野的Web攻击手段:XS-Leaks。
1、什么是XS-Leaks?
XS-Leaks即跨站泄漏。 XS-Leaks利用了对HTTP缓存进行查询的机制,通过对资源缓存的判断进而推断出当前用户的相关信息。如果你第一次听说XS-Leaks,那我相信你一定很意外为什么普普通通的HTTP资源缓存也能造成用户信息泄漏。
Chrome浏览器团队在他们的开发者网站中发表了一篇文章,表示在86版本之后的浏览器将开始对请求缓存资源机制进行分区(分域名)管理,原因就是因为之前的缓存机制可能会造成隐私泄漏。
在这之前Chrome浏览器的请求缓存策略很简单:
- 1、用户访问A页面,请求一张图片资源,浏览器拿到这张图片之后,会将这张图片进行缓存,并把这张图片的URL作为缓存查询的键值;
- 2、用户接着访问B页面,假如这个页面也用到了上述的那张图片,此时浏览器会先查询是否已经缓存了此资源,由于缓存过这张图片,因此浏览器直接使用了缓存资源;
由于缓存资源没有域名限制,所有网站都共享了缓存资源,因此利用这一点就可以检测用户是否访问过特定的网站:恶意网站通过发起特定的资源请求,通过判断此次资源是否来自缓存就可以推断出用户的浏览历史。比如我在我的网站中请求掘金的LOGO图片(或者其他更具唯一性的资源),如果我判断出这张图片来自缓存,那我就可以知道该用户访问过掘金网站。
XS-Leaks和上述的原理类似,利用了对HTTP缓存进行查询的机制,通过检测一个查询询问是否有结果来获取一些用户数据。XS-Leaks攻击的主要步骤流程如下:
- 1、删除特定网站的缓存资源。
- 2、强制浏览器刷新网站。
- 3、检查浏览器是否缓存了在(1)中删除的资源。
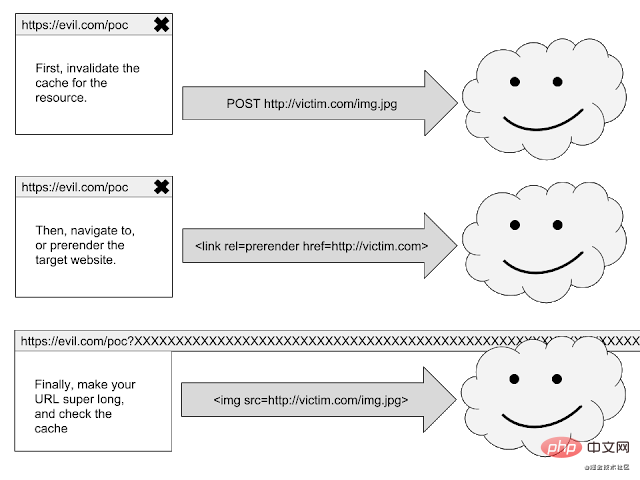
举一个小栗子,假如我们想知道当前访问我们网站的用户是否是某社交网站(假设链接为http://xxx.com)昵称为@helloWorld的用户,利用XS-Leaks攻击应该怎么做呢?
首先我们可以先将这名@helloWorld的用户头像图片从社交网站上扒下来,假设该图片链接长这样: http://xxx.com/user/helloWorld.jpg。
为了避免用户因为浏览了社交网站的一些页面(比如帖子列表页),请求过helloWorld的头像导致的缓存影响判断目的,当用户访问我们的页面时,我们需要先想办法清空这张头像的浏览器缓存。那么怎么能强制清楚一张图片的缓存呢?
FETCH POST http://xxx.com/user/helloWorld.jpg复制代码
没错,通过发起一个POST请求,就可以清除浏览器对这张图片的缓存(感兴趣的小伙伴可以看看这篇文章)。
接下来通过iframe或者<link ref=rerender href="http://xxx.com/user" />等方式悄悄发起一个请求,访问社交网站的个人信息页面http://xxx.com/user(这个页面包含用户的头像图片)。
紧接着只需要再请求一次头像http://xxx.com/user/helloWorld.jpg,判断其是否来自缓存,如果是,那不就说明了刚才请求的个人信息页面包含了这张图片,就可以推断出该名用户就是@helloWorld了。
那么问题又来了:如何判断一个请求来自缓存呢?
方法还是很多的,一种方法是通过读取img的宽高属性,来判断图片是否来自缓存:
const img = new Image();
img.onload = () => { // 如果img不是来自缓存,那么只有在图片加载完成触发onload之后,才能拿到实际的witdh值
console.log(img.width);
}
img.src = 'http://xxx.com/user/helloWorld.jpg';// 如果存在缓存,在这里可以立即读取到图片的 witdh 值,否则会打印 0console.log(img.width);复制代码
至此一次XS-Leaks攻击就完成了。我们也可以请求一些带权限的链接来判断用户是否拥有某个网站的特权身份等等。虽然这个小栗子看起来危害不大,只是做到了当前用户和目标网站账号的关联,但是不要小看黑客们的脑洞,一个看起来不起眼的漏洞很可能会带来巨大损失。
这里给大家分享一个关于XS-Leaks的github地址,里边记录了与XS-Leaks相关的攻击方式、知识和实际案例,帮助大家更深刻地理解概念和攻击手段。
2、防御方式
介绍了那么多,是时候总结一下XS-Leaks的一些防范措施了。可以看到XS-Leaks也是从第三方网站中发起攻击的,而且都是通过向目标网站发起请求而达到攻击目的,是不是和CSRF的攻击方式很相似?
没错,CSRF的防御手段同样可以让XS-Leaks对带鉴权的请求访问无效,从而降低危险。当然有些时候这种攻击其实并不需要鉴权就能达成目的,因此CSRF的防御手段并不能做到完美抵御,所以在浏览器层面增加缓存分区就显得非常有必要了:
- 设置SameSite Cookie;
- CSRF Token;
- 浏览器支持缓存分区;
3、web服务端缓存攻击
XS-Leaks利用了浏览器缓存的漏洞实现了攻击,但是其实不仅仅浏览器可以缓存,web服务器也是可以有缓存的,服务器缓存是把请求过的资源暂且放在一个专门的缓存服务器(例如CDN)上,当下一个用户访问同样的资源时就可以直接从缓存服务器上拿到响应,从而减轻Web服务器的压力。
那假如我们可以把攻击代码通过某种方式放在CDN等缓存服务器中,那发起了相同资源请求的用户就都会拿到这份恶意代码从而遭受攻击,这不就实现了XS-Leaks的“存储型攻击”?
缓存服务器通过cache-key来确定两个用户访问的是否是同一个资源,而这个cache-key通常由请求方法、路径、query、host头组成。假如一个web服务器有如下请求响应:

该响应中将请求头X-Forwarded-Host的值直接拼接到meta标签的content属性中,由此产生了XSS攻击的漏洞,因此我们通过发起一个如下请求:
GET /en?dontpoisoneveryone=1 HTTP/1.1Host: www.redhat.com X-Forwarded-Host: a."><script>alert(1)</script>复制代码
服务器就会返回如下响应,并缓存到缓存服务器中:
HTTP/1.1 200 OK Cache-Control: public, no-cache … <meta property="og:image" content="https://a."><script>alert(1)</script>"/>复制代码
由于X-Forwarded-Host不属于cache-key的一部分,因此当其他用户发起/en请求时,服务器都会认为是请求同一个资源从而应用缓存策略,将上面的恶意响应直接响应给用户,造成攻击。
上述的例子来自于BlackHat2020议题之Web缓存投毒这篇文章,文章非常详细地介绍了Web服务器缓存攻击的原理和案例,有兴趣的小伙伴也可以看看。
再说点啥
尽管已经有这么多的措施来应对和抵御web的各种攻击,但依旧有一个又一个的安全漏洞被黑客们发现和攻破,强如Google,页面简洁如Google Search的网站,依然在2019年遭到了XSS攻击。而这次攻击却只需要一行代码:
<noscript><p title="</noscript><img src=x onerror=alert(1)>">复制代码
大致的原因是Google在转义插入文本时,使用了HTML提供的template标签,使用template是个很不错的选择,因为它可以用来解析HTML,并且在解析过程中不会触发JavaScript脚本执行。然而template是JavaScript Disabled环境,而noscript在允许JavaScript和禁止JavaScript环境下的解析是不同的,这导致了这段恶意代码经过解析和sanitize之后仍然存在风险,最后成功实现了XSS攻击。有兴趣的小伙伴可以看看这篇关于这次XSS攻击的文章。
类似的“旁门左道”的攻击方式其实还很多,比如我们经常会用到的SVG图片,SVG的结构和HTML结构非常相似,通过forginObject标签我们还可以把script或者其他HTML标签插入到SVG图片中,假如web服务器允许用户上传任意SVG图像,那么就会存在持久型XSS攻击的安全风险。HTML转义有时候也并非一两行代码就能搞定,当我们碰到类似文本编辑需要保留用户粘贴内容样式的时候,如何在保留这些html的同时规避XSS的风险就值得我们仔细斟酌设计。
众所周知,我们在开发网页的时候基本不会遇到HTML的语法报错问题,因为HTML的解析引擎有着非常强大的容错机制,以至于不管你怎么写,浏览器都能帮你把文档解析渲染出来。然而这种容错性和复杂的解析逻辑也使得XSS能够不断找到新的攻击方式。
事实上,当我在用某网站在线制作前面章节的两张交互图的时候,就“无意中”触发了我里边的img代码,直接弹出了对话框,这也从侧面说明了web安全其实在很多开发团队中并没有得到足够多的重视,然而诸多的攻击案例告诉我们,我们的网站一旦遭受了攻击其损失可能是不可估量的,因此我们对于web安全,我们不能只是嘴上说说,纸上谈兵,或者只是当做面试的一个八股文知识点,而是应该时刻保持警惕,警钟长鸣才行。
受限于篇幅和精力,本次就先分享上述三个比较常见的web攻击手段,希望之后能够给大家分享更多关于web安全方面的知识和案例。
相关免费学习推荐:JavaScript(视频)
Atas ialah kandungan terperinci javascript介绍前端安全知多少. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 JavaScript in Action: Contoh dan projek dunia nyataApr 19, 2025 am 12:13 AM
JavaScript in Action: Contoh dan projek dunia nyataApr 19, 2025 am 12:13 AMAplikasi JavaScript di dunia nyata termasuk pembangunan depan dan back-end. 1) Memaparkan aplikasi front-end dengan membina aplikasi senarai TODO, yang melibatkan operasi DOM dan pemprosesan acara. 2) Membina Restfulapi melalui Node.js dan menyatakan untuk menunjukkan aplikasi back-end.
 JavaScript dan Web: Fungsi teras dan kes penggunaanApr 18, 2025 am 12:19 AM
JavaScript dan Web: Fungsi teras dan kes penggunaanApr 18, 2025 am 12:19 AMPenggunaan utama JavaScript dalam pembangunan web termasuk interaksi klien, pengesahan bentuk dan komunikasi tak segerak. 1) kemas kini kandungan dinamik dan interaksi pengguna melalui operasi DOM; 2) pengesahan pelanggan dijalankan sebelum pengguna mengemukakan data untuk meningkatkan pengalaman pengguna; 3) Komunikasi yang tidak bersesuaian dengan pelayan dicapai melalui teknologi Ajax.
 Memahami Enjin JavaScript: Butiran PelaksanaanApr 17, 2025 am 12:05 AM
Memahami Enjin JavaScript: Butiran PelaksanaanApr 17, 2025 am 12:05 AMMemahami bagaimana enjin JavaScript berfungsi secara dalaman adalah penting kepada pemaju kerana ia membantu menulis kod yang lebih cekap dan memahami kesesakan prestasi dan strategi pengoptimuman. 1) aliran kerja enjin termasuk tiga peringkat: parsing, penyusun dan pelaksanaan; 2) Semasa proses pelaksanaan, enjin akan melakukan pengoptimuman dinamik, seperti cache dalam talian dan kelas tersembunyi; 3) Amalan terbaik termasuk mengelakkan pembolehubah global, mengoptimumkan gelung, menggunakan const dan membiarkan, dan mengelakkan penggunaan penutupan yang berlebihan.
 Python vs JavaScript: Keluk Pembelajaran dan Kemudahan PenggunaanApr 16, 2025 am 12:12 AM
Python vs JavaScript: Keluk Pembelajaran dan Kemudahan PenggunaanApr 16, 2025 am 12:12 AMPython lebih sesuai untuk pemula, dengan lengkung pembelajaran yang lancar dan sintaks ringkas; JavaScript sesuai untuk pembangunan front-end, dengan lengkung pembelajaran yang curam dan sintaks yang fleksibel. 1. Sintaks Python adalah intuitif dan sesuai untuk sains data dan pembangunan back-end. 2. JavaScript adalah fleksibel dan digunakan secara meluas dalam pengaturcaraan depan dan pelayan.
 Python vs JavaScript: Komuniti, Perpustakaan, dan SumberApr 15, 2025 am 12:16 AM
Python vs JavaScript: Komuniti, Perpustakaan, dan SumberApr 15, 2025 am 12:16 AMPython dan JavaScript mempunyai kelebihan dan kekurangan mereka sendiri dari segi komuniti, perpustakaan dan sumber. 1) Komuniti Python mesra dan sesuai untuk pemula, tetapi sumber pembangunan depan tidak kaya dengan JavaScript. 2) Python berkuasa dalam bidang sains data dan perpustakaan pembelajaran mesin, sementara JavaScript lebih baik dalam perpustakaan pembangunan dan kerangka pembangunan depan. 3) Kedua -duanya mempunyai sumber pembelajaran yang kaya, tetapi Python sesuai untuk memulakan dengan dokumen rasmi, sementara JavaScript lebih baik dengan MDNWebDocs. Pilihan harus berdasarkan keperluan projek dan kepentingan peribadi.
 Dari C/C ke JavaScript: Bagaimana semuanya berfungsiApr 14, 2025 am 12:05 AM
Dari C/C ke JavaScript: Bagaimana semuanya berfungsiApr 14, 2025 am 12:05 AMPeralihan dari C/C ke JavaScript memerlukan menyesuaikan diri dengan menaip dinamik, pengumpulan sampah dan pengaturcaraan asynchronous. 1) C/C adalah bahasa yang ditaip secara statik yang memerlukan pengurusan memori manual, manakala JavaScript ditaip secara dinamik dan pengumpulan sampah diproses secara automatik. 2) C/C perlu dikumpulkan ke dalam kod mesin, manakala JavaScript adalah bahasa yang ditafsirkan. 3) JavaScript memperkenalkan konsep seperti penutupan, rantaian prototaip dan janji, yang meningkatkan keupayaan pengaturcaraan fleksibiliti dan asynchronous.
 Enjin JavaScript: Membandingkan PelaksanaanApr 13, 2025 am 12:05 AM
Enjin JavaScript: Membandingkan PelaksanaanApr 13, 2025 am 12:05 AMEnjin JavaScript yang berbeza mempunyai kesan yang berbeza apabila menguraikan dan melaksanakan kod JavaScript, kerana prinsip pelaksanaan dan strategi pengoptimuman setiap enjin berbeza. 1. Analisis leksikal: Menukar kod sumber ke dalam unit leksikal. 2. Analisis Tatabahasa: Menjana pokok sintaks abstrak. 3. Pengoptimuman dan Penyusunan: Menjana kod mesin melalui pengkompil JIT. 4. Jalankan: Jalankan kod mesin. Enjin V8 mengoptimumkan melalui kompilasi segera dan kelas tersembunyi, Spidermonkey menggunakan sistem kesimpulan jenis, menghasilkan prestasi prestasi yang berbeza pada kod yang sama.
 Beyond the Browser: JavaScript di dunia nyataApr 12, 2025 am 12:06 AM
Beyond the Browser: JavaScript di dunia nyataApr 12, 2025 am 12:06 AMAplikasi JavaScript di dunia nyata termasuk pengaturcaraan sisi pelayan, pembangunan aplikasi mudah alih dan Internet of Things Control: 1. Pengaturcaraan sisi pelayan direalisasikan melalui node.js, sesuai untuk pemprosesan permintaan serentak yang tinggi. 2. Pembangunan aplikasi mudah alih dijalankan melalui reaktnatif dan menyokong penggunaan silang platform. 3. Digunakan untuk kawalan peranti IoT melalui Perpustakaan Johnny-Five, sesuai untuk interaksi perkakasan.


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

MinGW - GNU Minimalis untuk Windows
Projek ini dalam proses untuk dipindahkan ke osdn.net/projects/mingw, anda boleh terus mengikuti kami di sana. MinGW: Port Windows asli bagi GNU Compiler Collection (GCC), perpustakaan import yang boleh diedarkan secara bebas dan fail pengepala untuk membina aplikasi Windows asli termasuk sambungan kepada masa jalan MSVC untuk menyokong fungsi C99. Semua perisian MinGW boleh dijalankan pada platform Windows 64-bit.

Dreamweaver CS6
Alat pembangunan web visual

mPDF
mPDF ialah perpustakaan PHP yang boleh menjana fail PDF daripada HTML yang dikodkan UTF-8. Pengarang asal, Ian Back, menulis mPDF untuk mengeluarkan fail PDF "dengan cepat" dari tapak webnya dan mengendalikan bahasa yang berbeza. Ia lebih perlahan dan menghasilkan fail yang lebih besar apabila menggunakan fon Unicode daripada skrip asal seperti HTML2FPDF, tetapi menyokong gaya CSS dsb. dan mempunyai banyak peningkatan. Menyokong hampir semua bahasa, termasuk RTL (Arab dan Ibrani) dan CJK (Cina, Jepun dan Korea). Menyokong elemen peringkat blok bersarang (seperti P, DIV),

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

