



本篇文章给大家带来的内容是关于node如何爬取网页中的图片(附代码),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
目录
安装node,并下载依赖
搭建服务
请求我们要爬取的页面,返回json
安装node
我们开始安装node,可以去node官网下载https://nodejs.org/zh-cn/,下载完成后运行node使用,
node -v
安装成功后会出现你所安装的版本号。
接下来我们使用node, 打印出hello world,新建一个名为index.js文件输入
console.log('hello world')
运行这个文件
node index.js
就会在控制面板上输出hello world
搭建服务器
新建一个·名为node的文件夹。
首先你需要下载express依赖
npm install express
再新建一个名为demo.js的文件 目录结构如图:

在demo.js引入下载的express
const express = require('express');
const app = express();
app.get('/index', function(req, res) {
res.end('111')
})
var server = app.listen(8081, function() {
var host = server.address().address
var port = server.address().port
console.log("应用实例,访问地址为 http://%s:%s", host, port)
})运行node demo.js简单的服务就搭起来了,如图: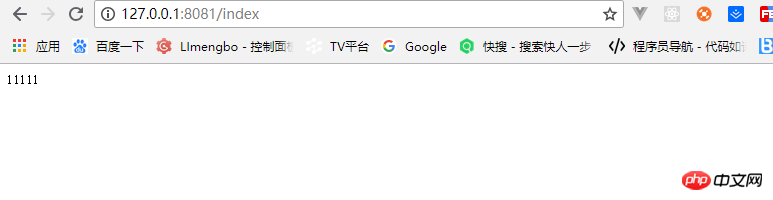
请求我们要爬取的页面
请求我们要爬取的页面
npm install superagent npm install superagent-charset npm install cheerio
superagent 是用来发起请求的,是一个轻量的,渐进式的ajax api,可读性好,学习曲线低,内部依赖nodejs原生的请求api,适用于nodejs环境下.,也可以使用http发起请求
superagent-charset防止爬取下来的数据乱码,更改字符格式
cheerio为服务器特别定制的,快速、灵活、实施的jQuery核心实现.。 安装完依赖就可以引入了
var superagent = require('superagent'); var charset = require('superagent-charset'); charset(superagent); const cheerio = require('cheerio');
引入之后就请求我们的地址,https://www.qqtn.com/tx/weixintx_1.html,如图:
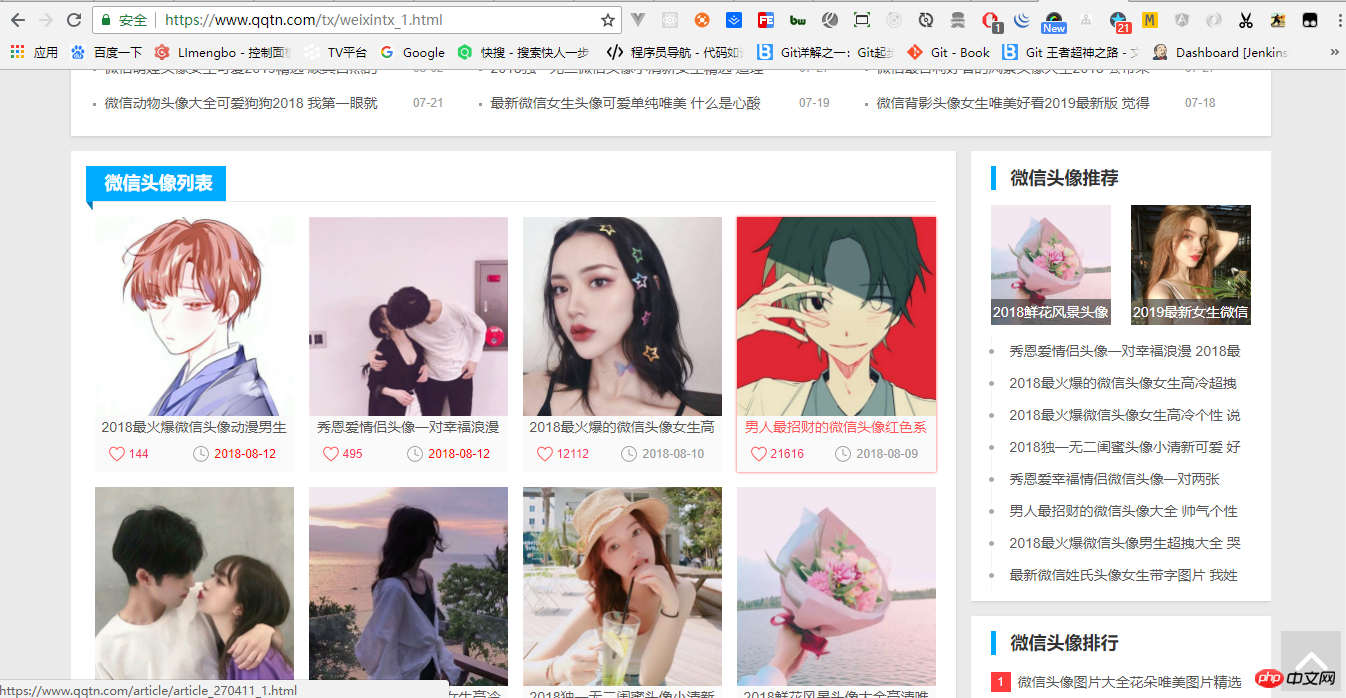
声明地址变量:
const baseUrl = 'https://www.qqtn.com/'
这些设置完之后就是发请求了,接下来请看完整代码demo.js
var superagent = require('superagent');
var charset = require('superagent-charset');
charset(superagent);
var express = require('express');
var baseUrl = 'https://www.qqtn.com/'; //输入任何网址都可以
const cheerio = require('cheerio');
var app = express();
app.get('/index', function(req, res) {
//设置请求头
res.header("Access-Control-Allow-Origin", "*");
res.header('Access-Control-Allow-Methods', 'PUT, GET, POST, DELETE, OPTIONS');
res.header("Access-Control-Allow-Headers", "X-Requested-With");
res.header('Access-Control-Allow-Headers', 'Content-Type');
//类型
var type = req.query.type;
//页码
var page = req.query.page;
type = type || 'weixin';
page = page || '1';
var route = `tx/${type}tx_${page}.html`
//网页页面信息是gb2312,所以chaeset应该为.charset('gb2312'),一般网页则为utf-8,可以直接使用.charset('utf-8')
superagent.get(baseUrl + route)
.charset('gb2312')
.end(function(err, sres) {
var items = [];
if (err) {
console.log('ERR: ' + err);
res.json({ code: 400, msg: err, sets: items });
return;
}
var $ = cheerio.load(sres.text);
$('div.g-main-bg ul.g-gxlist-imgbox li a').each(function(idx, element) {
var $element = $(element);
var $subElement = $element.find('img');
var thumbImgSrc = $subElement.attr('src');
items.push({
title: $(element).attr('title'),
href: $element.attr('href'),
thumbSrc: thumbImgSrc
});
});
res.json({ code: 200, msg: "", data: items });
});
});
var server = app.listen(8081, function() {
var host = server.address().address
var port = server.address().port
console.log("应用实例,访问地址为 http://%s:%s", host, port)
})运行demo.js就会返回我们拿到的数据,如图:
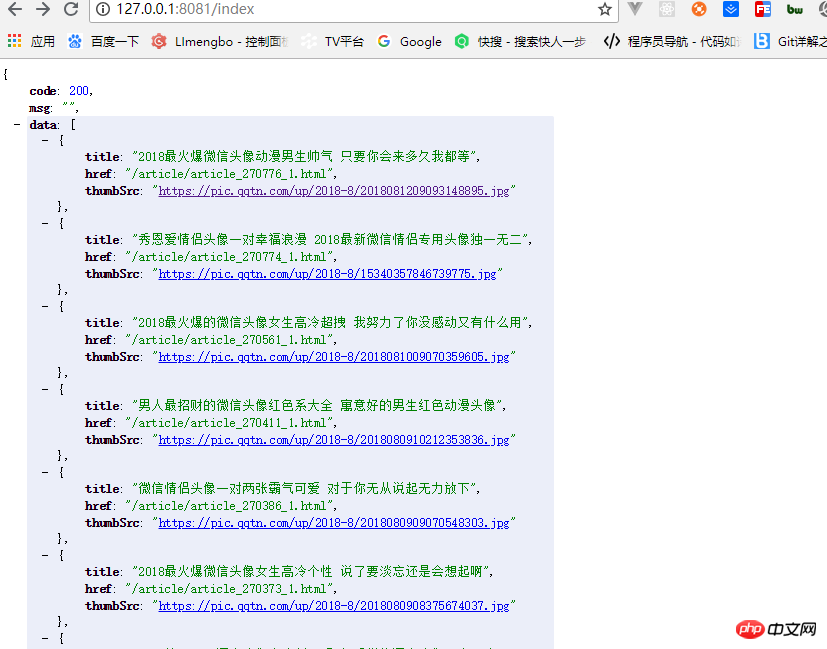
一个简单的node爬虫就完成了。
相关推荐:
node爬虫之gbk网页中文乱码解决方案_html/css_WEB-ITnose
Atas ialah kandungan terperinci node如何爬取网页中的图片(附代码). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Adakah JavaScript ditulis dalam C? Memeriksa buktiApr 25, 2025 am 12:15 AM
Adakah JavaScript ditulis dalam C? Memeriksa buktiApr 25, 2025 am 12:15 AMYa, teras enjin JavaScript ditulis dalam C. 1) Bahasa C menyediakan prestasi yang efisien dan kawalan asas, yang sesuai untuk pembangunan enjin JavaScript. 2) Mengambil enjin V8 sebagai contoh, terasnya ditulis dalam C, menggabungkan kecekapan dan ciri-ciri berorientasikan objek C. 3) Prinsip kerja enjin JavaScript termasuk parsing, penyusun dan pelaksanaan, dan bahasa C memainkan peranan penting dalam proses ini.
 Peranan JavaScript: Membuat Web Interaktif dan DinamikApr 24, 2025 am 12:12 AM
Peranan JavaScript: Membuat Web Interaktif dan DinamikApr 24, 2025 am 12:12 AMJavaScript adalah di tengah -tengah laman web moden kerana ia meningkatkan interaktiviti dan dinamik laman web. 1) Ia membolehkan untuk menukar kandungan tanpa menyegarkan halaman, 2) memanipulasi laman web melalui Domapi, 3) menyokong kesan interaktif kompleks seperti animasi dan drag-and-drop, 4) mengoptimumkan prestasi dan amalan terbaik untuk meningkatkan pengalaman pengguna.
 C dan JavaScript: Sambungan dijelaskanApr 23, 2025 am 12:07 AM
C dan JavaScript: Sambungan dijelaskanApr 23, 2025 am 12:07 AMC dan JavaScript mencapai interoperabilitas melalui webassembly. 1) Kod C disusun ke dalam modul WebAssembly dan diperkenalkan ke dalam persekitaran JavaScript untuk meningkatkan kuasa pengkomputeran. 2) Dalam pembangunan permainan, C mengendalikan enjin fizik dan rendering grafik, dan JavaScript bertanggungjawab untuk logik permainan dan antara muka pengguna.
 Dari laman web ke aplikasi: Aplikasi pelbagai JavaScriptApr 22, 2025 am 12:02 AM
Dari laman web ke aplikasi: Aplikasi pelbagai JavaScriptApr 22, 2025 am 12:02 AMJavaScript digunakan secara meluas di laman web, aplikasi mudah alih, aplikasi desktop dan pengaturcaraan sisi pelayan. 1) Dalam pembangunan laman web, JavaScript mengendalikan DOM bersama -sama dengan HTML dan CSS untuk mencapai kesan dinamik dan menyokong rangka kerja seperti JQuery dan React. 2) Melalui reaktnatif dan ionik, JavaScript digunakan untuk membangunkan aplikasi mudah alih rentas platform. 3) Rangka kerja elektron membolehkan JavaScript membina aplikasi desktop. 4) Node.js membolehkan JavaScript berjalan di sisi pelayan dan menyokong permintaan serentak yang tinggi.
 Python vs JavaScript: Gunakan Kes dan Aplikasi MembandingkanApr 21, 2025 am 12:01 AM
Python vs JavaScript: Gunakan Kes dan Aplikasi MembandingkanApr 21, 2025 am 12:01 AMPython lebih sesuai untuk sains data dan automasi, manakala JavaScript lebih sesuai untuk pembangunan front-end dan penuh. 1. Python berfungsi dengan baik dalam sains data dan pembelajaran mesin, menggunakan perpustakaan seperti numpy dan panda untuk pemprosesan data dan pemodelan. 2. Python adalah ringkas dan cekap dalam automasi dan skrip. 3. JavaScript sangat diperlukan dalam pembangunan front-end dan digunakan untuk membina laman web dinamik dan aplikasi satu halaman. 4. JavaScript memainkan peranan dalam pembangunan back-end melalui Node.js dan menyokong pembangunan stack penuh.
 Peranan C/C dalam JavaScript Jurubah dan PenyusunApr 20, 2025 am 12:01 AM
Peranan C/C dalam JavaScript Jurubah dan PenyusunApr 20, 2025 am 12:01 AMC dan C memainkan peranan penting dalam enjin JavaScript, terutamanya digunakan untuk melaksanakan jurubahasa dan penyusun JIT. 1) C digunakan untuk menghuraikan kod sumber JavaScript dan menghasilkan pokok sintaks abstrak. 2) C bertanggungjawab untuk menjana dan melaksanakan bytecode. 3) C melaksanakan pengkompil JIT, mengoptimumkan dan menyusun kod hot-spot semasa runtime, dan dengan ketara meningkatkan kecekapan pelaksanaan JavaScript.
 JavaScript in Action: Contoh dan projek dunia nyataApr 19, 2025 am 12:13 AM
JavaScript in Action: Contoh dan projek dunia nyataApr 19, 2025 am 12:13 AMAplikasi JavaScript di dunia nyata termasuk pembangunan depan dan back-end. 1) Memaparkan aplikasi front-end dengan membina aplikasi senarai TODO, yang melibatkan operasi DOM dan pemprosesan acara. 2) Membina Restfulapi melalui Node.js dan menyatakan untuk menunjukkan aplikasi back-end.
 JavaScript dan Web: Fungsi teras dan kes penggunaanApr 18, 2025 am 12:19 AM
JavaScript dan Web: Fungsi teras dan kes penggunaanApr 18, 2025 am 12:19 AMPenggunaan utama JavaScript dalam pembangunan web termasuk interaksi klien, pengesahan bentuk dan komunikasi tak segerak. 1) kemas kini kandungan dinamik dan interaksi pengguna melalui operasi DOM; 2) pengesahan pelanggan dijalankan sebelum pengguna mengemukakan data untuk meningkatkan pengalaman pengguna; 3) Komunikasi yang tidak bersesuaian dengan pelayan dicapai melalui teknologi Ajax.


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

EditPlus versi Cina retak
Saiz kecil, penyerlahan sintaks, tidak menyokong fungsi gesaan kod

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

