




相关学习推荐:java基础教程
初学Java时我们已经知道Java中可以分为两大数据类型,分别为基本数据类型和引用数据类型。而在这两大数据类型中有一个特殊的数据类型String,String属于引用数据类型,但又有区别于其它的引用数据类型。可以说它是数据类型中的一朵奇葩。那么,本篇文章我们就来深入的认识一下Java中的String字符串。
一、从String字符串的内存分配说起
上一篇文章《温故知新--你不知道的JVM内存分配》详细的分析了JVM的内存模型。在常量池部分我们了解了三种常量池,分别为:字符串常量池、Class文件常量池以及运行时常量池。而字符串的内存分配则和字符串常量池有着莫大的关系。
我们知道,实例化一个字符串可以通过两种方法来实现,第一种最常用的是通过字面量赋值的方式,另一种是通过构造方法传参的方式。代码如下:
String str1="abc";
String str2=new String("abc");复制代码这两种方式在内存分配上有什么不同呢? 相信大家在初学Java的时候老师都有给我们讲解过:
1.通过字面量赋值的方式创建String,只会在字符串常量池中生成一个String对象。 2.通过构造方法传入String参数的方式会在堆内存和字符串常量池中各生成一个String对象,并将堆内存上String的引用放入栈。
这样的回答正确吗?至少在现在看来并不完全正确,因为它完全取决于使用的Java版本。上一篇文章《温故知新--你不知道的JVM内存分配》谈到HotSpot虚拟机在不同的JDK上对于字符串常量池的实现是不同的,摘录如下:
在JDK7以前,字符串常量池在方法区(永久代)中,此时常量池中存放的是字符串对象。而在JDK7中,字符串常量池从方法区迁移到了堆内存,同时将字符串对象存到了Java堆,字符串常量池中只是存入了字符串对象的引用。
这句话应该怎么理解呢?我们以String str1=new String("abc")为例来分析:
1.JDK6中的内存分配
先来分析一下JDK6的内存分配情况,如下图所示:
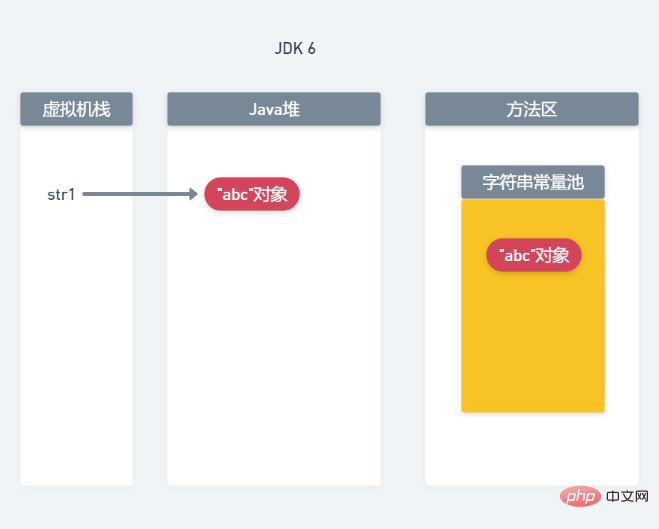
当调用new String("abc")后,会在Java堆与常量池中各生成一个“abc”对象。同时,将str1指向堆中的“abc”对象。
2.JDK7中的内存分配
而在JDK7及以后版本中,由于字符串常量池被移到了堆内存,所以内存分配方式也有所不同,如下图所示:
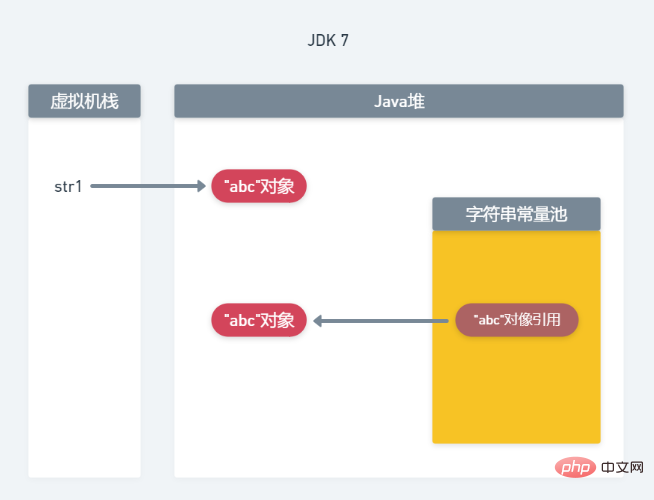
当调用了new String("abc")后,会在堆内存中创建两个“abc"对象,str1指向其中一个”abc"对象,而常量池中则会生成一个“abc"对象的引用,并指向另一个”abc"对象。
至于Java中为什么要这么设计,我们在上篇文章中也已经解释了: 因为String是Java中使用最频繁的一种数据类型,为了节省程序内存提高程序性能,Java的设计者们开辟了一块字符串常量池区域,这块区域是是所有类共享的,每个虚拟机只有一个字符串常量池。因此,在使用字面量方式赋值的时候,如果字符串常量池中已经有了该字符串,则不会在堆内存中重新创建对象,而是直接将其指向了字符串常量池中的对象。
二、String的intern()方法
在了解了String的内存分配之后,我们需要再来认识一下String中一个很重要的方法:String.intern()。
很多读者可能对于这一方法并不是太了解,但并不代表他不重要。我们先来看一下intern()方法的源码:
/**
* Returns a canonical representation for the string object.
* <p>
* A pool of strings, initially empty, is maintained privately by the
* class {@code String}.
* <p>
* When the intern method is invoked, if the pool already contains a
* string equal to this {@code String} object as determined by
* the {@link #equals(Object)} method, then the string from the pool is
* returned. Otherwise, this {@code String} object is added to the
* pool and a reference to this {@code String} object is returned.
* <p>
* It follows that for any two strings {@code s} and {@code t},
* {@code s.intern() == t.intern()} is {@code true}
* if and only if {@code s.equals(t)} is {@code true}.
* <p>
* All literal strings and string-valued constant expressions are
* interned. String literals are defined in section 3.10.5 of the
* <cite>The Java™ Language Specification</cite>.
*
* @return a string that has the same contents as this string, but is
* guaranteed to be from a pool of unique strings.
*/
public native String intern();复制代码emmmmm....居然是一个native方法,不过没关系,即使看不到源码我们也能从其注释中得到一些信息:当调用intern方法的时候,如果字符串常量池中已经包含了一个等于该String对象的字符串,则直接返回字符串常量池中该字符串的引用。否则,会将该字符串对象包含的字符串添加到常量池,并返回此对象的引用。
1.一个关于intern()的简单例子
了解了intern方法的用途之后,来看一个简单的列子:
public class Test { public static void main(String[] args) {
String str1 = "hello world";
String str2 = new String("hello world");
String str3=str2.intern();
System.out.println("str1 == str2:"+(str1 == str2));
System.out.println("str1 == str3:"+(str1 == str3));
}
}复制代码上面的一段代码会输出什么?编译运行之后如下:
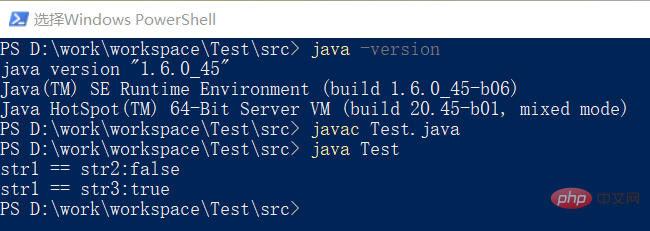
如果理解了intern方法就很容易解释这个结果了,从上面截图中可以看到,我们的运行环境是JDK8。
String str1 = "hello world"; 这行代码会首先在Java堆中创建一个对象,并将该对象的引用放入字符串常量池中,str1指向常量池中的引用。
String str2 = new String("hello world");这行代码会通过new来实例化一个String对象,并将该对象的引用赋值给str2,然后检测字符串常量池中是否已经有了与“hello world”相等的对象,如果没有,则会在堆内存中再生成一个值为"hello world"的对象,并将其引用放入到字符串常量池中,否则,不会再去创建。这里,第一行代码其实已经在字符串常量池中保存了“hello world”字符串对象的引用,因此,第二行代码就不会再次向常量池中添加“hello world"的引用。
String str3=str2.intern(); 这行代码会首先去检测字符串常量池中是否已经包含了”hello world"的String对象,如果有则直接返回其引用。而在这里,str2.intern()其实刚好返回了第一行代码中生成的“hello world"对象。
因此【System.out.println("str1 == str3:"+(str1 == str3));】这行代码会输出true.
如果切到JDK6,其打印结果与上一致,至于原因读者可以自行分析。
2.改造例子,再看intern
上一节中我们通过一个例子认识了intern()方法的作用,接下来,我们对上述例子做一些修改:
public class Test {
public static void main(String[] args) {
String str1=new String("he")+new String("llo");
String str2=str1.intern();
String str3="hello";
System.out.println("str1 == str2:"+(str1 == str2));
System.out.println("str2 == str3:"+(str2 == str3));
}
}复制代码先别急着看下方答案,思考一下在JDK7(或JDK7之后)及JDK6上会输出什么结果?
1).JDK8的运行结果分析
我们先来看下我们先来看下JDK8的运行结果:

通过运行程序发现输出的两个结果都是true,这是为什么呢?我们通过一个图来分析:
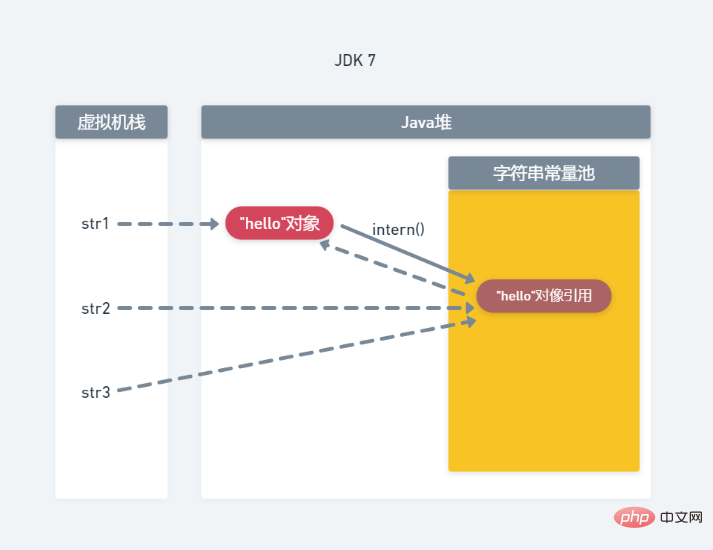
String str1=new String("he")+new String("llo"); 这行代码中new String("he")和new String("llo")会在堆上生成四个对象,因为与本例无关,所以图上没有画出,new String("he")+new String("llo")通过”+“号拼接后最终会生成一个"hello"对象并赋值给str1。
String str2=str1.intern(); 这行代码会首先检测字符串常量池,发现此时还没有存在与”hello"相等的字符串对象的引用,而在检测堆内存时发现堆中已经有了“hello"对象,遂将堆中的”hello"对象的应用放入字符串常量池中。
String str3="hello"; 这行代码发现字符串常量池中已经存在了“hello"对象的引用,因此将str3指向了字符串常量池中的引用。
此时,我们发现str1、str2、str3指向了堆中的同一个”hello"对象,因此,就有了上边两个均为true的输出结果。
2).JDK6的运行结果分析
我们将运行环境切换到JDK6,来看下其输出结果:
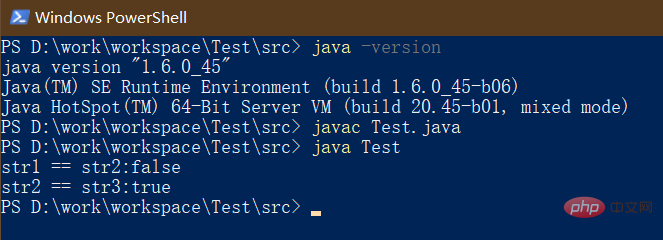
有点意思!相同的代码在不同的JDK版本上输出结果竟然不相等。这是怎么回事呢?我们还通过一张图来分析:
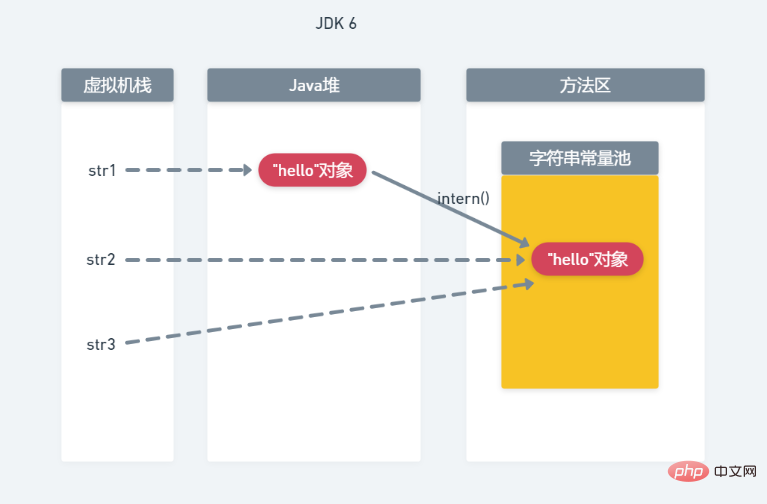
String str1=new String("he")+new String("llo"); 这行代码会通过new String("he")和new String("llo")会分别在Java堆与字符串常量池中各生成两个String对象,由于与本例无关,所以并没有在图中画出。而new String("he")+new String("llo")通过“+”号拼接后最终会在Java堆上生成一个"hello"对象,并将其赋值给了str1。
String str2=str1.intern(); 这行代码检测到字符串常量池中还没有“hello"对象,因此将堆中的”hello“对象复制到了字符串常量池,并将其赋值给str2。
String str3="hello"; 这行代码检测到字符串常量池中已经有了”hello“对象,因此直接将str3指向了字符串常量池中的”hello“对象。 此时str1指向的是Java堆中的”hello“对象,而str2和str3均指向了字符串常量池中的对象。因此,有了上面的输出结果。
通过这两个例子,相信大家因该对String的intern()方法有了较深的认识。那么intern()方法具体在开发中有什么用呢?推荐大家可以看下美团技术团队的一篇文章《深入解析String#intern》中举的两个例子。限于篇幅,本文不再举例分析。
三、String类的结构及特性分析
前两节我们认识了String的内存分配以及它的intern()方法,这两节内容其实都是对String内存的分析。到目前为止,我们还并未认识String类的结构以及它的一些特性。那么本节内容我们就此来分析。先通过一段代码来大致了解一下String类的结构(代码取自jdk8):
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence { /** The value is used for character storage. */
private final char value[]; /** Cache the hash code for the string */
private int hash; // Default to 0
// ...}复制代码可以看到String类实现了Serializable接口、Comparable接口以及CharSequence接口,意味着它可以被序列化,同时方便我们排序。另外,String类还被声明为了final类型,这意味着String类是不能被继承的。而在其内部维护了一个char数组,说明String是通过char数组来实现的,同时我们注意到这个char数组也被声明为了final,这也是我们常说的String是不可变的原因。
1.不同JDK版本之间String的差异
Java的设计团队一直在对String类进行优化,这就导致了不同jdk版本上String类的实现有些许差异,只是我们使用上并无感知。下图列出了jdk6-jdk9中String源码的一些变化。
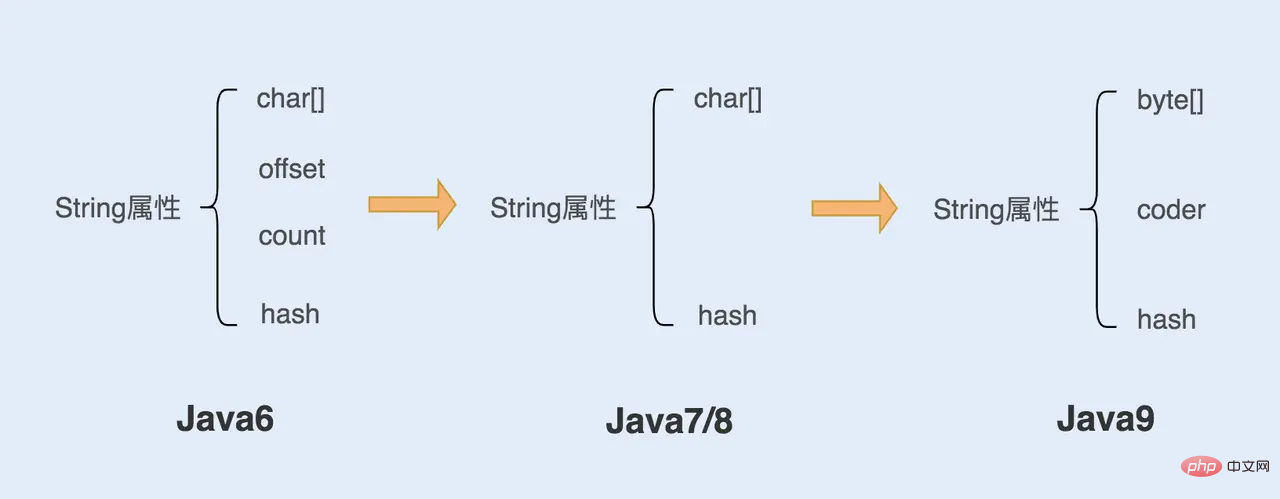
可以看到在Java6之前String中维护了一个char 数组、一个偏移量 offset、一个字符数量 count以及一个哈希值 hash。 String对象是通过 offset 和 count 两个属性来定位 char[] 数组,获取字符串。这么做可以高效、快速地共享数组对象,同时节省内存空间,但这种方式很有可能会导致内存泄漏。
在Java7和Java8的版本中移除了 offset 和 count 两个变量了。这样的好处是String对象占用的内存稍微少了些,同时 String.substring 方法也不再共享 char[],从而解决了使用该方法可能导致的内存泄漏问题。
从Java9开始,String中的char数组被byte[]数组所替代。我们知道一个char类型占用两个字节,而byte占用一个字节。因此在存储单字节的String时,使用char数组会比byte数组少一个字节,但本质上并无任何差别。 另外,注意到在Java9的版本中多了一个coder,它是编码格式的标识,在计算字符串长度或者调用 indexOf() 函数时,需要根据这个字段,判断如何计算字符串长度。coder 属性默认有 0 和 1 两个值, 0 代表Latin-1(单字节编码),1 代表 UTF-16 编码。如果 String判断字符串只包含了 Latin-1,则 coder 属性值为 0 ,反之则为 1。
2.String字符串的裁剪、拼接等操作分析
在本节内容的开头我们已经知道了字符串的不可变性。那么为什么我们还可以使用String的substring方法进行裁剪,甚至可以直接使用”+“连接符进行字符串的拼接呢?
(1)String的substring实现
关于substring的实现,其实我们直接深入String的源码查看即可,源码如下:
public String substring(int beginIndex) { if (beginIndex < 0) { throw new StringIndexOutOfBoundsException(beginIndex);
} int subLen = value.length - beginIndex; if (subLen < 0) { throw new StringIndexOutOfBoundsException(subLen);
} return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
}复制代码从这段代码中可以看出,其实字符串的裁剪是通过实例化了一个新的String对象来实现的。所以,如果在项目中存在大量的字符串裁剪的代码应尽量避免使用String,而是使用性能更好的StringBuilder或StringBuffer来处理。
(2)String的字符串拼接实现
1)字符串拼接方案性能对比
关于字符串的拼接有很多实现方法,在这里我们举三个例子来进行一个性能对比,分别如下:
使用”+“操作符拼接字符串
public class Test { private static final int COUNT=50000; public static void main(String[] args) {
String str=""; for(int i=0;i<COUNT;i++) {
str=str+"abc";
}
}复制代码使用String的concat()方法拼接
public class Test { private static final int COUNT=50000; public static void main(String[] args) {
String str=""; for(int i=0;i<COUNT;i++) {
str=str+"abc";
}
}复制代码使用StringBuilder的append方法拼接
public class Test { private static final int COUNT=50000; public static void main(String[] args) {
StringBuilder str=new StringBuilder(); for(int i=0;i<COUNT;i++) {
str.append("abc");
}
}复制代码如上代码,通过三种方法分别进行了50000次字符串拼接,每种方法分别运行了20次。统计耗时,得到以下表格:
| 拼接方法 | 最小用时(ms) | 最大用时(ms) | 平均用时(ms) |
|---|---|---|---|
| "+"操作符 | 4868 | 5146 | 4924 |
| String的concat方法 | 2227 | 2456 | 2296 |
| StringBuilder的append方法 | 4 | 12 | 6.6 |
从以上数据中可以很直观的看到”+“操作符的性能是最差的,平均用时达到了4924ms。其次是String的concat方法,平均用时也在2296ms。而表现最为优秀的是StringBuilder的append方法,它的平均用时竟然只有6.6ms。这也是为什么在开发中不建议使用”+“操作符进行字符串拼接的原因。
2)三种字符串拼接方案原理分析
”+“操作符的实现原理由于”+“操作符是由JVM来完成的,我么无法直接看到代码实现。不过Java为我们提供了一个javap的工具,可以帮助我们将Class文件进行一个反汇编,通过汇编指令,大致可以看出”+“操作符的实现原理。
public class Test { private static final int COUNT=50000; public static void main(String[] args) { for(int i=0;i<COUNT;i++) {
str=str+"abc";
}
}复制代码把上边这段代码编译后,执行javap,得到如下结果:
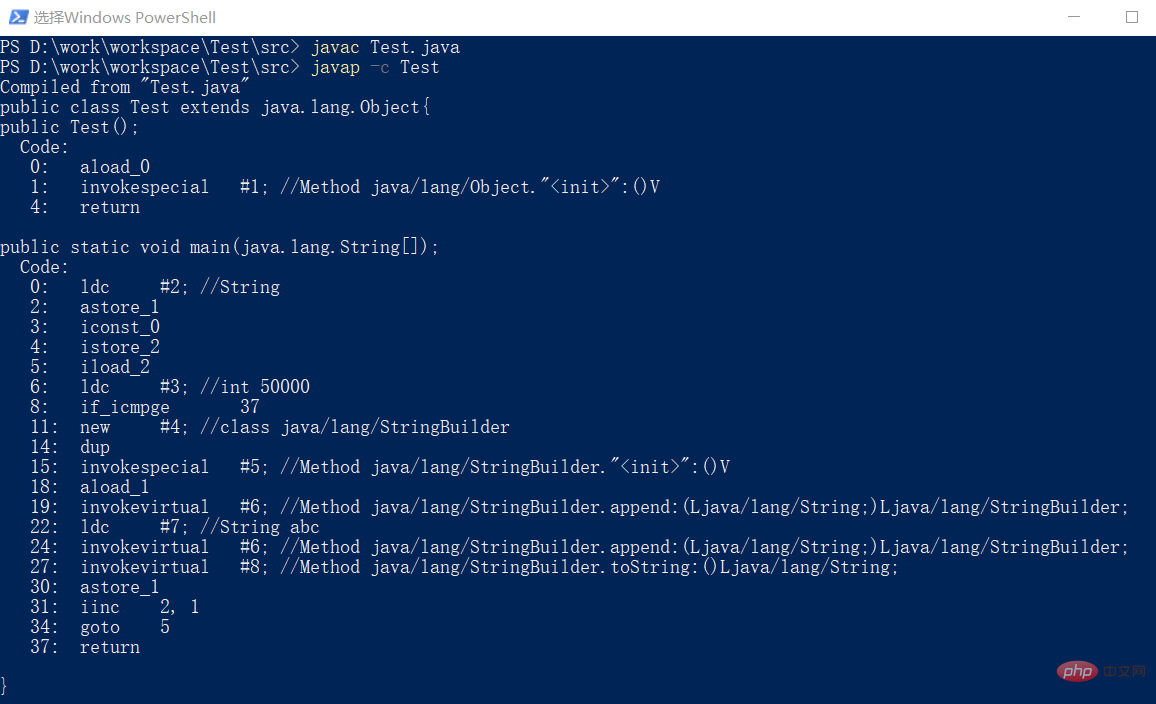
注意图中的”11:“行指令处实例化了一个StringBuilder,在"19:"行处调用了StringBuilder的append方法,并在第”27:"行处调用了String的toString()方法。可见,JVM在进行”+“字符串拼接时也是用了StringBuilder来实现的,但为什么与直接使用StringBuilder的差距那么大呢?其实,只要我们将上边代码转换成虚拟机优化后的代码一看便知:
public class Test { private static final int COUNT=50000; public static void main(String[] args) {
String str=""; for(int i=0;i<COUNT;i++) {
str=new StringBuilder(str).append("abc").toString();
}
}复制代码可见,优化后的代码虽然也是用的StringBuilder,但是StringBuilder却是在循环中实例化的,这就意味着循环了50000次,创建了50000个StringBuilder对象,并且调用了50000次toString()方法。怪不得用了这么长时间!!!
String的concat方法的实现原理关于concat方法可以直接到String内部查看其源码,如下:
public String concat(String str) { int otherLen = str.length(); if (otherLen == 0) { return this;
} int len = value.length; char buf[] = Arrays.copyOf(value, len + otherLen);
str.getChars(buf, len); return new String(buf, true);
}复制代码可以看到,在concat方法中使用Arrays的copyOf进行了一次数组拷贝,接下来又通过getChars方法再次进行了数组拷贝,最后通过new实例化了String对象并返回。这也意味着每调用一次concat都会生成一个String对象,但相比”+“操作符却省去了toString方法。因此,其性能要比”+“操作符好上不少。
至于StringBuilder其实也没必要再去分析了,毕竟”+“操作符也是基于StringBuilder实现的,只不过拼接过程中”+“操作符创建了大量的对象。而StringBuilder拼接时仅仅创建了一个StringBuilder对象。
四、总结
本篇文章我们深入分析了String字符串的内存分配、intern()方法,以及String类的结构及特性。关于这块知识,网上的文章鱼龙混杂,甚至众说纷纭。笔者也是参考了大量的文章并结合自己的理解来做的分析。但是,避免不了的可能会出现理解偏差的问题,如果有,希望大家多多讨论给予指正。 同时,文章中多次提到StringBuilder,但限于文章篇幅,没能给出关于其详细分析。不过不用担心,我会在下一篇文章中再做探讨。 不管怎样,相信大家看完这篇文章后一定 对String有了更加深入的认识,尤其是了解String类的一些裁剪及拼接中可能造成的性能问题,在今后的开发中应该尽量避免。
Atas ialah kandungan terperinci 温故知新(1)深入认识Java中的字符串. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

mPDF
mPDF ialah perpustakaan PHP yang boleh menjana fail PDF daripada HTML yang dikodkan UTF-8. Pengarang asal, Ian Back, menulis mPDF untuk mengeluarkan fail PDF "dengan cepat" dari tapak webnya dan mengendalikan bahasa yang berbeza. Ia lebih perlahan dan menghasilkan fail yang lebih besar apabila menggunakan fon Unicode daripada skrip asal seperti HTML2FPDF, tetapi menyokong gaya CSS dsb. dan mempunyai banyak peningkatan. Menyokong hampir semua bahasa, termasuk RTL (Arab dan Ibrani) dan CJK (Cina, Jepun dan Korea). Menyokong elemen peringkat blok bersarang (seperti P, DIV),

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

SecLists
SecLists ialah rakan penguji keselamatan muktamad. Ia ialah koleksi pelbagai jenis senarai yang kerap digunakan semasa penilaian keselamatan, semuanya di satu tempat. SecLists membantu menjadikan ujian keselamatan lebih cekap dan produktif dengan menyediakan semua senarai yang mungkin diperlukan oleh penguji keselamatan dengan mudah. Jenis senarai termasuk nama pengguna, kata laluan, URL, muatan kabur, corak data sensitif, cangkerang web dan banyak lagi. Penguji hanya boleh menarik repositori ini ke mesin ujian baharu dan dia akan mempunyai akses kepada setiap jenis senarai yang dia perlukan.

