



本篇文章给大家带来的内容是关于超简单的Python爬虫之网易云音乐的下载,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
目标
偶然的一次机会听到了房东的猫的《云烟成雨》,瞬间迷上了这慵懒的嗓音和学生气的歌词,然后一直去循环听她们的歌。然后还特意去刷了动漫《我是江小白》,好期待第二季...
我多想在见你,哪怕匆匆一眼就别离...好了,不说废话了。这次的目标主要是根据网易云中歌手的ID,下载该歌手的热门音乐的歌词和音频,并保存到本地的文件夹中。
配置基础
Python
Selenium(配置方法参照:Selenium配置)
Chrome浏览器(其它的也可以,需要进行相应的修改)
分析
如果爬取过网易云的网站的小伙伴都应该知道网易云是有反爬取机制的,POST时需要对一些信息的参数进行加密函数的模拟。但是这里为了简便,小白也能理解。直接使用了Selenium来模拟登录,然后使用接口来直接下载音乐和歌词。
实验步骤:
根据歌手ID获取该歌手的热门歌曲列表,歌曲名称和链接,并保存到csv文件中;
读取csv文件,根据歌曲链接,提取歌曲ID,然后利用相应的接口,下载音乐和歌词;
将音乐和歌词保存到本地。

Python实现
该部分将对几个关键的函数进行介绍...
获取歌手信息
利用Selenium我们就不需要看对网页的请求了,直接可以从网页源码中提取相应的信息。查看歌手页面源码可以发现,我们需要的信息在iframe框架内,所以我们先需要切换到iframe:
browser.switch_to.frame('contentFrame')
继续往下看,发现我们需要的歌曲名字和链接是在id="hotsong-list"的标签中,然后每一行对应的是一个tr标签。所以先获取所有的tr内容,然后遍历单个tr。
data = browser.find_element_by_id("hotsong-list").find_elements_by_tag_name("tr")
注意:前一个是find_element,后一个是find_elements,后者返回一个列表。
接下来就是解析单个tr标签的内容,获取歌曲名字和链接,可以发现两者在class="txt"标签中,而且链接是href属性,名字是title属性,可以直接通过get_attribute()函数获取。

for i in range(len(data)):
content = data[i].find_element_by_class_name("txt")
href = content.find_element_by_tag_name("a").get_attribute("href")
title = content.find_element_by_tag_name("b").get_attribute("title")
song_info.append((title, href))
下载歌词
网易云有个获取歌词的接口,链接为:http://music.163.com/api/song...
链接中的数字就是歌曲的id,所以我们拥有歌曲id后,可以直接从该链接下载歌词,歌词文件是json格式,所以我们需要用到json包。

而且直接获取的歌词中,每行有一个时间轴,需要用正则表达式来剔除,完整代码如下:
def get_lyric(self): url = 'http://music.163.com/api/song/lyric?' + 'id=' + str(self.song_id) + '&lv=1&kv=1&tv=-1' r = requests.get(url) json_obj = r.text j = json.loads(json_obj) lyric = j['lrc']['lyric'] # 利用正则表达式去除时间轴 regex = re.compile(r'\[.*\]') final_lyric = re.sub(regex, '', lyric) return final_lyric
下载音频
网易云也提供了音频文件的接口,链接为:http://music.163.com/song/med...
链接中的数字为歌曲的id,可以直接根据歌曲的id来下载音频文件。完整代码如下:
def get_mp3(self):
url = 'http://music.163.com/song/media/outer/url?id=' + str(self.song_id)+'.mp3'
try:
print("正在下载:{0}".format(self.song_name))
urllib.request.urlretrieve(url, '{0}/{1}.mp3'.format(self.path, self.song_name))
print("Finish...")
except:
print("Fail...")
相关推荐:
Atas ialah kandungan terperinci 超简单的Python爬虫之网易云音乐的下载. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Laravel开发:如何使用Laravel Dusk和Selenium进行浏览器测试?Jun 14, 2023 pm 01:53 PM
Laravel开发:如何使用Laravel Dusk和Selenium进行浏览器测试?Jun 14, 2023 pm 01:53 PMLaravel开发:如何使用LaravelDusk和Selenium进行浏览器测试?随着Web应用程序变得越来越复杂,我们需要确保其各个部分都能正常运行。浏览器测试是一种常见的测试方法,用于确保应用在各种不同浏览器下的正确性和稳定性。在Laravel开发中,可以使用LaravelDusk和Selenium进行浏览器测试。本文将介绍如何使用这两个工具进行测
 如何使用Selenium进行Web自动化测试Aug 02, 2023 pm 07:43 PM
如何使用Selenium进行Web自动化测试Aug 02, 2023 pm 07:43 PM如何使用Selenium进行Web自动化测试概述:Web自动化测试是现代软件开发过程中至关重要的一环。Selenium是一个强大的自动化测试工具,可以模拟用户在Web浏览器中的操作,实现自动化的测试流程。本文将介绍如何使用Selenium进行Web自动化测试,并附带代码示例,帮助读者快速上手。环境准备在开始之前,需要安装Selenium库和Web浏览器驱动程
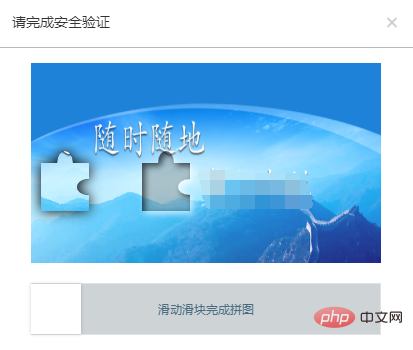 利用Java、Selenium和OpenCV结合的方法,解决自动化测试中滑块验证问题。May 08, 2023 pm 08:16 PM
利用Java、Selenium和OpenCV结合的方法,解决自动化测试中滑块验证问题。May 08, 2023 pm 08:16 PM1、滑块验证思路被测对象的滑块对象长这个样子。相对而言是比较简单的一种形式,需要将左侧的拼图通过下方的滑块进行拖动,嵌入到右侧空槽中,即完成验证。要自动化完成这个验证过程,关键点就在于确定滑块滑动的距离。根据上面的分析,验证的关键点在于确定滑块滑动的距离。但是看似简单的一个需求,完成起来却并不简单。如果使用自然逻辑来分析这个过程,可以拆解如下:1.定位到左侧拼图所在的位置,由于拼图的形状和大小固定,那么其实只需要定位其左边边界离背景图片的左侧距离。(实际在本例中,拼图的起始位置也是固定的,节省了
 在Scrapy爬虫中使用Selenium和PhantomJSJun 22, 2023 pm 06:03 PM
在Scrapy爬虫中使用Selenium和PhantomJSJun 22, 2023 pm 06:03 PM在Scrapy爬虫中使用Selenium和PhantomJSScrapy是Python下的一个优秀的网络爬虫框架,已经被广泛应用于各个领域中的数据采集和处理。在爬虫的实现中,有时候需要模拟浏览器操作去获取某些网站呈现的内容,这时候就需要用到Selenium和PhantomJS。Selenium是模拟人类对浏览器的操作,让我们可以自动化地进行Web应用程序测试
 高效率爬取网页数据:PHP和Selenium的结合使用Jun 15, 2023 pm 08:36 PM
高效率爬取网页数据:PHP和Selenium的结合使用Jun 15, 2023 pm 08:36 PM随着互联网技术的飞速发展,Web应用程序越来越多地应用于我们的日常工作和生活中。而在Web应用程序开发过程中,爬取网页数据是一项非常重要的任务。虽然市面上有很多的Web抓取工具,但是这些工具的效率都不是很高。为了提高网页数据爬取的效率,我们可以利用PHP和Selenium的结合使用。首先,我们需要了解一下PHP和Selenium分别是什么。PHP是一种强大的
 pycharm如何安装seleniumDec 08, 2023 pm 02:32 PM
pycharm如何安装seleniumDec 08, 2023 pm 02:32 PMpycharm安装selenium步骤:1、打开PyCharm;2、在菜单栏中选择依次选择 "File"、"Settings"、"Project: [项目名称]";3、选择 Project Interpreter;4、点击选项卡右侧的"+";5、在弹出的窗口搜索selenium;6、找到selenium点击旁边的"Install"按钮;7、等待安装完成;8、关闭设置对话框即可。
 Python中如何使用Selenium爬取网页数据May 09, 2023 am 11:05 AM
Python中如何使用Selenium爬取网页数据May 09, 2023 am 11:05 AM一.什么是Selenium网络爬虫是Python编程中一个非常有用的技巧,它可以让您自动获取网页上的数据。Selenium是一个自动化测试工具,它可以模拟用户在浏览器中的操作,比如点击按钮、填写表单等。与常用的BeautifulSoup、requests等爬虫库不同,Selenium可以处理JavaScript动态加载的内容,因此对于那些需要模拟用户交互才能获取的数据,Selenium是一个非常合适的选择。二.安装Selenium要使用Selenium,首先需要安装它。您可以使用pip命令来安装
 从零开始:如何使用PHP和Selenium构建网络数据爬虫Jun 15, 2023 pm 12:34 PM
从零开始:如何使用PHP和Selenium构建网络数据爬虫Jun 15, 2023 pm 12:34 PM随着互联网的发展,网络数据爬取越来越成为人们关注的焦点。网络数据爬虫可以从互联网中采集大量有用的数据,为企业、学术研究和个人分析提供支持。本文将介绍使用PHP和Selenium构建网络数据爬虫的方法和步骤。一、什么是网络数据爬虫?网络数据爬虫是指自动化程序,在互联网中采集指定网站的数据。网络数据爬虫使用不同的技术和工具来实现,其中最常用的技术是使用编程语言和


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

MantisBT
Mantis ialah alat pengesan kecacatan berasaskan web yang mudah digunakan yang direka untuk membantu dalam pengesanan kecacatan produk. Ia memerlukan PHP, MySQL dan pelayan web. Lihat perkhidmatan demo dan pengehosan kami.

SecLists
SecLists ialah rakan penguji keselamatan muktamad. Ia ialah koleksi pelbagai jenis senarai yang kerap digunakan semasa penilaian keselamatan, semuanya di satu tempat. SecLists membantu menjadikan ujian keselamatan lebih cekap dan produktif dengan menyediakan semua senarai yang mungkin diperlukan oleh penguji keselamatan dengan mudah. Jenis senarai termasuk nama pengguna, kata laluan, URL, muatan kabur, corak data sensitif, cangkerang web dan banyak lagi. Penguji hanya boleh menarik repositori ini ke mesin ujian baharu dan dia akan mempunyai akses kepada setiap jenis senarai yang dia perlukan.

PhpStorm versi Mac
Alat pembangunan bersepadu PHP profesional terkini (2018.2.1).

Dreamweaver CS6
Alat pembangunan web visual

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

