
Rumah >pangkalan data >tutorial mysql >MySQL的where查询的重新认识
MySQL的where查询的重新认识

- coldplay.xixike hadapan
- 2020-09-15 16:39:002666semak imbas


相关学习推荐:mysql教程
不能说不行
今天加班,业务的妹子过来找我们查数据,说数据查出来量不对。一看妹子的SQL是这样写的:
select distinct * from prvt_pub_stmt_vnwhere issue_time >= '2020-08-01'and issue_time <= '2020-08-01'and prs_dmtd_cde in ('p','n');复制代码
我分析来分析去,感觉没有问题呀,于是查了一下prs_dmtd_cde 字段的码值,发现不仅有大写的P还有小写的p,而妹子只查了小写的p,数据量却多了很多。
于是我就把妹子的SQL改了一下:
select distinct * from prvt_pub_stmt_vnwhere issue_time >= '2020-08-01'and issue_time <= '2020-08-01'and prs_dmtd_cde in ('p','n','P','N');复制代码
查出来的结果竟然是一样的。这就。。。
在妹子面前当然不能说不行啊,于是让妹子先回去再看看。
我这边飞快的上网查了查,发现竟然是MySQL 的编码格式和排序规则的问题。
知其所以然
我们MySQL数据库基本上用的都是 utf8 的编码格式,而 utf8 编码格式还存在各种排序规则。常用的如下:
utf8_bin:将字符串中的每一个字符以十六进制方式存储数据,区分大小写。
utf8_general_ci:不区分大小写,ci为case insensitive的缩写,即大小写不敏感。
再查一下默认的字符集设置:
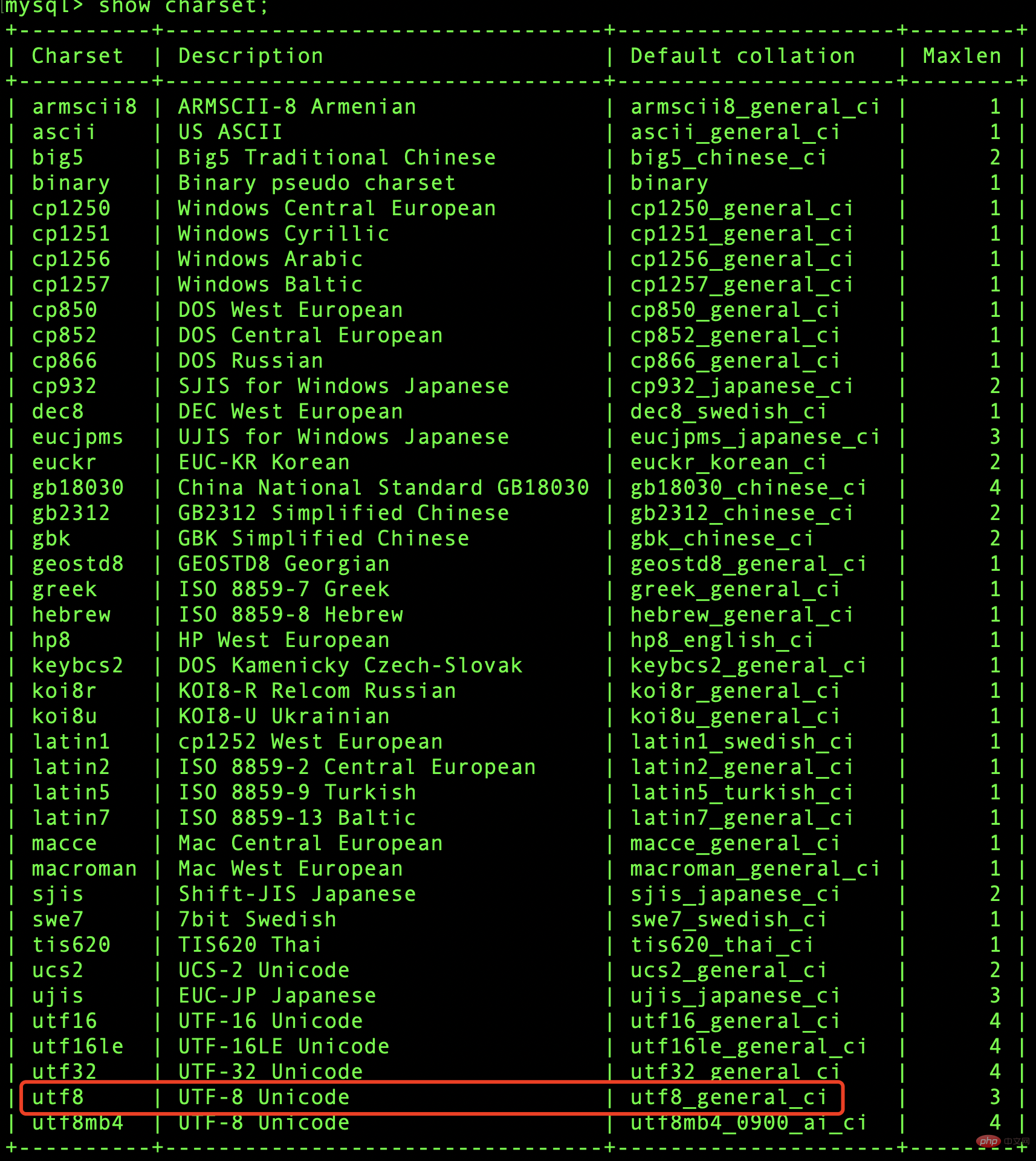
刚好 utf8 编码格式的默认排序规则就是:utf8_general_ci——即不区分大小写。
解决方案
问题原因找到了,那就对症下药好了。
解决方法自然就是直接修改字段的 collate 属性为 utf8_bin。
ALTER TABLE prvt_pub_stmt_vn CHANGE prs_dmtd_cde prs_dmtd_cde VARCHAR(255) CHARACTER SET utf8 COLLATE utf8_bin;复制代码
另外还有一种解决方法,就是不改变原有表结构,而是改SQL。在查询字段前加上 binary 关键字。
select distinct * from prvt_pub_stmt_vnwhere issue_time >= '2020-08-01'and issue_time <= '2020-08-01'and binary prs_dmtd_cde in ('p','n');复制代码
Mysql 默认查询是不分大小写的,可以在 SQL 语句中加入 binary 来区分大小写。
binary 不是函数,是类型转换运算符,它用来强制它后面的字符串为一个二进制字符串,可以理解为在字符串比较的时候区分大小写。
最后
问题解决了,当然是去告诉妹子这个问题多么多么深奥,我又是如何剖析原理最终解决的了。
看着妹子投来的崇拜目光,当然是很开心了。
最最重要的还是要记住这个问题,以后在遇到字段大小写敏感的业务,建表的时候要注意字符集和排序规则的选择,以避免今天这种事情的发生。
想了解更多编程学习,敬请关注php培训栏目!
Atas ialah kandungan terperinci MySQL的where查询的重新认识. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!