
Rumah >pangkalan data >tutorial mysql >我所理解的MySQL之二:索引
我所理解的MySQL之二:索引

- coldplay.xixike hadapan
- 2020-10-21 17:05:352370semak imbas
mysql教程栏目今天介绍相关索引知识。

MySQL 系列的第二篇,主要讨论 MySQL 中关于索引的一些问题,包括索引种类、数据模型、索引执行流程、最左前缀原则、索引失效情况以及索引下推等内容。
最早知道索引应该是在大二的数据库原理这门课中,当一个查询语句非常慢时,可以通过为某些字段添加索引来提高查询效率。
还有一个非常经典的例子:我们可以把数据库想象成字典,把索引想象成目录,当我们借助字典的目录来查询一个字的时候,就能体现出索引的作用了。
1. 索引种类
在 MySQL 中,从索引的逻辑或者说字段特性来区分,索引大致分为以下几个种类:普通索引、唯一索引、主键索引、联合索引和前缀索引。
- 普通索引:最基础的索引,没有任何限制。
- 唯一索引:索引列的值必须唯一。
- 主键索引:特殊的唯一索引,作为主键它的值不能为空。
- 联合索引:联合索引就是索引列为多个字段的普通索引,需要考虑最左前缀原则。
- 前缀索引:对字符类型的前几个字符或二进制类型的前几个字节建立索引。
还有另外一种从物理存储上来区分的索引分类:聚簇索引和非聚簇索引。
- 聚簇索引:索引顺序与数据存储顺序一致,其叶子节点存储的是数据行。
- 非聚簇索引:非聚簇索引的叶子节点存储的是聚簇索引的值,同时它是基于聚簇索引创建的。
简单来说,所谓的聚簇索引就是索引 key 与数据行在一起,而非聚簇索引的索引 key 对应的值是聚簇索引的值。
2. 索引的数据结构
常见的用于实现索引的数据结构有哈希表、有序数组和搜索树。
2.1 哈希索引
哈希表是一个以 key-value 形式来存储数据的容器,和 HashMap 一样,哈希索引也会将 key 通过特定的哈希函数计算得到索引值,然后在数组的相应位置存放 key 对应的 value,如果有两个 key 通过哈希函数计算得到的索引值相同(发生哈希冲突),那么数组的这个位置就会变成一个链表,存放所有哈希值相同的 value。
所以在一般情况下,哈希表进行等值查询的时间复杂度可以达到 O(1),但是在发生哈希冲突的情况下,还需要额外遍历链表中的所有值,才能够找到符合条件的数据。
另外,考虑到经过哈希函数计算得到的索引是不规律的——哈希表希望所有的 key 能够得到充分散列,这样才能让 key 均匀分布,不浪费空间——即哈希表的 key 是非顺序的,所以使用哈希表来进行区间查询时很慢的,排序也是同样的道理。
所以,哈希表仅适用于等值查询。
2.2 有序数组
有序数组顾名思义是一个按照 key 的顺序进行排列的数组,它进行等值查询的时间复杂度使用二分查询可以达到O(logN),这与哈希表相比逊色不少。
但是通过有序数组进行范围查询的效率较高:首先通过二分查询找到最小值(或最大值),然后反向遍历,直到另一个边界。
至于排序,有序数组本来就是有序的,天然已经排好序了,当然排序字段不是索引字段就另说了。
但是有序数组有一个缺点,由于数组元素是连续且有序的,如果此时插入新的数据行,为了维持有序数组的有序性,需要将比此元素 key 大的元素都往后移动一个单位,给他腾出一个地方插入。而这种维护索引的方式的代价是很大的。
所以,有序数组适合存储衣服初始化过后就不再更新的数据。
2.3 搜索树
了解过数据结构的人应该会知道,搜索树是一个查询时间复杂度为O(logN),更新的时间复杂度也是O(logN)的数据结构。所以搜索树相较于哈希表和有序数组来说兼顾查询与更新两方面。也正是由于这个原因,在 MySQL 中最常用的数据模型就是搜索树。
而考虑到索引是存放在磁盘中的,如果搜索树是一棵二叉树,那么它的子节点只能有左右两个,在数据比价多的情况下,这棵二叉树的树高可能会非常高,当 MySQL 进行查询的时候,可能由于树高导致磁盘I/O次数过多,查询效率变慢。
2.4 全文索引
除此之外,还有一种全文索引,它通过建立倒排索引,解决了判断字段是否包含的问题。
倒排索引是用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射,通过倒排索引可以根据单词快速获取包含这个单词的文档列表。
当通过关键词进行检索的时候,全文索引就会派上用场。
3. InnoDB 中的 BTree 索引
3.1 B+树
这是一棵比较简单的B+树。
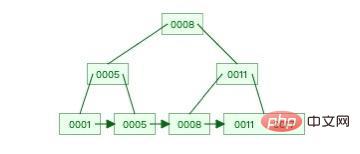
图片来源: Data Structure Visualizations
从上面这张示例图也可以看到,这棵B+树最下面的叶子节点存储了所有的元素,并且是按顺序存储的,而非叶子节点仅存储索引列的值。
3.2 图解 BTree 索引
在 InnoDB 中,基于 BTree 的索引模型的最为常用的,下面以一个实际的例子来图解 InnoDB 中 BTree 索引的结构。
CREATE TABLE `user` ( `id` int(11) NOT NULL, `name` varchar(36) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, INDEX `nameIndex`(`name`) USING BTREE ) ENGINE = InnoDB;-- 插入数据insert into user1(id,name,age) values (1,'one',21),(2,'two',22),(3,'three',23),(4,'four',24),(5,'five',25);复制代码
在这张表中只有两个字段:主键 id 和 name 字段,同时建立了一个以 name 字段为索引列的 BTree 索引。
以主键 id 字段的为索引的索引,又叫主键索引,它的索引树结构是:索引树的非叶子阶段存放的都是主键 id 的值,叶子节点存放的值是该主键 id 对应的整个数据行,如下图所示:
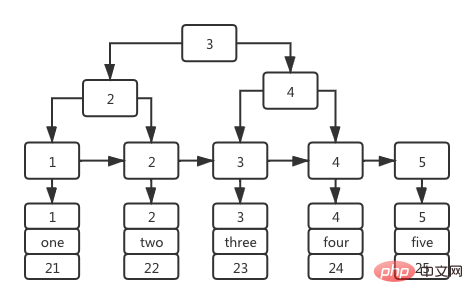
也正因为主键索引的叶子节点存储的是该主键 id 对应的整个数据行,主键索引又被称为聚簇索引。
而以 name 字段为列的索引树,非叶子节点存放的同样是索引列的值,而其叶子阶段存放的值是主键 id 的值,如下图所示。
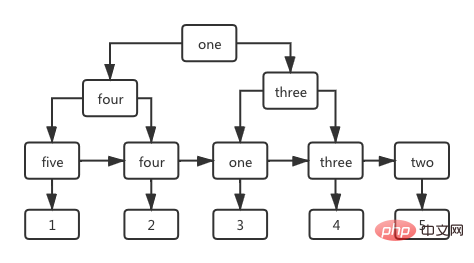
3.3 索引的执行流程
首先来看下面这句 SQL,查询 user 表中 id=1 的数据行。
select * from user where id=1;复制代码
这句 SQL 的执行流程很简单,存储引擎会走主键 id 的索引树,当找到 id=1 时,就会把索引树上 id=1 的数据行返回(由于主键值是唯一的,所以找到命中目标就会停止搜索,直接返回结果集)。
3.3.1 回表
接下来再看使用普通索引进行查询的情况,它的情况与主键索引略有不同。
select * from user where name='one';复制代码
上面这句 SQL 查询语句的流程是这样的:首先存储引擎会搜索普通索引 name 列的索引树,当命中 name 等于 one 的记录后,存储引擎需要经过一个非常重要的步骤:回表。
由于普通索引的索引树子节点存放的是主键值,当查询语句需要查询除主键 id 及索引列之外的其他字段时,需要根据主键 id 的值再回到主键索引树中进行查询,得到主键 id 对应的整个数据行,然后从中获取客户端需要的字段后,才将这一行加入结果集。
随后存储引擎会继续搜索索引树,直到遇到第一个不满足 name='one' 的记录才会停止搜索,最后将所有命中的记录返回客户端。
我们把根据从普通索引查询到的主键 id 值,再在主键索引中查询整个数据行的过程称之为回表。
当数据量十分庞大时,回表是一个十分耗时的过程,所以我们应该尽量避免回表发生,这就引出了下一个问题:使用覆盖索引避免回表。
3.3.2 覆盖索引
不知道你有没有注意到,在上一个回表的问题中有这样一句描述:“当查询语句需要查询除主键 id 及索引列之外的其他字段时...”,在这种场景下需要通过回表来获取其他的查询字段。也就是说,如果查询语句需要查询的字段仅有主键 id 和索引列的字段时,是不是就不需要回表了?
下面来分析一波这个过程,首先建立一个联合索引。
alter table user add index name_age ('name','age');复制代码
那么这棵索引树的结构图应该是下面这样:

联合索引索引树的子节点顺序是按照声明索引时的字段来排序的,类似于 order by name, age ,而它索引对应的值与普通索引一样是主键值。
select name,age from user where name='one';复制代码
上面这条 SQL 是查询所有 name='one' 记录的 name 和 age 字段,理想的执行计划应该是搜索刚刚建立的联合索引。
与普通索引一样,存储引擎会搜索联合索引,由于联合索引的顺序是先按照 name 再按照 age 进行排序的,所以当找到第一个 name 不是 one 的索引时,才会停止搜索。
而由于 SQL 语句查询的只是 name 和 age 字段,恰好存储引擎命中查询条件时得到的数据正是 name, age 和 id 字段,已经包含了客户端需要的字段了,所以就不需要再回表了。
我们把只需要在一棵索引树上就可以得到查询语句所需要的所有字段的索引成为覆盖索引,覆盖索引无须进行回表操作,速度会更快一些,所以我们在进行 SQL 优化时可以考虑使用覆盖索引来优化。
4. 最左前缀原则
上面所举的例子都是使用索引的情况,事实上在项目中复杂的查询语句中,也可能存在不使用索引的情况。首先我们要知道,MySQL 在执行 SQL 语句的时候一张表只会选择一棵索引树进行搜索,所以一般在建立索引时需要尽可能覆盖所有的查询条件,建立联合索引。
而对于联合索引,MySQL 会遵循最左前缀原则:查询条件与联合索引的最左列或最左连续多列一致,那么就可以使用该索引。
为了详细说明最左前缀原则,同时说明最左前缀原则的一些特殊情况。
5. 索引失效场景
即便我们根据最左前缀的原则创建了联合索引,还是会有一些特殊的场景会导致索引失效,下面举例说明。
假设有一张 table 表,它有一个联合索引,索引列为 a,b,c 这三个字段,这三个字段的长度均为10。
CREATE TABLE `demo` ( `a` varchar(1) DEFAULT NULL, `b` varchar(1) DEFAULT NULL, `c` varchar(1) DEFAULT NULL, INDEX `abc_index`(`a`, `b`, `c`) USING BTREE ) ENGINE = InnoDB;复制代码
5.1 全字段匹配
第一种情况是查询条件与索引字段全部一致,并且用的是等值查询,如:
select * from demo where a='1' and b='1' and c='1';select * from demo where c='1' and a='1' and b='1';复制代码
输出上述两条 SQL 的执行计划来看它们使用索引的情况。
mysql> explain select * from demo where a='1' and b='1' and c='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 18 | const,const,const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+1 row in set, 1 warning (0.00 sec) mysql> explain select * from demo where c='1' and a='1' and b='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 18 | const,const,const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+1 row in set, 1 warning (0.00 sec)复制代码
第一条 SQL 很显然能够用到联合索引。
从执行计划中可以看到,第二条 SQL 与第一条 SQL 使用的索引以及索引长度是一致的,都是使用 abc_index 索引,索引长度为 18 个字节。
按理说查询条件与索引的顺序不一致,应该不会用到索引,但是由于 MySQL 有优化器存在,它会把第二条 SQL 优化成第一条 SQL 的样子,所以第二条 SQL 也使用到了联合索引 abc_index。
综上所述,全字段匹配且为等值查询的情况下,查询条件的顺序不一致也能使用到联合索引。
5.2 部分字段匹配
第二种情况是查询条件与索引字段部分保持一致,这里就需要遵循最左前缀的原则,如:
select * from demo where a='1' and b='1';select * from demo where a='1' and c='1';复制代码
上述的两条查询语句分别对应三个索引字段只用到两个字段的情况,它们的执行计划是:
mysql> explain select * from demo where a='1' and b='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 12 | const,const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-------------+1 row in set, 1 warning (0.00 sec) mysql> explain select * from demo where a='1' and c='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+--------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+--------------------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 6 | const | 1 | 100.00 | Using where; Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+--------------------------+1 row in set, 1 warning (0.00 sec)复制代码
从它们的执行计划可以看到,这两条查询语句都使用到了 abc_index 索引,不同的是,它们使用到索引的长度分别是:12、6 字节。
在这里需要额外提一下索引长度的计算方式,对于本例中声明为 varchar(1) 类型的 a 字段,它的索引长度= 1 * (3) + 1 + 2 = 6。
- 第一个数字 1 是该字段声明时的长度。
- 第二个数字 3 是该字段字符类型的长度:utf8=3, gbk=2, latin1=1。
- 第三个数字 1 是该字段的默认类型,若默认允许 NULL,第三个数字是 1,因为 NULL 需要一个字节的额外空间;若默认不允许 NULL,这里应该是0。
- 第四个数字 2 是 varchar 类型的变长字段需要附加的字节。
所以这两条查询语句使用索引的情况是:
- 使用联合索引,索引长度为 12 字节,使用到的索引字段是 a,b 字段;
- 使用联合索引,索引长度为 6 字节,使用到的索引字段是 a 字段;
由此可见:最左前缀原则要求,查询条件必须是从索引最左列开始的连续几列。
5.3 范围查询
第三种情况是查询条件用的是范围查询(<,>,!=,<=,>=,between,like)时,如:
select * from demo where a='1' and b!='1' and c='1';复制代码
这两条查询语句的执行计划是:
mysql> EXPLAIN select * from demo where a='1' and b!='1' and c='1'; +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+--------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+--------------------------+| 1 | SIMPLE | demo | NULL | range | abc_index | abc_index | 12 | NULL | 2 | 10.00 | Using where; Using index | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+--------------------------+1 row in set, 1 warning (0.00 sec)复制代码
从执行计划可以看到,第一条 SQL 使用了联合索引,且索引长度为 12 字节,即用到了 a,b 两个字段;第二条 SQL 也使用了联合索引,索引长度为 6 字节,仅使用了联合索引中的 a 字段。
综上所述,在全字段匹配且为范围查询的情况下,也能使用联合索引,但只能使用到联合索引中第一个出现范围查询条件的字段。
需要注意的是:
- like 必须要求是左模糊匹配才能用到索引,因为字符类型字段的索引树也是有序的。
- between 并不一定是范围查询,它相当于使用 in 多值精确匹配,所以 between 并不会因为是范围查询就让联合索引后面的索引列失效。
5.4 查询条件为函数或表达式
第四种情况是查询条件中带有函数或特殊表达式的,比如:
select * from demo where id + 1 = 2;select * from demo where concat(a, '1') = '11';复制代码
可能由于数据的原因(空表),我输出的执行计划是使用了联合索引的,但是事实上,在查询条件中,等式不等式左侧的字段包含表达式或函数时,该字段是不会用到索引的。
至于原因,是因为使用函数或表达式的情况下,索引字段本身的值已不具备有序性。
5.5 其他索引失效的场景
- 查询影响行数大于全表的25%
- 查询条件使用 <>(!=), not in, is not null
- in 查询条件中值数据类型不一致,MySQL 会将所有值转化为与索引列一致的数据类型,从而无法使用索引
6. 索引下推
上文中已经罗列了联合索引的实际结构、最左前缀原则以及索引失效的场景,这里再说一下索引下推这个重要的优化规则。
select * from demo where a > '1' and b='1'; mysql> explain select * from demo where a > '1' and b='1'; +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+| 1 | SIMPLE | demo | NULL | range | abc_index | abc_index | 6 | NULL | 1 | 10.00 | Using index condition | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+1 row in set, 1 warning (0.00 sec)复制代码
上面这条查询语句,从它的执行计划也可以看出,它使用的索引长度为 6 个字节,只用到了第一个字段。
所以 MySQL 在查询过程中,只会对第一个字段 a 进行 a > '1' 的条件判断,当满足条件后,存储引擎并不会进行 b=1 的判断, 而是通过回表拿到整个数据行之后再进行判断。
这好像很蠢,就算索引只用到了第一个字段,但明明索引树中就有 b 字段的数据,为什么不直接进行判断呢?
听上去好像是个 bug,其实在未使用索引下推之前整个查询逻辑是:由存储引擎检索索引树,就算索引树中存在 b 字段的值,但由于这条查询语句的执行计划使用了联合索引但没有用到 b 字段,所以也无法进行 b 字段的条件判断,当存储引擎拿到满足条件(a>'1')的数据后,再由 MySQL 服务器进行条件判断。
在 MySQL5.6 版本中对这样的情况进行优化,引入索引下推技术:在搜索索引树的过程中,就算没能用到联合索引的其他字段,也能优先对查询条件中包含且索引也包含的字段进行判断,减少回表次数,提高查询效率。
在使用索引下推优化之后,b 字段作为联合索引列,又存在于查询条件中,同时又没有在搜索索引树时被使用到,MySQL 服务器会把查询条件中关于 b 字段的部分也传给存储引擎,存储引擎会在搜索索引树命中数据之后再进行 b 字段查询条件的判断,满足的才会加入结果集。
Ps: 执行计划中 Extra 字段的值包含 Using index condition 就代表使用到了索引下推。
7. 温故知新
- 索引分类?聚簇索引结构?非聚簇索引结构?
- 常用的实现索引的数据模型?
- B+树索引的执行流程?
- 什么是回表?如何优化?
- 什么是覆盖索引?
- 什么是最左前缀原则?
- 索引在哪些情况下可能会失效?
- 什么是索引下推?
更多相关免费学习推荐:mysql教程(视频)
Atas ialah kandungan terperinci 我所理解的MySQL之二:索引. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!